Video Text Retrieval에 대한 논문을 준비하고 있어, 해당 주제의 논문을 리뷰해보겠습니다.

- Conference: ICCV 2023
- Authors: Qinghao Ye, Guohai Xu, Ming Yan, Haiyang Xu, Qi Qian, Ji Zhang, Fei Huang
- Affiliation: Alibaba Group
- Title: HiTeA: Hierarchical Temporal-Aware Video-Language Pre-training
1. Introduction
최근 비디오(Video)-언어 사전학습(VLP, Video-Language Pretraining)이 활발히 연구되고 있습니다. 기존 연구들은 주로 이미지(Vision)-언어 사전학습의 성공을 기반으로 확장되었으며, 대규모 VLP은 비디오-텍스트 검색, 질의응답, 캡션 생성 등 다양한 멀티모달 태스크에서 성능 향상을 이끌어냈습니다.
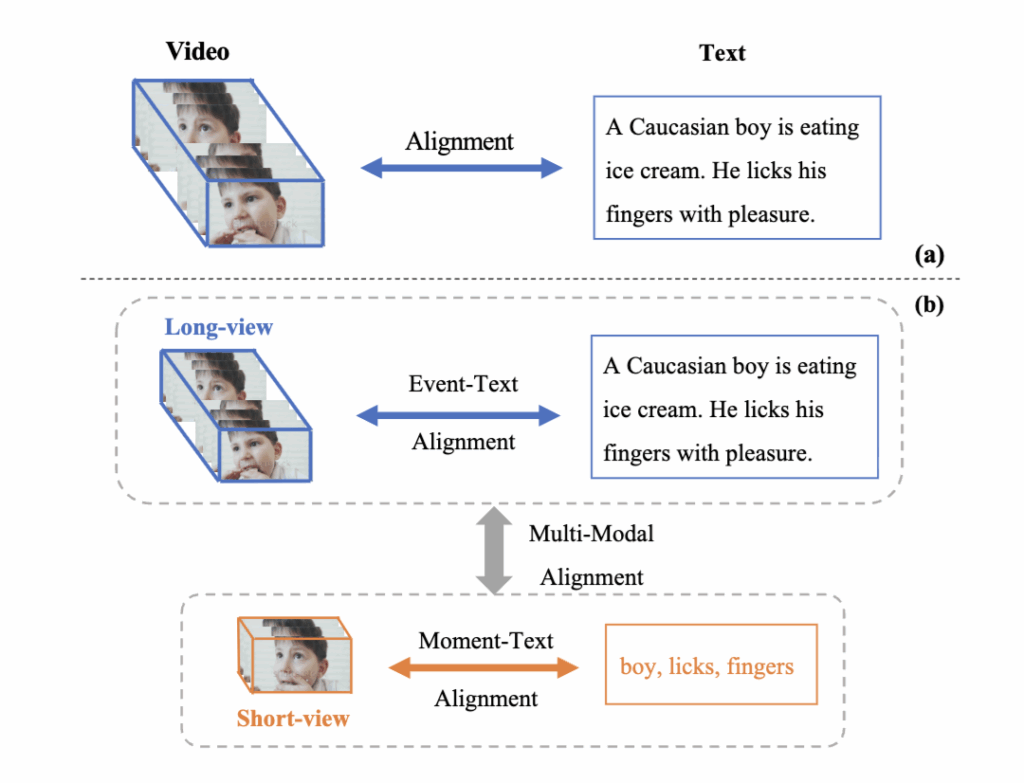
하지만 대부분의 모델은 비디오를 하나의 전체 단위(global view)로 처리해 시간적 맥락을 놓치는 한계가 있었습니다. 예를 들어 상단 그림 1(b)에서 짧은 구간(short-view)은 ‘손가락을 핥는’ 순간(moment)을, 긴 구간(long-view)은 ‘아이스크림을 먹는’ 사건(event)을 표현하지만, 기존 모델은 이런 세밀한 순간 정보를 포착하지 못하거나 두 구간 간의 인과 관계를 학습하지 못했습니다.
이러한 문제를 해결하기 위해 저자들은 HiTeA (Hierarchical Temporal-Aware) 프레임워크를 제안했습니다. HiTeA는 비디오를 긴 시점(long-view)과 짧은 시점(short-view)으로 나누어 계층적 시간 표현을 학습하며, 두 가지 새로운 모듈을 제안하였습니다. ① Cross-modal Moment Exploration (CME): 짧은 구간의 비디오와 관련된 텍스트 단어를 정렬하여 세밀한 순간 정보를 학습하고, ② Multi-modal Temporal Relation Exploration (MTRE): 서로 다른 시점의 비디오-텍스트 쌍을 맞춰 시간적 관계를 학습합니다.
