안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 slot attention 및 object branch / relation branch 병렬 구조를 적용하여 Pixel-Level / Box-Level Video Scene Graph Generation을 수행할 수 있는 방법론을 제안한 논문입니다. 처음 읽을때만 해도 Arxiv에 막 올라온 따끈한 논문이었는데, 리뷰 작성하고 있는 지금 보니 막 WACV2026에 accept되었네요. 개인적으로 세부 구현이 궁금해 빠른 코드 공개를 기대하고 있습니다.
그럼 바로 리뷰 시작하겠습니다.

이전 리뷰에서 여러 번 설명했듯, Scene Graph Generation(SGG)은 주어진 scene 에서 물체들을 찾고(object detection), 그 물체들 간의 관계(relation)을 찾아내어 <subject-predicate-object> triplet으로 잘 기술하는 것을 목표로 합니다. video scene graph generation에는 target frame에 대한 scene graph를 예측 할 때 해당 target frame 뿐만 아니라 다른 인접 프레임들의 정보를 활용하여 예측을 수행합니다. 기존에는 주로 object detection 기반의 SGG가 수행되었지만, 점점 발전하여 segmentation 기반의 SGG로도 확장되고 있습니다. 해당 논문에서는 object detection 기반의 video scene graph generaion을 VidSSG나 DSGG(Dynamic Scene Graph Generation)라고 표기하고, segmentation 기반의 SGG를 Panoptic Video Scene Graph Generaion(PVSG)라고 지칭합니다.
기존에는 video SGG가 multi-stage로 수행되는 것이 대부분이었는데, 본 논문에서 제안하는 방법론은 1-stage로 동작하게 하였으며, 동시에 모델 구조 변경을 최소화하여 VidSGG / PVSG 두 task에서 모두 동작할 수 있도록 모델을 설계하였습니다. 이 논문 이전에 2024 CVPR에서 DETR 구조를 기반으로 one-stage VidSGG을 수행할 수 있는 OED라는 모델이 제안되었었는데, 해당 모델과 본 논문이 제안하는 모델 UNO의 가장 큰 차이점은
1. OED는 object detection -> relation classification을 순차적으로 진행하는 직렬 구조라면 UNO는 object 예측과 relation 예측을 병렬적으로 별도로 수행하여 이후에 예측 결과를 매칭하는 방식이라는 점과
2. UNO의 object, relation 예측은 transformer decoder 구조가 아닌 slot attention을 기반으로 수행된다는 점입니다.
오히려 OED보다는 2025년 WACV에 제안된 DDS와 더 유사하다고 볼 수 있을 것 같네요. DDS는 DETR 구조를 기반으로 object / relation을 예측하는 branch를 별도로 두어(병렬구조) 예측을 수행하는 방법론입니다. 처음 UNO를 보면 솔직히 DDS 구조에서 decoder만 slot attention으로 바꾸고 안정성을 위해 contrastive loss 하나 추가한 구조라고 생각됩니다.
그래도 multi-stage pipeline이 주류였기 때문에, 저자는 이에 대해 문제 제기를 합니다. 또한, VidSGG와 PVSG 각각을 위한 모델 간 구조가 너무 달라 상호 호환이 불가능하다는 지적도 합니다(가끔씩 여러 task를 동시에 수행할 수 있는 통합 프레임워크를 제안할 때 종종 보이는 문제 정의 흐름입니다. 이런 논문들에서는 여러 task를 통합적으로 다룰 수 있으면 좋다고 주장합니다)
이러한 한계를 극복하기 위해 저자들은 1-stage로 동작하는 통합(unified) 프레임워크인 UNO를 제안합니다. 핵심 아이디어는 박스 레벨(VidSGG)과 픽셀 레벨(PVSG)이 서로 완전히 다른 task인것처럼 보이지만, 근본적으로는 ‘object-centric representation’이라는 공통된 semantic context를 공유한다는 가설입니다. 그리고 object-centric한 학습 및 추론을 위해 모델 전반에 slot attention을 적용하였습니다.
