안녕하세요. 오늘 제가 리뷰할 논문은 이번 NIPS 2025년에 공개된 논문입니다. 논문은 긴 비디오에서 인과적으로 연결된 두 지점(Needles)를 찾아 이해하는 능력을 평가하는 데이터셋인 Causal2Needles를 제안합니다. 기본적으로 QA 데이터셋이지만, 긴 비디오에서 인과관계를 정확하게 이해하고 위치 또한 찾아야하는 어려운 난이도의 데이터셋으로 모델의 Answering과 Reasoning 그리고 Grounding 능력을 요구합니다.
Long Video Understanding
논문 리뷰에 앞서 긴 비디오 이해(Long Video Understanding, LVU)에 대해 설명드리겠습니다. 최근에 대규모 멀티모달 언어모델(Multi-modal Large Language Model, MLLM)의 발전으로 짧은 비디오에 대한 이해 능력은 크게 향상되었습니다. 기존의 Video QA는 대부분 1분 내외의 짧은 비디오에 대한 이해 능력을 요구하였고, 많은 VideoQA 모델과 MLLM은 이러한 짧은 비디오에서 좋은 VideoQA 성능을 보였습니다. 하지만, 이러한 모델들은 긴 비디오에서는 몇가지 한계가 존재했습니다. 긴 비디오의 맥락을 파악하는 능력은 짧은 비디오에 비하면 현저히 안 좋았고 긴 비디오의 많은 정보를 처리하기 위해서는 오랜 시간, 많은 메모리가 요구되었습니다. 이러한 한계를 극복하기 위한 다양한 긴 비디오 이해를 위한 모델들은 추후 리뷰를 통해 소개하겠습니다. 우선 이번 리뷰에서는 긴 비디오 이해의 연구에 대한 소개와 저자가 제안하는 벤치마크에 대해서 자세하게 리뷰하겠습니다.
앞서 설명드린 것처럼 기존 모델들은 긴 비디오에 대한 Long-term reasoning 능력과 효율적인 메모리 활용 능력이 부족합니다. 왜냐하면 비디오의 길이가 길어질수록 비디오 내에서 사건들의 인과관계, 서사, 감정변화 등과 같은 긴 비디오의 맥락을 정확하게 파악하기 위해서는 복잡한 추론 능력과 기억력이 필요하기 때문입니다. 기존 연구들은 대부분 짧은 비디오로 학습되어 모델이 긴 비디오를 본 적이 없어 복잡한 추론 능력이 부족하고 긴 비디오의 내용을 기억하기 위해서는 많은 메모리가 필연적이기 때문에 현실적으로 긴 비디오에 대한 이해 능력은 future work로 남겨져 있었습니다. 더군다나 긴 비디오로 구성된 벤치마크 또한 존재하지 않아 연구를 하기 위해서는 직접 긴 비디오로 구성된 데이터셋을 구성해야하는 어려움도 존재했습니다. 당연하지만, 어노테이션 코스트도 너무 크고 라벨링 과정에서 어노테이터에 따른 편향도 들어가기 때문에 데이터셋을 구성하는 것 또한 어려움이 있었습니다.
그럼에도 불구하고 긴 비디오 이해를 위한 벤치마크들이 존재하지 않는 것은 아닙니다. 최근 몇년 동안 긴 비디오 이해를 위한 벤치마크들이 여럿 제안되었고, 긴 비디오 이해를 위한 연구 또한 점점 관심을 받고 있었습니다. 하지만, 기존 모델과 벤치마크에는 명확한 약점이 존재합니다. 현재 학계에서 LVU 모델 학습과 평가를 위해 많이 사용되는 데이터셋들인 MLVU, VideoMME, LongVideoBench 등의 데이터셋들은 다중 시점에 걸친 물체의 색, 개수 등의 속성을 고려한 QA가 존재하긴 했었지만 대부분의 질문은 여러 시간대의 프레임을 독립적으로 식별하면 해결할 수 있는 QA들이었고 표면적인 단서를 맞추기만하면 정답을 맞출 수 있기에 장면 간의 복잡한 추론 능력은 요구하고 있지 않습니다. 두 장면 이상의 독립된 사건을 연결지어 이해해야하거나 인과관계를 추론하도록 설계된 데이터셋은 존재하지 않았습니다.
