안녕하세요. 오늘의 X-Review는 Audio Visual Question Answering 방법론 논문입니다. 25년 10월 아카이브에 공개되었으며, 현재 실험중인 상황에서 최근 제안된 AVQA 방법론들을 읽는 중인데 정리 목적으로 글을 작성하게 되었습니다.
그럼 바로 리뷰 시작하겠습니다.
1. Introduction
AVQA(Audio-Visual Question Answering)는 비디오 내 시각, 오디오 정보를 동시에 이해해야 하는 복합적 멀티모달 추론 과제입니다. 단순히 영상 속 객체나 오디오 이벤트를 인식하는 것을 넘어, 두 모달리티가 시점별로 어떻게 상호작용하는지 해석하고 질문의 의도에 따라 관련 단서를 찾아내야 합니다. 최근에도 TSPM이나 QA-TIGER를 비롯한 모델들이 다양하게 등장하고 있는데, 이들이 계속해서 주목해왔던 핵심 질문 두가지는 아래와 같습니다.
- 모델은 질문과 가장 관련있는 오디오/비디오 구간을 어떻게 추려낼 것인가?
- 이렇게 추려낸 구간으로부터 중요 정보를 어떻게 추출할 것인가?
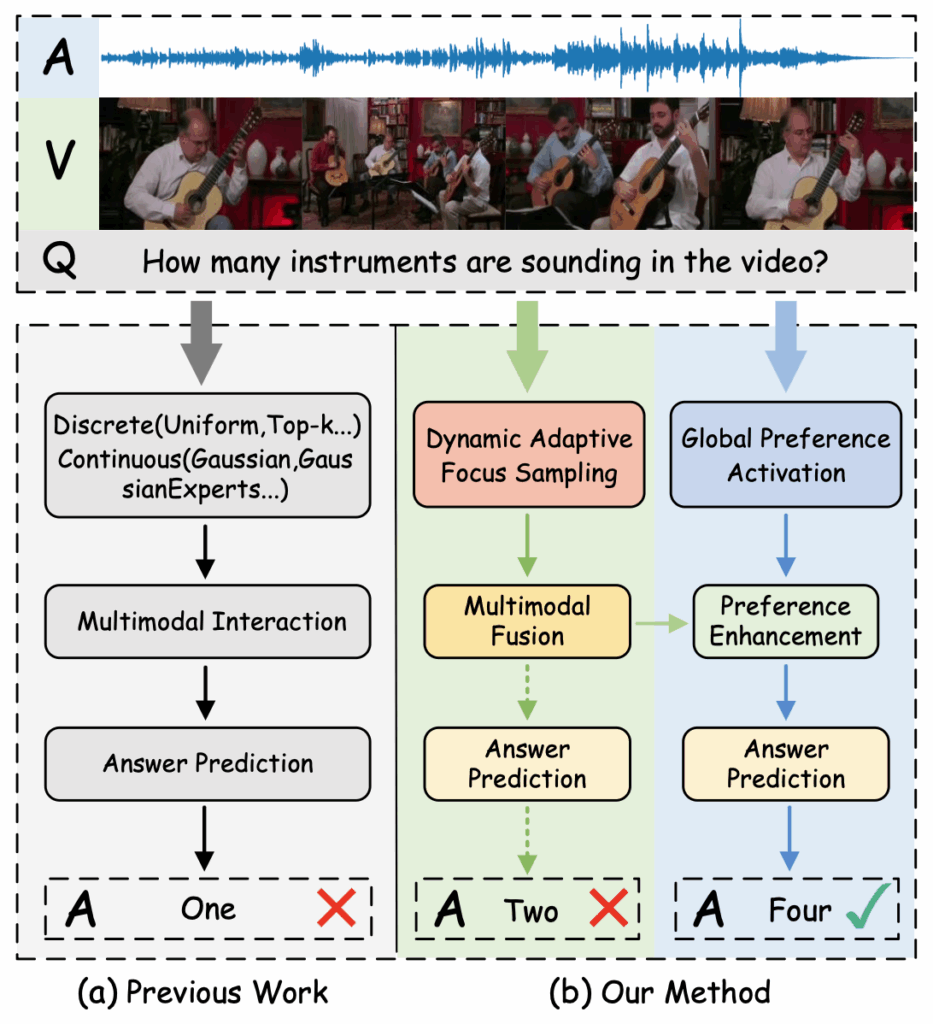
두 가지 핵심 질문에 답변하기 위해 저자는 그림 1을 보여줍니다. 먼저 첫 번째 질문과 관련해 그림 1 왼쪽 회색 부분을 보면, 기존 방법론들은 discrete, continuous한 방식으로 오디오/비디오에서 주요 구간을 추립니다. 예를 들어 TSPM은 질문과 유사도가 가장 높은 segment를 이산적으로 뽑고, QA-TIGER는 Gaussian expert를 통해 모든 segment에 가중을 주어 연속적인 aggregation을 수행합니다.
