안녕하세요. 이번에 리뷰할 논문은 ViNG: Learning Open-World Navigation with Visual Goals라는 논문 입니다. 이 논문은 2020년 ICRA에 게재된 논문이고 Visual Goal-Conditioned Navigation을 다룹니다.
사실 지지난번에 리뷰했던 GNM(General Navigation Model) 논문이 바로 이 ViNG의 학습 방식을 기반으로 하고 있어서,보다 기초적인 개념과 학습 구조를 명확히 이해하고자 이번에 ViNG 논문을 선정하게 되었습니다. 막상 읽어보니 기초적이지는 않은 것 같습니다. 여전히 개념적으로 복잡한 부분이 많고 논문만 읽었을 때는 아직 직관적으로 와닿지는 않는 것 같습니다. 관련논문 한 20편 이상은 읽어야 이 네비게이션 분야의 흐름을 잡아나아갈 것 같습니다.
암튼 이번 리뷰에서는 이 논문의 핵심 아이디어와 구조적 흐름을 중심으로 하나씩 정리해보려고 합니다. 바로 리뷰 시작하도록 하겠습니다.
introduction
먼저 저자는 복잡한 환경에서 로봇이 스스로 길을 찾아가는 Visual Navigation은 생각보다 훨씬 까다로운 문제임을 언급합니다. 왜냐하면 단순히 카메라로 본 이미지 하나만으로으로 주변 상황을 이해하고 공간정보를 이해해서 그에 맞게 움직여야 하기 때문입니다. 이를 조금 더 구체적으로 보면 실제 환경은 너무 복잡해서 로봇의 동작과 주변 환경 간 100% 이렇다 라고 모델링하기 어려울 뿐더러입력 자체가 고차원 이미지이기 때문에 이를 실시간으로 처리하기가 쉽지 않고새로운 데이터를 수집하는 것도 위험하거나 비용이 많이 들어서 대부분 이미 수집된 오프라인 데이터만으로 학습해야 하는 한계가 있기 때문입니다. 그리고 마지막으로 한 번 학습한 로봇이 다른 환경에서도 잘 작동하게 만드는 것(일반화)도 매우 어렵다고 합니다. 즉, 사진만 보고는 현재 여기가 어디가 어디인지 모르는 셈입니다. 물론 기존의 지도기반의 전통적인 planning알고리즘 중심 접근들은 이런 문제 중 일부를 잘 해결하긴 하지만 해당 방식 또한 기하학적인 지도만 가지고는 장애물과 같은 환경을 정밀하게 모델링하기 어렵고(예를 들어 풀밭과 같은 실제 환경에서는 겉보기에는 장애물처럼 보여도 실제로는 통과 가능한 구역일 수 있어 이러한 가정이 틀릴 수 있음) 조명이나 날씨가 바뀌면 성능이 급격히 떨어진다는 문제가 있습니다.
반면 인간은 훨씬 유연합니다. 예를 들어 우리가 낯선 동네를 걸을 때, 저기 전에 봤던 곳이네 여기선 이 방향으로 가는게 맞아하면서 자연스럽게 길을 찾는 것처럼 지도나 GPS 없이도 과거의 시각적 경험을 떠올려 이동할 수 있습니다. 이건 인간이 머릿속에 감각적인 정신적 지도(논문에서 이렇게 표현합니다)를 가지고 있기 때문이고, 그 지도는 환경의 기하학적 좌표가 아니라 시각적 단서(landmarks) 들 사이의 관계로 구성되어 있기 때문이라고 합니다.
그래서 저자는 로봇에게는 이런 감각 기반 지도가 없다는 점을 언급합니다. 게다가 GPS나 지도가 없는 상황에서는 어디로 가야 하는지 목표 자체를 정의하기도 어렵습니다. 예를 들어, 저기 있는 나무 앞까지 가라라고 말해도 로봇은 그 나무가 어디 있는지 모릅니다. 왜냐면 위치 기반 목표를 지정하려면 로봇이 자기 현재 위치를 알고 자기 위치랑 목표 위치를 비교할 수 있어야 하는데 자기 현재 위치도 알 수 없기 때문입니다. 따라서 이 논문에서 제안하는 방식은 이런 문제를 아주 인간처럼 직관적으로 풀어내고자 합니다. 저자는 인간이 과거에 봤던 랜드마크를 떠올리면서 그쪽으로 걸어가는 방식에 영감을 얻어서 로봇에게 목표를 정의할 때 가고 싶은 곳의 사진을 보여주는 방식을 활용합니다. 즉, 사용자가 목적지의 이미지를 로봇에게 보여주면, 로봇은 그 이미지를 기억 속의 관찰들과 비교해 아 이쪽 방향으로 가면 저 장면이 나오겠구나 하고 판단하며 이동하게 되는 셈입니다.다. 이 접근법의 중요한 장점은 앞서 언급했던 문제인 환경의 기하학적 구조(지도)나 공간 좌표에 대한 정보를 전혀 몰라도 된다는 점입니다. 그냥 목적지에 대한 시각적 정보와 현재의 시각 정보만으로도 어디로 가야 하는가를 추론할 수 있다는 것이 핵심입니다.
(논문 그림 1에서는 이 개념을 예시로 보여주고 있습니다.)

이런 아이디어를 실제로 구현하기 위해서 저자들은 실외 환경에서 visual goal에 도달할 수 있 완전 자율형 로봇 시스템을 만들었고 이 것이 저자가 제안한 ViNG (Visual Navigation with Goals)입니다. 먼저, 로봇은 두 장면(두 관찰) 사이의 거리를 예측하는 함수를 학습합니다. 정확히는 한 장면에서 다른 장면으로 이동하기 위해 필요한 시간 스텝 수를 학습한다고 보시면 좋을 것 같습니다. 이걸 통해 이 장면에서 저 장면으로 바로 갈 수 있을까?를 판단할 수 있게 되는 것입니다. 그다음에는 이 학습된 거리 함수를 이용해서 로봇이 과거에 본 관찰들을 하나의 위상 그래프로 구성합니다. 로봇의 기억 속 장면들(학습시키는 오프라인 데이터라고 볼 수 있습니다.)을 노드로 두고 서로 이동 가능한 장면끼리 간선으로 연결하는 형태라고 보시면 됩니다. 그 위에서 그래프 탐색을 통해 실제 경로를 계획(plan)하게 됩니다.이 과정에서 중요한 점은 로봇이 환경에 대해 아무런 기하학적 가정도 하지 않는다는 것입니다.즉, 두 장면이 실제로 몇 미터 떨어져 있는지나 좌표가 어디서 부터 어디인지 얼만큼 떨어져잇는지 같은 물리적 거리 정보나 기하학정보는 전혀 사용하지 않고,오로지 데이터로부터 학습된 장면들 사이의 관계만으로 이동 경로를 결정하는 것입니다. 그리고 추가적인 특징으로는 오프라인 데이터만으로도 학습이 가능하다는 점입니다. 즉, 시뮬레이터나 온라인 데이터 수집 없이 실제 환경에서 이미 수집된 오프라인 데이터만으로도 학습이 가능하다는 것입니다.
