제가 이번에 리뷰할 논문은, affordance에 대하여 “How” 관점에 조금 더 집중한 연구입니다. CoRL 2025의 oral 논문으로, 음식을 먹여주는 보조-로봇 문제로 한정되어있으나 다른 작업으로 충분히 확장이 가능한 방법론인 것 같습니다.
Abstract
음식의 다양한 물리적 특성과 도구 사이의 상호작용을 고려하여 성공적으로 음식을 집을 수 있도록 하는 것을 목표로 하는 연구입니다. 저자들은 SAVOR라는 방식을 제안하여 물리적을 조작 방식이 음식과 도구 사이의 상호작용에 얼마나 적합한지를 학습하는 skill affordance를 학습합니다. 저자들은 tool affordance와 food affordance라는 개념을 제안하였으며, tool affordance는 사전에 각 도구의 기능적 특성을 모델링하는 tool calibration 작업을 통해 학습하며, food affordance는 부드러움/수분/점도와 같은 물리적 특성에 대해 시각 정보 및 visuo-haptic 정보를 활용하여 추론하도록 한 뒤, 가장 적절한 조작 방식을 선택하도록 하여 총 20개의 음식에 대한 10가지 real 환경에서 평가하여 SOTA를 달성하였다고 합니다.
Introduction
로봇으로 음식을 집는 작업은 1) 음식의 물리적 특성이 다양하고, 시간에 따라 물리적 특성이 달라지며 2) 도구와 음식 사이의 상호작용 방식이 종류마다 크게 달라진다는 점에서 어려움이 있습니다. 특히, 상호작용 방식은 음식과 도구의 종류, 둘을 고려한 조작 방식에 따라 모두 달라지며, 저자들은 이러한 어려움을 통해, 도구와 음식에 대한 affordance를 결합하고, 지속적으로 업데이트 하는 방식을 통해 기술적 affordance에 대한 이해를 개선하여 작업을 성공시키고자 하였습니다. 사람을 예시로 들어보면, 딸기를 포크로 집는다고 하면, 일반적인 지식을 활용하여 포크로 찍어봅니다. 그런데 만약 냉동딸기라 포크로 찍기에 실패한다면 이를 퍼올리거나 하는 방식으로 바꾸어 다시 집게됩니다. 이러한 사람의 행동을 정리해보면, 도구로 할 수 있는 조작 능력을 이해한 뒤, 시각 정보를 기반으로 상식적인 음식의 특성을 추론하고, visuo-haptic 피드백을 통해 조작 기술을 조정하는 과정을 거치게 됩니다.
저자들은 이러한 통찰을 기반으로 SAVOR라는 2-stage의 방식을 제안합니다. tool affordance에 대하여 사전에 학습을 시킨 뒤, 실제로 조작을 수행하며 음식의 물리적 특성을 추론하고 visuo-haptic 정보를 기반으로 조작 기술을 업데이트 하는 방식으로 작동합니다.
해당 논문의 contribution을 정리하면
- 음식의 물리적 특성을 기반으로 초기에 시각 정보를 기반으로 상식적 추론한 뒤, 시각-촉각 정보를 활용하여 업데이트하는 food affordance 학습 방식 제안.
- 음식과 도구의 종류를 고려하여 적합한 조작 방식을 학습하는 방식 제안.
- 20가지 음식에 대하여 10가지 실제 식사 환경에서 평가하여 기존 방법론 대비 성능 개선을 확인
- 다양한 음식 및 도구로 일반화 가능한 trajectory-level의 visuo-haptic 데이터 셋 제안.
Method
0. Problem Formulation
로봇이 도구를 이용하여 음식을 지정된 순서로 집어야하는 작업으로 정의하며, 순서는 사용자가 자연어로 지정해주며, 로봇은 각 음식을 잡기 위해 하나 이상의 동작을 수행합니다. 음식을 성공적으로 집었을 경우 다음 음식으로 넘어가며, 정해진 시도 횟수 안에서 가능한 많은 음식을 집는 것을 성공하는 것이 목표입니다.
