안녕하세요 이번주는 시뮬레이션 데이터와 real 데이터로 동시에 학습하는 Co-training에 대해 분석을 진행해본 논문을 리뷰해보려고 합니다. 시뮬레이션 데이터가 실제로 policy에 어떤 영향을 미치는지 다양한 형태의 시뮬레이션 데이터가 어떤식으로 real 데이터와 상호보완적으로 활용할 수 있는지를 분석한 논문입니다.
Introduction
자연어 처리와 컴퓨터 비전 분야에서 대규모 데이터로 학습된 거대 모델들이 혁신을 이루었지만, 로보틱스 쪽에서는 쉽지 않는데요, 늘 말하듯 실제 로봇 시연 데이터를 모으는 일은 비용과 시간이 많이 들기 때문입니다. 다행히 시뮬레이션이나 비디오 같은 대안 데이터원이 유용한 정보를 제공할 수 있으며, 특히 시뮬레이터를 이용하면 로봇 데이터를 자동으로 수집할 수 있다는 엄청난 강점이 생깁니다. 시뮬레이션과 현실데이터는 각자 장단점이 있지만, 어느 하나만으로는 충분하지 않으므로 두 데이터를 상호보완적으로 활용하는 전략이 로봇 모방학습 성능을 크게 끌어올릴 잠재력을 갖는다고 봤다고 합니다. 저자는 이러한 co-training 방법을 심층적으로 조사하여, 시뮬레이션과 현실 데이터를 함께 활용할 때의 성능 향상 요인과 원리를 분석했습니다. 기존의 co-training의 recipe를 처음 제시한 nvidia의 논문보다 조금 더 다양하고 심층적인 분석이 들어가있었습니다. 저자들도 해당 연구를 통해 시뮬레이터 설계와 데이터 구축에 대한 지침을 제시하는 것이 연구의 목표였다고 합니다.
저자들은 Diffusion Policy 알고리즘을 사용하여, 픽셀 관측에 기반한 평면 푸싱 과제에서 시뮬레이션-현실 공동학습을 수행하였습니다. 총 50개 이상의 real기반 policy (1000회 이상의 실험)과 250개의 시뮬레이션 기반 policy(5만 회 이상의 시뮬레이션 실험)을 통해 매우 방대한… 실험 및 분석을 진행하였습니다. 결과를 요약하자면 다음과 같다고 합니다.
- 시뮬레이션 데이터를 함께 사용해 Co-training을 진행한 policy는 현실 데이터만으로 학습한 경우 대비 2~7배 높은 성공률을 보였으며, 현실 시연 데이터가 매우 적은 경우에도 큰 성능 향상을 달성했다고 합니다. 다만 시뮬레이션 데이터의 양을 계속 늘려도 이러한 성능 이득은 점차 줄어들어 추가 현실 데이터 없이는 일정 수준에서 정체 현상이 나타났다고 합니다. 기존 NVIDIA에서 처음으로 제시된 연구와 같은 현상 (co-training policy의 성능 고점은 real data의 수가 정해준다) 입니다.
- 현실과 시뮬레이터 사이의 sim2real 격차가 시뮬레이션 데이터의 유용성에 영향을 주었습니다. 특히 물리 모델의 정확도 차이는 성능에 가장 큰 영향을 미쳤으며, 시뮬레이터의 물리 정확도를 높이면 co-training 성능을 크게 향상시킬 수 있었습니다. 반면 단순한 시각적 격차(색감, 정확한 렌더링)의 영향은 비교적 적었다고 합니다. 이 점은 시뮬레이션 asset의 기하학적, 역학적 완성도가 큰 영향을 미친다고 볼 수 있을 것 같습니다
- 성능이 우수한 co-training policy들은 훈련 과정에서 시뮬레이션과 현실 환경을 구별하는 법을 학습한다는 흥미로운 현상이 관찰되었다고 합니다. 시뮬레이션의 시각적 품질을 현실과 완전히 같게 만들어 두 환경을 시각적으로 구별 불가능하게 하자 오히려 성능이 떨어졌는데, 이는 정책이 두 환경을 식별하지 못해 잘못된 동작을 하게 되기 때문입니다. 반대로, 환경 도메인을 나타내는 정보를 정책에 명시적으로 제공하였을 때는 성능이 향상되었다고 합니다.
- Co-training을 통해 시뮬레이션 데이터가 현실 데이터의 빈틈을 메우며 현실에서의 성능을 높이는 효과를 보였습니다. 시뮬레이션 데이터의 양이 현실에서의 policy 작동시에 미치는 영향이 어느정도 예측 가능한 양상을 보였고, 현실 데이터의 증가가 갖는 효과의 지수가 더 크게 나타나, 현실 데이터의 중요성도 정량적으로 확인되었습니다.
- 두 가지 대안적인 co-training 기법인 Classifier-Free Guidance 적용과 추가적인 loss를 도입해 평가했을 때 기존 공동학습 방법과 비교했을 때 뚜렷한 성능 향상을 보이지는 못했다고 합니다. 따라서 기존의 co-training 접근법이 이미 최적에 가깝고, 앞서 언급한 환경 구분 능력 등의 요소가 성능에 중요한 영향을 미친다는 것을 확인했다고 합니다.
Preliminaries
Co-training problem formulation
이 연구에서는 모방학습 정책을 시뮬레이션 데이터와 현실 데이터를 같이 구성해 Diffusion Policy 학습시키는 Co-training 문제를 다룹니다. Co-training의 목표는 이 두 데이터셋을 모두 사용하여 현실 환경에서의 성능을 최대화하는 정책 을 학습하는 것이었다고 합니다. 여기서 현실 성능은 Push T 작업의 성공률로 측정됐습니다. 기본적인 co-training 방법에 따라 두 데이터의 비율을 조절하기 위해 파라미터 α를 도입해 현실 데이터에서 샘플을 얻을 확률을 α (시뮬레이션은 1–α)로 하여 혼합 데이터셋을 구성하고 정책을 학습했습니다.
