안녕하세요. 오늘의 X-Review는 25년도 CVPR에 게재된 VisionZip이라는 논문입니다. 제목에서도 알 수 있듯 VLM의 vision token efficiency와 관련된 논문이며, 개인적으로는 VisionZip의 방법론 자체도 좋지만 이 방법론의 필요성과 효과에 대한 설득력이 좋다고 느껴져 정리해보게 되었습니다. 바로 리뷰 시작하겠습니다.

1. Introduction
Qwen-VL, LLaVA-1.5, LLaVA-NeXT와 같은 VLM이 어떻게 만들어지는지 먼저 간단히 설명드리겠습니다. 기본적으로는 이미 학습되어있는 LLM(GPT, Qwen, LLaMA 등)의 decoder를 활용합니다. LLM decoder 그 자체만으로는 자연어를 입력받아 올바른 자연어 출력을 만들어내는 능력을 갖추고 있습니다. 아직 이미지를 해석하고 이해하는 능력은 없는 것이죠.
이러한 LLM decoder를 vision-aware하게 바꾸기 위해 아래와 같은 과정을 거칩니다. 처리하고자 하는 이미지에 대해, CLIP이나 SigLIP과 같은 비전 인코더로부터 비전 토큰을 얻어줍니다. 이 비전 토큰들을 MLP 등과 같은 간단한 projection layer에 통과시킨 뒤 LLM decoder에 자연어 토큰과 함께 입력해주고 원하는 답변이 나오도록 여러 단계에 걸쳐 학습하는 것입니다. 그럼 이제 LLM decoder도 비전 토큰이 자연어 토큰과 함께 들어왔을 때 이게 무슨 의미인지, 어디를 중점적으로 봐야하는지 알 수 있게 되는 것입니다.
그러나 이 과정에서 엄청나게 많은 개수의 비전 토큰이 처리되며 많은 연산량 및 메모리 소모를 요구합니다. 예를 들어 LLaVA-1.5는 한 이미지를 576개 토큰으로, 또 LLaVA-NeXT는 672\times{}672 해상도의 이미지를 2,880개 토큰으로 만들어 처리합니다. 이 숫자가 많은건가 싶으실 수도 있지만, 같이 넣어주는 자연어는 대부분 1회 입력에 100개도 안됩니다. 더 나아가 비디오라면 더욱 자세한 내용 이해를 위해 입력 비전 토큰은 선형적으로 늘어나게 되죠.
최근 다양한 분야에서 좋은 성능을 보여주는 VLM들이 자율주행이나 로보틱스 등 엣지 컴퓨팅 관점에서 발전하려면 효율화는 필수라고 볼 수 있고, 효율화를 위해 가장 먼저 “과연 이 많은 비전 토큰들이 모두 필요한가?”에 대해 고민해볼 수 있습니다.

물론 기존의 여러 연구에서, 이미 영상이 텍스트보다 훨씬 sparse함을 보여주었고 다들 알고계시겠지만, 저자는 VLM에도 동일한지 확인하기 위해 많이 사용되는 비전 인코더 CLIP과 SigLIP의 비전 토큰을 확인해봅니다. 위 그림 1은 각 인코더가 추출한 이미지의 비전 토큰 attention 분포를 보여줍니다. 우선 그래프를 통해 attention이 0에 가까운 토큰들이 엄청나게 높은 비율을 차지하고 있음을 볼 수 있고, 공간축에서 시각화해봐도 실제 못해도 0.1~0.2 이상의 attention 값을 갖는 토큰도 손에 꼽을만큼 적음을 알 수 있습니다. 앞선 질문에 대해, 이 결과를 통해 “비전 토큰의 대부분은 redundancy를 갖는다.”는 답변을 낼 수 있습니다. 그러니까 저 많은 비전 토큰들을 확 줄여도 괜찮겠다는 결론을 얻을 수 있는 것이죠.
저자는 그림 1에서의 관찰을 바탕으로 성능의 하락을 최소화하면서, 효율성은 최대화할 수 있는 방법론 VisionZip을 제안합니다. 비전 토큰 내 redundancy를 ‘잘’ 제거하여 Informative한 비전 토큰만 남기는 방법을 제안하고, 또 여러 실험을 통해 성능과 효율성 간 trade-off를 보여주는 것이죠. VisionZip 방법론은 text-agnostic하며 이미 학습을 마친 VLM에 붙입니다. 이때 VisionZip은 training-free 또는 fine-tuning 방식으로 적용될 수 있습니다.
Training-free 방식에서는 먼저 비전 인코더에서의 self-attention으로부터 얻은 토큰의 attention이 큰 순서대로 dominant 토큰을 추리게 됩니다. 이때 dominant token만 사용하면 정보 손실이 너무 크기에 dominant로 선택되지 않은 토큰(non-dominant)은 non-dominant 토큰 자신들 스스로와의 유사도를 기반으로 merge하고 LLM decoder로 자연어 토큰과 함께 넘겨주게 됩니다.
다음으로 fine-tuning 방식에서는, 앞서 training-free 방식에서 했듯 merging까진 동일하게 진행되지만, LLM decoder는 merge 되지 않은 전체 raw token을 기준으로 사전학습 되어있기에 임베딩 공간의 align이 일부 맞지 않을 수도 있습니다. 그래서 LLM decoder가 VisionZip 방식으로 merge된 적은 개수의 비전 토큰에도 적응할 수 있도록 정합을 맞춰주는 30분짜리 소규모 fine-tuning을 해주는 것입니다.
