안녕하세요, 오늘도 AVQA 관련해서 논문 팔로우업도 할겸, 읽어보게 된 논문을 들고왔습니다. 이후 AVQA 관련 논문을 적을때 어떤 figure 어떤 실험들이 필요로하게 될지 생각의 폭을 넓히기 위해서, Abstract 부분을 읽고 리뷰하게된 논문인데, AVQA가 부분적 task로 포함되어 있고 다른 4가지 task 를 포함하는 벤치마크를 제안한 논문으로 오디오와 비디오의 fine-grained 한 능력을 보기 위한 LLM 을 제안한 논문입니다.
그럼 리뷰 시작하겠습니다.
Abstract
저자는 LLM 의 능력을 활용해서 시각과 오디오와 같은 다른 모달리티로 연구들이 확장되는 것으로 논문을 시작합니다. 현재 연구되고 있는 LLM 들은 오디오-비주얼 의미를 coarse-grained 한 수준으로 이해하는 task 들로 이루어진 것을 지적합니다. 따라서 Meerkat 이라는 시공간적으로 세밀한 오디오-비주얼 이해능력을 갖춘 모델을 제안합니다.
해당 모델은 Optimal transport 라는 최적 수송? 기반 모달리티 정렬 모듈과, 오디오-비주얼 일관성을 강화하는 cross attention 모듈을 통해 3가지의 고난이도 작업을 수행할 수 있다고 어필합니다.
- 오디오를 기반으로 이미지를 찾는 audio-referred image grounding
- 이미지를 이용해 오디오 내에서 특정 시점을 찾아내는 image-guided audio temporal localization
- 오디오와 비디오를 동시에 검증하는 audio-visual fact-checking
또한 저자는 공개 데이터셋들을 수집하여 300만개의 instruction-tuning 샘플들로 구성된 대규모 데이터셋 AVFIT 을 구축했고, 다섯 가지의 어려운 오디오-비주얼 task 들을 통합한 벤치마크인 Meerkatbench 를 제안한다고 합니다.
저자의 Meerkat은 모든 다운스트림 과업에서 SOTA를 달성했다고 어필학고 최대 37.12의 상대적 성능 향상을 보였다고 합니다.
Introduction
대규모 언어모델(LLM) 은 다양한 자연어 처리 과업에서 뛰어난 성능을 보여줬으며, 이해력과 추론 능려 ㄱ면에서 인간 수준의 정확도를 달성했다고 합니다.
또한 최근에는 명령어 기반 미세조정 패러다임을 통해 개방형 자연어 지시를 따를 수 있게 됐고, 더 나아가 시각과 같은 다른 모달리티와도 결합될 수 있다고 합니다. 오디오는 시각 장면과 밀접하게 연관되어 있음에도 불구하고, LLM 연구 맥락에서는 거의 탐구되지 않았다고 합니다. 소리를 들을 수 있는 다중모달 LLM을 구축한다면, 멀티미디어의 콘텐츠 분석이나 멀티모달 가상 비서, 교육 및 훈련 등 다양한 응용이 가능해질 것이라고 합니다. 앞서 존재했던 일부 선행 연구들이 존재하기는 했으나 주로 자막 생성이나 질의응답(QA) 와 같은 coarse-grained task 에 초점이 맞추어져있었고 이는 LLM 인터페이스로 통합하기에 상대적으로 쉬운 작업들입니다. 또한 이런 모델들이 오디오-비주얼 사건에서의 세밀한 정보를 포착하지 못하는 한계가 있어서 저자는 강력한 추론 능력을 세밀한 수준의 오디오-비주얼 이해로 확장하는 것을 목표로 했다고 합니다.
이러한 목표가 2가지 이유로 어렵다고 밝히는데
- 서로 다른 task 간에 입력/출력 형식의 차이가 크다 ( 오디오로부터 이미지 grounding, 이미지로부터 오디오 시점 localization 등)
- grounding 기능을 학습할 수 있는 대규모 오디오-비주얼 데이터셋이 존재하지 않는다.
