안녕하세요 황찬미입니다.
오늘 살펴볼 논문은 비디오 요약 task에서 multimodel summarization의 문제를 다루는 논문입니다.
동영상이 인풋으로 들어왔을때 통합모델 하나로 텍스트도 요약하고 비디오도 요약할수 있는 MSMO(Multimodal Summarization with Multimodal Output)가 최근 멀티모달 요약 task가 지향하는 바 라고 합니다.
해당 논문은 MSMO의 기존 기법들이 Temporal Alignment(시간정렬 문제)를 고려하지 않고, cross-modal간의 상관관계를 단순하게 처리한다는 문제점을 지적하며 개선된 방법론인 A2Summ(Align and Attend Multimodal Summarization)을 제안합니다
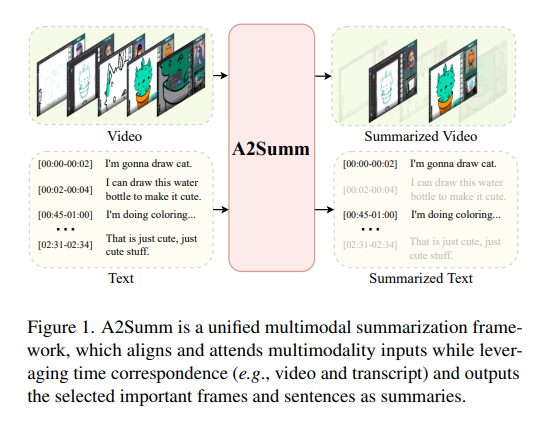
어떻게 개선했는지!! 리뷰 시작하겠습니다~
[Intro]
- multimodal summarization이란? 하나의 입력이 영상과 텍스트처럼 서로 다른 형태(모달리티)를 가질 때 각 모달리티의 정보를 결합하여 중요한 부분만을 추출하고 요약을 생성하는 모델을 말합니다.
- 기존의 방법들
- 초기 연구들은 출력이 비디오 요약 혹은 텍스트 요약 중 하나로 제한되어, 모달리티 간 상호보완적인 정보를 충분히 활용하지 못한다는 한계가 있었습니다.
이를 보완하기 위해 MSMO (Multimodal Summarization with Multimodal Output), 즉 멀티모달 입력으로부터 비디오와 텍스트 요약을 동시에 생성하는 통합 모델이 등장했습니다. - 하지만 여전히
(1) 어떤 문장이 영상의 어느 구간에 해당하는지와 같은 시점 맞춤 정보가 없거나, 있어도 서로 다른 모달 간의 temporal correspondence(시간적 대응관계)를 활용하지 못한다는 문제가 있었고,
(2) RNN이나 attention을 써서 모달 간의 연관을 약하게 학습함으로써 교차모달 간의 상관관계를 단순하게 처리하거나
(3) 비슷한 주제의 영상끼리 어떤 공통점이 있는지와 같은 서로 다른 샘플 간의 intrinsic correlation(내재적 상관관계)을 무시하는 한계가 있었습니다
- 초기 연구들은 출력이 비디오 요약 혹은 텍스트 요약 중 하나로 제한되어, 모달리티 간 상호보완적인 정보를 충분히 활용하지 못한다는 한계가 있었습니다.
저자들은 A2Summ(Align and Attend Multimodal Summarization)이라는 모델을 제안합니다. 단어의 의미를 간단히 살펴보자면 Align으로 서로 다른 모달을 시간적으로 맞추고, Attend로 self-attention을 통해 상호 정보를 통합하여 Align과 Attend를 동시에 수행하는 트랜스포머 기반 통합모델입니다.
대표적으로 제안하는 구조는 Alignment-Guided Self-Attention로, 시간적으로 정렬된 attention mask를 적용해서 비디오 프레임과 자막 문장간의 관계를 직접 연결함으로 같은 타임스탬프에 위치한 비디오-텍스트만 서로 attend하도록 유도하는 모듈입니다.
즉, 시간정렬 정보를 attention mask에 주입하여 같은 time-window에 속한 프레임-문장 쌍만 attend하도록 만들어 줌으로 비디오의 모든 문장에 주의를 기울이게 되는 단순 전역 cross-attention으로 인한 불필요한 noise를 줄이고 시점이 정렬된 멀티모달 융합을 구현하였습니다.