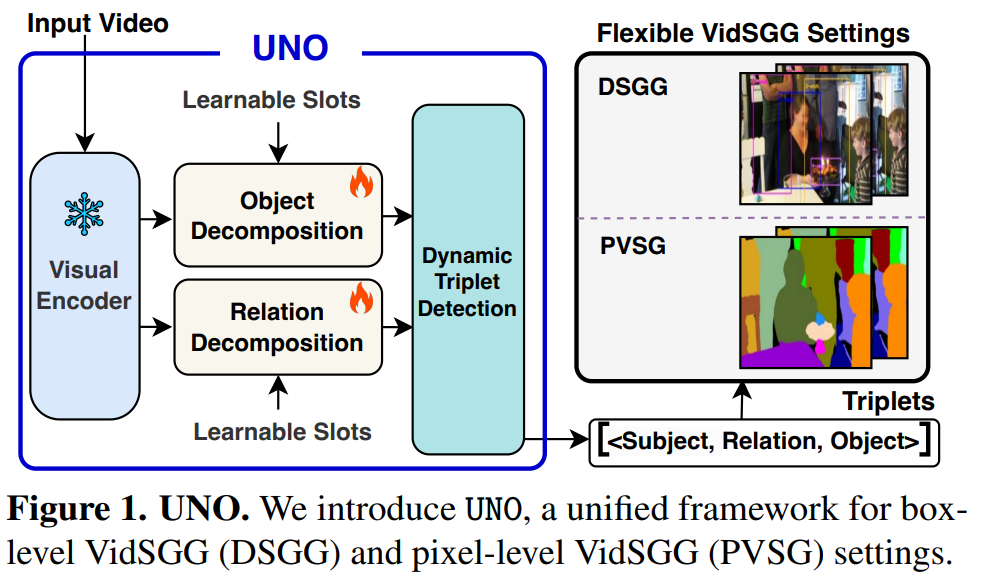
Figure 1에는 UNO의 전반적인 구조가 나타났습니다. object / relation decomposition을 수행하는 부분은 각각 object / relation에 대한 예측을 수행하는 slot attention module입니다. DETR의 decoder와 비슷한 역할을 수행한다고 생각하시면 이해가 쉬울 것입니다. 그럼 자연스럽게 visual encoder를 타고 나온 feature와 slot attention을 수행하는 learnable slot은 일종의 (DETR decoder에서의) object query와 비슷한 역할을 하는 무언가로 생각할 수 있겠죠. 이후 Dynamic triplet detection block에선느 object와 relation 각 예측값들을 매칭시켜주어 <subject-predicate-object> triplet을 만들어 최종 에측을 수행하는 구조입니다. 별다른 tracking module도 없고 크게 복잡하진 않습니다. 다만 단순한 transformer attention이 아닌 slot attention이 수행되기 때문에 visual feature map을 compact object / relation slot으로 분해(decompose)하는 방식으로 동작하게 됩니다(일반적인 트랜스포머의 어텐션이 정보 교환의 성격을 띈다면, slot attention은 각 slot들이 feature map에서 어떤 픽셀을 담당할지 경쟁하는 효과를 가지게 됩니다. 이 때문에 decompose라는 표현을 사용한 것 같습니다.)
이제 자세한 구조를 살펴보겠습니다.