기존의 오디오-비주얼 LLM 들은 coarse-grained 수준의 과업에 제한되어 있어 모달리티 간의 융합을 포함하지 않았고, 모달리티 간의 융합은 fine-grained 의 이해 및 추론을 위해 필수적인 요소입니다.
기존에 존재하는 모델중 image grounding 이 가능한 BuboGPT 나 temporal localization 이 가능한 TimeChat 이 존재했지만 각각 open-domain audoi 에 적합하지 않거나 end to end로 학습되지 않았다는 점을 단점으로 언급합니다.
이러한 상황에서 Meerkat 이라는 이미지와 오디오 모두에서 각각 공간적, 시간적 grounding 을 수행할 수 있게한 최초의 통합 오디오-비주얼 LLM 프레임워크를 제안합니다.
앞서 Abstract에서 간단하게 언급한 Meerkat의 세밀한 이해능력을 가능하게 한 핵심 구성요소는 다음과 같습니다.
- 이미지-오디오 패치 간의 상관관계를 optimal transport 기반으로 약하게 지도하는 모달리티 정렬 모듈
- 두 모달리티 간의 attention 을 일관되게 유지시키는 cross modal attention 모듈

저자는 또한 MeerkatBench 라는 meerkat의 학습 및 평가를 위한 벤치마크를 제안합니다. 총 5가지 오디오-비주얼 task를 통합한 평가용 벤치마크이며 위의 figure 는 각각 task 에관련된 내용을 담고 있습니다.
- 오디오 기반 이미지 grounding
- 이미지 기반 오디오 localization
- 오디오-비주얼 fact check
- 오디오-비주얼 QA
- 오디오-비주얼 캡셔닝
으로 구성되어 있습니다.
이러한 과제를 수행하기 위해 저자는 다양한 난이도를 포함한 300만개의 instrruction-tuning 샘플들로 구성된 댁규모 데이터셋 AVFIT 을 구축하고 학습시켰습니다.

다음은 기존에 존재하는 LLM 들과 비교하기위한 Table 입니다. Table 에 적힌 내용에서 Convention 이란 기존에 존재하는 공개 멀티모달 데이터셋을 그대로 쓰는 게 아닌, LLM 이 이해할 수 있는 instruction 포맷으로 가공하여 사용했는지 여부입니다.
여기서 기존 데이터셋은 보통 파일과 그 파일이 어떤 형태인지에 대한 라벨이 존재할텐데, 모델 입장에서 이러한 형태를 이해하는 문장 구조가 아니다보니 템플릿 형태로 감싸서 instrruction + input + expected output 구조로 바꾸어사용하는 것입니다.
EX :
{
audio : dog barrking → label “dog ”
}
에서
{
Instruction “ what animal is making the sound in this audio clip? “
input : (audio file)
Answer : “ A dog is barking.”
}
이렇게 하면 LLM 은 마치 사용자가 물어보는 지시문에 대해 응답을 생성하는 구조로 멀티모달 데이터를 학습할 수 있다고 합니다. 우측의 GPT-prompted 가 GPT-4/3.5 등을 이용해서 데이터를 생성했는지 여부를 확인시켜주는 부분입니다.
