오늘 소개드릴 논문은 NeurIPS 2025 에 소개된 Vide RAG 관련 논문입니다.
해당 논문은 시각적으로 정렬(Visually-aligned)된 정보를 통해 Long video에 대한 이해력을 높이는 RAG 기술을 제안한 논문입니다. 제안한 방법은 plug-and-play 방식으로 다양한 open-source LVLMs에 적용할 수 있으며, 방법을 적용하였을때, 추가적인 학습 없이 비디오에 대한 이해 능력이 개선됨을 보였습니다.
성능이 얼마나, 어떻게 개선되었는가?
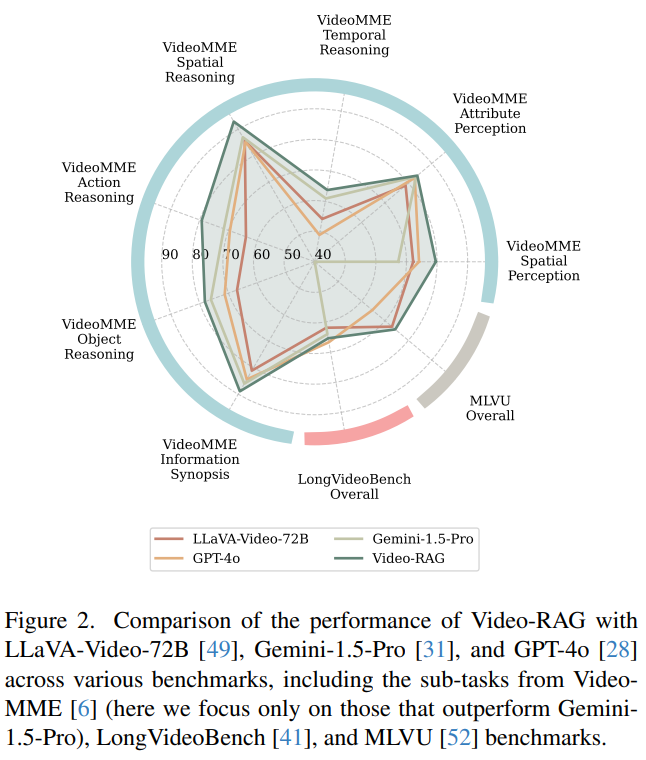
위의 Figure2는 제안한 방법의 성능 개선폭을 보여줍니다. 비디오 이해의 대표적인 데이터셋인 Video-MME, LongVideoBench, MLVU에 대해 실험하였으며 LLaVA-Video-72B, Gemini-1.5-Pro, GPT-4o, Video-RAG의 성능을 비교하였을때, 제안한 Video-RAG가 모든 벤치마크에서 최신의 Large video language models(LVLMs)을 뛰어 넘음을 시각적으로 확인할 수 있습니다. (이때, Video-RAG는 LLaVA-Video-72B를 베이스 모델로 합니다.)
그렇다면 개선을 위해 어떤 정보를 이용한 것일까?
