안녕하세요 x-review 작성자 최인하입니다. 오늘 리뷰할 논문은 Teleoperation system인 AnyTeleop입니다. 좋은 demonstration 데이터를 수집하기 위해서 정확한 teleoperation이 필요한 만큼 관련된 기술도 발전하고 있는 것 같습니다. 어떻게 보면 데이터를 수집하기 위한 하나의 도구 같은 느낌인데.. 한번 리뷰해 보겠습니다!

Vision based teleoperation은 로봇이 저렴한 카메라 센서만으로도 환경과 물리적으로 상호작용 할 수 있는 가능성을 제공합니다. 하지만 현재 vision teleoperation system은 특정 로봇 모델 그리고 특정 환경으로 설계되어서 다양한 변화에 대한 system의 확장성은 떨어진다고 합니다. 따라서 오늘 리뷰할 논문에서는 single system 내에서 다양한 로봇, 환경 구성을 지원하는 general한 teleoperation system인 AnyTeleop을 제안합니다. AnyTeleop는 하드웨어 선택에 대한 강인성을 제공하면서도, 뛰어난 성능을 보인다고 합니다. 대박인 것은 real world에서 AnyTeleop는 특정 로봇 하드웨어에 맞춰 설계된 기존 teleop system보다 더 높은 성공률을 보인다고 합니다. sim 환경에서의 teleop인 경우에도 이전의 해당 sim에 특화된 기존 방식들보다 더 좋은 imitation learning performance를 이끈다고 합니다.
Introduction
논문에서는 robotics 분야의 최종 목표는 로봇이 인간 수준의 지능을 갖추어 물리적으로 환경과 상호 작용할 수 있도록 하는 것이라고 합니다. 여기서 Teleoperation 기술은 로봇을 가르치기 위한 human demonstration을 획득하는 직접적인 수단입니다. gripper based manipulator와 비교했을 때, dexterous hand-arm system을 teleoperating 하는 것은 매우 복잡하기 때문에 종종 높은 비용의 특수 장치를 필요로합니다. 이번에 연구실에 들어온 meta quest3 같은 장치 말이죠. (혹은 apple vision) 따라서 vision based teleoperation 기법들은 위의 방식들에 비해서 로봇을 teleoperating하는데 low-cost, more generalizable 하다고 합니다.
하지만 현재 vision based teleoperation system에는 robot teaching 을 위한 data 수집과 규모를 확장하는데 있어서 다음과 같은 미흡한 점이 있다고 합니다.
- 기존 시스템은 특정 로봇이나 특정 deployment environment에 맞춰서 디자인 되어있는 경우가 많습니다. 예를 들면 일정한 스튜디오 환경에서 수집된 dataset으로 훈련된 모델 등등.. 이러한 시스템은 로봇 모델이 달라지거나, 환경의 다양성이 증가하면 확장성이 떨어집니다.
- 기존 시스템은 real world 아니면 sim 상황에서만 구현됩니다. sim-to-real 간극을 해소하기 위해서는 teleoperation 시스템이 sim 상황과 real world에서 모두 작동해야 합니다.
- 처음에 말한 것과 비슷하게 기존 teleoperation 시스템은 환경 뿐만 아니라 단일 로봇에게 맞춰져 있는 경우가 많다고 합니다.
따라서 이 논문에서는 vision-based teleoperation 기술로 데이터 수집을 확장하기 위한 기반을 마련하고자 앞서 말한 문제점등을 해결하고자 합니다. 이 논문의 main contribution은 다음과 같습니다.
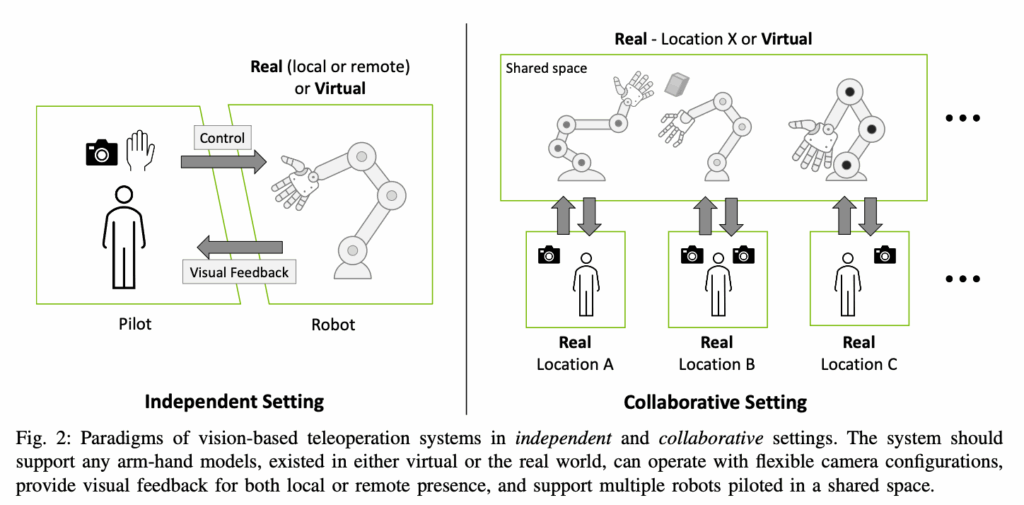
- 다양한 robot arm과 dexterous hand 모델에 적용이 가능하다.
