안녕하세요! 이번 리뷰는 로봇의 데이터 취득에 관련된 논문을 들고 왔습니다. Data-driven robotics 관점에서 핵심적인 요소는 데이터 그 자체라고 할 수 있습니다. 이 논문은 쉽고 빠르게 데이터를 모을 수 있을 뿐만 아니라 policy가 환경과 object에 generalization 성능도 갖출 수 있도록 하는 UMI framework를 제안합니다. 시작해보겠습니다.

Abstract
논문에서 소개하는 UMI(Universal Manipulatin Interface)는 in-the-wild한 환경에서 수집한 Human demonstration을 로봇에 바로 적용 가능한 policy로 직접 전달할 수 있게 하는 데이터 수집 및 policy learning framework입니다. 설계된 그리퍼와 Interface를 결합하여, 편리하면서도 저비용으로 난이도 높은 bi-namual 및 dynamic manipulation demonstration 데이터를 수집 가능하게 합니다. 즉 설계된 interface를 통해 사람이 직접 간편하게 복잡한 manipulation task를 demonstration 하여 데이터를 모으고, 이를 로봇의 end-effector에 부착하여 로봇을 속이는 것입니다. 생각해보면 참 단순하지만 이런 방식으로 UMI는 하드웨어에 대한 범용성, robot action diversity 그리고 새로운 환경과 객체에 대한 zero-shot generalization을 달성했다고 하네요.
Introduction
기존에는 복잡한 manipulation skill을 demonstration 하기 위해서는 teleoperation과, human video를 이용하였습니다. 하지만 teleoperation 방식은 하드웨어와 조작하는 사람의 숙련도에 영향을 많이 받고, human video는 로봇과 사람간 embodiment gap이 크다는 단점이 있습니다. 이를 해결하기 위해서 hand held gripper를 통해서 유연하고 직관적으로 human demo를 수집하는 방식이 등장했다고 합니다. 하지만 기존의 방식들은 action diversity에 어려움을 겪었다고 합니다. 즉 여러 action들을 수집할 수는 있지만 다음과 같은 이유로 데이터의 대부분이 효과적으로 robot policy에 전달될 수 없었다고 하네요.
- Insufficient visual context: wrist-mounted camera를 사용하는 것이 interface의 휴대성과 observation space의 align을 맞추는데 핵심이긴 하지만 gripper와 매우 근접해있어서 occlusion이 발생할 가능성이 높습니다. 따라서 풍부한 visual context를 제공하기 어렵다고 합니다.
- Action imprecision: 이전의 hand-held devices는 monocular SfM(Structure from Motion)에 의존하기 때문에 거리 정보나, scale을 측정하기 모호하며, motion blur에 취약하고, 환경에 영향을 받습니다.(주변 환경이 특징점을 추출하기 어려운 곳일 경우)
- Latency discrepancies: 우리가 hand-held interface를 가지고 data를 수집할 때는 observation과 action recording이 동시에 이루어집니다. 따라서 학습된 policy는 latency를 모르는 상황이 됩니다. 하지만 inference때 latency가 생기게 되고 policy는 대처하지 못하여 이상한 동작을 하게 될 수 있습니다. 특히 이런 현상이 Dynamic action일 때 더욱 두드러지게 나타난다고 합니다.
- Insufficient policy representation: 이전의 연구는 action regression loss를 가지고 policy representation을 진행하였다고 하며, 이는 human data가 가지는 복잡한 multimodal action distribution을 해석하는 능력을 제한한다고 합니다.

논문에서는 위와 같은 문제를 다음과 같이 해결합니다.
- 논문에서는 풍부한 visual context를 제공하기 위해서 Fisheye Lens와 side mirrors를 추가합니다. 이 방식이 GoPro의 IMU 센서와 결합될 때 빠른 motion에서도 robust한 tracking을 가능하게 했다고 합니다.
- UMI는 서로 다른 latency를 맞춰주어 policy transfer를 용이하게 하였고, Relative Trajectory를 action representation으로 사용해서 환경의 변화에 더욱 강건하게 만들었습니다. 또한 이전 연구와 같은 단순한 policy 학습 방법이 아닌 Diffusion policy를 사용하여 human data의 multimodal action distribution을 효과적으로 학습할 수 있게 하였습니다.