위처럼 지도나 공간정보 없이 오프라인으로 수집된 데이터로부터 goal dirceted 네비게이션을 효율적으로 학습할 수 있도록 하는 en 가지 핵심 아이디어는 다음 세 가지라고 보시면 됩니다.
- Graph Pruning (그래프 가지치기) – 불필요하거나 비효율적인 경로를 제거해서 탐색 공간을 줄입니다.
- Negative Mining (부정 샘플링) –도달 불가능한 장면 쌍을 학습에 포함시켜 모델이 실제 이동 가능성과 불가능성을 구분하도록 돕습니다.
이 두 가지 아이디어가 결합되어, ViNG은 복잡한 실제 환경에서도 지도 없이, GPS 없이, 오프라인 데이터만으로로봇이 목표 이미지를 향해 이동할 수 있도록 만든다고 보시면 될 것 같습니다. 위 3가지 아이디어에 대해서는 다음 메서드 파트에서 자세히 다루도록 하겠습니다.
그리고 2020 당시까지의 연구 중, ViNG은 시뮬레이터 학습이나 수작업으로 만든 지도없이 오프라인 데이터만으로 visual goals을 향해 long-horizon navigation을 수행할 수 있음을 실제 지상 로봇에서 시연한 최초의 시스템이라고 합니다.
Methods
ViNG이 다루는 과제는 goal-directed visual navigation입니다. 즉, 로봇에게 단순히 이 좌표로 가라가 아니라 이 사진처럼 보이는 장소까지 가라라는 형태의 목표가 주어지는 것입니다. 따라서 로봇은 입력으로 주어진 목표 이미지 o_G 를 보고, 현재 자신이 보는 카메라 영상과 비교하면서 점점 그 장면과 비슷한 곳으로 이동해야 합니다. 또 한 가지 중요한 점은 로봇이 단순히 이동만 하는 것이 아니라 목표에 도달했음을 스스로 인식해야 한다는 점입니다. 외부에서 도착했다 라고 알려주는 신호가 따로 주어지지 않기 때문에, 로봇은 시각적으로 목표 장면과 유사해졌는지를 스스로 판단해서 도착 신호를 내릴 수 있어야 합니다.
ViNG은 앞서 말했듯이 지도나 위치 정보(GPS, 좌표계) 같은 공간적 정보가 전혀 주어지지 않은 상황에서 동작합니다. 대신, 로봇은 과거에 수집된 주행 데이터(오프라인 데이터)에만 접근할 수 있습니다. 이 데이터들은 로봇이 과거에 이동하면서 찍은 이미지 시퀀스들인데, 이걸 이용해서 로봇은 환경(장면 간)의 위상적 관계를 학습하게 됩니다. 즉, ViNG은 실제 공간을 3D 좌표로 재구성하는 대신 이 장면에서 저 장면으로 이동 가능한가?를 학습한 거리 함수(한 장면에서 다른 장면으로 이동하기 위해 필요한 시간 스텝 수를 학습), 두 장면간 서로 도달이 가능한지를 계산하는 도달가능성 함수를 활용해서 환경을 그래프 형태로 표현합니다. 이렇게 위상그래프로 남드는게 인간처럼 사진 간의 연결 관계로 이루어진 정신적 지도를 만드는 것이라고 보시면 될 것 같습니다.
그리고 intro 마지막 부분에 ViNG은 오프라인데이터로부터 학습이 가능한 구조를 가지고 있다고 언급하였는데 좀더 자세히 설명드리자면 이 말은, 실제 로봇이 실시간으로 데이터를 모으지 않아도 이미 존재하는 데이터만으로 학습을 진행할 수 있다는 뜻입니다. 실제 로봇 시스템에서는 데이터 수집 비용이 크고, 반복 실험이 어렵기 때문에 오프라인 데이터만으로도 학습이 가능하다는 것은 큰 이점이라고 볼 수 있습니다. 요약하자면ViNG이 제시하는 시스템의 핵심은 입력으로 목표이미지와 현재 이미지가 주어지면 목표 지점까지의 이동 경로 및 도달 여부를 판단하는데 이때 학습과정에서는 오프라인에서 수집된 이미지 시퀀스데이터를 사용하고 단일카메라로만 주변을 관찰하고 자신의 위치나 자세를 계산하는 것을 수행하지 않는 방식으로 동작하는 시스템, 즉 사람처럼 동작하도록 하는 시스템이라고 이해하시면 좋을 것 같습니다.
이제 VING의 실제 동작 원리를 설명하도록 하겠습니다. ViNG의 전체 과정은 크게 두 단계로 나뉩니다.
- 학습 단계 : 데이터를 가지고 이동 가능성 함수와 상대 자세 예측기를 학습
- 실행 단계 : 학습된 함수들을 이용해 실제 그래프 기반 내비게이션 수행
즉, 처음에는 이 이미지에서 저 이미지로 갈 수 있는지를 배워두고 실제 주행할 때는 그 학습 결과를 바탕으로 그래프를 만들고 탐색하는 구조라고 생각하시면 좋을 것 같습니다. 이제 학습단계에 대해서 자세하게 설명을 드리자면 바로 위에서도 언급하였지만 ViNG이 학습하는 함수는 두 가지입니다.
