오늘은 늘 리뷰하던 Text-Video Retrieval이 아닌 Text-Visual Retrieval 페이퍼를 리뷰해보겠습니다

- Conference: ICML 2025
- Authors: Guofeng Ding, Yiding Lu, Peng Hu, Mouxing Yang, Yijie Lin, Xi Peng
- Affiliation: Sichuan University (China)
- Title: Visual Abstraction: A Plug-and-Play Approach for Text-Visual Retrieval
1. Introduction
Text-Visual Retrieval은 사용자가 입력한 문장을 기반으로 가장 관련 있는 이미지나 영상을 찾는 작업입니다. CLIP 같은 기존 VLM들은 대규모 이미지–텍스트 쌍으로 학습되어 높은 성능을 보여왔지만, 실제 검색 상황의 다양한 상황을 만족시키기에는 여러 한계가 있었죠
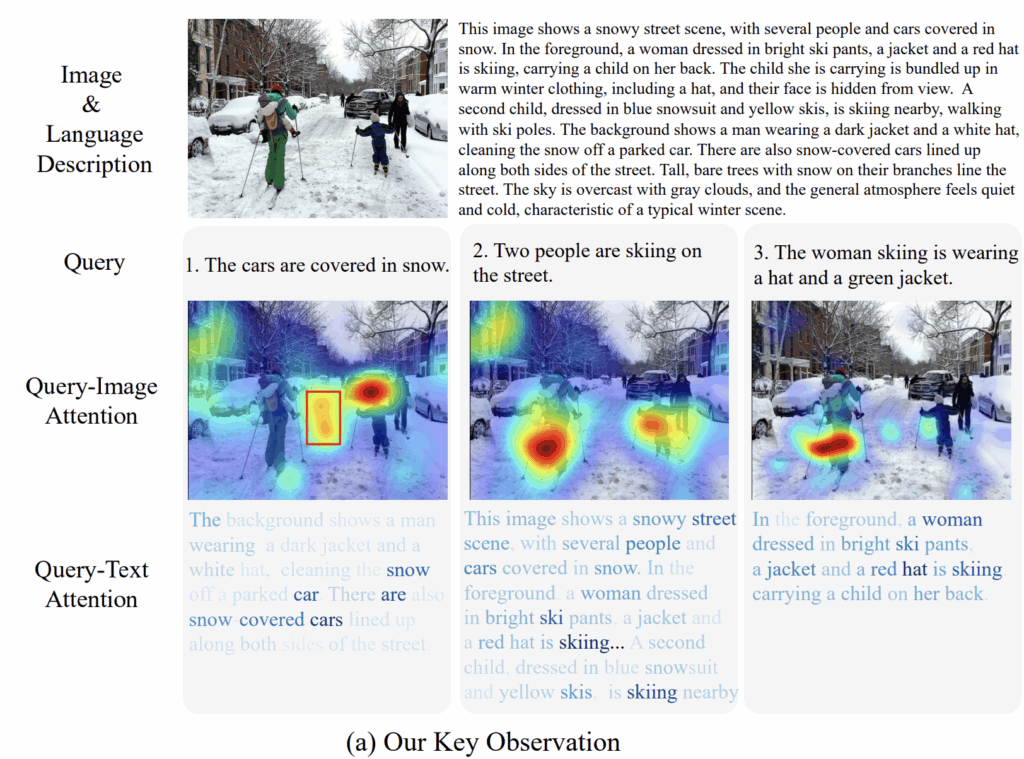
가장 큰 문제는 모델이 불필요한 저수준 시각 정보에 과도하게 주목한다는 점입니다. 그림 1(a)의 첫 번째 예시처럼, “눈에 덮인 차들”이라는 쿼리를 주었을 때 모델은 차보다 타이어 자국이나 배경 텍스처 같은 중요하지 않은 부분에 집중하는 모습을 확인할 수 있습니다. 이는 global contrastive learning 탓이라고 볼 수 있는데, 핵심 개념보다 주변 디테일을 더 크게 보고, 결국 검색 정확도를 떨어뜨리기 때문이죠.
또 다른 중요한 한계는 텍스트–이미지 간 의미 수준(granularity)의 불일치입니다. 이미지는 매우 다양한 수준의 정보를 담지만 웹 캡션은 짧고 단순하기 때문에, 사용자가 “사람 두 명이 스키를 타고 있다”처럼 조금 더 구체적인 쿼리를 던지면 모델은 이를 제대로 맞추지 못합니다. 그림 1(a)의 두 번째·세 번째 예시처럼, 모델은 전체 ‘스키 장면’은 잡지만, 사용자가 요청한 ‘특정 사람의 복장/행동’ 같은 세부 정보는 놓치는 모습을 확인할 수 있습니다.
기존 연구들은 객체 탐지 기반 설명이나 LMM(Large Multimodal Model)을 활용한 고품질의 캡션 생성 등을 시도하며 문제를 해결하고자 했습니다. 하지만 이러한 방법은 객체 수의 제한, 관계 표현의 부족, 그리고 모델을 새로 학습해야 하는 비용 문제 때문에 실용성이 떨어졌다는 한계가 있었죠.