하지만, 긴 비디오를 잘 이해하기 위해서는 복잡한 추론 능력이 필수적입니다. 긴 비디오 이해 능력을 면밀하게 평가하기 위해서 즉, 기존의 단순한 질문과 답변을 생성하는 것을 넘어 모델이 정말로 긴 비디오를 이해하고 있는지를 평가하기 위해서는 다음 두가지 평가방식이 활용될 수 있습니다.
- Multi-turn QA: 이 방식은 한번의 QA이 아니라 연속된 여러번(multi-turn)의 QA를 실시하는 평가방식입니다. 대화형으로 질문과 답변이 주어져 질문1 -> 답변1 -> 질문2 -> 답변2 … 의 순서로 진행되며 이어지는 질문은 앞선 질문에서 나온 답변을 토대로 출제됩니다. 예를 들어 “검정 모자를 쓴 남자는 무엇을 하고 있어?” – “사과를 먹고 있습니다.” – “그 사과는 무슨 색이야?” – “빨간색입니다.” – … 등의 방식으로 질문이 이어지며 대화에서의 맥락을 파악하고 있어야 올바른 답변을 생성할 수 있습니다. 이는 동적인 비디오 상황에서의 연속 추론 능력을 요구하여 긴 비디오에 대한 심층 이해를 이끌어낼 수 있습니다. OmniMMI와 같은 벤치마크가 이러한 Multi-turn QA 벤치마크에 해당합니다.
- Multi-hop Reasoning (QA)는 하나의 질문에 답변을 하기 위해서는 비디오의 여러 부분을 이해해야하는 QA를 실시하는 평가방식입니다. 예를 들어 “검정 모자를 쓴 남자가 먹은 과일은 어디에서 샀어?”와 같은 질문입니다. 하나의 질문이지만, 질문에 대한 정확한 답변을 하기 위해서는 검정 모자를 쓴 남자가 먹은 과일은 무엇인지 파악해야하며 또, 그 과일을 어디에서 샀는지를 알아야 합니다. 즉, 긴 비디오 내에서 존재하는 여러 장면들 중 답변을 하기 위해서는 어떠한 장면을 봐야하는 지 그리고 그 장면들을 연결하여 인과관계를 파악할 수 있어야합니다.
이러한 Multi-turn 추론과 Multi-hop 추론은 모두 긴 비디오 이해에서 중요한 평가 개념으로 활용되며 기존의 단순한 QA에서 더 나아가 모델이 정말로 긴 비디오를 이해하고 있는 지를 확인합니다. 제가 리뷰하는 Causal2Needles 벤치마크는 기존 벤치마크들의 단점을 보완하고 LVU를 정확하게 평가하기 위해 Multi-hop Reasoning 평가를 활용하는 벤치마크입니다.
Causal2Needles
긴 비디오의 이해는 건초 더미에서 바늘찾기(A Needle in a Haystack)에 비유할 수 있습니다. A Needle in a Haystack는 말 그대로 건초 더미 속에서 바늘을 찾는 것으로 우리나라 속담인 백사장에서 바늘 찾기와 같은 의미입니다. 매우 어렵거나 불가능에 가까운 일을 비유하는 속담으로 방대한 분량의 비디오와 정보(건초) 사이에서 원하는 특정 정보(바늘)을 찾는 것을 말합니다. 기존 벤치마크들은 1-needle 문제를 다뤄왔습니다. VideoQA에서 하나의 장면만 보면 답할 수 있는 문제를 말합니다. 이러한 방식에서 최신 연구들은 거의 사람에 가까운 성능을 내곤합니다. 하지만, 1-needle 질문을 잘 답하는 모델들이 여러 단서를 추출하고 종합하여야하는 multi-needle 질문에서도 성능이 좋을 지는 평가가 필요합니다. 기존에는 multi-needle 질문을 하는 벤치마크가 많지 않았기에 이를 평가하기가 굉장히 어려웠습니다.
또한 world model의 관점에서 기존 벤치마크들은 물체의 움직임 예측 등의 물리적 인과관계를 묻는 질문은 많았지만 사람의 행동의 인과관계를 묻는 질문은 별로 없었습니다. 예를 들어 공이 바닥에 부딪혔을 때, 공이 어떻게 되는 지를 묻는 질문은 존재했지만, 사람이 운동한 뒤 땀을 흘린다는 사실과 땀을 많이 흘리면 갈증을 느낀다는 등의 사람의 행동의 인과로 인한 관계를 묻는 질문은 적었습니다. 사람의 행동의 인과관계는 world model의 중요한 구성요소이지만 기존 모델들이 이를 내재적으로 습득했는 지에 대한 평가는 진행되지 않고 있었습니다.