[Method]
A2Summ
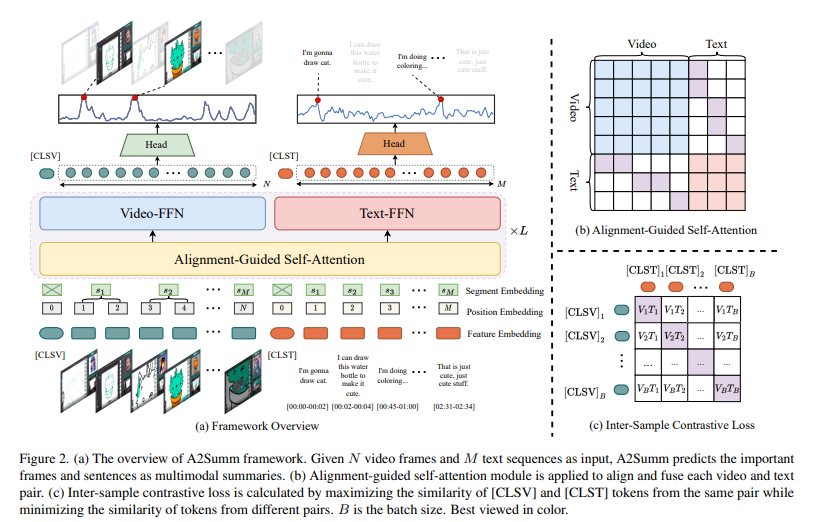
저자들의 목표는 untrimmed한 다중모달 입력이 주어졌을때 각 모달리티에서 가장 중요한 부분을 잘 선택하는 것이 목표입니다.
A2Summ은 N개의 비디오 프레임과 M개의 문장으로 구성되어 있고 각 전사문장은 시작시(ts)과 종료시간(te)을 가지고 있기 때문에 비디오와 텍스트는 해당 시간정보를 기준으로 자동으로 정렬(aligned)될수 있습니다. 즉, 수동 주석이 없이도 비디오-텍스트 간의 temporal정렬이 가능합니다.
- 전체 architecture 흐름 (fig2)
(1) 입력임베딩 : 모달리티별 특징을 추출해 동일 차원의 임베딩 공간으로 투영함
(2) 다중모달 정렬 및 융합 : Alignment-Guided Self-Attention을 통해 시간 정렬 기반으로 융합함
(3) 손실함수 : Focal loss + Inter-sample contrastive + Intra-sample contrastive 결합함
→ 한마디로 비디오와 텍스트를 임베딩하여 하나의 시퀀스로 결합한 뒤, 시간적으로 정렬된 self-attention으로 융합하고 dual contrastive loss로 학습하여 중요도 스코어를 산출하는 구조입니다
[입력 임베딩- fig2(a)]
- Feature Extraction
비디오 프레임과 텍스트는 사전학습된 특징추출기(ex. GoogLeNet, RoBERTa)를 사용하여 각각의 특징을 추출합니다.
추출된 특징벡터들은 FClayer를 거쳐 공통의 C차원 임베딩 공간으로 투영됩니다. - Positional embedding
BERT 구조처럼 각 시퀀스의 맨 앞에 [CLS] 토큰을 붙여주고 이 토큰은 이후 inter-sample contrastive loss계산에 사용됩니다
또한 learnable한 positional embedding을 추가해 순서 정보를 포함시킵니다. - Segment Embedding
각 문장은 [ts, te]의 시간 구간을 가지며 해당 구간에 포함되는 프레임들을 같은 세그먼트로 간주하여 동일한 segment embedding를 공유하게 됩니다.
이렇게 하면 트랜스포머가 이 프레임과 이 문장이 시간상 같은 구간이네! 하는 정보를 내장하게 됩니다.
즉, 시간축 정렬정보를 임베딩 단계부터 주입하여 이후의 alignment-guided attention에서 더 정밀한 매칭이 가능해집니다. - 최종 입력 시퀀스 X
비디오 시퀀스와 텍스트 시퀀스를 시간축으로 이어붙여서 하나의 입력 시퀀스 X를 구성하고 이것을 트랜스포머 인코더에 입력합니다.
트랜스포머는 이 시퀀스X를 읽으며 이 문장과 프레임이 동시에 발생했구나! 하는 관계를 학습하게 됩니다.
