안녕하세요 이번에 리뷰할 논문은 2023년도에 CoRL에 게재된 ViNT: A Foundation Model for Visual Navigation이라는 논문입니다. 저저번에 리뷰했던 GNM: A General Navigation Model to Drive Any Robot 논문에 이어서 같은 연구진들의 후속 연구라고 이해하시면 좋을 것 같습니다.
앞선 GNM이 서로 다른 로봇 간 데이터 통합을 통한 범용적인 내비게이션 정책 학습에 초점을 맞췄다면 이번 ViNT는 그 개념을 한 단계 확장하여 Transformer 기반의 범용 로봇 파운데이션 모델을 제안하는 논문입니다. 결국 특정 로봇이나 환경에 종속되지 않고 여러 로봇과 다양한 실제 환경에서 제로샷으로 동작할 수 있는 모델을 목표로 하는 연구라고 생각하시면 좋을 것 같습니다.
바로 리뷰 시작하도록 하겠습니다.
Introduction
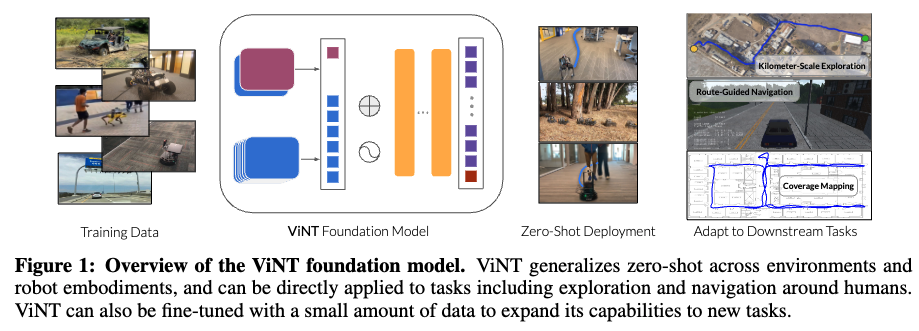
일단 논문 서두에서 저자는 최근 로보틱스 연구에서 자주 등장하는 파운데이션 모델의 개념을 로봇 분야에 어떻게 적용할 것인가라는 질문을 던집니다.
NLP나 Vision 분야에서의 범용적으로 쓰이는 모델처럼, 마찬가지로 로봇 분야에서도 어떤 범용적인 로봇 모델을 학습시켜 다양한 태스크에 제로샷 또는 파인튜닝으로 잘 활용될 수 있을지가 중요하게 생각하는 문제의식인 것 같슴니다.
저자들은 이런 관점에서 로봇 파운데이션 모델을 명확히 정의하고 있는데, 두 가지 조건이 핵심입니다.
첫째는 제로샷으로 완전히 새로운 환경과 로봇에서도 즉시 동작 가능한 사전학습된 모델이어야 하고,
두번쨰는 다운스트림 태스크에서 즉, 목적지 지정 방식(이미지 기반, 좌표기반, 명령어 기반 같은..)이나 행동의 형태들이 다른 새로운 과제에도 손쉽게 적응할 수 있어야 한다는 점입니다.
저자들은 이 두 가지를 모두 만족시키는 모델이 진정한 범용 로봇 파운데이션 모델이라고 정의합니다.
저자들이 초점을 맞춘 영역은 비전 기반 내비게이션쪽으로 이 문제를 해결하려고 합니다. 즉 Visual Navigation을 파운데이션 모델의 테스트 베드로 삼은 것닙니다. 그 이유가 visual navigation이 로봇이 오직 자신의 1인칭 시점 카메라 영상만을 입력으로 받아 목표 지점으로 이동해야 하는 문제로 센서나 환경이 달라져도 시각적 단서만으로 행동을 결정해야 하므로 일반화 능력 을 검증하기에 매우 좋은 태스크이기 때문이라고 합니다. 예를 들어 좌표 기반의 GPS 내비게이션 혹은 semantic 정보를 활용하는 방식들과 비교해보면 이 방식은 정확한 위치 정보가 필요 없고, 의미적 라벨(semantic 정보)이나 지도 정보도 필요하지 않습니다. 단순히 비디오 데이터 + 액션 정보만 있으면 학습이 가능합니다. 그래서 큰 비용없이 특정 로봇이나 환경에 종속되지 않고 여러 로봇의 데이터셋을 함께 사용해 학습할 수 있다는 점이 큰 장점입니다.
그리고 저자들은 단순히 특정 로봇이나 특정 환경에 특화된 모델을 만드는 것이 아니라 다양한 환경, 다양한 로봇다양한 태스크 들대해 공통적으로 동작하는 single policy를 만드는 것을 목표로 합니다.