- real world와 sim 상황 선택이 가능하다.
- 환경에 구애받지 않는 teleoperation이 가능하다.
- depth camera가 필요없이 RGB만으로 가능하며, 다양한 카메라 호환이 가능하다.
- 두 명의 작업자가 두대의 로봇을 개별적으로 control 가능하며, interaction이 가능하다.
논문에서는 이를 달성하기 위해서 human motion을 robot motion으로 learning 없이 실시간으로 변환하는 general and high performance motion retargeting library를 개발했다고 합니다. 또한 충돌 회피 모듈은 cuda 기반 geometry queries를 사용하는 learning free 기법이라고 합니다. 이들은 URDF 파일과 같은 kinematic 모델만 주어지면 새로운 로봇에 적응할 수 있다고합니다. 두번째로, 표준 브라우저와 호환되는 웹 기반 뷰어를 개발하여 simulator에 구애받지 않는 시각화를 구현하고 인터넷을 통해 teleoperation을 가능하게 한다고 합니다. 세번째로, visoin based teleoperation을 위한 일반적인 software interface를 정의하여 teleoperation 시스템 내부의 각 모듈을 표준화하고 분리합니다. 이를 통해 다양한 simulator나 실제 하드웨어에 원활하게 배포할 수 있다고 합니다.
Anyteleop는 실험 결과에서 매우 좋은 성능을 보였다고 합니다. real world Teleoperation인 경우, 이전 시스템 보다 높은 성공률을 보인다고 합니다. 논문에서는 10가지의 task중 8가지에서 동일한 로봇 기준 더 좋은 성능을 보인다고 하고, sim 상황인 경우 6가지 task 중 5가지에서 더 높은 성공률을 보였다고 합니다. 이로 인해 더 나은 Imitation learning 결과를 가져올 수 있다고 합니다. 마지막으로 다른 vision based teleoperation system과는 다르게 collaborative manipulation을 지원한다고 합니다.
System Overview
위에서 말한 전체적인 내용을 조합해서 설명해보면, AnyTeleop는 하드웨어, 환경적 측면에서 일반화 되어있으며, number of operator-robot collaboration 을 지원합니다. 또한 web 기반 시각화를 제공해서 simulator에 대한 제약 없이 어디서든 teleoperation과 simulation을 모니터링 할 수 있습니다. 그리고 모든 라이브러리는 docker image로 캡슐화 되어있어서, Linux machine에서 배포할 수 있기 때문에 사용자는 번거로운 종속성을 처리할 필요가 없습니다. 이제 이 내용에 대해서 자세히 설명해 보겠습니다!
System Design
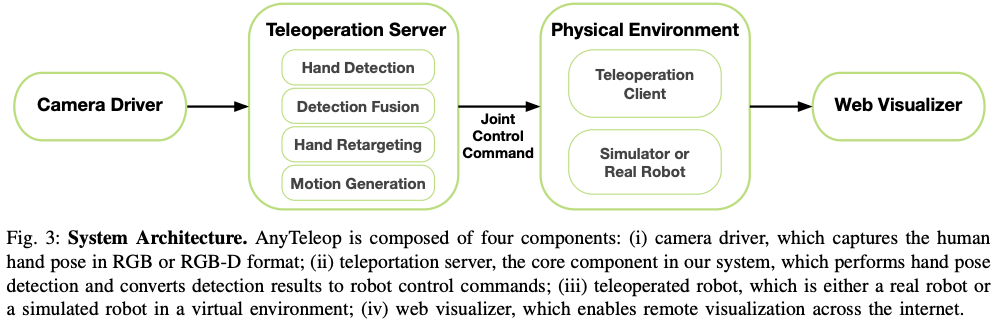
위의 그림은 AnyTeleop의 전반적인 구조입니다. Server는 camera driver를 통해 hand pose를 감지하고, 각 관절값으로 변환합니다. client는 이 변환 값을 network communication으로 받아서 sim과 real 상황에서 사용합니다. 이 전체적인 구조에서 중요한점은 모듈화를 통해서 robot arm, camera, Hand의 범용성을 높였으며, 서버에 복잡한 계산을 맡겨 사용자는 고성능 workstation 없이 그냥 노트북을 들고 다니면서 어디서든 Teleoperation을 수행할 수 있습니다. 또한 containerized를 통해서 다른 시스템에 비해서 software dependencies를 낮춥니다.