이동 가능성 함수 (Traversability Function, T) : 두 관찰(이미지) 사이를 실제로 이동할 수 있는지를 정량적으로 예측하는 함수(얼마나 많은 시간 스텝이 필요한지 = 동적 거리)
상대 자세 예측기 (Relative Pose Predictor, P) : 두 이미지를 보고, 하나가 다른 하나에 비해 어디 방향에 있는지를 예측
위 두 함수는 서로 다른 역할을 수행하지만, 모두 이미지 입력만을 사용한다는 공통점을 가집니다.
먼저 Traversability Function (T)입니다. (이동 가능한가?를 학습하는 친구) 단순히 생각하면 ViNG의 거리 함수 T는 단순히 두 이미지가 비슷를 비교하는 함수라고 생각하실 수 있는데 아닙니다. 논문에서는 이 T를 학습시키는 것을 동적 거리 학습이라고 하는데, 하나의 관찰에서 다른 관찰로 이동하는데 필요한 예산 시간 스텝 수를 예측하도록 이 함수를 학습시키게 됩니다.
T(o_i, o_j) = \text{Estimated time steps to go from } o_i \to o_j즉, o_i에서 o_j까지 가는 데 얼마나 걸릴까?를 추정하는 함수라고 이해하시면 좋을 것 같습니다.
ViNG은 이 T 함수를 두 가지 방식으로 학습하였습니다.
- 지도 학습 (Supervised Learning) 같은 trajectory 내의 이미지 쌍 $(o_i, o_j)$ 을 선택하고 실제 경과 시간 d_{ij} = j - i 를 GT로써 사용하게 됩니다. 즉, 실제 걸린 step 수를 그대로 예측하도록 학습하도록 합니다. 이 방식은 직관적이지만, 실제 최단 거리보다 과대 추정되는 경향이 있습니다. 왜냐하면 로봇이 돌아서 갔을 수도 있기 때문이죠. 예를들어 같은 trajectory 내 이미지쌍이 A-B-C-D라고 했을 때 A,B의 step은 3이 됩니다. 하지만 만약에 A랑 D사이에 지름길 E가 있다면 실제 step 2만에 갈 수 있는걸 3step으로 돌아가게끔 학습이 될 수 도 있다는 단점이 있게 됩니다. 따라서 이러한 문제를 해결하기 위해서 시차학습이란 것을 사용합니다.
- 시차 학습 (Temporal Difference Learning) 위 방식은 뭔가 강화학습 개념에서 사용되는 것 같은데, 논문에 자세히 나와있지 않아서 간단하게만 설명하자면 시간차를 기반으로 점진적으로 거리 함수를 업데이트를 하는 방식이라고 합니다. 이론적으로는 지도학습 기반과는 달리 최단 경로 거리 에 수렴 가능하다고 합니다. 다만 구현은 복잡하지만, 학습 효율 면에서는 더 안정적입니다.
이제부터 intro에 마지막에 언급한 2개의 아이디어에 대해서 자세하게 설명드리도록 하겠습니다.
Negative Mining (핵심 아이디어 1)
처음에는 같은 trajectory 내에서만 이미지 쌍을 학습에 썼더니, 학습 분포와 실제 평가 분포가 다르기 때문에 모델이 잘 일반화되지 않았다고 합니다. 예를 들어, 실제 주행 중에는 서로 다른 trajectory에서 온 장면끼리 비교하게 되는데 학습은 같은 경로 내 이미지들만 보고 배운다면 그런 케이스를 경험하지 못한 채로 학습이 끝나버립니다. 즉같은 주행 궤적 안에서만 샘플링되면 모델은 늘 갈 수 있는 경우만 보게 되고 전부 positive pair (도달 가능)만 학습하니까 못 가는 경우(negative pair)를 구분할 경험이 아예 없게 되는 문제가 생깁니다.. 그래서 ViNG은 Negative Mining 기법을 도입했습니다. 서로 다른 trajectory에서 랜덤하게 관찰 쌍을 만들어 그 쌍에 대해 매우 먼 거리러 라벨로 주는 겁니다.이렇게 하면 모델은 여기는 절대 근처가 아니다를 명확히 구분할 수 있게 되고 그래프를 만들 때 잘못된 연결 이 줄어듭니다. 결과적으로, 이 음성 샘플링 기법은 거리 함수의 학습 안정성과 그래프 품질을 모두 향상시켰다고 합니다.
Graph Pruning (핵심 아이디어 2)
두번쨰 핵심아이디어인데요 이를 설명하기에 앞서위상그래프에 대해서 좀더 설명을드리면 학습된 ViNG은 거리 함수 T를 이용해서, 환경을 위상 그래프 형태로 표현합니다. 이 그래프의 노드는 이미지(관찰) 들이고, 엣지는 두 장면 간 이동 가능성(Traversability) 을 나타냅니다. 이 장면에서 저 장면으로 이동 가능하다면 그 둘을 엣지로 연결하는 방식이라고 보시면 좋을 것 같습니다. 그리고 엣지의 가중치는 거리 함수 T가 예측한 거리 값입니다. 결국 이 그래프는 비기하학적지도, 즉 실제 좌표계가 아닌 시각적 관계만으로 구성된 지도라고 보시면 됩니다.
이제 여기서 문제는 로봇이 경험을 쌓을수록 노드가 많아져서 그래프가 너무 복잡해진다는 점입니다. 노드가 N개면 엣지는 N²개로 늘어나게 되는 문제가 생깁니다.이를 해결하기 위해 ViNG은 임계값 기반 가지치기를 적용합니다. 예를 들어 예측된 거리 값이 너무 작으면 너무 가까워서 굳이 그래프에서 관리할 필요 없으니깐 해당 엣지를 그래프에서 제외하는 것입니다. 연속된 이미지 시퀀스에서 한장면의 바로 다음 이미지 시퀀스는 너무 거리가 짧기 때문에 컨트롤러가 직접 이동할 수 있는 짧은 거리라면 엣지를 제거해 버립니다. 이렇게 하면 불필요한 간선이 줄고,그래프 탐색 속도도 빨라지며, 경로 계획 시 계산 효율이 크게 향상됩니다.