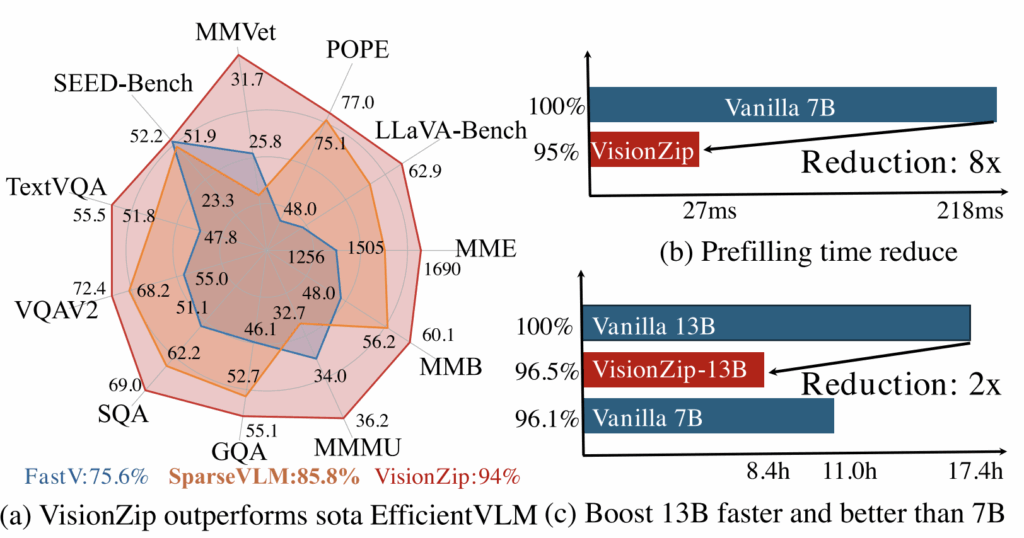
위 그림 2를 통해 VisionZip 방법론의 우수함을 확인할 수 있습니다. 그림 2-(a)는 VisionZip(training-free)과 유사하게 VLM의 비전 토큰의 효율화를 핵심 method로 삼는 FastV, SparseVLM과의 벤치마크 성능 비교입니다. 동일 모델에 대해 VisionZip이 다른 효율화 방법론에 비해 가장 높은 성능을 유지하는 것을 볼 수 있습니다.
다음으로 그림 2-(b)는 모델의 prefilling time을 보여주고 있습니다. VLM은 답변을 ‘generate’하고, 실제 이 generate는 (‘입력된 비전 토큰’ + ‘자연어 토큰’ + ‘지금까지 모델이 만들어 낸 답변 토큰’)을 입력하여 한 단어씩 만들어내는 ‘forward’의 반복 과정이라 생각해주시면 됩니다. 결국 이 과정 중 앞단에 있는 토큰에 대해서는 동일한 forward가 반복되기에 이를 KV cache에 저장해두고 반복함으로써 효율성을 높여줍니다. 여기서 prefilling time은 가장 첫 반복 시기에 KV cache에 값을 채우는 데 소요되는 시간으로 실제 모델의 효율성과 직결된다고 보시면 됩니다. VisionZip 방식으로 비전 토큰 개수를 크게 줄이며 이 prefilling time이 8배 감소되었음을 강조하고 있습니다.
마지막으로 그림 2-(c)는 LLaVA-NeXT 13B 모델에 VisionZip을 적용해 추론하는 경우 성능은 상대적으로 떨어지나 이 성능이 Vanilla LLaVA-NeXT 7B 모델보다는 높은 성능을 달성하였고, 더욱이 빠른 추론 시간을 갖게되며 real-world로 나아가기 위해 적용해볼법한 좋은 방법론임을 강조하고 있습니다.
방법론에 대한 자세한 설명과 분석은 이어서 살펴보겠습니다.
2. VisionZip
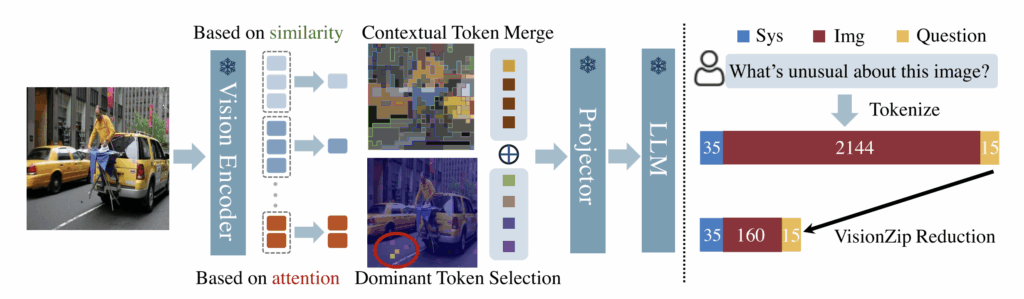
위 그림 3은 VisionZip 방법론을 간단하게 보여주고 있습니다. 먼저 비전 인코더의 attention 값을 기반으로 dominant token(그림 중하단)을 선택합니다. 다음으로 dominant로 선택되지 않은 토큰들은, 자신들끼리의 유사도를 기반으로 merge됩니다. 이러한 방식을 통해 원래 이미지에서 나온 2,144개 비전 토큰 대신 160개로 줄어든 토큰만을 사용하여 성능 감소는 최소화하며 효율성은 극대화하게 됩니다.