전자의 이산적인 Top-K 샘플링 방식은 aggregate된 프레임이 말 그대로 discrete하다는 것이 문제입니다. 오디오와 비디오가 가지고있는 자연스러운 시간적 흐름이 뚝뚝 끊긴다는 주장이죠. Fine-grained understanding에 이러한 방식을 적용하는 경우 hallucination이 발생할 수 있게 됩니다.
다음으로 QA-TIGER의 Gaussian expert 기반 연속적 샘플링 방식은 물론 전자의 방식보다는 시간적 끊김을 많이 완화했지만, 조금씩이라도 비디오의 프레임을 모두 사용한다는 점에서 큰 redundancy가 존재하는 것이 단점입니다. 이 방식이 성능 향상을 저해한다고 이야기하는데, 사실 hallucination이 발생한다거나 성능 향상을 저해한다고 이야기만 하고있어 문제 정의가 추상적이라는 느낌이 드네요. 그래도 마지막에 SOTA 성능으로 저자의 방식이 가장 좋음을 보여준다면 어느정도는 납득이 되겠죠.
두 번째 질문에 대해, 기존 AVQA 방법론들은 거의 대부분 오디오/비디오 정보를 단순히 fusion의 대상인 보조 정보로 여긴다고 지적합니다. 오디오와 비디오는 엄연히 다른 모달리티이기 때문에, 질문을 포함해 서로 fusion될 때 단순히 서로 Cross attention을 태우거나 concat하기만 해선 부족하다는 의견입니다. 질문에 따라 어떤 모달리티에 집중해야할지 모델이 판단할 수 있어야 한다는 이야기입니다.
이러한 두 한계를 해결하기 위해 저자는 AV-Master라는 새로운 dual-path 프레임워크를 제안합니다. 핵심은 질문과 가장 관련 있는 미세한 오디오·비디오 단서를 찾아내는 것과, 동시에 질문이 어떤 모달리티를 더 선호하는지 전역적 관점에서 파악하는 것을 하나의 모델 안에서 모두 처리하는 데 있습니다.
먼저 첫 번째 측면에서 주요 구간을 잘 찾는 방식을 제안합니다. 기존 방식이 discrete 또는 continuous라는 양 극단의 방법을 선택했다면, 저자는 이를 절충한 dynamic adaptive focus sampling을 제안합니다. 쉽게 말하면, 매 시점의 오디오/비디오 segment를 모두 그대로 쓰지도 않고, 반대로 몇 개의 segment만 덜컥 선택하는 것도 아닌 방식입니다. 0초부터 시간 축을 쭉 따라가면서 질문과의 연관성이 높은 순간들을 점진적으로 추려가며, segment 간 자연스러운 temporal 흐름은 유지하되 redundant한 정보는 과감히 제거하는 구조입니다. 저자는 이 방식이 discrete sampling의 단절성과 continuous sampling의 과도한 중복을 동시에 보완한다고 주장하고 있습니다.
두 번째 측면은 모달리티 선호도, 즉 어떤 질문에서 오디오가 핵심인지, 비디오가 핵심인지 모델이 스스로 판단할 수 있어야 한다는 문제입니다. 질문에 따라 두 모달리티 중 필요한 정보가 달라질 수 있습니다. 예를 들어 “어떤 악기가 먼저 소리를 내는가?”는 거의 전적으로 오디오 기반 질문이고, “어디에 위치한 악기가 연주 중인가?”는 시각 정보가 더 중요합니다. 저자는 기존의 단순 fusion 방식만으로는 이러한 차이를 충분히 반영할 수 없다는 점을 강조하며, global preference activation이라는 별도의 path를 설계합니다. 이 path에서는 오디오와 비디오를 각각 독립적으로 바라보고, 질문과의 상관성을 기반으로 현재 질문에서 이 모달리티가 얼마나 중요한가를 전역적 관점에서 모델에게 알려주는 역할을 합니다.
결국 AV-Master는 두 경로가 상호 보완적으로 작동합니다. 하나는 시간축에서 fine-grained 단서를 정교하게 찾아내고(Temporal Dynamic Perception Path), 다른 하나는 모달리티 관점에서 어떤 정보가 더 핵심인지 판단(Global Preference Activation Path)합니다. 두 경로에서 얻은 표현은 후반부에서 통합되어 최종 답변을 생성하게 되며, 저자는 이 dual-path 구조가 기존 AVQA 모델들이 갖고 있던 추론의 모호함을 명확히 해소한다고 주장합니다.
각 모듈의 자세한 내용은 방법론 파트에서 더욱 자세히 알아보겠습니다.