따라서 저자는 plug-and-play 방식인 VISual Abstraction (VISA)를 제안하여, 이러한 문제를 학습 없이(test-time) 해결하는 새로운 방향을 제안합니다. 핵심 아이디어는 이미지·영상을 먼저 텍스트로 추상화해 검색을 텍스트 공간에서 수행하는 것입니다. 자연어 설명은 본래 저수준 시각 정보를 덜어내고 의미 중심 표현을 남기기 때문에, 그림 1(a)에서 보듯 모델이 핵심 개념에 더 선명하게 집중하도록 도와줄 수 있었다고 하는데요.
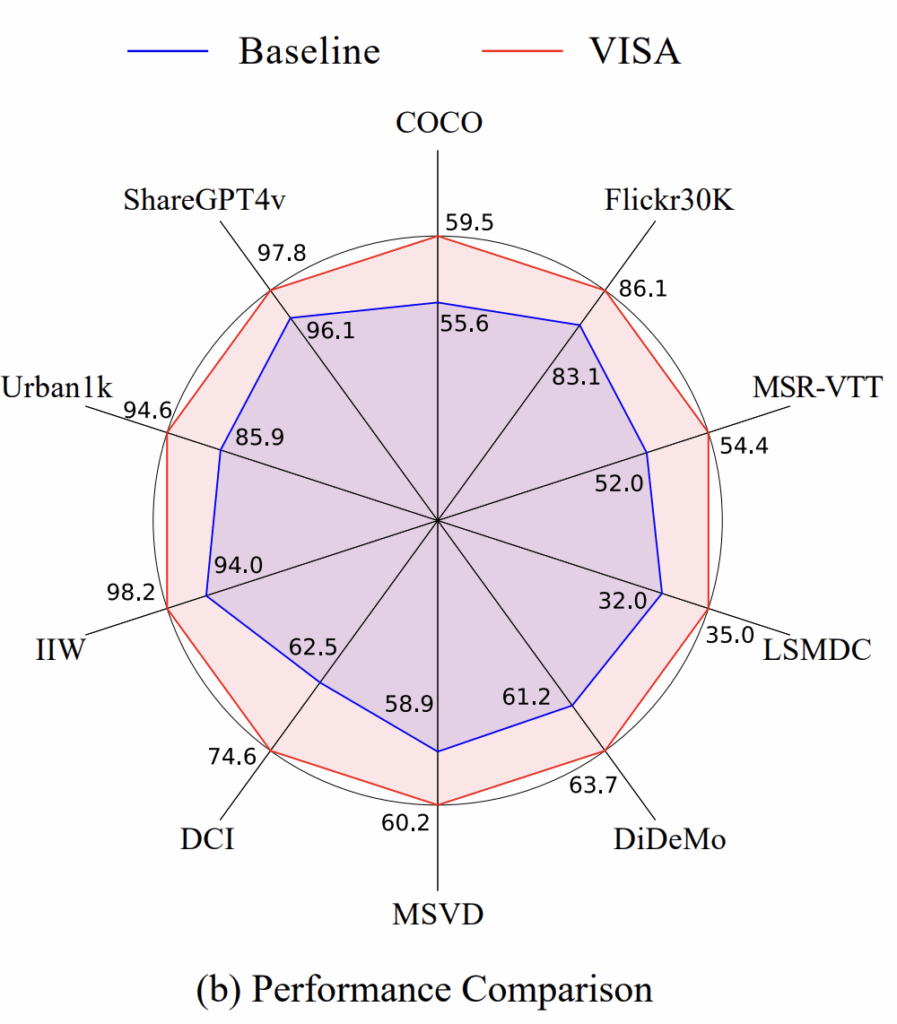
그리고 그림 1(b)에 나타난 것처럼, 이러한 단순한 test-time 플러그인 방식만으로도 기존 VLM 대비 대부분의 이미지·비디오 검색 벤치마크에서 성능 향상을 보이기도 했다고 합니다. 저자가 제안하는 방식이 무엇인지 지금부터 살펴보겠습니다.
2. Method
저자가 제안하는 VISA는 테스트 시간 동안 텍스트에서 시각적 검색 능력을 향상시키기 위해 설계된 play-and-plug 방식입니다. 따라서 먼저, VISA가 텍스트를 사용한 시각적 검색을 기존 VLM에 통합하는 방법에 대해 다뤄보겠습니다.
2.1 Enhancing Text-to-Visual Retrieval with VISA
기존 VLM 기반 TVR 모델은 텍스트와 비주얼을 같은 임베딩 공간에 매핑해 유사도를 계산하는 방식으로 동작합니다. 즉, 주어진 쿼리 q와 후보 이미지 I_i가 있을 때, 모델이 출력하는 기본 유사도 점수 s는 다음과 같이 표현합니다
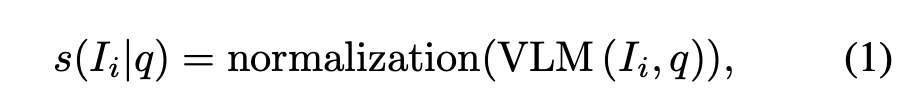
여기서 normalization은 후보들 간의 점수 스케일을 맞추기 위한 min–max 정규화 과정입니다.
