이번에 소개드릴 논문은 CVPR2024에 게재된 논문으로 Domain Generalization for Semantic Segmentation 분야입니다.
Intro
Semantic Segmentation은 task 자체가 워낙 label annotation에 비용이 많이 드는 task입니다. 그래서 학습 데이터를 스케일업하는 것도 쉽지 않은데, 겨우 모델을 학습시켜도 모델이 학습 때 보지 못한 도메인에 대해서 성능이 나쁜 경우가 종종 발생합니다. 그래서 Unsupervised Domain Adaptation과 같이 target domain에 대해 manual GT가 없더라도 모델을 학습시키는 방법론들도 예전에 많은 인기를 끌긴 했지만, 해당 방법론은 target domain이 무엇인지 그리고 해당 데이터에 대해 접근 할 수 있다라는 조건이 있어야만 활용 가능합니다.
하지만 대부분의 경우 target domain이 무엇인지 불확실하고, 설령 안다 하더라도 해당 도메인을 재학습할 수 있는 상황이 현실적으로 많지 않습니다. 그래서 source domain data만을 가지고 학습한 모델의 zero-shot 성능을 크게 개선시키기 위한 Domain Generalization 연구도 꾸준히 관심을 받고 있었습니다.
소개드릴 논문 역시 이러한 관점에서 Domain Generalization을 잘하기 위한 방법론이며, 총 4가지 loss function을 제안합니다. 2가지의 loss function은 모델의 encoder에 적용되는 loss로 encoder feature가 domain agnostic한 feature를 추출하도록 학습시키는 목적 함수입니다.
DG 쪽 분야에서 흔히 말하는 domain agnostic은 image의 밝기, 대조, 텍스처, 컬러와 같은 style 정보가 아닌 scene의 structure, 실루엣, shape와 같은 구조적 정보들을 의미합니다. 그래서 encoder가 feature를 추출할 때 이러한 style 정보들을 최대한 배제하고 content 정보들을 위주로 모델링하게 하기 위한 목적 함수들이라고 생각하시면 됩니다.
그리고 나머지 두 loss function은 모델의 decoder에 적용되는 목적 함수로 task 자체가 semantic segmentation이다보니 결국 각 영역들에 대한 클래스를 잘 구분해야하는데 이 부분을 보완하기 위하여 decoder feature의 분별력을 높이는 목적함수를 적용하게 됩니다.
Method
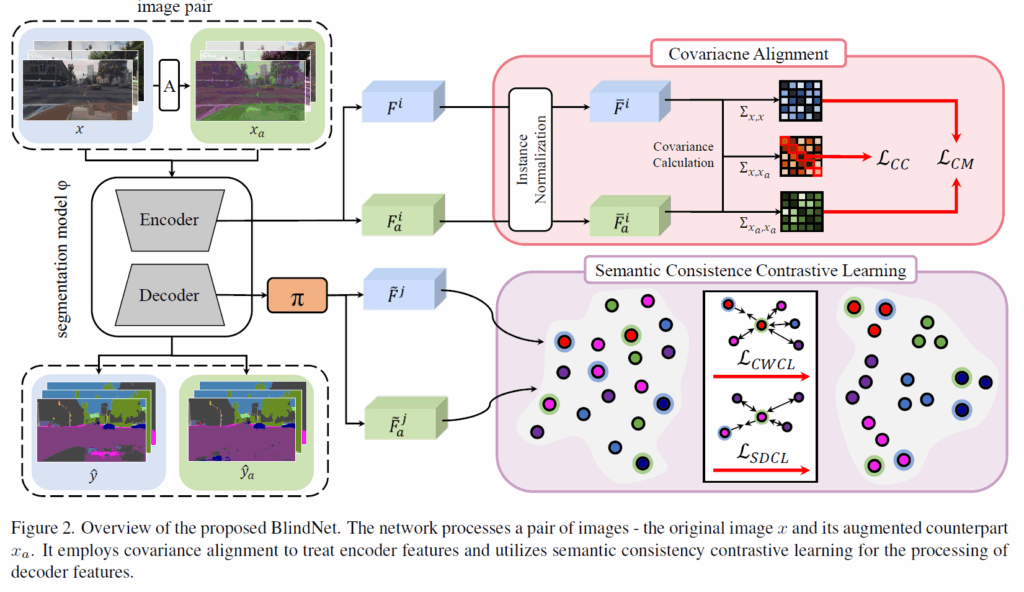
해당 논문의 overall framework은 위의 그림과 같습니다. 앞서 인트로에서 언급했다시피 encoder와 decoder에 각각 2개의 목적 함수가 적용되는 모습입니다. 그럼 우선 encoder의 목적 함수부터 알아보도록 하겠습니다.