Diffusion Policy
Diffusion Policy는 diffusion model을 로봇 정책 학습에 응용한 것으로, 과거 관측들의 시퀀스를 받아 미래의 행동 시퀀스를 확률적으로 생성하는 구조입니다. 행동 시퀀스의 조건부 분포 를 학습하기 위해 denoiser를 학습하며, 학습 시에는 손실 함수를 통해 임의의 가우시안 잡음이 섞인 action으로부터 원래의 action을 복원하도록 훈련합니다. 학습된 policy로부터 행동을 샘플링할 때는, 노이즈가 섞인 초기 행동을 점진적으로 정제하는 과정을 거칩니다. 이러한 방식으로 diffusion policy는 조건부 생성 모델로서 observation에 따라 로봇 action 시퀀스를 생성합니다. 저자들은 ResNet-18을 비전 백본으로 사용했다고 합니다. 그냥 카메라로 지금 보이는 장면에 따라서 액션을 생성한다고 이해하시면 될 것 같습니다.
Planar-Pushing From Pixels
평면 푸싱(planar pushing)은 로봇 팔 끝의 pusher로 평면 위에 있는 T자형의 물체를 밀어서 목표 위치까지 옮기는 조작 과제입니다. 원형 푸셔를 이용해 검은 T자 물체를 노란색 T자 모양 표적까지 밀어 움직입니다. Planar-Pushing From Pixels이라는 것은 로봇이 환경의 완전한 물리 상태를 알지 못하고 카메라 이미지 관측만으로 조작을 수행한다는 뜻입니다. Push T 태스크가 고차원 visuomotor policy의 핵심을 포함하고 있으면서도, 시뮬레이션을 통한 데이터 생성이 비교적 용이하여 실험용 표준 과제로 널리 쓰이고 있다고 합니다. 해당 연구에서도 planar pushing을 테스트베드로 삼아 다양한 시나리오를 실험했습니다.
Data Collection
현실 로봇 데이터는 teleoperation을 통해 수집하였고, 시뮬레이션 시연 데이터는 Towards Tight Convex Relaxations for Contact-Rich Manipulation기반 플래너를 사용해 생성하였다고 합니다. 저도 자세히 접해보진 않았던 연구인데 contact rich manipulation을 위한 최적화 기반의 플래너라고 합니다. 생성된 시뮬레이션 궤적들은 물리 시뮬레이터인 Drake(첨보는 시뮬레이텁니다) 상에서 rollout하면서 이미지 데이터도 그 안에서 취득했다고 하빈다. 이 때 플래너 기반의 시뮬레이션 데이터는 인간보다 더 부드럽게 움직이기 때문에 액션 갭이 발생하고, 이 또한 중요한 관전 포인트였다고 합니다. 데이터 수집은 현실과 시뮬레이터에서 모두 동일한 로봇(KUKA LBR iiwa 7)을 사용하였고, 행동 공간은 푸셔의 평면 상 목표위치 (x, y)로 정의되며 observation은 EE상태 값과 두 대의 RGB 카메라 이미지 (천장 카메라 + 손목 카메라)로 구성되었다고 합니다.
Real World Experiments

저자들은 우선 소량의 현실 시연 데이터와 시뮬레이션 데이터를 혼합하여 Co-training하는 경우 성능을 평가하고, 여기에 미치는 다양한 요인을 분석했습니다. 현실 데이터만 학습한 경우(α=1)와 시뮬레이션만 학습한 경우(α=0)를 포함하여 폭넓은 α 값을 실험했습니다. α를 0.25, 0.5, 0.75 등 여러 값을 시도하였고, 현실 시연의 갯수도 10, 50, 150개 , 시뮬레이션 개수 500, 2000개를 조합하여 성능을 측정했습니다. 실제 로봇으로 20회씩 평가하여 성공률로 기록했으며, 각 실험 조건에 대해 최적 성능과 그 분산을 분석했다고 합니다. 다음 세개의 질문을 던지고, 각각의 답을 얻었다고 합니다.
- Does cotraining with sim data improve real-world policy performance?
- How do the size and the mixing ratio between both datasets affect real-world performance?
- How does cotraining compare with finetuning?
Does cotraining with sim data improve real-world policy performance?
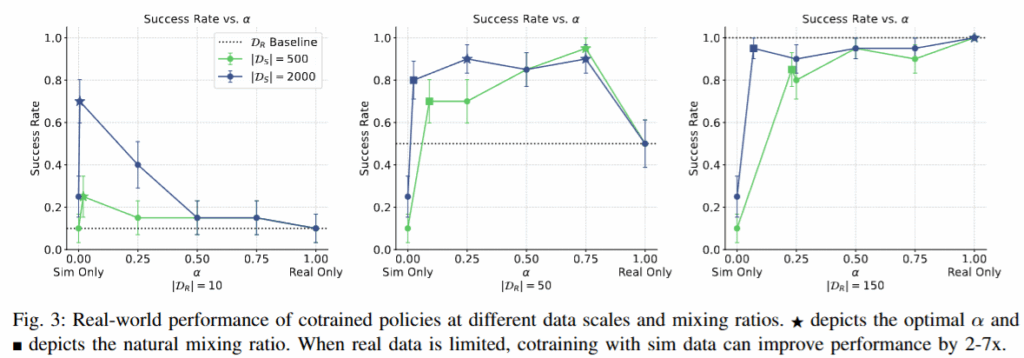
위 figure에서 알 수 있듯, 현실 데이터가 적은 환경에서는 시뮬레이션 데이터를 섞어 학습한 정책이 현실 데이터만으로 학습한 정책보다 압도적으로 높은 성공률을 보였습니다. 현실 시연 10개로 학습한 경우 성공률이 2/20 (10%)에 불과했으나, 동일한 데이터에 시뮬레이션 시연 500개를 함께 학습하자 14/20 (70%)까지 향상되었습니다. 현실 시연 50개인 경우도 두배정도 향상되어 2~7배의 성능 개선을 달성했다고 언급했습니다. 현실 시연 150개가 주어지는 고데이터 환경에서는 현실 데이터만으로도 20/20의 성공률을 달성하므로 추가 향상의 여지가 작았습니다. 결국 현실 데이터가 충분히 많은 경우 co-training의 이득은 제한적이지만, 현실 데이터가 부족할수록 공동학습의 효과가 극대화됨을 확인했다고 합니다. 이 부분은 처음 dex hand와 2지 그리퍼로 co-training에 대한 연구를 발표한 nvidia의 논문과 거의 일치하는 모습을 보여주어서 push t를 포함해 굉장히 많은 task에서 같은 양상을 보인다는 것을 알 수 있었습니다.