2.1 Informative Visual Token Zip
2.1.1 Dominant Token Selection.
막대한 개수의 비전 토큰을 줄이기 위해, 가장 먼저 모델이 어떤 토큰의 정보를 가장 많이 활용하는지 알아야 합니다. 여러 기준을 통해 골라낼 수 있겠지만, 여기에선 비전 인코더의 self attention 과정에서 나오는 attention weight 값을 활용합니다.
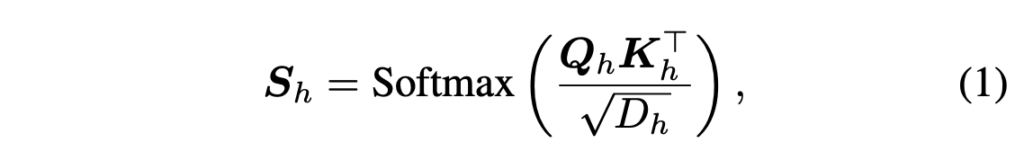
위 수식 (1)은 일반적인 attention 연산에서 attention 값을 추출하는 과정을 나타냅니다. \boldsymbol{Q}, \boldsymbol{K}는 연산의 쿼리, 키를 의미하며 D는 head의 차원입니다. 추가로 각 값 아래 붙어있는 h는 한 레이어의 head 인덱스를 의미하며, 최종적으로 dominant token을 결정할 attention 값은 head 축으로 평균낸 \boldsymbol{S}_{avg} \in{} \mathbb{R}^{B \times{} SeqLen \times{} SeqLen}입니다. 여기서 SeqLen은 sequence length로 전체 토큰 개수와 같다고 보시면 됩니다.

결국은 위 알고리즘 1과 같이 레이어 내 모든 헤드의 평균 attention 값을 기준으로 Top-K개의 dominant token을 추리는 것입니다. K에 해당하는 dominant token 개수는 하이퍼파라미터로 직접 설정할 수 있으며, 뒤 실험에선 모델마다 다르게 바꿔가며 성능을 보여줍니다. 알고리즘 1 마지막의 filter 부분은 선정한 dominant token 인덱스를 바탕으로 gather하는 것으로 생각해주시면 좋을 것 같습니다.
위 알고리즘 1에서는 CLIP과 같이 한 이미지를 대표하는 CLS 토큰이 있을때를 기준으로, 이 CLS 토큰과의 attention 값이 높은 토큰을 dominant로 설정하는 상황을 보여주고 있습니다. 만약 SigLIP과 같이 CLS 토큰이 없다면 하나의 토큰이 다른 토큰과 갖는 attention 값을 모두 평균내어 사용합니다. 해당 평균값이 높으면 dominant로 채택되는 것입니다.
2.1.2 Contextual Tokens Merging.
그림 1과 3에 따르면, 앞서 뽑은 dominant token들이 몇 개를 뽑든 거의 99%의 attention 값을 차지하고있는 것은 사실입니다. 또 저자에 따르면 이 dominant token들이 대부분의 visual information을 갖는다고 이야기하긴 하는데, 사실 논문 그림에 담긴 예시에서는 아스팔트 부분에만 잔뜩 찍히고 있어 이해가 잘 안되긴 하네요.
저자는 dominant token이 많은 정보를 담고 있지만 그럼에도 불구하고 혹시나 이들이 놓칠 수 있는 visual 정보 또한 가져가기 위해 dominant가 아닌 토큰들도 해당 토큰들끼리 merge해서 context token으로 써야한다고 이야기하지만, 예시 그림만 보면 오히려 반드시 merge해줘야만 뒷단의 task에서의 성능이 좀 나올 것만 같은 느낌이 드네요. 아무튼 이러한 이유로, 나머지 토큰인 non-dominant token들은 자신들끼리의 유사도를 기반으로 merge됩니다.

위 알고리즘 2가 해당 merge 과정을 보여주고 있습니다. remaining 변수에 dominant를 제외한 나머지 non-dominant token들을 담고, 기존의 token merging 방식과 유사하게 두 개의 집합으로 나눈 뒤 다른 하나의 집합 내 토큰 중 자신이 합쳐질 토큰을 argmax로 선택하게 됩니다. 이때 유사도는 self attention 과정에서 각 토큰의 정보를 이미 잘 요약하고 있는 키(K) 값을 기준으로 계산합니다. 이렇게 선택된 토큰과 자신을 평균내어 merging을 수행합니다. 최종적으로는 dominant token과 context token이 concat되어 projection layer에 입력됩니다.
2.2 Efficient Tuning
앞선 2.1절에서 소개드린 내용이 VisionZip의 training-free 방식이고, 여기선 fine-tuning 방식을 소개합니다. 사전학습 되어있는 projection layer 및 LLM decoder는 VisionZip과 같은 token merging 과정 없이 raw 비전 토큰을 입력으로 받았기에, 10배 이상 줄어든 비전 토큰을 입력받을 경우 임베딩 공간 상에서의 misalignment가 발생할 수 있습니다.