결과적으로 이 위상그래프에서 로봇이 플래닝을 어떻게 하는지를 설명을 드리면 실제 주행 시 로봇은 현재 관찰o_t 와 목표 관찰 o_G 를 만들어둔 위상 그래프에서 각각 대응되는 노드로 localize 합니다.이후 Dijkstra 알고리즘을 이용해 두 노드 사이의 최단 경로를 계산합니다. 그리고 그 경로 상에서 바로 다음에 갈 노드(=웨이포인트)를 선택해서 컨트롤러에게 전달합니다.이 과정을 반복하면서 로봇은 점진적으로 목표 이미지에 가까워지는 방향으로 이동하게 됩니다. 그럼 어떻게 이동하는지 설명을 드리면 위의 플래너가 다음 웨이포인트 이미지를 주면 이제 제어기는 실제 로봇이 그 방향으로 움직이도록 명령을 내려야 합니다. 문제는현재 상태와 웨이포인트 모두 이미지라는 점입니다. 즉, 좌표가 없기 때문에 이 방향으로 몇 도 회전해라를 바로 계산할 수 없습니다. 이를 해결하기 위해 ViNG은 method 서두에 잠깐 언급헸던 상대 자세 예측기(Relative Pose Predictor, P) 를 따로 학습합니다. 이 모델은 두 이미지 (o_i, o_j) 를 입력으로 받아 o_j 가 o_i 기준으로 어느 방향에 있는가? 를 예측합니다.
P(o_i, o_j) \Rightarrow \Delta p_{ij} = \{\Delta x, \Delta y, \Delta \theta\}
이렇게 예측된 상대 자세는 로봇의 실제 주행 센서(odometry)와 함께 PD 제어기로 전달되어 실제 로봇이 웨이포인트 쪽으로 이동하게 됩니다.
즉, 아래 처럼
- 현재 이미지 o_t와 웨이포인트 이미지 o_{wp} 입력
- P가 방향과 거리(상대 자세) 예측
- PD 제어기로 이동 명령 생성 이 과정을 반복합니다.
마지막으로 T와 P네트워크 구조 와 학습과정에 대해서 설명을 드리겠스비다. T,P 두 모듈은 MobileNet 인코더를 공유합니다. 하나의 인코더에서 시각적 특징을 추출한 뒤,이 특징 벡터를 각각의 목적에 맞게 나눠서 사용하는 구조인 것 같습니다.
먼저 T 같은 경우는 MobileNet 기반 인코더를 통해 입력 이미지 쌍을 1024차원의 벡터로 인코딩한 뒤, 이를 3개의 fc layer에 통과시켜 50개의 클래스(label)을 내뱉게끔 합니다. 즉, 두 장의 이미지가 얼마나 떨어져 있는지를 50개의 거리 구간(bin) 으로 나눈 후, 각 구간의 확률을 예측하도록 설계했다고 보시면 될 것 같습니다. 각 bin의 확률 분포를 예측하도록 Cross Entropy Loss을 최소화하는 방식으로 학습합니다. 이는 실제 거리 값을 regression하는 대신 classification문제로 바꿔 예측하게끔 하는 방식으로 동작한다고 이해하시면 좋을 것 같습니다.
P의 구조도 마찬가지로 MobileNet 인코더 뒤에 3개의 Dense layer 가 붙은 형태이며, 출력은 3차원 벡터 {\Delta x, \Delta y, \Delta \theta} 입니다. 즉, 현재 시점 이미지와 웨이포인트 이미지 사이의 상대 이동 거리(translation)와 회전(rotation)을 직접 회귀 형태로 예측합니다. 요약하자면, T는 두 장면이 얼마나 떨어져 있는가를 예측하고, P는 그 방향으로 얼마나 움직여야 하는가를 예측하게끔 한다고 보시면 될 것 같습니다.
그리고 탐색 가능성 함수 T는pos 데이터(D^+) 와 neg 데이터(D^-) 를 함께 사용합니다. D^+ 는 같은 trajectory 내의 관찰 쌍 (실제로 이동 가능한 관계)이고 D^- 는 서로 다른 trajectory에서 샘플링된 쌍 (이동 불가능한 관계) 입니다. T는 이 두 데이터셋을 합친 D^+ ∪ D^- 로 학습이 진행되고 반면,상대 자세 예측기 P는 오직 pos 데이터(D^+)만 사용합니다. P는 이 라벨을 기반으로 \ell_2 regression loss를 최소화하면서 두 장면 간의 상대적인 위치 변화를 학습합니다.
Experiments
드디어 실험 파트 입니다. 실험의 핵심 목적은 아래의 세 가지 질문에 답하는 것입니다.
Q1. 오프라인 데이터만으로 학습한 ViNG이 기존 방법들과 비교했을 때 얼마나 잘 작동하는가?
Q2. ViNG은 완전히 새로운 환경에서도 일반화와 adaptation이 가능한가?
Q3. ViNG의 제어기는 다른 설계 대안들과 비교했을 때 어떤 강점을 가지는가?
먼저 첫 번째 실험은 ViNG이 실제 환경에서 기존 방법들과 비교했을 때 어떤 성능을 보이는지를 평가한 부분입니다. 실험은 도시 지형(urban) 과 비포장 지형(off-road) 이 혼합된 실제 야외 환경에서 수행되었으며, 훈련에는 약 40시간 분량의 오프라인 데이터가 사용되었습니다. 수집된 이 오프라인 데이터는 10개월 전에 수집된 것으로, 계절 변화와 조명 차이 등으로 인해 외관이 상당히 달라진 상태였다고 합니다. 그래도 ViNG은 같은 장소이지만 완전히 다른 시각적 조건 속에서도 일관된 목표 도달 행동을 하도록 학습하는 모습을 보입니다.