이로 인해 UMI는 human demonstration에서 robot policy로의 높은 transferability를 유지하면서, training data만 바꿔 다양한 task를 수행할 수 있게 되었습니다. 또한 다양한 human demonstration data로 training 되었을 때 최종 policy는 새로운 환경과 물체에 대해서 zero-shot generalization 능력을 보여줬다고 합니다.
정리하자면 UMI는 하드웨어와 환경에 대한 강건성과 pick and place를 넘어 복잡한 human manipulation skill을 embodiment gap을 최소화 하여 포착하고 transfer 하기 위한 목적으로 설계되었다고 생각하시면 될 것 같습니다.
Method
UMI에는 앞에서 설명한 것 처럼 하나의 camera sensor(GoPro)가 사용되었습니다. 따라서 data 수집이 매우 편리해집니다. 또한 데이터를 수집할 때 와 실제 로봇에 deploy 할 때 같은 그리퍼를 사용하며 동일한 위치에 GoPro를 배치함으로써 calibration이 필요 없어지고, embodiment gap이 최소화 됩니다. 논문에서는 moving camera의 이점으로 background 대신 task relevant object 중점으로 policy가 학습되어서 inference 시점에서 주변 요소에 대한 강건함을 갖춘다고 하는데 ai worker도 moving camera였는데 그렇지 않았던 것 같아서.. 잘 모르겠습니다.
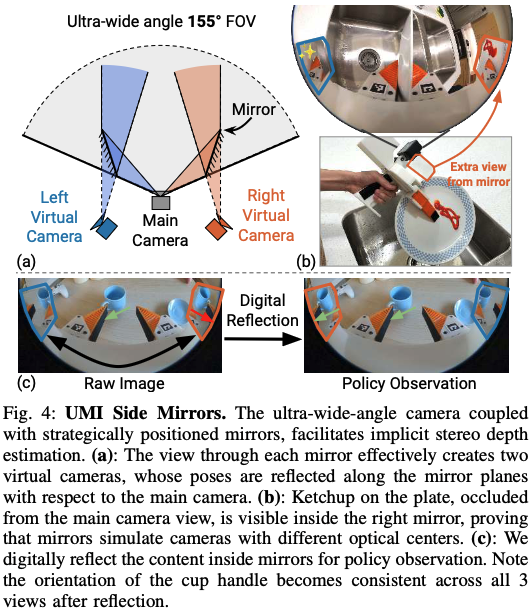
Fisheye Lens for visual context
논문에서는 풍부한 visual context를 얻기 위해서 GoPro 카메라에 155-degree Fisheye lens를 부착하여 사용한다고 합니다. 또한 왜곡 보정은 하지 않고 그대로 사용하는데 그 이유가 Fisheye 효과가 중심부의 해상도를 편리하게 유지하고 주변 시야 정보를 잘 압축해서 표현하기 때문이라고 하네요.
Side mirrors for implicit stereo
Monocular view가 depth perception 을 제공하지 못하므로 논문에서는 카메라 주변에 거울을 부착하여 stereo view를 제공했다고 합니다. 하지만 거울로 보이는 사물은 메인 카메라가 보는 view랑 반대로 보이기 때문에 fig(4)에서 보이는 것 같이 crop해서 digital reflection 시켜준다고 합니다.
IMU-aware tracking
UMI는 GoPro의 기능을 사용하여 mp4 video file에 IMU data를 기록합니다. 그리고 visual tracking 과 inertial pose constraints를 최적화 함으로써 ORB-SLAM3은 motion blur나 visual feature가 부족할 때에도 짧은 시간 동안 tracking을 유지한다고 합니다. 또한 vision 정보와 IMU 정보를 최적화 함으로써 서로의 단점을 보완해주는 이점도 있는데요 빠르게 움직일 때 생기는 vision 정보의 blur 현상과, monocular camera로 측정하기 힘든 scale과 거리 등을 IMU 센서가 보완해줍니다. 또한 IMU 센서의 오차가 누적되는 drift 현상을 vision 정보가 어느정도 잡아줌으로써 안정적인 pose를 추정할 수 있게 합니다.