이는 POMDP(Partially Observable Markov Decision Process) 문제로 정의되며, 튜플 ( \mathcal{S, A, O_0, O, T, Z}, R, L)로 표현됩니다. (로봇이 불확실한 환경 속에서 목표를 달성하기 위해 어떤 행동을 선택해야 하는지를 수학적으로 정의하는 방식으로, 강화학습은 이러한 정의를 기반으로 최적의 정책을 학습하는 등 활용됨)
- State s \in \mathcal{S}: 로봇의 엔드이펙터 자세, 목표 음식 항목, 접시 위의 모든 음식의 위치 및 물리적 특성을 포함
- Action a \in \mathcal{A}: 사전에 정의된 skill library (
push, cut, skewer, dip, scoop, twirl) 중 하나의 조작 방식 - init observation o_0 \in \mathcal{O}_0: robot의 손에 부착된 카메라로 얻은 초기의 RGB-D 이미지 I_0 \in \mathbb{R}^{W⨉H⨉4}
- observation o \in \mathcal{O}: 이후 수집된 연속적인 RGB-D 이미지 시퀀스 I \in \mathbb{R}^{T⨉W⨉H⨉4}, force-torque 센서 데이터 F \in \mathbb{R}^{T⨉6}, end-effector의 pose P \in \mathbb{R}^{T⨉6}
- transition model \mathcal{T}: 다음 상태로 넘어가게 하는 모델로, unknown
- observation model \mathcal{Z}: 로봇이 관측한 환경을 모델링하는 모델로, unknown
- reward function R: 대상 음식을 집는 데 성공하면 1을 반환하고 아니면 0 반환하는 보상 함수
- time horizionL: 로봇이 의사결정을 내릴 때, 고려하는 시간적 한계
음식의 물리적 특성은 visuo-haptic 관측값 (I,F)을 이용하여 추정되며, 물리적 특성으로는 모양, 크기, 부드러움, 수분, 점도 5가지를 고려하였으며, 모양과 크기에 대해서는 자연어로 나타내고 나머지는 1~5 까지의 값으로 표현하였다고 합니다
1. SAVOR
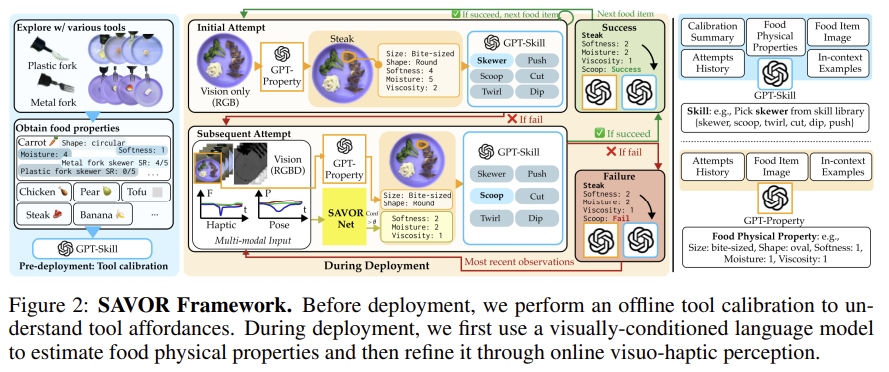
SAVOR는 먼저 tool affordance를 추정하기 위해 tool calibration 과정을 거칩니다. 해당 과정은 다양한 음식에 대하여 조작 skill을 실행하여 calibration dataset을 구합니다. 또한, 시각-촉각 정보를 함께 입력으로 받아 음식의 물리적 속성을 예측하는 SAVOR-Net을 학습합니다. 이후 테스트 시점에 새로운 접시의 음식이 주어졌을 때, 초기에는 시각 정보만을 이용하여 물리적 특성을 구하여 작업을 실행한 뒤, 이후 학습된 SAVOR-Net을 통해 예측된 물리적 특성을 업데이트합니다. 작업을 수행하기 위해 물리적 특성과 skill에 대한 calibration data을 VLM에 입력하여 skill sequence를 생성하여 행동을 수행합니다.
