이번에 참여하게 된 2025 자율주행 인공지능 챌린지 후기를 적어보고자 합니다.
저와 정민님이 한달 동안 한것을 시간순서로 쭉 적어보고자 합니다.
자율주행 챌린지 설명
자율주행 챌린지에는 3가지 카테고리가 있었습니다.
- 라이다 기반 3D객체 검출
- Semantic Segmentation
- 미래 궤적 예측
저는 그중에 정민님과 함께 Semantic Segmentation 분야에 참여했습니다.
데이터셋 설명
챌린지의 task는 간단했습니다. 도로주행 상황의 데이터를 가지고 학습하여, 같은 도로주행의 segmentation을 진행하는 것이였습니다.
다만 세부적으로 들어가면, 여러 문제들이 보였습니다.
- 학습 데이터는 정면뿐만 아니라 측면 후면 데이터도 존재하였습니다.
- 학습 데이터와 테스트 데이터의 해상도가 다르고, 다양한 카메라로 촬영된 사진이였습니다
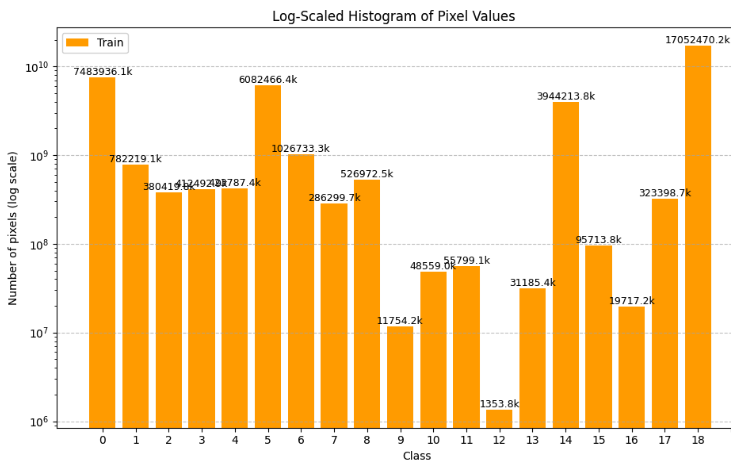
- 클래스의 분포가 상이하여 long-tail 문제가 있었습니다. 아래는 클래스별 픽셀 수를 나타낸 그래프입니다(log scale)
- 너무 많은 물체들이 기타로 분류되어 있었습니다. 아래 사진에서 18번이 기타였습니다. log scale임을 감안하면 굉장히 많은 물체들이 others로 분류되고 있었습니다.
독특한 점은 예측해야하는 test 사진 역시 주어져서, 어떤 방향으로 학습을 시켜야하는지 알 수 있었습니다.
진행 과정
validation 구성
그래서 가장 먼저 한 것은 validation을 구성한 것이였습니다.
이번 챌린지는 test의 이미지가 주어졌기 때문에, 한번 test와 train의 분포가 어떻게 다른지 확인해보고자
test 이미지의 feature map을 dinoV2를 이용해서 추출해주었고, 이를 train의 feature map과 비교하여 분포를 확인하고 clustering하여 validation을 구축하였습니다.
baseline 원복
그리고 가장 다음으로 진행한 것은 baseline 성능 원복이였습니다.
validation이 test와 얼마나 차이가 나는지 확인하기 위해서, 원복하여 성능을 확인했고 대략 10%정도 차이가 나는구나라는걸 알 수 있었습니다.
baseline를 원복하는 과정에서 계속 성능이 안나와서, 문제를 찾고 찾다가 정민님이 원본 코드에서 test할 때, normlization이 빠져있는것을 발견해주어 해결했던 것이 기억에 남습니다. 주체측에서 의도적으로 빼놓은건지는 모르겠습니다.
생성형 모델을 통한 데이터 증강
이번 대회에서 중요한 점은 모델의 GFLOPs의 제한이 빡빡했고, 추론속도 역시 평가기준에 들어갔습니다. 추론속도가 조금만 높아져서 감점이 엄청나게 되었기 때문에, 모델을 통한 성능 증진보단 데이터를 통해 성능을 올리는게 좋을 것 같다는 판단을 하였습니다. diffusion을 통한 데이터 생성을 통해서, 데이터를 다양하게 만들어서 전반전인 성능을 올려보자!를 목표로 먼저 접근하였습니다.
그래서 “Reliability in Semantic Segmentation: Can We Use Synthetic Data? (ECCV 2024)”를 이용하여, label mask를 기반으로 이미지를 생성하는 방법을 사용하였습니다.
label mask에 맞게 생성하기에 annotation을 해줄 필요 없이, 바로 학습에 사용할 수 있다는 장점이 있고, 추가적으로 text prompt를 입력으로 받기 때문에 더욱 scene을 다채롭게 해줄 수 있지 않을까라는 판단에 GAN 모델이 아닌 이것을 선택하였습니다.