Methodology
Uno Architecture
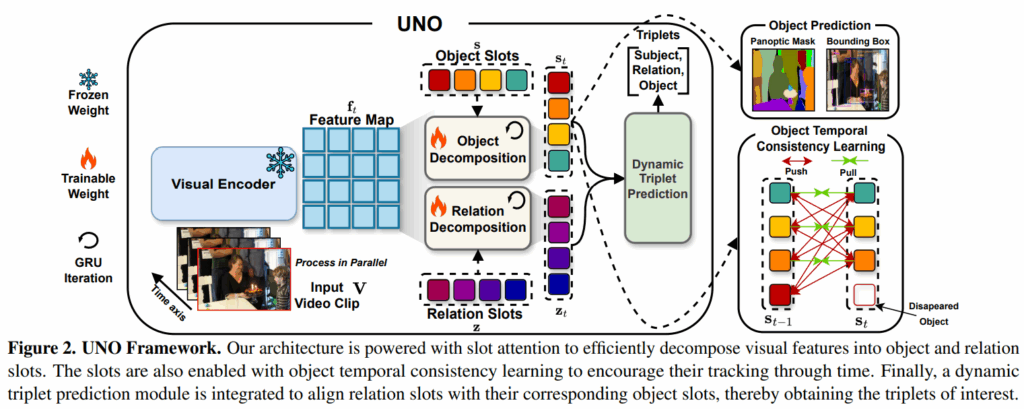
UNO의 전체적인 구조는 위 Figure 2.와 같습니다. 우선 사전학습된 비전 모델을 freeze하여 인코더로 사용합니다. 각 프레임들이 입력되면 인코더를 거쳐 피쳐맵을 추출합니다. 이렇게 추출된 피쳐맵의 정보에는 각 위치에 특정 object의 정보만 있는게 아니라 다양한 semantic 정보가 얽혀 있습니다. object-centric learning 계열 학습법들에서는 이런 feature들을 semantic하게 분리/분해하고자 합니다. 본 논문에서도 섬세한 object/relation 예측을 위해서 이런 과정이 필요하다고 합니다. 이는 object decomposition / relation decomposition으로 수행됩니다.
Object Decomposition
근래에 slot attention이 object-centric learning에서 좋은 결과들을 보여주었기에, 저자들은 피쳐맵으로부터 의미 있는 패치들을 사전정의된 slot으로 grouping하는 클러스터링 매커니즘으로 slot attention을 사용하였습니다. slot들은 각 고유한 object region들을 할당 받아 담당하게 됩니다. slot은 N개로 그 수를 미리 정의하고, learnable token 형태로 사용하게 됩니다. DETR 디코더의 object query와 거의 비슷하죠. 그런 다음 t번째 frame의 feature map {f}_{t}는 N개의 frame-wise object slot feature {f}_{t} = {{s}^{1}_{t}, ..., {s}^{N}_{t}}로 분해합니다. slot attention을 수행하면 기존처럼 feature map에 다양한 의미론적 특징이 얽혀있는(entangled) 형태로 학습되는게 아닌, 각 slot이 모듈화된 의미를 포착할 수 있도록 유도하여 프레임 전반에 걸쳐 일관된 slot representation을 확보할 수 있다고 합니다. 이는 slot attention의 특징 중 하나인데, 기존의 Convolution, transformer attention과 같은 연산으로 feature map을 만들면 다양한 정보가 벡터/행렬 형태로 얽혀있어 특정 의미만 깔끔하게 추출하기 어려웠는데(특정 장면에서 ‘의자’에 대한 semantic information을 뽑아내고 싶어도 이에 해당하는 정보만 깔끔하게 분리하기 어렵죠), slot attention은 어떤 slot이 feature map에서 특정 영역의 픽셀/패치를 담당할건지 슬롯 간 경쟁하는 효과가 생겨 보다 모듈화된 표현을 확보할 수 있다고 설명하고 있습니다. 이 때문에 ‘해당 장면에서 컴퓨터는 1번 슬롯, 의자는 2번 슬롯, 책상은 3번 슬롯 .. ‘과 같은 각 슬롯이 특정 영역을 담당하도록 학습이 이루어져 decomposition이라는 표현을 사용합니다.
저자들은 표준 Slot Attention 메커니즘을 적용해서, 3개의 선형 변환 head를 사용해 object slot s를 Query q에 매핑하고, feature-wise feature map {f}_{t}을 Key k 와 Value v로 매핑합니다. 이후 반복적으로 attention score를 계산하고 slot representation을 GRU를 거쳐 업데이트하도록 하였습니다.
각 반복(iteration) 과정은 다음 수식 (4)와 같이 이루어집니다.