이를 통해 모델은 ‘순간’과 ‘이벤트’를 연결하며 시간의 흐름과 인과적 관계를 이해하게 됩니다. 또한 저자들은 기존 데이터셋이 정적 장면 중심으로 치우친 문제를 지적하며, 프레임 순서를 섞어 모델의 시간 의존성을 평가하는 Temporal Shuffling Test를 제안했습니다. 본격적인 설명 시작하겠습니다.
2. Method
2.1. Overview
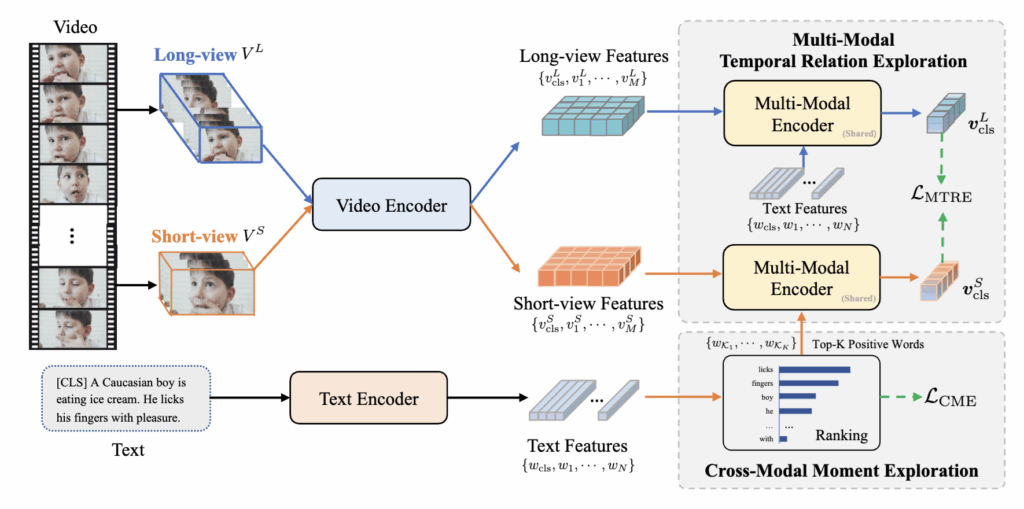
HiTeA 모델의 전체 구조는 Figure 2에 제시되어 있습니다. 모델은 크게 세 가지 구성요소로 이루어져 있으며, 비디오와 텍스트를 각각 인코딩하는 두 개의 단일 모달 인코더(unimodal encoders), 두 모달리티 간 상호작용을 담당하는 멀티모달 인코더(multi-modal encoder), 그리고 텍스트 생성을 위한 디코더(text decoder) 로 구성되어 있습니다.
기존 방법들은 비디오 전체를 하나의 단일 시점(single-view)으로 인코딩했기 때문에, 비디오 속에 존재하는 다양한 시간적 세부 정보(temporal detail)를 충분히 반영하지 못했습니다. 이에 반해 HiTeA는 입력 비디오를 두 가지 시점으로 나누어 처리합니다.
- Long-view (Vᴸ): 전체 비디오를 활용해 사건(event)-수준 정보를 학습
- Short-view (Vˢ): 임의로 잘라낸 짧은 구간으로 순간(moment)-수준 정보를 학습
이렇게 두 시점을 통해 시간적 계층 구조를 구성하고, 비디오 인코더를 통해 각각의 비디오를 임베딩 시퀀스로 변환합니다. CLS 토큰은 비디오의 전체 의미를 대표하는 global 표현이고, 텍스트 인코더 또한 문장을 토큰 시퀀스로 변환해 유사한 구조로 정렬됩니다. 이후 멀티모달 인코더가 두 모달리티를 통합하여 비디오의 다중모달 표현을 생성합니다.