하지만 문제는, 이러한 공통 임베딩 방식이 다양한 “세분화 수준(granularity)”의 쿼리에 모두 잘 대응하지 못한다는 점입니다. 예를 들어 전체 장면 설명에는 강하지만, ‘모자 색깔’처럼 미세한 속성을 요구하는 쿼리에서는 중요한 정보를 놓치기 쉽습니다. 이는 VLM이 학습 과정에서 높은 수준의 의미 정렬에 집중하고, 세부 시각정보가 점차 약화되는 구조적 한계 때문입니다.
VISA는 이 문제를 “plug-and-play” 방식으로 해결했는데요, 바로 retrieval을 한 번 더 텍스트 공간에서 재정렬(reranking) 하는 것입니다. 즉, 먼저 기존 VLM으로 top-k 후보 \mathcal{G}_{top-k}를 뽑고, 그 다음 각 후보 이미지를 자연어 설명 T_i으로 바꿔 다시 텍스트-텍스트 매칭을 수행합니다.
이때 텍스트 공간 유사도는 다음과 같이 계산됩니다:
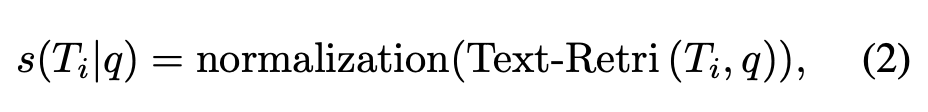
여기서 \text{Text-Retri} 는 off-the-shelf 텍스트 검색기(예: BM25, gemma2 retriever 등)를 이용해 쿼리와 후보 텍스트 묘사 간의 유사도를 계산하는 거라고 하네요. 즉, VISA는 이미지 → 텍스트 변환 후 기존 텍스트 검색 엔진의 강점을 가져오는 구조라고 할 수 있습니다 최종적으로 최적의 retrieval 결과는 두 점수를 합산해 결정합니다:
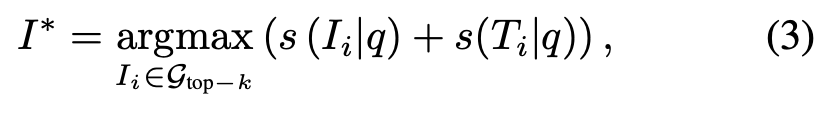
정리하자면, 1) VLM의 기존 점수는 전체적인 의미 정렬을 반영하고, 2) 텍스트 기반 점수는 세부 속성과 다양한 granularity를 반영하도록 보완하는 것이죠! 즉, 이미지를 다시 텍스트로 추상화하여 텍스트 검색의 장점을 추가한 방법론이라고 이해하면 될 것 같네요
2.2 Visual Abstraction
앞 단원에서, 기존 연구가 다루지 못하 세부 표현 보완을 위한 시각표현에 대한 텍스트 유사도가 추가된 것을 확인했습니다. 그럼 이제는 이 시각표현을 어떻게 자연어로 변환했는지를 알아봐야겠죠? 바로 시각 정보를 자연어로 변환하는 것 (VISual Abstraction)이 저자가 제안하는 VISA입니다. VISA는 크게 두 가지 모듈로 구성되며, 각 모듈에 대해 순서대로 설명하겠습니다./
1. General Description Generation