생성된 결과는 위와 같습니다. 물론 조금 잘 나온 사진만 가져오긴 했습니다.
해당 모델로 prompt로 다양한 날씨의 이미지를 생성해주었습니다(foggy, rain, sunny, cloudy)
그러나 위 이미지들을 추가하여 학습해주었을 때, 성능 하락을 보였습니다. 작은 물체들을 제대로 생성 못하는건가 싶어서, 작은 물체들을 원본에서 잘라 붙여넣어서 학습을 했음에도 마찬가지였습니다.
실수
그리고 이쯤에 제가 큰 실수를 하나 했음을 알았습니다. 처음에는 validation을 제외하고 학습을 잘 시켰지만, 어느 순간 코드를 수정하다가 validation이 포함되어 학습이 진행되고 있었습니다…
그래서 이전의 실험들이 아무런 의미가 없어졌습니다. 결국 validation만 학습을해서 fitting되면 성능이 제일 좋기에 데이터를 아무리 늘려주어도 성능이 떨어질 수 밖에 없었습니다.
이때가 연휴가 끝날 때 쯤이였습니다.
validation을 올바르게 수정하였지만 그럼에도 생성된 이미지로 성능향상을 이루지 못했습니다.
이리저리 생각해본 결과, 현재 생성 모델은 label mask에 맞춰서 생성하는 것만 학습하고 있습니다. 그렇기에 생성되는 이미지의 그림체가 너무 달라서 악영향을 끼치는게 아닌가하는 생각에 LORA모듈을 붙여서 그림체까지 학습시켜보았습니다. 하지만, 이 역시 성능은 오르지 않았습니다.
그래서 이미지 생성은 여기서 접고, 성능을 어떻게든 끌어올려 보자라는 생각으로 다른 방향으로 접근하기 시작했습니다.
마지막 한주
가장 먼저한건 copy-paste였습니다.
적은 물체들의 예측 성능이 저열하여, 적은 물체들은 잘라내서 일반 사진에 그냥 무작정 붙여넣기하면 어떻까 싶었습니다.
그 다음으로 한 것은 GAN을 이용하여, clear한 이미지를 rainy한 이미지로 바꿔주었습니다.
마지막으로는 patch 단위로 augmenation을 해주었습니다.
이렇게 3개는 학습 단계에서 랜덤하게 확률적으로 각각 적용되게 하였습니다.
전부 각각 변수를 제어하여 실험할 시간은 없었기에, 최종적으로는 patch 단위로 augmenation 하는것만 남기게 되었습니다.
또한 데이터도 선별해주었습니다.
처음에는 test 데이터가 정면이였기에, train 데이터 역시 정면만 사용하었습니다.
그러나 측면과 후면 데이터의 수가 많았기에 이것을 어떻게 사용할지 고민해보았습니다.
단순히 전부 쓰면 성능이 떨어졌기에, class imbalance를 해결하기 위헤 소수 객체를 포함한 사진만 뽑아서 사용해보자고 생각했습니다.
이것 역시 실험해볼 시간이 많지 않았기에, 일부 측면과 후면을 추가해주면 성능이 오른다 정도만 확인할 수 있었습니다.
최종 제출
추가적으로 모델도 변경하였고, Knowledge Distillation까지 적용하기로 결정했습니다
그래서 최종적으로 적용된 것은
PIDNet(모델 변경), Knowledge Distillation, 데이터 선별(측면/후면 포함), patch augmentation입니다.
baseline을 제출하였을 때 48.93의 성능이였고
위 4개를 추가로 적용하여 최종 성능은 55.12로 챌린지를 마무리하였습니다.
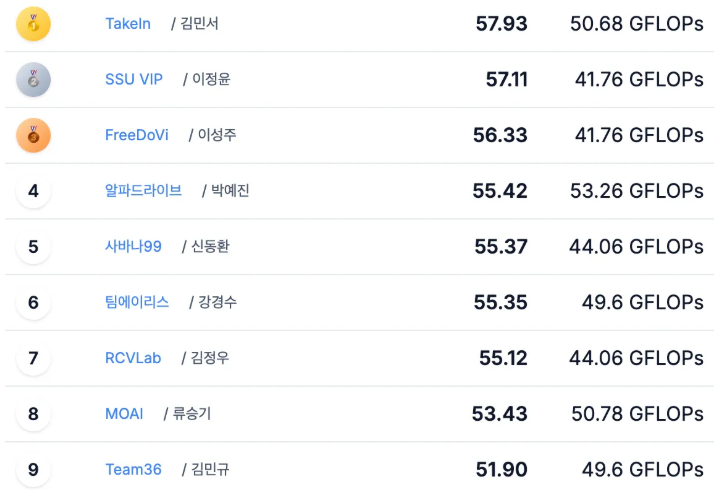
그렇게 7등으로 마무리하였습니다.