[Multimodal Alignment and Fusion– fig2(a), fig2(b)]
- Alignment-Guided Self-Attention A2Summ의 핵심 구성요소로 두 모달리티 간의 시간적 정렬 정보를 활용하여 모달간의 입력을 효과적으로 융합하도록 설계된 모듈입니다.
- 트랜스포머 구조를 기반으로 하며 비디오 요약 task의 대부분은 untrimmed 데이터로 구성되는데 이런 데이터들은 불필요한 배경 정보(중요하지 않은 정보)가 압도적으로 많습니다. 이때 멀티모달 입력에 대해 global self-attention을 그대로 적용하면 이 불필요한 노이즈가 융합과정에 유입될 수 있습니다.
- 이것을 방지하기 위해 Fig2(b)와 같이 masked self-attention 연산을 사용합니다. 비디오길이 N, 텍스트길이 M의 0으로 초기화된 attention mask 행렬을 먼저 정의하고 이 마스크가 시간정렬 정보를 표시하도록 설계합니다. 같은 모달리티 간에는 표준 global attetnio을 적용해 모든 정보를 확인할 수 있게하고, cross-modality간에는 동일한 segment embedding을 가진 경우에만 attention이 수행되도록 마스크의 값을 1로 설정합니다. 이렇게 구성된 마스크는 아래의 수식에서 A_i로 기본 self-attention연산 과정에 적용됩니다.
- 결과적으로 서로 다른 모달리티 간의 정렬 정보를 마스크로 명시적으로 활용함으로써 배경프레임이나 무관한 문장으로 인한 노이즈를 효과적으로 줄일 수 있습니다.
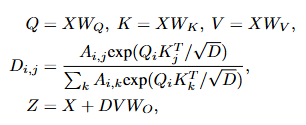
[Mixture-of-Modality Experts & Score Prediction]
- self-attention 이후에는 두 개의 모달 전용 FFN(비디오 전문가Video-FFN, 텍스트 전문가Text-FFN)을 두어 각각의 모달 특성을 독립적으로 학습합니다. 마지막으로 모달별 헤드를 통해 프레임,문장별 중요도 score를 예측하고 이를 기반으로 두 모달리티의 최종 요약을 생성합니다.
→ 즉, 공유된 어텐션으로 융합하고 → 모달별 FFN으로 세분화하고 → 모달별 헤드로 중요도를 예측하는 구조입니다.
[Loss Function]
최종 Loss Function은 classification loss + Inter-Sample Contrastive Loss + Intra-Sample Contrastive Loss의 세 손실의 조합으로 구성됩니다

- Classification Loss (Focal Loss)
각 프레임 또는 문장이 핵심(1)인지 비핵심(0)인지 예측하는 이진 분류 손실입니다.
핵심 구간이 비핵심 구간보다 훨씬 적어 발생하는 클래스 불균형 문제를 Focal loss를 사용해 틀리거나 어려운 샘플에 더 큰 가중을 주어 완화합니다. - Inter-Sample Contrastive Loss (샘플 간 대조손실)
배치내의 가능한 비디오-텍스트 조합 중 올바른 동일 샘플 쌍을 맞히도록 설계됩니다.
각 샘플의 [CLS]토큰을 사용하여 배치크기를 B라고 할때 B개의 정답 쌍에 대해 비디오-텍스트 임베딩의 코사인 유사도를 극대화하고, 나머지 오답 쌍 과는 유사도를 최소화 하도록 학습합니다.
이를 통해 샘플간의 구별 능력을 강화합니다 - Intra-Sample Contrastive Loss (샘플 내 대조손실)
동일한 비디오-텍스트 쌍 내부에서 핵심구간과 비핵심구간을 구분하기 위해 사용됩니다.
비디오 요약 task에서는 긴 영상속에서 배경 프레임이나 덜 관련된 문장을 배제하는것이 핵심이기 때문에 동일한 샘플 내에서도 대조학습을 수행합니다.
Contrastive pair구성은 미리 정의된 positive pair(GT-연결된 피처)를 기준으로 nagetive샘플은 hard negative를 사용합니다. 즉 GT와 인접하지 않으면서도 중요도 score가 높은 시점을 negative로 선택합니다.
fig3(a)의 상단 띠 그래프처럼 GT key-frame(정답 핵심구간)의 양쪽을 확장하여 인접 프레임까지 더미로 positive에 포함한 뒤, 그 구간 밖에서 top-k에 해당하는 시점을 hard negative로 선택합니다. 이렇게 구성된 contrastive pair를 통해 모델은 비슷하지만 핵심이 아닌 구간!을 정확히 구별하도록 학습됩니다.
