안녕하세요. 이번 리뷰는 Long-horizon human demo video를 인풋으로 받아, VLM 기반으로 sub-task decomposition을 수행하고, 이를 LMP(Language Model Program) code generation 방식과 연결지어 low-level primitive action까지 연결짓는 방법론입니다. 사실 이렇게만 들으면 sub-task decomposition 분야에서 흔히들 언급되는 CaP(Code as Policies), VoxPoser, MOKA 등과 뭐가 그렇게 다르지 싶습니다.
일단 다른 점은 Long-horizon human demo video 인풋을 처리했다는 게 다른데, 이 제약이 많아보이는 video 인풋을 어떻게 샘플링해서 VLM 인풋으로써 요리조리 잘 처리했길래 까다로운 long-horizon sub-task decomposition 을 처리할 수 있었던 걸까의 관점이 우선 첫번째 주안점인 것 같구요. 다음은 그들의 LMP라는 방법론은 거의 손대지 않고 그대로 가져가면서 VLM의 spatial understanding 능력을 극대화시키기위한 visual prompting 방법론 어필이 두번째 포인트가 된 것 같습니다.
요즘 저도 long-horizon task를 풀고 싶어서 저번에 제가 세미나에서도 브레인스토밍으로 시나리오 의견을 도움받고 있는데요. 마지막 포인트로는 본 논문이 들고 온 문제정의와 해결방안을 잘 어필하는 experiment task 시나리오 세팅이 단순하면서도 합리적인 편이라고 생각이 들었습니다. 아래에서 스윽 살펴보겠습니다.
1. Introduction
VLM은 요즘 로봇이 환경, 문맥을 이해하는 데 강력한 기반이 되고 있습니다. 풍부한 의미 추론, 상식 추론 능력 덕분에, 로보틱스 분야에선 기본적으로 3가지 경향성으로 연구에 접목되고 있습니다. 첫번째는, CaP(Code as Policies)나 SayCan처럼 자연어 명령을 이해하고 sub-task decomposition을 수행하여 planning하는 컨셉이 있습니다. 두번째는 여타 pi_zero 같은 요즘의 VLA 방법론들에서 VLM 백본을 두어 파인튜닝하는 방식이 있습니다. 마지막은 씬 내나 공간 내에서 주목해야 할 객체나 특정 키 포인트를 이해하고 여러 후보군들 중 셀렉하고 찾아주는 방식의 VoxPoser, ReKep같은 방법론들이 있겠습니다.
하지만 이런 경향성 모두 뜯어놓고 보면 모두 인풋 타입이 language가 기본 전제로 들어가 있습니다. 그도 그럴 것이 사람이 무언가 명령을 내린다는 전제는 항상 language기반의 instruction 자체가 기저로 깔린 셈이죠. 근데 언어란 건 사실 의도로 한 모든 행동을 정확하게 기술하기 어려운 형태라고도 볼 수 있습니다. 특히 되~게 복잡한 long-horizon task를 말로만 열심히 표현하기엔 설명의 형태도 굉장히 길어질테고, 이를 단계별로 지시를 쪼개서 표현하자니 되게 비효율적일 것이죠. 반대로 video 영상은 생각보다 함축적으로 이런 표현을 담을 수 있긴 합니다. 예를 들어 사람도 어떤 복잡하게 생긴 DIY물건을 조립한다고 쳤을 때, 이걸 글로만 적힌 설명서를 열심히 들여다보면서 조립하는 것보단, 유튜브에 올라온 조립 동영상을 스윽 보고 따라하는 게 더 이해가 잘되죠. 같은 컨셉이라고 보면 될 것 같습니다. video라는 모달리티는 시공간,상호작용 등이 language보단 더 직관적으로 표현되어 있고, temporal한 이해 측면에서도 long-horizon task에 제격인 모달리티라고 할 수 있습니다. 더군다나 이런 human video는 인터넷 스케일로도 널려있죠. 괜히 CoRL2025에서 human video-based VLA training 방법론들이 우후죽순 나왔던 게 아닐겁니다. VLA training으로도 확장가능성이 좋습니다.
그렇다면 human video-based의 VLA training 하면 된다는 거 아니냐? 싶은데, 저자들은 여기서 자기들 연구방향으로 한번 꺾어주기 위해서 다음의 말을 하면서 슉 빠져나갑니다. IL 시에 human demo video → robot action 을 할 때는 human-robot embodiment gap이 있지 않냐? 이거 직접 모방학습이 쉽지 않지 않냐고 끌고 갑니다. 더구나 저자들이 주목하고 있는 건 지금 Long-horizon task에 대한 human demo video이기에 이거 그럼 IL 학습할 때 데모 취득하는 것도 정말 많은 cost가 요구되는 거 아닌가로 문제가 집중되죠.
그래서 저자들은 사람이 long-horizon task 영상보고 자연스럽게 sub-task 추론 해서 단계적으로 동작해나가듯이, VLM 기반으로 로봇도 그렇게 하는 방식으로 접근하게 됩니다. 결국 long-horizon human demo video를 취득해서 IL 학습해나갈 비용보단, 이를 VLM Agent Planning에 인풋으로 활용해서 이해시키는게 더 좋은 이유로 다음 2가지 이유를 듭니다. 1. VLM은 embodiment gap에도 task goal을 다각도로 이해하는 rich commonsense가 있다는 점. 2. 강한 zero-shot generalization 능력으로 인해서 demo video와 real world deploy 간의 차이가 있어도 unseen 환경과 objects 변화에 robust하다는 점입니다. (이 쪽에서 살짝 어필이 아쉬웠던 것 같아서 그렇게 잘 쓴 introduction은 아닌 것 같습니다. 제가 나중에 이 쪽 task 논문을 쓴다면 어떻게 풀어나가야될 지 고민을 해봐야겠네요.)

그래서 저자들은 SeeDo라는 위 figure 1에서 보이는 바와 같은 방법론을 고안합니다. 사람의 long-horizon task demo video input을 보고, VLM이 sub-task 형태의 language plan으로 변환하고, 이 plan을 LMP(Langauge Model Program)과 사전정의된 low-level primitive action으로 동작하는 흐름입니다. 근데 막상 VLM만 써서 인풋으로 video 데이터를 처리하려하니, frame 수가 너무 커서 인풋으로 먹이기엔 processing 에서 token 수 등을 감당하기 어려웠다고 합니다. 그래서 keyframe selection하는 모듈을 추가로 붙이고, visual prompting module도 추가로 붙여서 VLM agent 혼자서 행할 어려움을 하나하나씩 해소하는 방식으로 성능도 올리고, 파이프라인도 구축할 수 있었던 것이 방법론의 핵심입니다.
