이번에 읽을 해당 논문은 현우님과 같이 연구할 주제에서 baseline 이 되는 논문입니다. 현우님이 기존에 x-review를 작성하셨지만, 해당 논문으로부터 연구를 진행해야할 만큼 제대로 한번 읽어보는 것이 중요할 것 같았고, 어느 부분에서 어떤 내용을 적으면 좋을지, 기존 연구에서의 contribution 이 어느정도인지 알고자 읽어보게 되었습니다.
Abstract
AVQA 과제는 다양한 시각적 물체, 소리, 그리고 그들관의 관계를 비디오 내에서 파악하고 질문에 답할 수 있는 능력을 다룹니다. 보통 멀티모달 정보를 담고 있는 비디오는 복잡하고 풍부한 정보를 담고 있는데, 그 정보중 일부분만이 질문에 연관된 정보입니다. 어찌보면 당연한 말이지만 이러한 상황에서 원하는 질문에 해당하는 오디오-비주얼 정보를 얻는 것이 올바른 대답을 위해 필수적이라고 합니다.
저자는 TSPM 이라는 Temporal-Spatial Perception Model 을 제안하고 이 모델의 목표는 질문에 관련이 있는 오디오 비주얼 인지하는 것이라고 합니다. 특히 사전학습된 visual-language 모델을 사용하여 non-declarative questions 를 visual representations 들과 같은 semantic space로 정렬하는 행위가 어렵다는 것을 알기 때문에 질문 template 으로부터 declarative sentence 프롬프트를 얻어서 사용한다고 합니다. 이렇게 되면 질문과 중요하게 연관된 부분을 찾기 쉬워진다고 하며 to assist the temporal perception module 이라고 표현합니다.
우선 저자가 제안하는 Temproal 적 내용이 먼저 나와서 이야기를 간단히 하고 넘어가자면 보통 AVQA 에서 사용하는 질문 템플릿이 의무문에 어떤 행위나 악기, 시점, 등을 물어보는 형식으로 이루어져 있습니다. 다만 CLIP 같은 대규모 언어모델을 사전학습할때는 이미지와 그에 해당하는 캡션이 보통 세상을 설명하는 description 형태로 되어있어 모델이 저런 질문형, 의무문형 문장을 보게되면 마치 OOD 를 보는 것 같은 효과를 가지게 되는 것입니다. 또한 의무문 문장에서는 보통 object subject verb 의 관계가 명시적이지 않습니다. 예를 들어 질문의 형태가 “what is the man doing?” 이었을때 언어 인코더 입장에서 시제, 순서, 이벤트 구조 등을 이해하기 어렵지만 평서문 단위로 바꿔서 “The man is playing the guitar”, “The violin plays last.” 등과 같이 바꾸면 subject-verb-object 구조가 명시적으로 보입니다. 평가를 진행할때는 정답에 해당하는 guitar 와 같은 부분을 [mask] 처럼 표현하여 event slot 으로 활용하면 되기 때문에 모델이 이해하기 쉬운 표현으로 바꾸는 행위가 모델의 temporal alignment 를 맞출 수 있다는 점으로 의무문 → 평서문 변환을 contribution 으로 풀어나간 것입니다.
그리고 spatial perception module 은 visual 토큰들을 merge 하는 형태로 구현되었다고 합니다. 병합되는 부분들은 audio 에서의 정보를 토대로 sound-aware 인 지역들을 골랐다고 언급합니다. 결과적으로 temporal-spatial cues 들이 질문에 대답하기 좋은 형태로 묶이게 되고 이는 정량적 성능으로 입증했다고 하며 Absract 를 마칩니다.