이 점이 기존 연구들과는 뚜렷하게 구분되는 부분이라고 볼 수 있습니다. 특히 저번에 리뷰했던 GNM 같은 경우는 다양한 로봇이나 다양한 환경에 대해 공통적으로 동작하는 single policy를 제안을 하긴 하였지만 이 친구는 단일 태스크(목표가 이미지로 주어져야만 처리 가능)에 국한된 모델이라는 점이 한계였습니다. 물론 당연히 로봇의 형태나 로봇이 가지는 센서, 그리고 로봇이 동작하는 환경 등이 다르기 때문에 지금 까지의 연구는 데이터 측면으로나 학습 측면으로나 당연히 특정 로봇이나 특정환경에 특화된 모델을 만들 수 밖에 없었겠지만요.. 그래서 이를 위해 제안된 것이 바로 ViNT입니다. ViNT는 현재 이미지에서 목표 이미지로 이동하는 방법을 학습하고 이 방식은 별도의 지도나 좌표 정보 없어도 대부분의 이동 로봇 데이터셋에 적용 가능하도록 학습이 이루어집니다. 또한 ViNT는 단순히 학습된 policy에만 그치지 않고 Diffusion 모델을 이용해 새로운 단기 목표(subgoals) 를 스스로 생성하는 탐색 모듈을 포함합니다. 결과적으로 이 diffusion 모델 덕분에 SPTM과 다르게 사람이 수동으로 새로운 환경에 대한 탐색 정보를 주지 않고도 스스로가 탐색하면서는 이전에 본 적 없는 환경에서도 목표에 도달 할 수 있게 되는데, 해당 내용에 대해서는 이후 method 파트에서 자세하게 다뤄드리도록 하겠습니다. 다시 돌아와서 이 diffusion 모델을 활용하는 이 부분은 GNM과의 가장 큰 차별점 중 하나인데 GNM이 단순히 이미지 목표 도달에만 초점을 맞췄다면, ViNT는 탐색자체를 학습에 포함시킨다는 점에서 훨씬 확장된 구조라고 볼 수 있습니다.
지금까지 ViNT의 핵심이 되는 부분을 간단하게 설명드렸는데 이후 Method 파트에서는 ViNT가 학습이 어떻게 되고 실제로 동작은 어떻게 하는지 다양한 스크림 태스크로의 전이는 어떻게 되는지 등등을 자세하게 다루도록하겠습니다.
Method
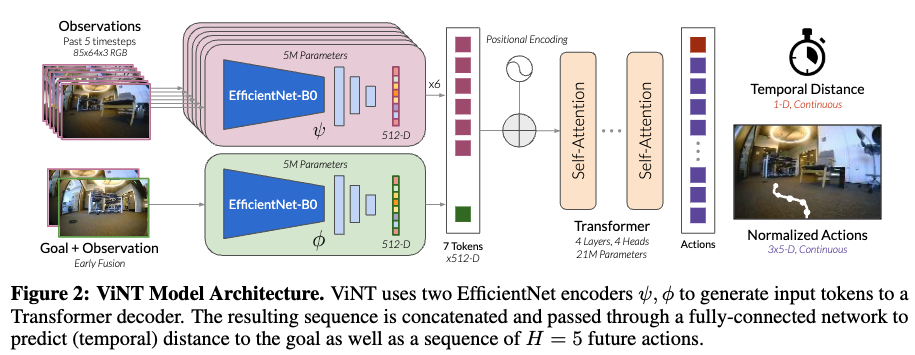
Train
일단 ViNT 모델의 입력은 크게 두 가지입니다.
- 현재 및 과거의 관찰 이미지 o_{t−P:t}
- 목표 이미지(subgoal) o_s
출력은 두 가지 형태로 나오는데 1) 목표까지 남은 시간(step)인 거리랑 2)목표로 이동하기 위한 행동 시퀀스 입니다. ViNT는 얼마나 더 가야 하는지랑 어떻게 가야 하는지 를 동시에 예측하는 모델이라고 보시면 됩니다.
그 다음 모델의 구조에 대해서 설명을 드리면 먼저 ViNT는 Transformer 기반 구조로 되어 있습니다.
입력 이미지들은 모두 트랜스포머에 들어가기 전에 어떤 임베딩 벡터로 변환되어는데 이때 앞단의EfficientNet-B0을 태우고 나온 값이 트랜스포머의 input으로 들어가게 됩니다.
Observations(ψ(o)t:t−P )
먼저 앞단의 obsevations 부분에 대해서 설명을 드리면 현재 시점과 5개의 과거 시점 이미지(P=5)를 각각 EfficientNet-B0로 개별적으로 인코딩합니다. EfficientNet의 마지막 convolution layer에서 추출된 feature map을 flatten하고 이를 하나의 토큰으로 압축합니다. 그래서 총 6(1+5)개의 512차원의 토큰이 생기게 되고 이것이 트랜스포머의 인풋으로 들어간다고 보시면 됩니다.
Goal + Observation( ϕ(ot, os))
그 다음 Goal + observation 부분에 대해서 설명드리면 저자는 처음에는 단순히 목표 이미지만을EfficientNet 인코더에 넣어 특징을 추출했지만 모델이 목표를 거의 무시하는 현상이 나타났다고 합니다. 그래서 저자들은 목표의 절대적 정보보다는 현재와 목표 간의 상대적인 정보가 중요하다는 가설을 세웁니다. 그래서 최종적으로 현재 관찰(oₜ)과 목표(oₛ)를 함께 입력으로 넣는 방식으로 설계를 합니다.