Teleoperation server
Teleoperation server는 4가지 모듈로 구성되어있습니다.
- Hand pose detection module: camera view를 통해서 손목 관절과 finger 관절의 pose를 predict합니다.
- Detection Fusion module: Multiple camera view를 합칩니다.
- Hand pose retargeting module: Hand pose와 dexterous robot hand를 mapping합니다.
- Motion Generation module: robot에게 high-frequency 제어 신호를 보냅니다.
각각의 모듈에 대해서 자세히 설명해보면,
Hand pose Detection module
Detection module은 다양한 카메라 상황에서 손목 기준으로 손가락의 position과 카메라 기준 frame으로 손목 6D pose를 output으로 내보냅니다. 여기서 손가락은 RGB data만으로 충분하지만 손목은 depth가 있으면 더욱 정확하다고 하네요.
Finger Keypoint Detection으로는 MediaPipe 알고리즘이 사용된다고 합니다.

Wrist pose detection 같은 경우는 RGB only와 RGB-D를 비교하여 설명해보겠습니다. 우선 RGB-D인 경우에는 감지된 키포인트의 픽셀 위치를 사용하여 깊이 영상에서 해당 깊이 값을 가져온 후 intrinsic parameters를 이용하여 카메라 좌표계에서 키포인트들의 3차원 위치를 계산합니다. 이렇게 얻은 camera frame에서의 3D 키포인트 위치를 가지고, PnP 알고리즘을 사용하여 손목의 자세를 추정할 수 있습니다.
RGB only인 경우 손목의 pose를 추정하기 어려운데 논문에서는 FrankMocap에서 사용된 방식을 채택하여, 손목의 6D pose를 근사했다고 합니다. 이는 depth 정보가 있는 것보다는 정확성이 적지만 teleoperation에서는 충분한 정확도를 제공한다고 언급합니다.

여기서 Error는 잘못된 피아노 건반을 눌렀을 경우입니다.
Detection Fusion
카메라를 한대만 사용하는 경우에는 손가락 가림현상이 pose detection에 문제가 될 수 있습니다. 특히 카메라와 손의 각도가 수직일 때, 카메라를 여러대 사용하는 것은 해결책이 될 수 있습니다. 하지만 추가적인 view가 문제가 될 수도 있습니다.
- 각각의 카메라는 자신의 좌표계에서만 손 자세를 추정할 수 있습니다.
- 각 탐지 결과의 신로도를 정량적으로 평가할 명확한 기준이 없습니다.
첫번째 문제를 해결하기 위해 논문에서는 사람 손을 기준점으로 생각하여 auto-calibration을 제공합니다. 즉, 여러 카메라에서 얻은 초기 N 프레임 동안에 손 탐지 결과를 이용해 각 카메라 간의 상대적 회전 관계를 계산하고, 이를 3차원 회전 공간으로 표현합니다. 즉 각각의 카메라 간의 상대적인 rotation matrix를 구하고 이를 하나의 좌표계로 나타내는 작업을 수행하는 것입니다.
두번째 문제는 teleoperation 과정에서, 사용자의 hand shape parameters는 일정하게 유지되어야 합니다. 그러나 self-occlusion이 발생하면 예측된 parameters에 오류가 포함될 수 있습니다. 이로 인해 pose parameters 오류도 커지게 됩니다. 논문에서는 N=50(초기 측정 frame의 수)으로 설정하고, N frame 동안 사용자가 손가락을 벌리고 있는 동작을 수행합니다. 이를 기준 hand shape parameters로 지정하고, 이후 프레임에서 예측된 shape parameters와의 오차를 계산합니다. 오차가 작을 수록 해당 카메라의 탐지 결과를 신뢰할 수 있다고 판단하고 module은 가장 높은 신뢰도 점수를 가진 카메라의 parameter 측정 값을 다음 module로 넘깁니다.