Covariance Matching Loss
우선 저자들이 적용한 loss function 중 하나는 CML loss로 Covariance Matching Loss의 약자입니다. 우선 그림2에서도 보셨다시피 입력 영상으로 2가지 종류가 사용되는데 하나는 원본 영상이고, 나머지는 원본 영상에 강한 photometric augmentation을 적용한 것입니다. 그리고 이 두 영상에 대한 encdoer feature를 아래와 같이 정의가능합니다.
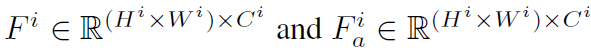
그 다음 해당 feature map에 대해서 instance normalization을 적용한 것을 \bar{F}, \bar{F}_{a} 라고 명칭합니다. 여기서 batch normalization이 아닌 instance normalization을 적용한 이유는 기존의 DGSS 방법론들은 feature map에 instance norm을 적용하면 feature의 style이 어느정도 희석?된다고 생각하였습니다. 정확히는 Instance norm이 style transfer 분야에서 먼저 등장했는데 특징의 각 채널들에 대한 평균과 분산이 해당 영상의 스타일 정보를 대표한다라고 생각했고, 그래서 style을 변환시키기 위해서는 현재 영상의 평균과 분산을 정규화한다음 style 영상의 평균과 분산을 적용하면 된다고 했었죠.
이러한 style transfer 분야의 방식들에 영감을 받아서 DGSS 방법론들은 instance normalization을 shallow feature map에 많이들 적용합니다. 아무튼 instance norm은 아래와 같이 수식으로 표현할 수 있습니다.

여기서 뮤는 평균을 시그마는 표준편차를 의미합니다. 이렇게 정규화된 feature map에 대하여 이제 아래 수식과 같이 공분산 행렬을 계산해줍니다.
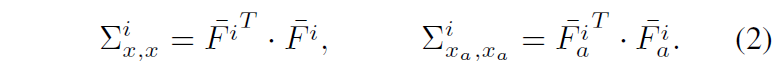
이 공분산 행렬은 자기 자신의 feature map에 대하여 HW축으로 내적을 하기 때문에 최종 결과값은 CxC의 shape을 가지게 됩니다. 즉 self-attention 연산을 할 때 attention score를 계산하기 위하여 CxC축으로 내적을 해 HWxHW의 map을 구하는 것과는 반대의 과정이기도 한거죠.
평균이 0이기 때문에 공분산 행렬이라고도 하고, style transfer 분야에서는 CxC의 행렬을 gram matrix라고도 부릅니다. 이러한 채널축에 대한 관계성을 나타낸 행렬은 HW 축의 공간적 정보들이 다 사라져버리고 채널축끼리의 관계성만 남아있으므로 shape, structure와 같은 content 정보보다는 반복적으로 등장하는 패턴, texture와 같은 style 정보들을 대부분 담고 있다고 보시면 됩니다.
그래서 원본 영상의 feature map의 gram matrix(또는 공분산 행렬)과 augmented feature map의 gram matrix를 서로 같다고 하는 아래 CM loss의 수식은 두 영상의 style이 같아지도록 하는 규제화라고 생각하시면 좋을 듯 합니다.