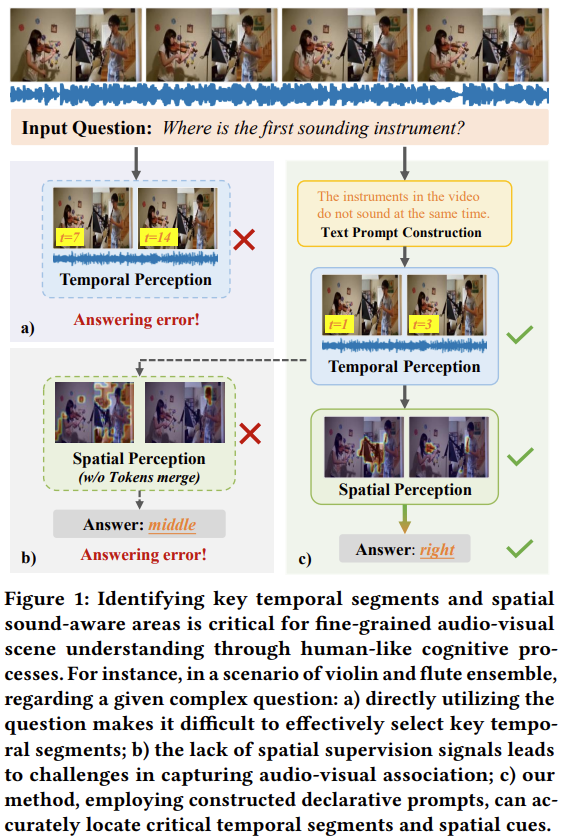
다음은 저자가 제안한 방법론에서 시간적 인지(Temporal Perception)와 공간적 인지(Spatial Perception)가 각각 어떻게 의도한대로 작동하는지, 없다면 어떻게 될지에 대한 figure 입니다. Input Question 으로 “where is the first sounding instrument?” 라는 질문이 들어왔을때, 기존 방식대로 작동하면 각각 a) 와 b) 부분에서 시간적, 공간적 정보를 놓쳐 틀린 답을 대답하게 되지만 저자의 방식을 적용했을때 올바른 대답을 보여주는 그림입니다. 저자의 방법론이 무엇인지에 대해서는 이후 더 구체적으로 설명을 드리겠습니다.
Introduction
우리의 실생활에서 오디오와 비디오의 청각적, 시각적 정보들이 서로 상호 복합적으로 정보를 주어 어떠한 상황을 인지하거나 이해하는데 도움을 준다고 합니다. 예를 들어 위험한 산길에서 운전을 하고있다고 생각할때 커브길에서 경적을 울리면서 지나가면 마주오는 상대편이 시각적으로 우리를 인지하지 못했더라도 경적 소리를 듣고 위험을 미리 감지할 수도 있습니다.
저자가 제안하는 AVQA 라는 태스크가 있기 이전 sound source localization, video parsing, segmentation, question answering, 등등이 연구가 되었고 특히 이제는 AVQA에도 관심이 생기고 있다고 합니다. 저자가 제안한 논문 컨셉 이전의 연구들에는 2가지 개선해야할 부분이 있다고 하는데, 각각 Temporal perception 과 Spatial perception 으로 나누어서 설명을 하게 됩니다.
우선 시간적 측면에서 기존 방법론들이 uniform sampling 을 통해 너무 많은 정보를 좀 정제하고, 컴퓨팅 코스트를 좀 제어하게 됐던게 너무 단순한 방법이며, 특정 방법론들은 CLIP 에서 나온 질문표현과 프레임의 유사도를 계산하여 프레임들을 골랐었는데 거기에 사용된 질문들이 의무문의 형식이며 이는 CLIP에서 학습된 적 없는 형태인 점을 지적합니다.
공간적 측면에서는 공간에 나타나는 객체와 오디오의 사전 정보들이 존재하지 않아 모델로 하여금 비디오내의 어떤 위치가 소리를 내는지 알기 어렵다고 합니다. 어떤 연구에서는 (저자의 이전 연구) ViT를 사용하여 비디오의 프레임들을 토큰단위로 바꾸게 되고 질문과 가장 유사한 토큰들을 선택하여 key target으로 설정하는 방법이 있었지만 이는 패치토큰에 객체의 정보가 들어있지 않아 정확한 위치를 렌더링하는 것이 어렵다고 합니다. 여기서 패치토큰에 왜 객체의 정보가 없지? 라고할 수 있는데 논문에 구체적인 언급이 더 존재하지는 않으나 생각해볼 수 있는 점은 ViT의 토큰 자체가 의무문인 질문을 받았을 때 명시적으로 객체의 정보를 가지고 있지 않아서 object-centric 한 선택이 안되는 것을 지적한 것 같습니다. 따라서 이후 저자는 선택된 프레임 패치들 중에서 Audio 와 관련된 token 들만 남기는 방식으로 object 가 있을법한 위치를 찾게 합니다.