2. Methodology
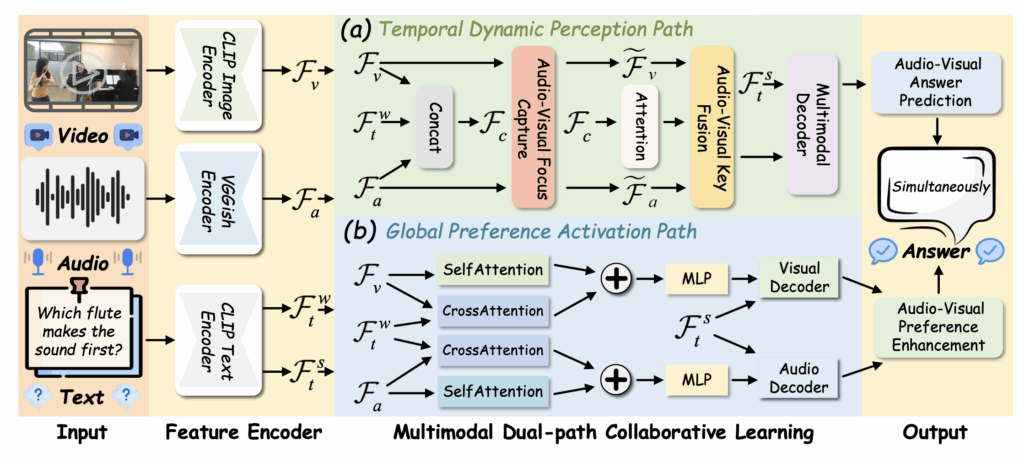
위 그림 2가 저자가 제안하는 AV-Master의 전체 프레임워크입니다. 노란색으로 표시 된 부분은 Feature extraction 및 Answer prediction으로 공통적인 과정이고, 초록색과 파란색으로 표시된 Temporal Dynamic Perception Path, Global Preference Activation Path가 저자가 제안하는 두 path입니다.
2.1 Input Representation
(a) Visual representation
비디오는 1초 단위의 겹치지 않는 segment T개로 먼저 분할됩니다. 이 segment는 CLIP에 vision encoder에 입력되어 비디오 feature \mathcal{F}_{v} = \{\mathcal{F}_{v}^{1}, \cdots{}, \mathcal{F}_{v}^{T}\} \in{} \mathbb{R}^{T \times{} D}로 추출됩니다.
여기서 특이한 점이, 기존의 모든 AVQA 방법론들은 CLIP에서 뽑히는 patch feature를 함께 썼지만 AV-Master는 이를 전혀 쓰지 않는다는 점입니다. 요즘 연구실 세미나에서도 많이 언급되고 있듯 patch feature는 그 개수가 굉장히 많고 심지어 AVQA는 비디오를 다루기 때문에 패치 토큰 개수가 시간 축만큼 곱해지게 되는데, 이 정보를 활용하지 않고 성능을 올렸다는 점이 놀랍습니다.
(b) Audio representation
오디오는 비디오에 함께 붙어있는 모달리티이기 때문에, 동일한 1초 짜리 segment T개의 음성은 VGGish 백본을 통해 오디오 feature \mathcal{F}_{a} = \{\mathcal{F}_{a}^{1}, \cdots{}, \mathcal{F}_{a}^{T}\} \in{} \mathbb{R}^{T \times{} D}로 추출됩니다.
(c) Question representation
입력 문장은 CLIP text encoder에 입력되어 단어 수준의 feature \mathcal{F}_{t}^{w} = \{\mathcal{F}_{t}^{1}, \cdots{}, \mathcal{F}_{t}^{L}\} \in{} \mathbb{R}^{L \times{} D}와 문장 수준의 feature \mathcal{F}_{t}^{s} \in{} \mathbb{R}^{1 \times{} D}를 얻게됩니다.
2.2 Temporal Dynamic Perception Path
AV-Master를 구성하는 두 개의 핵심 path 중 첫번째입니다. 앞서 언급했듯 너무 discrete하거나 continuous하지 않은 방식으로 오디오/비디오 핵심 정보를 가져오는 것이 본 path의 목적입니다. 이 path는 다시 두 개의 모듈로 나뉩니다. 첫 번째는 dynamic adaptive focus sampling 모듈, 두 번째는 audio-visual key fusion 모듈이고, 각 모듈의 목적은 모달리티 특징으로부터 주요 정보 추출, 추출한 각 모달리티의 정보 통합입니다.