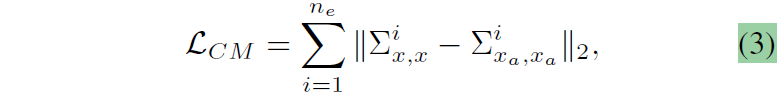
아까 스타일은 텍스처, 컬러, 명도와 대조 등등의 개념이라고 했었는데 augmented image와 오리지널 이미지는 이미 이 스타일을 억지로 다르게 만든 영상입니다. 근데 이들의 gram matrix를 같아지도록 한다라는 것은 모델이 입력으로 들어오는 영상의 style이 어떠하든지 간에 동일한 style을 예측해야한다는 것이고 이는 곧 style-agnostic한 feature를 뽑도록 학습시키는 것으로 생각하시면 됩니다.
Cross-Covariance Loss
앞서 소개드린 CM loss의 경우 자기 자신에 대한 공분산을 계산하여 비교하는 방식이었습니다. 저자들은 자기 자신에 대한 공분산 뿐만 아니라 두 특징(원본과 augmented feature) 사이에 대한 공분산에 대해서도 규제화가 필요하다고 합니다.
그래서 저자들은 수식4와 같이 Cross-Covariance를 계산한 다음, 수식5와 같이 Cross-Covariance Loss를 적용합니다.
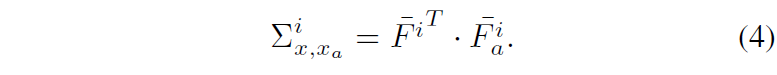
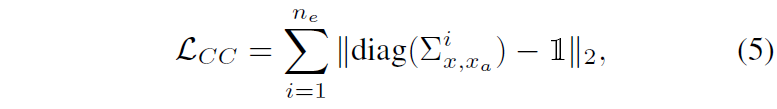
여기서 왜 Cross-Covariance에 대한 대각 행렬 성분을 identity가 되도록 규제화를 하냐에 대해서 간단하게 설명드리면, 기존의 DGSS 방법론들 중에서 Feature Whitening 방식을 통하여 style 정보를 제거하려는 연구가 유행했었습니다.
그래서 gram matrix에 대하여 learnable한 방식으로 feature whitening을 하기 위해 대각 성분은 1, 비대각성분은 0으로 규제화를 했었죠. 이상적으로 gram matrix가 content 정보는 완전히 배제한 체 style 정보만을 다 담고 있었더라면 이러한 규제화를 적용하였을 때 모델이 domain agnostic한 정보를 잘 추출할 수 있었겠지만, 사실 gram matrix 내부에 비대각행렬은 style 정보와 함께 content 정보도 일부 얽혀있습니다.
그래서 이러한 규제화 방식은 content 정보의 손실로 이어져 segmentation output의 바운더리가 일그러지는 문제점이 발생했다고 하죠. 그래서 그 이후의 연구들은 최대한 비대각 원소들 중 어떤 부분이 content 정보이고 어떤 부분이 style 정보인지를 선별해서 최대한 style 정보에 해당하는 성분들만 whitening 하는 연구들이 성행했었는데, 이들도 역시 content 정보가 일부는 훼손될 수 있다는 한계점이 있을 겁니다.
그래서 본 논문의 저자는 어설프게 비대각행렬에 대한 whitening을 적용하는 것보다는 확실하게 대각 성분 자체는 분산을 1로 만드는 것이 확실하니 그 부분만 확실하게 규제화를 시켜주겠다는 겁니다. 그래서 수식5와 같은 loss가 적용이 된거죠.