저자가 제안하는 Causal2Needles는 앞서 언급한 두가지 능력은 동시에 평가하기 위한 long-context 비디오 이해 벤치마크입니다. 긴 비디오에서 서로 떨어진 두 지점(two needles)의 정보를 추출하여 종합적으로 이해하는 능력과 인과(cause and effect) 관계로 이어진 사람 행동 사건을 파악하는 능력을 평가합니다. Causal2Needles는 1-needle 질문 2606개와 2-needles 질문 1494개로 총 4000개의 질문으로 구성되어 있습니다. 이 중 902개의 1-needle 질문과 2-needles 질문은 causal, worl-modeling reasoning을 포함하는 질문입니다.
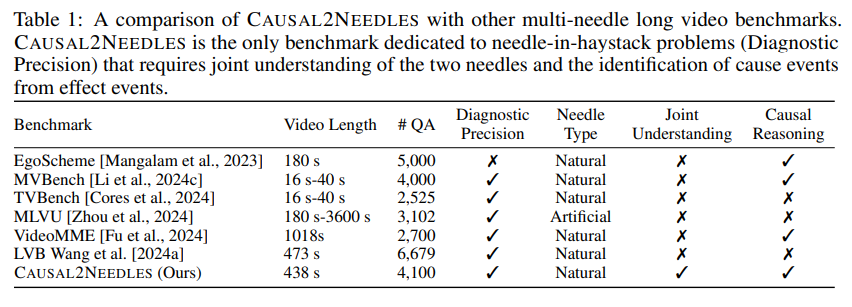
표 1은 저자가 제안하는 Causal2Needels 벤치마크의 통계를 보여줍니다. Causal2Needles는 스토리가 있는 긴 비디오로 구성되어 있습니다. 영화 줄거리 요약 데이터셋인 YMS와 SyMoN 데이터셋에서 192개의 비디오를 선정하여 사용했으며 영화는 다양한 장르가 존재하며 각 영상은 전체 내래이션 자막과 사건 별로 자른 장면 클립이 주어집니다. 하나의 사건은 내래이션 상의 한 문장과 대응됩니다. 저자는 LLM을 활용하여 사건 간 인간 관계를 자동으로 추출했고, 내래이션을 분석하여 글로벌 사전 그래프와 세부 장면 별로 추출한 로컬 그래프를 결합해서 영상 내에서 원인과 결과로 이어진 sentence pair를 찾습니다. 그리고 원인과 결과 사이에 3개 이상의 다른 사건이 연결된 경우에 인과관계로 채택하여 어노테이션 했습니다. 이것은 저자가 의도적으로 long context를 찾을 수 있도록하여 난이도를 어렵게 조절하였습니다.
Causal2Needles의 핵심은 바로 2-needles 질문의 구성입니다. 저자는 단순히 관련된 사건을 물어보는 것을 넘어서 질문 자체를 두 파트로 나누어 모델이 순차적으로 추론할 수 있도록 유도했습니다. 저자는 bridge entity를 도입했는데, 이거는 원인과 결과에 공통된 정보를 의미합니다. 2-needles 질문에서 파트1은 bridge entity를 알아내기 위한 결과에 관한 질문을 하고 파트2는 파트1에서 얻은 정보를 토대로 원인에 대한 질문을 합니다. 저자는 만약에 이 bridge entity가 직접적으로 질문에 연관되어있다면 1-needle 질문과 동일하기 때문에 직접적으로 이러한 bridge entity를 언급하지는 않는다고 합니다. 예를 들어 실제 영화 속 사건이 “슈퍼맨의 죽음”이 원인이 되어 “메트로폴리스에서 그의 추모식이 열렸다”일때 bridge entity는 슈퍼맨의 죽음입니다.ㅏ 저자는 파트1 질문은 “메트로폴리스 추모식에서 기념된 비극은 무엇인가”로 제히됩니다. 이것만으로는 기념된 비극이 무엇인지 알 수 없기 때문에 저자는 추모식 장면을 찾아야하고 기념된 비극이 슈퍼맨의 죽음임을 알아내야합니다. 파트2는 그 지극이 어떻게 발생했는가로 주어집니다. 이러한 관계를 통한 논리적인 과정을 통해 질문에 답해야하는 2-needles 질문은 Figure 1에서 확인할 수 있습니다.