2. QA-Based Description Refinement
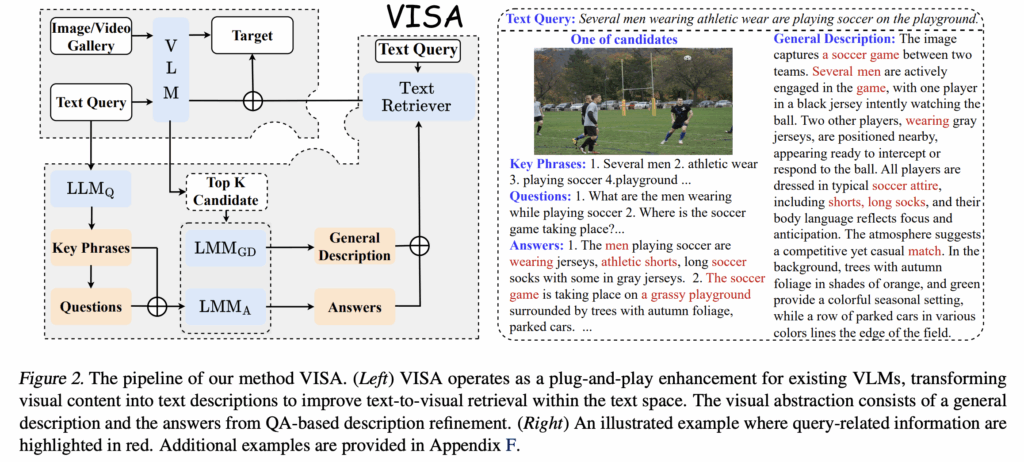
2.2.1 General Description Generation
VISA는 먼저 top-k 후보 이미지 각각을 LMM을 통해 설명문 형태로 바꿔주는 과정을 거칩니다. 이때 생성되는 긴 문장 T_i^{GD}는 다음 수식처럼 이미지를 문장으로 변환하는 함수로 볼 수 있습니다:
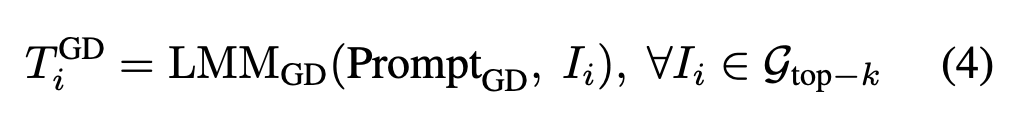
이 단계의 핵심은, 원본 이미지에 포함된 배경 잡음·질감처럼 불필요한 저수준 정보를 제거하고, 시각적 의미만 남긴 ‘압축된 서술을 얻는 것이라고 합니다. 이렇게 텍스트 형태로 표현된 시각 정보는 쿼리 문장과 비교하기 훨씬 쉬워지기 때문에, 이후의 재정렬 과정에서 검색 일관성이 크게 향상된다고 하네요
2.2.2 QA-Based Description Refinement
기존 데이터셋에 존재하는 일반 설명은 장면의 큰 흐름을 잘 잡아주지만, 사용자의 쿼리가 요구하는 ‘세부 속성’까지는 충분히 반영하지 못하는 경우가 많습니다. VISA는 이를 보완하기 위해 쿼리에서 중요한 표현을 먼저 추출하고, 그 표현에 기반한 질문을 생성해 각 후보 이미지에 대해 하나씩 답변을 얻는 QA 과정을 추가하였습니다 이 과정을 통해 시각적 요약과 쿼리 간의 세분화 수준 차이를 줄이고, 검색에 필요한 핵심 정보만 더욱 명확히 드러내고자 하였습니다.
VISA는 먼저 쿼리에서 객체·속성·행동처럼 의미적으로 중요한 표현을 뽑아 질문 세트를 생성합니다:
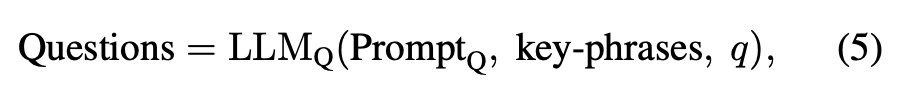
이 질문들은 명확히 답할 수 있어야 하고, 쿼리와 동일한 granularity를 유지해야 한다는 기준 아래 생성되며, LMM이 시각 정보만 보고 확실하게 판단할 수 있도록 설계되었습니다. 각 질문에 대해 후보 이미지 I_i를 보고 다시 LMM이 답변을 생성하면, 그 결과가 T_i^A로 기록됩니다:
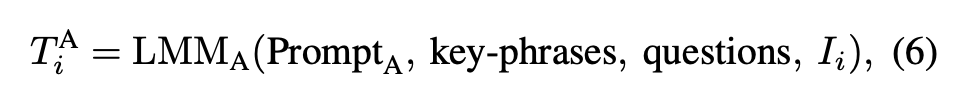
답변 과정에서는 단순한 yes/no가 아니라 문맥을 담은 설명을 만들도록 유도하며, 답이 모호한 경우에는 Uncertain으로 처리해 잘못된 정보가 반영되지 않도록 하였다고 합니다.