이러한 misalignment를 보완하기 위해 선택적으로 fine-tuning을 진행할 수 있습니다. 뒷단의 projection layer가 짧아진 비전 입력을 보고 intruction tuning 학습을 한 번 함으로써 적응을 하게 만들어주는 것이죠. 이때는 이미 모델이 사전학습한 LLaVA-1.5 instruction tuning 데이터의 10%만을 가져와 다시 학습시키고, 이 학습은 8장의 A800 GPU에서 LLaVA 1.5 7B 기준 30분밖에 걸리지 않는다고 합니다. 3090에서도 충분히 가능한 fine-tuning이라고 하네요. 물론 이 fine-tuning을 하지 않아도 VisionZip이 이야기하는 효과는 다 누릴 수 있지만, 이 효율적인 정합학습만으로도 VisionZip의 효율성은 유지하며 성능 관련된 출혈이 적어진다는 것입니다.
2.3 Usage of VisionZip
VisionZip은 이미지나 비디오 관련 VLM task에도 쉽게 적용될 수 있습니다. 가장 큰 장점으로는 입력 문장 텍스트에 agnostic하기에, multi-turn에도 효율성과 성능을 잃지 않는다는 점입니다. 유사한 efficient VLM 방법론들은 입력 text를 바탕으로 이미지나 비디오 토큰 개수를 줄이게 되는데, 만약 다음 턴에서 첫 턴에 suppress된 이미지, 비디오 내용을 묻는다면 대응하기 어렵거나 다시 이에 맞게 suppress를 진행해야한다는 단점이 생기는 것입니다. 그러나 VisionZip은 text-agnostic하기에 이러한 문제가 안생긴다는 것이죠.
VisionZip 방식을 적용하면 원본 모델의 성능을 90%이상 보존하면서 runtime과 메모리는 3배 이상 절약할 수 있습니다. 앞서 언급한대로 VLM 13B 모델의 추론 시간을 7B보다 짧게 만들며 성능은 7B보다 높게 가져가는 등 장점이 많은 방법론이라고 볼 수 있습니다.
3. Experiments
3.1 Effectiveness on Image Understanding
Evaluation Tasks.
VisionZip의 성능을 보여줄 이미지 벤치마크는 GQA, MMB, MME, POPE, SQA 등 총 11종을 사용하였으며, 비교 방법론으로는 attention weight를 기반으로 비전 토큰의 개수를 점진적으로 줄여나가는 기존 efficient VLM SOTA 방법론인 FastV와 SparseVLM을 채택하였습니다. 기준이 되는 VLM은 LLaVA-1.5, LLaVA-NeXT를 채택하였습니다.
Results on LLaVA 1.5
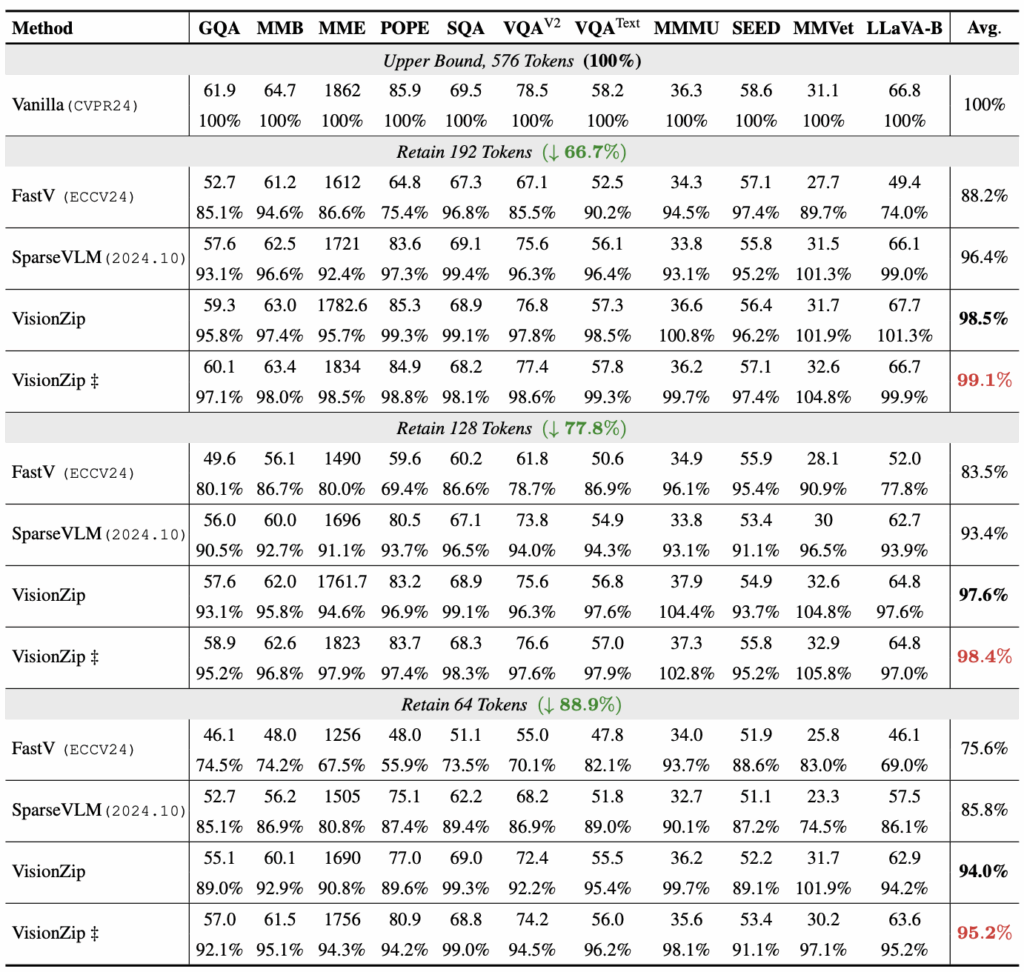
표 1은 LLaVA-1.5에 VisionZip 등 다양한 efficient 방법론을 붙였을 때의 벤치마크 성능입니다. 표에서 일반 ‘VisionZip’은 앞서 언급한 training-free 방식, ‘VisionZip\ddagger{}‘는 projector를 위한 fine-tuning 방식을 의미합니다. 또한 표에서 베이스라인인 Vanilla 성능은 이미지 당 576개의 토큰을 활용할때이며, 벤치마크마다 성능 비교가 어려우니 바닐라의 성능을 100%로 두었을때 각 방법론의 상대적 성능을 %로 표기하고 있습니다.