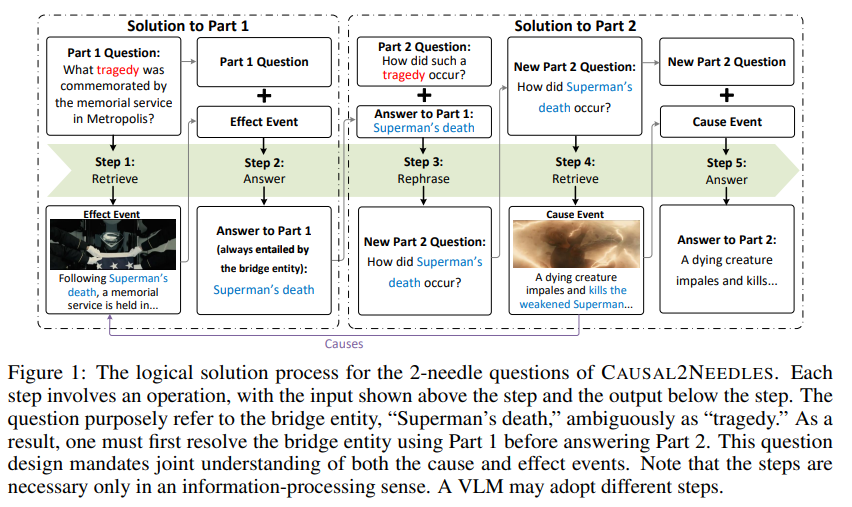
Figure 1은 2-needles 질문을 해결하기 위한 해결 과정의 예시입니다. 파트1과 파트2로 구성된 2-needles 질문을 Retreive, Answer, Rephrase, Retrieve, Answer의 과정을 통해 해결하게 됩니다. 이 과정에서 두개의 장면을 연계하여 이해해야하며, Resoning 능력을 요구합니다. 이 과정에서 event의 위치를 grounding하는 능력도 필요하게 됩니다.
긴 비디오 줄거리는 텍스트로 구성된 내래이션이 영상을 이해하는 데에 큰 도움을 줍니다. 하지만 이는 자칫하면 모델이 영상을 보지않고 텍스트만으로 답을 추론하는 텍스트 편향이 일어날 수 있습니다. 이를 방지하기 위해 Causal2Needles는 2-needle 질문은 두가지 방식으로 구성되어 있습니다. 하나는 visual grounding 형식입니다. 이 형식에서는 모델이 답을 찾은 후에 그 답이 있는 비디오의 위치를 grounding 합니다. 정확하게는 grounding이 아니라 장명의 index를 고르게됩니다. 어느 장면에 답이 있는지 번호를 고르는 것으로 reasoning 능력을 간접적으로 확인할 수 있습니다. 이렇게하면 영상의 이해가 기반이 되어야하므로 텍스트에만 편향되는 것을 막을 수 있습니다. 두번째 방식은 image description 형식입니다. 파트2 질문을 약간 변경하는 것으로 원인 장면을 보지 않는 다면 이해하기 어려운 세부 정보를 묻게 되고 객관식 선택지를 제안합니다. 예를 들면 “그 비극(슈퍼맨의 죽음)이 발생하는 장면에서 괴물이 발사한 에너지 빔의 색은 무슨 색인가”를 질문하고 A.노랑, B.파랑, C.빨강, D.하양 으로 제안합니다. 이때 정답은 실제로 정답의 근거가 되는 구간의 시각적 정보가 없다면 알 수 없는 정보로 저자는 이러한 구성을 통해서 image description 형식이 텍스트에만 의존하는 것을 어렵게 만든다고 주장하고 있습니다. 만약에 모델이 영화에서 괴물이 쏜 빔의 색을 기억하고 있는 다면 사전지식을 통해 정답을 맞출 수 있습니다. 따라서 저자는 위의 visual grounding과 image description 두가지 방식을 통해서 모델의 성능을 다각도로 평가할 수 있습니다.

Figure 2는 Causal2Needles의 평가 방식을 보여주고 있습니다. 위에서 설명한 1-needle 질문, 2-needle 질문 그리고, visual grounding과 image description 총 4가지 평가방식이 존재합니다.