Semantic Consistence Contrastive Learning
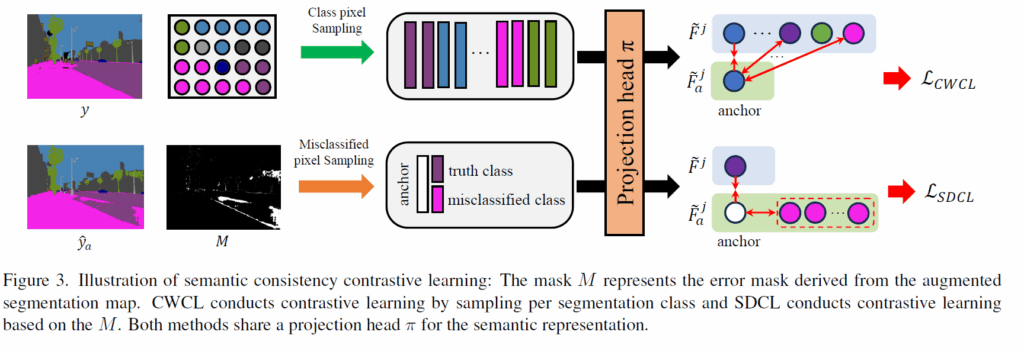
앞서 인코더에 대한 규제화 loss를 2개 알아보았으면 지금은 decoder와 관련된 loss입니다. 인트로에서도 설명드렸다시피 decoder 부분은 semantic segmentation을 잘 수행하기 위해 분별력있는 feature를 추출하는 것을 목표로 합니다. 분별력 있는 특징을 학습하는 방식으로 가장 확실한건 대조학습 방식이 있습니다. anchor에 대해서 positive 끼리는 가까워지고 negative 끼리는 멀어지도록 학습하여 군집들이 분별력 있도록 학습이 되는거죠.
그래서 저자들은 decoder feature map에 대해 아래 수식과 같이 InfoNceLoss를 적용합니다.
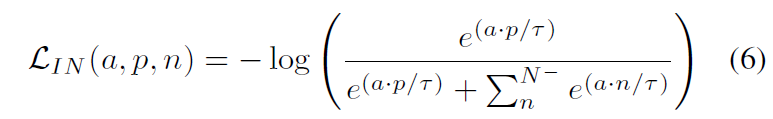
a, p, n은 각각 anchor, positive, negative를 의미하고 N은 negative sample의 개수를 의미합니다. 일단 대조학습에서 가장 중요한건 anchor와 positive 그리고 negative sample을 어떻게 선정하는지입니다. 이제부터 저자들은 어떤 식으로 각각의 샘플들을 선정했는지에 대해 알아보겠습니다.
Class-wise Contrastive Learning
우선 notation 표기에 대해서 설명을 드리면 다음과 같습니다.
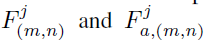
위의 두 값은 각각 원본 영상과 augmented 영상을 네트워크에 입력으로 하여 j번째 decoder block에서의 m,n 좌표에 해당하는 decoder feature 값을 의미합니다. shape은 1x1xC이고 C는 디코더 feature map의 채널이겠죠. 그리고 해당 decoder feature에 대하여 FC layer로 구성된 projection head \pi 에 태워 projected feature \tilde{F}, \tilde{F}_{a} 를 추출합니다.
그럼 이제 학습에 사용하는 segmentation label y를 j번째 decoder feature map의 해상도에 맞추어 down-sampling을 해줍니다.
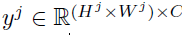
해당 segmentation label을 이용해서 class 별로 디코더 feature를 샘플링할 수 있게 되는데, 저자들이 제안하는 Class-Wise Contrastive Learning(CWCL) loss는 다음과 같습니다.

여기서 anchor와 positive의 관계는 동일한 좌표 (m,n)에서의 원본 영상의 decoder feature와 augmented image의 feature로 되어있습니다. 그리고 negative의 경우에는 m,n위치가 아닌 p,q위치에 해당하는데 해당 p,q는 m,n의 위치에서의 GT class와는 다른 class에 해당하는 지점입니다. 쉽게 얘기해서 m,n 픽셀의 class GT값이 강아지라면 네거티브 샘플이 뽑힐 수 있는 후보 영역은 강아지 class를 제외한 다른 class가 위치하는 좌표라는 것이죠.