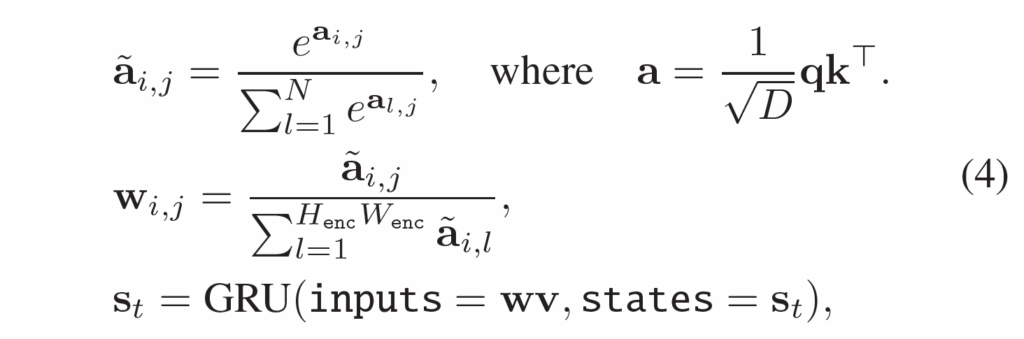
여기서 attention weights \tilde{a} 는 slot 축(차원)을 따라 softmax 연산으로 정규화되고, 가중평균계수(weighted mean coefficient) w가 value v를 집계하여 slot을 업데이트합니다. slot 축으로의 softmax 정규화 연산 과정에서 slot 간 경쟁 효과를 주게 되고, 결과적으로 각 slot이 서로 다른 object feature를 포착하도록 유도합니다. 최종적으로 마지막 iteration에서의 object slots {s}_{t}를 feature maps {f}_{t}에서의 object token으로 사용합니다.
Object Prediction
이후 object class, bounding box, mask prediction을 수행하는 가벼운 예측 head(2계층 FFN)를 활용하여 object에 예측을 수행합니다. DETR의 최종 예측 head와 유사하게 object class head와 bounding box head를 사용하여 object detection 기반의 SGG에서 물체 예측을 수행하고, segmentation 기반의 PVSG task에서는 mask prediction을 위해 4개의 transpose convolution을 활용해 feature map을 원본 사이즈로 업샘플링하고 업샘플링한 피쳐맵과 object slot 간 행렬곱을 수행해 panoptic mask를 얻어 각 object slot에 대한 binary mask로 예측을 수행한다고 합니다.
Object Temporal Consistency Learning
slot attention은 본래 이미지 도메인에서의 unsupervised semantic segmentation에서 활발히 활용되었습니다. 이를 비디오에서도 활용하고자 하는 시도가 많았는데, 비디오에 바로 slot attention을 적용시키면 temporal 축에 따라 object가 일관적으로 할당되지 않는 문제가 있었습니다. 따라서 video 도메인에 slot attention을 제대로 활용하려면 object slot이 시간적/공간적으로 일정한 representation을 가지고 일관되게 할당하도록 추가적인 제약을 걸어야 했습니다. 기존 방법론들은 contrastive loss를 추가해 object의 시간적 일관성을 확보했다고 합니다. UNO에서도 유사하게 contrastive loss를 활용하였습니다.
프레임 간 동일한 GT index로 매칭되는 slot들 끼리는 positive sample로, 그 이외의 모든 slot끼리는 negative로 취급하여 contrastive learning을 진행합니다. 이 대 t, t-1 프레임끼리 비교하는 것으로 구현했다고 합니다. 해당 과정은 Figure 2. 의 오른쪽 부분에 그려져 있습니다.
저자들이 사용한 consistency loss는 다음 수식 (5)와 같습니다.

contrastive learning이 항상 그렇듯 positive sample끼리는 가깝게, negative sample끼리는 멀어지도록 학습을 진행하여 매칭된 슬롯 간 representation이 일관성을 가지도록 하였습니다.
한가지 의문인 것은, 이 논문이 video scene graph generation을 다루는 논문임에도 temporal consistency loss 이외에는 temporal 정보를 활용하는 부분이 없다는 것입니다. 사실 이 consistency loss도 학습할때만 사용되기 때문에 inference 단계에서는 인접 frame들의 temporal 정보를 활용하는 부분이 전혀 없어서 이걸 ㅣvideo scene graph generation모델이라고 불러도 되는지 의문이 들었지만.. 이런 부분들까지 깔끔하게 해결했으면 WACV가 아닌 ICCV에 붙었겠지 하는 생각으로 넘어갔습니다. 애초에 문제 정의가 PVSG, DSGG를 모두 수행할 수 있는 모델 제안이었으니까 어떻게든 리뷰어를 잘 설득했나 봅니다.