또한, HiTeA는 두 시점의 정보를 최대한 활용하기 위해 두 가지를 제안하였습니다. 첫째, Cross-modal Moment Exploration (CME) 은 짧은 구간의 비디오와 관련된 텍스트 단어나 구절을 정렬해 세밀한 순간 정보를 학습합니다. 둘째, Multi-modal Temporal Relation Exploration (MTRE) 은 짧은 구간(moment)과 긴 구간(event) 사이의 시간적 관계를 모델링해 인과적 맥락을 포착합니다. 이 두 과제를 통해 HiTeA는 비디오 속 시간 구조를 이해하고, 텍스트와의 의미적 정렬을 더욱 정교하게 수행할 수 있었습니다. 이제 각 제안 방식에 대해 설명드리겠습니다.
2.2. Cross-Modal Moment Exploration
짧은 시간 구간(short-view)으로 구성된 비디오는 세밀한 순간(moment) 정보를 담고 있지만, 함께 제공되는 텍스트는 종종 비디오의 일부만을 설명하기 때문에 노이즈가 포함될 수 있습니다. 예를 들어, “아이스크림을 먹는 소년”이라는 캡션은 실제로는 ‘손가락을 핥는 장면’만 담긴 짧은 구간과 정확히 일치하지 않을 수 있죠. 이러한 불일치는 모델이 순간 단위 정보를 학습하는 데 방해가 됩니다.

이를 해결하기 위해 HiTeA는 Cross-Modal Moment Exploration (CME)를 제안했습니다. CME는 텍스트 내에서 짧은 비디오 구간과 의미적으로 가장 밀접한 단어를 찾아내어, 해당 단어와 비디오를 positive pair 로 정렬하는 방식입니다. 다시말해, 텍스트 인코더에서 얻은 임베딩들과 비디오 인코더의 short-view CLS 토큰 간 코사인 유사도(cosine similarity) 를 계산하고, 그중 상위 K개의 단어를 선택합니다. 이렇게 선택된 단어들은 해당 구간의 핵심 의미를 표현하는 단서로 사용됩니다.
이후 선택된 단어(positive word)와 짧은 비디오 구간(positive video)을 정렬하고, 나머지 단어들은 negative samples 로 처리하여 CME Loss(L_\text{CME}) 을 계산합니다. 이러한 방식으로 모델은 텍스트의 세부 단어와 순간 비디오 정보를 정밀하게 연결하여, 세밀한 시간 단위의 의미적 정렬 능력을 강화할 수 있었다고 합니다.
2.3 Multi-Modal Temporal Relation Exploration
비디오 인코더가 시간적 맥락 관계(temporal contextual relations) 를 명시적으로 파악하는 데에는 여전히 한계가 있습니다. 기존의 비디오-언어 사전학습은 주로 텍스트와 비디오 간 의미적 정렬(alignment)에 집중했기 때문에, 텍스트가 비디오의 시간 정보를 안내하는 역할은 거의 고려되지 않았습니다. 이로 인해 모델은 장면이나 객체 중심의 정보에 치중하고, 시간의 흐름이나 사건 간 인과 관계를 놓치는 문제가 있었죠
이를 해결하기 위해 HiTeA는 Multi-Modal Temporal Relation Exploration (MTRE) 을 제안했습니다. MTRE는 비디오의 시간적 계층(long-view / short-view) 간 관계를 학습하여, 짧은 순간(moment)과 긴 이벤트(event) 간의 맥락을 연결하는 방식이죠
- Short-view 비디오(Vˢ) 는 세밀한 순간 정보를 담고,
- Long-view 비디오(Vᴸ) 는 사건(event) 수준의 전체적인 구조를 표현합니다.