How do the size and the mixing ratio between both datasets affect real-world performance?
Co-training 성능에는 real world의 배치 구성 비율α, 현실 시연 개수 D_R, 시뮬레이션 시연 개수 D_S가 모두 영향을 미쳤다고 합니다. 성능이 α에 상당히 민감하여, 잘못 설정할 경우 크게 저하되는 것을 확인할 수 있었습니다. 현실 데이터가 매우 적은 경우(D_R=10) 최적 성능은 α = 0.25에서 얻어졌고, 현실 데이터가 늘어날수록 최적 α도 점차 현실 데이터 비중이 증가하는 쪽으로 움직였습니다. 이는 현실 데이터 양이 충분할 때는 현실 위주로 학습하는 편이 유리하지만, 현실 데이터가 적을 때는 약간의 현실 데이터 혼합만으로도 성능이 크게 향상됨을 의미합니다. 실제로 α를 0으로 낮추어 순수 시뮬레이션 학습으로 가면 성능이 급락하는데, 소량이라도 현실 데이터가 섞이면 성능이 크게 개선되는 현상이 관찰되었습니다. 사실 이 부분도 앞서 제시됐던 연구와 거의 동일한 결과가 나왔습니다.
How does cotraining compare with finetuning?
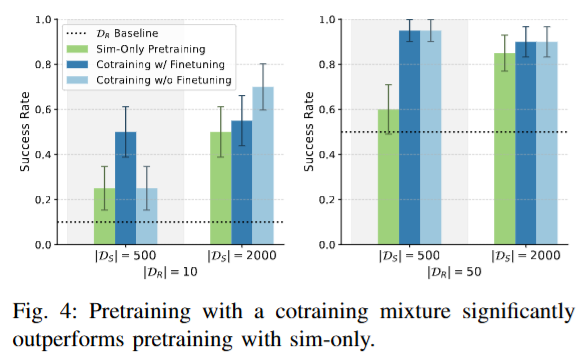
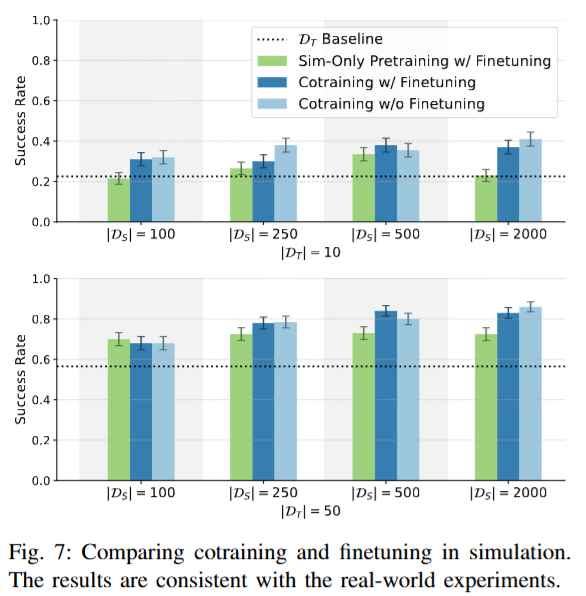
Co-training이 finetuning의 접근보다 나은지 평가하기 위해, 두 가지 전략을 시험했다고 합니다. 시뮬레이션 데이터로만 학습한 뒤 현실 데이터로 파인튜닝한 경우와 시뮬레이션 + 현실데이터로 co-training 한 뒤 현실데이터로 파인튜닝을 진행한 경우 두가지로 나누어서 실험을 진행했습니다. 실험 결과, 데이터를 처음부터 혼합하여 학습한 경우가 두 단계를 나눠 학습한 경우보다 일관되게 높은 성능을 보였다고 합니다. 또 단일 task인 설정에서는 co-training 후 추가 파인튜닝을 해도 성능이 크게 향상되지 않았는데, 저자들은 co-training 정책이 이미 현실 환경에 대한 일반화가 되어 있으므로 추가 파인튜닝이 오히려 개별 사례에 대한 오버피팅을 일으킬 수 있다고 해석했습니다. 저자들은 멀티태스크의 경우에는 파인튜닝 효과가 달라질 수 있을 것 같다고 언급했습니다. 추가로 실험은 안 한것 같습니다.
Simulation Experiments
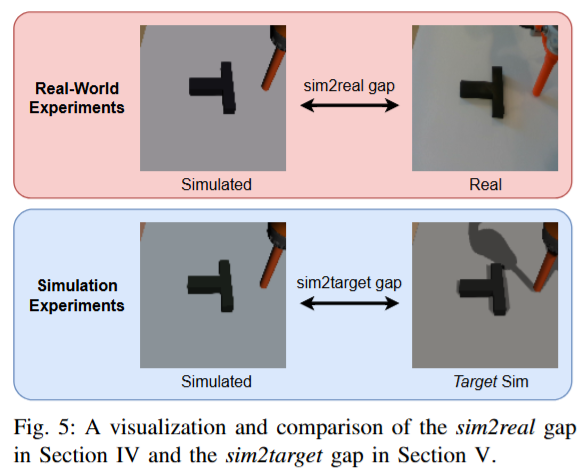
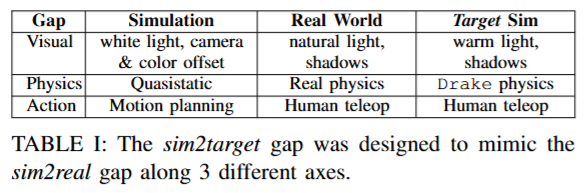
시뮬레이션을 통해서는 효율적인 실험이 가능하기 때문에 저자들은 sim2sim으로도 평가를 진행했다고 합니다. 기본적으로 sim2real gap을 줄일 수 있는지?에 대한 접근이기 때문에 real환경에 해당하는 simulator를 target sim으로 정의하고 기본 sim이 단순화된 물리엔진을 사용한 반면, target sim에는 보다 현실적인 Drake 물리엔진을 탑재한 시뮬레이션을 사용하였다고 합니다. (그림자나 색감, 렌더링 품질을 보시면 될 것 같습니다)시연 데이터 또한 기본 sim의 시연들이 모션 플래너에 의해 생성된 최적 궤적이라면, target sim에서의 시연은 teleoperation을 통해 수집되어 현실 데이터와 유사한 특성을 갖도록 했습니다. 정확한 요소들을 아래 표와같이 구분해두었습니다. Target sim 환경에서 평가를 진행했고, 충분한 평가 통계를 얻기 위해 정책당 무작위 초기조건을 구성해 200회의 에피소드를 실행해 성공률을 계산했다고 합니다. 현실 실험에서는 정책당 20회 평가를 실시했으니 10배 더 많은 에피소드를 통해 분석을 진행했습니다. 다만 이게 애초에 현실과는 다를텐데 어쨌든 domain gap을 해소하는것에 대한 실험 결과로는 인정을 받는 것 같습니다. 이 부분에 대해서 저자들은 explicit control over the sim2real gap between the two cotraining environments이라고 어필했습니다.