이 과정에서는 두 이미지를 채널 축으로 으로 컨캣하고 앞서 observation 부분과 동일하게 두 번째 EfficientNet-B0 인코더를 통과시켜 Goal Token을 생성합니다.
이제 앞서 생성된 (P+1+1)개의 토큰 즉, 과거 P개 + 현재 1개 + 목표 1개 를 Transformer의 입력으로 넣어주게 됩니다. (여기서 트랜스포머는 decoder-only구조를 사용합니다)
이제 학습과정을 좀더 자세하게 설명 드리도록하겠습니다.
먼저 학습데이터 같은 경우네는 하나의 trajectory 집합을 샘플링 하고 이후 P개의 연속된 관찰을 샘플링해서 o_{t−P:t}을 만들고 이에 해당하는 미래 시점의 관찰(o_s = o_{t+d})을 랜덤하게 뽑아 subgoal 로 사용합니다. 이때 사용되는 GT는 (1) 미래 행동 시퀀스(step H) â = a_{t:t+H} 와 (2) 거리 d (step) 입니다. (이때 d 는 구간 [l_min, l_max] 에서 랜덤하게 샘플링됨) 이 때 궁금하실 수 있는 부분이 H랑 d랑 같은건가? 라는 생각이 드실 수 있는데 둘이 다른 값입니다. 예를 들어 subgoal이 20 step뒤라면 그에 해당하는 모든 20step의 액션값을 다 학습에 사용하지 않습니다. 왜냐면 한번의 예측으로 20step동안 뭘 해야할지 결정하도록 학습이 이루어질 텐데 실제 환경에서는 20step같이 조금 긴 장기 예측은 불확실성이 크기 때문입니다. 그래서 5step(H-step)과 같은 단기 계획을 반복적으로 갱신하는 구조로 학습하기 위해서 d와는 다른 값으로 설정한 것으로 이해하면 좋을 것 같습니다. 다시 정리하면 실제 실행시 짧은 구간(H-step)을 안정적으로 계획하고 반복적으로 갱신하기 위해서 각기 다른 값으로 설정하여 데이터 셋을 생성하고 결과적으로 ViNT는 항상 H step 분량의 행동만 예측하고 그 행동들이 다양한 거리의 subgoal (d \in [l_min, l_max])을 향하도록 학습이 이루어진다고 보시면 될 것 같습니다.
결과적으로 데이터 쌍은 [/latex] (o_{t:t−P}, o_s, \hat{a}_{t:t+H}, d)[/latex] 이렇게 구성이 됩니다.
그리고 GNM리뷰에서도 설명드렸지만 액션 값은 low level의 제어 신호는 아니고 로봇의 현재 위치를 기준으로 다음에 어디로 가야하는가를 좌표 형태로 표현한 값을 액션 값으로 정의 합니다. ViNT는 로봇별로 다른 속도 제어 명령대신 현재 위치를 기준으로 다음에 이동해야 할 상대적 위치(Δx, Δy)를 액션 으로 정의했다고 보시면 됩니다.(그리고 로봇마다 속도나 크기가 다르기 때문에 이 좌표 값은 각 로봇의 최대 속도에 맞게 정규화가 이뤄짐.) 이렇게 하면 모든 로봇에서 동일한 의미의 액션을 사용하는 것이니깐 하나의 공통 policy로 학습이 가능해집니다. 그래서 결국 ViNT는 단지 어디로 가야 하는가만 예측하고 실제 어떻게 갈 것인가(제어)는 각 로봇의 제어기가 로봇의 특성에 맞게끔 제어하도록 담당합니다.
Loss 수식은 아래와 같습니다.
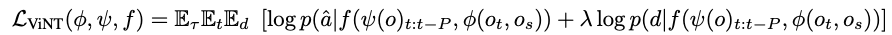
결국 ψ(o)_{t:t−P} 이 observations 를 나타내는 부분이고 ϕ(o_t, o_s) 이것이 goal+observation의 부분을 보여주는 것이고 여기서 나온 벡터들을 f(트랜스포머 디코더)에 태우는 방식으로 동작합니다. 그리고 여기서 λ는 두 손실(행동 예측과 거리 예측)의 비중을 조절하는 하이퍼파라미터입니다.
앞에서 학습데이터에 대한 설명을 빠트렸는데 설명을 드리고 넘어가자면, ViNT는 100시간 이상의 실제 내비게이션 trajectory 데이터(다양한 위치에서의)로 학습되었고 총 8종의 로봇 플랫폼에서 수집된 데이터가 사용되었다고 합니다.
이제 ViNT는 SPTM과 마찬가지로 액션, 거리 값을 예측할 수 있도록 모델을 학습을 시켜놨는데 ViNT는 현재 시점에서 단기 subgoal 까지 가는 정책만을 학습했기 때문에 장거리 내비게이션을 수행 할 수 없습니다. 따라서 마찬가지로 Topology Graph를 활용하게 됩니다. 이 그래프는 SPTM과 다르게 목표 수행과 동시에 생성이 이루어집니다. 현재 목표 수행 과정중 관찰이나, subgoal들을 노드로 생성하고 각 노드간 다른 노드로 도달 가능하다고 예측이 되면 엣지연결(shortcut)을 연결하는 방식으로 그래프 생성이 점진적으로 이루어집니다.