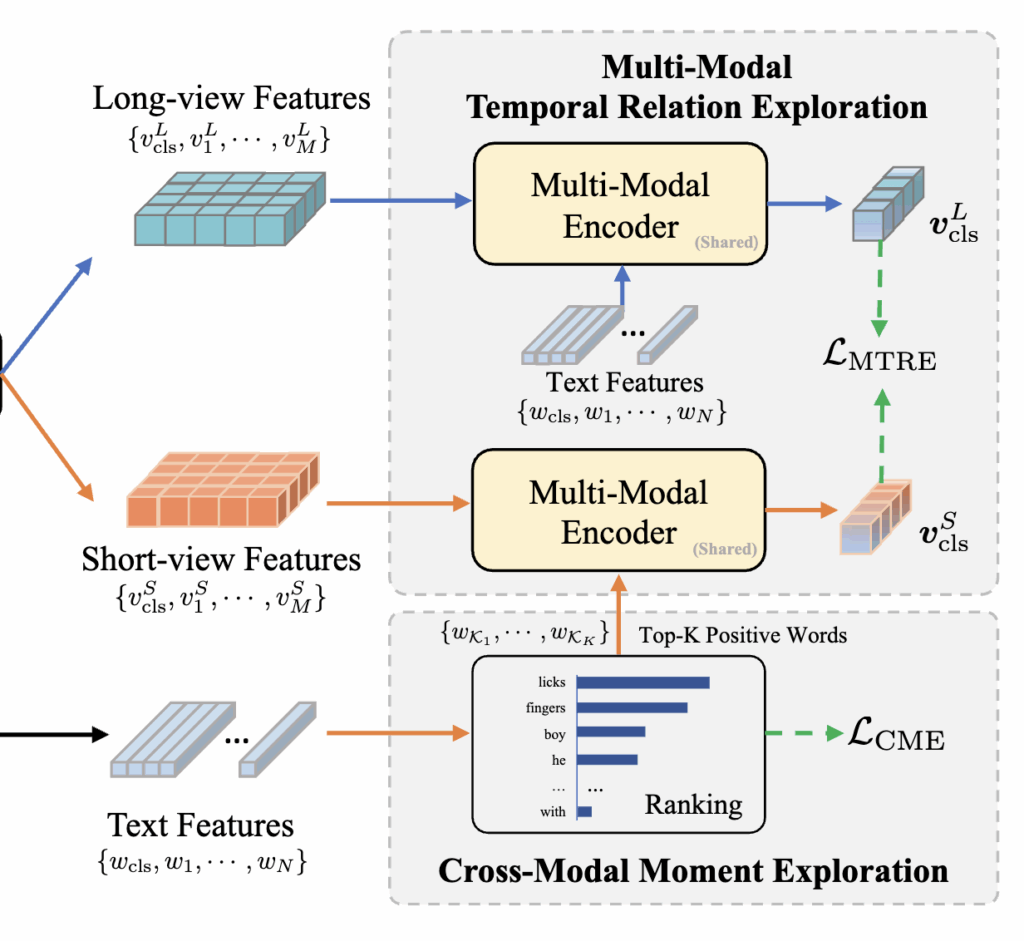
모델은 두 시점을 각각 인코딩한 후, 멀티모달 인코더를 통해 텍스트와 상호작용시켜 텍스트-가이드 비디오 표현(text-guided video representation) 을 생성합니다. 이때 short-view의 경우 텍스트 전체보다는 CME 단계에서 선택된 positive words 만을 사용하여 표현을 보정합니다. 이렇게 함으로써 비디오-텍스트 쌍의 불일치로 인한 노이즈를 줄이고, 순간 단위 표현을 더 정교하게 만들 수 있었다고 합니다.
이후 모델은 두 시점의 표현이 서로 얼마나 유사한지를 학습하기 위해, short-view와 long-view 간의 텍스트-가이드 표현을 정렬합니다. 구체적으로는 SimSiam 프레임워크를 활용해 두 표현 간의 negative cosine similarity 를 최소화하며, 두 시점이 시간 규모가 다르더라도 비슷한 의미적 구조를 공유하도록 유도하였습니다. 마지막으로, Loss (L_\text{MTRE}) 를 정의하여, 두 비디오 표현 간의 일관된 시간적 맥락 학습을 수행했습니다.
결과적으로 MTRE는 CME에서 학습된 순간 단위 표현을 기반으로, 시간의 흐름 속에서 사건들이 어떻게 연결되는지를 모델이 스스로 학습할 수 있게 하여, 비디오의 전체 구조를 더 깊이 이해하도록 돕는 역할을 한다는 것으로 이해하면 좋을 것 같네요
최종 Loss는 기존 VTR 기본 Loss에 위에서 제안한 CME, MTRE Loss를 모두 합산하여 계산됩니다.
3. Experiment
3.1 Experiment Setup
Pre-training Datasets
HiTeA는 사전학습 단계에서 WebVid-2M과 CC3M (Conceptual Captions) 두 가지 공개 데이터셋을 사용했습니다. 기존 연구들은 HowTo100M(1.36억 쌍), YT-Temporal-180M(1.8억 쌍) 등 훨씬 더 큰 규모의 데이터셋으로 사전학습을 수행했지만, HiTeA는 계산 효율성을 위해 중간 규모의 데이터셋만을 활용했습니다. 이는 대규모 학습 없이도 시간적 표현 학습이 가능함을 보여주기 위함이라고 하네요.