Relation Decomposition
기존 많은 방법론들은 object detection을 먼저 수행하고 detection 결과를 바탕으로 subject-object 간 relation을 예측했습니다. 하지만 UNO는 병렬적으로 object와 relation을 동시에 예측합니다. relation을 예측하기 위해 뭔가 특별히 새로운 모듈을 도입한것은 아니고, object 예측과 동일하게 위의 식(4)를 활용하여 slot attention을 통해 relation slot으로 feature map에서 relation을 예측합니다. object 예측과 완전히 동일한 구조이지만 각 slot이 object가 아닌 slot을 예측하게 학습한다는 점이 다릅니다. 이후 각 프레임마다의 relation slot을 classification FFN head에 태워서 relation을 예측하게 됩니다.
triplet을 하나의 set으로 예측하면 중복 예측값들이 생길 수 있는데, 제안하는 방법은 slot attention 기반으로 동작하기 때문에 slot attention에 내재된 경쟁 효과 덕분에 중복성을 줄이는 효과가 있어 NMS같은 후처리 과정이 없이 unique한 예측이 잘 만들어진다고 합니다.
Dynamic Triplet Prediction
relation과 object간의 예측을 별도로 수행하므로, 최종 <s-p-o> triplet을 만들기 위해 예측 결과를 매칭할 필요가 있습니다. 이때 모든 경우의 수를 고려하면 object 예측 N개에 대해 N(N-1)개의 조합이 만들어지기 때문에 모든 예측 score를 다 만들지는 않고, 유사도 기반의 매칭을 수행합니다.
Pairwise Index Matching
매칭 과정은 Figure 3과 같습니다. relation slot으로부터 subject, object reference embedding을 만들고 이를 바탕으로 object slot과 매칭하는 방법입니다.
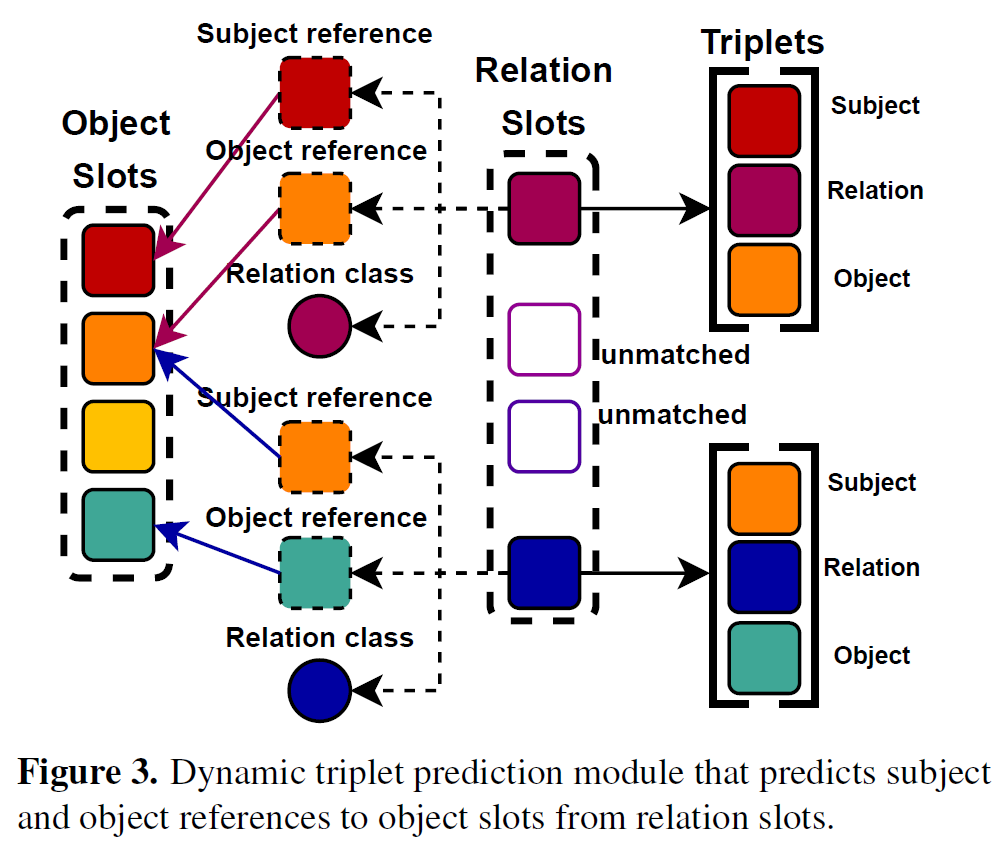
각 relation은 본질적으로 subject 및 object와 관련이 있기 때문에 relation slot으로부터 연관된 subject, object를 예측하여 매칭치킵니다. 우선 t번째 프레임에서 K개의 relation slot {z}_{t} = {z}^{1}_{t}, ... , {z}^{K}_{t}이 주어졌을 때 각 {z}^{j}_{t}에 대해 두개의 FFN을 사용해서 subject-object pair의 참조 임베딩(reference embedding) {p}^{s}_{j}, {p}^{o}_{j}을 만듭니다.