다만 아쉬운점은 4등부터 7등까지 성능차이가 크게나지 않기 떄문에, 조금만 더 올렸다면 2차 평가기준인 4등에 들 수 있지 않았을까하는 아쉬움이 남습니다.
느낀점
이번 챌린지를 하면서 뼈저리게 느낀점은 제 코드 짜는 나쁜 습관들이였습니다.
코드를 처음 짤 때는 유지보수 가능하게 예쁘게 짜야지라는 생각을 하지만 에러에 치이다보면 일단 돌아가게하는걸 목표로 바뀌게 됩니다. 그러다보면 코드는 점차 무거워지고 알아보기 힘들어졌습니다. 게다가 저는 주석도 잘 달지 않기에, 실수를 해도 눈치를 못채고 점점 보기도 싫은 코드가 되어 갔습니다.
그래서 제가 앞으로 목표로 삼은 것은
- 주석 꼭 달기
- 백업 혹은 버전관리로 과거 코드 꼭 저장해두기
- 실험을 제어하는 방법을 항상 마련해두기(코드 수정으로 실험하지 말기)
입니다.
그리고 실험하는 과정에서 생각만큼 흘러가지 않는다는 것도 많이 느꼈습니다.
GAN으로 Scene의 날씨를 다양하게 해주면 성능이 오르겠지? ⇒ 떨어짐
이미지 생성으로 데이터를 다양하게 해주고 늘려주면 성능이 오르겠지? ⇒ 떨어짐
patch augmenation을 강하고 다양하게 해주면 성능이 오르겠지? ⇒ 떨어짐 등등
그래서 실험을 최대한 여러방면으로 해보는게 중요하다고 생각했고 이를 위해서 GPU 자원을 최대한 계획적으로 쓰는 것도 중요하다고 느꼈습니다.
맺음말
만약 validation 실수를 하지 않았고, 앞 몇주를 통해 1~2퍼의 성능향상을 보였다면 최종적으로 높은 등수로 마무리할 수 있지 않았을까라는 생각을 많이 했습니다. 아쉬움이 많이 남지만, 그럼에도 이번 챌린지를 통해 많은 부분을 배우고 알아갔다고 생각합니다. 또한 정민님이 방향을 계속해서 잘 잡아주시고, 같이 챌린지를 진행하는 과정에서 많이 배울 수 있었습니다. 거의 semantic segmenation 분야의 과외를 받은것 같습니다. 너무 감사합니다.
정말 빠르게 한달이 지나간 것 같습니다. 자율주행 챌린지는 매년 열리는 걸로 알고 있습니다. 내년에도 연구원분들이 참여해서 좋은 경험을 해보고 좋은 결과까지 이어졌으면 좋겠습니다.
안녕하세요 정우님!
챌린지에 참여한지 시간이 좀 지났는데 질문을 남겨보겠습니다!
그 때 옆에서 지켜보면서 정우님이 참 고생하는 것 같아서 어떻게 진행하는지 궁금했는데 읽어보니까 여러 일이 있었네요!
몇가지 궁금한 점이 있습니다!
validation을 제외하고 학습을 제대로 진행시켰지만 그럼에도 불구하고 성능에 변화가 없는 이유는 무엇일까요?
그리고 그림체까지 학습을 시켰는데 성능이 그대로 인것도 이유가 무엇일까요?
정우님의 생각이 궁금합니다!!
감사합니다!
인하님 댓글 감사합니다.
1등을 한 팀의 발표를 들었을 때, 해당 팀도 diffusion을 생성을 통해 성능을 증진하였습니다.
그러나 제 접근과 달랐던 점은,
첫번째로, 저는 stable diffusion을 기반으로 하는 controlnet을 사용하였고
1등팀은 FLUX.1라는 모델을 사용하였습니다
FLUX.1은 파라미터가 stable diffusion보다 12배 많고, 성능이 좋은 모델이였습니다.
두번째로, 저는 이미지 생성을 통해 다양한 날씨 변화를 학습시켜 준 반면, 1등팀은 inpainting을 통해 소수객체를 증강시켜주었습니다. 저도 시도해봤지만, 모델의 성능이 좋지 않아 포기했었는데, FLUX를 썼기에 가능했던 것 같습니다.
그렇기에 위 2가지로 보아.
이미지 생성으로 현실과 유사한 이미지는 생성했지만 결국 domain gap이 있었고,
결국 봤던 장면을 다른 환경으로만 학습하였기에 성능이 나오지 않았던걸로 생각하고 있습니다.