이제 서두에 잠깐 언급한 Diffusion Model의 역할에 대해서 자세하게 설명드리도록 하겠습니다.
학습이 아닌 실제 운용 단계에서 ViNT는 목표 이미지가 있어야 움직일 수 있는데 이때 운용되는 환경에서는 어디로 갈지 모르니 subgoal이 없게 됩니다. 그래서 이때 실제 목표 수행시 diffusion 모델을 활용해서 현재 관찰 o_t 를 조건으로 미래에 존재할 법한 장면 후보(subgoal 후보)를 여러 개 생성합니다.
학습은 ViNT의 주행 데이터(trajectory)로 이루어지고 각 궤적에서 랜덤하게 선택된 미래 관찰(o_{t+d})을 GT로 사용하여 학습이 이루어집니다. Diffusion 모델은 이런 식으로 현재를 입력하면, 앞으로 몇 스텝 뒤에 볼 수 있을 법한 이미지를 생성하도록 학습됩니다.
근데 이 diffusion이 생성한 여러 후보의 subgoal들이 있을 텐데 ViNT는 이 각 후보들에 대해서 얼마나 실제 최종 목표 G와 가까운지를 평가해서 하나만을 골라야합니다.
이를 위해서 휴리스틱하게 선택하도록 함수를 설계를 하는데 이 함수는 현재 관찰(o_t)에서 특정 subgoal(o_s^i)로 갔을 때, 그 경로가 최종 목표(G)에 얼마나 가까운지를 점수화합니다.
휴리스틱 함수는 두 가지 방식으로 구현될 수 있습니다.
1.단순히 로봇과 목표 간의 유클리드 거리 기반 2. 학습기반 (이 때는 추가적인 위성 영상 같은 컨텍스트 정보를 활용해 학습하여 실제로 subgoal 선택 퀄리티를 높일 수 있다고 합니다.)
그리고 이 휴리스틱 함수와 더불어 추가적으로 앞서 학습시킨 d를 예측하는 모델도 활용해서 아래 처럼 종합적인 비용함수를 생성하고 이 비용이 가장 낮은 subgoal을 선택을 하게 됩니다.
- s: 새로 평가 중인 서브골(subgoal)
- s^-: 해당 서브골의 부모 노드(before subgoal)
- o_t: 현재 로봇 상태(현재 관찰 이미지)
- G: 장기 목표(long-horizon goal)
- C: 추가적인 문맥(context, ex> 위성 지도 등- 학습기반이면 사용O 아니면 사용 X)
위 수식같은 경우 논문의 appendix에 자세하게 설명이 되어있으나 궁금하실 수 있으실거 같아 간단하게 언급하고 넘어가도록 하겠습니다.
여기서 말하는 부모노드, 자식 노드의 개념이 헷갈리실 수 있는데 이 둘에 대해서 설명을 하고 넘어가자면 로봇이 새로운 환경을 탐색하면서 이동할 때 현재 시점에서 도달 가능한 후보 지점(subgoal)들을 diffusion 모델이 생성하게 되는데 이 subgoal들이 자식 노드이고, 부모노드는 그 이전의 subgoal 이라고 이해하시면 좋을 것 같습니다. 결국 자식 노드는 새로 제안된 subgoal 후보(탐색 방향의 다음 위치 후보들)인 것이고 부모노드는 이미 방문했던 subgoal(그래프 상에 등록된 기존 노드) 이거나 혹은 현재 상태일 수 있는 것입니다. 그래서 d_M(o_t, s^-) 이 항이 작다는 것은 지금 내가 그래프 상의 기준 노드(부모 노드) 근처에 잘 도착했구나 라는 것이 되는 것입니다.
그리고 두 번째 항 d_{pred}(s^-, s) 부모 노드로부터 새로 평가 중인 subgoal 후보들 자식노드까지 이동하는 데 필요한 예상 step 수를 의미합니다. 마지막으로 h(s, G, C) 해당 subgoal이 최종 목표 G 방향으로 얼마나 효율적으로 진전할 수 있는지를 나타내는 휴리스틱항이라고 이해하시면 좋을 것 같습니다. 이 친구는 단순히 유클리드 거리로 정의될 수도 있고 학습 기반 접근에서는 위성영상이나 지도 정보 등 문맥(C, Context)를 입력으로 활용해서 어떤 subgoal이 실제로 목표에 도달하기 좋은 선택인지를 학습적으로 점수화할 수도 있습니다. 이 휴리스틱항에 대해서는 논문에서 제안한 방법론은 아니기 때문에 자세한 내용은 이 방법론을 제안한 논문을 참고해야할 것 같습니다.
결국 이 3가지 항의 합이 제일 작은 서브골이 다음에 움직여서 가야할 최종 서브골로 선택이 이루어집니다.