Sim2target gap vs Sim2real gap
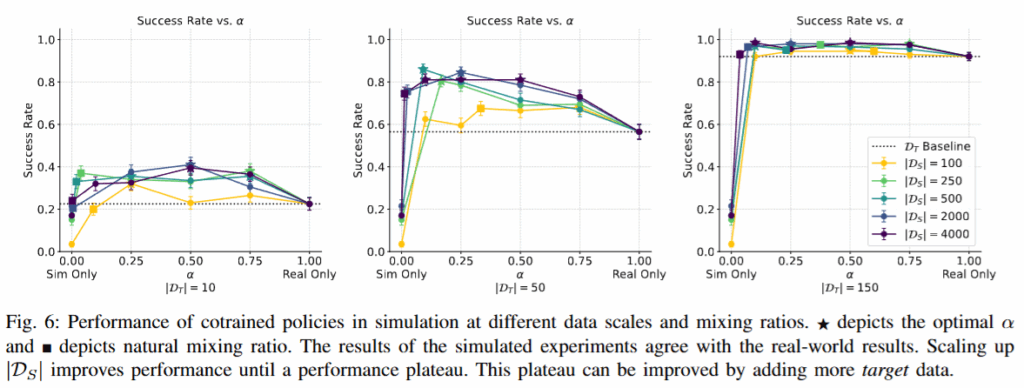
시뮬레이션 환경들 사이의 co-training 결과, 전반적인 경향은 sim2real일때와 대체로 일치했으나 몇 가지 흥미로운 차이가 나타났다고 합니다. 맨 오른쪽 그래프를 보면 D_T=150인 경우에도 co-training 성능을 추가로 향상시켰습니다. 이는 현실 실험에서는 150개의 시연으로 이미 성공률 100%를 달성해 공동학습 이득이 없었던 것과 대조적이라고 합니다. 근데 현실의 물리법칙이 훨씬 정교하니까 당연한 결과가 아닌가 싶습니다. 다만 적은 target sim데이터/중간 영역에서의 향상 폭은 현실 실험만큼 크지는 않았습니다. 현실 데이터의 중요성이 돋보이는 결과인 것 같습니다. 또 최적의 α 값이 현실 실험보다 전반적으로 낮게 관측되었다고 합니다. 저자들은 sim2target gap이 sim2real gap보다 작았기 때문에, 시뮬레이션 데이터에 더 의존해도 성능이 잘 나오고 최적의 α가 낮게 형성된 것으로 추측했습니다. 한편 finetuning과의 비교 실험 결과는 아래와 같 현실 실험 때와 일관되게 이득이 크지 않다는 결론을 보여주었습니다.
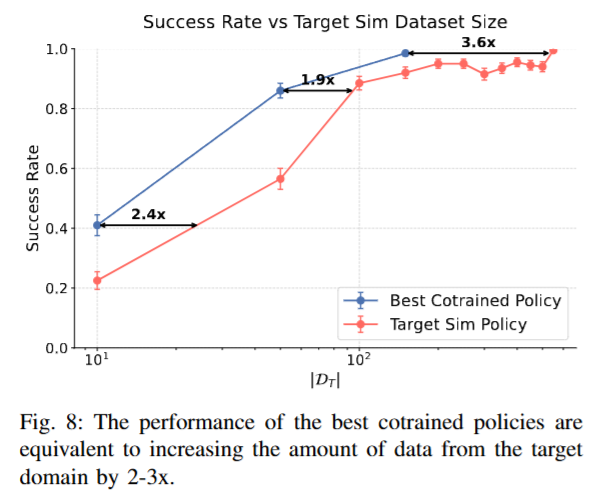
How does performance scale with Simulation demos?
시뮬레이션 데이터를 늘리는 스케일링 실험에서도 현실 실험과 유사한 패턴이 관측되었습니다. D_S를 증가시킬수록 정책 성능이 꾸준히 향상되었지만, 점차 개선 폭이 줄어들며 일정 성능 수준에서 미미해지는 경향을 보였습니다. 이는 시뮬레이션 데이터만으로는 현실 성능을 무한정 높일 수 없고, 결국 현실 데이터의 추가가 있어야 공동학습 성능의 상한선을 끌어올릴 수 있음을 의미합니다. 아래 그래프를 보면 이러한 현상을 각 현실 데이터 크기별로 보여주는데, co-training으로 얻은 최고 성능이 추가 현실 데이터 2~3배를 얻었을 때의 성능과 맞먹는 수준임을 정량적으로 확인할 수 있었습니다. Co-training 150개 target sim 데이터 수준의 성능을 내려면 target sim시뮬레이터 시연만으로는 3.6배 더 필요했다고 합니다. 이 결과는 시뮬레이션 데이터를 통한 co-training이 현실 데이터의 부족을 부분적으로 해소해주는 역할을 함을 볼 수 있습니다. 다만 현실에서는 이미 150개로 success rate가 100인데.. 진짜 현실 데이터는 일단 무조건 중요한 것 같습니다.