바닐라 576개 대비 192, 128, 64개 토큰으로 줄였을 때 성능을 리포팅하고 있으며, 192개 토큰으로 줄였을때 VisionZip은 1.5%만 성능이 하락하는 것을 볼 수 있습니다. 특히 64개 토큰만을 남겼을 때, 다른 방법론은 바닐라 대비 75.6%, 85.8%의 성능만을 내나 VisionZip은 94%로 엄청 큰 성능 보존 격차를 보이고 있습니다. 바닐라 대비 88.9% 감소된, 엄청 적은 양의 비전 토큰을 썼음에도 6%만 성능이 떨어지는 것은 효율성과 성능을 모두 잡았다고 봐도 될 것 같습니다.
또 모든 토큰 개수 실험에서 VisionZip\ddagger{}가 유의미한 성능 차이를 보여 짧은 fine-tuning만으로도 정합 공간이 맞춰지며 저자의 의도대로 임베딩 공간에 안정성을 더했음을 알 수 있습니다. 추가로 MMVet나 MMMU 벤치마크에선 토큰 개수를 줄였음에도 간혹 100%를 넘기며 베이스라인보다 높은 성능을 달성하는 것을 볼 수 있습니다. 두 벤치마크는 모두 다양한 도메인의 이미지에 대해 다양한 종류의 QA를 포함하고 있는데, 이에 대해 저자는 원 이미지가 워낙 redundant한 정보를 많이 담고 있어 오히려 efficient 방법론들이 노이즈를 제거해준 것으로 생각한다고 합니다.
Results on LLaVA-NeXT
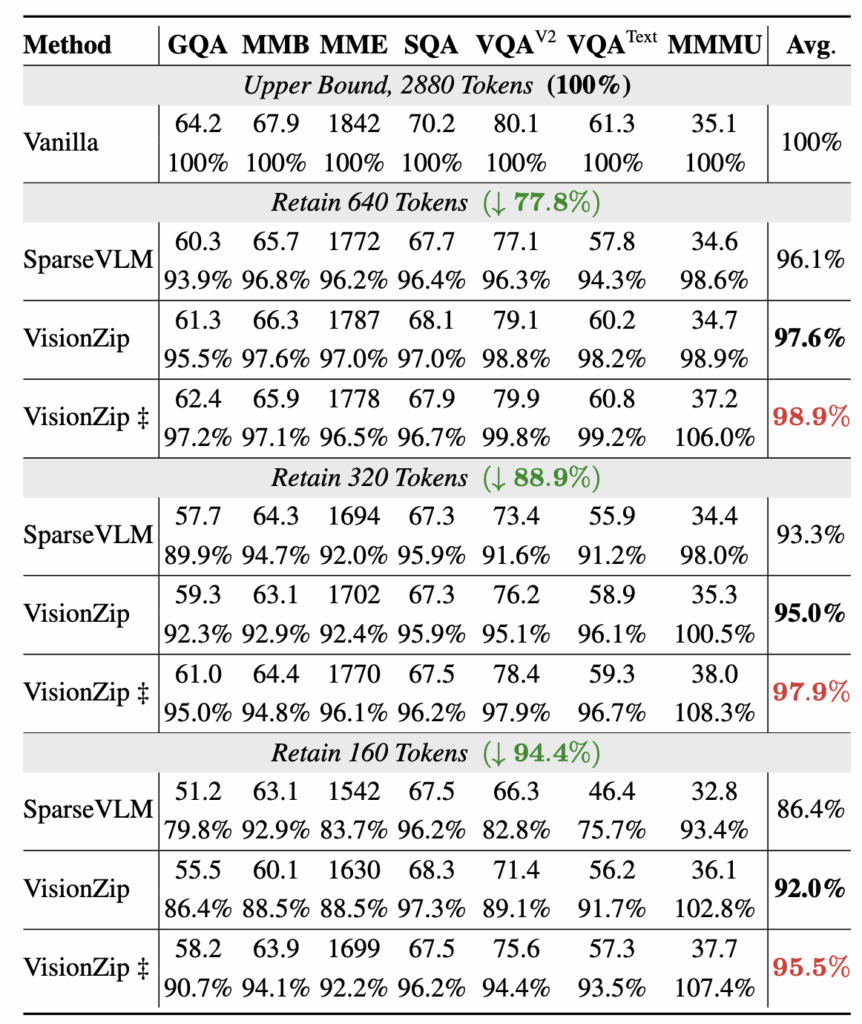
위 표 2는 LLaVA-NeXT에 각 방법론을 적용했을 때의 성능을 보여주고 있습니다. 우선 바닐라 LLaVA-NeXT 모델은 이미지 당 2,880개 비전 토큰을 활용합니다. 본 표에서는 앞선 표 1과 마찬가지로 토큰 개수가 줄어듦에도 타 방법론 대비 좋은 성능 방어력을 보여주고 있어 자세한 설명은 생략하도록 하겠습니다.