그래서 같은 공간적 위치에 같은 클래스에 대한 feature는 서로 가까워지도록, 공간도 다르고 클래스도 다른 feature들끼리는 멀어지는 학습을 통해서 구분력 있는 특징을 추출할 수 있도록 학습시킵니다.
Semantic Disentanglement Contrastive Learning
다음은 2번째 loss인 SDCL loss입니다. 여기도 마찬가지로 positive, negative 샘플을 어떻게 추출하는지만 보시면 될 것 같습니다.
우선 수식부터 바로 보시죠.
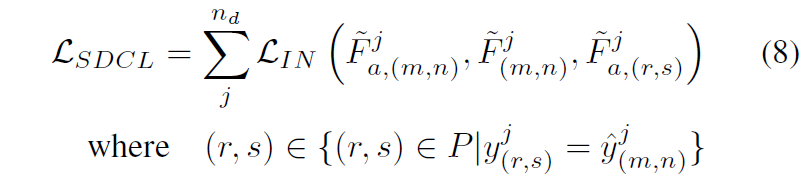
일단 anchor와 positive의 관계는 아까 CWCL loss랑 동일하게 같은 위치에서의 original feature와 augmented feature로 구성되어있습니다. anchor를 추출하는 방식에 대해서 알아보면 우선 아래 수식에서 \hat{y} 는 augmented image의 feature로부터 예측한 segmentation output을 의미합니다. 그리고 모델의 예측값과 실제 예측값이 서로 다른 영역들을 anchor로 설정합니다.
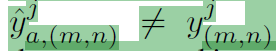
negative sample들은 저 anchor로 선정할 수 있는 영역 외에 지점들로부터 선택될 수 있는데, 이때 중요한 점은 아무 클래스나 선정하는 것이 아니라 augmented feature의 prediction 값 \hat{y}_{a, (m,n)} 과 같은 클래스들의 위치들로 선정이 된다는 점입니다.
예를 들어, y_{m,n}, \hat{y}_{a, (m,n)} 이 각각 개와 고양이라면, negative sample로 선정되는 (r,s)위치에서의 GT class는 개, 코끼리, 갈매기 같은 다른 클래스가 아닌 같은 클래스인 고양이어야한다는 점입니다.
이러한 SDCL loss의 목적은 augmentation feature를 통해서 예측한 모델의 output 값이 틀린 경우 이는 domain-shift로 인해 모델이 예측을 어려워하는 영역이라 판단하는 것이죠. 그래서 모델의 틀린 오답과 같은 클래스의 다른 영역들을 negative sample로 삼아 이들과 현재 anchor는 분명히 다른 클래스니 거리가 멀어지도록 학습시킨다고 생각하시면 됩니다.

위의 그림을 보면 road와 sidewalk과 같이 서로 비슷한 외관을 가지는 클래스들에 대하여 모델의 decoder feature가 구분력이 부족한 모습을 보여주는데 SDCL loss를 적용하니 이전보다는 더 분별력 있는 특징을 추출했다? 라는 내용입니다.
Experiments
그럼 실험 결과 보고 리뷰 마치겠습니다.