Hand Pose Retargeting
Hand pose retargeting module은 human hand data를 robot hand의 joint position으로 teleoperated 합니다. 이 과정은 사람 손과 로봇 손의 다른 keypoint vector들의 차이를 최소화 하는 일종의 optimization problem이라고 생각하시면 됩니다.
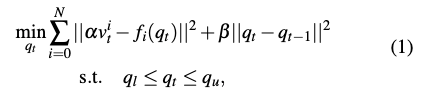
- N은 고려되는 키포인트의 총 개수를 나타냅니다.
- α는 인간 손과 로봇 손의 크기 차이를 보정하기 위한 스케일링 인자입니다.
- v는 시간 t의 i번째 키포인트 벡터를 의미합니다.
- f는 로봇 손의 i번째 forward kinematics 함수입니다. 로봇 손의 관절 위치 q를 입력 받아 i번째 키포인트의 3D 위치를 계산합니다.
- 그리고 두 벡터간의 유클리드 거리의 제곱을 최소화 함으로써 로봇 손의 키포인트가 인간 손의 키포인트에 최대한 가깝게 일치하도록 합니다.
- 두번째 항은 로봇의 부드러운 움직임을 확보하기 위한 regularization 항입니다.
- β 값이 클수록 현재 관절 위치 q가 이전 시간 관절 위치와 더 유사하도록 강제하여 로봇의 움직임이 갑작스럽게 변하는 것을 방지하고 부드럽게 이어지도록 합니다.
- 마지막 식은 제약조건을 나타냅니다. 즉 관절의 RoM의 범위를 넘어가지 않도록 하는 조건입니다.
즉 AnyTeleop는 최적화 문제로 retargeting을 수행합니다! 학습된 모델 없이 URDF 파일로 새로운 로봇에 적용할 수 있도록 설계된 시스템입니다!
Motion Generation
논문에서 목표는 로봇의 End Effector가 목표 cartesian space에 도달하도록 부드럽고 충돌이 없는 움직임을 생성하는 것입니다. 따라서 논문에서는 CuRobo 라이브러리를 채택하였습니다. 이는 GPU에서 동작하며, real-time으로 로봇의 충돌 없고 자연스러운 움직임을 생성합니다. motion generation module에서는 low-frequency(25Hz)로 end-effector의 cartesian space를 받고 충돌 회피 joint space trajectory를 생성합니다. 이 때 high-frequency(120Hz)로 생성된 궤적은 sim 혹은 실제 로봇의 제어기에의해 안전하게 실행될 준비가 됩니다.
System Evaluation
이제 AnyTeleop의 방법론을 알았으니 다른 기존의 방법들과 비교한 결과를 간단하게 살펴보겠습니다. 결론적으로 기존에 특정 로봇에게 맞춰진 system보다도 task를 수행함에 있어서 좋은 성능을 보여줬습니다. 또한 수집된 demonstration을 가지고 imitation learning을 수행할 때에도 기존의 방식들보다 더 좋은 성공률을 보였습니다. 자료를 통해 확인해보겠습니다.

Real world에서 robot task에 대한 공정한 비교는 똑같은 환경을 만들어서 비교하기 매우 어렵습니다. 따라서 논문에서는 Robotic Telekinesis에서 제안된 10개의 manipulation 작업을 동일한 XArm6, Allegro hand 그리고 유사한 물체를 사용해서 Task를 진행하였습니다. 각 작업을 10번 수행하였고, 단일 intel realsense 카메라를 사용했다고 합니다!
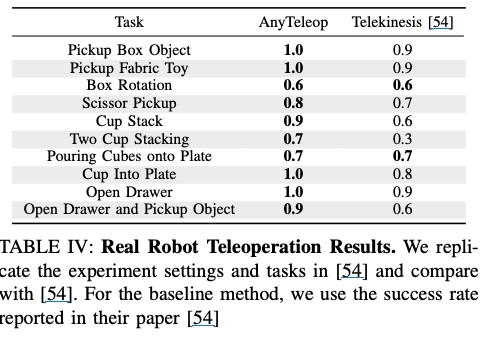
10번밖에 안하긴 했지만 성공률이 기존 방식보다 더 높은 것을 볼 수 있습니다! 중요한 점은 AnyTeleop는 general하게 설계되었지만 기존 baseline은 XArm6, Allegro hardware에 맞게 설계 되었다는 점입니다. 논문에서는 이러한 이유가 최적화 기반의 retargeting module은 손가락 끝 사이의 거리를 좁혀 컵을 더 안정적으로 잡을 수 있게 한다고 설명합니다.