위 방법론 contribution으로는 살짝 약해보이긴 한데, 다른 contribution으로는 long-horizon human demo video에 대한 benchmark 시나리오를 구성하고, 새로운 eval metric을 제시했다는 점에서 contribution을 가져갔습니다. 또 실험은 다른 VLA 방법론들과 비교를 아예하지 않고, VLM모델들만 변화를 줘가면서 VLM task planning 위주의 거의 self-evaluation이긴 했지만 상대적으로 두드러진 성능을 보여주었습니다.
2. Methods
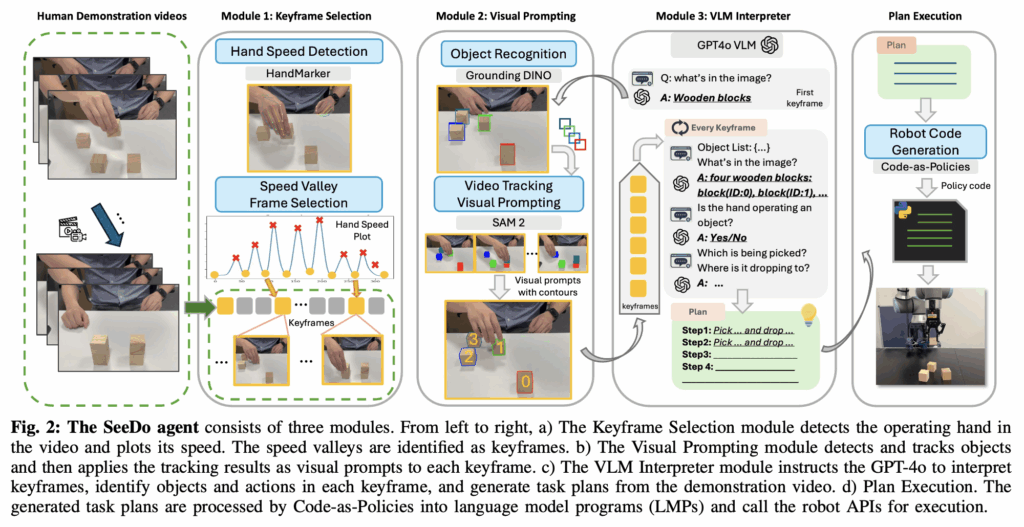
방법론이 매우 간단합니다. 위 Figure 2에 보이는 바와 같이 크게 3모듈인 Keyframe Selection module, Visual Prompting module, VLM Interpreter module으로 나뉘어 집니다.
Keyframe Selection module
여기가 그래도 다른 방법론 대비 핵심 contribution이 될 수 있는 모듈같습니다. VLM에 들어갈 비디오 인풋을 쓴다면 어떻게 샘플링을 해야 효율적으로 인풋을 만들어줄 수 있을까? 전체 영상에서 Keyframe을 어떻게 뽑아낼까? 에 대한 답을 낸 모듈입니다.
우선 VLM이 long-horizon 비디오를 처리할 때 content length가 제약으로 작용한다는 점에서 문제가 시작되는데, LLaVA나 VILA같은 오픈소스 VLM은 보통 프레임을 균등한 간격으로 샘플링해서 입력하는 방식을 사용하지만, 이 균등 샘플링 자체가 Long-horizon 데모 비디오에 대해서는 중요한 동작이 담긴 keyframe을 놓치게 만드는 역할을 해버려서 효과적이지 않음을 꼬집습니다. 그래서 이를 해결하기 위해서 저자들은 비디오 내의 “사람 손의 속도” 변화를 기반으로 한 휴리스틱 방식으로 keyframe selection하는 방식을 취하게 됩니다. HRI 관점이나, Affordance 관점의 선행연구에서도 human-object interaction이 데모 영상 내에서 매우 중요한 역할을 한다고 하며, 보통 손이 물체를 집거나 내려놓을 때 속도가 느려지는 경향이 있기에 이것이 keyframe을 찾는 단서가 될 수 있다고 말합니다.
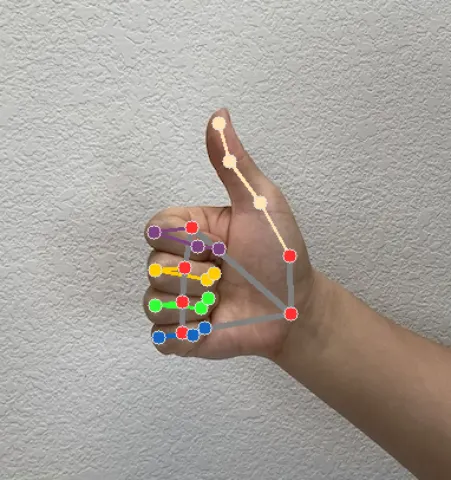

그래서 저자들은 MediaPipe라는 19년도에 나온 가벼운 라이브러리 툴을 활용합니다. 위 사진이 그 예시인데, 이거로 hand skeleton keypoint를 검출하고, 이 keypoint들의 중심이 시간이 흐르면서 이동하는 속도를 EgoPAT3Dv2라는 방법론에서 제시한 방식에 따라 계산해서 그래프 형태로 그려내게 됩니다.
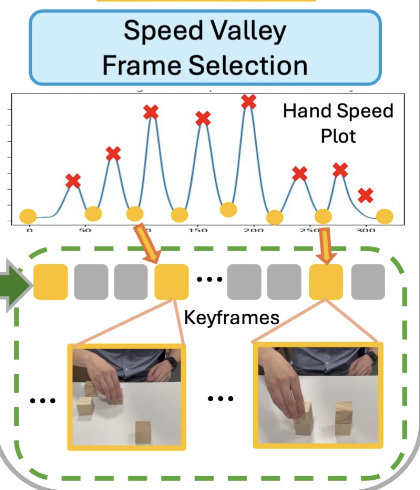
만들어진 속도 곡선을 선형 보간과 스무딩하면 파형 형태의 그래프가 그려지게 되는데, 저자들은 속도가 가장 낮은 골짜기에 해당하는 프레임들을 keyframe으로 선정합니다. 근데 손 검출이란 게 항상 완벽하지가 않고, 보간 자체도 없던 골짜기를 만들어내버리기도 하기에 VLM planner 모듈 중에서 손-물체 상호작용이 없어보이는 프레임은 제거하도록 필터링하는 프롬프트를 추가했다고 합니다.