Distribution Shift Experiments
솔직히 지금까지는 기존 논문과 딱히 다른점이 없었는데, 여기서부터 좀 재밌는 실험들이 있었습니다. 저자들은 현실과 시뮬레이터 사이에 존재할 수 있는 다양한 domain shift들이 co-training 성능에 미치는 영향을 조사했습니다. 아래와 같은 shift가 고려되었습니다. 카메라의 시야, 무게중심, goal pose, object 종류가 고려되었습니다.

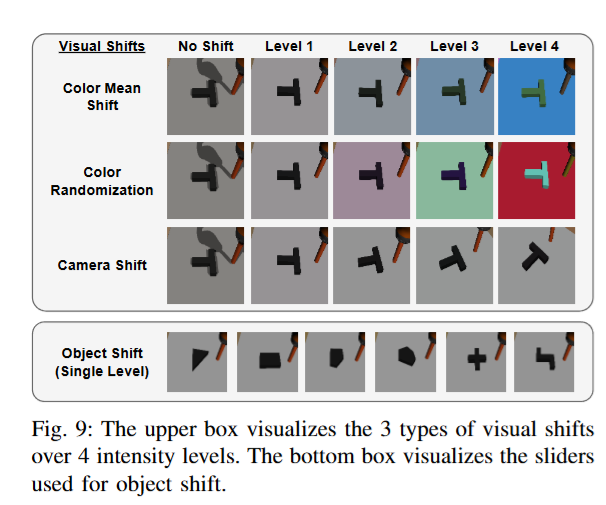
각 차이마다 Level 1 ~ Level 4로 변화의 크기를 달리하여 실험했고, Level 1은 가능한 작은 변화(단순 시뮬레이터 vs 현실 차이 수준으로 설정되었습니다. 예를 들어 색상 무작위화의 경우 Level 1은 본래 색에서 아주 근소하게(random half-radius 0.025) 변화시키는 정도이고, Level 4는 물체 색을 완전히 무작위로 바꾸어 버렸다고 합니다. 모든 실험에는 현실에 해당하는 목표 시뮬레이터 데이터 D_T 50개와 시뮬레이터 데이터 D_S 2000개를 사용하고, 변화시킬 격차만 조절했다고 합니다. 또한 비교를 위해 격차가 없는 추가 시뮬레이션 데이터셋을 만들어 해당 경우도 시험했습니다.
당연하지만 분포 차이가 커질수록 성능이 감소했지만, 몇가지 눈에 띄는 점들이 있었다고 합니다. 먼저 object나 goal pose가 달라지는 경우 성능 저하가 매우 두드러졌지만, 단순 시각적 차이만 있는 경우 성능은 비교적 강건했다고 합니다. 색상 평균값을 약간 바꾸는 정도(Level 4까지)로는 성공률이 거의 떨어지지 않았고, 카메라 각도 변화도 큰 영향을 주지 않았습니다. 반면 goal pose를 10cm 정도 차이나게 설정하거나 물체의 무게중심을 6cm정도 다른 위치에 설정하는 경우에는 성공률이 크게 하락했습니다. 또한 색상 무작위화나 목표 위치 변화의 강도가 커질수록 최적 혼합비 α가 현실 데이터 쪽 (α 증가)으로 치우치는 경향이 일부 관찰되었지만, 다른 격차들에서는 α 최적값에 뚜렷한 변화가 나타나지 않았다고 합니다.
물리 정확도의 중요성도 드러났습니다. 시뮬레이터의 물리 모델을 현실과 최대한 유사하게 맞춘 경우 co-training 정책의 성공률이 높게 나타났습니다. Contact rich한 task의 경우 성능에 가장 결정적 요소임을 보여주었다고 합니다. (물론 주로 시각적 또는 의미적 판단에 의존하는 작업이나, 물체를 파지하여 안정적으로 다루는 작업 등에서는 물리 격차에 따른 영향이 이렇게 크지 않을 수도 있다고 저자들은 언급했습니다.)
마지막으로는 시각적 격차에 대한 미묘한 효과입니다. 일반적으로 렌더링 품질을 높여 시각적 격차를 줄이면 성능이 개선되는 경향이 있는데, 역설적으로 시각적 격차를 완전히 없앤 정책의 성능은 오히려 약간 떨어졌다고 합니다. 즉 아주 작은 시각적 차이는 도리어 이득이 있었는데, 저자들은 그 이유를 정책이 두 환경을 구별할 수 있는 단서를 남겨두기 때문이라고 해석했습니다. 시각적 차이가 전혀 없으면 정책이 현재 자신이 현실 환경에 있는지 시뮬레이터에 있는지 알 수 없게 되고, 그로 인해 동작 예측에 혼선이 생겨 성능이 저하된다는 가설입니다.
전체적으로 요약을 해보자면 시뮬레이터로 학습용 데이터 생성을 할 때 물리 엔진의 정확도를 최대한 현실에 가깝게 높이는 것이 매우 중요하며, 시각적 품질도 향상시킬수록 성능이 좋아지지만 정밀한 photorealistic한 정도 까지는 불필요함을 주장하고 있습니다. 오히려 약간의 시각적 차이나 명시적인 환경 표시가 있는 편이 정책이이 어느 환경에 배포되었는지 인지하게 만들어 올바른 행동을 선택하는 데 도움을 준다고 합니다. (이 내용은 조금 뒤에 더 자세히 다루도록 하겠습니다) 또한 대부분의 분포 격차 조건에서 최적의 α 값은 크게 변하지 않았으며, 극단적인 환경 차이가 있는 경우에도 현실 데이터는 여전히 성능에 지대한 영향을 미칩니다.
How Does Co-training Succeed?
단순히 실험적인 결과에 덧붙여서 저자들은 어떤 요소가 co-training에 긍정적으로 작용하는지를 추가적으로 설명하려고 했습니다. 우선 정책의 도메인 식별 능력의 중요성에 대해서 언급하고, 어떤 요소들이 긍정적으로 작용하는지에 대한 설명이 진행됐습니다.