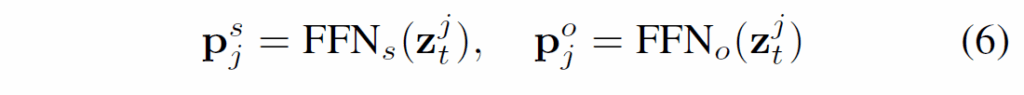
이후, 유사도 함수를 사용해서 참조 임베딩을 object slot {s}_{t}와 매칭해 object slot에 해당하는 subject, object를 찾아서 매칭합니다.

이후 매칭된 쌍들을 모아 최종적으로 <subject-predicate-object> triplet을 예측합니다.
Training Objectives
학습 과정에서는 예측된 object의 mask/box와 GT 간 헝가리안 매칭으로 object slot을 할당하고, detection / classification에 대한 학습을 수행합니다. DSGG task에 대해서는 다음 수식 (8)의 loss를 사용합니ㅏㄷ.
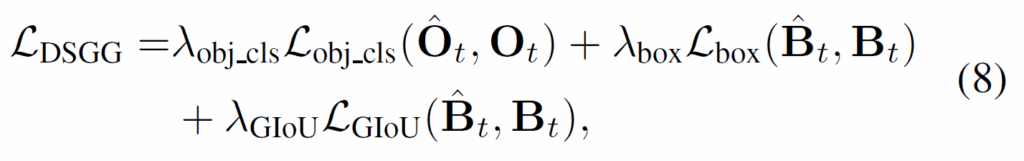
수식 (8)에서 분류 손실함수 항은 cross-entropy, box loss는 L1, GIoU loss항은 GIoU loss입니다
DSGG가 아닌 PVSG task에 대해서는 다음 (9)의 손실함수를 사용합니다.

mask loss항은 Cross-Entropy이고, dice loss항은 Dice loss입니다.
Experiments
실험 결과 살펴보고 마무리하겠습니다.
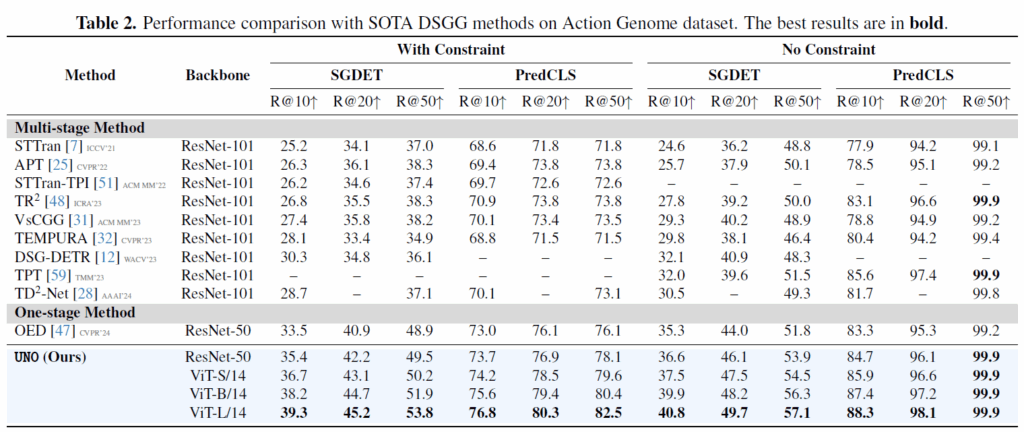
먼저 DSGG task입니다. 항상 등장하는 Action Genome dataset에서 벤치마크가 이루어졌습니다. Recall@K 지표 기준으로 기존 SOTA였던 OED와ㄴ 비교해서 동일 백본 기준 소폭 상승한 성능을 보였습니다. 최종 성능에서 많이 차이나기는 하는데 DINOv2 백본으로 바꾸니 성능이 크게 오르네요. DSGG에서는 object slot 개수 40개, relation slot 개수 24개로 설정하였다고 합니다. mR@K에 대한 리포팅은 없습니다.