Deployment
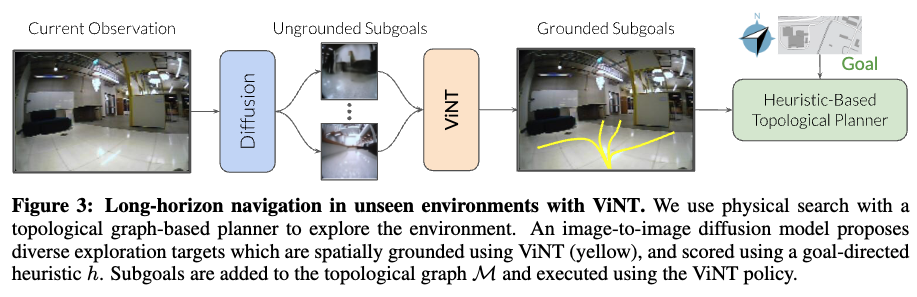
ViNT가 새로운 환경에서 동작할 때는 다음 순서로 진행이 됩니다.
- Diffusion 모델이 현재 관찰 o_t로부터 서브골 후보 집합 S를 생성
- 각 후보들 중에서 가장 적절한 후보 선택 (f(s)함수 기반)
- 이 서브골을 그래프에 추가하고, ViNT policy로 그 지점까지 주행
이 과정을 반복하면서 로봇은 점점 더 넓은 영역을 커버하면서 원하는 목표 지점까지 자연스럽게 도달 할 수 있게 됩니다.
그리고 ViNT의 또다른 중요한 부분인 다운스트림 태스크에 어떻게 적용이 되는지에 대해서도 설명드리겠습니다.

일단 ViNT는 기본적으로 image goal을 사용하지만 다른 형태로도 쉽게 확장될 수 있습니다.
이게 가능한 이유는 이미지가 아닌 새로운 형태의 modality를 goal token공간(트랜스포머 인풋 이전)으로 매핑하는 작은 신경망을 학습함으로써 다양한 입력 형태를 처리할 수 있도록 했기 때문입니다.
따라서, 만약 새로운 형태의 subgoal 예를 들어 2D 좌표나 command(지시어)같은 새로운 모달리티가 주어지면 작은 신경망 \tilde{ϕ}을 새로운 형태의 subgoal 새롭게 학습시킨 다음에 기존 ViNT 구조에서
원래의 goal 인코더 ϕ(o_t, o_s) 대신 \tilde{ϕ}(σ)로 대체시킴으로써 새로운 태스크에 대해서도 수행이 가능하게 됩니다. 그래서 ViNT를 새로운 모달리티에 맞게 파인튜닝 할 때,
온태스크 데이터셋 D_F 를 사용하여 아래의 수정된 목적함수로 학습이 이루어집니다.
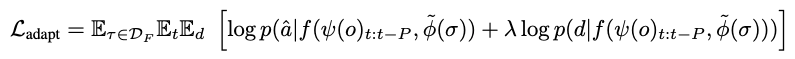
이 식은 원래 ViNT의 학습 목적(Eq.1)과 동일하지만 목표 인코딩 부분만 새 모달리티 입력 \tilde{ϕ}(σ) 로 대체된 형태라고 보시면 될 것 같습니다. 결과적으로 새로운 입력 형태(ex> 좌표, 언어 명령, 방향 지시 등)에 ViNT를 빠르게 adaptation 할 수 있게 됩니다.
Experiments
드디어 실험 부분입니다.
저자들은 ViNT를 서로 다른 종류의 로봇 플랫폼에 배포하여, 로봇 형태나 환경이 달라져도 하나의 모델이 그대로 작동할 수 있는지를 검증했습니다. 그리고 각 로봇의 센서나 제어기 설정을 통일하거나 전혀 보정하지 않은 채 모델을 그대로 적용하여 평가를 진행합니다.
일단 저자는 4가지 질문에 대한 답을 얻을 수 있는 실험을 진행합니다.
Q1. ViNT는 이전에 한 번도 본 적 없는 새로운 환경을 효과적으로 탐색할 수 있는가
Q2. ViNT는 새로운 로봇에 대해 일반화할 수 있는가?
Q3. ViNT는 분포 밖(ood) 환경에서도 파인튜닝을 통해 성능을 향상시킬 수 있는가?
Q4. ViNT 정책(policy)은 새로운 형태의 task나 데이터 모달리티에 적응할 수 있는가?