Visual Prompting module
여기선 우선 VLM의 시각적 한계, 특히 grounding에 대한 문제점이 여러 연구들에서 지적된 바 있음을 언급하고 시작하는데요. 더구나 long-horizon 인간 데모 영상에서는 시간이 지남에 따라 시각적으로 유사한 객체를 일관되게 구분하지 못하는 문제가 자주 발생하게 된다고 합니다. 그래서 MOKA가 SoM(Set-of-Marker) 방식의 visual prompting 방식을 접목했듯, 본 논문도 비슷한 컨셉의 visual prompting 방식을 접목합니다.
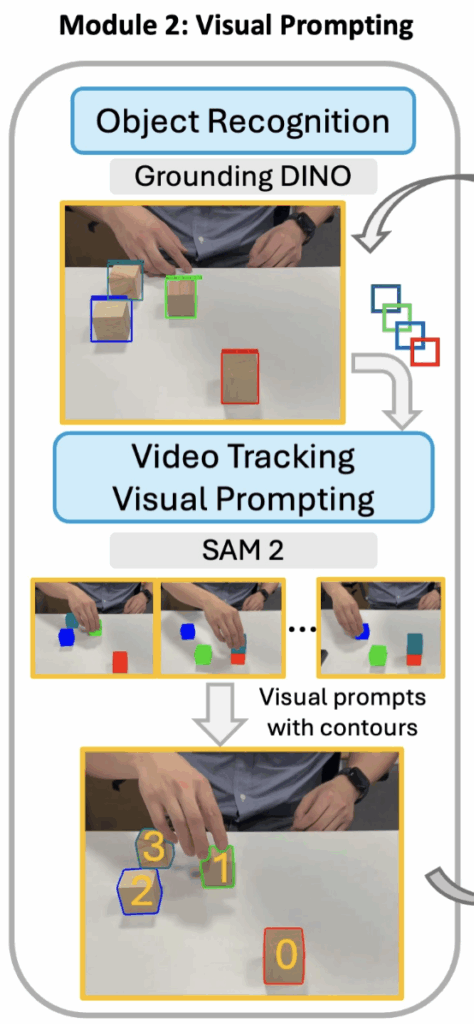
Grounding DINO 1.5를 사용해서 첫번째 입력 프레임에서 객체의 Bbox를 추출하고, 그 bbox를 SAM2에 입력해서 전체 프레임들에 대해 객체 tracking을 진행합니다. 그리고 각 추출된 객체들에 대해 부여된 tracking ID와 mask contour를 이전에 선택됐던 keyframe들 위에 덧그리는 식으로 씌웁니다. 이걸 visual prompting으로써 다음의 VLM interpreter 모듈에 인풋으로 활용하게 됩니다.
VLM Interpreter module
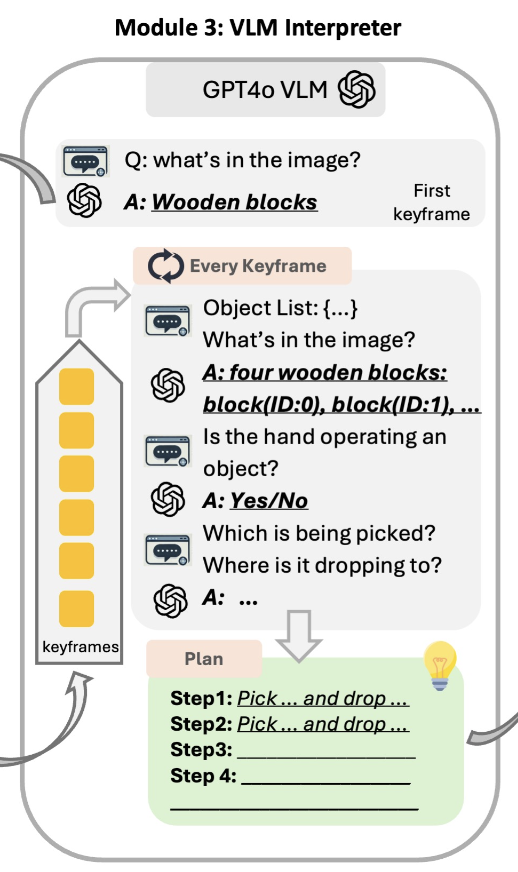
VLM Interpreter 모듈에선 GPT-4o를 활용해서 chain-of-thought(CoT) prompting을 활용해서 task planning을 수행합니다. 앞선 visual prompt와 함께 mask의 중심 좌표와 tracking ID를 텍스트 프롬프트에 함께 제공하여 객체 간 공간 관계를 VLM에게 암시하도록 구성하게 됩니다. 객체 식별이랑 객체 간 공간 관계 이해가 매우 중요하다는 점에서 봤을 때 기존의 MOKA 등에서도 visual prompting의 grounding 효능을 보였었기에, 사실 엄청 새로운 방식은 아니고 비슷하게 따라간 것으로 보입니다. 아래는 prompt예시입니다.

CoT step1에서 scene 내의 object 수와 종류를 특정하게 하고, step2에서 pick 동작을 상호작용할 object를 선정하게 하고, step3에서는 step2에서 뽑힌 object와 상호작용할 reference object를 선정하고, step4에서는 어떤 object에서 어떤 object 쪽으로 drop할지를 선택하는 prompt 예제라고 보면 되겠습니다.
Plan Execution
이는 CaP(Code as Policies)의 LMP(Language Model Program) 세팅을 거의 그냥 그대로 따라갑니다. UR10e 로봇 기반의 Pybullet 시뮬레이터 환경 및 리얼 환경으로 세팅하고, action primitive는 사전에 정의한 pick, place 등의 함수 형태로 정의해놓고 LMP가 호출하는 식입니다. 리얼 환경에서는 관심 객체를 분할하기 위해 기존 CaP 세팅처럼 MDETR로 OVS(Open Vocabulary Segment)를 수행하고, RealSense 캠 센싱기반인지라 동일 픽셀좌표의 depth 이미지를 활용해서 객체 3D 정보를 구해 action 좌표에 활용하는 식으로 접근한다고 합니다.