Continuous gripper control
이전 연구들은 gripper에 대해서 binary open-close action을 수행했다면 UMI는 gripper의 width를 연속적으로 제어하여 parallel-jaw gripper로 수행 가능한 task 범위를 크게 확장시켰습니다. 예를 들면 물건을 잡아서 던지는 task에서는 던지는 순간에 gripper가 물체를 놓아야 합니다. 또한 물체마다 width가 다르기 때문에 binary gripper action만으로는 task를 수행하기 어렵습니다. 따라서 논문에서는 gripper 부분에 maker를 부착해서 연속적으로 width를 추정합니다. 그리고 논문에서 series elastic end effectors principle을 이용해서 soft finger의 변형 정도를 통해 악력을 제어한다고 합니다.
kinematic-based data filtering
UMI는 로봇 하드웨어에 범용성을 지닙니다. 따라서 데이터를 다양한 로봇에 적용할 수 있도록 kinematics-based data filtering을 적용한다고 합니다. 즉 로봇의 base와 kinematics가 주어졌을 때 로봇의 workspace와 제약 조건을 알 수 있겠죠? 이 결과를 바탕으로 SLAM을 통해 얻은 end-effector의 pose와 비교하여 kinematics와 dynamics의 타당성을 필터링 한다고 합니다. 그리고 이렇게 필터링된 data로 policy를 학습한다고 하네요.
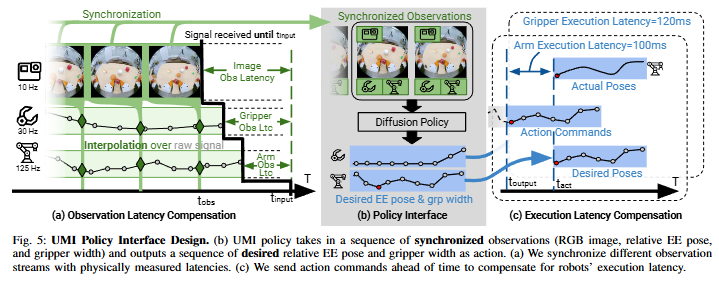
Inference-time Latency matching
human demo data는 동기화된 observation과 zero-latency action을 가정합니다. 하지만 실제 로봇 시스템은 hardware의 latency가 존재하죠. 이를 처리하지 않으면 training과 testing 간의 timing mismatch가 발생하여 빠른 action이나 정밀한 task에서 성능 저하가 발생할 수 있습니다.
따라서 위의 그림을 보시면 카메라, 그리퍼, 로봇이 서로 다른 주파수를 가지고 있습니다. 따라서 UMI는 이를 해결하기 위해서 inference 할 때 latency가 가장 큰 observation stream을 기준으로 모든 observation을 align합니다. 따라서 RGB image observation이 입력되는 시점에 gripper와 robot observation을 정렬하는 것입니다. 이는 linear interpolation으로 수행됩니다. 이러한 방식으로 interpolation된 observation을 모아서 Diffusion policy의 입력으로 사용합니다. 출력은 synchronized gripper width와 EE pose입니다. 마지막으로 policy가 로봇에게 deploy 될 때 그리퍼와 로봇이 정보를 받고 수행하기 까지의 latency가 존재합니다. 따라서 latency를 측정하고 그 latency 만큼 신호를 미리 보내는 방식을 사용합니다.
Relative end-effector pose
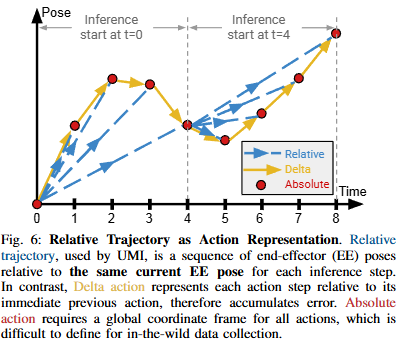
UMI는 하드웨어의 의존성과 좌표계의 의존성을 피하기 위해서 전체 EE pose를 inference 시작지점 EE pose에 대한 상대적인 좌표로 표현합니다. 따라서 Absolute action 처럼 global coordinate frame을 구해줄 필요가 없으며, Delta action 처럼 이전의 값을 계속 참조함으로써 error가 누적되는 상황도 없습니다. 따라서 로봇의 기준 좌표계가 의미 없어지고, 상호작용 하는 object들이 workspace 안에 있으면 task performance에 영향을 주지 않는다고 합니다. 이러한 점 때문에 UMI framework를 mobile manipulator에도 적용 가능하다고 하네요.
Evaluation
논문에서는 세 가지 측면을 중점을 평가를 진행했다고 합니다.