3.2 Effectiveness on Video Understanding
저자는 이미지 모델 뿐만 아니라 비디오 모델에도 VisionZip을 적용할 수 있음을 보여줍니다.
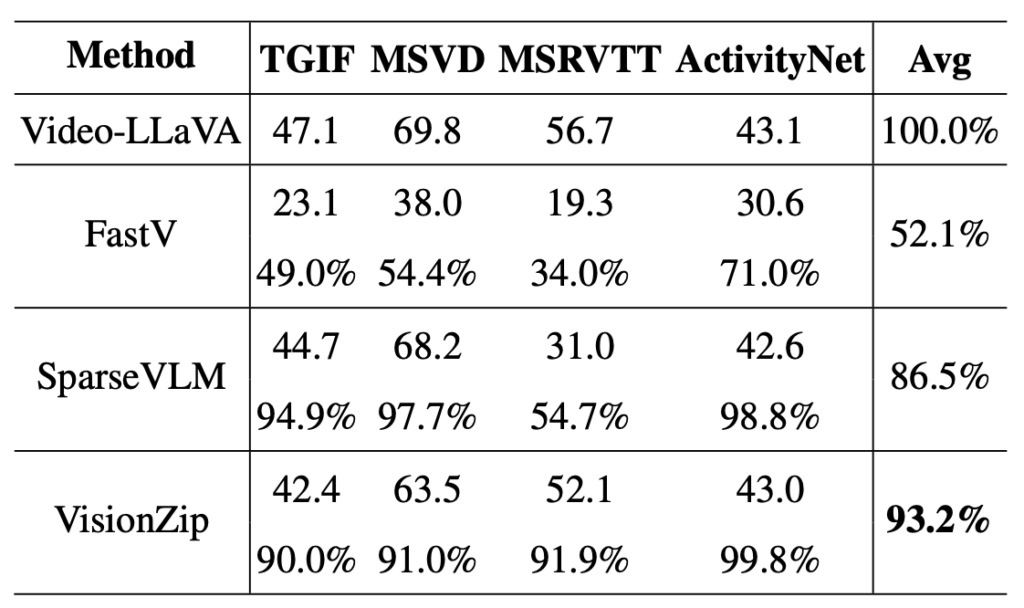
표 3은 Video-LLaVA 모델에 efficient VLM 방법론을 적용했을때의 벤치마크 성능 표입니다. 바닐라 Video-LLaVA는 한 프레임 당 256개, 총 8개 프레임을 추출하며 결국 한 비디오 당 2,048개의 비전 토큰을 쓰고, 나머지 방법론들은 이를 136개로 줄였을 때의 성능에 해당합니다. 한 프레임의 256개 토큰을 17개로 줄여 8개 프레임을 붙이는 방식을 사용한 것입니다. VisionZip training-free 방식에서도 바닐라 성능 대비 93.2%의 성능을 보여주며 동일 조건에서 타 방법론보다 적은 성능 하락폭을 보여주었습니다.
3.3 Efficiency Analysis
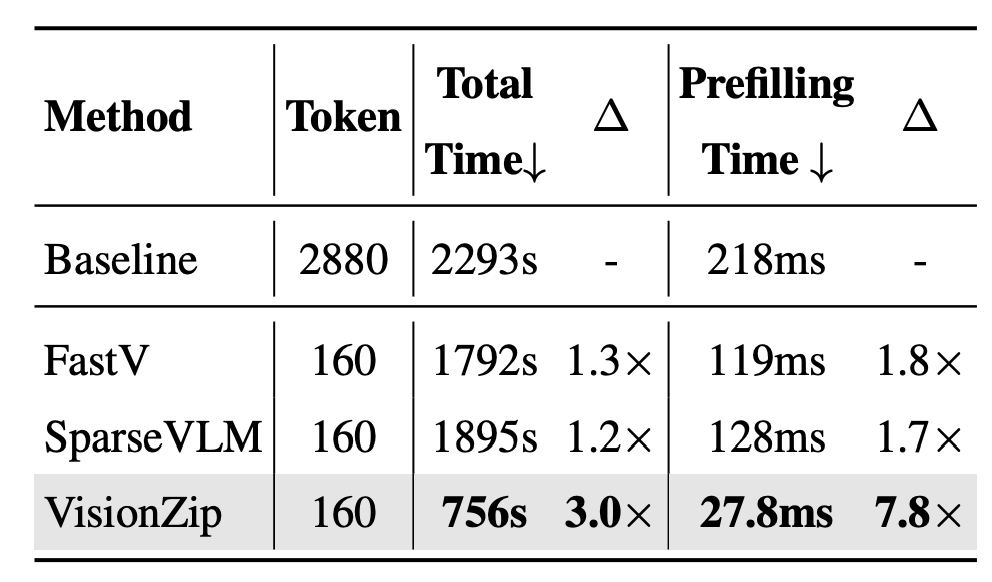
표 4는 VisionZip의 효율성을 정량적으로 보여주는 표입니다. A800 GPU 1장에서 LLaVA-NeXT 7B 모델로 POPE 벤치마크를 평가할때 걸리는 Prefilling time과 Total time을 보여주고 있습니다. 본 표 4를 통해서 VisionZip이 기존 방법론 대비 성능 뿐만 아니라 실제 inference time까지 크게 줄이며 우세한 것을 보여주고 있습니다. 사실 FastV와 SparseVLM이 실제로 어떻게 동작하는지 알면 좀 더 자세히 설명드릴 수 있을 것 같긴 한데, 이에 대해서는 시간이 되면 정리해보도록 하겠습니다.