마지막으로 VISA는 일반 설명 T_i^{GD}과 QA 기반 세부 설명 T_i^{A}을 이어 붙여 최종 텍스트 표현 T_i을 구성합니다. 이렇게 만들어진 묘사는 쿼리와 granularity가 맞춰진 형태가 되어, 이후 텍스트 기반 재정렬 단계(Eq. 2, 3)에서 훨씬 안정적인 검색 성능을 제공할 수 있었다고 하네요
3. Experiment
3.1 Short-context Image Retrieval
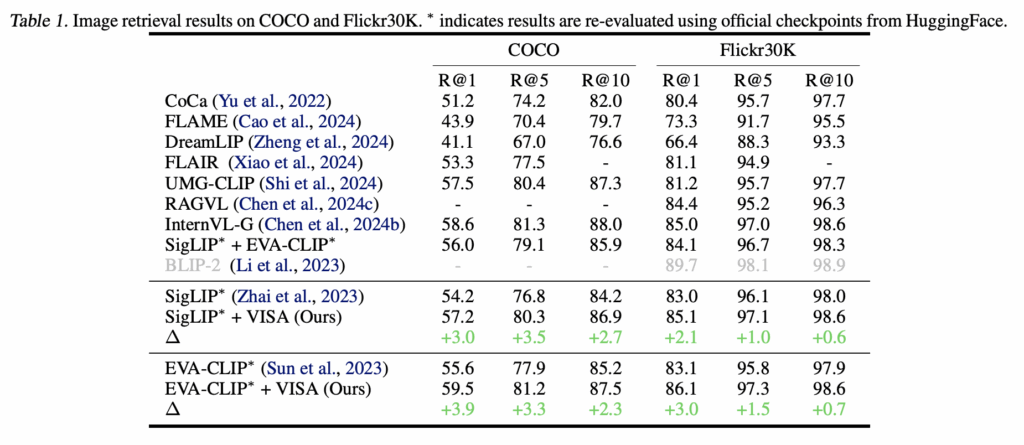
저자들은 MS-COCO와 Flickr30K에서 VISA를 평가했으며, 기존 VLM(SigLIP, EVA-CLIP)에 VISA를 단순히 덧붙이는 것만으로도 R@1 기준 COCO는 최대 3.9, Flickr30K는 최대 1.5의 성능 향상을 보였습니다. 이는 파라미터 수가 훨씬 큰 VLM을 단독으로 사용하는 것보다 더 높은 성능으로, VISA의 Abstraction이 단순 모델 확장보다 효과적이라는 점을 보여주는 결과라고 할 수 있습니다.
또한 DreamLIP, FLAIR처럼 설명문을 생성하는 방식이나, RAGVL·FLAME처럼 LLM을 fine-tuning하거나 distill하는 기존 재정렬 기법보다도 높은 성능을 달성하였는데요, 이는 대규모 모델을 새로 학습하지 않고도, 테스트 시점에서의 텍스트 기반 재정렬만으로 충분히 엄청난 개선을 보일 수 있음을 실험을 통해 확인했습니다.
3.2 Short-Context Video Retrieval
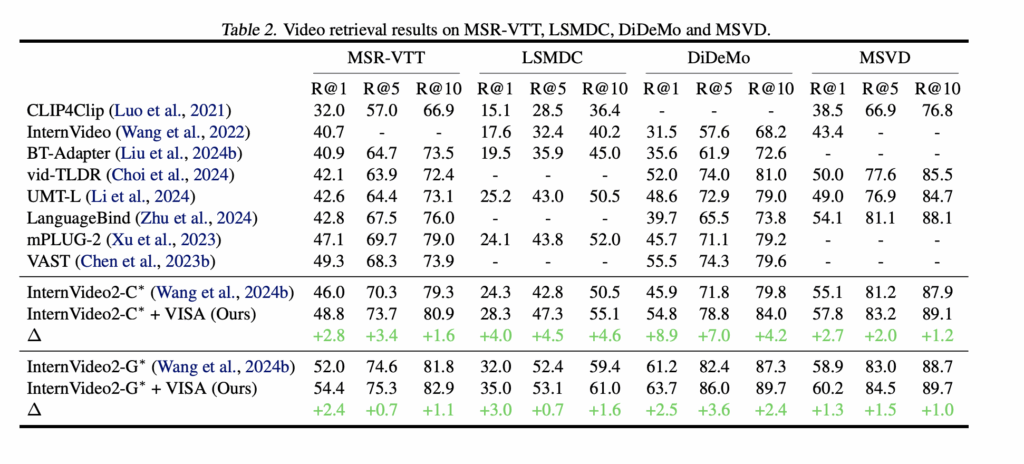
저자들은 네 가지 대표 비디오 리트리벌 데이터셋(MSR-VTT, DiDeMo, LSMDC, MSVD)에서 VISA를 평가했습니다.
VISA는 InternVideo2-C(dual-stream)와 InternVideo2-G(single-hybrid) 두 가지 기반 모델 모두에서 일관된 R@1 향상을 보였습니다. 예를 들어 InternVideo2-C에서는 MSR-VTT 46.0→48.8%, LSMDC 24.3→28.3%, DiDeMo 45.9→54.8%로 상승하며, 특히 DiDeMo에서 8.9%라는 큰 성능 향상을 보였고, InternVideo2-G에서도 모든 데이터셋에서 고르게 성능이 향상되었죠
전체적으로 VISA는 단순히 이미지가 아닌 비디오에서도 강력한 효과를 보이며, 서로 다른 구조의 비디오-언어 모델 모두에서 성능을 끌어올릴 수 있는 범용적이고 안정적인 플러그-앤-플레이 기법임을 확인한 결과라고 하네요.