- Capability: complex, dynamic, bimanual.. 등의 task에서 robot policy를 얼마나 잘 전달 할 수 있는가를 평가하였습니다.
- Generalization: in-the-wild 환경에서 수집된 데이터로 학습된 policy가 unseen 환경과 물체에 일반화 능력이 있는가 평가하였습니다.
- Data collection efficiency: UMI를 통해 얼마나 빠르고 편리하게 데이터를 수집할 수 있는지 평가하였다고 합니다. (cup arrangement task에서는 teleoperation 대비 3배 이상 빠르다고 하네요)
Capability
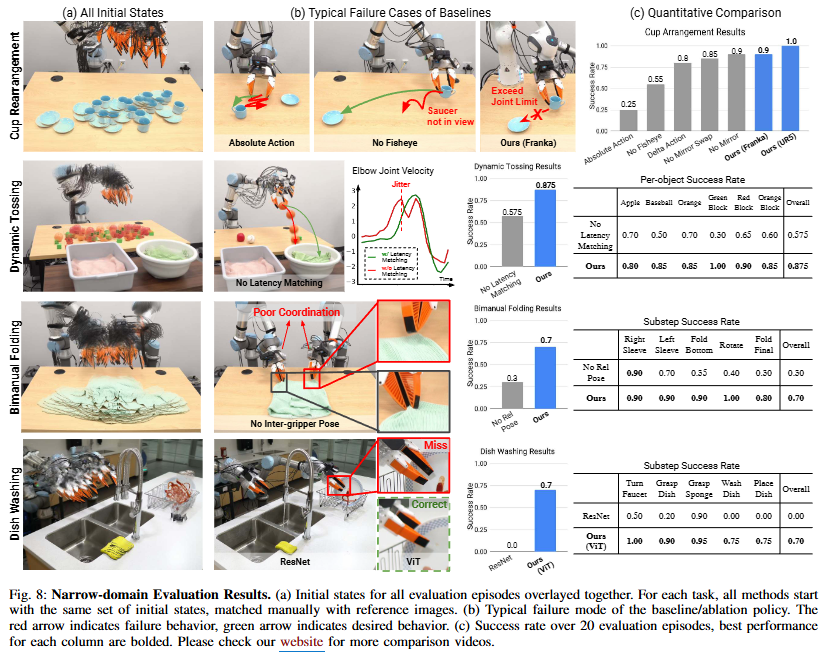
모든 task는 데이터를 모은 환경과 동일한 곳에서 평가하지만 로봇과 object의 위치는 무작위로 설정한다고 하네요. 첫번째 task는 pick and place task로 컵 받침 위에 컵의 손잡이가 로봇의 왼쪽으로 오게 하는 task였습니다. 성공률은 20/20이었다고 하네요. Frank로 수행했을 때는 joint limit 때문에 실패해서 franka의 위치가 달랐으면 성공 했을 것이라고 합니다. mirror를 사용하지 않는 것 보다 mirror의 좌우 반전을 바꿔주지 않는 것이 더욱 성공률이 낮은 것이 신기했습니다. 또한 fisheye lens를 사용하지 않고 wide view를 사용했을 때 성능 저하가 크게 나오는 것을 보였습니다. 이는 객체에 집중할 수 있는 fisheye lens의 이점이 사라지기 때문에 오히려 객체가 보일 때도 불안정한 action이 보였다고 하네요. 논문에서는 이런 visual context가 policy를 오히려 불필요한 multimodal을 forced? 하게 했다고 추정하네요.
논문에서는 latency를 고려하지 않고 inference 할 때 성능이 크게 떨어지는 것을 확인했습니다. robot의 jittering이 모터 가속을 방해하고, action과 gripper간의 misalignment는 부정확한 object release를 유발했다고 합니다. 하드웨어 간 주파수와 latency를 고려하는 것은 매우 중요한 것 같습니다.
bimanual manipulation task는 양 팔의 협력을 요구하기 때문에 one arm task 보다 어려운데요 UMI에서는 각 gripper간의 서로의 상대적인 pose를 policy에 제공함으로써 성공률을 높였다고 합니다. 또한 두 팔 모두 goal pose에 도착 후 grasp를 진행하게 동기화 시켰다고 하네요.
