안녕하세요, 오늘은 AVQA 논문들을 팔로우업 하면서 읽어보게 된 논문입니다. AVQA 태스크를 어느정도 들어보셔서 알고 계시겠지만, 기본적으로 오디오와 비디오의 정보를 이해하고 그에 관련한 자연어 질의에 대답해야 하는 태스크입니다. 바로 리뷰 시작하겠습니다.
Abstract
오디오와 비디오의 질의응답을 해야하는 AVQA task는 자연어 질의에 정확하게 응답해야 하는 복잡한 멀티모달 추론 과제입니다. 저자는 기존의 AVQA 접근법들은 데이터셋의 편향을 과도하게 학습하는 경향이 있으며 이는 낮은 강건성을 초래한다고 합니다. 제가 이 분야의 많은 논문을 읽어보고 데이터셋을 찾아보고 한 것은 아니지만, 현우님이 진행하고 계신 개인연구의 MUSIC-AVQA 데이터셋을 보더라도 어느정도 편향이 존재할 부분들이 분명히 존재했습니다. 가령 악기의 종류가 몇 종류인지를 물어보는 질문에 대해 답이 0~9, 10개 이상 이라는 답변이 가능할때 답이 0~4개인 경우는 굉장히 많은 반면 7개 8개 9개인 샘플은 100배정도 적은 훈련셋과 평가셋이 존재하는 경우도 있었습니다.
저자는 이러한 문제들을 해결하기 위해 새로운 데이터셋인 MUSIC-AVQA-R 을 제안합니다. 이 데이터셋은 두가지 단계로 구성된다고 합니다.
- 공개 데이터셋 MUSIC-AVQA 의 테스트 분할 내 질문들을 Rephrasing 즉 재표현한다.
- 해당 질문들에 대한 분포를 조절한다.
전자는 크고 다양한 테스트 공간을 형성하며 후자는 희귀한 질문, 빈번한 질문, 그리고 전체 질문에 걸친 포괄적 강건성 평가를 가능하게 한다고 합니다.
두번째로 bias learning을 극복하기 위해 multifaceted cycle collaborative debiasing strategy 를 활용하여 강건한 아키텍처를 제안합니다.
저자는 기존의 데이터셋인 MUSIC-AVQA 과 저자의 데이터셋인 MUSIC-AVQA-R 에 대해 각각 제안된 디바이어싱 전략을 분석하고 기존의 방법론들에도 해당 전략이 잘 통하는지에 대한 ablation까지 진행했다고 합니다.
Introduction
인간은 청각적 시각적 단서를 매끄럽게 통합하여 시각 자극과 청각 자극 사이에 응집력 있는 관계를 형성하는 능력을 가지고 있습니다. 오디오-비주얼 질의응답 모델들은 이러한 능력을 지능형 시스템이 획득하도록 하여 주어진 자연어 질문에 기반한 답변을 생성하는 것을 목표로 합니다. 이는 시스템이 오디오-비디오-언어 모달리티에 걸친 개념들의 고차 상호작용 표현을 학습해야함을 먼저 언급합니다.
이러한 시스템들의 고차원적 추론 능력들은 유해한 편향이나 통계적 규칙성이 존재하지 않는 대규모 데이터에 주로 의존하지만 데이터셋 내 부정적 편향을 완전히 피하는 것은 어렵다고 합니다.
이전의 QA 연구에서는 정답 분포 변화나 인간이 직접적으로 관여하는 적대적 공격 관점에서 편향을 분석했었는데, 저자는 이러한 기존 연구들에 영향을 받아, 논문의 평가와 설계 측면에서 AVQA 과제에 관한 몇가지 오픈된 질문들을 제기합니다.
Q1 : have existing datasets comprehensively measured model robustness?
기존의 데이터셋들은 모델의 강건성을 포괄적으로 측정했는가?
현재 AVQA 데이터셋의 질문들은 사전에 정의된 제한된 템플릿 집합으로 생성되며 예를 들어 MUSIC-AVQA 데이터셋에는 33개의 템플릿만 존재합니다.