[Dataset & Experiment]
[Dataset]
실험은 다섯 개의 데이터셋을 사용하여 진행되었습니다. 두개의 video summarization 데이터셋(SumMe, TVSum)과 두개의 multimodal summarization 데이터셋(Daily Mail, CNN), 마지막으로 저자들이 새롭게 제안한 Behance LiveStream Summarization (BLiSS) 데이터셋입니다.
- BLiSS Dataset
비디오 프레임에서는 CLIP, 텍스트 문장에서는 RoBERTa를 사용해 각각의 피처를 추출합니다. 총 674개의 livestream 비디오와 그에 대응하는 transcripts로 구성되어 있으며, 각 비디오는 5분 단위 클립으로 분할되어 있습니다. 각 클립마다 사람이 직접 transcripts에서 핵심 문장을 선택하고, 클립 별 요약문과 핵심 키워드를 작성하였습니다. 또한 영상이 업로드된 페이지의 썸네일 이미지와 가장 유사한 프레임을 GT(key frame)으로 사용했습니다. BLiSS는 기존의 멀티모달 데이터셋과 비교하여 13,303개의 데이터 샘플과 총 1,109 시간의 비디오로 구성된 훨씬 대규모이고 잘 정렬된 데이터셋입니다. (대표 기존데이터셋: TVSum(3.5시간), DailyMail(44.2시간)
[Evaluation]
- video summarization
GT와 프레임 단위의 일치도의 F1 score, 예측된 중요도 순서와 GT순서의 불일치 비율을 측정하 Kendall’s τ, 두 순위의 순서간의 상관관계정도를 측정하는 Spearman’s ρ를 사용하여 평가합니다. (뒤의 두 지표는 예측된 중요도 순위가 GT 순위와 얼마나 유사한지를 평가하는 평가지표입니다) - text summarization
ROUGE F1 (R-1 단어 단위/ R-2 연속 단어 쌍/ R-L 문장 길이 단위)로 생성된 요약과 GT요약의 중첩도를 통해 평가를 진행합니다. - 비디오–텍스트 통합 평가
예측된 비디오 요약과 GT비디오 요약간의 코사인 유사도를 통해 측정합니다.
[SumMe, TVSum vs A2Summ]
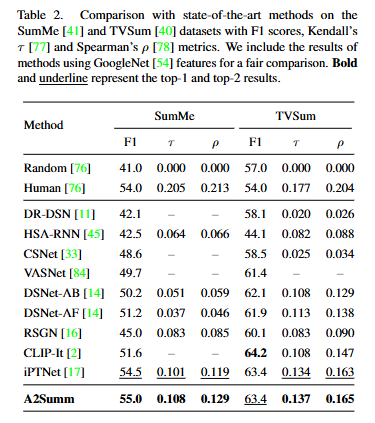
Table2결과에 따르면 A2Summ은 기존 SOTA 방법들과 비교했을 때 SumMe와 TVSum 데이터셋 모두에서 우수한 성능을 달성했습니다. 특히 순위기반 지표에서 높은 상관도를 보임으로 중요 구간의 정확한 탐지 능력을 가지는 것을 알수 있습니다.
[Daily Mail, CNN vs A2Summ]

Table 1은 멀티모달 요약 결과를 보여줍니다. ROUGE F1 점수와 비디오–텍스트 간 코사인 유사도 모두에서 A2Summ이 alignment-guided attention과 dual contrastive loss를 통해 두 모달리티의 정보를 효과적으로 학습하여 기존 방법들을 전반적으로 능가하는 성능을 보였습니다.
[BLiSS dataset]

Table3은 새로 제안한 BLiSS데이터셋에서의 비교 결과를 보여줍니다. A2Summ은 결과로 확인할 수 있듯이 라이브스트림 같이 길고 복잡한 데이터셋에서도 대표적인 비디오 요약 기법과 텍스트 요약 기법 모두보다 높은 성능을 달성하는 것을 확인할수 있습니다.