3.3 Long-Context Video Retrieva
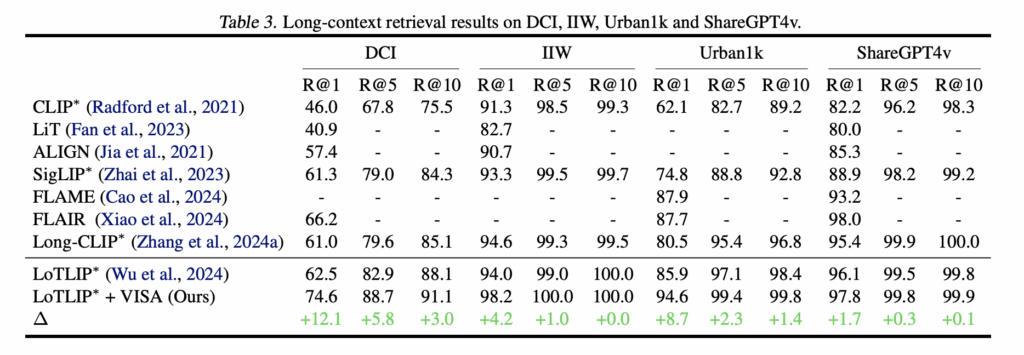
긴 context를 가진 쿼리에서도 세밀한 정보까지 처리할 수 있는지를 확인하기 위해, 네 가지 데이터셋(DCI, IIW, Urban1k, ShareGPT4v)에 대한 성능 평가도 수행하였습니다. 이 데이터셋들은 평균적으로 170토큰 이상의 descriptions부터 객체/위치/관계에 대한 라벨링이 있는 Urban1k까지, 다양한 granularity를 요구한다는 점이 특징이라고 하네요
베이스라인으로 LoTLIP을 사용했고, VISA를 결합했을 때 모든 데이터셋에서 R@1 성능이 크게 향상되었습니다. 특히 DCI에서 62.5% → 74.6%(+12.1%), Urban1k에서 85.9% → 94.6%(+8.7%)로 성능이 향상되며, 복잡한 장면 서술이나 긴 문장의 핵심 요소를 안정적으로 포착한다는 점을 보여주었습니다. 물론 IIW(+4.2%), ShareGPT4v(+1.7%)에서도 성능 개선이 있었죠.
정리하면, VISA는 기존 long-context 전용 모델보다도 안정적인 성능을 제공하는 것을 확인하였습니다. 이는 언어 기반 추상화가 장면을 구조적으로 정리해주는 효과 덕분이며, VISA의 범용성과 강인함을 뚜렷하게 보여주는 결과라고 할 수 있다고 하네요
3.4 Analysis Experiment
VISA 프레임워크의 일반화 성능과 각 구성 요소의 영향력을 확인하기 위해 네 가지 분석 실험도 확인해보겠습니다
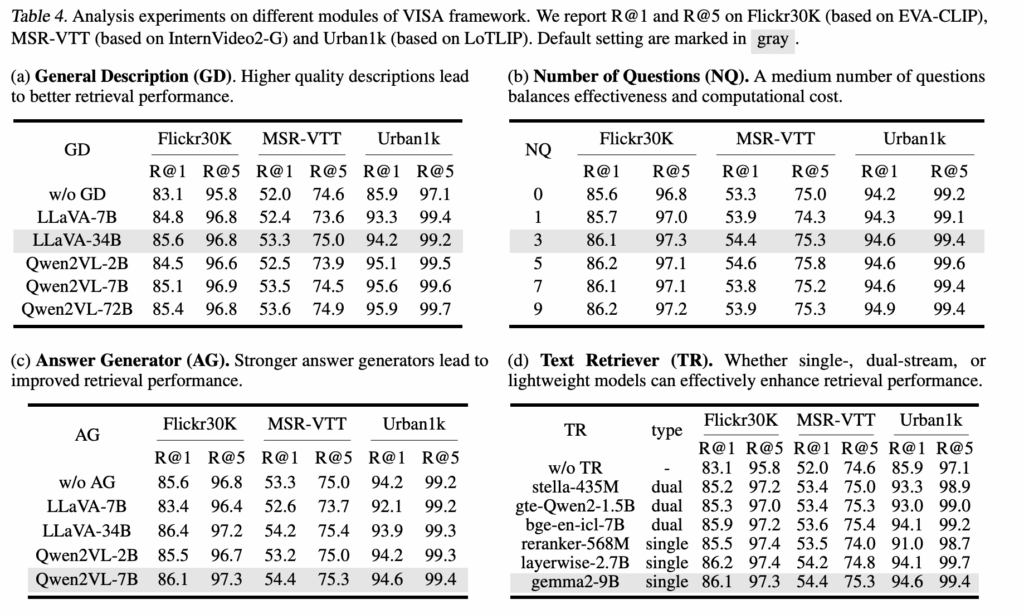
(a) General Description (GD)
텍스트 설명을 생성하는 LMM의 품질이 높을수록 검색 성능도 함께 향상했습니다. 작은 모델(LLaVA-7B, Qwen2VL-2B)도 이미 의미 있는 성능 향상이 있었고, 모델 규모가 커질수록 더 풍부하고 정확한 설명을 생성해 검색 성능이 지속적으로 높아졌습니다.
(b) Number of Questions (NQ)
영상에 대해 LMM에게 묻는 질문 수를 달리해 실험한 결과, 3~5개의 질문이 가장 좋은 성능과 효율성 사이 최적이었다고 합니다. 질문 수가 너무 많아지면(특히 MSR-VTT) 중복된 질문이 늘어 오히려 성능이 떨어졌습니다.