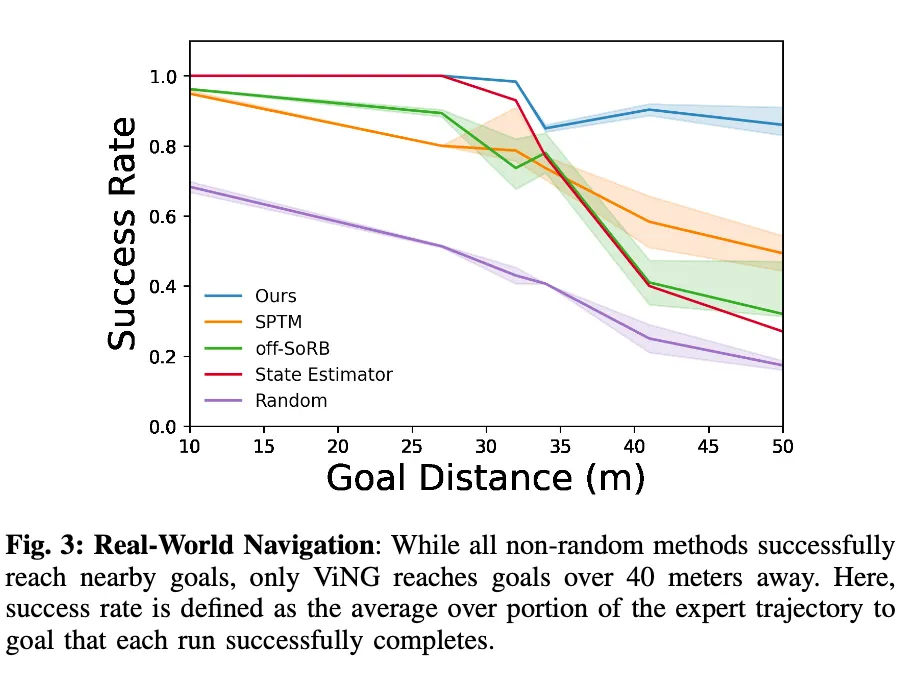
먼저 위 표를 보시면 ViNG은 모든 과제에서 가장 높은 목표 도달률을 기록하는 것을 확인하실 수 있습니다. 특히 40m 이상 떨어진 장거리 목표에서도 86%의 성공률을 보였습니다.

위는 실험 당시 실제 주행 경로를 시각화한 모습입니다.
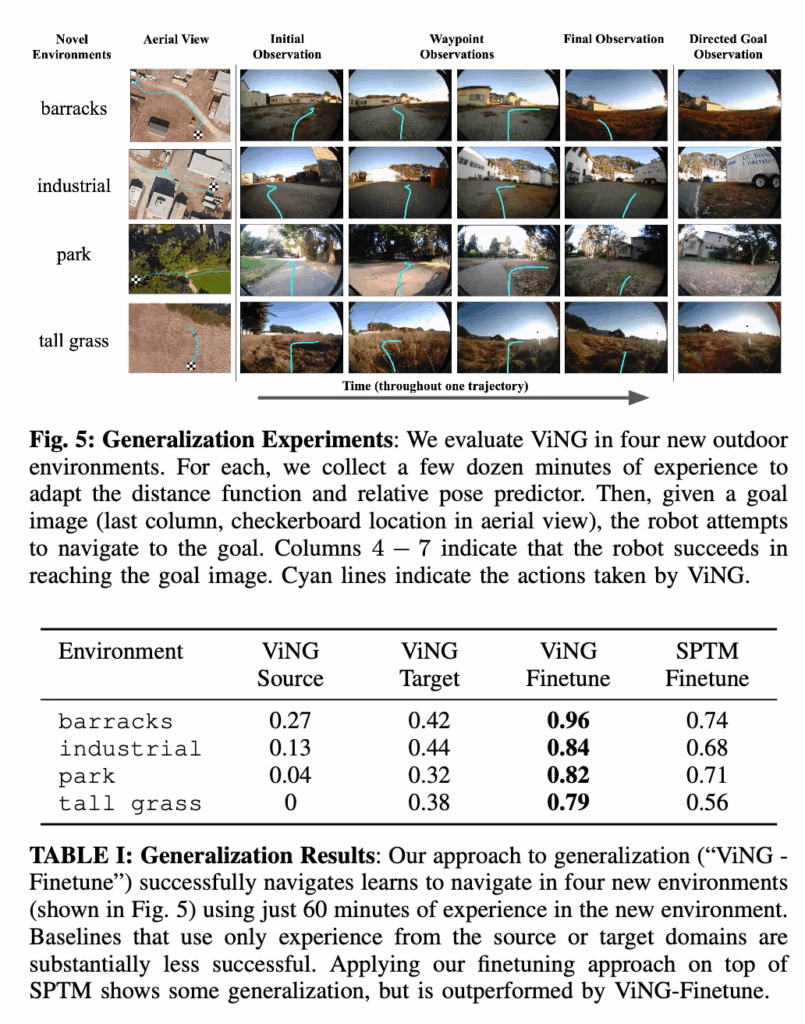
다음 실험은 ViNG이 새로운 환경에서 얼마나 빠르게 적응할 수 있는가를 평가한 부분입니다. 앞선 실험이 이미 본 환경에서 새로운 목표로 이동하는 문제였다면 이번은 완전히 보지 못한 환경(unseen domain) 에 대한 테스트입니다. 새로운 환경에서 ViNG은 처음부터 새로 그래프를 구성하고, 탐색 가능성 함수 T와 상대 자세 예측기 P를 파인튜닝합니다. 실험은 4개의 새로운 실외 환경에서 수행되었습니다. 먼저 각 환경에서 사람이 로봇을 조종해 초기 탐색 데이터를 수집합니다. 수집 한 데이터로 파인튜닝 한후 이후부터는 로봇이 스스로 이전 관찰 중 하나를 목표(goal) 로 설정하고,자율적으로 그곳으로 이동을 시도하고 한 에피소드가 끝날 때마다 새로 얻은 데이터(전문가 주행 + 자율 주행)를 모두 활용하여 모델을 점진적으로 업데이트 했다고 합니다.
결과적으로, 0분 → 20분 → 60분 으로 시간이 지날수록 로봇은 점점 더 안정적으로 목표를 찾아가게 되고 60분 후에는 모든 시도에서 성공적으로 목표에 도달하는 모습을 보입니다. Table 1을 보면 ViNG-Finetune 은 단일 도메인으로 학습된 ViNG-Source 나 새로운 환경만으로 학습한 ViNG-Target 보다 훨씬 높은 성공률을 기록했습니다. 즉, ViNG은 기존 경험(source) 과 새로운 경험(target) 을 함께 사용하는 파잍뉴팅하는 구조에서 가장 좋은 성능을 보였습니다.