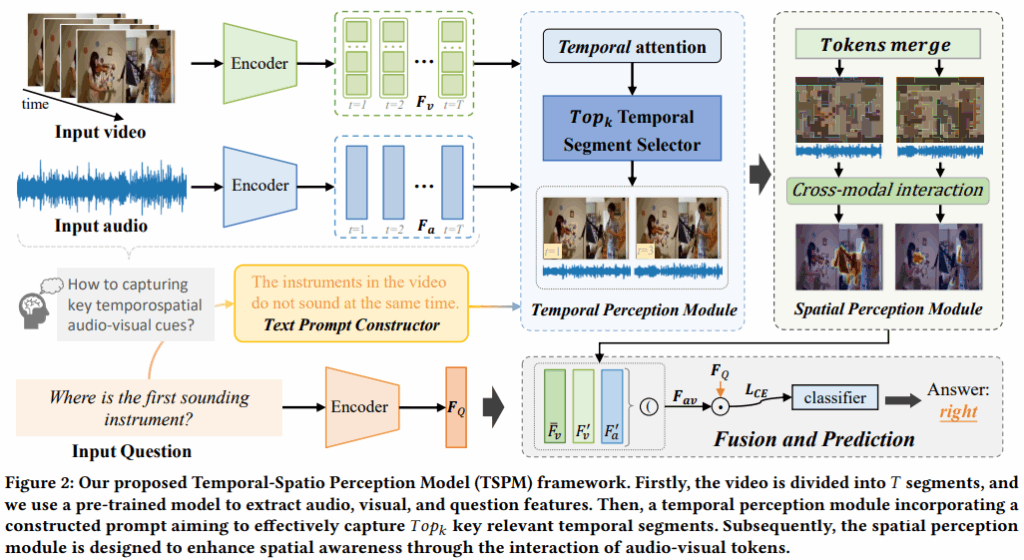
저자는 위의 2가지 문제점을 해결하기 위해서 TSPM 이라는 Model 을 만들게 되고 이는 질문과 관련된 auditorial-visual cues 들을 인지하는 모델이라고 합니다. 해당 모델은 우선 TPC(Text Prompt Constructor) 를 이용하여 의무문 형식의 문장을 설명문 형태로 바꾸어 비디오 프레임들에 효과적으로 align 할 수 있게하고 TPM (Temporal Perception Module) 을 사용하여 질문과 유사한 Temporal 프레임들을 cross-modal attention 을 통해 정하게 됩니다.
마지막으로 SPM (Spatial Perception Module) 을 이용하여 선택된 visual tokens 들을 merge 하고 ( prune 이 아니라 정보를 지킬 수 있는 선택지가 있음) merge 된 토큰들을 audio 정보와 attention 하여 sound-aware 한 지점들을 알 수 있게 했다고 합니다.
저자의 contribution 은 다음으로 요약할 수 있습니다.
- 질문을 서술문 형태로 변환하여 질문 의미를 시각 프레임과 더 정확히 정렬합니다. 이를 통해 질문과 관련된 핵심 시간 구간을 더 잘 찾아낸다.
- 선택된 핵심 시간 구간에서 중요한 시각 토큰들을 병합해 대상 정보를 보존하고 이후 이미지와 오디오 간 Cross-modal interaction 을 수행하여 소리와 연관된 영역을 효과적으로 포착합니다.
Input Representation
주어진 비디오-음성 정보에서 1초단위의 T개의 segment 로 쪼개고, 각 segment 에서 오디오는 VGGish, 이미지와 질문은 각각 CLIP 에서 임베딩을 뽑아 사용합니다. 각 segment 는 오디오 와 비디오
로 구성됩니다.
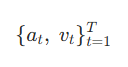
각 프레임은 M 개의 패치로 분할되고, 첫 번째 패치 앞에 [CLS] 토큰이 추간된다고 합니다. 또한 질문 문장 Q는 N개의 단어 토큰으로 분해되어 사용됩니다.
Audio Representation
각 audio segment 는 VGGish 를 통해 D차원 audio feature vector
로 표현하고, 다음과 같이 표현됩니다.
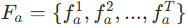
Visual Representation
각 visual segment 는 CLIP을 통해 뽑히게되고 frame-level 과 token-level 의 feature로 각각
로 표현되며 M은 한 프레임의 token 넘버라고 생각하면 됩니다. 최종적으로는 각각 audio Represenatation 처럼 표현됩니다.