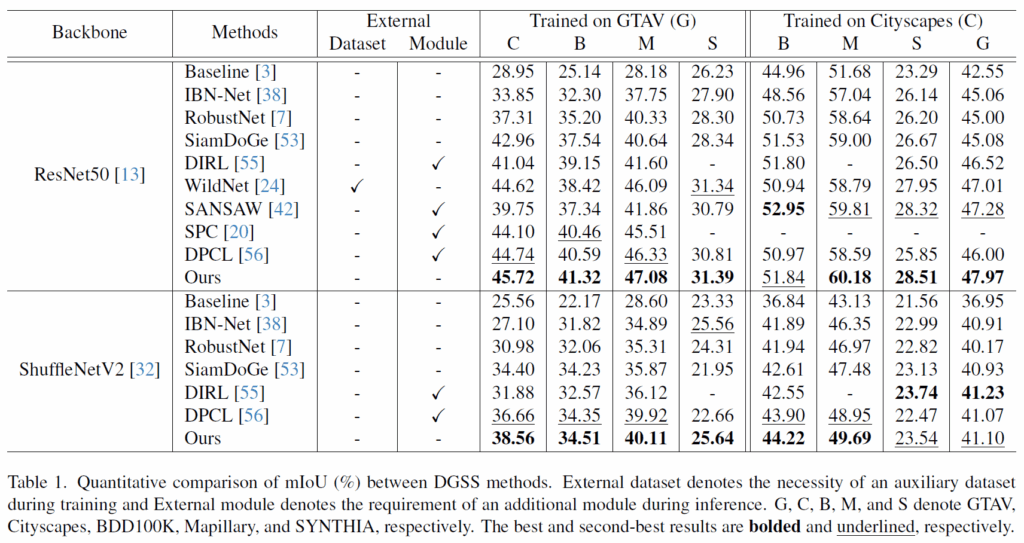
우선 실험에 사용되는 데이터셋은 총 5개로, 각각의 데이터셋이 의미하는 바는 위의 표에 캡션을 통해 확인하실 수 있습니다. DGSS 쪽 분야에서는 하나의 source domain으로 모델을 학습한 다음 각각의 도메인들에 대해 평가하는 것을 확인할 수 있습니다.
결론부터 말씀드리면 저자들의 방법론은 이전 연구들 대비 대부분의 데이터셋에서 가장 좋은 성능을 보여주며, 학습을 위해 추가적인 외부 도메인 데이터가 필요하다거나, 추론 단계에서 추가적인 모듈이 필요한 방법론이 아니라는 점입니다.
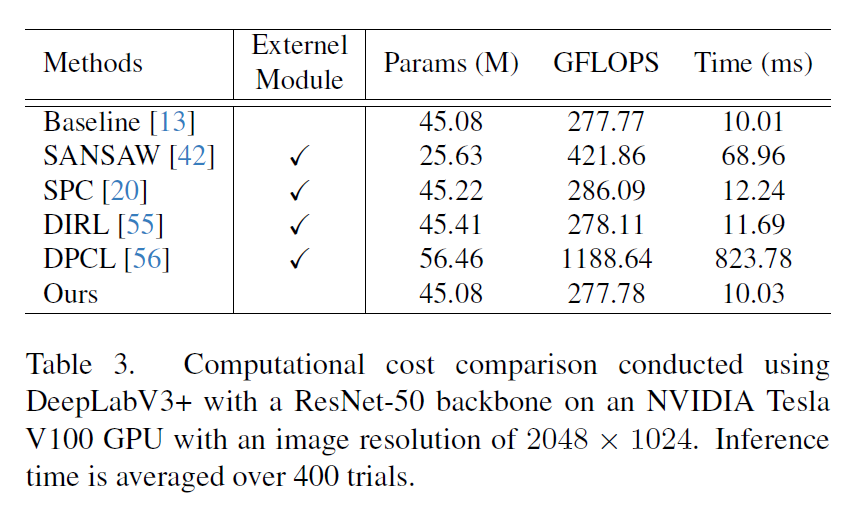
이는 곧 이전 연구들의 경우 기존 baseline 대비 추론에 필요한 파라미터 수가 늘어나거나 또는 GFLOPS, Time 등이 증가하는 반면에 저자들의 방법론은 베이스라인과 동일한 파라미터 및 시간이 걸린다는 것이죠.

그리고 위의 표는 ablation study에 관한 것인데, 우선 Encoder 쪽 loss들을 순차적으로 적용해도 성능이 오르지만 재밌는 점은 decoder의 loss가 성능 향상에 더 크게 기여한다는 점입니다. 이를 미루어보았을 때 domain-agnostic feature를 뽑기 위해 열심히 노력하는 것보다는 결국 모델이 예측에 어려워하는 domain-shift 상황 혹은 class 분별력이 떨어지는 것들을 해결하는 것이 일반화 성능에 더 큰 영향을 끼치는 것이 아닐까 싶네요.