논문에서는 또한 AnyTeleop와 기존 baseline 방식으로 수집한 demonstration 데이터로 imitation learning 알고리즘을 훈련하여 비교하였습니다. 그리고 RL 기반 알고리즘과도 비교를 수행하였습니다!

공정한 비교를 위해 동일한 환경의 simulation 상에서 진행되었으며 Imitation 알고리즘은 Demo Augmented Policy Gradient 방식이 사용되었다고 합니다. task는 Relocate, Flip Mug, Open Door로 구성되었습니다. 그리고 Floating hand는 robot arm 없이 hand만 둥둥 떠다니는 환경이고, Arm-Hand는 robot Arm에 hand가 부착되어 있는 상황입니다. 논문에서는 50개의 demo 궤적을 RGB-D 카메라 하나를 사용해서 수집하였다고 합니다. 기존 baseline 방식은 floating hand 방식만 지원하며, 이 궤적을 arm-hand 형식으로 변환한다고 합니다. AnyTeleop는 Arm-Hand 방식으로 수집하고 이를 Floating hand 형태로 변환하여 모든 버전에서 사용할 수 있게 했다고 합니다.
결과를 분석해보면 Floating Hand 부분에서 Flip Mug를 제외하고 AnyTeleop가 더 높은 성공률을 보인 것으로 나타났습니다. Flip mug 부분이 낮은 이유를 논문에서는 Arm 형태로는 floating hand 방식 보다 복잡한 궤적이 어려워서 시연 품질이 낮아진 이유라고 합니다. 결과적으로 AnyTeleop가 baseline 방식보다 궤적이 smooth해서 정책의 state-action 쌍이 더욱 일관적이기 때문에 model이 더욱 쉽게 학습할 수 있었다고 논문에서는 언급되어 있습니다. 그리고 arm-hand task의 성공률이 유독 높은 이유는 당연하게도 arm-hand 형식으로 demo를 했기 때문이라고 생각합니다.
AnyTeleop는 main contribution은 높은 품질의 일반화된 Teleoperation의 제안이라고 생각합니다. 결국 data-driven robot learning에 있어서 데이터의 질은 중요하므로 앞으로의 Teleoperation 방법들은 이러한 방향으로 발전하지 않을까 생각됩니다. 감사합니다.
안녕하세요 인하님, 좋은 리뷰 잘 읽었습니다!
해당 논문은 다양한 로봇, 카메라, 그리고 real/sim 환경에 구애받지 않는 범용적인 teleoperation 시스템을 제안한 논문이며, 학습 없이도 새로운 로봇에 즉시 적용할 수 있다는 것이 장점인 것 같습니다.
hand pose detection fusion과 관련해 간단한 질문이 있습니다. hand shape parameter가 손가락 길이와 같이 사람 손의 고유한 모양을 나타내는 값이라고 이해했는데, pose estimation 과정에서 이 파라미터가 어떤 식으로 활용되나요? 이 파라미터는 고정된 값인데 왜 매 프레임마다 모든 카메라에 대해 계산하여 하나를 선택해야 하는지 궁금합니다.
감사합니다.
안녕하세요 예은님 좋은 댓글 감사합니다!!
이해하신 부분이 맞습니다.
차근차근 설명해 보겠습니다. 설명하기 전 논문에서는 hand pose parameters를 SMPL-X model을 사용하여 구하게 됩니다. 우선 카메라를 여러대 쓰는 이유가 무엇일까요? 여러 view를 이용해서 pose detection을 수행함으로써 카메라 하나를 사용하는 것보다 더 향상된 성능을 볼 수 있기 때문입니다. 하지만 문제점이 있습니다. (좌표계에 대한 auto-calibration은 이해하신 것 같아서 넘어가겠습니다.) teleopertaion을 수행하는 과정에서 여러 카메라로 pose detection을 수행하였는데 어떤 카메라의 view가 정확히 손의 pose를 인식 정확한 평가의 기준이 없다는 것입니다. 이는 정확한 teleoperation을 위해 매우 중요한 과정입니다. 따라서 논문에서는 초기 N frame으로 hand parameters를 측정 후 이를 기준 hand parameters로 선정을합니다. 그 이후 프레임마다 계산 후 이제 사람이 손을 움직이겠죠? 가림 현상이 발생할 수 있고 그럴 것입니다. 그런 과정에서 가장 오차가 적은(즉 기준 hand parameters 와의 차이가 적은)hand paramters를 다음 retargeting module로 넘김으로써 정확한 retargeting 즉 정확한 teleoperation이 되도록 하는 것입니다. 오차가 제일 적은 hand parameters를 측정한 카메라는 하나겠죠? 그래서 하나를 선택해서 넘깁니다.