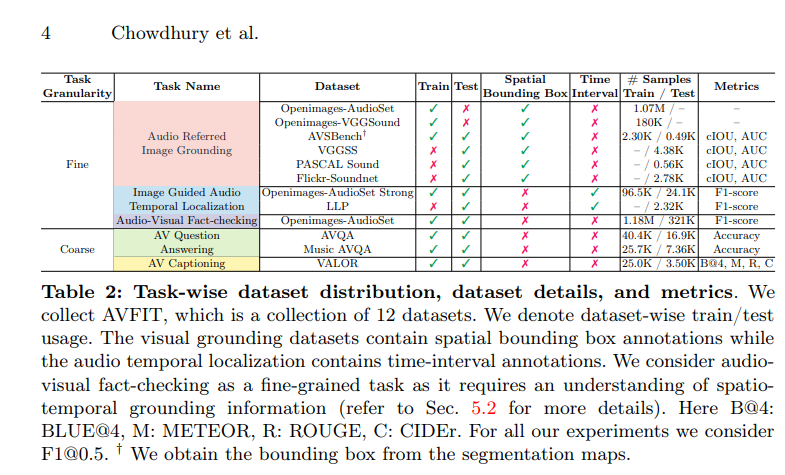
다음은 Meerkat 이 사용하는 AVFIT 데이터셋의 세부 구성으로 총 12개의 데이터셋과 태스크별 지표를 정리한 표입니다. 어떻게 train/test 로 나누었는지나 어떤 어노테이션 형식을 가졌는지, 어떤 metric 을 사용했는지가 정리되어 있습니다.

해당 figure 는 전체 파이프라인으로 입력인 이미지와 오디오 텍스특가 두 단계의 정렬 모듈을 거친 뒤 LLM (Llama 2) 으로 통합됩니다.
우선 B 라고 표기되어 있는 AVOpT 인 Audio-visual Optimal Trasport Alignmet 모듈은 이미지와 오디오의 로컬 특징을 약하게 정렬시켜 두 모달리티가 동일한 의미적 공간으로 들어오게 만드는 단계입니다.
A 라고 표기되어 있는 AVACE 인 Audio-Visual Attention Consistency Enforcement 모듈은 앞서 AVOpT로 약하게 정렬된 rerpresentation 을 바탕으로 LLM 의 cross-attention map 이 실제 물체 영역에 집중하도록 하는 모듈입니다.
세 모듈의 latent token 들을 결합해 하나의 prompt 로 입력하여 LLM 이 downstream task 를 공통 형식으로 출력하게 되고 LoRA 를 통해 튜닝하게 됩니다.
Method
Multi-modal Feature Extraction
Image Encoder 로는 사전학습된 CLIP ViT-B/16 을 사용했다고 합니다.
입력 :
출력 :
여기서 는 image tokens 수이며
는 hidden 차원수입니다.
Audio Encoder 로는 사전학습된 CLAP ( Audio Transformer) 를 사용해 시각-주파수 스펙트로그램을 입력으로 사용한다고 합니다. 주파수 축의 구성 요소 개수 와 시간축 구간수
를 갖습니다.
입력 :
출력 :
여기서 값은 오디오 토큰개수입니다.
Text Encoder 로는 Llama 2-chat (7B) 기반 을 사용했고, 모든 모달리티 임베딩의 차원을 맞추기 위해 linear projection layer를 삽입하게 됩니다.
텍스트 임베딩 :
여기서 은 Llama 2의 tokenizer 이며
는 텍스트 토큰의 길이입니다.
AVOpT (Audio-Visual Optimal Transport Alignment)
목적은 CLIP 과 CLAP 이 각각 다른 의미 공간에 있기 때문에, 패치 단위 분포 정렬을 수행합니다. 그 과정으로 Optimal Transport (OT) 기반의 Wasserstein 거리 최소화를 수행한다고 합니다.
주어진 이미지-오디오 쌍 (I,A) 로부터, 각각 패치단위 임베딩을 추출합니다.
이미지와 오디오 패치 임베딩은 각각 확률분포로 표현된닥고 합니다.
여기서 는 각각의 확률분포에서 패치별 중요도를 나타내는 가중치 벡터이며 다음 조건을 만족합니다.
두 확률분포 간의 geometric 한 이동 비용을 최소화하는 OT 문제는 다음과 같습니다.
여기서 는 Transport plan 으로 이미지 분포
의 확률 질량을 오디오 분포
로 옮기는 최적 매핑을 의미한다고 합니다. 각 패치간 거리는 코사인 거리로 정의됩니다.
AVACE (Audio-Visual Attention Consistency Enforcement)
AVOpT 가 patch 수준의 약한 정렬을 담당했다면, AVACE 는 region 수준의 강한 정렬을 수행합니다. 이를 통해 오디오와 이미지가 동일 객체 영역에 집중하도록 합니다.