Physical Gap vs Visual Gap
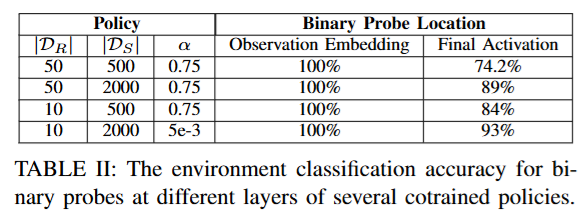
저자들은 Co-training이 효과가 있으려면 정책이 현재 입력이 어느 도메인(시뮬레이션인지 현실인지)에서 온 것인지 식별할 수 있어야 함이 밝혀졌다고 합니다. 성능이 높은 co-training 정책일수록 동일한 관측에 대해 시뮬레이터와 현실에서 서로 다른 행동을 예측하도록 학습되며, 정책이 환경을 구분하고 다른 전략을 구사한다는 것을 밝혔다고 합니다.저자들은 아래 Table 2와 같이 학습된 정책 네트워크의 내부 표현을 분석하여, 이진 분류기를 통해 해당 임베딩이 시뮬레이션에서 나온 것인지 현실에서 나온 것인지 아래 표와 같이100% 정확도로 맞출 수 있음을 보였습니다. 초기 시각 특성을 추출한 네트워크 층의 임베딩에서는 환경 분류 정확도가 100%에 달했고, 최종 출력 직전의 임베딩에서도 74~93% 수준의 높은 정확도로 환경 정보를 보존하고 있었습니다. 저자들은 이는 정책 신경망이 관측에 내포된 환경 구별 단서를 학습 과정에서 잃지 않고 끝까지 전달하고 있다는 뜻으로 해석했습니다. 그러면서 성공적인 co-training 정책은 시뮬레이터와 현실을 구분하며, 각 환경에 맞는 동작을 따로 익히는 것으로 나타났다고 합니다.
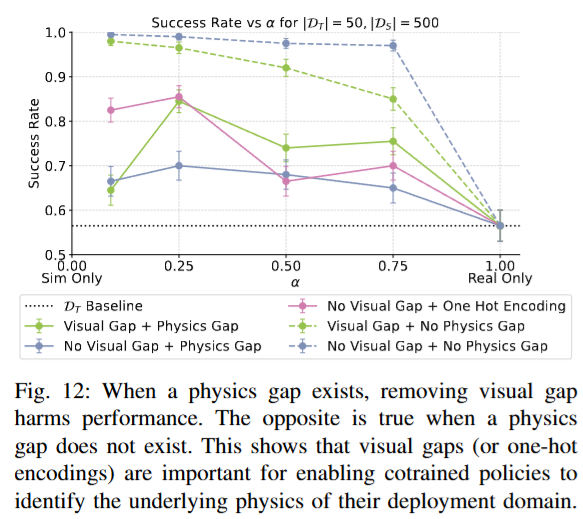
이러한 도메인 식별의 필요성은, 두 환경의 물리 특성이 서로 다를 때 더욱 두드러지게 나타난다고 합니다. 아래 figure 12를 보면 시뮬레이터와 현실 간 physics gap이 존재하는 경우, 두 환경의 visual gap을 제거해버리면 정책의 현실에서의 성공률이 크게 떨어졌습니다. 반면 환경을 나타내는 one hot encoding 정보를 정책에 추가로 제공했을 때 다시 성능이 좋아졌는데, 이를 통해서 정책이 시각적 단서 또는 명시적 신호로 환경을 구별할 수 있어야 함을 또 증명할 수 있었다고 합니다. 또 physics gap이 없는 경우에는 정반대의 결과가 나타났습니다. 두 환경이 물리적으로 동일하다면 시뮬레이터와 현실 간의 visual gap을 제거하는 것이 오히려 성능을 높였습니다. 어느정도 당연하겠지만 환경 구분이 필요하지 않을정도로 구성된 상황에서는 불필요한 시각 차이를 줄이는 편이 유리하다는 의미입니다. 결국 co-training 정책이 환경을 식별하는 능력이 중요한 이유는, 시뮬레이터와 현실의 물리엔진이 다르기 때문이라는 결론을 낼 수 있을 것 같습니다. 이런거 보면 정말 neural physics engine이 발전하거나 world model을 활용하는 방법으로 흘러가는게 맞는 것 같습니다..
Mechanisms For Positive Transfer in Cotraining
공동학습에서 시뮬레이션 데이터가 현실 성능을 높여주는 메커니즘으로, 저자들은 데이터 커버리지와 스케일링 법칙 두 가지 관점을 제시합니다.
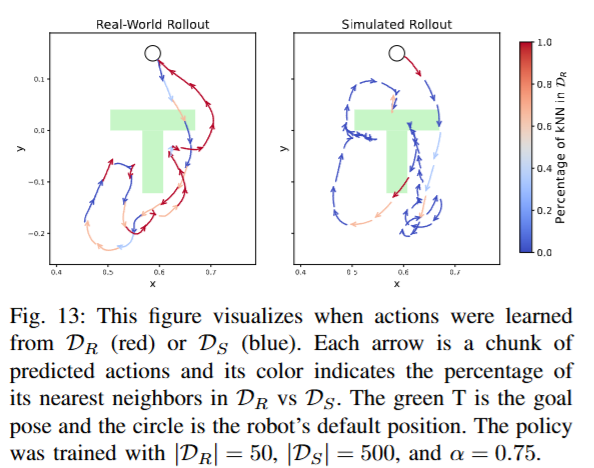
먼저 데이터 커버리지 관점에서 시뮬레이션 데이터 현실 데이터가 포괄하지 못한 state-action gap을 메워주는 역할을 한다고 합니다. 저자들은 하나의 co-training 정책을 동일한 초기 상태에서 현실 환경과 시뮬레이터에서 각각 실행시키고, 각 행동 결정에 가까운 K-nearest neigbor가 현실 시연에 속하는지 시뮬레이션 시연에 속하는지 색깔로 표시하여 시각화했습니다. (녹색 T가 target, 원은 로봇의 초기 푸셔 위치입니다). 아래 Figure 13에서 볼 수 있듯이, 현실 환경에서의 정책의 rollout은 경로 대부분(빨간색 화살표 구간)은 현실 데이터상의 경험들을 참고해 행동을 결정했으나 중간중간 현실 데이터에 없는 구간에서는 시뮬레이션 데이터에 의존하는 모습이 관찰되었습니다. 반대로 시뮬레이터에서의 rollout은 주로 파란색(시뮬레이터)에 의존하면서도 일부 구간은 빨간색(현실 이웃)이 섞여 있었습니다. 흥미로운 점은, 이 실험에서 시뮬레이션 데이터 D_S의 규모가 현실 D_R의 10배였음에도 불구하고 현실 환경에서의 정책 결정은 여전히 현실 데이터 위주(대부분 빨간색)로 이루어졌다는 것입니다. 일관되게 시뮬레이션 데이터로 현실 데이터를 완전히 대체할 수 없고 섞어서 활용해야 시너지가 생긴다는 점을 알 수 있습니다.