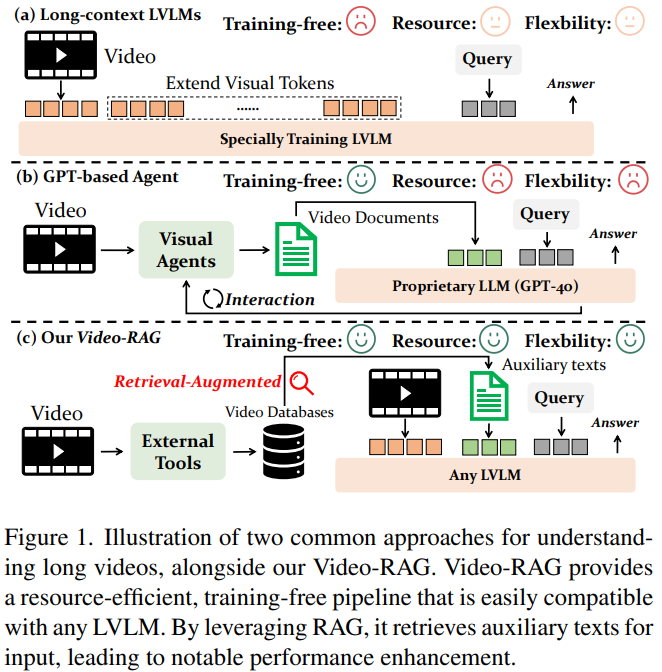
앞서서 제안한 방법은 비디오 외의 추가적 정보를 aligned 되도록 하여, 비디오에 대한 이해능력을 개선했다고 말씀드렸습니다. Visually aligned이 중요한 이유는 다음과 같습니다. 기존 RAG는 비디오 입력을 이용할때 비디오 프레임을 모두 증강에 활용하면 연산량이 크게 증가하므로, Figure1의 (b)와 같이 비디오를 텍스트로 1차 변환하고, 해당 텍스트를 기반으로 RAG를 수행했습니다. 그러나 이러한 방법은 정보변환의 과정에서 변환에 사용된 VLM 모델 등이 집중하지 못한 시각정보에 대한 손실이 있음을 감안해야 합니다. 시각정보에 대한 손실을 최소화하기 위하여 논문은 Figure1의 (c)와 같이 비디오를 직접 입력에 사용할 뿐 만 아니라, 비디오 내 자막정보나 오디오에서 auxiliary texts를 생성하여 활용하므로서 비교적 소량의 프레임만 입력에 활용하여도 정확도가 떨어지지 않도록 하여 시각 정보를 직접 증강에 이용할 수 있는 Video RAG 구조를 제안했습니다.
Video-RAG의 전체 워크플로우
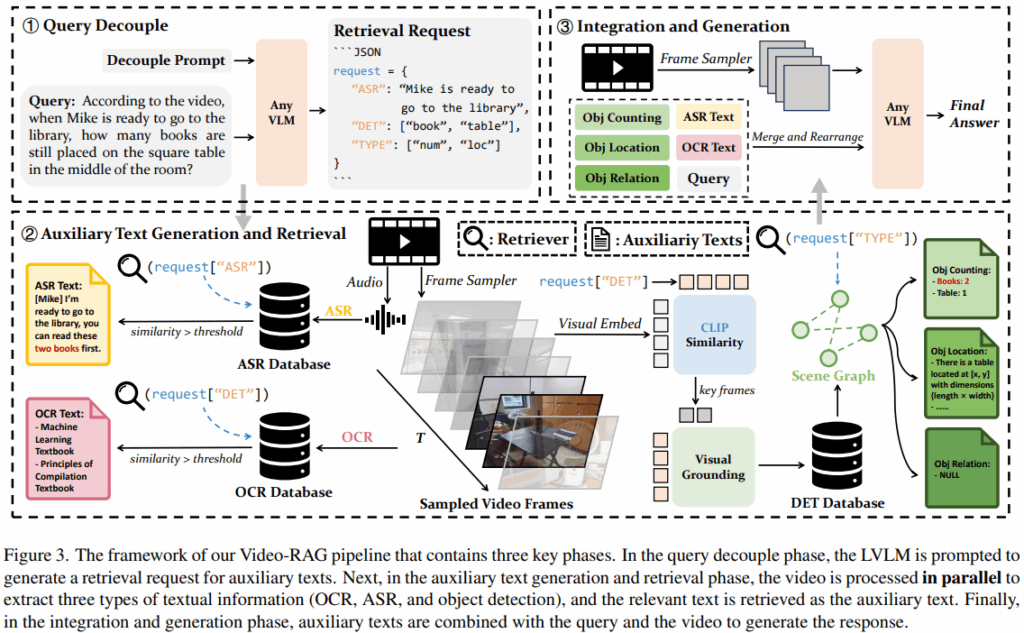
Video-RAG의 전체 워크플로우는 Figure3에서 확인할 수 있듯이 3단계로 구성됩니다. 먼저 사용자의 질의(Query)를 VLM을 통해 Json 형태로 변환합니다. 특히 다음 단계에서 비디오에서 auxiliary texts를 생성하기 위한 지시를 명확히 하기 위해 음성(ASR)에서는 어떠한 정보가 필요한지, 물체(DET)와 같은 정보는 어떻게 포함되는지, 어떤 정보에 집중해야하는지(TYPE)으로 구분하게 됩니다. 아래는 해당 변환의 예시입니다. 이때 변환을 위한 입력으로는 사용자의 질의와 미리 설계된 프롬프트만을 활용하며 비디오 정보는 활용되지 않습니다.

