Intro
최근 Vision-and-Language Navigation (VLN) 분야는 괄목할 만한 성장을 이루었지만, 여전히 시뮬레이션 모델과 실제 로봇 배포 환경 사이에는 큰 격차가 존재합니다. 기존 연구들은 로봇의 움직임과 제어에 대해 지나치게 이상적인 가정(Idealized assumptions)을 하고 있는데, 대부분의 벤치마크는 물리적 실체가 없는 점(Point)이나 이상적인 바퀴형 에이전트를 가정하기 때문에, 실제 로봇이 겪게 되는 시점 변화(Viewpoint shifts), 넘어짐(Falling), 충돌(Collision), 동작 오류(Motion errors)와 같은 물리적 문제들을 제대로 다루지 못한다고 합니다.
예를들어, 이전 VLN 연구 중 하나는 미리 정의된 그래프 노드 사이를 ‘점프(Teleporting)’하며 이동하는 방식이었는데, 이는 아무래도 노드 사이를 움직인다는 가정으로 접근하다보니 실제 로봇의 연속적인 움직임과는 거리가 멀었습니다.
최근 연구들은 연속적인 공간에서의 네비게이션을 수행하고자 모델을 설계하였지만, 이 역시 가상의 원통형 로봇(Pseudo Cylinder Robots)을 사용하여 낮은 수준의 오라클 액션을 수행할 뿐이며, 실제 로봇의 복잡한 기구학이나 물리적 상호작용은 반영하지 못한다고 합니다.
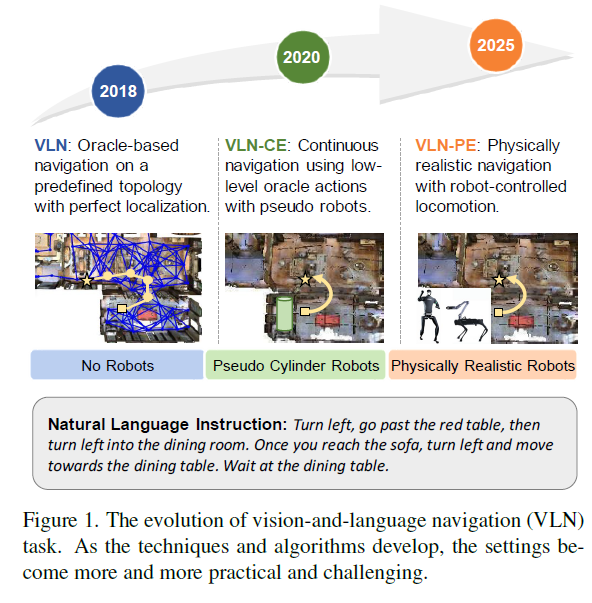
저자들은 이러한 한계를 극복하기 위해 VLN-PE라는 새로운 플랫폼과 벤치마크를 제안합니다. 우선 단순한 애니메이션이 아닌, 물리 엔진(GRUTopia/Isaac Sim)을 기반으로 실제 로봇 역학을 시뮬레이션합니다. 해당 시뮬레이션에서는 휴머노이드, 4족 보행, 바퀴형 로봇 등 다양한 형태의 로봇을 지원하며, 각각에 맞는 실제 로봇 제어기(Locomotion Controller)를 연동합니다. 그리고 이전 연구들이 많이들 활용한 기존 Matterport3D(MP3D) 환경뿐만 아니라 고품질 합성 장면과 3D Gaussian Splatting(3DGS)으로 스캔된 현실적인 환경을 통합하여 시각적 다양성을 확보했다고 하네요.
VLN-PE Platform and Benchmark
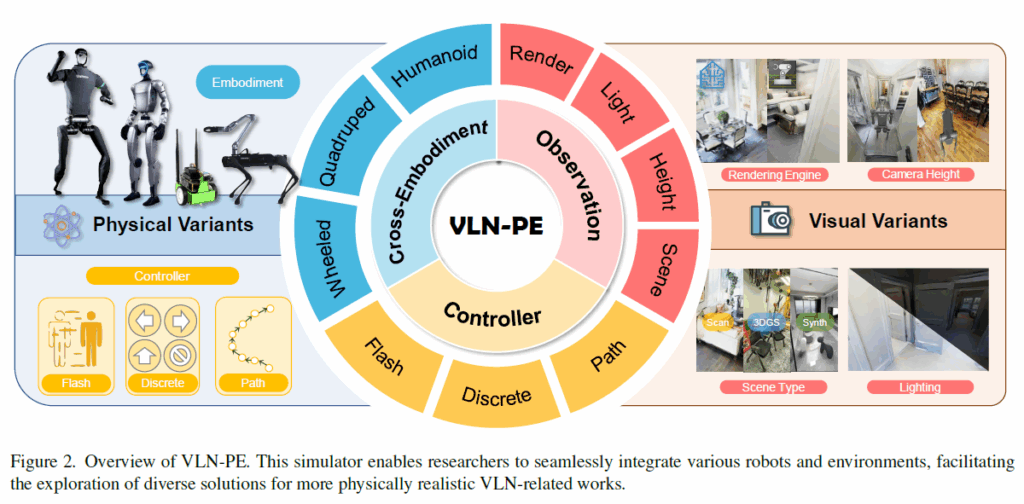
기존 연구들이 단순히 애니메이션이나 가상의 위치 이동(Teleporting)에 의존했던 것과 달리, 저자들이 제안하는 VLN-PE는 물리적으로 사실적인 시뮬레이터인 GRUTopia를 기반으로 구축되었습니다. 이는 NVIDIA Isaac Sim을 활용하여 정교한 물리 법칙이 적용되었으며, 휴머노이드(Unitree H1, G1), 4족 보행 로봇(Unitree Aliengo), 바퀴형 로봇(Jetbot) 등 다양한 형태의 로봇을 지원합니다. 그리고 각각에 최적화된 RL 기반 컨트롤러 API를 제공하는 등 단순한 ‘이동’이 아니라 실제 로봇의 ‘보행’과 ‘주행’을 시뮬레이션 할 수 있다고 합니다.