4. Analysis and Discussion
본 4장에서는 왜 VisionZip이 필요한가를 설명합니다. 앞에서 VisionZip은 비전 토큰의 redundancy를 줄이기 위해 고안되었다고 설명하였는데, 좀 더 근본적으로 비전 토큰의 redundancy는 왜 생기는지 설명하고, 이러한 이유로 VisionZip이 필요함을 이야기하려는 것입니다.
4.1 Reasons of Redundancy in Visual Tokens
Visualization of the Redundancy.

위 그림 5는 VLM layer에 따른 attention 분포 시각화 입니다. 초반에는 여러 토큰에 걸쳐 attention이 뿌려져있지만, 뒤로 갈수록 소수 토큰에 집중하다가 마지막 24번 레이어에서는 다시 흩어지는 것을 볼 수 있습니다. CLIP과 같은 비전 인코더는 텍스트와의 대조학습을 기반으로 임베딩 공간이 형성되어있다보니, 마지막 24번 레이어는 텍스트와의 대조학습을 위해 임베딩 공간이 형성되어있어 attention 정보가 너무 산발되어있거나 너무 소수에만 집중되어있는 문제가 있다고 합니다. 결국 24번 레이어에선 실제 입력 이미지의 정보를 담기보단 텍스트와의 대조학습을 준비하는 feature가 만들어지는 것이죠.
이러한 현상은 이전부터 발견되어 대부분의 VLM은 23번 레이어 즉 -2번 레이어에서 얻은 비전 토큰을 활용합니다. 그러나 23번 층을 쓰면 표현력은 좋으나 그림 5의 시각화 결과처럼 정말 소수의 dominant token에만 어텐션이 쏠리는 것을 볼 수 있습니다. 이러한 이유로 대부분의 VLM이 뽑아쓰는 비전 토큰에는 redundancy가 존재하고, VisionZip이 이러한 부분을 완화해줄 수 있다고 주장합니다.
Explanation.
여기서도 마찬가지로 왜 기존 비전 토큰에는 redundancy가 존재하는지 설명합니다. 첫번째로는 대조학습 과정에서 비전 인코더가 CLS 토큰 등 정말 소수 토큰에만 집중해도 대조학습이 잘 되는 일종의 ‘shortcut’을 발견한 것이라고 저자는 주장합니다. 더 큰 원인으로는 softmax를 꼽고 있습니다.
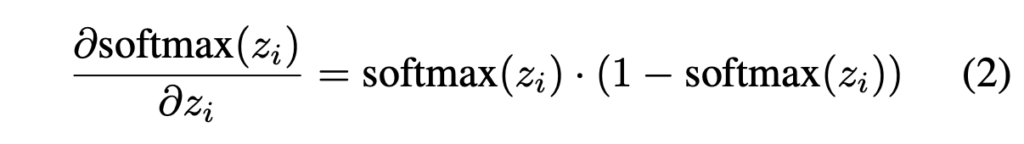
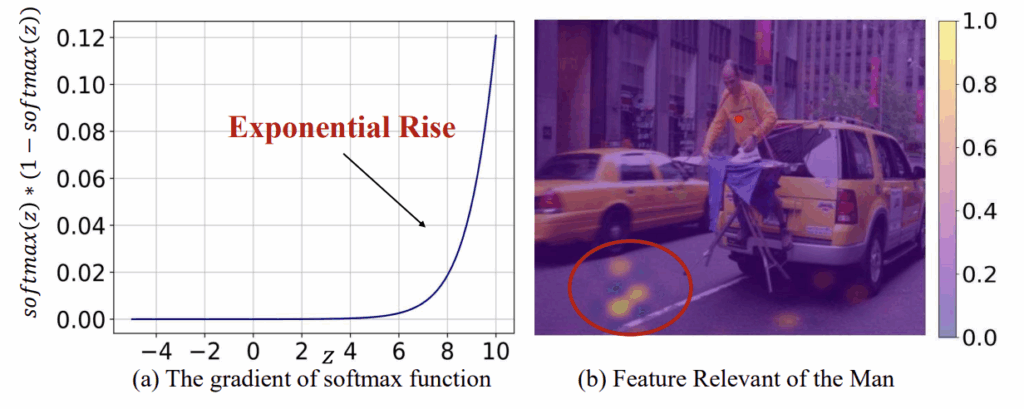
수식 (2)는 softmax의 gradient 수식이며, 아래 그림 6-(a)는 수식 (2)를 그래프로 나타낸 것입니다. 결국 softmax가 forward에 관여하면 z_{i}가 클수록 gradient는 지수적으로 증가, 작을수록 0에 가깝게 무시되는 속성이 있기에 정말 극소수의 토큰만 높은 attention을 할당받는 현상이 발생한다고 이야기합니다. 보통 학계에서 이야기하는 ‘Attention sink’와 동일한 현상이라고 볼 수 있습니다.