Downstream Datasets
HiTeA의 성능은 총 18개의 Video-Language 벤치마크에서 평가되었습니다. 주요 태스크는 다음 세 가지로 나뉩니다.
① Video-Text Retrieval
사용된 데이터셋: MSRVTT, DiDeMo, LSMDC, ActivityNet Caption, SSv2-Label, SSv2-Template
② Video Question Answering (VideoQA)
1. MC (Multiple Choice): TGIF-Action, TGIF-Transition, MSRVTT-MC, LSMDC-MC, NExT-QA
2. OE (Open-Ended): TGIF-Frame, MSRVTT-QA, MSVD-QA, LSMDC-FiB, ActivityNet-QA
③ Video Captioning
사용된 데이터셋: MSRVTT, MSVD
즉, HiTeA는 단순한 검색이나 캡션 생성뿐 아니라, 비디오 이해와 시간적 추론 능력까지 포괄적으로 검증될 수 있는 실험 세팅을 구성하였다고 합니다.
Implementation Details
We pre-train HiTeA for 10 epochs, using a batch size of 16 on 8 NVIDIA A100 GPUs.
3.2 Comparison to Prior Arts
3.2.1 Text-to-Video Retrieval
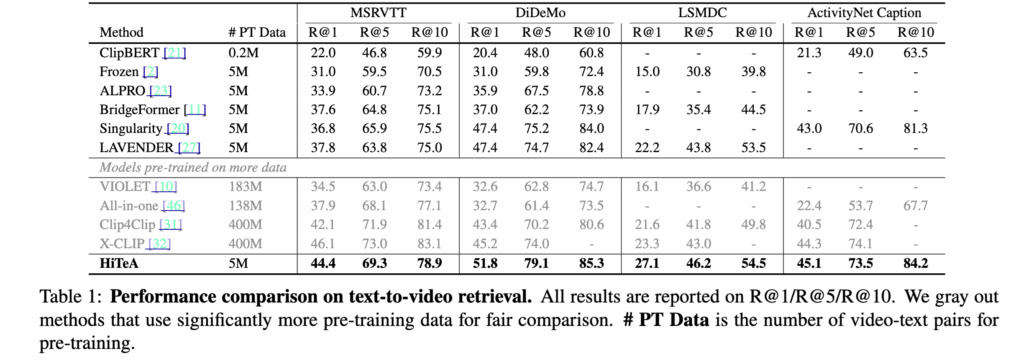
모든 데이터셋에서 HiTeA는 기존의 모델보다 우세한 성능을 보였습니다. 특히, 5M 비디오-텍스트 쌍만 사용했음에도 MSRVTT에서 R@1 기준 6.6% 향상을 기록했고, CLIP 인코더를 사용하는 최신 모델들과 비교했을 때도 비슷하거나 더 나은 성능을 보여, 제안한 방법의 효율성과 성능을 입증했습니다. LSMDC 데이터셋에서도 영화 클립 내 다양한 순간 정보를 효과적으로 활용하여 우수한 결과를 얻었습니다.
3.2.2 Video Question Answering
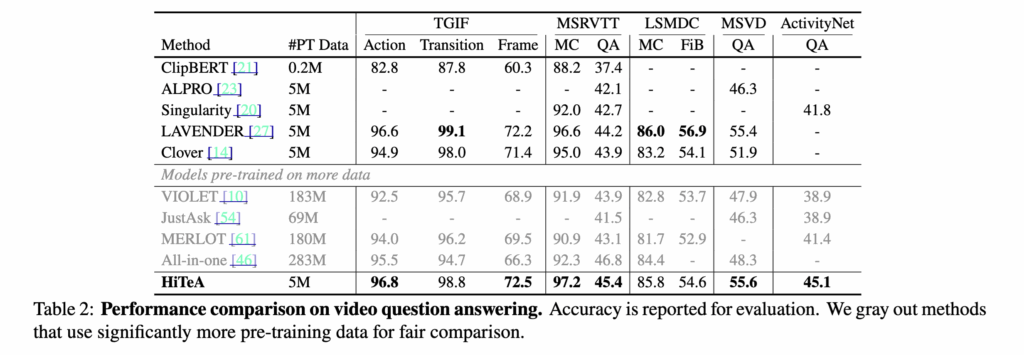
9개의 VideoQA 데이터셋에서, HiTeA는 적은 사전학습 데이터로도 대부분의 벤치마크에서 최고 성능을 달성했습니다. 이러한 결과는 CME 모듈을 통해 학습된 순간 단위 정보가 질문의 단서(clue)를 찾는 데 효과적임을 보여준 것입니다.