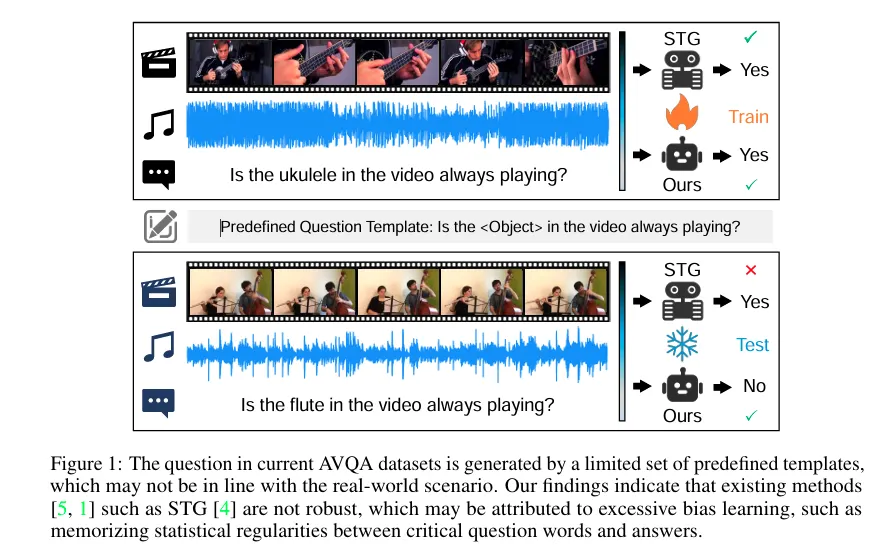
그림 1은 사전 정의된 템플릿을 사용해 생성된 훈련 및 테스트 샘플을 보여줍니다. 관찰되는 차이는 대체로 한 단어 변화에서 기인하며, 그 결과에 영향을 주는 어휘의 수가 93개로 매우 제한적인 상황입니다. 이러한 상황에서 기존의 편향 분석 방법론들은 changing answer distributions 즉 정답 분포의 불균형이 모델의 추론을 왜곡한다는 관점이 있습니다.
간단한 예시로 “Is the guitar playing?” → 대부분 yes 이러한 경우 모델은 실제 판단이 아닌 guitar가 들어가면 yes 라는 답변이 나오도록 통계를 학습하게 된다는 것입니다. 이는 현실 세계에서는 다양한 질문 상황과 괴리가 있을 수 있습니다. 또한 현재 데이터셋은 희귀하거나 드문 샘플에서의 성능을 반영하지 못하는데, 이는 강건성 평가의 중요한 지표가 될 수 있다고 합니다.
Q2: have existing methods overcome the data bias?
기존 방법들은 데이터 편향을 극복했는가?
STG 등의 기존 방법들은 희귀 정답이 포함된 질문에는 취약함을 발견했다고 합니다. 이를 저자는 ”is”, “Playing”, ”Yes” 와 같은 핵심 질문 단어와 정답 사이의 통계적 규칙성을 기억하기 때문일 수 있다고 언급합니다. 그러한 증거로 STG 모델은 MUSIC-AVQA 의 테스트 셋에서 질문 문장만 입력했을 때조차 54.09% 의 정확도를 보였기 때문입니다. 이는 멀티모달 추론 문제인 AVQA 태스크에서 질문만으로 절반을 맞춘 것으로 데이터셋 안에 언어적 패턴이 존재함을 뜻합니다.
저자의 논문에서는 첫 번째 질문을 정확히 해결하기 위해 새로운 데이터셋인 MUSIC-AVQA-R 을 제안하며 이 데이터셋은 기존 MUSIC-AVQA 를 보완하며 현존 AVQA 모델들의 성능을 보다 정밀하게 진단할 수 있다고 어필합니다. 내재된 편향을 유지하기 위해 원본 MUSIC-AVQA의 훈련 검증 분할은 그대로 사용하고 테스트 분할에서는 human-machine collaboration 매커니즘을 이용해서 질문을 재표현했다고 합니다.
이러한 방법으로 자연스럽고 다양한 질문 형식을 확보하면서, 질문수가 9129개에서 211572개로 대폭 확장되었고 특정 질문 유형의 정답 분포를 기준으로 분포 변화(distribution shfit) 를 도입했습니다. 이를 통해 in-distribution 데이터와 out-of-distribution 모두에서 성능을 동시에 측정할 수 있다고 합니다.
두 번째 질문을 해결하기 위해 multifaceted cycle collaborative debiasing(MCCD) 을 적용한 강건한 프레임워크를 제안합니다.
구체적으로는 해당 전략은 단일 모달 로짓과 멀티 모달 로짓 사이의 분포 차이를 확대하는 새로운 최적화 목표를 도입하는 것이라고 합니다. 이를 통해 모델은 개별 모달리티로부터 편향을 학습할 가능성이 줄어들게 됩니다. method 에서 좀 더 구체적으로 설명하겠습니다.
결과적으로 저자의 프레임워크는 두 데이터셋 모두에서 유의미한 향상을 보였고 특히 MUSIC-AVQA-R 에서 뚜렷한 개선이 관찰되었다고 합니다.
Related work
저자는 MUSIC-AVQA 데이터셋을 개편하기 위해 기존 QA 데이터셋들이 어떤 과정을 거치며 데이터셋이 발전되어왔는지를 언급합니다.