(c) Answer Generator (AG)
질문에 대한 답변을 생성하는 LMM의 성능도 검색 결과에 직접적인 영향을 미쳤습니다. 대형 모델이 당연하게도 더 좋은 성능을 보였고, 특히 Qwen2VL-7B가 LLaVA-34B와 비슷한 성능을 보여 효율성과 정확성의 균형이 좋았다고 하네요. 이때, Qwen 모델이 불확실한 정보는 배제하고 중요한 내용만 유지하는 능력이 뛰어나기 때문이라고 합니다
(d) Text Retriever (TR)
텍스트 검색기(retriever)는 single-stream, dual-stream, lightweight 모두 VISA의 성능 향상에 기여하였습니다. Dual-stream이 문장 결합 효과로 가장 높은 성능을 보였지만, 크기가 작은 retriever조차도 일관된 성능 향상을 보여 VISA가 다양한 크기와 구조의 모델과 잘 결합된다는 점을 확인했습니다.
4. Summary
본 논문은 Text-to-Visual Retrieval 태스크로, 기존 VLM 기반 Retrieval이 텍스트–비주얼 정렬 능력은 우수하지만 세밀한 장면 표현 부족, 긴 문맥을 처리하지 못함, 단순 캡션 기반의 낮은 정보 밀도 등의 한계를 갖는다는 점을 지적했습니다. 이를 해결하기 위해 저자들은 VISA(Visual Abstraction)라는 프레임워크를 제안했습니다. VISA는 장면을 더 풍부하고 구조적으로 요약하는 시각적 추상화 텍스트(Visual Abstraction Caption)를 생성해 retrieval 성능을 올리는 방식이었습니다. 특히, 시각적 정보를 바탕으로 텍스트로 만들어 텍스트-텍스트 검색을 활용하였다는 점이 인상적이었습니다.
안녕하세요 리뷰 잘 봤습니다.
한가지 질문이 있는데, 리뷰 내용 중에 “즉, 먼저 기존 VLM으로 top-k 후보 G_{top-k}를 뽑고, 그 다음 각 후보 이미지를 자연어 설명 T_{i} 으로 바꿔 다시 텍스트-텍스트 매칭을 수행합니다.” 라는 부분에서 후보 이미지에 대한 자연어 설명은 이미 annotation으로 함께 제공이 되어있는 상태인가요? 아니면 captioning 모델이 추가로 필요한 상황인가요?
그리고 Text-Text 매칭은 결국 이미지 매칭을 통해 계산된 top-k 후보군 내에서 진행이 되는데 제 생각엔 text-text 매칭이 더 빠르고 효율적일 것 같아서요. Text-Text 매칭을 top-k가 아닌 전체에 대해서 매칭하였을 때 TVR 성능은 없을까요? 또는 Text-Text 매칭을 먼저 해서 뽑은 top-k에 대해 기존 이미지 매칭을 하는 방식에 대한 실험등도 없는지 궁금합니다.
댓글 감사합니다.
해당 부분을 조금 더 명확히 설명드리면,
1. 후보 이미지에 대한 자연어 설명은 annotation으로 주어지는 것이 아니라, VISA가 테스트 단계에서 captioning을 통해 새로 생성하는 것입니다. 논문에서는 LLaVA, Qwen-VL 등 off-the-shelf LMM을 활용해 입력 이미지를 문장으로 변환하고 있으며, 별도의 annotation이나 추가 학습 데이터는 사용하지 않습니다. 이 “시각→텍스트 변환”이 VISA의 핵심 모듈 중 하나입니다.
2. Text–Text 매칭을 전체 갤러리에 대해 수행하는 실험은 논문에서 수행하지 않았습니다. 대신 코드 구조상 의도는 “VLM의 coarse ranking → 텍스트 재정렬로 fine correction”이며, text-only retrieval을 standalone 방식으로 쓰는 것이 목표는 아닙니다. 즉, 텍스트 매칭이 빠르고 효율적이라는 장점을 인정하면서도, 저자 관점에서는 VLM의 글로벌 의미 정렬을 baseline 신호로 유지한 상태에서 fine-grained 보정을 추가하는 방향이 더 실용적이라고 본 것으로 보입니다.
3. Text–Text 매칭을 먼저 수행하고, 그 top-k에 대해 이미지 기반 유사도를 다시 적용하는 역순 구조 또한 실험되지 않았습니다. 저자의 의도는 “VLM 기반 검색을 완전히 대체하는 것”이 아니라, “추가 학습 없이 플러그인처럼 성능을 끌어올리는 test-time 모듈”에 가깝다고 할 수 있을 것 같습니다. 따라서 retrieval 파이프라인을 뒤집는 경우까지는 실험 범위에 포함되지 않았습니다.
안녕하세요 주영님 좋은 글 감사합니다.