Q1. ViNT는 이전에 한 번도 본 적 없는 새로운 환경을 효과적으로 탐색할 수 있는가
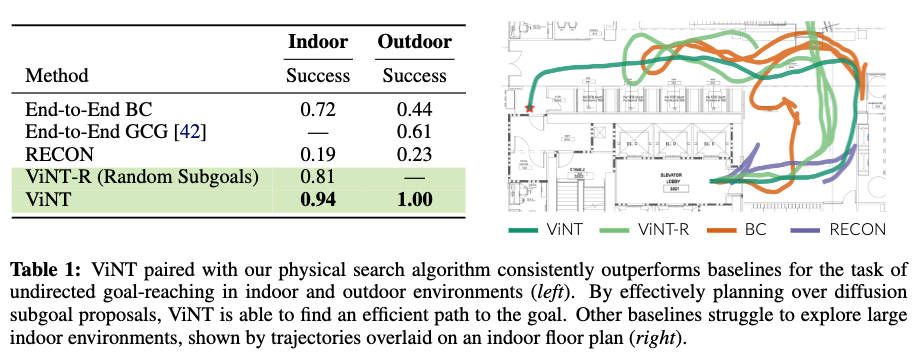
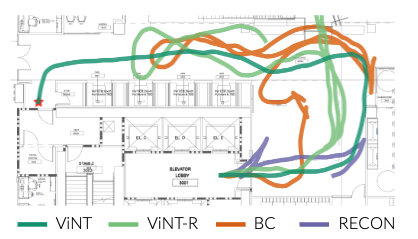
훈련 데이터에 없던 환경에서도 ViNT는 diffusion 기반 subgoal 생성 + 그래프 기반 탐색을 결합해서
기존의 end-to-end 정책 및 SOTA 탐색 모델들보다 훨씬 넓은 탐색 범위, 높은 성공률, 낮은 충돌률을 기록하였습니다. 오른쪽 정성적 결과를 보면 Diffusion 모델이 제안한 다양한 subgoal 후보들을 기반으로 planning하면 보다 효율적인 경로가 형성되는 반면 다른 기준선들은 탐색 과정에서 불필요하게 구불구불한 경로를 택하는 경향이 있는 것을 확인할 수 있습니다.
Q2. ViNT는 새로운 로봇에 대해 일반화할 수 있는가?

위는 사전학습된 ViNT policy를 추가적인 파인튜닝없이 서로 다른 로봇 플랫폼에 직접 배포하여 무방향 탐색과제를 수행시킨 결과를 보인 표입니다.( 무방향 탐색은 목표를 주지 않고 로봇이 알아서 움직이도록 하는 것이고 위 표는 사람의 개입이 들어가기 직전까지 움직인 거리, 얼마나 멀리 이동했는지를 나타낸 것임)
Go 1 같은 사족 보행 로봇 같은 경우에는 훈련데이터에 한번도 등장하지 않은 로봇 데이터임에도 불구하고 성공적으로 이동하는 모습을 보입니다. 기본적으로 ViNT는 단일 로봇 전용 모델이나 GNM보다 높은 최대 이동 거리를 보입니다. 결과적으로 ViNT는 로봇 간 지식 전이가 가능함을 보여주는 것 같습니다.
Q3. ViNT는 분포 밖(ood) 환경에서도 파인튜닝을 통해 성능을 향상시킬 수 있는가?
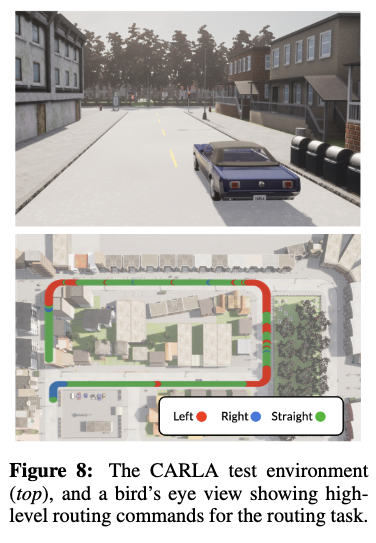

위는 새로운 환경인 CARLA 자율주행 시뮬레이터에서 1~2시간 분량의 데이터만으로 파인튜닝을 진행했습니다. CARLA는 ViNT의 학습 분포와 매우 다른 시각적 특성 혹은 로봇의 다른 움직임(차선 유지, 부드러운 회전)을 갖고 있음에도 불구하고 ViNT는 빠르게 적응하며 높은 성공률을 달성했습니다.
scratch 모델이나 단순 시각 표현 기반 모델에 파인튜닝 한것보다 훨씬 안정적이고 GNM보다도 일반화 성능이 뛰어났습니다. 결과적으로 ViNT가 대규모 사전학습에서 습득한 탐색 사전 지식을 재활용할 수 있는 능력을 갖고 있음을 보여주는 것 같습니다.
Q4. ViNT 정책(policy)은 새로운 형태의 task나 데이터 모달리티에 적응할 수 있는가?
마찬가지로 해당 결과는 Table 3에 있습니다.
ViNT는 단순히 goal 이미지가 아니라 GPS 웨이포인트나 좌/우/직진(commands)같은 다른 형태의 모달리티 표현에도 적응할 수 있음을 보였습니다. 이 실험에서도 ViNT는 ImageNet, VC-1, GNM보다 우수한 성능을 보이는 것을 확인 할 수 있습니다.



마지막으로, ViNT는 학습 과정에서 명시적으로 규칙을 배우지 않았음에도 자발적 행동을 하는 결과를 보입니다. 예를 들어 아무런 의미 없는 subgoal이 주어져도 충돌 없이 탐색하면서실외에서는 도로 중앙, 실내에서는 복도 중앙을 따라 주행하려는 암묵적 주행 습관을 보이는 결과를 나타냅니다. 또한 동적 보행자나 이동 장애물에 대해서도 자연스럽게 회피 행동을 보입니다. fig 11을 보면 로봇이 두명릐 보행자 뒤편에 있는 목표 지점으로 이동해야하는 상황에서 ViNT는 보행자를 회피하는 방향으로 움직였다가 이후 원래 경로로 복귀해서 결국 목표 지점에 도달하는 모습을 보입니다. 그래서 이에 대해 저자가 말하길 ViNT의 대규모 데이터 기반 학습으로 부터 ViNT가 기본적인 안정적 주행 행동들을 내재적으로 학습할 수 있었다고 합니다.