결국 본 절에서는 VisionZip 방법론에 대한 분석보다는, 위 두 가지 이유로 비전 토큰의 redundancy는 필연적이며, 이를 VisionZip 방식으로 해결할 수 있다고 이야기하는 것입니다. 사실 CLIP, SigLIP과 같은 백본 자체가 위 현상이 발생하지 않도록 개선되지 않는 이상, VisionZip과 같은 일종의 후처리를 해주는 것이 가장 효율적이라고 볼 수 있을 것입니다.
5. Conclusion
본문에도 실험이 많아 최대한 여러 분석 결과를 담으려고 적어보았습니다.
우선 본 방법론은 논문 작성 관점에서 별도의 학습 없이도, 추론만 진행해가며 큰 성능향상을 보였다는 점과, 특히 방법론이 간단하다보니 뒷받침할 수 있는 motivation과 analysis가 굉장히 뛰어났다고 생각합니다. 요즘은 제안하는 방법론의 어떤 모습을 보여주기 위해 어떤 실험 결과를 설계하는지, 또 그 결과에 따라 논지를 어떻게 펼치는지 위주로 살펴보려고 노력중인데 참 도움이 많이 되는 논문이었던 것 같습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요 현우님! 리뷰 잘 읽었습니다~!!
이미지 표현에서 정보량 있는 소수의 토큰만 사용해도 충분하다는게 핵심 모티베이션으로 이해 했습니다!
그렇다면 dominant로 선택되지 않은 나머지 토큰들은 전부 버리는 게 아니라, 일부만 사용한다고 이해하면 될까요?
논문에서 non-dominant 토큰들이 서로의 유사도를 기반으로 merge된다고 하셨는데 이때 어떤 기준으로 non-dominant 토큰을 선택하거나 병합하는지 다시 말하자면 어떤 토큰끼리 합쳐져서 디코더로 전달되는건지 기준이 궁금합니다!
안녕하세요 좋은 질문 감사합니다.
dominant로 선택되지 않은 모든 token들은 non-dominant로 병합된다고 보시면 됩니다. 전체 과정으로 따지면 1) Dominant 추리기 2) 나머지를 자연스럽게 Remaining으로 지정 3) Remaining 끼리 병합(평균)하여 non-dominant 생성에 해당합니다.
예를 들어 한 이미지에 대해 원래 vision encoder를 태워 100개의 토큰이 얻었고, 여기서 dominant token을 top-30개로 지정했다면, 나머지 70개는 remaining으로 두는 것입니다. 이후 70개의 remaining 토큰들을 다시 병합해 non-dominant를 만들어줍니다.
이 과정을 좀 더 자세히 설명드리겠습니다. Remaining 중 non-dominant를 10개로 추리겠다고 결정한 상황, 즉 non-dominant를 10개만 가져가는 상황으로 보겠습니다. 그럼 remaining 70개 중 10개를 uniform sampling한 뒤 나머지 60개가 이 10개 중 어디로 병합될지 유사도 기반으로 결정합니다. 60개의 remaining은 10개 중 하나로 평균 기반 병합이 되며 최종적으로는 dominant 30개 + non-dominant 10개 총 40개만 남게 되는 것입니다.
안녕하세요 현우님 좋은 리뷰 감사합니다!
VLM에서 이미지 내 불필요한 부분들이 꽤 많지 않을까?라는 막연한 궁금증이 있었는데 이를 해결하기 위한 방법론을 설명하고 있는 논문이라서 흥미롭게 읽었습니다.
VisionZip은 text-agnostic인데 반해 SparseVLM과 같은 기존 방법론은 text 기반으로 의미 있는 visual token을 뽑아내는 방식이라고 이해를 하였는데요, 단순히 직관적인 생각으로는 text guide가 있으니까 SparseVLM의 성능이 더 좋지 않을까 생각했는데 오히려 VisionZip의 성능이 좀 더 높은 것이 의아했습니다. 왜 이런 결과가 나왔는지 궁금합니다!
감사합니다.
안녕하세요 좋은 질문 감사합니다.
우선 말씀해주신 결과의 원인은 리뷰 글 4.1절을 살펴보시면 좋을 것 같습니다. 결국 CLIP, SigLIP과 같은 vision encoder의 구조와 학습 방식에 있다고 볼 수 있습니다.
말씀해주신 내용이 VisionZip 방법론이 주장하는 것의 전부라고 생각합니다. 사람 눈으로 봤을 때 유의미한, 예를 들면 “man”이라는 텍스트를 던졌을 때 사람이나 그 사람 주변 물체가 유사도 높게 나오는 것이 바람직한 상황이고 해석 가능한 상황이라고 이야기하는 것이 SparseVLM을 비롯한 일반적 통념이라고 생각합니다.
그러나 VisionZip은 “‘man’의 정보는 아스팔트 패치에 모두 담겨있다”라는 결론을 내렸습니다. 거대 vision encoder의 구조와 학습 과정 상 수 백개의 패치 중 실제 이미지의 정보를 담고있는 패치는 손에 꼽을 정도로 적고, 그 토큰에 모든 정보가 담겨있다보니 텍스트와 유사한 패치일수록 유의미한 정보를 담고 있다고 보기엔 어렵다는 것이 논문의 주장입니다.