3. Experiments
Task Design
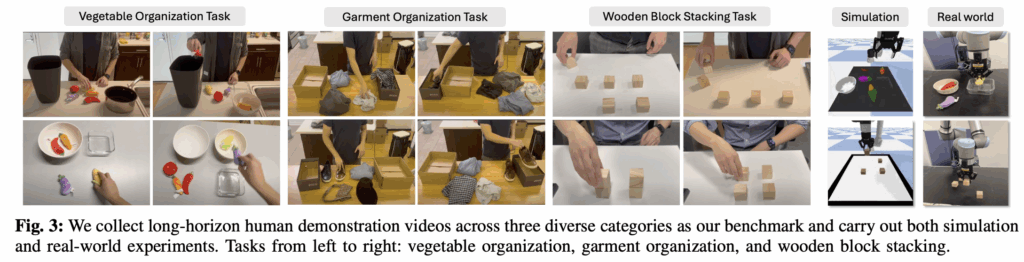
세 가지 카테고리의 long-horizon 데모 태스크를 pybullet 기반 simulator 환경과 real 환경으로 구성해서 실험했다고 합니다. 각 데모 태스크는 여러 단계로 이루어진 복잡한 pick and place sequence로 구성되기에 temporal한 dependency가 굉장히 중요하고, spatial relation이 문제 해결의 핵심 정보로 작용하게 구성했다고 합니다. 태스크들은 다음과 같습니다.
(1) Vegetable Organization Task
채소 6종, 용기 4종으로 구성된 물체들로 채소를 용기에 넣기 태스크. 장난감 채소 사용. 시뮬환경에서는 인터넷에서 긁어온 free .obj 모델과 text-to-3D모델 써서 구성했다고 함. 총 38개 데모 영상.
특징으로는, 시각-공간적 구분 필요. 장기 계획의 순서 의존성 문제를 풀 수 있는가?
(2) Garment Organization Task
셔츠, 신발, 넥타이, 우산 등 다양한 의류 종류 구분해서 박스에 정리 태스크.
채소보다 더 부드러운 deformable 재질. 다양한 형태. 시각 변형성이 더 큼. 총 30개 데모 영상.
유사한 색상 옷이 많아서 grounding 난이도 증가.
(3) Wooden Block Stacking Task
여러 개의 나무 블록을 일정한 구조로 쌓는 태스크. 나무블록들이 시각적으로 매우 유사.
상대적 위치, 상하 관계 등 정밀한 공간 이해가 필요. 총 39개 데모 영상.
가장 높은 난이도. 객체 tracking과 grounding, spatial reasoning이 큰 관건
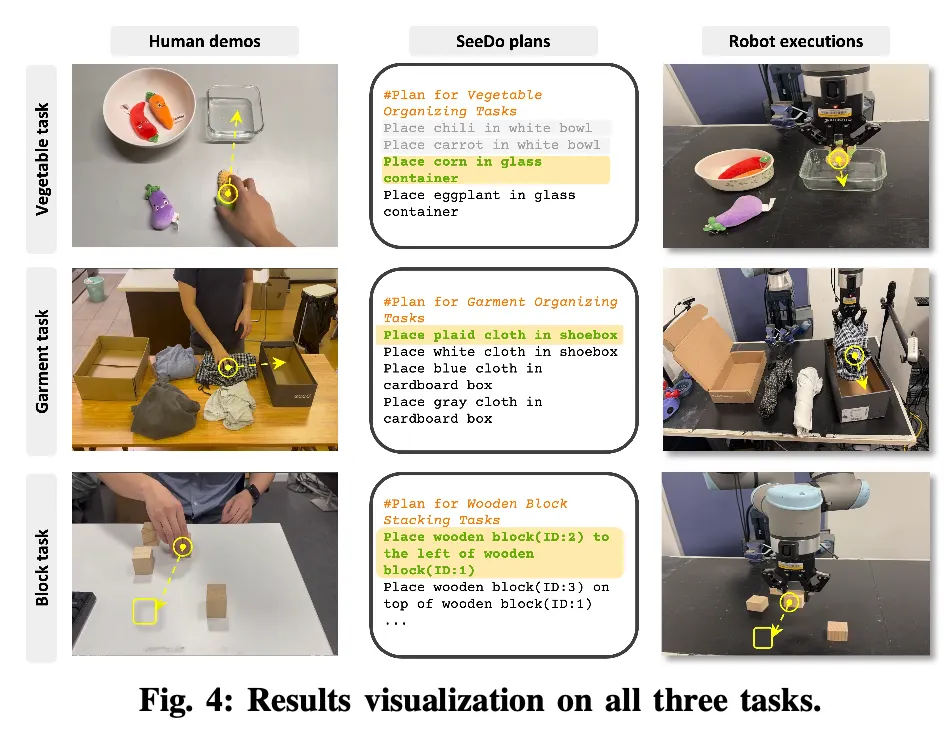
특이한 점은 Figure 4처럼 주어진 task setting 자체가 human video 기반인데, 절대 좌표나 고정된 카메라 뷰포인트에 의존하지 않을 수 있다는 특징이 있습니다. 모든 planning이 객체들 간 상대적 관계(left/right, front/back, above/below 등)으로 기반해서 생성되기에 입력 영상이 1인칭인지 3인칭인지에 관계없이 동일한 구조의 planning을 재현하게 구성한 것이라고 합니다.
Evaluation Metric
기존의 단일 SR만으로는 Long-horizon 비디오 기반 task generation 의 세세한 성능 측정이 어렵기에, 본 연구는 계획의 완전성, 시간적 정합성, 최종 상태의 success를 개별적으로 분리해서 평가했습니다. 평가지표를 각각 만들었는데, 다음과 같습니다.
TSR(Task Success Rate): 전체 plan step이 데모 비디오의 step과 완전히 동일한가? TSR이 1이 되기 위해선 content, temporal order 측면에서 서로의 step이 완전히 동일해야하는 컨셉입니다.
FSR(Final-state Success Rate): 최종 상태만 놓고 보아도 정답과 일치하는가? 기존 SR과 같습니다.
SSR(Step Success Rate): plan이 어느 지점까지는 정확하게 진행되다가, 어느 시점에서 처음 오류가 발생하는지?(부분 성공률). 생성된 plan의 steps를 데모 비디오의 steps와 시간순으로 정렬하고, 데모의 GT step 수에 대해서 몇 step까지 올바르게 정렬됐는지.