안녕하세요, 인하님. 흥미로운 논문 리뷰 잘 읽었습니다.
특히 AnyTeleop의 learning-free motion retargeting 구조와 멀티 로봇 간 일반화 가능성이 인상 깊었습니다.
한 가지 궁금한 점은, Teleoperation server의 모듈 중 hand pose detection과 motion generation이 각각 독립적으로 동작한다고 설명되어 있었는데요. 그렇다면 hand pose retargeting 단계에서 발생할 수 있는 예측 오차나 노이즈가 motion generation 단계에서 별도의 보정 없이 그대로 전달되는 구조인지, 아니면 두 모듈 간에 피드백 루프나 smoothing 메커니즘이 존재하여 갑자기 예외적인 포즈를 구성하는 것을 예방하는 방식을 수행하는지 궁금합니다.
좋은 리뷰 공유해주셔서 감사합니다.🤖
안녕하세요 기현님 좋은 댓글 감사합니다!!
hand pose retargeting 단계는 Mediapipe로 측정한 사람 손가락의 keypoint의 위치와 로봇의 URDF 파일로 알고있는 Forward kinematics를 이용하여 cartesian space 상에서의 두 keypoint들의 위치의 오차를 적게 만드는 로봇 관절의 위치 즉 모터 값을 찾는 문제라고 생각하시면 될 것 같습니다. 이 값이 그대로 motion generation module로 들어가게 됩니다. 이 과정에서 말씀하신 피드백 루프는 존재하지 않습니다. motion generation module에서는 CuRobo 라이브러리를 통해 충돌을 방지하고 자연스러운 움직임을 유도한다고 하는데 CuRobo 알고리즘을 제가 따로 찾아보지는 않아서 정확히 설명드리기는 어려울 것 같습니다. 그리고 hand pose retargeting module에서는 두번째 항으로 beta를 사용하여 이전 관절 값과의 차이를 적게 만들어 각 관절의 부드러운 움직임을 유도합니다. 이러한 방식으로 AnyTeleop에서는 예외적인 포즈를 구성하는 것을 예방하는 것 같습니다.
안녕하세요 인하님 좋은 리뷰 감사합니다.
뭔가 특정 로봇에 국한되지 않는 어느로봇에도 적용가능한 범용적인 teleop 시스템을 만들었다는 점이 인상깊네요.
해당 논문을 찾아보니깐 2023년에 나온 논문같은데 해당 논문이 이런 범용적인 teleop 시스템을 만든 최초 논문인가요?(뭔가 2023년도에 범용적인 모델을 처음 연구하는 그런 논문들이 보여서 단순히 궁금해서 질문드렸습니다..)
그리고 두번째 질문이 제가 Retargeting 최적화 식에서 사용되는 keypoint에 대한 개념적인 부분을 잘 몰라서 드리는 질문일 수 있겠는데, 사람 손의 keypoint와 로봇 손의 keypoint가 1:1로 맵핑되는 것인지,아니면 로봇 손에서는 일부만 사용되는지 궁금합니다. 예를 들어 Allegro Hand는 human hand와 joint 구조가 완전히 동일하지 않은데 리뷰에서는 단순히 로봇 손의 키포인트가 인간 손의 키포인트에 최대한 가깝게 라고만 되어 있어서 세부적인 매칭 전략이 궁금해서 질문 드립니다.
감사합니다.
안녕하세요 인하님 리뷰 감사합니다.
Retargeting 모듈이 learning-free optimization 방식으로 설계된 이유가 학습 기반 접근보다 일반화나 정확도 측면에서 이득이 있기 때문인가요? 아니면 이 논문이 나올떄까지는 아직 학습 기반으로 해결하기 어려운 한계가 있었을까요? 아니면 최적화 방식으로 이미 충분하기 때문에 teleoperation을 위해서는 해당 방법으로 굳어진건가요??