Conclusion
일단 논문의 분량이 꽤 많아 리뷰에 언급 하지 못한 부분이나 되게 간단하게 언급하고 넘어간 부분이 있습니다. 대부분 추가적인 내용은 appendix에 담겨져있는데 이 부분까지 리뷰로 담기에 너무 양이 많아질 것 같아서 중요하다고 생각되는 부분만 리뷰로 작성했습니다..
암튼 결과적으로 ViNT는 훈련에 포함되지 않은 환경과 로봇에서의 제로샷 일반화 능력, 기존 내비게이션 모델보다 높은 탐색 효율성과 성공률,소량 데이터로의 빠른 파인튜닝,그리고 동적 보행자나 장애물 상황에서도 자발적인 충돌 회피 능력을 다 보여 준 것 같다는 생각이 듭니다. 다만 한계도 존재합니다.
ViNT는 아무래도 트랜스포머 기반이기 때문에 소형 드론과 같은 플랫폼에서는 실시간 동작이 어려울 수 있고 LiDAR 등 새로운 센서 모달리티에는 적용하기 쉽지 않다고 합니다.
논문의 제목에는 Foundation Model이라고 되어있지만 아직까지는 Foundation Model 이라고 보기엔 많은 한계가 있는 것 같습니다. 다만 저자는 결국 Foundation Model로의 첫 연구로써 조금 가능성을 보여주기 위해서 저렇게 제목을 짓지 않았나 싶습니다. 그래도 앞으로 더 크고 다양한 다중 로봇 데이터 셋이 나온다면 더 넓은 범위로 일반화 해서 더 좋은 파운데이션 모델로 이어지지 않을 까 싶습니다. ViNT는 다양한 로봇 플랫폼과 과제에 걸쳐 하나의 로봇 policy로 다양한 로봇들을 제어하는 범용 내비게이션 모델의 가능성을 보여주는 의미있는 연구라는 생각이 듭니다.
이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요. 한가지 질문이 있는데, 표3에서 GNM대비 ViNT가 더 좋은 결과를 보여주는 것으로 확인이 됩니다.
이때 두 모델이 같은 데이터셋으로 학습이 된 것 같은데 학습 데이터셋이 어떻게 수집되고 구성되나요? LocoBot부터 재칼까지 4종류의 로봇을 학습 때 사용하지 않았다고 하는데, 그럼 학습 때는 어떠한 로봇 구성으로 진행이 된 것인지 궁금합니다. 그리고 학습 때 보지 못한 로봇 뿐만 아니라 scene 환경 자체도 학습 때 보지 못했는지 아니면 장면은 학습된 것인지도 궁금하네요.
안녕하세요 정민님 댓글 감사합니다.
두 모델이 같은 데이터 셋 기반으로 학습된 것은 맞지만 ViNT는 기존 데이터셋에서 추가적인 플랫폼들의 데이터를 추가로 사용해서 기존보다는 보다 큰 규모의 데이터 셋을 사용했다고 보시면 좋을 것 같습니다. (정확히는 GNM은 6대의 로봇에서 약 60시간정도 규모이고 ViNT는 여기에 추가적인 로봇을 더해서 8가지 로봇 플랫폼으로부터 수집된 100시간 이상의 규모입니다.)이 데이터들은 모두 기존 연구에서 공개된 영상 기반 내비게이션 데이터로 저자들이 새롭게 수집하지 않고 이미 존재하는 공개 데이터셋을 통합하여 사용했다고 보시면 좋을 것 같습니다. 그래서 결과적으로 어떻게 보면 학습 때 활용하지 않은 로봇일 뿐만 아니라 scene 환경 자체도 학습 때 보지 못했다고 볼 수 있습니다. 근데도 표3에서 좋은 결과를 보이는 이유는 새로운 환경에 대한 파인 튜닝을 진행해준 실험 결과이기도 하고 결국 사전학습 시킨 모델은 예를 들어 복도, 사무시르 캠퍼스 오프로드 와 같은 다양한 실제 환경에서 수집된 데이터를 사용해서 학습되었기 때문에 훈련 중 보지 못한 생로운 scene이 대해서도 일반화를 잘 할 수 있지 않았을까 생각합니다.
감사합니다.
안녕하세요 우현님 리뷰 감사합니다.
Visual Navigation에 대한 foundation 모델을 목표로 연구한 논문들을 리뷰해주셨는데, VLM에 의존하지 않는 것 같아서 질문 드립니다. Rgb 데이터 만으로 diffusion이 subgoal을 만들어내는 식으로 이해헀는데, 조금 long horizon이 되거나 unseen 환경에서 작동하는 핵심이 무엇인가요?
안녕하세요 영규님 댓글 감사합니다.