또한 시뮬레이션 데이터의 문제점은 Real domain과의 시각적인 차이가 존재한다는 점인데 저자들은 이를 의식하여 시각적 다양성을 확보하고 기존 데이터셋의 한계를 보완하였다고 하네요. 우선 기존의 벤치마크에서 사용하던 Matterport3D를 개선하는 과정을 수행하는데 기존 90개의 MP3D 씬을 가져오되, 물리 시뮬레이션 시 로봇이 걸려 넘어질 수 있는 바닥의 구멍이나 결함들을 수작업으로 수정했다고 합니다. 또한 조명 조건을 조절할 수 기능을 추가하여 다양한 환경 변화를 실험할 수 있게 했습니다. 그리고 기존의 VLN-CE 벤치마크의 좌표계를 저자들이 제안하는 VLN-PE 시뮬레이션 환경과 정합시킴으로써 기존에 사용하던 어노테이션을 동일하게 활용할 수 있다고 합니다.
다음으로 MP3D의 시각적 한계를 넘어서기 위해, 고품질의 합성 데이터인 GRScenes (10개 씬)와 3D Gaussian Splatting 기술로 스캔된 실제 실험실 환경을 추가했습니다 . 이는 렌더링 노이즈나 고화질 환경에서의 모델 성능을 평가하는 데 사용됩니다.
Dataset
이러한 시뮬레이션을 기반으로 학습 및 평가할 수 있는 데이터셋을 구축해야하는데, 저자들은 이러한 데이터셋 구축을 표준 벤치마크인 R2R 데이터셋을 기반으로 생성하였다고 합니다. 다만 현재 보행 컨트롤러의 한계로 인해 계단이 포함된 에피소드는 데이터셋 구축 때 제외시켰다고 하네요. 이렇게 필터링 후 남은 R2R 데이터셋은 학습용(Training) 8,679개, 검증용-Seen(Val-Seen) 658개, 검증용-Unseen(Val-Unseen) 1,347개의 에피소드로 재구성되었습니다.
또한, 기존 Matterport3D(MP3D) 환경의 시각적 다양성 부족을 해결하기 위해, 새로 도입된 씬들에 대해 LLM을 활용하여 지시어(Instruction)를 생성하고 검증하는 파이프라인을 구축했습니다. 구축 과정은 새로운 씬에서 경로를 샘플링한 뒤, LLM을 통해 VLN 스타일의 네비게이션 지시어를 생성합니다. 이후 엄격한 수동 검증을 거침으로써 2개의 평가 데이터셋을 만들게 되는데, 하나는 고품질 합성 환경인 GRScenes를 기반으로 만든 GRU-VLN10 데이터셋이며 해당 데이터셋은 3개의 씬을 학습용, 7개의 씬을 Unseen 테스트용으로 배정했습니다.
두번째 평가 데이터셋은 3DGS-Lab-VLN 데이터셋으로 3D Gaussian Splatting으로 렌더링된 실제 실험실 환경이 구성되어있으며 이는 렌더링 노이즈가 있는 현실적인 환경에서의 성능을 평가하기 위함이라고 합니다.
평가에 사용되는 평가 지표는 물리적 현실성을 반영한 새로운 평가지표를 도입했다고 하며, 이는 물리 시뮬레이션 환경에서 로봇의 안정성을 평가할 수 있다고 합니다. 우선 기존 지표와 새로 도입한 지표는 다음과 같습니다.
기존지표
- TL (Trajectory Length): 이동한 경로의 총 길이(m).
- NE (Navigation Error): 예측된 도착 지점과 실제 목표 지점 사이의 거리.
- SR (Success Rate): 목표 지점의 일정 반경 내에 성공적으로 도착한 비율.
- OS (Oracle Success Rate): 경로 중 어느 한 지점이라도 목표 근처에 도달했었던 비율 .
- SPL (Success weighted by Inverse Path Length): 성공률(SR)에 경로 효율성을 가중치로 둔 지표.
새지표
- FR (Fall Rate): 로봇이 의도치 않게 넘어지는 빈도.
- StR (Stuck Rate): 로봇이 장애물 등에 걸려 움직이지 못하게 되는(Deadlock) 빈도.
이는 시뮬레이션과 달리 실제 하드웨어가 움직임 도중에 넘어지거나 부딪히는 물리적인 상황까지 고려한 것으로 보입니다.
그리고 저자들의 VLN-PE의 가장 큰 특징 중 하나는 시뮬레이션과 실제 로봇 제어 간의 불일치를 최소화했다는 점인데 이를 위해 단순히 로봇을 좌표상으로 이동시키는 것이 아니라, 최신 강화학습 기반의 이동 정책(Locomotion Policy)을 API 형태로 탑재했습니다. 이는 휴머노이드나 4족 보행 로봇과 같이 복잡한 관절 움직임이 필요한 로봇들에 최적화되어 있다고 하네요.
또한 시뮬레이션에서 훈련된 이동 모델을 실제 로봇 실험에 수정 없이 그대로 적용할 수 있도록 설계되어있어 연구자들은 시간과 비용이 많이 드는 실제 실험 대신 시뮬레이션 상에서 실질적인 검증을 수행할 수 있으며, 오픈소스 코드를 통해 더 발전된 이동 알고리즘을 쉽게 통합할 수 있다고 합니다.
Baselines
새로운 데이터셋을 제안하였으니 그럼 베이스라인 방법론들도 적용하여 벤치마크를 구성해야겠죠. 저자들은 현재 대부분의 실제 로봇이 1인칭 시점의 RGB-D 핀홀 카메라(Egocentric RGB-D pinhole cameras)를 장착하고 있다는 점을 감안하여, 이 하드웨어 설정에 맞는 세 가지 서로 다른 기술 파이프라인을 선정했습니다.