추가적으로 시뮬레이션 데이터가 늘어남에 따라 현실 도메인에서의 test loss와 actionMSE가 얼마나 감소하는지를 분석한 결과, power law에 따라 오류가 줄어드는 양상 (로그-로그 스케일에서 직선 형태의 감소 추세라고 합니다) 이 나타났습니다. Test loss는 Diffusion Policy의 학습 과정에서 사용하는 denoiser loss를 테스트 데이터셋에 대해 계산한 값입니다. 학습된 denoiser가 unseen에서 얼마나 noise를 action으로 잘 변환했는지에 대한 지표로 생각하면 될 것 같습니다. Action MSE는 gt action과의 MSE입니다.
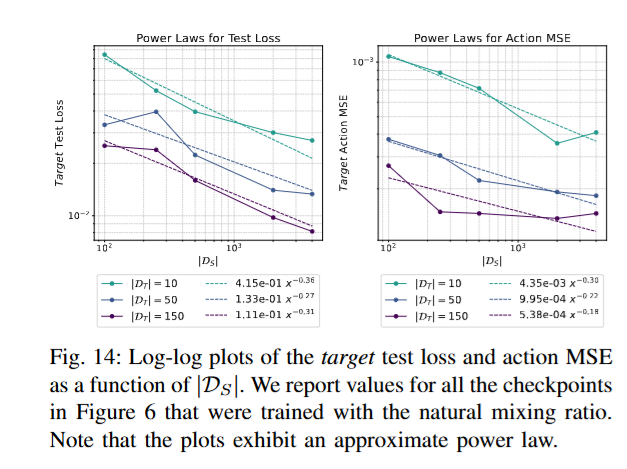
위 figure14를 보면 시뮬레이션과 현실 데이터 두 지표에 대해 모두 확실한 성능 향상 효과를 가져옴을 알 수 있습니다. 시뮬레이션 데이터를 늘려가는 과정에서 현실에서의 성능도 예측 가능한 정도로 개선을 보이는데, D_S가 많이 커지더라도 또 성능 향상에 한계가 있는 포인트는 여전히 볼 수 있습니다.
Ablation Studies
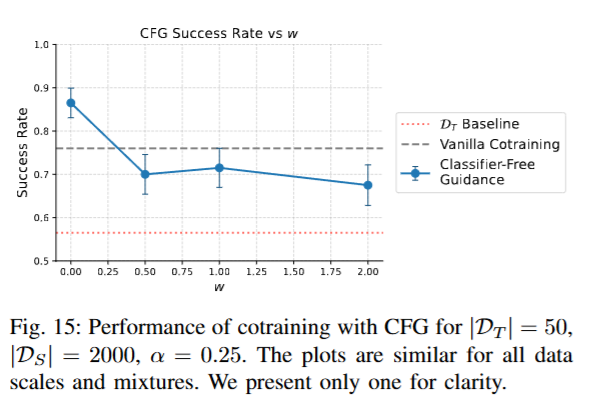
저자들은 앞서 얻은 인사이트를 바탕으로 환경에 따른 행동 차이를 샘플링 단계에서 의도적으로 증폭시키는 Classifier-Free Guidance를 적용해 환경의 one hot 벡터를 추가하고 실험을 진행했는데, 아래 figure 15와 같이 해당 조건의 영향을 증폭하지 않았을때는 성능이 조금 증가했지만 오히려 w값을 높여서 증폭을 하는 경우에는 vanilla co-training 방법보다 성능이 나오지 않았다고 합니다.
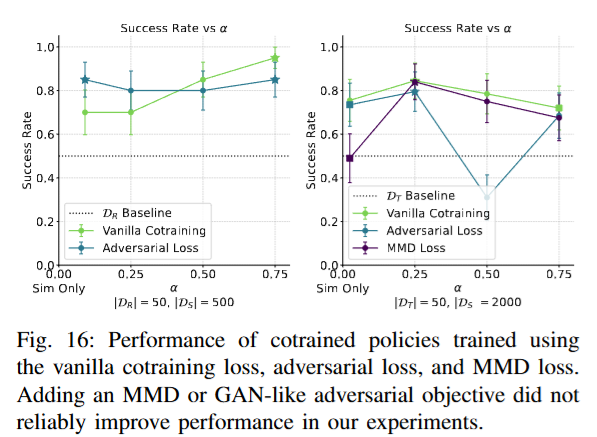
시뮬레이터 격차를 줄이는 또 다른 접근으로 정책 신경망의 표현 공간에서 두 도메인의 분포를 가깝게 만드는 방법도 진행해봤다고 합니다. GAN 형식으로 도메인 분류기를 학습해 표현이 어느 도메인인지 맞추지 못하도록 정책을 학습하는 방법과 표현 분포 간 MMD 거리를 계산해 최소화하는 방법을 시도해봤는데, 아래 figure 16과 같이 기존의 vanilla co-training보다 일관되게 높은 성능을 보이지는 않았다고 합니다. 다만 아직 시도되지 않은 다른 표현 정렬 방식 중에는 기본 공동학습보다 나은 성능을 낼 가능성도 배제할 수 없다고 언급하면서 시뮬레이터 자체의 개선이 아닌 표현 공간에서 도메인 격차를 줄이는 방향은 여전히 흥미로운 연구 주제라고 언급했습니다. X-sim에서는 real과 sim간의 rollout시의 observation 기준으로 DP의 인코더를 contrastive learning 했다고 했는데 비슷한 맥락인건가..?는 조금 고민을 더 해봐야 할 것 같습니다.