이미지 및 오디오 임베딩을 입력으로 받아 CrossAttention 을 계산합니다.
객체의 실제 위치를 나타내는 bounding box 를 마스크로 정의하게 되고 AVACE 에서 attention map 이 객체 내부에서는 커지고, 배경에서는 작아지도록 손실을 구성했다고 합니다.
여기서 로 설정하며 이 loss 는 LLM 이 주목해야할 객체 영역의 attention consistency를 높이는 역할을 하게 됩니다.
Overall Training Objective
meerkat 의 최종 학습 목표는 세가지 손실의 조합으로 정의됩니다.
훈련절차는 다음과 같습니다.
- 이미지 오디오 텍스트 임베딩 추출
- AVACE 를 통해 오디오-비주얼 어텐션 계산
- 모든 모달리티 임베딩을 결합
- LLM 으로 예측 수행
- 세 손실을 통해 최적화
LLM 은 텍스트 기반 모델이기 때문에, Meerkat 은 시각적 위치(bounding box) 와 시간 구간(time segment) 를 자연어 시퀀스 안에 수치값으로 직ㄱ접 삽입하여 표현합니다. 각 객체의 위치는 좌상단-우하단 좌표로 표현되고 값은 이미지 크기로 정규화됩니다.
이 표현은 입력 시퀀스나, 출력 시퀀스 중 하나에 포함될 수 있습니다.
Audio Referred image Grounding 에서는 Meerkat 이 box 를 예측 (output)
Audio-Visual Fact Checking 에서는 box가 입력(input) 으로 주어집니다.
오디오의 이벤트 발생 구간은 시작-종료 시간으로 표현됩니다.
이 역시 태스크에 따라 입력 또는 출력으로 사용됩니다.
Image-Guided Audio Temporal Localization 에서는 모델이 시간 구간을 예측
Fact-Checking 에서는 해당 구간이 텍스트에 포함됩니다.
MeerkatBench : A unified Benchmark suite for Fine-grained Audio-Visual Understanding
MeerkatBench 는 meerkat 모델의 성능을 검증하기 위해 새롭게 제안된 벤치마크로, Fine-grained Audio-visual 이해 능력을 통합적으로 평가하도록 설계되었습니다.
앞서 언급했듯이 최근 LLM의 멀티모달 대화 능력이 자연어 이해를 넘어 시각적 청각적 문맥까지 포괄하여 주목을 받고 있ㅈ지만 기존 연구들이 주로 Vision-Language task 에서도 QA 나 captioning 에 집중되어 있어 오디오 영역으로 확장한 연구가 아직 부족한 상태라고 합니다. 나아가 Fine-grained 수준의 멀티모달 추론은 훨씬 복잡한 영역이며 이러한 태스크를 위한 공개 데이터셋 또한 존재하지 않습니다.
저자는 이러한 상황에서 5가지 태스크로 구성된 오디오-비주얼 통합 벤치마크를 제안하고 그중 Fine-grained task 3개와 coarse-grained task 2개를 구분합니다.
Fine-grained Tasks
- Audio Referred Image Grounding (ARIG) 주어진 오디오 신호에 해당하는 객체의 이미지 내 위치를 찾는 태스크입니다. $[x_{\text{Left}}, y_{\text{Top}}, x_{\text{Right}}, y_{\text{Bottom}}]$ 출력 bounding box 좌표입니다.
- Image Guided Audio Temporal Localization (IGATL) 주어진 이미지가 묘사하는 이벤트가 오디오 내에서 언제 발생하는지를 찾는 태스크입니다. $[t_{\text{Start}}, t_{\text{End}}]$ 출력은 시간 구간입니다.
- Audio-Visual Fact Checking (AVFC) 주어진 이미지-오디오-문장 조합이 사실인지 검증하는 과제입니다. Fine-grained grounding 정보를 필요로 합니다.