우선 Single-step Discrete Action Prediction 방법론으로 매 스텝마다 ‘앞으로 이동’, ‘왼쪽 회전’과 같은 이산적인(Discrete) 행동을 하나씩 예측하는 전통적인 End-to-End 학습 방식입니다. 이산 행동 예측 모델도 마찬가지로 3가지 모델을 가져왔는데 우선 Seq2Seq 모델은 LSTM으로 지시어를, ResNet50으로 이미지를 인코딩한 뒤 GRU를 통해 다음 행동을 예측합니다.
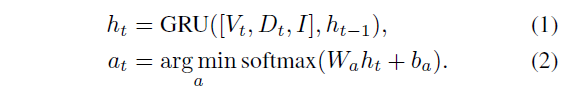
여기서 V, D, I는 각각 RGB, Depth 그리고 text instruction embedding을 의미합니다.
CMA(Cross-Modal-Attention)은 Seq2Seq를 개선한 모델로 언어와 시각 정보 간의 교차 주의(Attention) 메커니즘을 추가하여 명령어와 화면의 연관성을 더 잘 파악하도록 설계되었습니다. 우선 CMA 방법론은 GRU가 2개로 구성이 되어있는데, 첫번째 GRU Unit은 이전 액션 값과 이전 히든 상태, 그리고 이미지와 깊이 임베딩을 토대로 현재 히든 상태 h^{1st}_{t} 를 예측을 합니다. 그리고 이 현재 히든 상태는 아래 수식과 같이 3가지 모달리티에 대한 어텐션을 수행하게 됩니다.
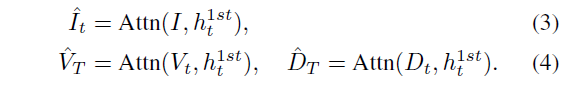
이후 2번째 GRU에서 아래 수식과 같이 입력 특징들과 예측된 액션 값 등을 concat하여 최종 action을 추론합니다.
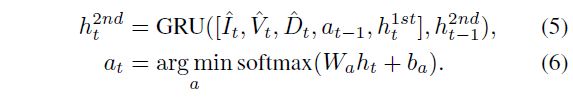
3번째 베이스라인인 Navid는 최신 트렌드를 반영한 비디오 기반의 거대 멀티모달 모델(MLLM)입니다. LLaMa-VID를 기반으로 하며, 이전의 작은 모델들과 달리 방대한 사전 지식을 활용하여 이동 거리나 회전 각도를 구체적인 수치 인자(Arguments)로 예측한다고 합니다.
구체적으로, 연속된 t프레임의 비디오를 이미지 인코더를 통해 인코딩한 뒤 해당 이미지 특징을 language token과 정합시킵니다. 그리고 해당 모델에는 <HIS>, <OBS>, <NAV> 토큰이 존재하는데 각각은 과거 관측 기록, 현재 관측, 행동에 대한 LLM의 언어적 형태를 의미합니다.
NaVid의 출력값은 이산적인 집합에서 선택된 행동 유형과 각 행동에 필요한 정량적 인자로 구성됩니다. 구체적으로 ‘전진(Forward)’ 행동에 대해서는 이동 거리를 예측하고, ‘좌회전’ 및 ‘우회전’에 대해서는 회전 각도를 추정합니다. 이렇게 예측된 값들은 평가 및 실제 배포 단계에서 정규 표현식(regular expression) 파서를 통해 행동 유형과 인자로 추출되어 활용됩니다.
Multistep Continuous Prediction Method
지금까지 단일 단계 이산 행동 예측을 수행하는 모델이었다면 지금은 다중 단계 연속 예측 모델 (Multi-step Continuous Prediction)에 대한 베이스라인입니다.
최근 로봇 팔 제어(Manipulation)나 국소 네비게이션 분야에서 Diffusion Policy는 부드럽고 안정적인 경로를 생성하는 데 탁월한 성능을 입증했습니다. 저자들은 이러한 특성이 연속적인 움직임이 필요한 VLN에도 유용할 것이라 판단하고, 이를 VLN 테스크에 맞게 개량한 RDP (Recurrent Diffusion Policy)를 새로운 베이스라인으로 제안했습니다.
우선 RDP는 이전에 소개드린 베이스라인 방법론들과 동일하게 1인칭 시점의 RGB-D 입력을 받으며, 예측값이 이산적이지 않고 연속적인 경로를 생성하는 구조를 가집니다.
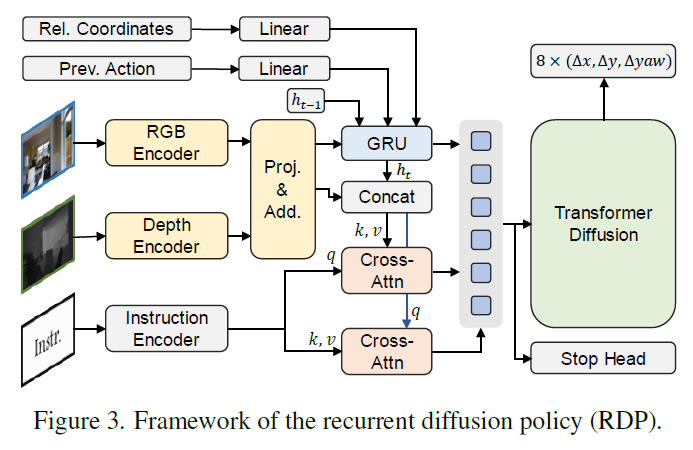
텍스트와 이미지 간의 정교한 정렬을 위해 LongCLIP 모델을 사용하여 각각 인코딩을 수행하며, 뎁스 이미지의 경우에는 기존 방식(CMA 등)과 동일하게 사전 학습된 ResNet50을 사용합니다. 그리고 시각 정보와 언어 정보는 두 개의 멀티 헤드 크로스 어텐션 모듈을 통해 서로 정보를 교환하고 정렬됩니다. 마지막으로 퓨전된 특징(c_t)을 조건으로 받아, 트랜스포머 구조의 디코더가 확산 과정을 통해 행동을 생성합니다.