Conclusion
Diffusion Policy를 기준으로 다양한 실험을 통해 체계적으로 co-training에 중요한 요소들에 따른 성능 변화를 보여주었는데, 실험의 규모가 꽤 큰 것 같습니다. 다만 아직 DP에 대해서만 분석이 이루어졌고, 그 분석들이 simulation data를 활용하는데 있어서 유의미하다고 판단되기 때문에 Diffusion Policy 뿐 만 아니라 VLA 모델들에서도 각종 task에 대해서 실험을 통해 분석하는것도 가능하다면 해보고싶다는 생각이 들었습니다. 또 Diffusion Policy에서 보더라도 저자들이 고려하지 않은 simulation과 현실의 차이, task구성이나 추가 조건등을 생각해볼 수 있을 것 같습니다.
좋은 리뷰 감사합니다.
처음에 제목을 보고 ‘sim 데이터와 real 데이터를 이렇게 세밀하게 조합하여 학습을 하면 가장 효과적이다~’ 라는 느낌의 학습 방식 제시 논문일 줄 알았는데 \alpha 값을 변경하면서 진행한 분석 실험에 가깝군요. 그럼에도 꼼꼼히 잘 작성해주셔서 이해하는데에 수월했습니다.
fig 4 (How does cotraining compare with finetuning) 와 관련해서 간단한 질문이 있는데요, 좌측 |D_R|=10 인 차트에서 |D_S|=500 에서는 cotraning w/o finetuning -> cotraning w/ finetuning 으로 파인튜닝을 진행할 때 성능이 팍 치고 올라가는데 |D_S|=2000 에서는 파인튜닝을 하니 오히려 성능이 감소하는 결과가 보여집니다. (하늘->파랑)
이에 대해선 어떻게 이해하면 될지 저자의 분석이나 영규님의 견해가 있으실까요?
감사합니다.
안녕하세요 석준님 댓글 감사합니다.
Ablation에는 ‘sim 데이터와 real 데이터를 이렇게 세밀하게 조합하여 학습을 하면 가장 효과적이다~’ 에 대해서도 실험을 진행해본 것 같은데, 효과가 없어서 강조를 안 한 것 같습니다.
질문에 대한 답을 하자면 이 현상에 대해서 저자들도 언급을 했었는데요, fine-tuning은 real data의 수가 적을 때는 positive transfer로 작용하지만, sim data가 충분히 많은 경우엔 이미 cross-domain generalization이 포화 상태에 도달했기 때문에 fine-tuning이 그 representation을 오히려 망가뜨리는 결과를 초래할 수 있다고 해석했습니다.
저는 아직도 fine-tuning 방식과 근본적인 차이를 구조적으로 이해하진 못한 것 같습니다만.. 논문에 사용된 policy가 diffusion 기반인 만큼 data distribution의 구조를 기껏 잘 학습해놨더니 망가뜨리는? 모습이라고 생각합니다.
굉장히 흥미롭고 많은 인사이트를 주는 방법론 같습니다.
간단한 질문 몇 개만 하도록 하겠습니다.
Q1. 사람이 직접 시연한 real world 데이터셋이 상한을 정한다고 했습니다. 그럼 pusth T는 몇이라고 생각하면 될까요?
Q2. 그리고 상한은 task에 따라 크게 변동 될 것이라고 예상됩니다. 이에 대한 저자는 별다른 언급이 없었을까요?
안녕하세요 태주님 댓글 감사합니다.
답변을 드리자면,
A1. 저자가 real data 수를 바꿔가며 실험을 진행할 때, Real data가 150개일땐 Real data 만으로도 성공률 100퍼센트를 달성했습니다. 따라서 150개라고 생각하시면 될 것 같습니다. 150개 까지는 100퍼센트는 아니지만 사용된 real데이터가 늘어날수록 점진적으로 Co-training한 정책의 성공률도 같이 올라갔습니다.
A2. 저자들도 task를 Push-T로만 정해둔 것을 한계점으로 꼽으면서 task에 따라 상한을 결정하는 요소와 상한선 자체가 달라질 수 있다는 것을 언급했습니다.
제 개인적인 의견이지만 Pushing 같은 물리 상호작용 중심의 task에서는 real-world 데이터의 현실 역학이 핵심이었지만, 시각적인 인지 능력이 중요한 과제에서는 시각적인 fidelity나 domain randomization같은 요소가 중요할 수도 있을 것 같습니다.
안녕하세요 영규님
좋은 논문 리뷰 감사합니다.
Q1. task 선정에서 왜 Push T를 사용하는건가요? 특별한 이유가 있는건지 궁금합니다.
Q2. 글에서는 object나 goal pose가 달라지는 경우 성능 저하가 매우 두드러졌지만, 단순 시각적 차이만 있는 경우 성능은 비교적 강건했다고 하는데 저희가 저번주에 AI worker를 가지고 했던 실험에서 로봇의 위치가 살짝 틀어져 카메라의 시점이 살짝 바뀌었는데 성능 저하가 크게 보였던 것으로 기억합니다. 이 현상에는 다른 이유가 있을까요?
감사합니다.
안녕하세요, 영규님. 흥미로운 리뷰 잘 읽었습니다.
특히 시각적 격차(visual gap)가 완전히 사라질 경우 오히려 정책의 성능이 저하된다는 분석이 인상 깊었습니다.
한 가지 궁금한 점은, 리뷰에서는 시각적 차이가 약간 존재하는 편이 정책의 일반화에 유리하다고 언급되어 있었는데요. 그렇다면 현실과 같이 시뮬레이션 환경에 의도적으로 배경 노이즈나 단순한 객체를 추가하여 시각적 다양성을 높이는 접근이 정책의 강건성(robustness)을 향상시킬 가능성에 대해서도 논문에서 언급이 있었는지 궁금합니다.
좋은 리뷰 공유해주셔서 감사합니다.🤖