다음은 위의 JSON 질의를 통해 비디오에서 auxiliary texts를 생성하는 과정입니다. auxiliary texts로는 영상 내의 텍스트를 통해 구축하는 OCR database와 오디오 정보에서 쿼리와 유사한 정보를 통해 구축하는 ASR databse가 있습니다.
- OCR database
OCR은 영상의 중요 정보중 하나입니다. 본 논문에서는 EasyOCR라는 방법론을 통해 프레임에서 샘플링(일정간격으로 N개의 프레임 추)된 비디오 프레임에 포함된 텍스트를 추출합니다(T_ocr) 이후 T_ocr을 텍스트 임베딩 모델인 Contriever로 임베딩(E_ocr) 한 후, FAISS 인덱스(검색을 위한 구조화)를 통해 DB를 구축합니다.
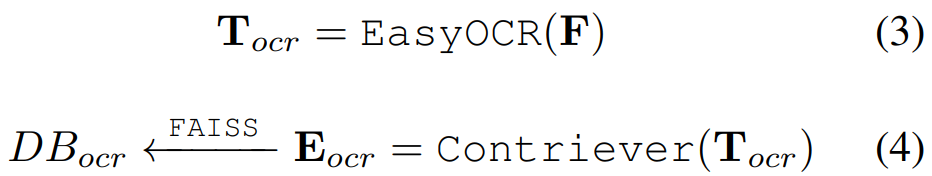
- ASR database
앞서서는 시각 정보를 위주로 다루었습니다. 하지만 멀티모달 데이터인 비디오는 음성 역시 중요한 정보입니다. 본 논문에서는 비디오에서 raw audio(U)를 추출하여 오디오-텍스트 변환 모델인 Whisper를 통해 텍스트로 변환(T_asr)합니다. 이후 T_asr 역시 텍스트 임베딩 모델 Contriever로 임베딩(E_asr)하며 FAISS 인덱스 기반의 DB로 구축됩니다.

- DET database
다음으로 시각 정보에서 주된 정보로 다루어지는 객체 정보를 통해 DB를 구축합니다. 해당 데이터베이스 구축을 위해서는 먼저 샘플링된 프레임에서 CLIP기반으로 위의 json query에서 요청한 객체 (즉 사용자 질의에 답변하기 위해 필수적인 객체)를 포함한 키프레임(F_key)을 선별합니다. 이후 APE라는 open-vocabulary detector를 통해 키프레임에서 요청된 물체를 탐지하고, 객체의 위치/수량을 텍스트(T_det)로 변환합니다.

위의 방식으로 데이터베이스의 구축은 완료했습니다. 이제 본격적으로 쿼리를 활용해 데이터베이스에서 답변을 생성하기 위해 사용할 정보를 검색해야합니다. 검색의 방법은 아래와 같습니다. 먼저 contriever을 통해 임베딩하여 구축된 OCR/ASR database에 대해 쿼리와 유사한 임베딩을 검색합니다. DB가 쿼리와 역치범위 이상 유사할때 검색의 결과로 활용됩니다. (이때 t는 실험적 값으로 0.3)

한편 DET database는 이미 쿼리를 기반으로 생성되었습니다. 따라서 해당 데이터베이스는 쿼리와의 검색없이 해당 정보를 통해 특정 탬플릿을 활용한 SceneGraph를 구축하여 검색 결과로 활용합니다.