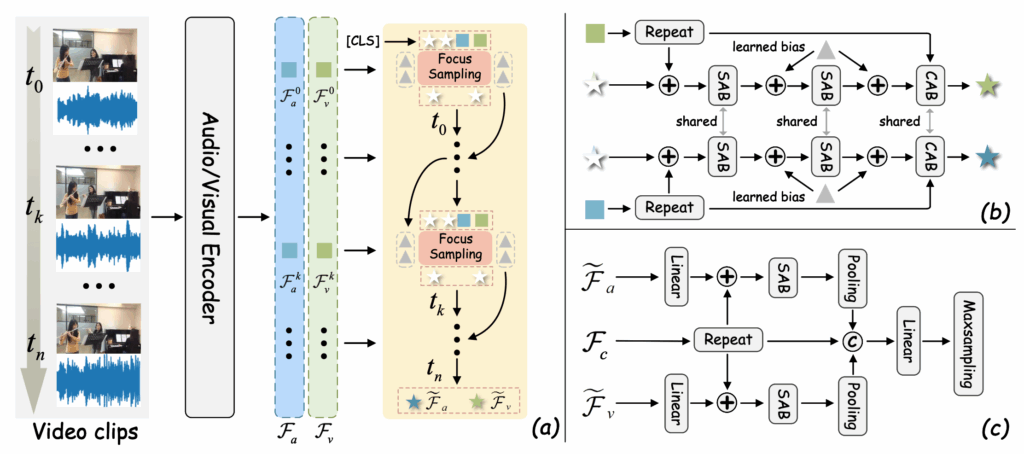
위 그림 3이 Temporal Dynamic Perception Path를 보여주고 있습니다. 여기서 (a), (b), (c) 이렇게 3개로 그림이 나눠져있지만, 사실 그림 3 상에서 (a)는 dynamic adaptive focus sampling 모듈의 큰 그림, (b)는 이 모듈의 동작 방식, (c)는 audio-visual key fusion 모듈의 동작 방식입니다. 사실상 그림 (a)와 (b)는 동일 과정이라고 보시면 됩니다. 아래에서 한 가지씩 설명드리겠습니다.
(a) Audio-visual focus capture
여기선 질문과 관련된 오디오/비디오의 핵심 구간을 찾아내는 방법을 소개하는 부분입니다. 기존 모델들이 discrete 혹은 continuous sampling을 사용해 segment를 고정적으로 선택했던 것과 달리, AV-Master는 질문 조건에 따라 중요한 순간을 점진적으로 정제해가는 구조를 제안합니다.
입력 비디오와 오디오에서 추출된 feature (각 T개 segment)에 대해 먼저 self-attention과 cross-attention을 반복적으로 적용하여 중요한 토큰의 정보만 계속 뽑아가는 방식으로 focus를 강화합니다. 이 과정은 단순히 각 시점의 특징을 independent하게 보는 것이 아니라, 질문이 요구하는 temporal dependency를 기준으로 어떤 순간이 중요해지는지를 동적으로 반영합니다.
이를 위해 오디오/비디오 feature를 0초부터 T-1초까지 훑으며 정보를 취합합니다. 먼저 learnable query에 해당하는 각 모달의 predefined template \mathcal{A}_{cls}, \mathcal{V}_{cls}(그림 3에서 별 표시)를 선언합니다. 이 template은 여러 개(실제로는 모달별 각 8개)의 learnable vector들이라 생각하시면 됩니다.
그리고 각 시간 축에서 다양한 변화들을 강조하기 위해 learnable biases(그림 3에서 세모 표시)를 함께 사용합니다. 그림 3-(a)에 이 과정이 나타나있습니다. 그럼 이 특징과 변수들이 어떻게 상호작용하며 중요 정보를 추출하는지 아래에서 이어 설명드리겠습니다.
(b) Dynamic adaptive focus sampling
그림 3-(b)는 k라는 특정 timestep에서 중요 정보를 추출하는 과정을 보여줍니다. 먼저 입력은 각 모달리티의 feature와 template인 \mathcal{F}_{v}^{k}, \mathcal{F}_{a}^{k}, \mathcal{A}_{cls}^{k-1}, \mathcal{V}_{cls}^{k-1}입니다. 이전 step까지의 template과 현 시점의 특징이 들어오는 것이죠.
오디오와 비디오 두 모달리티에 대해서 동일한 과정을 거치기에 수식은 비디오를 기준으로 작성되어있습니다. 아래 수식 (1)과 같이 본 모듈을 마쳤을 때의 visual feature는 \tilde{\mathcal{F}}_{v}라 표기하고 이는 전체 T번의 FocusSampling 과정을 마친 뒤 만들어집니다.
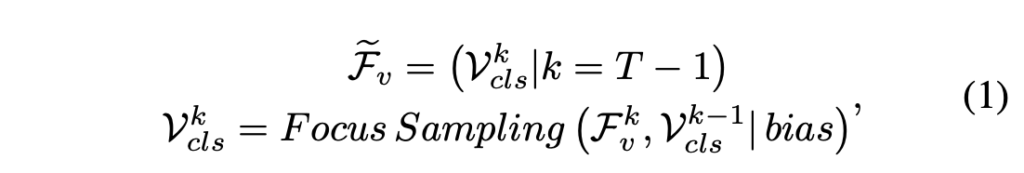
FocusSampling 과정은 그림 3-(b) 또는 아래 수식 (2)와 같습니다.