기존 모델들이 ‘전진’, ‘회전’ 같은 이산적인(Discrete) 행동을 선택했다면, RDP는 향후 T_a 스텝 동안의 연속적인 상대 변위와 회전각(\{\Delta x_t, \Delta y_t, \Delta yaw_t\})을 한 번에 예측합니다. 이러한 방식은 촘촘한 웨이포인트(Dense Waypoints)를 생성하여 부드러운 이동을 가능하게 합니다.
그리고 단순한 로봇 제어와 달리, VLN은 긴 문맥을 이해하고 복잡한 지시를 따라야 하기 때문에 저자들은 이를 위해 Recurrent GRU와 Stop head라는 두 가지 핵심적인 설계를 추가했습니다.
우선 Reccurent GRU의 경우 일반적인 Diffusion Policy는 현재 상태만을 보고 행동을 결정하는 경우가 많지만, VLN은 과거의 방문 기록이 중요합니다. 이를 위해 GRU 유닛을 도입하여 과거의 관측 정보(History)를 기억하고 업데이트하도록 설계하여 장기 의존성(Long-range dependency) 문제를 해결했습니다.
그리고 Stop head의 경우 Diffusion 모델은 연속적인 움직임을 생성하는 데는 능하지만, “언제 멈춰야 하는지”를 언어 지시어에 맞춰 정확히 판단하는 데 어려움이 있었습니다. 이를 보완하기 위해, 네비게이션 진행률(0에서 1까지)을 예측하는 별도의 MLP 헤드(Stop Head)를 추가하여 정밀한 정지 결정을 내리도록 하네요.
해당 모델의 학습 방식은 DDPM(Denoising Diffusion Probabilistic Models) 방식을 따릅니다. 노이즈가 섞인 행동 데이터로부터 원래의 행동을 복원하는 노이즈 예측 손실(MSE)과, 정지 시점을 예측하는 손실을 결합하여 모델을 최적화하는 것이죠.
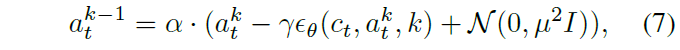
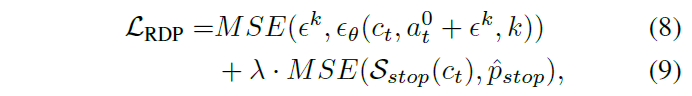
최종 학습 loss는 위와 같은데 \hat{p}_{stop} 은 GT stop progress를 의미합니다. 즉 수식 9는 stop head를 학습시키는 함수이며 수식8이 노이즈 예측 손실에 해당합니다.
Modular Map-based Train-free Method
앞서 소개드린 방법론들은 End-to-End 학습 방식으로 데이터에 의존적이며 새로운 환경에 적응하기 어렵다는 단점이 있습니다. 반면, 최근 등장한 LLM과 Open-vocabulary 비전 모델들은 별도의 학습 없이도(Zero-shot) 복잡한 추론과 인식이 가능합니다. 저자들은 이러한 사전 학습된 모델(Pre-trained Models)들을 모듈처럼 결합하여 네비게이션 시스템을 구축하는 방식을 테스트했습니다.
저자들은 대표적인 방법론으로 VLMaps를 선정하고, 이를 조금 개선시켰는데 우선 LLM을 통하여 복잡한 자연어 명령어를 해석하여, 실행 가능한 파이썬 코드 형태의 하위 목표들로 변환합니다 (e.g. 소파와 의자 사이로 이동해” \rightarrow robot.move_in_between('sofa', 'chair').
그리고 로봇이 주변 환경을 이해하기 위해 LSeg 모델을 사용합니다. 해당 모델은 3D 공간의 복셀들을 텍스트 임베딩과 정렬된 의미론적 지도로 구축하여, “소파가 어디에 있는지”를 텍스트 검색하듯 찾아낼 수 있게 합니다. 이러한 VLMaps는 목표 물체가 이미 지도에 있거나 시야에 보일 때는 잘 작동하지만, 보이지 않는 곳에 있는 물체를 찾아가는 능력은 부족했습니다. 따라서 저자들은 이를 보완하기 위해 VLFM (Vision-Language Frontier Maps)이라는 탐험 정책을 통합했습니다.
해당 logic은 만약 로봇이 현재 시야나 지도에서 목표 물체를 찾지 못하면, 1) 제자리에서 회전하며 주변을 살피고, 2) 아직 가보지 않은 영역(Frontier)으로 이동하여, 3) LSeg 인코더를 통해 해당 위치에서 목표 물체가 보일 가능성을 평가합니다.
Experiments
그럼 이제 실험 섹션 다뤄보겠습니다. 저자들은 실험 섹션을 통해 다음과 같은 질문들을 해소하고자 하였습니다.
- 기존 VLN-CE 모델들은 물리 환경(VLN-PE)에서 얼마나 잘 작동하는가?
- 물리 컨트롤러(Physical Controller)는 성능에 어떤 영향을 미치는가?
- 로봇의 형태(Cross-embodiment)가 달라지면 어떻게 되는가?
- 환경 관측 조건(조명)은 얼마나 중요한가?