QA 데이터셋들은 주목할만한 성과가 있었음에도 데이터셋의 편향으로 인해 불완전한 평가 문제를 겪어왔고, 최근 몇 년간 다양한 관점에서 이 문제를 다루기 위한 수많은 연구가 이루어졌다고 합니다. 그중 한 방향은 기존 데이터셋을 재구성하여 훈련과 테스트 분할 간의 분포를 크게 다르게 혹은 역전시켜서 재구성된 데이터셋을 만들었고, 이는 OOD 상황에서의 성능을 반영하지만, ID 상황에서는 성능을 측정하지 못합니다.
이를 해결하기 위해 GQA-OOD 는 검증 및 테스트 분할 모두에 distribution shift를 도입하여 시각적 QA 모델의 ID/OOD 상황 성능을 동시에 평가할 수 있도록 했습니다. 그러나 이 데이터셋 또한 테스트 데이터에서 질문 수가 2796개에 불과하여 모델의 일반화 능력을 충분히 반영하지 못한다고 합니다.
적대적 공격에서도 영감을 받은 또 다른 연구 방향은 데이터셋 구성을 인간 어노테이터 vs 학습된 모델 간의 게임으로 간주한다고 합니다. 즉 모델을 성공적으로 공격 ( 모델이 틀리게 만듬 ) 한 인간이 생성한 샘플만 데이터셋에 포함시키는 방식입니다.
저자가 제안한 MUSIC-AVQA-R 은 위 연구들과 달리 질문 다양성을 우선시하면서도 테스트 샘플의 볼륨도 고려했다고 합니다. 이를 통해 강건성 평가의 정밀도와 포괄성을 모두 향상시킵니다.
저자는 MUSIC-AVQA-R 이 강건성 평가를 위해 명시적으로 설계된 최초의 AVQA 데이터셋임을 어필합니다.
Dataset Creation and Analysis
저자는 AVQA 모델의 강건성을 평가하기 위해 MUSIC-AVQA-R 을 제안했습니다. 이 데이터셋은 두 핵심 단계로 구성되는데 각각 Rephrasing, spliting 입니다. 전자는 MUSIC-AVQA 테스트 셋 질문을 재작성하는 과정이고, 후자는 질문을 frequent 여부와 rare 여부등으로 하위집합으로 나누는 과정입니다.
Rephrasing
기존 데이터셋의 질문들은 사전에 정의된 제한된 템플릿으로만 작성되어 다양성과 현실성을 높이기 위해 각 질문을 25회 재표현할 수 있는 tool 을 사용했다고 합니다.
재표현의 품질을 보장하기 위해 세명의 annotator 가 검증 과정에 참여했고 모두 information science senior 학생이라고 합니다. (학부생이라는 뜻이겠죠..)
두명의 검증자가 품질을 인정했을 경우에만 데이터셋에 포함되었으며 전체 재표현의 92.4%가 검증을 통과했다고 합니다.
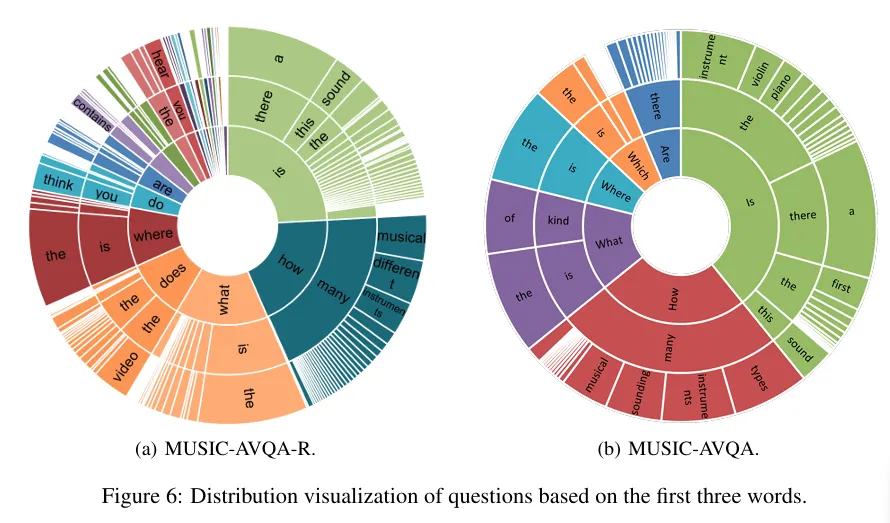
이는 재표현된 질문들의 첫 세 단어의 기준 분포입니다. 훨씬 다양하게 분포가 퍼졌으며 데이터셋의 어휘 크기 자체도 5배가량 커졌다고 합니다.

Splitting
AVQA 모델의 정확한 진단을 제공하기 위해 특정 질문 유형의 정답 분포를 기반으로 분포변화를 도입했다고 합니다.