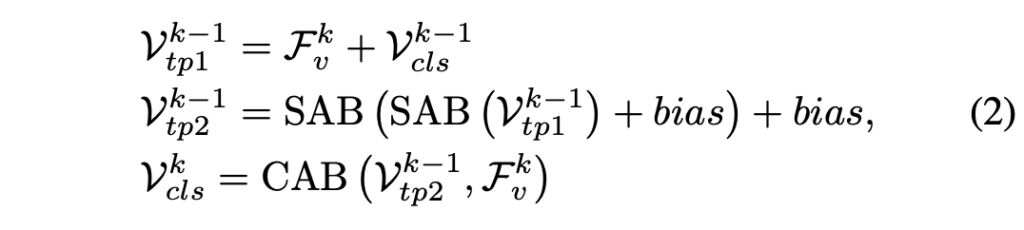
이 과정은 모달리티 feature와 이전 step template의 합으로 시작해 여러 번의 self-attention, cross-attention을 거쳐 완성됩니다.
(c) Audio-visual key fusion
(b)에서 설명한 과정을 비디오와 오디오에 대해 모두 거치면 주요 정보가 담긴 feature \tilde{\mathcal{F}}_{v}, \tilde{\mathcal{F}}_{a}를 얻을 수 있습니다. 앞 과정까진 오디오와 비디오 내부적으로 중요한 부분을 선택했다면 본 과정에서는 질문 특징을 활용해 각 모달리티의 중요 부분을 취합하고 합치게 됩니다. 이 과정은 아래 수식 (3)과 같습니다.

수식에서의 Pooling은 T축으로 summation에 해당합니다. 전반적으로 concat, self-attention, fc layer의 연속으로 구성되어 있습니다. 또한 최종적으로 합쳐진 \mathcal{F}_{fu}를 얻을 때 채널 축으로 max pooling을 취하는 점도 특이한데 이를 비롯해 모든 구조 설계에 대한 별다른 저자의 고찰은 없어 우선 구성 형태만 살펴보고 넘어가겠습니다.
2.3 Global Preference Activation Path
여긴 2.2절의 path와 독립적으로 진행되는 또 다른 path입니다. 목적은 현재 질문에 대해서는 둘 중 어떤 모달리티에 좀 더 힘을 주면 좋을지 결정하는 것입니다. Path 이름대로, 오디오와 비디오를 분리한채 질문이 각 모달리티의 전역적 문맥을 바탕으로 fine-grained feature를 만들어내게 됩니다. 아마 앞선 path가 모든 시간 축에 대해 feature를 살펴보았다보니 이 path는 global이라 표현한 것 같습니다.
과정은 아래 수식 (4)와 같고, 사실 목적과 역할을 저자가 굉장히 거창하게 써두었을뿐 또 self-attention, cross-attention을 통해 질문 정보를 담은 오디오/비디오 preference feature \mathcal{F}_{v}^{p}, \mathcal{F}_{a}^{p}를 만드는 것이 전부입니다. 지금 아래 수식에서 cross-attention에 \mathcal{F}_{v}^{p} + \mathcal{F}_{t}^{w}가 입력된다 되어있는데 잘못 작성되어있는 것 같고, \mathcal{F}_{v}^{p}를 쿼리, \mathcal{F}_{t}^{w}를 키와 밸류로 넣는 것 같습니다.
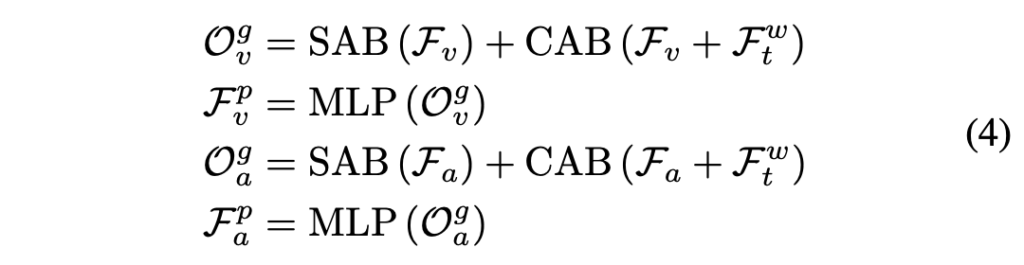
2.4 Optimization and Answer Prediction
이제 앞서 뽑은 feature들을 활용해 모델이 어떻게 학습하는지, 또 최종 답변 클래스를 어떻게 예측하는지만 남아있습니다. 학습에는 주어진 GT 기반으로 분류하는 Dual-path prediction loss와 서로 다른 path에서 나온 feature들 결국 하나의 임베딩 공간으로 떨어뜨려주는 Dual-path contrastive loss를 사용합니다. 추론 시에는 두 path에서 나오는 예측 확률을 모두 평균내어 나온 argmax를 최종 예측으로 사용합니다.