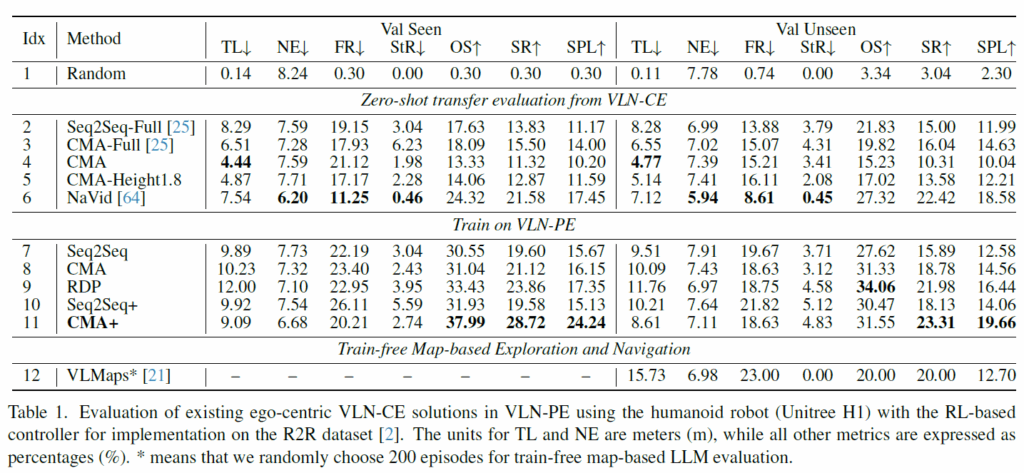
우선 첫번째 질문에 대한 실험들부터 살펴보겠습니다. 우선 위의 표를 살펴보면 VLN-CE로 학습된 모델을 곧바로 VLN-PE로 zero-shot 평가를 수행하였을 때 상당한 성능 하락을 겪었다고 합니다. 구체적으로 Seq-Seq Full, CMA-FULL, NaVid의 success rate가 10, 16, 18%로 상당히 낮은 모습입니다. 그나마 Navid가 가장 좋은 성능을 보여준다는 점에서 MLLM이 VLN에서 보여주는 잠재력이 높다고 평가하는 모습입니다.
또한 제일 아래쪽 열에 있는 VLMaps의 경우 Unseen 상황에서 SR가 20%정도로 기존 연구들과 비교해서 더 좋거나 유사한 성능을 보여주고 있다는 점에서 저자들은 해당 방법론도 하나의 유의미한 VLN 방법론이라고 합니다.
다음은 zero-shot이 아닌 VLN-PE로 학습해서 평가하는 In domain에서의 평가 결과입니다. 우선 기존 VLN-CE 모델들은 수십만 건의 데이터 증강(Augmentation)을 거쳤음에도 불구하고, 증강 없이 VLN-PE 환경에서 수집한 데이터로 처음부터 학습한(Train from scratch) 모델보다 성능이 낮았습니다.
저자들이 in-domain 평가와 zero-shot 평가 결과를 비교하고 있는데 이게 아무래도 zero-shot이라 할지라도 학습 때 몇십만장을 학습한 모델과 in-domain에서 조금의 데이터로 학습한 모델의 성능 차이를 두고 무엇이 더 좋다 안좋다라고 하기 모호하다고 저는 생각을 합니다. 하지만 저자들의 의도를 조금 고려해봤을 때 결국 VLN-CE보다 VLN-PE가 더 현실적인 조건들을 고려했다보니 도메인 강건성을 위해 학습 데이터를 늘리는 것보다 데이터 양이 적더라도 더 사실적인 환경들을 구축해야될 필요성이 있다는 주장을 하고 싶은게 아닐까 싶습니다.
물론 10번과 11번 행과 같이 VLN-CE에서 SOTA 결과를 낸 가중치에 VLN-PE 데이터셋으로 사전학습한 경우 가장 좋은 성능을 보여준다는 점도 참고 바랍니다. 그리고 이산적인 행동 예측 모델 말고도 저자들이 새롭게 제안한? 연속적인 행동 예측 모델 RDP에 대한 성능도 표1에 같이 리포팅되고 있습니다.
저자들이 제안한 확산 기반의 RDP 모델은 처음부터 학습시켰을 때 기존의 scratch로 학습한 CMA나 Seq2Seq보다 우수한 성능을 보여, 연속적인 경로 예측 방식이 물리 환경에 더 적합함을 입증했습니다.
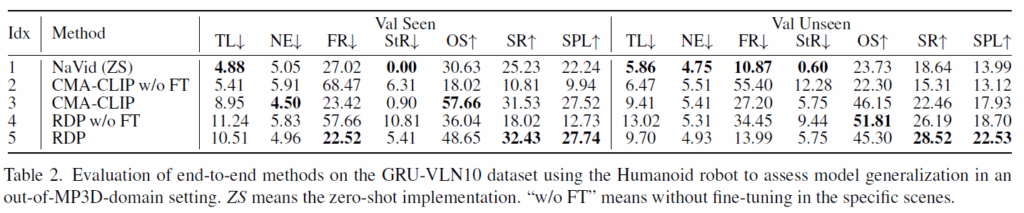
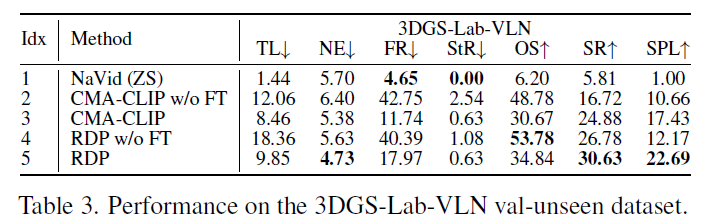
그리고 위에 표 2,3은 저자들이 보다 사실적인 시각 환경을 고려한 평가용 데이터셋 2종류를 제안했다고 했었는데 그에 대한 결과값입니다. 우선 눈여겨보실 점은 새로운 환경의 데이터 441개만으로 작은 모델(CMA-CLIP 등)을 미세 조정했을 때, 거대 모델(NaVid)의 제로샷 성능을 크게 앞질렀습니다. 이는 적은 양의 데이터만으로 학습하는 것도 indomain 상황에서는 충분히 의미있는 결과를 낼 수 있다는 점을 증명합니다.
그리고 표3에서 NaVid가 상당히 부정확한 성능을 보여주고 있는데, 저자들은 실제 환경을 3D Gaussian Splatting으로 렌더링할 때 3DGS 특유의 렌더링 노이즈가 거대 모델의 시각적 인식을 방해했을 것이라고 예측합니다.