Baseline
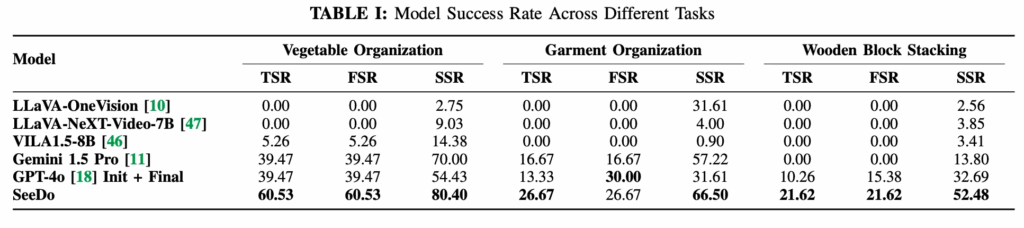
세 가지 long-horizon 태스크(채소 정리, 의류 정리, 블록 쌓기)를 기준으로 기존 오픈소스 비디오 VLM들과 SeeDo의 성능을 비교한 결과, SeeDo는 모든 지표(TSR, FSR, SSR)에서 일관적으로 높은 성능을 보여줍니다.
물론, 사용하는 모든 모델이 “비디오 기반 long-horizon planning”이라는 어려운 문제를 푸는 것이라고 볼 수 있기에 전체적으로 TSR이 낮고, 계획을 완전히 정답처럼 따라가는 모델은 거의 없는 모습을 보이긴 합니다.
하지만 좀 눈여겨 볼 부분이 있긴한데, TSR, FSR은 데모 영상의 전체 흐름을 처음부터 끝까지 제대로 이해한건가? 의 측면에서 의미있는 지표가 될 수 있습니다. 근데 기존 모델들 중 인풋을 16프레임으로 균등 샘플링한 오픈소스 모델들은 거의 10 이하의 성능을 보이는 조금은 충격적인 모습을 보이고, 그나마 Gemini 1.5 Pro는 자체의 네이티브한 비디오 입력지원으로, GPT4o는 첫+끝 샘플링 인풋으로 진행한 파이프라인이 그나마 성능을 조금 치고 올라오는 모습을 보입니다. SeeDo는 video input에서의 샘플링 개선과 visual prompting 개선으로 이들보단 좋은 성능을 보인 것이라고 이해하면 될 것 같습니다. input sampling을 위해서 keyframe selection을 어떻게 잘해주고, 이를 기반으로 어떻게 visual prompting을 잘 만들어주냐에 따라 성능이 올랐다! 라고 할 수 있겠지만서도,, 이게 생각보다 단순하면서도 직관적인 인사이트긴 하지만, 그저 오픈소스 모델이 생각보다 closed모델보다 reasoning 성능 자체가 약해서 그런 것 아닌가 싶은 생각도 좀 크게 듭니다. 아무래도 이 메인 실험 자체가 좀 빈약한 느낌이 씨게 드네요… (어케 IROS 붙은 거지) SSR은 “몇 단계까지 맞게 따라갔는가?”의 측면에서 Long-horizon에 대해 평가를 하려한 것이라고 볼 수 있는데, 그래도 저자들의 SeeDo가 유의미한 성능 증가폭을 보이긴 했습니다.
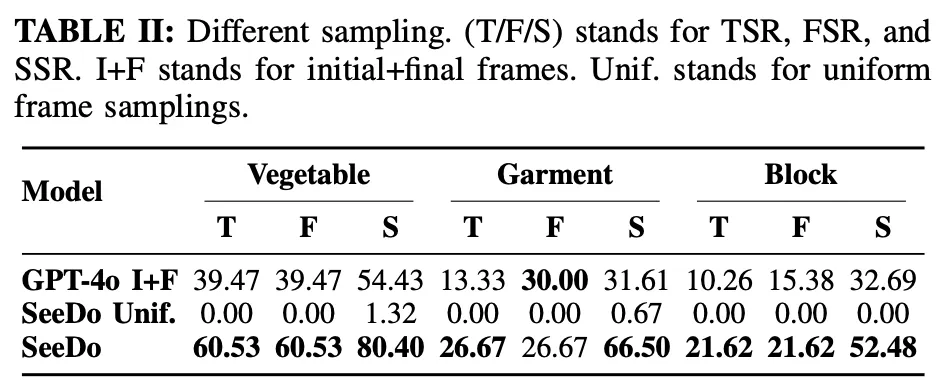
테이블 2는 Keyframe Selection module에 대한 ablation study라고 보시면 됩니다. SeeDo Unif는 keyframe selection을 하지 않고, 그냥 16 프레임으로 균등 샘플링 한 것 입니다. 샘플링된 모든 프레임을 한 번에 입력하면 컨텍스트 제한을 초과하는 경우가 많았다는 문제가 있었다곤 합니다. 어쨌든 결과는 SeeDo가 keyframe selection을 하는 것이 가장 성능이 좋았습니다. 비디오의 input sampling을 어떻게 하느냐에 따라 성능이 달라진다는 것을 보여주는데, 이게 VLM에 비디오 인풋 샘플링을 어떻게 해주느냐가 이렇게까지 성능에 영향을 크게 미치는 줄 저는 몰랐는데,,, 살짝 의아하면서도 신기했습니다. 이게 단순히 아 keyframe sampling 잘해줘서 잘 넣어주면 VLM이 understanding 이랑 reasoning 더 잘하구나! 의 컨셉만은 아니고, 확실히 Long-horizon task처럼 긴 텀으로 temporal하고 spatial한 reasoning이 필요한 경우엔 애초에 주어지는 정보 자체도 유의미해야된다는 관점에서 어찌보면 당연한 것 같기도 하네요.. 하나 아쉬운 점은 왜.. GPT-4o만 가지고 self-evaluation만 했는가.. 가 좀 아쉽네요. IROS 리뷰어들 입장에선 앞선 main results에서 보였으니 충분하다고 받아들여진 것 같기도 합니다.