(a) Dual-path prediction loss
학습 중 모델의 두 path를 거치며, 수식 (3)으로부터는 \mathcal{F}_{fu}, 수식 4로부터는 \mathcal{F}_{a}^{p}, \mathcal{F}_{v}^{p}를 얻을 수 있었습니다. 그림 2에서는 이 feature들이 각각 multimodal decoder, visual decoder, audio decoder를 거치는 것으로 나와있는데, 논문에서 이 decoder는 transformer block + linear layer라는 정도의 설명만 언급되어있습니다. 이 feature들에는 이미 질문 feature 정보가 주입되어있기 때문에, 바로 GT를 활용해 아래 수식 (5)와 같이 Cross Entropy Loss를 적용해줍니다.
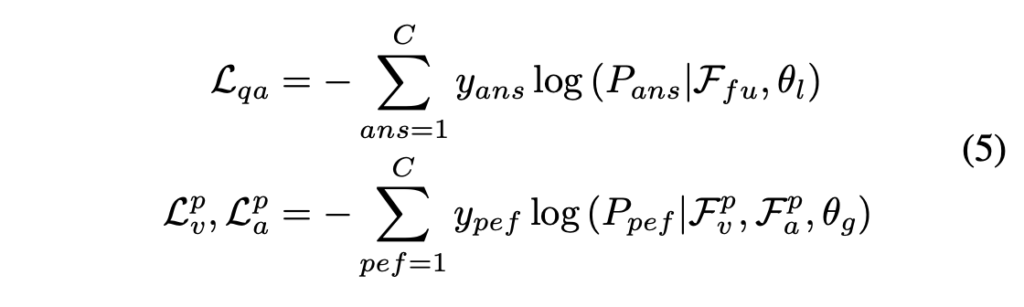
(b) Dual-path contrastive loss
저자가 제안하는 두 path는 완전히 독립되어있기 때문에 좀 더 안정적인 학습 및 추론을 위해서는 이 출력 feature들의 임베딩 공간을 조정해줄 필요가 있습니다. 이 과정은 아래 수식 (6)과 같습니다.
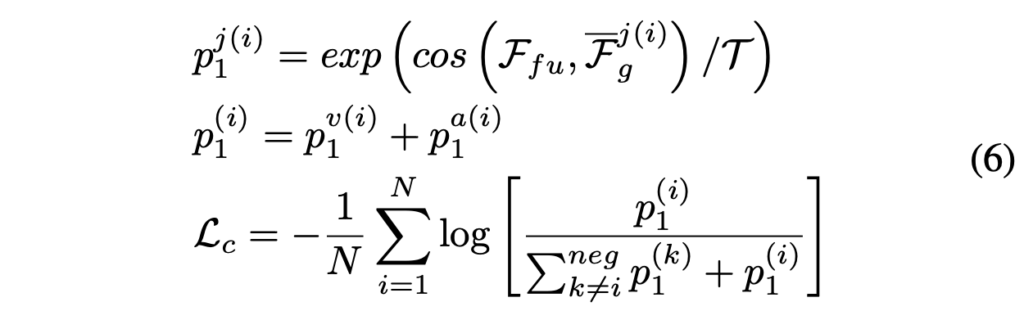
수식 (6)은 한 배치 내 InfoNCE라고 생각해주시면 되고, j \in{} \{v, a\}로 오디오 또는 비디오 모달리티를 의미합니다. \bar{\mathcal{F}}_{g}^{j(i)}는 현재 \mathcal{F}_{fu}와 배치 내에서 같은(positive) 샘플이면서, 각 모달리티의 preference feature를 temporal 축으로 평균낸 값을 의미합니다. Notation이 굉장히 복잡하지만 결국 두 path에서 얻은 총 3개의 feature(fusion, audio, visual)를 미니 배치 내에서 contrastive learning 하는 것이라 볼 수 있습니다.
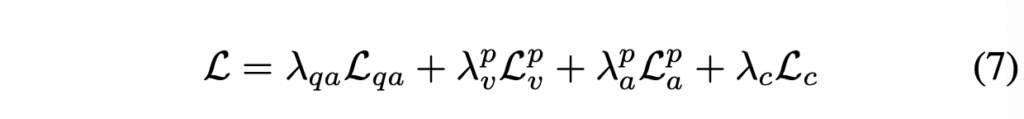
최종 학습 loss는 위 수식 (7)과 같습니다.