설거지를 하는 task를 위해서 한 사람이 258개의 demonstration을 수집했다고 하며 접시 위치나, 스펀지 위치, 케첩의 종류, 수도꼭지의 각도 등은 random하게 설정되었다고 합니다. 또한 세척 도중 케첩이 또 뿌려지는 상황에서도 다시 recovery 행동에 대한 demo도 포함되어 있다고 합니다. CLIP으로 pretrained된 ViT vision encoder를 fine-tuning하여 diffusion policy를 학습했다고 하는데요 various distractors에도 강건함을 보였다고 합니다.(mustard, chocolate syrup..) 하지만 ResNet34를 학습시켜서 사용했을 때는 주변 환경 변화에 민감하게 반응했다고 합니다. 실제로 성공률이 0%였습니다.
Generalization

논문에서는 in-the-wild한 환경에서 수집된 데이터가 일반화 능력에 어떤 영향을 미치는지 확인하기 위해서 3명의 사람들이 각각 12시간 동안 다양한 환경에서 cup-arrangement task를 위해 데이터를 수집했다고 합니다. 컵의 종류도 다양하게 가져갔다고 합니다. 또한 이러한 일반화 성능이 pretrained vision backbone 때문이 아니라는 것을 보여주기 위해서 lab실에서 demo를 수집하였다고 합니다. 그결과 성공률은 0% 나오는 것을 보아서 in-the-wild한 환경에서 수집한 data가 unseen object, environment에 일반화 능력을 주는 것을 확인했다고 합니다.
이럼에도 불구하고 논문에는 한계점이 존재하는데요 robot kinematic limits를 모르기 때문에 filtering에 의존한다는 점과 slam의 환경적 제약, gripper의 자유도 제약으로 인한 dexterous manipulation이 어렵다는 점입니다.
따라서 차후 논문에서는 robot의 kinematics로 불가능한 action으로부터도 전달 할 수 있는 framework 개발과 3인칭 view활용, gripper 개선에 노력한다고 합니다.
안녕하세요 인하님, 좋은 리뷰 잘 읽었습니다.
method에서 stereo view 효과를 주기 위해서 사이드 미러를 사용했다고 하는데, 그 원리가 잘 이해가 가지 않아서 질문 드립니다. 거울을 통해 보이는 추가적인 뷰를 제공함으로써 마치 두 개의 카메라를 사용하는 듯한 효과를 주기 위함인가요? 이를 통해 얻는 이점이 무엇인지 궁금합니다. 그리고 앞으로의 연구에서 사용할 UMI에서는 사이드 미러를 사용하지 않을 계획으로 알고 있는데 그 이유도 궁금합니다!
감사합니다.
안녕하세요 예은님 질문 감사합니다!
바로 답변 드리겠습니다.
UMI에서 side mirror를 추가한 이유를 설명해보면, depth 정보 인식이 부족한 단안 카메라의 단점을 해결하기 위해서 도입되었다고 생각하면 될 것 같습니다. 거울에 반사된 image를 통해서 더욱 풍부한 visual context를 policy에게 제공할 수 있는 것이죠. 하지만 image를 그대로 사용할 경우 mirror view 특성상 imgae의 좌우 반전이 있기 때문에 crop하여 좌우 이미지를 바꿔서 사용합니다.
사이드 미러를 사용하지 않을 계획은 저도 처음들어서 허허 생각해보면 단안 카메라를 사용하는 경우에는 side mirror가 필요할 것 같으나 stereo camera를 사용할경우 사용하지 않아도 괜찮을 것 같습니다. 하지만 fisheye view가 성능에 큰 영향을 미치므로 복합적으로 고려해봐야 될 것 같습니다. 또한 앞으로는 tactile sensor가 gripper 부분에 추가 될 것이므로 보완 가능성이 있어 보인다고 생각합니다.
감사합니다.
인하님 좋은 리뷰 감사합니다.
fisheye 렌즈가 현실 정보의 왜곡이라 생각하였는데, 중앙 시점에 집중하는 효과를 주어 성능이 개선되었다는 점이 인상적인 것 같습니다.
몇가지 궁금한 점이 있습니다.
기존 연구의 한계 중, monocular SfM에 의존하기 때문에 거리 및 scale 정보를 측정하기 모호하여 motion blur에 취약하다고 하였는데, 굉장히 작게 보이는 side mirror로 이를 해결할 수 있었다는 것이 신기합니다. side mirror의 유무에 따른 정량적 평가는 따로 없었는 지 궁금합니다. 또한, 기존 연구는 RGB-D 센서를 사용하지 않는 것이 일반적이였나요?