활용된 탬플릿:
“Object {node ID} is a {object category} located at coordinates [x, y] with dimensions {length × width}”
“Object counting: – {object category}: {number}”
“Object {node ID} ({object category}) is Object {node ID} ({object category})”
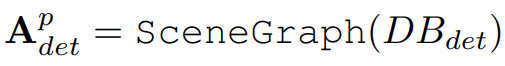
이후 위를 통해 검색된 결과를 증강에 활용하여 초기 샘플링된 비디오 프레임과 함께 LVLM의 입력으로 사용됩니다.
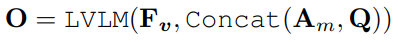
정확한 정량적 우수성은 어떻게 되는가?
- 메인 실험
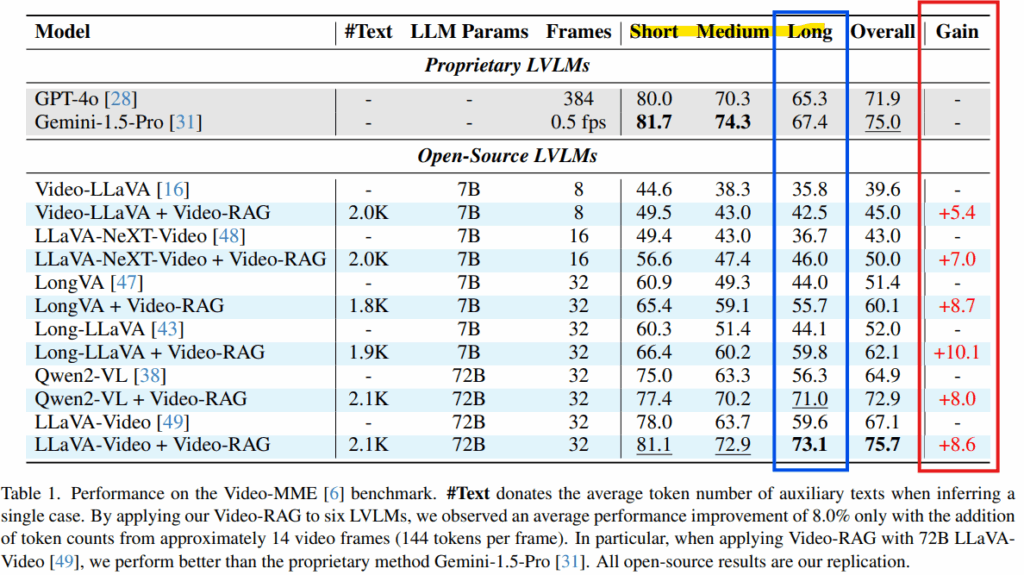
Table1은 제안된 Video-RAG의 주된 결과입니다. LVLM 평가에 가장 많이 사용되는 데이터셋인 Video-MME에 대한 성능입니다. 모든 모델과 모든 세팅에서 Video-RAG를 통한 증강을 하였을때 유의미한 성능 개선이 있었음을 확인할 수 있습니다. 아래의 발췌에서 확인할 수 있듯이 Video-MME와 같이 Long 비디오를 포함하는 벤치마크의 경우 단순히 정보량을 증가하는것이 유의미하지 않을 수 있는데요, 제안된 방법을 적용했을 때 Long 에서도 모든 LVLM 모델에서 성능 개선이 있음을 통해 성공적인 Long-context를 위한 RAG 기법이였음을 알 수 있습니다.