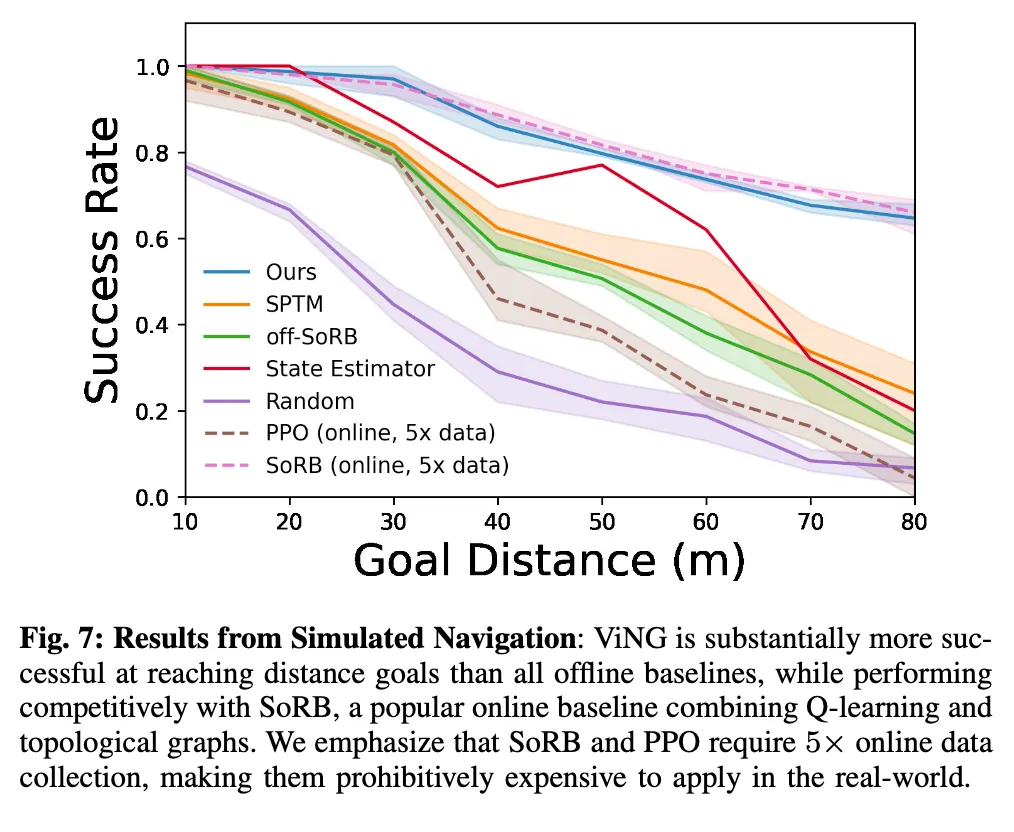
그 다음은 ViNG은 오프라인 데이터만 사용하지만 그렇다면 강화학습(RL) 기반의 온라인 기법들과 비교했을 때의 결과 입니다. 이 실험에서는 실제 환경이 아닌 Unity 기반의 포토리얼리스틱 야외 시뮬레이터 를 사용했다고 합니다. 이유는 실제 환경에서 온라인 RL을 학습시키기에 어렵기 때문이라고 합니다.
RL 기반의 PPO는 200시간의 데이터를 학습했음에도 불구하고, 장거리 목표에서는 거의 실패하는 모습을 보입니다. 이는 단순한 이미지 기반의 반응형 정책만으로는 장기 목표를 계획하기 어렵다는 점을 보여줍니다. RL기반의SoRB(Online)는 성능이 높았지만 ViNG과 비슷한 수준에 머물렀습니다. 근데 마찬가지로 SoRB는 200시간의 온라인 데이터가 필요했고 반면 ViNG은 40시간의 오프라인 데이터만으로 같은 성능을 냈습니다.이는 ViNG이 데이터 효율성 측면에서도 훨씬 좋다는 것을 보입니다.
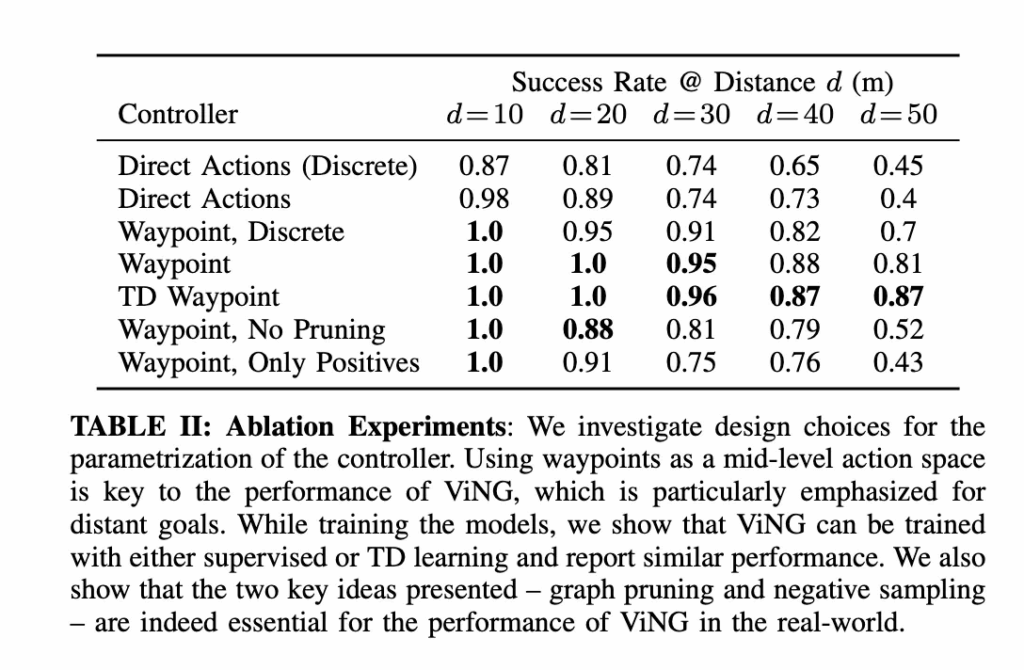
다음은 ablation study입니다.