1-1. Pre-Deployment
1단계의 사전 작업입니다. tool calibration과 SAVOR-Net에 대한 사전학습을 수행합니다.
<Offline Tool Calibration>

tool calibration은 도구의 affordance에 대한 맥락적 지식을 제공하는 것을 목표로, 다양한 음식에 대한 여러 조작 skill을 무작위로 수행하여 생성된 소규모의 offline calibration dataset을 수집합니다. 이는 사람이 수동으로 수집하였으며, 도구와 음식의 종류, 음식의 물리적 특성, 수행 결과(성공여부)가 포함되며, 위의 그림처럼 자연어로 표현이 되어있습니다. 이런식으로 만들어지는 데이터를 VLM에 입력하여 VLM-based planning을 통해 로봇이 움직이도록 합니다.
<Offline Training SAVOR-Net>
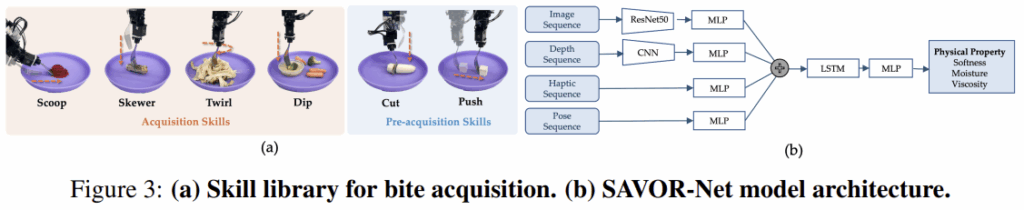
SAVOR-Net은 시각-촉각 정보를 기반으로 음식의 물리적 특성을 예측하는 신경망으로, 위의 Figure 3의 (b)를 통해 대략적인 구조를 확인하실 수 있습니다. 입력으로 RGB-D와 force-torque 센서 데이터, end-effector의 pose에 대한 시계열 데이터를 입력으로 한 뒤, 부드러움/수분/점도에 대한 1~5 단계별 확률 \psi \in \mathbb{R}^{3⨉C}를 출력합니다.
SAVOR-Net은 4가지 입력(RGB와 Depth를 구분)에 대하여 별도의 encoder를 이용하며, 동일 차원(128차원)으로 인코딩한 뒤 4개의 벡터를 결합하여 하나의 통합된 multi-modal representation을 만들어 2개의 LSTM을 통과시키고 3 layer의 MLP를 통과시켜 최종 출력을 생성해냅니다. 해당 네트워크는 기존 데이터(사람이 다양한 음식에 대하여 skewering 작업을 수행하는 400개의 예시로 구성)를 사전학습에 사용한 뒤, 자체적으로 저자들에 생성한 300개의 예시 데이터(20가지 음식에 대하여 skewering, push, twirling. cutting, dipping, scooping 작업을 수행)로 fine-tuning을 수행하였다고 합니다.
1-2. During Deployment
<State Estimation>
tool calibration 데이터 셋과 사전학습된 SAVOR-Net이 주어졌을 때, 첫번째 시점에서는 로봇이 시각 정보를 기반으로 초기 상태를 추정합니다. 추정한 상태를 활용하여 로봇이 행동을 수행하면서 시각-촉각 데이터를 수집한 뒤, 이를 다시 SAVOR-Net에 적용하여 행동을 refine합니다. 성공시에는 다음 물체로 넘어가게 되며, 실패했을 시 초기 수행을 통해 얻은 정보를 기반으로 다른 skill을 선택하여 다시 작업을 시도하는 방식으로 점차 업데이트를 수행합니다.