3.2.3 Video Captioning
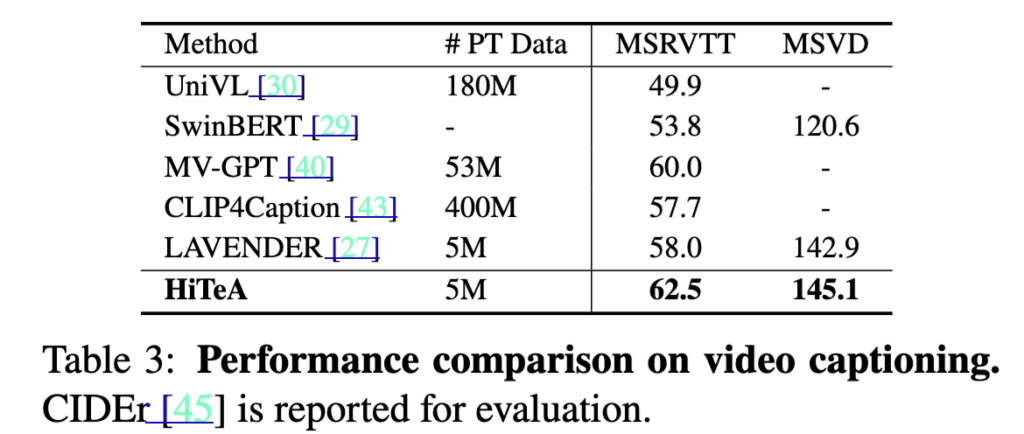
MSRVTT와 MSVD 캡셔닝 실험에서 HiTeA는 기존 대규모 사전학습 모델보다 적은 데이터로도 높은 생성 성능을 달성했습니다. 특히 MSRVTT Caption에서 SoTA 모델인 MV-GPT보다 2.5% 높은 CIDEr 점수를 기록했습니다. 재밌는 점은 MV-GPT가 오디오 기반 전사(ASR) 정보까지 추가 입력으로 사용하는 반면, HiTeA는 순수히 비디오 입력만으로 이 성능을 달성했다는 점입니다. 이는 HiTeA가 시간적 문맥과 순간적 정보를 동시에 학습하는 강력한 표현력을 지녔음을 보여준다고 하네요.
3.3 Discussion
Generalization on Plain Backbone
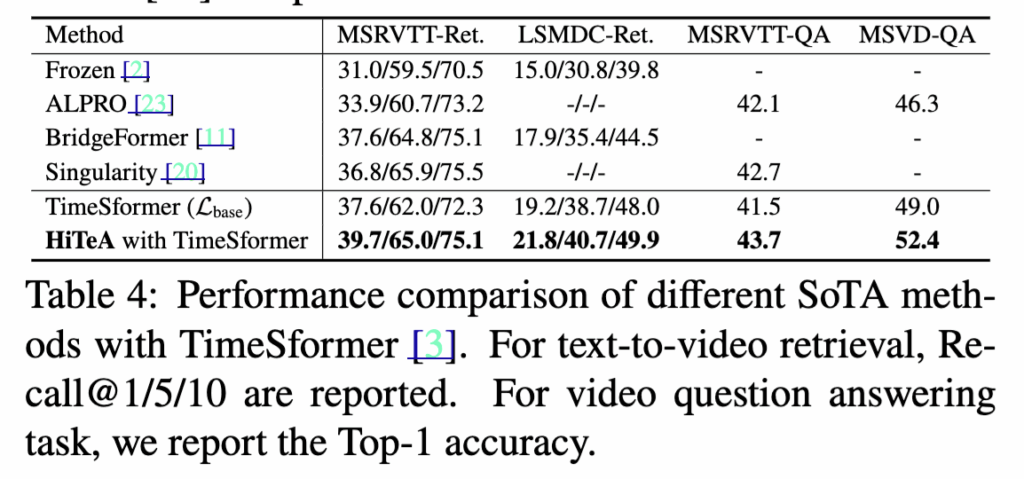
HiTeA의 일반화 성능을 검증하기 위해 복잡한 사전학습 백본 대신 TimeSformer를 사용한 실험을 진행했습니다. ImageNet-21K로 사전학습된 TimeSformer를 비디오 인코더로 적용한 결과, HiTeA는 ALPRO, Bridge-Former, Singularity 등 기존 SOTA 모델보다 동일한 데이터와 프레임 수 조건에서 더 높은 성능을 기록했습니다. 특히, HiTeA는 TimeSformer 기반 모델 대비 MSRVTT-Retrieval에서 +2.6%, MSVD-QA에서 +3.4% 향상을 보여, 제안한 시간 인식 사전학습 과제가 백본 성능을 효과적으로 강화함을 보여ㅛㅆ습니다.