[시각화결과]
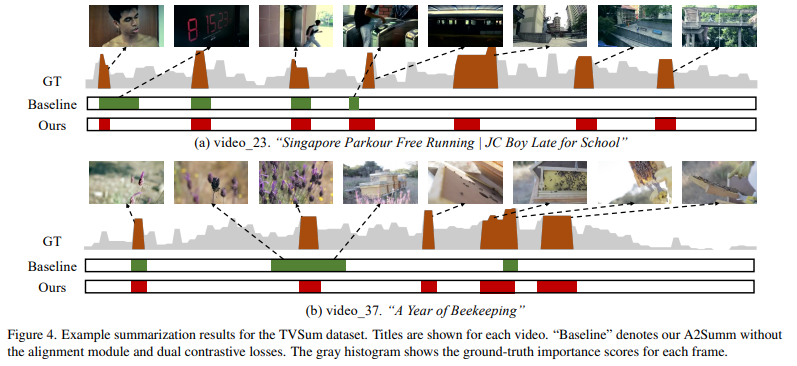
fig4에서 알수 있듯이 기존 모델들의 중요구간 누락이나 부정확한 예측 등의 문제를 A2Summ은 시간정렬 정보(temporal alignment)와 샘플 간&샘플 내 대조학습을 함께 활용함으로써 핵심 구간을 보다 정교하게 잡아낼수 있었습니다.
요즘 비디오요약 task와 관련된 논문 작성을 목표로 해당 논문을 베이스라인으로 분석을 슬슬 시작하고 있습니다! 분석을 기반으로 어떤 문제를 새롭게 정의하고 어떤 방향으로 확장할 수 있을지를 고민하며 구체적인 연구방향을 잡아갈 예정입니다!
이제 막 시작하는 첫 연구라 그런지 아직까진 흥미진진합니다🤓 이 마음이 계속되길~~
읽어주셔서 감사합니다 🙂
이상으로 리뷰 마치겠습니다 !
안녕하세요, 리뷰 잘 읽었습니다
1. introduction에서 언급해주신 ‘내재적 상관관계(intrinsic correlation)’의 예시가 무엇인지 궁금합니다. 같은 주제의 영상 정도라고 작성해주셨는데 summarization 관점에서 내재적 상관관계가 구체적으로 어떤거고, 왜 필요한지가 궁금해서요. 그리고 나아가서 본 논문이 이 기존 한계를 극복했다고 보인 실험이 있었을까요? 아니면 성능 향상을 통해 간접적으로 주장하는 수준이었나요?
2. 비디오는 GoogLeNet, 텍스트는 RoBERTa로 추출한다고 하셨는데, 요즘에 많이 쓰이는 백본(ViT or CLIP) 대비 표현력/속도 트레이드오프에 대한 코멘트가 있었나요? 백본 교체에 대한 성능 및 언급은 없었을까요?
3. 비디오·텍스트를 하나의 시퀀스로 단순 연결(concat) 후 인코딩하는 방식이, 모달 스케일 불균형(프레임 수 ≫ 문장 수)에서 bias 가 될 수도 있을 것 같은데, 추후 논문에서는 이를 개선하는 시도 혹은 방향은 없었나요?
안녕하세요 주영님 댓글 감사합니다 🙂
1a : 요악관점에서 내재적 상관관계라고 하면 샘플간의 의미적인 유사성이나 패턴관계를 말하는데 조금 더 단순히 얘기하자면 주제가 비슷한 여러 영상(자막)들 사이에 반복적으로 나타나는 공통적인 패턴(핵심 장면이나 순서 등)을 말합니다!
기존 방법들은 이런 샘플간의 규칙성을 거의 안쓰거나 약하게만 사용하는데 본 논문은 내재적 상관관계를 inter-sample contrastive loss를 통해 학습과정에서 추가적인 self supervision을 형성할수 있고, 또 공통적인 패턴을 학습하여 일관된 요약을 생성하기 위함이라고 합니다.
한계에 대한 실험은 Ablation study에서 샘플 간의 내재적 상관관계 학습에 해당하는 inter-sample contrastive loss를 추가했을때가 하지 않았을때 보다 성능이 높다!로 간접적으로 주장합니다!
2a : 오호!! 주영님이 질문해주신 덕분에 제가 잘못 적어놓은 부분을 확인했습니다! 비디오는GoogLeNet, 텍스트는 RoBERTa가 아니라 ‘사전학습 특징추출기(예. GoogLeNet, RoBERTa)로’ 해당 내용 수정해두었습니다!! 감사합니다~
실제로는 데이터셋별로 관행(?)에 따라 SumMe,TVSum은 GoogLeNet으로 비디오피처를 사용하는데 저자들이 제안하는 BLiSS는 말씀주신 대로 요즘 많이쓰는 백본인 CLIP으로 비디오 피처를 추출합니다.