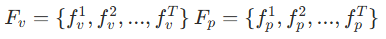
Text Representation
주어진 질문 Q에 대해 각 단어 은 비디오와 마찬가지로 사전학습된 CLIP에 들어가 질문 feature
로 표현됩니다.
Temporal perception Module (TPM)
저자는 질문과 가장 시간적으로 유사한 TopK segments들을 고르기 위해 TPM 이라는 모듈을 사용하게 됩니다. 앞서 언급했듯이 저자가 의무문인 문장들이 질문과 유사한 프레임들을 고르기 어렵게한다는 점을 토대로 TPM의 key 포인트는 의무문인 문장들을 설명문의 declarative sentence로 바꾸고 중요한 시간 구간을 식별하도록 돕는 데에 있습니다. 이를 달성하기 위해 우선적으로 입력 질문을 기반으로 서술문을 생성하기 위한 Text Prompt Constructor (TPC) 를 고안하였습니다. TPC 의 각 과정은 다음과 같이 진행되었습니다.
- 구성 가이드라인: 입력 질문에는 답이 포함되어 있지 않기 때문에, 이것을 직접 서술문으로 변환하는 것은 어렵습니다. 따라서 저자는 질문과 관련 없는 구간을 제외하고 질문과 관련된 시간적 내용을 향해 모델의 주의를 유도하게끔 문장을 설계했다고 합니다.
- 구성 과정: 질문 템플릿을 기반으로 가이드라인을 따르는 서술문 템플릿을 수작업으로 구성하였다고 합니다. ( 수작업인 점이 약간 아쉽긴 하다만, 정해진 템플릿에 따른 수작업이라 완전히 무분별한 규칙은 아닙니다.) 이러한 템플릿은 여러 기여자들과의 논의를 통해 그 타당성을 보장하도록 최적화했다고 언급합니다.
- 구성 결과: FIg.2 의 예시에서 볼 수 있듯이, 입력 질문이 “where is the first sounding instrument?” 일 때, 목적은 첫 번째 악기가 연주되기 시작하는 순간을 식별하는 것입니다. 비디오 속 아기들이 동시에 연주되지 않고 순차적으로 연주되기 때문에 저자는 모델의 주의를 악기들이 동시에 연주되지 않는 비디오의 구간으로 유도하기 위해서 해당 문장을 TPC를 활용하여 다음과 같은 서술문으로 변환합니다. “ The instruments in the video do not sound at the same time” 이를 TPrompt 라고하며 이는 비디오의 의미적 내용과 특징 표현이 잘 정렬되게 됩니다. 이를 통해 TPrompt와 관련된 구간을 찾아내고 이후 질문과 관련된 시간 구간을 찾아낼 수 있게 됩니다.
저자는 주어진 서술문 TPrompt 를 주어진 질문과 같은 인코더를 사용하여 feature 임베딩을 뽑게 되고 하나의 linear projection layer인 key(·) 를 통해 기존 비디오 feature 였던 를 k 로 인덱싱합니다. 아래의 수식을 통해 attention 가중치를 구하게 됩니다.
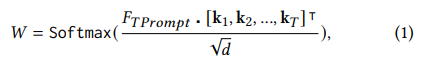
여기서 k_j = Key(F_v^j), j ∈ {1, 2, …, T}, d 는 key 벡터의 차원입니다. 높은 weight 는 비디오 내용과 TPrompt 간의 강한 상관성을 나타내기 때문에, 저자는 T 개의 시간 구간 중 TopK feature를 고릅니다. 구체적으로 정렬 알고리즘을 기반으로 구현된 시간 선택 연산자 $\psi$ 를 사용해 가장 높은 attention weight 를 가진 중요한 구간을 선택합니다.
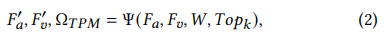
여기서 ψ 는 선택연산자로 은 Topk 의 가장 높은 weight에 해당하는 인덱스 위치.
,
는 선택된 시간적 feature로
,
로 표현됩니다.