결과적으로는 4가지의 loss를 모두 적용하였을 때 가장 좋은 성능을 보여주기는 합니다.
결론
방법론 소개라던지 실험 구성이 담백하니 기본에 잘 충실하게 쓴 논문 같고, 옛날 CV쪽 논문들과 비슷한 느낌이 나서 읽기가 참 편했네요.
안녕하세요 신정민 연구원님 리뷰 감사합니다.
Cross-covariance Loss에 대해 궁금한점이 있습니다. 물론 주대각성분 외의 정보에 제약을 가할경우 정보손실이 있을 수 있어 해당 주대각성분에만 규제를 가하는 목적함수를 구현했다고 이해했습니다. 혹시 기존 연구 등에서 주대각성분이 아닌 부분이 갖는 정보량에 대해 분석한 것이 있을까요?
주대각/비주대각 성분에 규제를 가하는 과정중에 gradient decent 과정중에 충돌이 있는것 아닐까 궁금한데, PCGrad와 같은 그라디언트 수정(충돌하는 업데이트 하지 않기) 방법으로 개선하는 방안은 어떻게 생각하시는지 궁금합니다. 이런 학습 방법 수정은 최근 트랜드에서 조금 벗어난것일까요?
댓글 감사합니다.
일단 주대각성분이 아닌 부분이 갖는 정보량에 대해 분석한 내용에 대해서는 지금 제가 리뷰한 논문에서는 따로 없지만 2021년도 CVPR에 게재된 RobustNet이라는 논문을 읽어보시면 도움이 될 것 같습니다. 해당 논문의 경우 주대각성분이 아닌 부분 중에서 제거해야될 부분(style)과 살려야할 부분(content)을 최대한 구분하는 모델링을 제안하여 제거해야될 부분만 제거하는 학습 방식을 제안했었거든요.
그리고 주대각/비주대각 성분에 규제를 가하는 과정중에 gradient conflict가 있냐는 질문에 대해서 혹시 비대각성분을 0으로 규제화시킬 때 content 정보 같이 제거할 경우 성능이 오히려 drop되는 영역들에 대해서는 loss가 커질테니 graident conflict가 일어날 것이고 이를 규제화하면 되냐는 것으로 이해를 했는데, 만약 제가 이해한 내용이 맞다면 그 부분으로 접근한 연구들이 있는지에 대해서는 제가 자세히는 알지 못합니다. 말씀해주신 부분에 대해 제 생각을 말씀드리면 이론적으로 괜찮은 접근같아 보이나 이게 막상 적용하기는 쉽지 않을 것 같습니다.
가령 i번째 채널과 i+5번째 채널에 대해서는 content 정보에 대한 관련성이 높아 이를 0으로 강제할 경우 segmentation loss가 커지는 gradient conflict가 발생한다는 것이 이상적인 방향이지만 그 외에 나머지 채널들에 대한 공분산들은 0으로 강제하는 것이 segmentation 관점에서 평균 loss가 더 낮게 나올 수 있거든요. 즉, 일부 채널들에 대한 공분산이 0이되면 안되는 상황이더라도 전체 채널들에 대한 공분산 관점에서는 0으로 만드는 것이 semantic segmentation의 평균 loss를 더 크게 개선시킬 수 있기 때문에 실제로 gradient conflict가 발생했다라고 판단하기가 상당히 어려울 것 같습니다. 실제로 대각성분은 1, 그 외에 성분은 0으로 강제해버린다고해서 segmentation 성능이 매우 크게 하락하는건 아닌 듯 해서요. object의 boundary 부분이 일부분 뭉게지는 등 부분적으로 성능의 아쉬움이 있다? 수준으로 저는 이해했어서 영상 전체 평균 관점에서는 conflict 상황을 이해하기 어려울 듯 하네요.