Impact of Physical Controller
다음은 2번째 질문이었던 물리 컨트롤러가 네비게이션 성능에 어떠한 영향을 미치는지에 대한 실험입니다. 해당 실험의 목적은 단순히 로봇을 좌표상으로 이동시키는 것이 아니라, 실제 다리로 걷는(Locomotion) 물리적 역학을 학습 과정에 포함시키는 것이 성능에 어떤 영향을 미치는가?에 대하여 알아보는 것입니다.
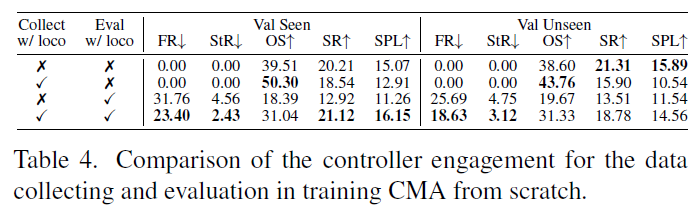
저자들은 자신들의 VLN-PE 플랫폼의 가장 큰 장점인 ‘실제와 유사한 물리 시뮬레이션’ 기능을 활용하여, 물리적 보행 컨트롤러(Physical Controller)의 개입 여부가 모델 성능에 미치는 영향을 실험했습니다. 실제 다리가 달린 로봇은 바퀴 달린 로봇이나 이상적인 에이전트와 달리, 걸을 때마다 몸이 흔들리고 시야가 요동치며(Motion disturbances), 때로는 균형을 잃기도 합니다. 저자들은 이러한 물리적 역학이 포함된 데이터로 모델을 학습시키면, 로봇이 더 잘 적응할 수 있을까?라는 가설을 세웠습니다.
휴머노이드 로봇을 대상으로, 데이터 수집(Collect)과 평가(Eval) 단계에서 물리 컨트롤러(Locomotion Controller)를 켰는지 껐는지에 따라 성능을 비교했습니다. 즉 표4번에서 Collect w/ loco은 물리 컨트롤러를 켜고(로봇이 실제로 걸어 다니며) 수집한 데이터로 학습한 것을 의미하며, Eval w/ loco은 물리 컨트롤러를 켜고(실제 물리 법칙 적용) 평가함을 의미합니다.
실험 결과, 학습(Collection)과 평가(Evaluation) 단계 모두에서 동일하게 물리 컨트롤러를 사용했을 때 가장 높은 성능을 보였습니다. 반대로, 컨트롤러 없이 이상적으로 수집된 데이터로 학습한 뒤, 평가 때만 물리 컨트롤러를 적용하면 성능이 급격히 하락했습니다 (SR 12.92% \rightarrow 21.12%로 차이 발생)
그리고 저자들이 강조하는 부분 중 하나는 물리 컨트롤러로 수집된 데이터(즉, 흔들림과 불안정함이 포함된 데이터)로 학습한 모델이 넘어짐(FR)과 끼임(StR) 비율을 감소시켰다는 점입니다. 이러한 결과들을 VLN 모델들은 토대로 길을 찾는 법’뿐만 아니라, 학습 데이터에 내재된 ‘로봇의 물리적 움직임 특성’까지 함께 학습한다는 것을 보여주며 노이즈가 섞인 현실적인 데이터로 학습해야 실제 물리 환경에서의 불안정성을 견디고, 넘어지거나 끼이는 상황을 줄일 수 있음을 나타냅니다.
Impact of Cross-embodiment Data
해당 실험은 휴머노이드(키가 크고 2족 보행), 4족 보행 로봇(키가 작고 4족 보행), 바퀴형 로봇(안정적 주행) 간의 데이터가 서로에게 어떤 영향을 미치는지 분석한 실험입니다.
우선 저자들은 기존 모델(NaVid 등)을 서로 다른 로봇에 적용했을 때 성능 차이가 발생하는지, 그리고 여러 로봇의 데이터를 섞어서 학습시키면 더 강력한 모델이 탄생할 수 있는지를 검증했습니다.
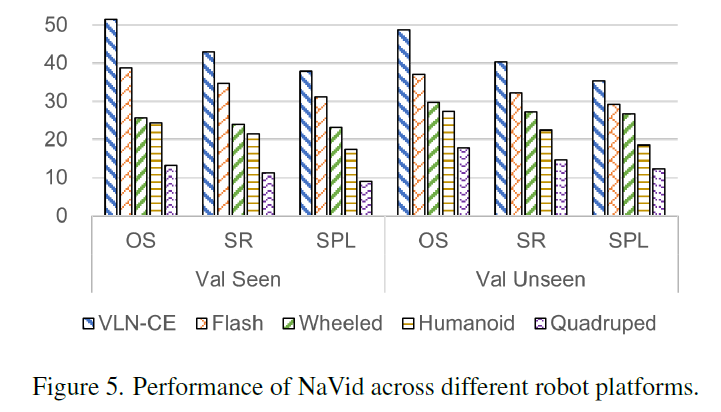
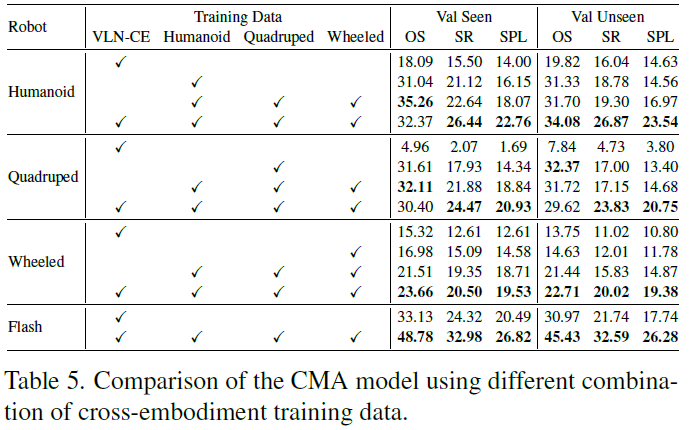
실험 결과를 빠르게 정리해드리면 우선 VLN 모델은 카메라 높이(Camera Height)에 극도로 민감했습니다. 표5에서 VLN-CE로만 학습된 모델에서의 결과를 살펴보시면 기존 시뮬레이터(Habitat)와 유사한 키와 움직임을 가진 휴머노이드 로봇에서는 모델이 비교적 잘 작동했습니다. 반면, 키가 약 0.5m로 매우 낮은 4족 보행 로봇(Quadruped)에 기존 모델을 적용하자 성능이 거의 0에 가깝게 추락했습니다. 이는 모델이 학습한 ‘눈높이’와 실제 로봇의 시점이 너무 달랐기 때문입니다.