Coarse-grained Tasks
- Audio-Visual Question Answering (AVQA) 오디오 및 이미지 문맥을 기반으로 주어진 질문에 텍스트로 답변하는 과제입니다.
- Audio-Visual Captioning (AVC) 주어진 오디오-이미지 입력으로 전체 장면을 설명하는 문장을 생성합니다.
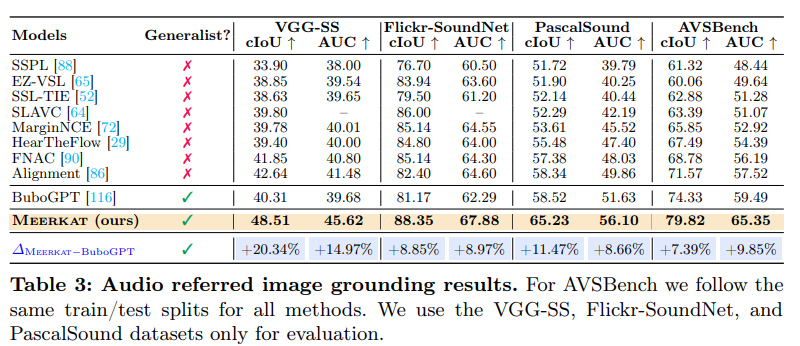
다음은 오디오 신호에 해당하는 객체를 이미지에서 찾아 bounding box로 localize 하는 task의 Table 성능입니다. 즉 소리가 나는 객체를 정확히 찾을 수 있는지를 보여주며 cIoU 는 centered IoU 로 기본 IoU에 박스 중심점 위치 오차까지 반영한 지표입니다. AUC 는 Area Under Curve 로 높을수록 localization 정확도가 좋은 것입니다.
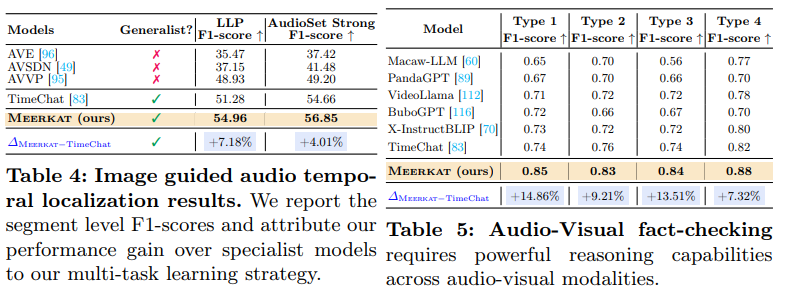
실험 4는 이미지를 단서로 삼아 오디오 속 이벤트가 언제 발생하는지 찾는 taks 에 대한 성능입니다. 평가 지표는 F1-score 로 precision 과 recall 의 조화평균값입니다. (둘 다 반영하는 지표라 생각하면 됩니다.) 이 결과를 두고 오디오-비주얼 patch alignment 가 temporal consistency 향상에 기여했다고 합니다. 실험 5는 오디오-이미지-문장 조합이 사실인지 거짓인지를 판별하는 것으로 단순 분류가 아닌 시공간적 추론이 필요합니다. 여기서 얘기하는 각 Type 1~4는 각각 이렇습니다.