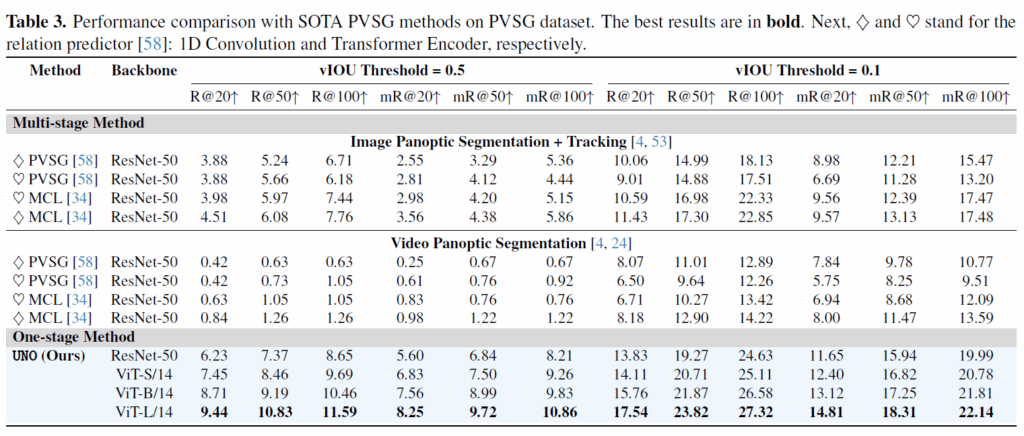
그 다음은 PVSG task에서의 벤치마크입니다. 애초에 데이터셋이 제안된지 얼마 안되어서 그런지 비교군이 많지 않습니다. 기존 방법론들보다 굉장히 많이 개선된 성능을 보여줍니다. 백본 교체로 인한 성능 이득도 크지만, 그 이전에 PVSG에서 제대로 동작하는 프레임워크가 제대로 없었던 상황에서 잘 동작하는 모델을 제안했네요.
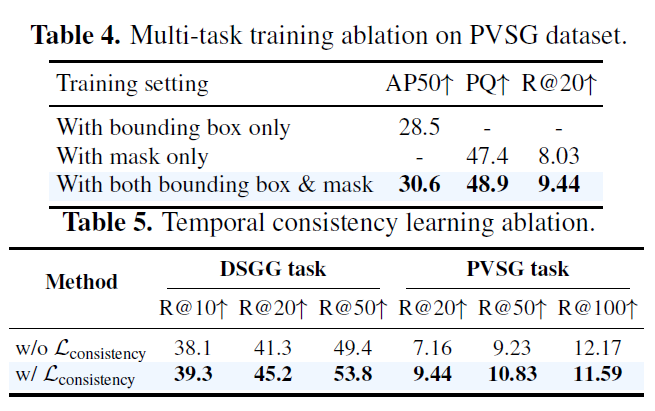
Table 4,5는 Ablation입니다. method 부분에서 task마다의 loss를 소개했는데, box-level 및 pixel-level에서의 VidSGG GT를 모두 제공하는 PVSG 데이터셋에서의 멀티태스크 학습과 task 간 시너지가 좋다고 하네요. AP는 저희가 잘 아는 Average Precision이고, PQ는 Panoptic Quality라는 지표라고 합니다.