조금 더 구체적으로 설명드리자면, 초기에는 GPT-4V를 이용하여 음식의 종류를 추저한 뒤, GroundedSAM으로 물체 영역을 찾아냅니다. 이후 VLM에 해당 물체 영역과 위의 프롬프트를 함께 입력하여 물체의 물리적 속성을 추정합니다.
<Planning>
마지막으로 tool calibration dataset과 예측한 음식의 물리적 속성 \hat{s}_t을 활용하여 VLM(GPT-4v이용)에 query를 던져 skill library에서 사용할 기술을 선택합니다.

만약 작업에 실패한다면, SAVOR-Net을 통해 음식의 물리적 속성을 추론하여 작업을 다시 수행하는 방식으로 업데이트합니다. 만약 새로운 음식에 대하여 이전의 상호작용 데이터가 없다면, 유사한 음식에 대한 결과를 기반으로 초기 추정을 수행한다고 합니다.
Experiments
저자들은 실험을 통해 다음 4가지 질문에 대하여 실험적으로 확인하였습니다.
- Q1: tool calibration이 skill selection에 도움이 되는지?
- Q2: viso-haptic 정보를 활용한 피드백이 음식의 물리적 특성을 추정하는 데 도움이 되는지?
- Q3: 제안한 방식이 기존 연구보다 얼마나 효과적인지?
- Q4: 새로운 음식으로 일반화 가능한지?
Setting

SAVOR는 20가지 음식에 대하여 음식별 시나리오와 위의 Figure 4와 같은 실제 식사와 같은 10개의 시나리오, 총 30가지에 대하여 평가가 이루어졌습니다. 평가지표는 Success Rate을 사용하며, 5초 이상 집어올린 상태를 유지하면 성공으로 판단합니다. 평균 시도 횟수에 따라 SR1~SR3(1~3번시도)가 되며, 총 3번 재시도하였을 때 실패하는 것을 실패로 판단합니다. 또한, Average Attempt Efficency(AE)를 정의하여, 전체 시도 대비 성공한 비율도 함께 리포팅합니다.
하드웨어는 Kinova Gen3 로봇팔을 이용하였으며, end-effector 위치에 도구를 장착해두고 작업을 수행합니다. RealSense D435 카메라를 로봇의 손에 달았으며, Nano25 F/T force-torque 센서를 통해 haptic 정보를 수집합니다.

Results
<Evaluating the Contribution of Tool Calibration (Q1)>
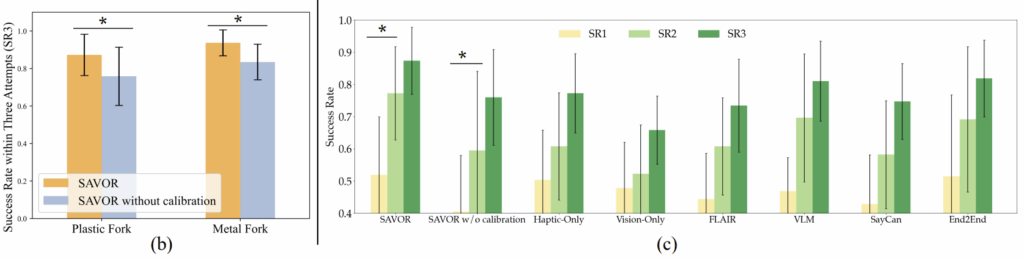
플라스틱과 금속 포크 2가지에 대한 tool calibration 효과를 평가한 실험 결과입니다. tool calibration을 통해 성공률이 유의미하게 개선되었음을 확인하였으며(b), SR2에서 18%, SR3에서 13%의 성능 향상이 이루어졌습니다(c). 또한, 저자들에 따르면 tool calibration을 수행하지 않으면 상황과 무관하게 skewering(찌르기) 방식을 시도하는 경향이 있다는 것을 확인하였다고 합니다.