영규님꼐서 말씀해주신 것 처럼 ViNT는 VLM에 의존하지 않고 대신 순수하게 RGB 시각정보만으로 어떻게 움직여야할지를 학습합니다. (다양한 로봇과 환경에서 실제 주행 경험 데이터-100시간 이상으로 부터 이 장면에서는 이렇게 움직여야한다라는 것을 학습하는 구조라고 보시면 좋을 것 같습니다.)
long horizon이 되는이유는 GRaphy memoy(topology map)을 사용했기 때문이고 unseen환경에 대해서 잘 작동하는 이유는 다양한 환경에서 수집된 데이터 기반으로 학습시키면서 Diffusion이 학습된 정보를 바탕으로 내가 보고있는 장면이 이러니 다음 장면은 이래야해 하면서 이미지를 생성하기때문에 Unseen 환경에서도 잘 동작할 수 있는 것 같습니다.(물론 이 diffusion 같은 경우에는 탐색과정에서 사용되는 것입니다.) 이 둘을 복합적으로 생각했을 때 Graph Memory(topology map)를 통해 현재 -> 예측된 subgoal -> 이동(반복) -> 장거리 목표로 이어지는hierarchical한 탐색 구조를 가지기 때문에 실제 이동의 목적은 local 하게 움직이지만 결국 이것이 최종 목적에 다가가기 위해서 생성한 topology map위에서 반복되어서 수행되기 때문에 longhorizon 혹은 unseen환경에서 잘 동작할 수 있지 않을까 싶습니다.
감사합니다.
리뷰 잘 읽었습니다.
Diffusion 모델 관련하여 질문이 있는데, 제가 이해한 바에 의하면 deployment 시 i) diffusion 모델이 현재 관찰로부터 subgoal 집합을 생성, ii) 생성된 subgoal 중 최적 선정, 이런 과정을 거치는듯 합니다.
여기서 질문이,
1. 생성되는 subgoal 이라는 것은 장면 ‘이미지’ 인가, 아니면 ‘경로’ 인가요?
2. 만약 subgoal 이 ‘이미지’ 라면, figure 3에서 질문이 있습니다. diffusion 에 의해 생성된 subgoal images 들이 ViNT 로 들어가서 경로들이 예측되는거 같은데, 만약 diffusion 에 의해 생성된 이미지가 실제 환경이랑 많이 다르게 예측될 경우에는 어떻게 경로들이 예측되게 되나요?
안녕하세요 석준님 좋은 댓글 감사합니다.
Q1. 생성되는 subgoal 이라는 것은 장면 ‘이미지’ 인가, 아니면 ‘경로’ 인가요?
먼저 ViNT에서 Diffusion 모델이 생성하는 subgoal은 이미지 입니다.
여기서 subgoal은 현재 장면으로부터 일정 스텝 뒤에 도달합 법한 시각적인 관찰 정보라고 보시면 됩니다 이거를 생성하게 됩니다. 그래서 경로 자체를 생성하지는 않습니다!
2, 만약 subgoal 이 ‘이미지’ 라면, figure 3에서 질문이 있습니다. diffusion 에 의해 생성된 subgoal images 들이 ViNT 로 들어가서 경로들이 예측되는거 같은데, 만약 diffusion 에 의해 생성된 이미지가 실제 환경이랑 많이 다르게 예측될 경우에는 어떻게 경로들이 예측되게 되나요?
먼저 말씀하신대로 이렇게 생성된 subgoal 이미지는 그대로 ViNT의 입력으로 들어가서 ViNT가 각 subgoal에 대해서 그 subgoal까지 가기 위한 예측 경로(웨이포인트)와 시간적 거리를 예측하여 출력합니다.
하지만 질문 주신 것처럼, 만약 Diffusion이 생성한 이미지가 실제 환경과 엄청 다르게 생성되면 경로 에측이 잘못될 확률이 굉장히 높을 가능성이 높다고 생각합니다. 근데 또 어떻개 보면 큰 문제가 되지 않을 것이라고 생각이 드는게 ViNT가 현재 장면과 subgoal 이미지 간의 상대적 시각적 차이를 이용해서 행동을 예측하기 때문에 사실 subgoal이 완전히 실제 환경의 한 프레임과 일치할 필요는 없고, 현재 장면으로부터 일관성있게 방향을 제시해주면 큰 문제는 없을 것 같다는 생각이 듭니다.
그리고 시각적으로만 생성된 subgoal 이미지라도 물리적으로 도달 가능한 후보인지 f(s)라는 점수로 판별할 수 있기 때문에 결국, diffusion이 만들어낸 subgoal은 시각적 탐색 가이드역할만 한다고 이해하기면 좋을 것 같습니다.
감사합니다.
안녕하세요 우현님, 좋은 리뷰 잘 읽었습니다.
로봇에 무관하게 동작할수 있도록 하고, OOD에서도 잘 동작하는 것을 보아
foundation처럼 만들고자한 저자의 노력이 잘 보인것 같습니다.
궁금한게 있습니다. VINT는 diffusion으로 이미지 생성 과정이 중간에 들어가는데
이미지의 퀄리티에 따라서도 성능 차이가 날것이라고 생각했습니다.
그런데 experiment에 ablation이 없어서, 논문에 관련 내용에 대한 언급이 있었는지 질문드립니다.