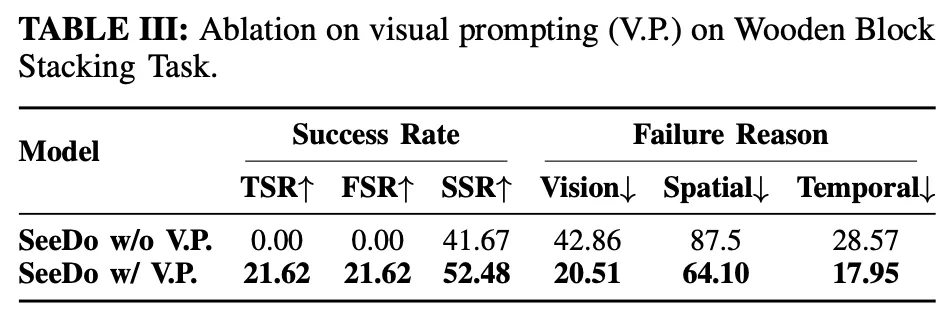
테이블 3은 visual prompting에 대한 ablation study 결과입니다. 오직 Wooden Block 태스크에 대해서만 결과를 보였는데, 이 태스크가 모두 나무 블록 표면을 가지고 있어서 grounding 구별이 가장 쉽지 않은 태스크라는 점에서 이 태스크만 실험 결과를 보인 것 같긴합니다. 근데 사실 Garment도 옷 색깔이 비슷해보이는 것도 많고, deformable한 형태여서 grounding 어려워보이긴 했는데 쏙 뺀게 사알짝 의심스럽긴 하네요. 아무튼 해당 ablation study에서도 keyframe들에 대해 Visual Prompting을 적용한 것이 VLM의 reasoning 및 planning에 직접적인 영향을 줬다는 점을 보였다고 볼 수 있겠습니다.
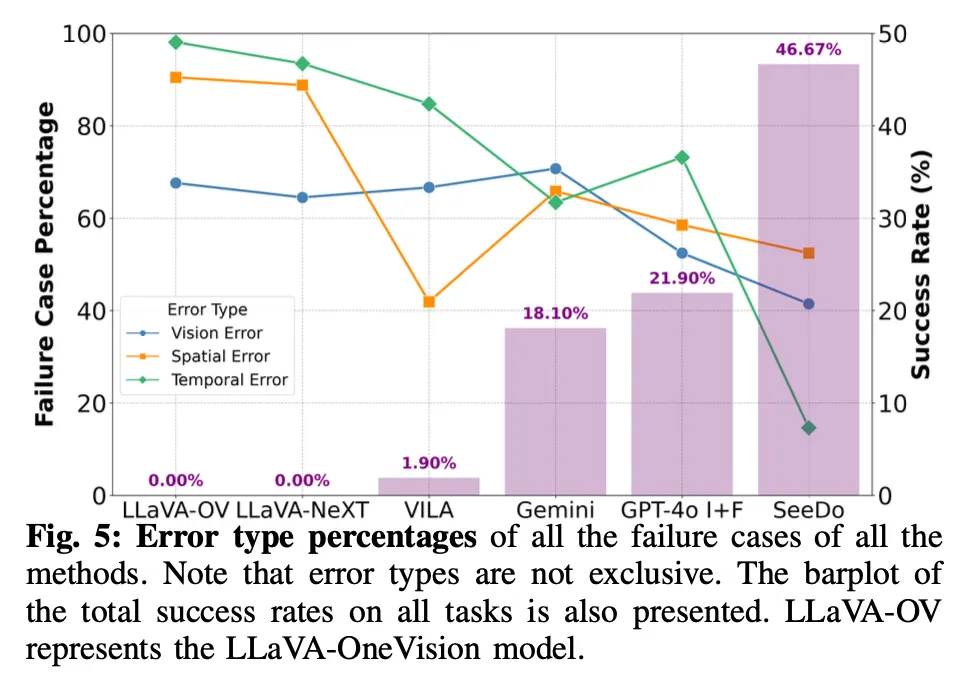
마지막은 Error type의 비율과, success rate의 성능을 왼쪽, 오른쪽으로 동시에 보인 그래프인데요. 베이스라인으로 삼은 오픈소스 VLM모델들과 closed VLM인 Gemini, GPT-4o I+F 들에 비해 일반적으로 저자들의 SeeDo 방법론을 사용한 것이 Failure case percentage가 낮은 모습을 보이긴 합니다. 특이한 점은 SeeDo에서 temporal한 error가 가장 많이 줄었다는 점에서 미루어볼 때 keyframe selection을 통한 VLM planning이 temporal한 reasoning에 효과를 많이 주었다고 생각해볼 수 있을 것 같고, spatial error의 경우는 SeeDo의 failure case에서 가장 많은 비중을 차지하고 있는 것으로 보아, visual prompting을 사용하더라도 VLM(GPT4o)의 spatial reasoning은 부족한 면이 있다는 것을 유추해볼 수 있었습니다. 특히 그런 관점에서 Spatial Error는 Vision Error랑도 서로 중첩되어 error가 증폭될 수 있을 것으로 생각되기도 합니다.
4. Conclusion
읽고,, key contribution 방법론이 되게 단순하다.. 본인들이 세팅한 experiment 세팅과 제안한 eval metric 등은 거의 Self-evaluation 스럽네.. 이 정도만 써도 IROS 붙었다고? 생각이 자꾸 들게 만든 논문이었습니다. 그래도 앞으로 제가 sub-task decomposition 연구를 수행함에 있어서, 비디오 인풋을 처리하고 싶은 경우엔 어떻게 효과적으로 프레임을 샘플링하지에 대한 고민이 살짝 있어왔는데 이런 keyframe selection이 planning 시에 좋은 영향을 줄 수 있다는 점을 보면서 고민의 해답을 조금 얻어간 것 같아 도움이 된 논문이었습니다. 감사합니다.
재찬님 좋은 리뷰 감사합니다.
keyframe selection 기준을 사람의 손 움직임을 기준으로 한다는 점이 참신한 것 같습니다.
물건을 들거나 내려놓는 경우 손이 느려진다는 정보를 기준으로 keyframe을 선정하였는데, sub-task planning을 보면 물체를 든다 -> 어디로 이동한다 ->내려놓는다 이런식으로 중간에 어디로 이동한다와 같은 정보가 누락되는 건 아닐까 하는 생각이 듭니다. 따라서 속도가 변하는 영역을 기준으로 keyframe을 선정하는 건 어떨까 하는 생각이 듭니다. 이에 대한 재찬님의 의견이 궁금합니다.
또한, 실험 세팅을 보면, 1인칭과 3인칭 영상이 혼재되어있는데, 이를 함께 사용하지 않았을 때 성능 개선이 더 이루어질 수 있지 않을까 하는 생각이 듭니다. 이러한 시점에 대한 영향을 분석한 내용은 따로 없었는 지 궁금합니다.
승현님, 리뷰 읽어주셔서 감사합니다.
1.
타당한 질문이라고 생각이 들지만, 본 논문에서는 pick-and-place를 low-level primitive action으로 두기 때문에, keyframe selection에서 이동중이다에 대한 장면을 고려하지 않게끔 일부러 유도한 것 같습니다.