Impact of Loss Terms
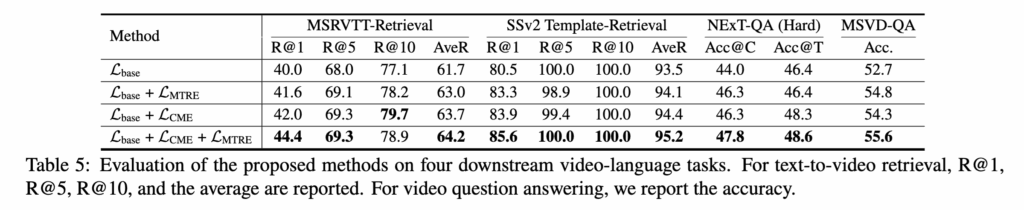
두 개의 핵심 Loss항인 L_\text{CME}과 L_\text{MTRE}의 영향을 분석한 결과, 두 Loss를 함께 사용했을 때 Text-to-Video Retrieval과 VideoQA에서 각각 +1.7% (Average Recall), +2.9% (Average Accuracy) 향상이 있었습니다. 또한 MSRVTT 데이터셋에서는 L_\text{CME} 단독 성능이 L_\text{MTRE}보다 더 우수했는데, 이는 CME가 텍스트에서 positive words뿐 아니라 행동 객체까지 선택하여 정렬 정확도를 높였기 때문이라고 합니다. 즉, CME는 비디오 속 ‘행동(action)’과 ‘대상(object)’의 세밀한 매칭에 효과적인 것으로 나타났습니다.
Evaluation on Temporal-aware Tasks
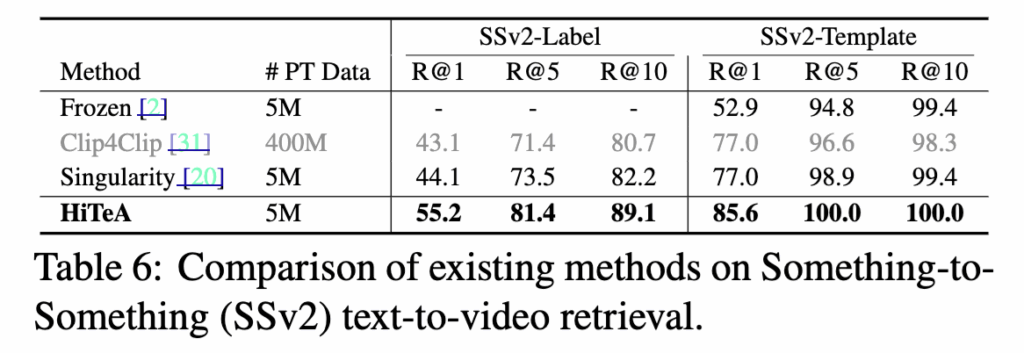
기존 리트리벌 데이터셋들이 주로 외형적 특징(appearance)에 치중된 반면, HiTeA는 시간적 맥락 이해 능력을 검증하기 위해 SSv2-Template과 SSv2-Label 데이터셋에서 평가되었습니다. 그 결과, 두 데이터셋 모두에서 R@1 기준 +8.5% 향상을 기록하며 순간(moment)과 시간적 관계(temporal relation)를 정교하게 학습함을 보여주었습니다. 또한 시간적·인과적 추론(causal reasoning)을 요구하는 NExT-QA에서도 +9% 향상을 보였으며, 인과성에 특화된 하드 스플릿 평가에서도 기존 VideoQA 전용 모델 대비 +4.1%의 성능 향상을 달성했습니다.
이러한 결과는 HiTeA가 단순히 정적인 외형 정보에 의존하지 않고, 시간적 변화와 인과 관계를 포착할 수 있는 진정한 Temporal-aware 모델임을 의미한다고 합니다.