이해한 파이프라인이 질문 쿼리에 대해 가장 유사한 이미지 top k 개 기존 VLM으로 뽑고, 해당 질문 쿼리의 세부 속성들로 QA 질문들을 만들어 해당 질문들에 대한 설명들을 General Description에 더해 최종 텍스트 표현으로 만들며, 마지막에 top k 중에서 최종 1개의 이미지를 고르는거로 이해했습니다. 읽다가 궁금한 점이 있는데, 쿼리와 동일한 granularity를 유지하는 기준이 어떻게 측정되거나 설정되었는지 궁금합니다. LLM에 지시문으로 넣어주는 형태로 구현이되는건가요? 또한 최종 성능이 General Description 대비 QA 기반 설명이 차지하는 비중에 다소 민감해 보이는데, 이 비율 조절이 실험적으로 설정된 것인지, 혹은 모델이 자동적으로 학습 하는 것인지도 궁금합니다.
감사합니다.
좋은 질문 감사합니다. VISA에서 쿼리와 동일한 granularity를 유지하는 기준은 별도의 metric으로 정량적으로 측정되는 방식은 아니며, LLM 프롬프트 설계로 유도하는 방식에 가깝습니다. 논문에서 사용하는 질문 생성 단계는 쿼리 문장에서 핵심 객체·속성·행동을 추출하도록 지시한 뒤, “이미지의 세부 요소를 명확히 식별할 수 있는 방식으로 질문을 생성하라”라는 형태로 제약을 걸어 granularity mismatch를 방지하죠. 즉, granularity alignment는 모델이 자동으로 학습하는 과정이 아니라 프롬프트 기반의 규칙적 제어라고 이해하는 게 가장 가깝습니다.
또한 General Description과 QA 기반 설명의 비중을 어떻게 반영할지에 대해서도 학습을 통해 자동 결정되는 방식은 아닙니다. 최종 retrieval 점수는 두 설명에서 계산된 텍스트-텍스트 유사도를 단순 합산하는 방식이며, 비중 조절을 위한 가중치 튜닝이나 자동 학습 모듈은 포함되어 있지 않습니다. 다만 Ablation 결과를 보면 QA 기반 설명을 제거할 경우 성능 하락이 뚜렷해, GD로 전반적인 의미를 형성하고 QA로 세부 granularity를 맞추는 두 단계가 서로 보완 관계라는 점을 확인할 수 있습니다.
안녕하세요 주영님 좋은 리뷰 감사합니다.
본 방법론을 사용해서 Retrieval을 사용하면 자연스럽게 검색 속도가 증가할 것 같은데, 속도에 대한 실험도 따로 있는지 궁금합니다.
그리고 VISA의 핵심은 이미지를 자연어로 바꿔주어 이를 가지고 retrieval을 하는데 결국 LLM이 얼마나 정확하게 묘사를 하느냐에 큰 영향을 받을 것 같습니다.
본 논문에서는 LLM이 생성한 묘사에 대한 평가도 따로 하나요?
마지막으로 VISA가 이미지를 텍스트로 아무리 자세히 묘사한다고 해도 fine-grained 정보가 삭제되거나 축약될 가능성이 있어보입니다. 그래서 제 생각에는 Visual 정보도 함께 고려하면 더 높은 정확성을 달성할 수 있을 것 같은데, 이 부분에 대한 주영님의 의견이 궁금합니다.
좋은 질문 감사합니다.
1. VISA를 적용하면 추가적인 LMM 호출이 필요하기 때문에 검색 속도 오버헤드는 당연히 존재합니다. 논문에서도 이를 인지하고 있는지, Appendix에서 처리 시간 비교를 제시해 두었습니다. 다만 VISA는 전체 데이터셋에 대해 텍스트 생성과 매칭을 수행하는 것이 아니라, 기존 VLM으로 top-k를 먼저 좁힌 뒤 그 후보에 한해 Visual Abstraction을 적용하기 때문에 속도 증가폭을 실용적인 수준으로 이를 억제하고 있습니다.
2. 또한 LMM이 생성한 description의 품질이 retrieval 성능에 영향을 줄 수 있다는 점도 논문에서 언급됩니다. LLM/LMM을 사용한 연구라면 당연히 따라오는 질문이 아닐까 싶은데요, 이 부분은 별도의 정량적 caption 평가 실험을 수행하지는 않았지만, hallucination을 줄이기 위한 설계로 불확실한 경우 “Uncertain”으로 답하도록 제한하고, QA 기반 보강을 통해 핵심 속성을 명시적으로 확인하는 방식으로 안정성을 확보하려 했다는 설명이 있습니다.
3. 마지막으로 fine-grained 정보의 손실 가능성에 대해서는 동의합니다만, VISA의 주장이 “텍스트만으로 완벽하다”라기보다는, 텍스트 재정렬이 기존 VLM의 한계를 보완하는 추가 신호로 유효하다는 방향에 가깝다고 할 수 있을 것 같습니다. 비주얼 특징과 텍스트 추상화를 결합한 방식이 향후 더 높은 upper-bound을 보일 수 있다는 점에는 저도 가능성이 높다고 생각합니다.