Spatial Perception Module (SPM)
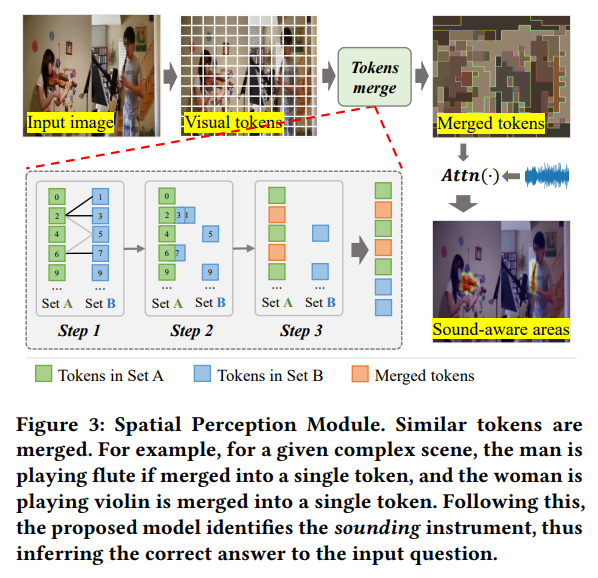
저자는 핵심 악기와 관련된 시각적 영역을 식별하기 위해 SPM 을 설계하였습니다. 간단하게 얘기하자면 선택된 시간 구간 내에서 시각 토큰들을 유사도 기반으로 병합하여 그들의 의미를 보존하는 설계입니다. 기존 연구가 질문과 시각 토큰 간의 의미 유사도를 기반으로 중요한 영역을 식별하려 했지만 이들 토큰 내 객체에 대한 의미 정보가 부족해 소리와의 효과적인 상관 관계를 구축하기 어려웠다고 합니다. 이를 해결하기 위해서 저자는 선택된 핵심 시간 구간을 시각 토큰들의 의미 정보를 더 잘 보존하도록 강화했다고 하며 유사한 토큰들을 각 프레임 내에서 병합함으로써 객체에 대한 더 풍부한 의미 정보를 갖는 병합 토큰이 생성되게 했습니다.
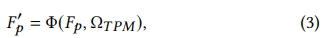
여기서 즉 Topk 개의 frame 들의 M 개의 패치의 임베딩으로 표현됩니다. 저자는 ToMe 라는 방법론에서 영감을 받아 트랜스포머 블록의 어텐션 브랜치와 MLP 브랜치 사이에서 token-merging 전략을 적용했다고 합니다.

합쳐진 후의 표기는 이렇습니다.
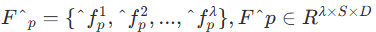
여기서 는 선택된 temporal segments 이고 S 는 합쳐진 토큰 번호입니다.
정확히는 Fig. 3 에서
- M 개의 토큰을 A와 B의 두 subset 으로 분할합니다.
- A의 각 토큰들과 B의 각 토큰들 간 similarity 를 계산하고
- 유사 토큰끼리 mean fusion 을 진행합니다.
- 두 subset을 concat하여 병합된 토큰을 생성합니다.
결과적으로 소리와 시각적 공간적 연관성을 고려해 선택된 병합 토큰과 오디오 특징 사이의 cross-modal attention 을 수행합니다. 정규화된 형태의 feature는 다음과 같습니다.
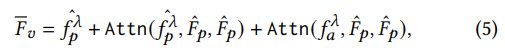
Multimodal Fusion and Answer Prediction
AVQA 작업을 달성하기 위해서 TPM과 SPM 에서 얻은 시각 특징 ,
와 오디오 특징
를 연결합니다. 시각-오디오 결합 특징
는 선형층 FC 를 통해 얻게됩니다.
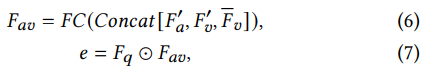
오디오-비주얼 결합이 효과적인지 검증하기 위해서 질문특징 와
를 element wise 곱을 하여 통합하게 됩니다. softmax를 거쳐 후보 정답에 대한 확률 P 를 출력하고 Cross entropy loss는 다음과 같습니다.
위의 과정이 결과적으로 최종 42개에 해당하는 정답들중 질문과 가장 유사한 feature가 오디오 정보, 비디오 정보, 오디오-비디오 융합정보 중 어느 모달리티가 가장 잘 반영하는지 모델이 스스로 결정하게 되는 구조라고 생각하면 좋을 것 같습니다.