Evaluation Result
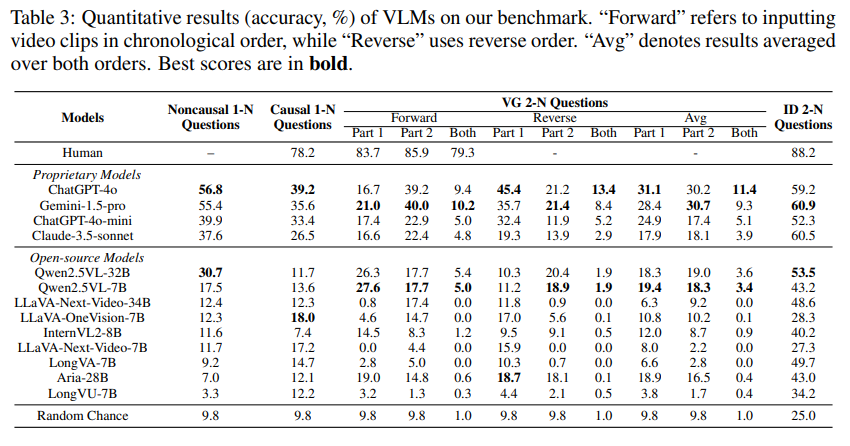
Table 3은 Causal2Needles 벤치마크에서 기존 여러 MLLM 모델들의 성능을 보여줍니다. 대부분의 모델들은 2-needle 질문에서 성능이 많이 낮은 것을 확인할 수 있습니다. 1-needle에서는 꽤 높은 성능을 보인 모델들도 2-needle에서는 굉장히 낮은 성능을 보입니다. 특히 파트2에서의 성능이 많이 낮은 것을 확인할 수 있습니다. 어떤 사건이 원인이었다라는 것을 현 모델들은 잘 파악하지 못한다고 볼 수 있습니다. 저자가 또한 주목한 부분은 proprietary 모델과 open source 모델 사이의 성능 차이입니다. 대부분의 open source 모델은 2-needle에서 낮은 성능을 보였습니다.
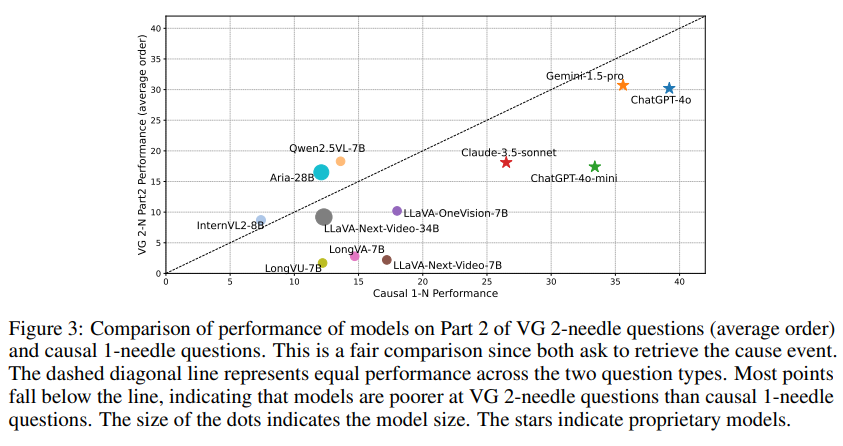
Figure 3은 여러 MLLM의 1-needle과 2-needle 성능을 비교하고 있습니다. GPT-4 계열의 모델 조차도 2-needle에서는 큰 성능 감소 있는 것을 확인할수 있습니다. 이것은 아직 긴 비디오 이해를 위해 연구가 아직 더 진행되어야한다는 것을 의미합니다. 이후에는 긴 문맥 이해 능력을 키우기 위해서라도 복잡한 질문을 평가하는 것이 필수적임을 알 수 있습니다.
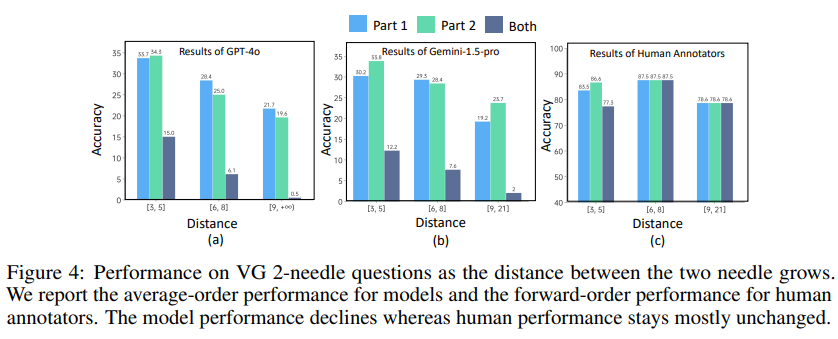
Figure 4는 1-needle과 2-needle 질문에서 두 연관된 장면의 거리에 따른 성능의 차이를 보여줍니다. 두 장면 사이의 거리가 멀어짐에 따라 모델의 성능이 낮아지는 것을 확인할 수 있습니다. 이를 통해 기존 모델들이 긴 비디오에서 복잡한 추론 능력이 떨어지는 것을 확인할 수 있습니다.