하지만 제 생각으론 실제 low-level action이 복잡해질 수록 승현님이 제안한 속도변화부분에 대한 keyframe selection도 유효할 수도 있을거란 생각이 듭니다.
2.
논문 내에선 시점을 1인칭만, 3인칭만, 모두 에 대한 ablation 실험은 없었습니다. 제 개인적인 생각으론 실제로봇작업 환경과 휴먼 비디오의 뷰포인트를 동일시 시키면 더 잘할 것 같단 생각이 들긴 합니다.
감사합니다!
안녕하세요 재찬님 좋은 리뷰 감사합니다!
읽으면서 간단하게 궁금한점이 생겼는데요!
균등한 샘플링 자체가 중요한 동작이 담긴 keyframe을 놓치게 만드는 점을 방지하기 위해서 사람의 손이 물체를 잡거나 내려놓을 때 속도가 느려지는 경향을 통해 keyframe을 선정하였다고 이해를 했습니다! 하지만 제 생각에 이 경우에는 손가락의 움직임은 빠를 것 같다고 생각이 들었습니다!
궁금한 것은 속도의 기준이 어떤 keypoint인지 나와있었나요? mediapipe에서 손목이 기준 keypoint로 알고있는데 혹시 손목이 기준인가요??
감사합니다
인하님, 리뷰 읽어주셔서 감사합니다!
말씀해주신 부분 중
1. wrist keypoint에 대한 속도만 계산한거냐?
-> 손에 모든 keypoints들의 centroid를 계산해서 그 centroid를 기준으로 시간에 따른 이동속도를 계산한거라고 합니다.
2. 손가락 속도는 손보다 더 빠른데 어떡하냐?
-> 실제 휴먼 비디오 데모 데이터를 보니,, 이거 저자들이 작정하고 key frame이 될만한 장면에 대해서 일부러 손 속도를 느려지게 천천히 동작하더라구요ㅋㅋ; 그래서 본 논문 상에선 문제가 되지 않은 것으로 보입니다. 더구나 손의 모든 keypoints들의 centroid로 속도를 계산하다보니 아무리 손가락 keypoints가 크게, 빠르게 변화해도 손 전체로 봤을 땐 centroid에 큰 영향을 주지는 않을 것 같단 생각입니다. 물론 손가락만으로 무언갈 미세하게 행동하는 경우엔 영향이 생길 것 같긴 하네요.
감사합니다!
안녕하세요 재찬님 리뷰 감사합니다.
VLM으로 영상을 분석할 때 로봇 데이터 상 gripper의 움직임이 생기는 부분, 로봇이 멈추는 부분 등 다양한 keyframe selection 연구들도 있었지만 keyframe을 균등하게 샘플링 하는 방식을 그냥 사용했던 연구도 있었는데, 그들의 연구에서는 더 복잡한 액션에 대해서도 성능이 어느정도 나왔던걸로 기억하는데 ablation에서 uniform frame sampling을 진행했을때 성공률이 0인게좀 의아하네요.. 제가 keyframe selection 과정을 잘못 이해한걸수도 있을 것 같습니다만 뭔가 실험은 어떻게 설계하느냐에 따라 다른건가..? 싶기도 합니다. 혹시 괜찮으시다면 이번에 연구 진행하시면서 keyframe에 대한 실험을 해보면 궁금증이 좀 해소될 것 같습니다 ㅎㅎ..
또 visual prompting 부분에서 해당 연구에서 제안된 방법과 다른 방식이 있나요? 개선된 방안이 있는지 visual prompting 부분에 좀 약해서 여쭤봅니다!!
영규님, 리뷰 읽어주셔서 감사합니다.
1.
저도 리뷰 쓰며 의아했던 부분이긴 합니다. 뭐 저렇게 까지 성공률이 0일수가 있지. 저자들이 실험을 잘못 세팅한 거 아닌가. 뭐 이런저런 내용들을 보면서 제가 결론에서 이정도만 해도 IROS 붙었다고란 말이 나와버린 것 같습니다. 말씀해주신 것처럼 keyframe selection 실험을 추후 진행해보면 저도 궁금증이 해소될 것 같습니다..
2. 음 사실 SoM의 방식이랑 거의 똑같은데, 다만 다른 점은 본 방법론에선 video input을 사용하기에 frame별 tracking을 해주기 위해 SAM2 쓴 것이 좀 다른 것 같습니다. 제가 모든 visual prompting 논문을 읽어본 건 아니지만 보통의 visual prompting을 사용하는 방법론들은 대부분 SoM방식을 따라가곤 합니다.
감사합니다!
안녕하세요 재찬님, 좋은 리뷰 감사합니다!
얼마 전부터 long-horizon task video를 그대로 써먹을 순 없을까?라는 궁금증이 있었는데 human demo video를 planning의 인풋으로 활용한다는 점이 재미있었습니다. 꽤 단순한 방법론인 것 같은데 비디오를 활용했다는 점에서 의미가 있는 논문인 것 같습니다.
planning의 각 단계는 객체 간 상대적인 위치 관계에 기반하여 생성되기 때문에 절대좌표나 카메라 뷰포인트 차이에 의존하지 않을 수 있다고 하였는데요, execution 단계에서 사전 정의된 함수가 아닌 action model을 사용하게 되면 결국 다시 저들에 의존하게 되는 것 아닌가? 하는 생각이 들었습니다. 만약 그렇다면 어떻게 이 문제를 보완할 수 있을지… 재찬님의 의견이 궁금합니다.
감사합니다.
예은님, 리뷰 읽어주셔서 감사합니다!
생각지도 못하고 있었는데, 완전 타당한 질문이네요. 좋은 문제정의 같습니다. 근데 조금 어려운 문제라고 생각이 들어서, 저희가 하고자하는 연구방향에서 해당 문제까지 실제로 해결한다면 매우 높은 수준의 논문을 만들지 않을까… 싶네요. 지금 당장은 저도 이 문제를 어떻게 보완할 지 방도가 떠오르지 않습니다. 우선은 여전히 휴먼 비디오 영상도 최대한 로봇작업환경과 유사한 뷰포인트에 의존하는 방식으로 제약을 걸고 연구하기를 생각하고 있습니다. 물론 이렇게 하면 휴먼 비디오의 장점이 확 떨어지지만요.. 좀 더 고민해보고 해결방향이 떠오른다면 나중에 같이 논의할 시간 만들어보겠습니다.
감사합니다!