<Evaluating the Contribution of Visuo-Haptic Perception (Q2)>
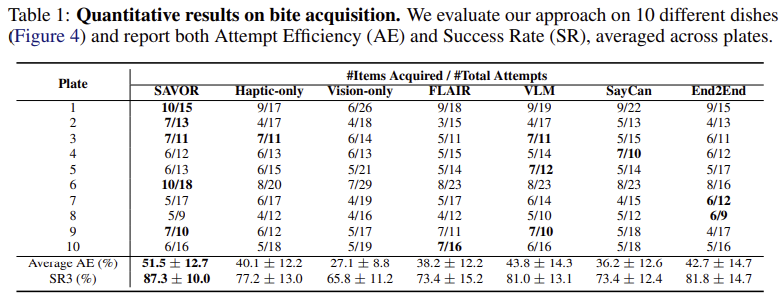
시각 정보와 촉각 정보 인식의 효과를 확인하기 위해 둘 다 사용한 SAVOR와 각 정보만을 사용한 vision-only 와 haptic-only 버전을 비교하였습니다. 실험적으로 두 정보를 활용하므로써 전반적인 성능이 개선되었음을 확인하였습니다. vision-only 모델의 경우 시각적으로 비슷하지만 물리적 특성이 다른 딸기, 수박, 당근에 대하여 잘못 분류하였으며, softness에 대하여 판단에 실패하여 당근을 집는 데 반복하여 실패하였다고 합니다. 또한, haptic-only 모델은 시각 정보를 사용하지 않기 때문에, 두부와 같이 부드러운 음식에 대해 포크가 바닥면을 치거나, 견과류와 같이 단단한 물체를 집을 때 포크가 휘면서 발생하는 force의 변화 패턴이 유사하여 잘못된 힘을 주는 경향이 있다는 것을 확인하였다고 합니다. 반면 SAVOR는 두 정보를 활용하므로써, AE 51.5%, SR3 87.3%를 달성하였습니다.
<Evaluating the the Overall Framework (Q3)>
앞선 그래프와 표를 통해 기존 연구 대비 성능 개선을 확인할 수 있습니다. 저자들에 따르면, 그래프(c)의 결과를 통해 SR1에서 SR3까지 모두 성능 개선이 이루어졌으나, 기존 연구들은 단순히 반복횟수만이 늘어난 것이며, SAVOR 방식만이 앞선 시도를 기반으로 다른 skill을 시도하는 등의 적응적인 결과를 보였다는 점을 어필합니다.
<Evaluating Generalization to Unseen Food Items (Q4)>
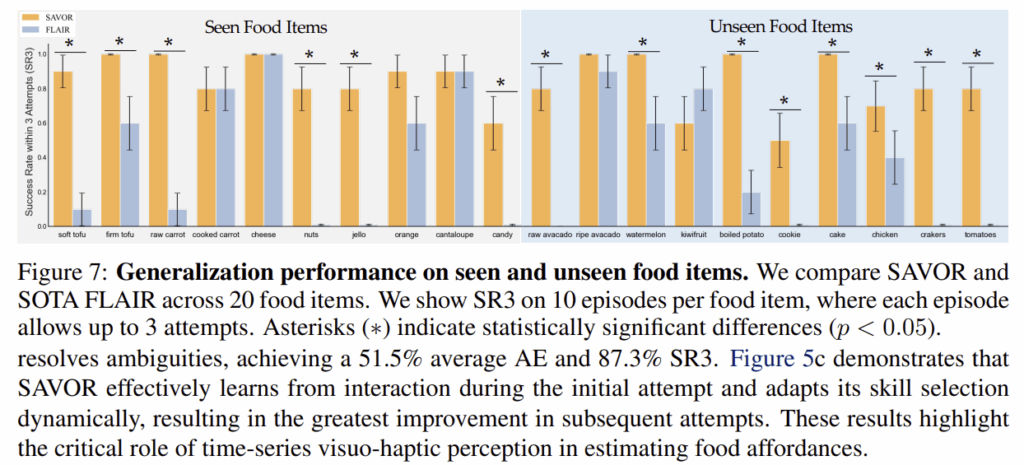
마지막으로, unseen 음식으로의 일반화 성능을 검토하였습니다. 기존 방식인 FLAIR에 비해 70%의 무렟에 대하여 더 높은 SR3를 달성하였다는 것을 확인할 수 있으며, 이러한 결과를 통해 음식의 물리적 속성을 명시적으로 추정하므로써, 뛰어난 일반화 능력을 갖출 수 있었다고 어필합니다.