Table 5는 consistency loss에 대한 결과입니다. 일관적인 slot 할당 경향성을 추가하기 위해 consistency loss를 추가하였었는데요, 해당 loss를 적용하기 이전/이후의 성능 차이가 좀 있어서 실제로 학습에 긍정적인 영향을 주는 것을 확인했습니다.
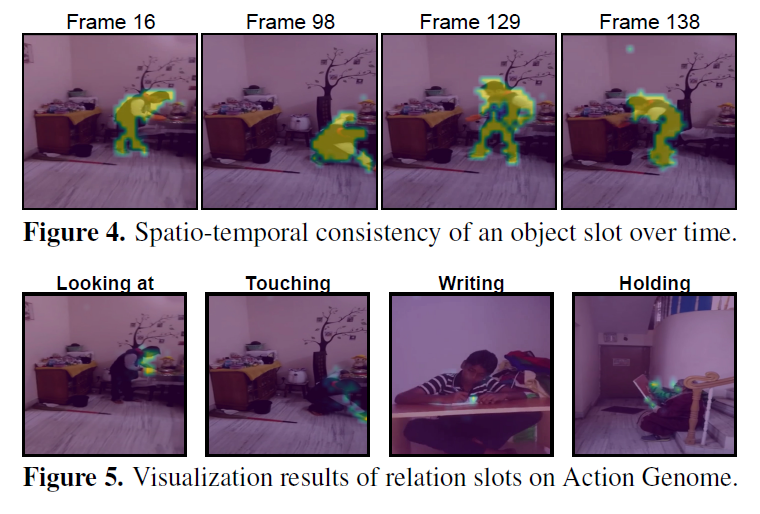
마지막으로 정성적 시각화 결과 살펴보고 리뷰 마무리하겠습니다. Figure 4, 5는 object slot과 relation slot을 시각화 한 것입니다. Action Genome에서 GT에 mask label이 없었음에도 프레임이 진행됩에 따라 object 영역이 각 slot에 할당되는것을 확인할 수 있습니다. relation slot도 subject와 object 사이 영역에 활성화가 되는것을 확인할 수 있습니다. 여기에 대해 좀 뭔가 분석/해석이 있었으면 좋았을텐데 그냥 UNO 프레임워크가 relation에 해당하는 구조적 의미를 포착할 수 있다 정도로만 설명이 되어 있네요. 논문에 전반적으로 SGG task임에도 relation 예측에 대한 고려나 서술이 좀 빈약한 것 같아 아쉽습니다.
전반적으로 relation에 대한 고려 및 temporal 정보 활용 측면에서 아쉬운 논문이었지만, 그래도 detection, segmentation 모두 잘 하는 프레임워크 제안을 위해 slot attention을 사용한다는 컨셉은 재밌었습니다.
이만 리뷰 마무리하겠습니다.
감사합니다.
리뷰 잘 읽었습니다. 몇 가지 궁금한 점이 있어 댓글 남깁니다.
UNO는 relation도 별도 relation slot으로 decompose해서 예측한다고 하셨는데, relation slot 자체에 대한 공간적 supervision(subject–object 사이 영역을 강조한다든지)이나 auxiliary loss가 있는지는 감이 잘 안오네요. 혹시 논문에 relation slot이 “어디를 봐야 하는지”를 유도하기 위한 별도의 설계(mask, attention constraint 등)가 있는지, 아니면 단순히 triplet classification loss만으로 relation slot이 알아서 subject–object 사이 영역에 집중되는건지 궁금합니다
temporal consistency를 위해 인접 프레임 간 같은 GT index에 매칭된 slot을 positive로, 나머지를 negative로 두고 contrastive loss를 쓴다고 이해했는데요. video SGG에서는 occlusion, detection 누락 등이 자주 발생할텐데, 이런 경우에는 positive pair를 구성할 수 없는 frame 쌍도 많을 것 같습니다. 논문에서 GT 트랙이 끊기는 구간, 동일 object가 일부 프레임에서는 아예 annotated 되지 않은 구간 에 대해 consistency loss를 어떻게 처리하는지(그냥 해당 쌍을 스킵하는지, 보수적으로 negative로 취급하는지 등) 구체적으로 언급되어 있었는지도 궁금합니다.