Generalization 실험 파트에서, pretrained vision bacbone이 일반화 성능 때문이 아니라는 것을 보여주기 위해 lab실에서 데모를 수집하였고, 그 결과 성공률이 0%였다는 것이 잘 이해가 되지 않습니다. 조금 더 설명해주실 수 있나요?
안녕하세요 승현님 질문 감사합니다!!
Q(1) 제가 리뷰에서 슈욱 넘어간 부분이 있어서 설명해보면 Fig.8 부분에서 No mirror 부분이 side mirror를 사용하지 않은 평가 결과입니다. success rate 0.9로 약 10% 정도 떨어진 것을 확인할 수 있습니다! 또한 기존의 연구들을 많이 살펴 본 것은 아니지만 논문에서 언급된 기존 연구를 보면 아이폰을 사용한 것으로 보아 depth에 대한 정보가 사용되는 것으로 보입니다. 하지만 UMI는 간편하면서도 효율적이고 누구나가 다 쉽게 데이터를 취득하게 하자는 철학을 가지고 있어 최대한 간편하게 GoPro를 사용한 것 같습니다!
Q(2) 좀 더 풀어서 설명해보겠습니다! UMI 저자들은 UMI로 취득한 데이터 즉 in-the-wild 상황(밖에 돌아다니면서 데이터 취득 카페, 공원, 벤치) 에서 취득한 데이터로 CLIP 기반 ViT를 fine tuning 해서 사용합니다. 저자들은 사람들이 이런 pretrained vision backbone의 일반화 성능 때문에 policy 학습이 잘되는거아닌가? 생각할 수도 있을 것 같아서 in-the-wild에서 취득한 데이터로 fine tuning한 ViT와 일반적인 lab실 그냥 같은 환경에서 취득한 데이터로 fine tuning한 ViT로 diffusion policy를 학습 시켰을 때 일반적인 lab실에서 취득한 데이터로 학습 시킨 경우 unseen 상황에서 0%의 성능이 나왔다고 합니다.
감사합니다
안녕하세요 인하님 리뷰 감사합니다.
UMI 논문이 단순히 데이터 취득 하드웨어 이외에 해당 파이프라인으로 policy를 학습하고 inference시에 일반화나 작업 성공률을 크게 향상시켜주는 부분으로 relative end effector pose가 있다고 생각하는데요, 로봇의 기준 좌표계가 의미 없어지고, 상호작용 하는 object들이 workspace 안에 있으면 task performance에 영향을 주지 않는다는 부분에 대해서 조금 더 설명을 부탁드려도 될까요? Figure 상에 relative, delta, absolute의 차이가 궁금합니다.
안녕하세요 영규님 질문 감사합니다!!
좀 더 풀어서 설명해보겠습니다.
맞습니다. UMI에서 bimanual manipulation task를 수행할 떄 성공률을 크게 향상시키는 부분으로 relative and effector pose를 계산해서 policy에게 학습시키는 방식이 있습니다.
질문 주신 로봇 기준 좌표계가 의미가 없어진다는 부분을 풀어서 설명해보겠습니다! 우선 relative, delta, absolute에 대해서 설명해보겠습니다. 우선 absolute는 지정된 절대 좌표계 기준으로 좌표가 정해집니다. 즉 지정된 frame 기준으로 EE pose가 계산되는 방식이라고 생각하시면 될 것 같습니다. 이러한 방식을 사용하면 로봇의 base frame이 바뀌는 순간? 모든 좌표가 틀어지게 되겠죠? 따라서 환경에대한 일반화 성능이 떨어지는 현상이 생깁니다. 그리고 delta는 이전 EE pose를 기준으로 다음 pose를 예측합니다. 이 과정은 absolute 처럼 로봇의 base frame 변화에 민감하지 않습니다. 하지만 오차가 생기면 생길수록 전의 EE pose를 기준으로 계산하므로 계속해서 오차가 누적되는 단점이 있습니다. 마지막으로 relative 방식은 기준 frame을 inference시 EE pose로 선정하여 환경에 강건성도 가져가면서, 오차의 누적도 최소화 할수 있는 방안입니다!
감사합니다