Direct Actions / Direct Actions (Discrete)같은 경우는 위상 그래프 없이, 현재 이미지와 목표 이미지를 입력으로 직접 행동을 예측하는 단순 행동 모방 학습(behavior cloning) 모델이라고 생각하시면 좋을 것 같습니다.(즉, ViNG에서 ‘계획기(planner)’를 제거한 버전) 그리고 Waypoint, Discrete같은 경우는 동일한 웨이포인트를 사용하지만, 하위 제어기로 이산형(discrete) 행동 제어기를 사용한 모델(몇도 각도로 몇 만큼의 속도로 이동하고 하는 게 아니라 오른쪽으로가 왼쪽으로가 앞으로가 처럼 이산적으로 행동을 제어하는 모델)이고 TD Waypoint는 ViNG의 거리 함수 T를 지도 학습이 아닌 TD 학습(앞서 언급했던 시차 학습)으로 학습한 버전. 그리고 마지막으로 No Pruning / Only Positives은 Graph Pruning 또는 Negative Sampling 단계를 제거한 ablation 모델이라고 보시면 좋을 것 같습니다. 표를 보시면 결과적으로 웨이포인트 기반 중간 계획(mid-level action space)을 사용하는 ViNG이 장거리 목표에서 가장 안정적인 모습을 보이며 지도 학습과 TD 학습 간의 차이는 크지 않은 결과도 보입니다. 그리고 특히 Negative Sampling과 Graph Pruning을 제거했을 경우 장거리 성공률이 크게 떨어지는 모습을 보입니다. ViNG의 두 핵심 아이디어 Negative Sampling 과 Graph Pruning 이 실제 성능에 결정적인 기여를 한다는 사실이 보이는 실험결과입니다.

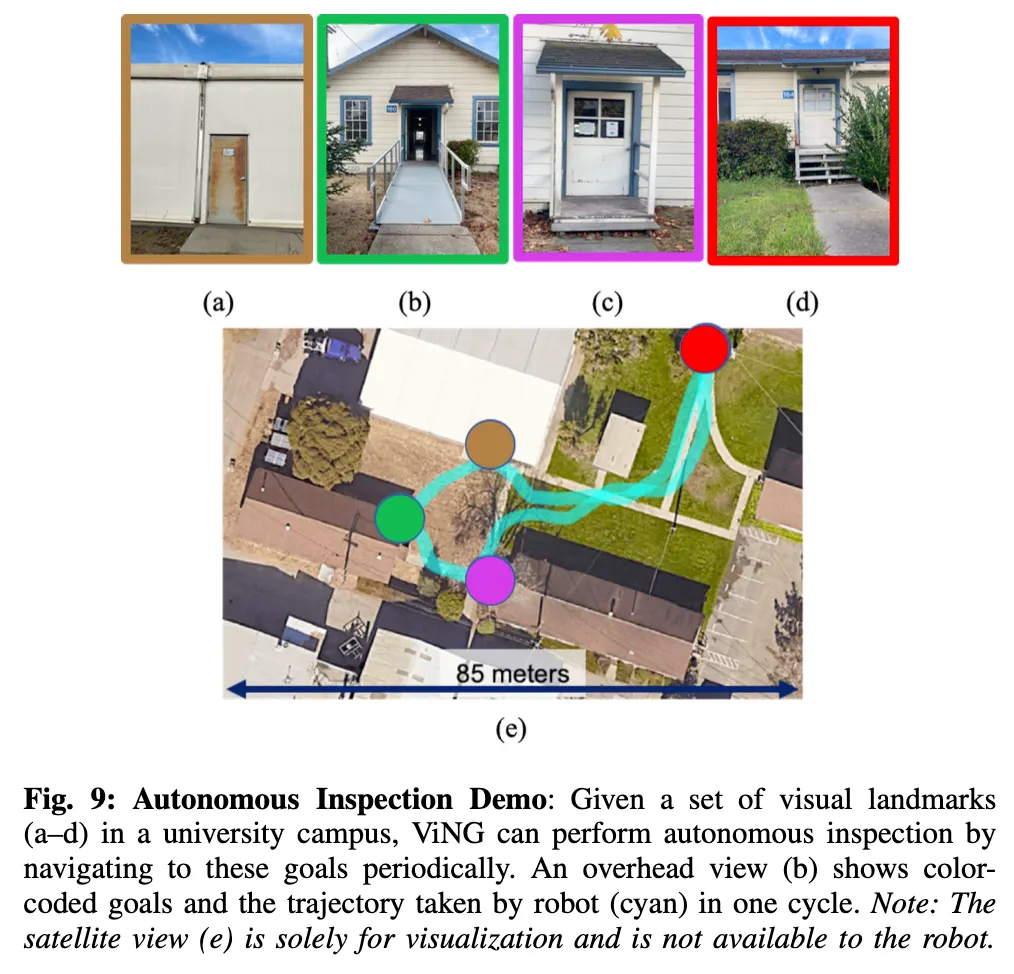
마지막으로 ViNG의 실제 응용 가능성을 보여주는 시연결과를 논문에 제시가 되어있었습니다. 이 시연을 통해서 ViNG은 지도나 GPS 없이도 오직 시각 정보만으로 움직임에도 일상적인 환경에서도 실용적인 자율 내비게이션이 가능하다는 점을 보입니다.
Fig 8의 비대면 라스트마일 배송 (Contactless Last-Mile Delivery)시연 인데 사용자가 단순히 도착지의 사진 한 장만 찍어 로봇에 전달하면, ViNG은 그 이미지를 목표로 인식하고 도시 환경 내에서 스스로 이동하여 패키지를 전달(deliver) 하는 모습을 보입니다. 그리고 fig 9같은 경우는 자율 순찰 및 점검 (Autonomous inspection) 시연인데 정확한 위치 정보가 없는 복잡한 건물이나 캠퍼스 환경에서 ViNG은 주요 랜드마크 이미지를 목표로 지정하여 정기적으로 각 지점을 방문하며 상태를 점검할 수 있습니다. 이전 관찰과 새 관찰을 비교함으로써 환경 변화나 이상을 감지하는 데 활용할 수 있습니다. Figures 8과 9는 ViNG이 실제 도시 환경에서 이 두 응용 과제를 성공적으로 수행하는 모습을 보여줍니다.