Type1. 객체가 오디오 소리를 내는가
Type2. 오디오에 해당하는 시각적 객체가 이미지에 존재하는가
Type3. 객체가 특정 시간 구간 내에서 해당 소리를 내는가
Type4. 오디오가 bbox 내 객체와 연관이 있는가
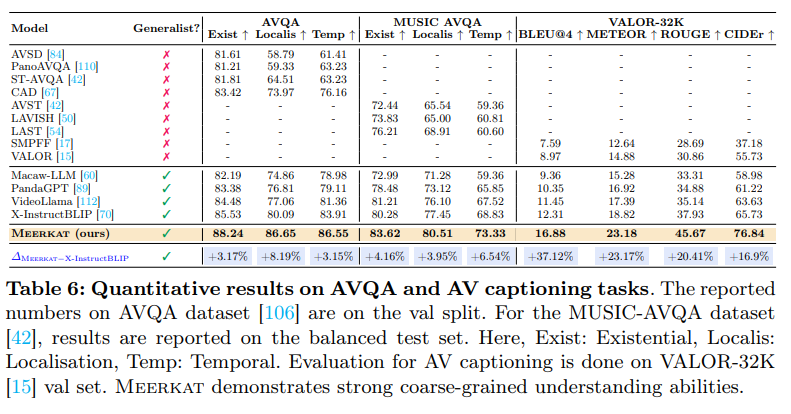
실험 6 은 Meerkat 이 AVQA 와 AV captioning 에서 strong coarse-grained 이해능력을 가졌다고 주장하며 다른 모델들에 비해 상대적으로 높은 성능을 보입니다.
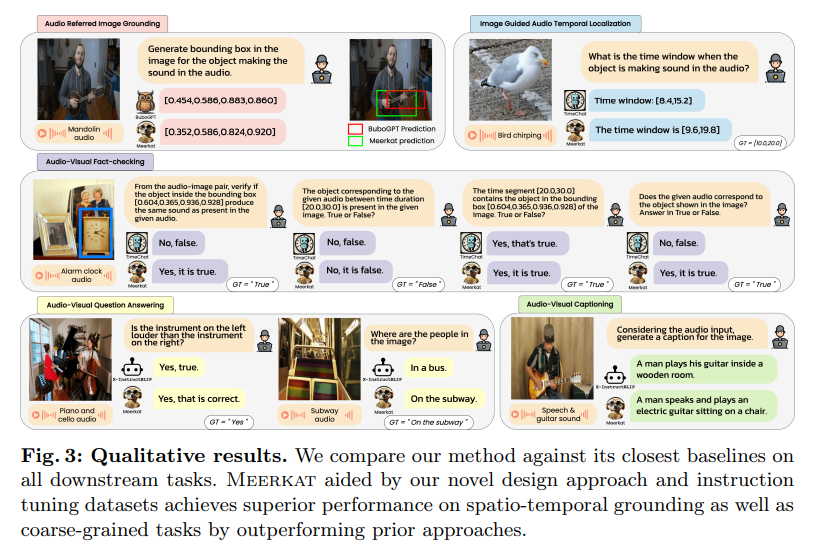
해당 figure는 Table3~6 에 보인 결과를 시각적으로 보여주는 예시입니다.
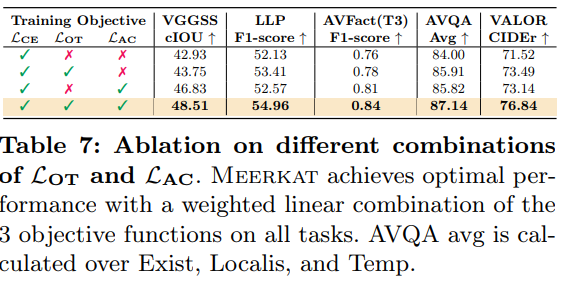
해당 실험은 저자가 제안한 Loss 구성으로의 ablation으로 이전에 실험했던 각 Table 들의 성능을 loss 구성으로부터 진행하여 저자의 loss 설계를 뒷받침하고있습니다.
Conclusion
저자는 Meerkat 이라는 오디오-비주얼 입력으로부터 세밀한 시공간적 이해를 가지는 대형 LLM 을 만들었고 2가지 모듈의 능력을 실험적으로 증명하고 5가지 task를 통합한 meerkatBench를 제안했습니다. 생각보다 contribution이 많고 뒷받침할 실험들이 엄청 많아서 놀랐습니다.. 큰 Table로 큼직한 실험들을 보여주고 Appendix에 image-audio 유사도나 오디오 샘플들의 평균 시간, 등 총 40page에 달하는 논문을 작성해 이러한 논문을 작성하려면 도대체 시간을 얼마나 쓰고 얼마나 많은 실험을 해야하나 싶은 논문이었습니다. 하이퍼 파라미터에 대한 튜닝이나 LoRa 의 하이퍼파라미터 ablation, 데이터셋의 세부 분포등을 추가적으로 확인하고싶다면 Appendix를 참고해주시면 되겠습니다. 감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
논문에서는 fine/coarse-grained의 분류 기준이 혹시 나와있었는지가 궁금합니다.