4. Summary
HiTeA는 비디오-언어 사전학습(VLP)에서 간과된 시간적 계층 구조와 순간 정보의 중요성을 고려한 연구입니다. 기존 모델들이 비디오를 전체 단위로만 인코딩해 세밀한 순간(moments)이나 시간적 관계(temporal relations)를 놓치는 한계를 극복하기 위해, HiTeA는 Hierarchical Temporal-Aware Framework를 제안하였습니다.
< HiTeA 특징 2가지 >
Cross-Modal Moment Exploration (CME): 짧은 구간(short-view) 비디오와 텍스트 단어 간의 정밀한 정렬을 통해 미세한 시간 단위 정보를 학습함
Multi-Modal Temporal Relation Exploration (MTRE): 긴 구간(long-view)과 짧은 구간 간의 관계를 학습하여 사건(event) 간 시간적 맥락과 인과성을 모델링
이러한 구조를 통해 HiTeA는 대규모 데이터 없이도 강력한 시간 인식 표현을 학습할 수 있었으며, MSRVTT, ActivityNet, NExT-QA 등 18개 벤치마크에서 일관된 성능 향상을 보였습니다. 특히, 시간 추론이 중요한 SSv2와 NExT-QA에서도 성능 향상을 기록하며, 시간적 이해 능력의 우수성을 입증하였습니다. 결국 HiTeA는 단순히 비디오와 텍스트를 연결하는 수준을 넘어, 시간적 의미의 계층적 표현(hierarchical temporal representation) 을 학습한 모델이라고 정리할 수 있을 것 같네요!
안녕하세요, 주영님. 좋은 논문 리뷰 감사드립니다.
HiTeA가 비디오 이해를 위해 제시한 계층적 구조가 흥미로워 인상 깊게 읽었습니다.
리뷰를 보면서 두 가지 점이 궁금했습니다.
1. short-view는 임의로 나누는 랜덤 클립 기반인지, 아니면 일정한 기준(길이, 샘플링 간격 등)에 따라 나누는지
2. long-view와 short-view의 임베딩 차원 또는 feature 구조가 다를 것으로 보이는데, shared encoder를 사용하는 과정에서 차원을 정렬하거나 통합하는 방식이 있는지도 궁금합니다.
다시 한번 좋은 리뷰 감사드립니다. 📼
1. Short-video는 임의 구간을 랜덤하게 자르는 방식으로 생성됩니다.
” a video segment is randomly truncated from the input video”
저자는 모델이 다양한 시점의 순간 정보를 학습할 수 있도록, 고정된 길이/간격이 아니라 매번 다른 구간이 선택되도록 설계하였습니다.
2. long-view와 short-view의 임베딩 차원은 동일하지만, 시간적 스케일이 달라서 feature의 분포나 표현 구조가 다르게 형성됩니다. HiTeA는 이를 별도의 네트워크로 처리하지 않고, shared encoder 구조를 사용해 같은 차원에서 표현을 학습합니다. 대신 multi-modal encoder 단에서 텍스트와 결합하며 cross-modal attention을 통해 시간적 관계를 조정합니다. 또한 MTRE 손실을 통해 두 스케일의 비디오 표현이 semantic space 상에서 일관되도록 정렬(alignment) 되며, 이 과정이 long-short 간 feature 통합의 핵심적인 역할을 합니다.
안녕하세요 주영님, 좋은 리뷰 감사합니다.
HiTeA가 long-view와 short-view를 동일한 인코더로 처리한다는 점이 신기한 것 같습니다. 그런데 그렇다면 이 두 feature distribution 차이를 줄이기 위해 별도의 align방법이 사용이 된 걸까요?
네, 말씀하신 대로 long과 short 모두 동일한 비디오 인코더를 사용하나, 두 입력의 시간적 스케일이 달라 distibution 차이가 발생합니다. 이 사이 alignment 를 위해 MTRE 모듈을 제안한 것이죠. MTRE는 long-view와 short-view에서 생성된 비디오-텍스트 임베딩을 서로 매칭하여, 시간적 스케일이 다른 두 표현이 동일한 의미 공간(semantic space)에서 정렬되도록 학습합니다. 이때 SimSiam 기반의 negative cosine similarity loss를 사용해, 두 representation이 서로 다른 시간 구간이라도 동일한 의미를 공유하도록 강제합니다.