2번째로 각 로봇의 시점에서 수집된 데이터로 모델을 미세 조정(Fine-tuning)했을 때, 성능이 극적으로 회복되었다는 점입니다. 특히 휴머노이드 로봇의 경우 OSR이 19.82에서 31.33으로, 4족 보행 로봇의 경우 7.84에서 32.37로 대폭 상승했습니다. 이는 로봇마다 다른 viewpoint를 가지는 점을 고려해 최소한 자신의 추론 시점을 학습시키는 것이 필수적임을 보여줍니다.
마지막으로, 휴머노이드, 4족 보행, 바퀴형 로봇의 데이터를 모두 섞어서 학습시켰을 때, 단일 로봇 데이터로만 학습했을 때보다 전반적으로 더 우수한 성능을 보였습니다. 저자들은 이것이 단순한 데이터 양의 증가 때문만이 아니라, 다양한 높이와 시점에서 환경을 학습함으로써 모델이 공간을 더 입체적이고 강건하게 이해하게 되었기 때문이라고 분석했습니다.
Impact of Lighting Conditions
마지막 실험입니다. 바로 조도에 관한 것으로 기존 VLN이 조도 강인성에 얼마나 강한지에 대한 실험인 것이죠.
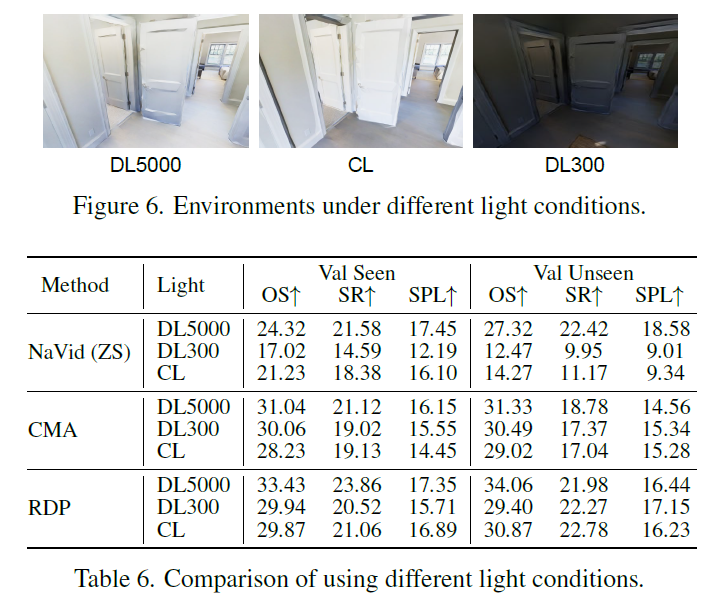
VLN-PE 플랫폼의 렌더링 기능을 활용하여, 완벽한 조명 환경이 아닌 다양한 조명 조건하에서 모델들의 강건성(Robustness)을 평가했습니다. 우선 조도 환경은 DL5000, CL, DL300으로 3가지가 있으며 각각 패널 조명(Disc Light) 강도가 5000인 밝은 주간 환경 (기준점), 로봇에 부착된 조명(전조등)만 사용하는 환경, 그리고 조명 강도가 300으로 매우 어두운 야간 환경을 의미합니다. 여기서 CL의 경우 .정면은 반사광으로 인해 밝지만, 측면은 어두워지는 불균일한 조명 특성을 가진다고 하네요.
표6의 결과를 살펴보시면, 오직 RGB 카메라 영상에만 의존하는 NaVid는 조명 변화에 매우 취약했습니다. 구체적으로, 어두운 환경(DL300)이나 전조등 환경(CL)에서 성공률(SR)이 기준점 대비 약 11%~12% 정도 하락하는 모습이죠.
반면, RGB와 깊이 정보를 함께 사용하는 CMA와 RDP 모델은 성능 저하가 크지 않았습니다. 이는 RGB 영상이 어두워져 사물 식별이 어려워져도, 깊이 정보(Depth)는 벽이나 가구의 구조적 형태를 그대로 유지하고 있기 때문에 길을 찾는 데 큰 타격을 입지 않았다고 볼 수 있고, 보통 Depth camera가 적외선 카메라를 사용한다는 점에서 조도 환경에서도 강건한 깊이를 추론한다는 가정이 깔린 모습으로 보입니다.
결과적으로 실제 물리 환경에서의 배포를 위해서는 단일 모달리티(RGB Only)만으로는 부족하다는 것을 의미하며, 저자들은 로봇이 다양한 조명 조건에서도 안정적으로 작동하려면, 빛의 영향을 받지 않는 Depth 센서나 라이다(LiDAR/Radar)와 같은 멀티모달 센서 퓨전이 필수적임을 강조합니다.
결론
저도 자세히는 모르지만 vision domain에서 학습 및 평가하던 VLN 벤치마크는 이미 성능이 너무 올라 saturation 된 것으로 알고 있습니다. 그래서 새로운 벤치마크가 필요할 수 있겠다는 생각을 가지긴 했었는데 이번 ICCV2025에서 보다 사실적인 상황을 고려한 벤치마크가 나온 것 같아서 긍정적인 것 같습니다. 환경이 얼마나 복잡하면 SR이 20~30%대에 머물러 있는지.. 많이 어려운 환경인가 봅니다. 근데 또 베이스라인 벤치마크가 기존의 VLN SOTA 방법론들이 빠져있는 것 같다는 생각도 들어서 해당 벤치마크가 학계에 어떤 영향을 미치는지는 조금 더 지켜봐야 할 것 같습니다.