3a : 저자들도 프레임수(N개)<문장수(M개)라는 문제가 있기 때문에 이걸 해결하기위해 segment embedding이라는 기법을 제안했습니다. 프레임이 훨씬 많더라도 같은 문장에 속하는 프레임에는 공통 세그먼트임베딩을 부여하는것으로 과도하게 프레임쪽으로 쏠리는 편향을 완화하고자 했습니다! 해당 문제를 여기서 더 개선하고자 하는 시도나 방향은 현재 제가 아는 바로는 없습니다!
안녕하세요 황찬미 연구원님. 좋은 리뷰 잘 읽었습니다.
비디오쪽 논문은 처음이라 흥미로웠습니다.
간단한 질문이 있습니다.
해당 논문의 접근은 multimodal에서 untrimmed를 해결하는 과정으로 이해했습니다.
같은 modality에서는 그대로 global attention을 한다면, 같은 modality에서는 untrimmed 문제가 남아있는게 아닌가 궁금합니다.
안녕하세요 찬미님 좋은 리뷰 감사합니다.
읽으면서 궁금했던 점을 질문드리자면 저자각 제안한 방식이 불필요한 attention cost 를 줄였다면 얼마나 줄엇는지에 대한 실험이나 그로 인한 정량적 성능이 존재했는지 궁금합니다.
그리고 Classification loss 부분에서 focal loss 설명하는 부분이 있는데, 그냥 0~1의 확률적 값으로 하는건 어떤지, 가능한건지 궁금합니다.
감사합니다.
황찬미 연구원님. 좋은 리뷰 감사합니다. 리뷰를 읽는 도중 정확히 이해가 가지 않는 부분들이 있어서 질문 드리겠습니다.
1. untrimmed data에서 불필요한 배경 노이즈를 줄이기 위해 masked self-attention 을 사용하는데, 정확히 마스킹을 어떤 영역에 하는건지 궁금합니다. video와 text의 각 embedding들을 concat해서 Self-Attention 수행할 때 video 끼리, text끼리는 global attention을 수행하고 V-T간에만 masking을 적용하는것 같은데 그럼 시간적으로 정렬되어 있는 video-text 간에만 self-attention을 수행하고 나머지는 마스킹을 한다는 뜻인가요?
2. 그리고 해당 모듈에서 SA와 별개로 시간적으로 정렬된 Video-text embedding끼리만 positive pair로 묶어서 contrastive learning을 동시에 수행하는건지 궁금합니다.
3. 마지막으로, classification loss에서 프레임 / 문장이 핵심인지 비핵심인지 binary classification을 수행한다고 하는데, 이 핵심 정보들이 정확히 무엇인지 답변해주시면 감사하겠습니다. 데이터셋에 annotation으로 주어지는것 같은데 핵심으로 취급하는 데이터들이 어떤 특징을 가지고 있는지, anootation이 어떻게 되어있는지 궁금하네요.
감사합니다.
안녕하세요 찬미님 비디오 요약연구를 리뷰해주셔서 감사합니다.
입력임베딩 생성부분에 궁금한점이 있습니다. 서로 다른 인코더로 표현된 두 모달리티의 특징벡터가 FClayer로 임베딩 되는것으로 이해했는데, 해당 FClayer의 파라미터 학습에는 contrastive learning, 중요도에 대한 이진분류 목적함수가 관여하는것 같습니다. 그러나 학습 데이터의 크기가 충분하지 않은 만큼(특히 TVSum, Summe) 조금 더 명시적인 맥락 학습 로스를 추가하는 것에 대해 어떻데 생각하시나요?
CLIP과 같은 방법론은 Webscale의 데이터셋으로 학습하기에 contrastive learning등으로 맥락 정보를 학습하기에 충분하겠지만, 해당 방법론은 그렇지 않을 것 같아 질문 남깁니다. T-SNE 등으로 학습 전과 후의 텍스트와 비전 도메인의 특징벡터를 뽑아보는것도 좋을 것 같습니다.
위의 연장선으로 CLIP, SigLIP과 같은 임베딩 모델을 활용하거나 DINOv2와 같은 비전 정보를 강화한 모델의 임베딩을 사용했을때 결과를 분석해보는것은 어떨까 궁금하네요
감사합니다