제가 해당 분야에 대한 지식이 많이 없어서 드리는 질문일 수 있겠는데 예를 들어 소리가 나는 곳에 있는 객체는 무엇인지 찾는 질문같은 경우 bounding box나 temporal cue를 필요로 하므로 fine-grained reasoning으로도 볼 수 있을 것 같은데 이런 경우 어떤 기준으로 coarse/fine을 나누셨는지 알고 싶습니다.
감사합니다.
안녕하세요 우현님 답글 감사합니다.
저자가 제안한 5가지 task 중 3가지의 fine-grained tasks 는 단순히 multi modal의 요소를 고려하는 것 이상으로 지역적 패치레벨에서의 reasoning 을 요구하는 것 같습니다. grounding 적 요소나 localization 그리고 fact checking 의 task 도 multi modal 의 이해 + 객체의 위치등의 세밀한 정보를 필요로 하여 fine 으로 나눴다고 할 수 있습니다.
감사합니다.
인택님 안녕하세요 좋은 리뷰 감사합니다.
큰 모델을 학습시키는 것이, 리소스 뿐만 아니라 고려해야할게 참 많음을 알게해주는 논문인 것 같습니다.
1. 표 1에서 데이터셋별 비교를 하며 GPT-Prompted와 Robustness를 한 열로 만들어 강조하고있는데, GPT-Prompted는 왜 표시해둔건가요? 이에 대한 효과를 같이 저자가 언급했는지 궁금합니다. 그리고 Robustness는 유일하게 meerkat에만 표시되어있는데 무엇을 의미하는것인지도 궁금합니다.
2. AVQA를 수행하기 위해 지금처럼 거대 모델을 학습시키는 경우도 있고, 직전에 리뷰하셨던 논문 처럼 소규모 모델을 학습시키는 경우도 있습니다. 본 리뷰에서도 이를 ‘Generalist’라고 칭하는 것으로 보이는데, 연구를 직접 수행한다는 측면에서 두 갈래의 장단점을 생각해보셨는지도 궁금합니다.
안녕하세요 현우님 답글 감사합니다.
우선 GPT-Prompted 는 Instruction Generation 에 GPT 를 사용했는지 여부를 알려주는 부분이며 이에 대한 효과를 알려주기보단 기존 데이터셋들은 coarse-grianed 수준의 설명만 포함했기에 저자의 AVFIT 학습용 데이터셋을 구축할 때 LLM 을 사용하여 instruction 다양화를 시도했는지 알려주기 위합입니다.
그리고 Meerkat 만 fine-graiend 환경에서의 cross modal alignment 를 평가했기에 Robustness를 유일하게 체크했다고 할 수 있습니다.
2번째 질문에 대한 대답으로는 성능에 대한 측면이나 새로운 task 를 제안할건지, 데이터셋을 고정해서 사용할건지, 연구실 환경이 가능한건지 여러 요소를 고려하게 하는 부분인 것 같습니다. 범용 모델을 재학습하는 과정이 아무리 LoRA 를 사용한다 하더라도 데이터셋의 규모가 크니 더 부담이 될 것이고, 처리하는 task 개수가 늘어남에 따라 더 범용적인 부분에서의 모델 설계가 필요할 것 같고, 소규모 모델을 파인튜닝하는 과정에서는 타겟으로하는 task에 대해 좀더 구체적인 문제정의를 하여 해당 부분을 증명하면 될 것이라 생각해서 접근하기에는 좀더 편하지 않나 싶습니다.
감사합니다.