3. Experiments
3.1 Quantitative Results
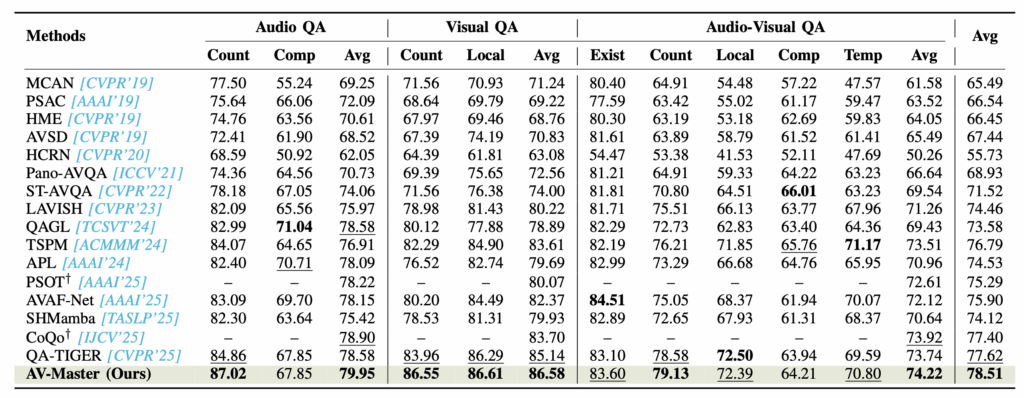
표 1은 MUSIC-AVQA 데이터셋에서의 벤치마크 성능입니다. 표에서 \dagger{} 표시는 원래 다른 audio encoder를 썼으나 AV-Master 및 타 방법론들과 동일한 audio encoder를 썼을 때의 성능임을 의미합니다. 기존 SOTA 방법론인 QA-TIGER보다 더욱 높은 평균 성능을 달성하였고, 특히 각 모달리티의 counting 질문에서 성능이 많이 오른 모습을 볼 수 있습니다.
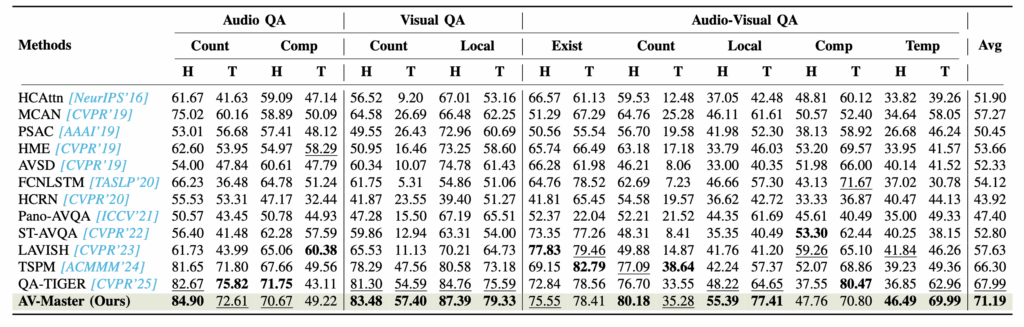
위 표 2는 MUSIC-AVQA-R 데이터셋에 대한 성능입니다. R 데이터셋은 원본 MUSIC-AVQA 데이터셋의 테스트 스플릿 중 질문을 다양하게 rephrase해둔 데이터셋입니다. 모델이 텍스트 질문에 대한 일반성을 얼마나 갖는지 파악해볼 수 있습니다. 여기에서도 큰 차이로 SOTA를 달성하며 방법론이 우수함을 보여주고 있습니다.
3.2 Ablation Studies
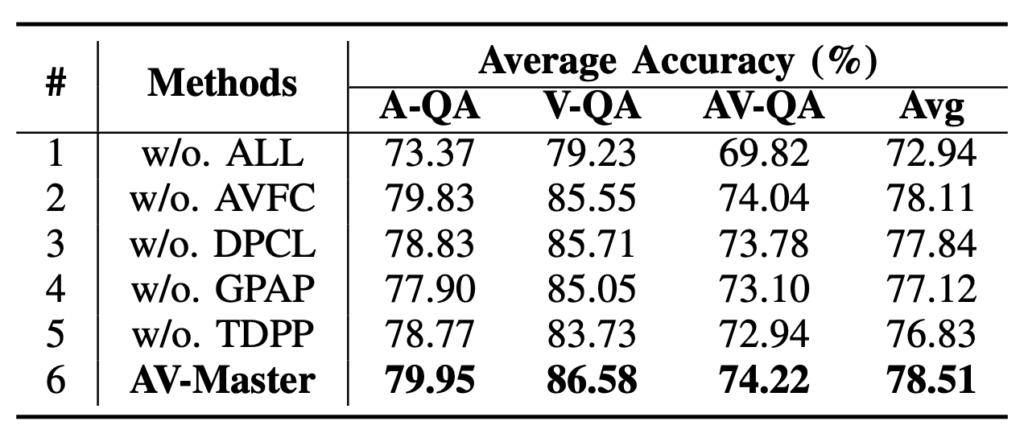
표 3은 모듈별 ablation 성능입니다. 표에서 TDPP는 Temporal Dynamic Perception Path, GPAP는 Global Preference Activation Path, DPCL은 Dual-path Contrastive Loss, AVFC는 Audio Visual Focus Capture입니다. 두 path 중에는 TDPP의 기여가 좀 더 높은데, learnable vector를 두어 한 timestep씩 local하게 정보를 살펴보는게 도움이 많이 된다는 점을 알 수 있었습니다.