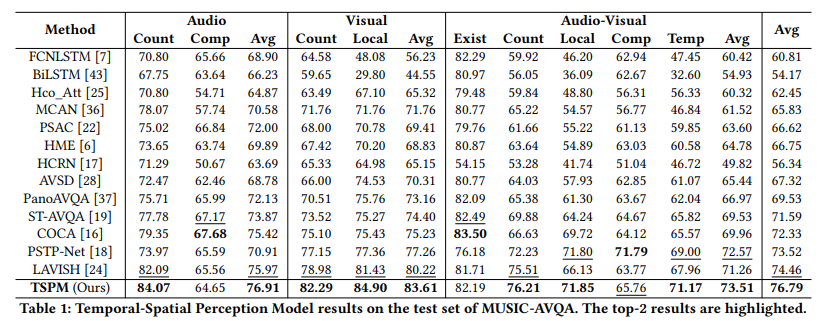
MUSICV-AVQA 데이터셋에 대하여 저자의 방법론이 해당 시점에서 SOTA 를 달성한 모습을 확인할 수 있습니다. 저자가 제안한 구성에 의해 Local 에대한 성능이 높을 것이라 생각할 수 있고 단일 모달보다 Visual 이나 Audio-Visual 정확도가 상대적으로 많이 증가한 모습입니다.
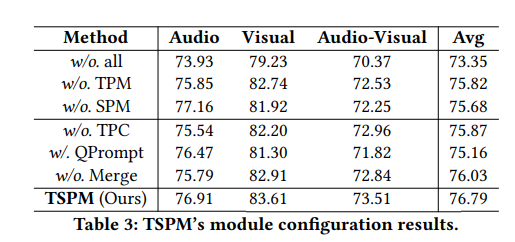
저자의 방법론에서 각 모듈의 ablation입니다. 의무문 → 설명문 변환은 1.6퍼센트정도의 성능이 떨어지는 것이 가장 큰 성능 드랍임을 확인할 수 있습니다. 또한 TPM 과 SPM 이 각각 원본정보량에서 필요한 정보만 잘 추려내게 되어 성능이 증가함도 알 수 있습니다. 사용하는 정보량이 적어지는 만큼 사실 성능이 크게 증가하지 않을 수 있는 부분인데 그만큼 정답을 추리는 데에 중요한 부분들을 잘 골랐을 수도 있고, 중복적인 frame이 많이 존재해서 그럴 수도 있겠다는 생각을 했습니다.
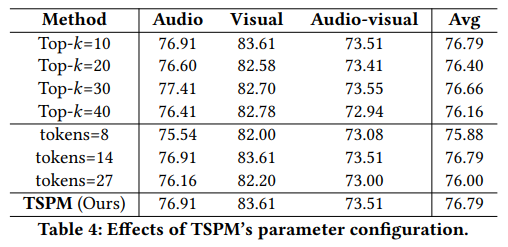
해당 Table 에서 효과적인 Topk 개수와 merge된 token 수를 알 수 있으며 영상이 1분이라는 것을 감안했을때 정보를 1/6으로 줄이고 CLIP ViT-B/32 기준 224입력의 패치토튼 49개를 14개로 1/3개 정도 사용하는 것이 효과적임을 알 수 있습니다.
Conclusion
저자는 저자의 제안 방법론이 질문과 관련된 시간 구간을 정확히 찾고 그 시간대에서 소리와 관련된 공간적 영역까지 정밀하게 인식할 수 있도록 설계했다고 합니다. 결과로 보여주는 것들이 어느정도 타당한 실험설계인 것 같고 오디오-비주얼 질의응답 상황에서의 이유 있는 추론을 가능하게 하는 모델 구조라고 생각합니다. 여기서 의무문을 설명문으로 바꾸는 프레임워크가 생각보다 성능을 많이 올려주지만 구성하는 방식이 너무 나이브하고 해당 데이터셋에 수작업으로 한 만큼 범용성이 떨어져 조금 아쉽다고 생각합니다. 감사합니다.
안녕하세요 신인택 연구원님 좋은 리뷰 감사합니다.
CLIP에서 학습하지 않은 형태로 입력하는 것은 큰 성능 향상을 기대하기 어렵다는 언급이 있었는데 질문의 형태를 평서문으로 변환하여 입력하더라고 CLIP의 일반적인 학습 프롬프트와는 형태가 다를 것 같다는 생각이 듭니다. 완전히 같지는 않더라고 기존 질문의 형태보다는 더 비슷한 형태로 바꿔주는건가요? 일반적으로 오디오랑 비디오랑 align이 되어있지 않아서 cross-attention만으로는 오디오 특징을 정확하게 반영하지 못할수도 있을 것 같은데 비디오와 오디오가 align이 잘 되어있는 인코더를 사용하는 건가요? 또, 크로스 엔트로피 손실함수 외에 또 사용하는 손실함수가 있는지 궁금합니다.