(추가)https://keh0t0.github.io/EgoX/ -> 이거 최근에 나온 따끈따끈한 논문인데, 코드는 아직 미공개지만 3인칭 비디오를 1인칭 Ego-centric 비디오로 변환생성해주는 방법론입니다. 만일 이게 큰 노력없이 활용가능하다면 모든 human video 영상을 ego-centric으로 변환해주고, 로봇작업환경의 뷰도 ego-centric스럽게 맞춰줄수만 있다면 나쁘지 않을 것 같기도 하다? 란 생각이 듭니다.
좋은 리뷰 감사합니다!
해당 논문 리뷰를 통해서 지금 가고 있는 방향이 나쁘지 않은 방향이라는 확신을 가질 수 있었던 던 것 같습니다.
해당 방법론 관련해서 궁금증이 있어 간단한 질문만 하고 갈게요!
Q1. 해당 실험은 휴먼 비디오 환경과 로봇의 환경이 동일한 배치에서 작동한다는 전제 하에서 평가를 진행하는 건가요?
Q2. 만약에 Q1이 맞다면 해당 기법은 휴먼 비디오의 행동을 로봇이 동작 가능하도록 복사하는 연구라고 해석이 됩니다. 이러한 방식이 어디에 사용될 수 있을지 저자가 밝힌 바이 있을지, 없다면 재찬님은 어떤 점이 이득이 될 수 있을지 생각하시는지?
Q3. 그럼, 휴먼 비디오의 동작을 로봇 동작으로 적응적으로 복사가 가능하다면 이는 IL의 학습 데이터로 활용이 가능할 것 같습니다만… 과연 효율적인 방식인지에 대해서는 의문이 듭니다. IL 학습 데이터으로 활용한다는 관점에서 재찬님 생각은 어떠신지 궁금합니다.
태주님, 리뷰 읽어주셔서 감사합니다!
Q1. 휴먼비디오작업환경 – 로봇작업환경 이 동일한 배치라는 전제인가?
카메라 뷰포인트나 미세한 위치나 자세조정까지 완벽히 동일 배치는 아니어도 되고, 객체 종류와 상대적 위치관계만 동일시 했습니다. 저자들이 장점으로 주장하길, 휴먼 비디오에서 VLM이 ’상대적 공간 관계’를 추출해 계획을 만들다보니까 로봇환경에서 꼭 카메라 뷰포인트가 휴먼비디오와 동일 뷰가 아니어도 그런 상대동작이 재현될 수 있더라는 내용이 논문에 명시되어 있었습니다. 하지만 제가 판단하기로는 비디오 내의 물체 자세 정도는 살짝 달라져도 파지나 계획에 크게 상관없는 물체들(affordance가 중요하지 않은 물체들)로만 실험을 진행한지라 이런 게 가능하지 않았을까, 혹은 물체의 상대적 위치관계가 상,하,좌,우 정도로만 간단해서 가능하지 않았을까 생각합니다. 또 아직 3D 공간 관계는 VLM이 판단하기 어렵지 않을까 생각합니다.
(추가) 예은님의 댓글을 보고 생각이 들었는데, 저희가 생각하는 방식으로 가려면 휴먼비디오작업환경 – 로봇작업환경 과 뷰포인트까지 동일한 배치 여야할 것 같습니다. . .
Q2-1. 휴먼 비디오 행동을 로봇이 가능한 형태로 복사하는 연구..?
음.. 일단 Q1에서 질문주신 내용이 부분적으로만 맞다보니, 휴먼 비디오의 행동을 로봇의 동작으로 복사한다고까지 표현하기엔 아직 어렵고 아쉬운 부분이 있는 논문이라고 생각듭니다. 저희가 늘 생각하듯 CaP류의 방법론들은 low-level 제어를 pick and place 수준의 primitive action 으로 둔다는 점도 문제가 되는데, 그래서 복잡한 휴먼 비디오 행동을 로봇의 동작으로 복사한다고까지 일반화하려면 저희의 생각처럼 VA/VLA/Motion Planning 등으로 low-level제어를 붙여주는 저희의 방향이 맞다는 생각이 들구요. 저자들도 conclusion에서 말하길 좀 더 복잡한 행동으로 일반화 확장하고 싶다고 합니다.
Q2-2. 어딘가에 쓸모가 있는 방법론인지?
우선 저자가 어필하는 바가 “Long-horizon 태스크를 사용자가 열심히 자연어로 길게 풀어서 지시하지 않고도, 비디오 시연 찍어서 넣어주기만 하면 된다”는 것입니다. 그래서 제가 판단한 이 방법론의 쓸모는, 저희가 생각하는 LMP구조의 input으로써 모호한 명령을 내려야 할 땐, 차라리 해당 모호한 자연어랑 유사도가 높은 human demo video를 데이터베이스에서 RAG방식으로 retrieval해서 그 비디오 인풋을 받는 게 좋지 않을까? VLM의 멀티모달 추론 능력을 최대로 활용하려면 그 방향이 좋지 않을까. 이런 방향으로 쓸모가 있을 거라고 저는 생각합니다.
Q3. IL 학습 데이터로 활용 가능해 보이는데, 과연 효율적인가?
당장은 어려울 것 같습니다만, 이론적으로는 VLM기반 CaP의 grounding 및 작업분할 추론능력과 low-level policy 가 정교해진다면 IL학습데이터로 가능은 할 것 같습니다.
하지만 태주님이 걱정하시는 대로 효율적이거나 fancy한 데이터는 아닐 것 같습니다. CaP의 LMP구조의 latency가 우려되는지라 작업 데이터의 시간축도 굉장히 길어질 것 같고, 정교함이 매우 떨어져 현재 학계가 기대하는 수준의 IL데이터로써는 적합하지는 않을 것 같습니다. 물론 low-level policy가 정교해진다면 활용가능성을 기대해볼 수 있을 것 같습니다. 혹은, Long-horizon scenario의 sub-task들 자체를 사람이 판단하기가 너무 주관적이고 cost가 들다보니까, 시연비디오에서 sub-task들만 잘 분할하게 하여, 그 분할된 서브태스크에 대한 수도라벨을 만들고 나중에 사람이 검수해서 데이터로 활용할 용도로는 좋을 것 같습니다. 근데 이것도 결국 나중에 각 sub-task들마다에 적절한 policy들은 어떻게 learning해서 매핑해줄 지까지 고려되기에, 아직 문제는 있는 것 같습니다. 적고 보니 아직 좋은 방도가 떠오르진 않네요.
감사합니다!