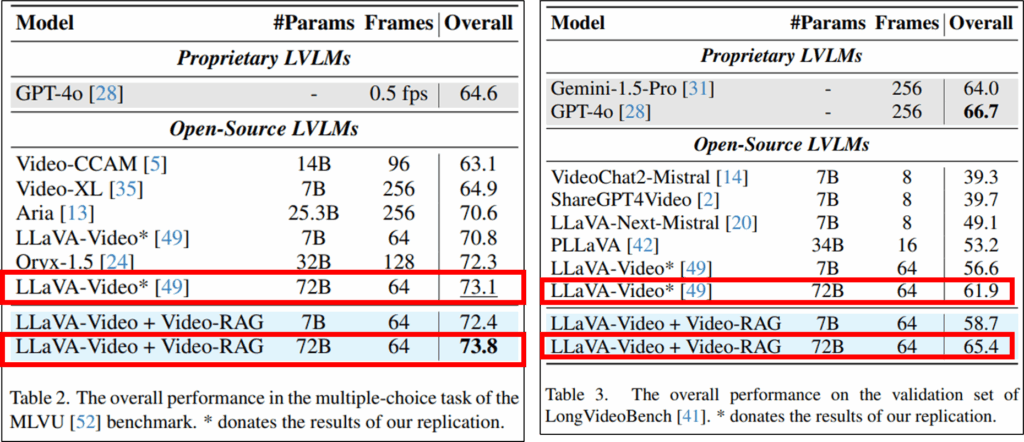
또한 이러한 개선 결과는 실험에 사용된 다른 Long video 벤치마크인 MLVU와 LongVideoBench에서도 확인할 수 있습니다.
- Abulation study
다음은 Abulation study로 각 DB가 전체 비디오 이해 성능에 어느 개선을 보였는지를 확인할 수 있습니다. RAG 를 활용하지 않고 auxilary text를 모두 LVLM에 입력하였을 때 대비 성능 개선이, overall 기준 약 3%임을 확인할 수 있습니다. 실험을 통해 설계에 활용된 각 단위들을 모두 적용할때 가장 높은 성능을 보임을 확인할 수 있습니다.
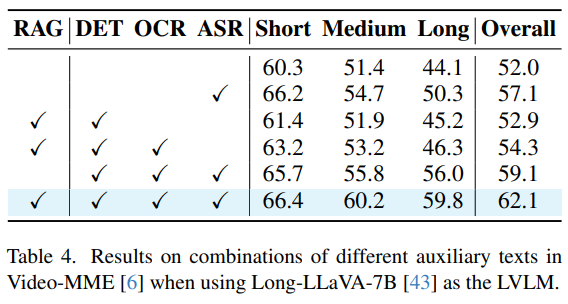
- 추가적인 분석 결과
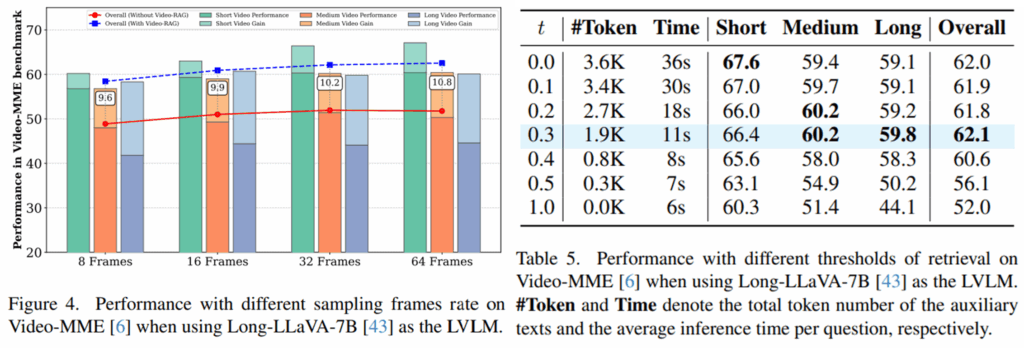
추가적인 실험으로는 프레임 수와 RAG 검색시에 활용된 역치(t) 결정에 활용된 실험적 결과입니다. Figure4에서는 비디오에서 초기 샘플링 시에 8/16/32/64 몇개의 프레임을 활용하더라도 모든 실험결과에 대해 제안된 video RAG가 성능 개선을 보였으나, 32 프레임보다 많을 경우 오히려 노이즈로 작용하여 성능이 하락함을 확인할 수 있습니다. 검색에 역치 스코어로 활용된 t의 경우 0.3일때 모든 정보를 활용한것(t=0.0)보다 높은 성능으로 가장 효율적임을 실험적으로 확인한 결과는 Table5와 같습니다.