감사합니다.
안녕하세요 성준님 답글 감사합니다.
우선 질문의 형태를 바꾸어주는 형태가 생각보다 성능 향상에 큰 기여를 해서 유의미한 분석이라고 생각하기는 합니다. 물론 의무문- >평서문으로 바꾼거로 이해한다기보다 temporal 축에서 질문에 더대답하기 쉬운 형식의 text 로 변환해서 그게 가능했다는 맥락으로 이해하는게 더 올바를 것 같습니다. 그리고 비디오와 오디오가 잘 align 되어있는 인코더를 사용하는 것은 아니고 pretrained 된 단일/멀티 모달 임베더들을 사용해서 뽑아낸 다음 사용합니다. 손실함수로는 크로스 엔트로피 함수만 사용하며 이는 정해진 템플릿 내에서 답변할 수 있는 정답이 42개로 정해져 있어서 가능합니다.
감사합니다.
안녕하세요 인택님! 좋은 리뷰 감사합니다.
간단한 질문 하나만 드리고자 하는데, TPC가 질문 템플릿을 수동으로 구성하는 방식이 정해진 템플릿 내에서는 상관없겠지만, 새로운 비정형 질문들이 들어왔을 때는 일반화 성능에 영향을 미치지 않을까 생각하는데, 논문에서 템플릿 구성을 자동화하고자 했던 부분이 있었는지 궁금합니다..!
안녕하세요 재윤님 답글 감사합니다.
새로운 비정형 질문들이 들어오면 해당 task 는 당연히 성능이 떨어지기도 할 것이고 저자가 구상한 의무문 -> 설명문 형태의 텍스트 변환은 불가능할 것 같습니다.. 사전에 정의된 템플릿에 대해서만 변환하는 공식을 만들어뒀다고 생각하면 될 것 같습니다.
감사합니다.
안녕하세요 인택님, 좋은 리뷰 감사드립니다.
TPM에서 attention score 기반으로 Top-K segment를 선택하는 과정과 관련해 궁금한 점이 있어 댓글드립니다.
리뷰에 제시해주신 Top-K 실험 테이블을 보았을 때 개인적으로는 K 값이 달라져도 전체적인 성능 차이가 크게 나타나지 않는 것으로 보였습니다. 그렇다보니 저자가 혹시 Top-K 선택에 대한 보다 자세한 분석을 논문에서 별도로 진행했는지가 궁금합니다. 잘은 모르지만 일반적으로 K가 너무 작으면 중요한 temporal cue를 놓칠 가능성이 있고 반대로 K가 너무 크면 불필요한 정보가 포함되어 오히려 noise가 증가할 수 있을 것 같은데 논문에 제시된 표만으로는 이러한 trade-off를 저자가 어떻게 해석했는지가 궁금합니다.
감사합니다!
안녕하세요 우현님 답글 감사합니다.
top k 방식의 프레임 셀렉션의 trade-off 를 저자가 해석한 내용은 구체적으로 존재하지는 않습니다. 다만 결과적으로 해석하기 나름이고 데이터셋이나 해당 task에 따라 다를 것 같습니다. token pruning 관점에서 모든 정보를 이용하는 것보다 적은 token 을 사용하면 성능이 보통 하락하는 것처럼 비디오의 프레임을 줄일수록 중요한 정보가 소실될 확률도 높아질 것입니다. 영상의 형태에 따라 다르겠지만 반복되는 프레임이 너무 많으면 정보의 redundancy가 높고 이런 경우라면 정보를 압축하는 방식이 성능을 오히려 올려줄 수도 있는 것입니다. MUSIC-AVQA 데이터셋은 모든 영상을 60프레임으로 사용했고 장면 전환이 보통 한번에서 많게는 두번 세번정도 존재하는 것으로 아는데, top k 방식같은 경우는 데이터셋과 task 에 어느정도 영향을 받을 수치라고 생각이 듭니다.
감사합니다.