Causal2Needles 데이터셋은 긴 비디오에 대한 모델의 진짜 이해 능력을 확인할 수 있는 벤치마크입니다. 당연하게도 굉장히 난이도 있는 데이터셋으로 아직 성능이 많이 낮습니다. 이는 반대로 생각하면 아직 발전 가능성이 많이 남아있다고도 분석할 수 있을 것 같습니다. 단순히 자주 등장하는 패턴이나 쉬운 단서만을 파악하는 것에서 더 나아가서 plot의 전반을 통찰하고 인과적 맥락을 파악하는 능력을 평가할 수 있는 이 벤치마크 데이터셋은 앞으로 긴 비디오에 대한 이해 능력을 평가하는 벤치마크의 역할을 수행할 수 있을 거라 기대됩니다.
감사합니다.
안녕하세요 성준님 재미있는 논문 소개해주셔서 감사합니다.
Table3에 대해 질문이 있는데요, VG 2 Needle Questions 성능에서 Forward, Reverse, average 성능이 무엇인지 할 수 있을까요?
둘째로 Figure1에서 2-needle 질의의 예시를 보여주고 있는데, part 1 질문 역시 1-needle로 질의해도 된다고 생각하는데요, 2-needle 방식으로 해결시 연산 속도 측면에서 손해가 있을 것 같습니다. 동일한 질의에 대해 1-needle과 2-needle 방식으로 리포팅한 성능이 있을까요? 혹시 그것이 Table3의 Causal 1-N/VG 2-N으로 이해하면 되는지 궁금합니다.
감사합니다.
안녕하세요 성준님, 좋은 리뷰 감사합니다. 모델이 단순히 비디오의 한 프레임에 관한 간단한 질문만 답하는 것이 아니라 ‘인과관계’, ‘맥락’을 학습할 수 있도록 했다는 점이 인상적이었고, 미래에 더 실용적으로 많이 쓰일 기술(?)이라고 생각이 들어 흥미롭게 읽었던 것 같습니다.
간단한 질문 한 가지만 드리겠습니다..! 나레이션에 의한 텍스트 편향을 방지하기 위한 질문 방식 구성 중 visual grounding에서, 모델이 답이 있는 장면의 인덱스를 고른다고 하셨는데, 이때 인덱스는 비디오(영화)의 모든 frame에 매겨지는 건지, 아니면 keyframe처럼 일부 frame을 따로 추출해서 이들에게만 인덱스를 부여하고 답을 찾게 하는 건지 궁금합니다!!
성준님 안녕하세요. 좋은 리뷰 감사합니다.
1. 보통 Video NIAH 문제를 다루는 논문에선 입력 프레임 개수를 비디오 당 수 만개까지 늘려가며 성능이 비례하게 오르는지도 보는 것으로 알고있는데, 이 논문에는 프레임 개수에 대한 제한이 없나요? 없다면 벤치마크 성능을 찍을때 각 모델이 원래 한 비디오에 입력받도록 설정되어있는 프레임 개수를 쓴 것이 맞는지 궁금하고, needle이다보니 많으면 많을수록 좋을 것 같은데 우선 보여주신 표에는 언급이 없는 것 같습니다. 이에 대해서는 어떻게 바라보면 될지 성준님의 생각이 궁금합니다.
2. 추가적으로 장면 인덱스를 고르는 visual grounding은 단순 분류가 맞나요? 그렇다면 랜덤이 9.8일 때, 왜 많은 모델이 랜덤보다도 못한 성능을 내는지 궁금합니다. 아예 몰라서 찍는다면 말그대로 랜덤 수치가 나와야하는데, 그 랜덤 수치도 안나오는 것이 뭔가 모델에 편향이 있는건지, 또는 저자들이 봤을때 오답에는 경향이 있었다든지 등 견해가 궁금합니다.
감사합니다.