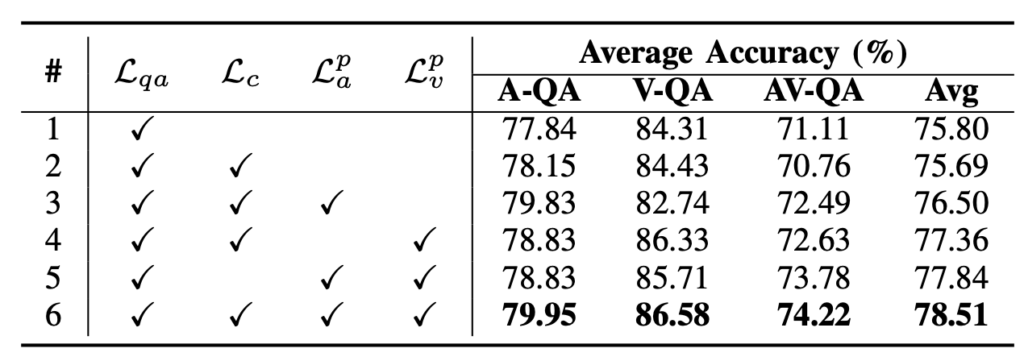
위 표 4는 loss에 대한 ablation 실험 성능입니다. 신기한게 표 3에서는 TDPP의 성능 향상 폭이 더 컸는데, loss 단에서는 GPAP에 붙는 loss들이 더욱 성능을 많이 올려주는 것을 볼 수 있습니다.
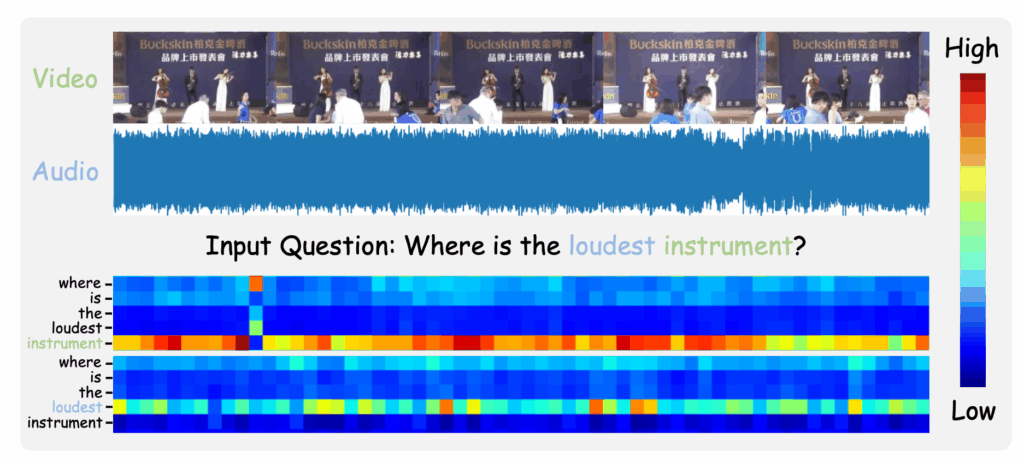
마지막은 오디오와 비디오에 대한 각 단어별 attention score 그림이고, 각 모달리티에 강조되는 instrument, loudest 단어가 가장 잘 activation 되는 것을 볼 수 있습니다.
실험 결과는 많은데 별다른 분석이 없어서, 이정도로만 알아보겠습니다.
아직 게재되지는 않은 논문이라 그런지 전반적으로 읽기에 조금 어려움이 있었습니다. 모듈 이름과 동작에 대해 불필요하게 중복적으로 비슷한 이름을 붙인다거나, 중복되는 notation이 있어 이해에 일부 어려움이 있었습니다. 실험은 추후에 정식 버전으로 게재되면 다시 한 번 살펴보는 것으로 하고, 이상으로 리뷰 마치겠습니다.
안녕하세요 현우님!
리뷰 감사합니다~!!
간단한 질문이 있습니다! Introduction 초반부에 오디오,비디오 모달리티를 단순히 크로스 어텐션을 태우거나 콘캣하는게 아니라 질문에 따라 집중 할 모달리티가 달라야 한다는 부분이 있는데,
그럼 질문이 오디오 기반 질문인지/비디오 기반 질문인지를 어떻게 구분하는건지, 이 부분이 명시적으로 판별해주는 모듈이 따로 있는게 아니라면 어텐션이 질문과 모달리티 간의 상관관계를 학습해서 암묵적으로 질문을 판단(구분) 하는건지 궁금합니다!
안녕하세요. 현우님 좋은 리뷰 감사합니다.
방법론 중 Global Preference Activation Path에서 질의에 따라 중요한 모달리티를 학습한다고 설명하셨는데, 본 방법에서는 명시적인 modality weight가 존재하지 않아 실제로 질문에 따라 오디오/비디오의 중요도를 동적으로 조절하는지, 혹은 단순히 모달리티별 특징을 추가로 인코딩하는 효과인지 구분이 어려운 것 같습니다. 혹시 오디오 중심/비디오 중심 질문별로 path 기여도 변화에 대한 정량적 분석의 결과가 있을까요?
감사합니다.