Limitation
저자들은 음식을 모두 하나의 단위로 간주하여 특성을 추출하는 방식이 한계라는 것을 밝혔습니다. 예를들어, 브로콜리의 경우 줄기 부분과 꽃 부분의 부드러움이 크게 달라지는데, 이러한 세분화된 표현을 추후 고려하겠다고 이야기합니다. 개인적으로는, 시간에 따라 음식의 속성이 달라진다고 하였는데, 이러한건 방법론적으로 다루고 있지 않고, 업데이트를 통해 최종적인 음식 형태를 따르는 방식으로 이루어진다는 점이 조금 아쉬웠습니다. 또한, 저자들은 open-loop 방식으로 조작 이후 결과를 실시간으로 반영하지 못한다는 것과, 작업 중 미끄러짐이 발생하면 촉각 신호에 문제가 생겨 추정이 부정확해질 수 있다는 점을 개선해야한다고 밝혔습니다. 여기서 open-loop 방식이라는 것이 결국, 성공 여부를 자동으로 판단하지 못한다는 것을 의미하는 것으로 보입니다.
리뷰 잘 읽었습니다
처음 이 논문을 소개시켜주셨을 때 든 의문이었는데, GPT 같은 대형 LLM이 가진 엄청난 prior knowledge 만으로 음식의 속성을 어느정도 이해할 수 있을 것이라 생각했습니다. 가령 논문의 예시에서처럼 차가운 치킨너겟은 딱딱하다 처럼 말이죠. 즉, LLM을 어차피 중간 과정에서 사용한다면 더 많은 정보를 뽑아낼 수 있지 않을까 싶은데 어떻게 생각하시나요?
두번째는 해당 논문이 open-loop 한계를 인정했다고 하신 것 같은데요. 그럼 실제로는 실패를 자동 감지하지 못하고 “사람이 보고 판단”하는 셈인데, 이 점이 보고된 SR/AE 지표에 유리하게 작용했을 가능성은 없나요?
리뷰 잘 읽었습니다.
Q1. Problem Formulation에서 transition model, observation model이 등장하는데 이후 리뷰에는 보이지 않는 것 같습니다. 두 모델은 GPT를 사용하는 것이라고 예상이 되는데요. 어떻게 작동이 되는 건지 궁금합니다.
Q2. Force-Toque sensor는 Tool에 부착된 센서일까요? 어떤 방향으로 툴에 수직 방향으로 배치된 센서인지 아니면 팔에 탑재된 센서인지 궁금합니다.
안녕하세요 승현님. 좋은 리뷰 잘 읽었습니다.
Q1. tool calibration 과 관련하여 질문하고 싶습니다. 논문에서는 tool을 포크만 선택해서 진행 한 것 처럼 보이는데 이유가 있을까요? 다른 tool에 대한 분석 결과는 없는지 궁금합니다. (그리고 제가 이해한 tool이 이 tool 맞겠죠?)
Q2. table1에서 설명하시길 수박, 당근, 딸기가 시각적으로 비슷하다고 하셨는데, 이 부분이 이해가 잘 안가는 것 같습니다. 그리고 어찌보면 저는 당근과 수박은 포크를 사용함에 있어서 물리적인 정보가 비슷하다고 생각하는데, softness 판단에서 왜 당근만 실패해서 집는 것을 실패한지 궁금합니다. 그리고 포크를 사용하면서 집는다는 표현이 어떤 행동인지 궁금합니다!
감사합니다.