- 정성적 결과

마지막으로 정성적 결과는 위와 같습니다. 제안 방법으로 RAG를 활용했을 때 모델이 확실히 추론에 대한 대답을 위해 쿼리와 연관된 영역을 하이라이트 하고 있음을 확인할 수 있으며 t-SNE로 keyframe의 시각적 특징(붉은색)과 텍스트 쿼리(파란색)를 시각화 할 때 Video RAG 활용 방법이 더욱 잘 정렬되었음을 확인할 수 있습니다. (두 분포의 중심 거리가 더 가까움)
이상으로 리뷰를 마치겠습니다. 감사합니다.
안녕하세요 리뷰 잘 읽었습니다.
1. 해당 논문의 방법이 ‘시각적으로 정렬된 보조 텍스트(OCR/ASR/DET)’에 많이 의존하는 구조로 이해했는데요, 만약 정렬 품질이 조금 떨어지는 상황(자막 타임스탬프 편차, OCR 박스 흔들림 등)에서도 성능이 안정적이었는지 궁금합니다. 논문에 그런 케이스가 언급이 되었을까요?
2. Ablation에서 ‘보조 텍스트만 투입’ 대비 RAG가 약 3%p 더 올랐다고 하셨던 것 같습니다. 혹시 질문 카테고리별 성능 평가 ablation(OCR형·ASR형·DET형)은 없었나요? 각 요소에 대한 영향력이 궁금해져서요
안녕하세요 홍주영 연구원님, 질문 감사합니다.
부록을 찾아보았는데 아쉽게도 질문주신 두 실험 결과는 확인하지 못했습니다.
답변드릴 수 있는점은 1번 질문에서 자막 타임스탬프 편차의 경우는, 자막을 통해 OCR DB를 구축 한 다음 쿼리와 유사한 정보에 대해 검색을 진행하기 때문에 문제가 없을것으로 판단됩니다. 둘째로 OCR 박스의 흔들림의 경우는 사용하는 OCR 모델 성능에 의존할 것으로 생각됩니다.
안녕하세요, 황유진 연구원님. 좋은 리뷰 감사합니다.
읽다 보니 2가지 궁금증이 있어 질문 남깁니다.
비디오의 특성에 따라 다르긴 하겠지만 비디오 데이터에서 OCR 정보가 중요하다는 점이 저에게는 낮선데, 혹시 해당 벤치마크 데이터셋에는 글자가 많이 포함되어 있나요? 만약 글자가 포함되지 않은 비디오라면 OCR database에서 무엇을 반환하는지 궁금합니다.
또한, Figure 3의 2 Auxiliary Text Generation and Retrieval 부분에서 DET database에서 scene graph를 만들어서 넣어주는데 여기서 scene grpah가 구체적으로 어떻게 생성되는지, 어떻게 입력되는지 알고 싶습니다.
감사합니다.
안녕하세요 허재연 연구원님, 질문 감사합니다.
해당 데이터셋에는 뉴스데이터, 시사 영상 등을 포함하며, 뉴스의 자막과 같은 요소로 OCR database를 구축합니다. 정확히 몇 퍼센트인지는 측정해보지 않았지만, 영상마다 글자가 꽤 포함되는 편인것 같습니다. 만약 글자가 포함되지 않는다면 OCR database에서는 반환을 하지 않습니다.
Scene graph의 경우 open-vocabulary detector인 APE의 추론 결과를 통해 본문의 “활용된 탬플릿”으로 작성된 문장으로 가공하여 입력으로 활용하는 것을 의미합니다