결론
저자들도 언급하길 ViNG이 여전히 오프라인 관찰 데이터셋에 의존한다는 점이 해당 논문의 한계입니다. 즉, 한 번 수집된 데이터는 시간이 지나면 조명, 날씨, 혹은 주변 물체 변화 등으로 인해 실제 환경과 점점 달라질 수 있습니다. 이런 상황에서는 ViNG이 학습한 거리 함수나 그래프 구조가 현재 환경의 시각적 분포와 맞지 않게 된다는 문제가 생기게 되는데, 처음에는 오프라인 데이터셋으로 학습시킬 수 있다는 것을 논문에서 장점 처럼 얘기했지만 결론 부분에서는 이를 한계라고도 언급합니다. 온라인 데이터 셋이 일반화 측면에서 훨씬 성능이 좋아서 인가? 라는 생각이 들기도 합니다. 해당 논문은 새로운 신에 대해서 태스크 수행을 잘하기 위해서는 파인튜닝을 해야만하기 때문에 이러한 부분이 비효율적일 수 있을 것 같다는 생각이 듭니다. 추후 논문들을 읽어보면서 비슷한 문제에 직면했을 때 어떤 방법론을 제안했는지 많이 찾아보면서 인사이트를 넓혀나가야할 것 같습니다. 이만 리뷰 마치도록 하겠습니다.
안녕하세요, 우현님. 좋은 논문 리뷰 잘 읽었습니다.
특히 ViNG이 시각적 연결성을 기반으로 경로를 구성하기 때문에, 녹화된 관측 분포 내에서는 매우 안정적으로 동작한다는 점이 인상적이었습니다.
한 가지 궁금한 점이 있는데요, 리뷰에서 언급하신 것처럼 ViNG이 학습에 사용된 녹화 구간에서는 강건하게 동작하지만, 그렇다면 녹화 범위 밖의 새로운 장소에서는 성능이 크게 떨어지는지 궁금합니다. 또한 이러한 한계를 완화하기 위해 활용될 수 있는 대안적 접근법이나 개선 연구(생성 모델 활용 등)가 있는지도 여쭤보고 싶습니다.
좋은 리뷰 공유해주셔서 다시 한 번 감사드립니다.🚗
안녕하세여 기현님 댓글 감사합니다.
ViNG은 녹화된 데이터 분포 내에서는 매우 안정적이지만, 완전히 새로운 장소에서는 관찰 간 거리 함수(T)의 일반화 한계로 인해 성능이 급격히 떨어지지 않을 까 싶습니다. 이를 해결하기 위해 다양한 데이터를 활용하여 다양한 환경에 대해서 잘 동작할 수 있도록 일반화 성능을 높이거나, 학습으로 해결하는데 한계가 있다면 토폴로지 맵을 어떻게 잘 구성할지에 대한 연구를 하는 것 같습니다.
감사합니다.
안녕하세요 우현님, 좋은 리뷰 잘 읽었습니다!
최근 우현님의 리뷰들을 읽으면서 저도 topological map이 뭔지 점점 알게 되는 것 같아 흥미롭네요!!
간단한 궁금증이 있습니다. Graph Pruning의 T 네트워크에서, regression이 아닌 50개 클래스의 classification으로 학습하는 이유가 무엇인가요? 어떤 이점이 있어서 classification으로 푸는 건지 궁금합니다.
감사합니다!
안녕하세요 예은님 댓글 감사합니다.
일단 ViNG이 classification을 채택한 이유는 거리의 불확실성과 이동 가능성의 확률적 특성을 반영하기 위해서라고 보시면 정확합니다. 여기서 거리 불확실성이라고 하면 노드와 노드간의 거리는 step으로 모델이 정확한 거리를 예측하는 구조는 아닙니다. 현재관촬, 그리고 목표 관찰 이 두 관찰이 얼마나 reachable한가를 안정적으로 학습하는 데 있기 때문에 회귀방식은 모델이 항상 단일 값을 예측해야 하지만, ViNG의 경우는 거리의 분포를 예측하는 것이 더 합리적이기 떔누에 사용한 것 같습니다. 예를 들어, 두 관찰이 매우 가까우면 1~3 step 구간일 수도 있고, 중간 정도 떨어져 있으면 10~15 step 정도일 수도 있는데, 이런 메트릭 거리가 명확히 주어지지 않은 상태에서 모델이 자연스럽게 표현하려면 regression 보다는 이 이미지 쌍이 1~50 구간 중 어디에 속할 확률이 높은가를 예측하도록 하는 multi-class classification 구조로 해결하는 것이 합리적이어서 사용한 것 같습니다.
감사합니다.
안녕하세요 우현님, 자세한 리뷰 감사합니다!
저도 항상 인공지능과 사람의 길찾는 너무 동떨어져있다고 생각했는데
위 논문도 그 간극을 줄여보자는 의도가 잘 전달되었습니다.
수년전 간 곳도 몇가지 시각적 힌트만 주면 다시 기억해낼 수 있는
사람 두뇌의 성능이 새삼 대단하다는 것을 또 느낍니다.
한가지 궁금한 점이 있습니다.
결국 위 논문은 정보가 많아질수록 그래프가 많아지는 것을 pruning으로 완화했다고 얘기했습니다.
물론 pruning을 통해 더 깊은 그래프를 저장할 수 있어졌지만, 그럼에도 여전히 너무 작은 공간만 찾을 수 있는 느낌입니다.
혹시 후속연구나 요즘 연구에선 이 문제가 해결되었는지 궁금하여 질문드립니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
새로운 연구분야를 팔로우업 하고 있는 상황에서 나였으면 여기서 이러이러한 것을 추가해보고 싶다. 이건 왜 이렇게 안했을까 추가로 해보고싶은 실험설계 같은게 존재할까요? 저자가 GPS 나 거리등의 정보를 배제하고 인간의 시각적인 인지방식을 따라했다곤 하지만, 저런 실제 좌표와 같은 데이터값들도 주어진다면 충분히 사용할 수 있는 정보일텐데 만약 데이터가 동시에 주어진다면 지금 학습방식에서 추가적으로 보완할 수 있는 부분이 있을지 생각이 궁금합니다.
감사합니다.