안녕하세요 정민님 리뷰 감사합니다.
우현이 리뷰를 보거나 얼핏 지나가면서 봤을 때 navigation 쪽은 생각보다 문제가 많이 풀려있나? 했었는데, 글을 읽고나니 VLN을 실세계에 가져다 두고 직접 제어를 시키면 역시 빡세구나 싶었습니다. 각종 domain gap을 비롯해 벤치마크에서 SR이 20~30퍼센트 대에 머물고 있는 것을 보니 manipulation쪽과 근본적으로 비슷한 문제를 겪고있는 것 같기도 합니다. 데이터의 품질과 viewpoint, RGB만의 한계 등등 역시나 아직 해결할것이 많아 보이는 것 같은 느낌이 들었습니다.
DP를 개선시킨 RDP도 흥미로웠는데, 질문이 두가지 있습니다.
Q1. 어떻게 멈추지?에 대한 부분이 따로 학습하는 term이 있다는 것을 처음 알았습니다. 이러한 stop head는 어떻게 학습하는지 알 수 있을까요? 가만 생각해보니 navigation은 단지 clean한 액션을 뱉는것 외에도 내가 어디있는지를 명확히 알고 거기서 멈추는게 중요한 것 같은데 학습 데이터에 이러한 부분이 있는지 궁금합니다.
Q2. 이것도 egocentric한 view를 가지고만 모델이 맥락을 판단할 때 핵심인 것 같은데, 제가 뭔가 놓친게 있는 것 같습니다. RDP에서 history를 사용해서 내가 지금 어디있는지를 더 강화하는 것 같은데, 기존 manipulation용 DP에서 직전, 혹은 두개 정도의 이전 상태를 추가로 입력받는것과는 조금 다른 포인트가 있나요?
저도 VLN 쪽 논문을 많이 본 편은 아니어서 자신있게 답하기는 어려우나 저자들이 주장하는 기존의 VLN-CE라고 불리는 시뮬레이션 상의 벤치마크에서는 VLN의 성능이 매우 높은 것으로 보았습니다. SR이 막 80%를 넘겼던 것 같아요. 하지만 해당 벤치마크는 리뷰 내용에서도 담겼듯이 가상의 원통형 로봇을 agent로 가정하고 조도, 환경 다양성도 크게 고려되지 않았으며, 당연히 넘어지거나 벽, 장애물에 끼임도 크게 고려하지 않았다보니 높게 책정되었던 것 같습니다.
RDP 관련해서는 리뷰 내 수식9번을 보시면 GT stop progress와 모델의 predict progress끼리 MSE loss를 계산하는 것을 볼 수 있습니다. 이것을 통해 모델이 학습이 되는데 저 stop progress는 제가 코드레벨에서 보지는 않았지만 논문에서 밝히기로는 0~1사이의 range를 지닌 진척도라고 했던 것 같습니다. 즉 goal 위치에 다가갈 수록 모델이 예측하는 progress가 1에 가까운 값을 지니지 않을까라느 생각이 듭니다.
두번쨰 질문에 관해서는 제가 manipulation용 DP를 잘 몰라서 기존 연구들과의 차별점?등을 비교하며 설명드리기 어렵네요 허허. 근데 저자들이 논문에서 밝히길 manipulation에서 DP가 좋은 모습을 보여주었기에 그 framework을 참고해서 RDP라는 베이스라인을 만들었다고하니 아마 영규님이 생각하는 기존 manipulation DP와 비슷한 포인트를 가지지 않을까 추측합니다.
안녕하세요 리뷰 감사합니다
VLN 분야의 벤치마크가 익숙하지 않아 질문 드립니다. VLN-CE와 VLN-PE의 차이가 궁금합니다. 혹시 로봇의 역할(원통형->4종로봇)이 궁금한데, 다양한 뷰에서 촬영된 영상을 제공하는것일까요? 또한 네비게이션 데이터셋의 label 형식이 궁금한데, 단순히 시작지점과 목표지점을 주어주고, 지표에 따라 평가하나요? 그렇다면, 목표 지점까지 도달하는데 걸리는 기간/길이의 경우 무한할 수 있을것같은데, 특정 역치로 멈추게 되는지 궁금합니다.
감사합니다.
안녕하세요. VLN-CE가 이전 VLN 연구 분야에서 많이 활용한 벤치마크 방식으로 가상의 원통형 로봇이 agent로 움직인다는 가정하에 VLN 모델의 output 값을 통해 navigation을 평가하는 것을 의미하는 것으로 알고 있습니다. 그러다보니 2족, 4족 등등 다양한 형태의 물리적 agent에 대하여 기존 알고리즘들이 얼만큼 잘 동작하는지에 대해 기존의 VLN-CE 벤치마크 방식으로는 평가가 어렵다는 것을 저자들은 문제로 지적하고 있습니다. 그래서 저자들이 제안하는 VLN-PE라는 벤치마크는 이러한 agent의 다양성 뿐만 아니라 시각적 다양성과 현실성을 개선하고, 넘어지거나 부딪히는 상황까지 모두 고려하고 있습니다.
두번째 질문에 대하여 VLN은 제가 알기로 시작과 끝으로 이어진 sequence들이 구성되어 있으며 각 sequence에 대하여 다음 sequence로 이동하기 위한 action값이 있는 것으로 알고 있습니다. 평가 방식으로는 하나의 sequence에 대한 RGB (+ Depth) 영상들과 text로 구성된 instruction을 토대로 모델이 최종 goal까지 도달하게 되면 해당 지점에서의 거리와 실제 target의 거리를 비교하는 방식 등으로 평가할 수도 있고 그 외에도 다양한 평가지표가 리뷰에 보시면 나와있습니다.