이 분포를 바탕으로 재표현된 질문들을 head 와 tail 로 분류하여 ID / OOD 성능을 평가할 수 있게 했습니다. 또한 각 질문들을 Existential, Location, Counting, Comparative, Temporal 등 질문 유형별로 그룹화 했다고 합니다.
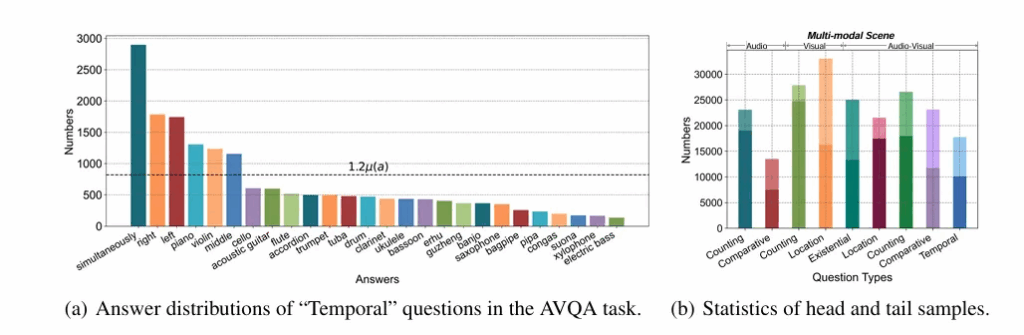
Figure 3 (a) 를 보면 AVQA 태스크 내 시간적 질문들의 정답 분포를 보여주며 long-tailed distribution 임을 확인할 수 있습니다. ( 다른 유형들은 appendix B에 존재합니다.)
(b) 를 확인하면 Head 와 tail 의 분포가 Audio, visual, Audio-visual 각각의 평가항목에 골고루 존재하여 데이터가 균형적으로 존재하지 않음을 보여줍니다. 이는 ID/OOD 를 평가하기에 적합합니다.
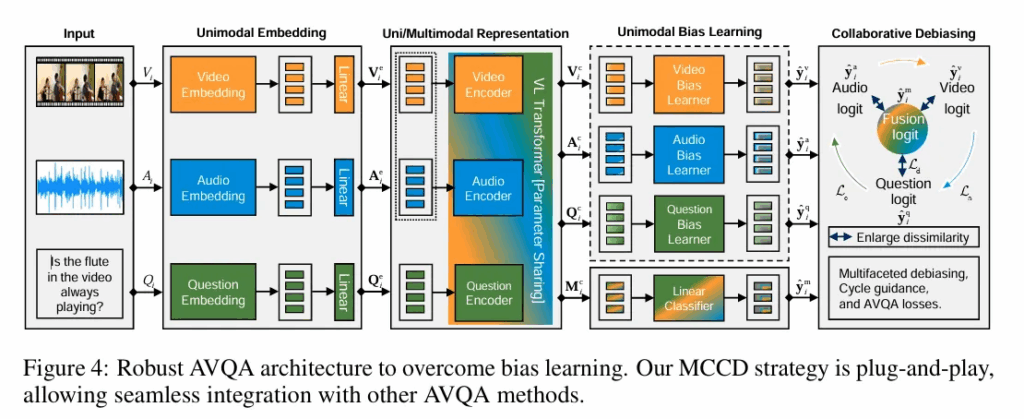
저자의 전체 모델 구조도입니다. 먼저 사전 학습된 모델을 이용해 단일 모달 및 멀티 모달 표현을 학습합니다.
그 다음 각 모달리티에 존재하는 편향을 포착하기 위해 별도의 bias learner를 활용합니다.
마지막으로 다중 모달 표현으로 얻은 fusion logit 과 단일 모달 표현으로 얻은 bias logit 사이의 차이를 확대하기 위해 collaborative debiasing strategy 를 적용합니다.
그러면서 cycle guidance 매커니즘을 통해 각 단일 모달 bias logit 간의 유사성을 유지한다고 합니다.
여기서 단일 모달 학습은 한 모달리티만을 입력으로 사용하여 각 모달이 단독으로 뭘 학습하는지 편향이 얼마나 심한지를 학습하는 것이며 멀티 모달은 모든 모달리티를 한번에 입력으로 넣어 실제 정답을 예측하는 최종 목적을 학습한다고 생각하면 됩니다.
Uni-modal Embedding
입력 샘플 = 비디오 시퀀스 + 질문 으로 구성됩니다. 각 비디오와 오디오를 1초 길이의 T개의 세그먼트로 구분합니다
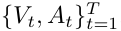
그 후 각 모달리티에 대해 별도의 임베딩 레이어를 사용하여 단일 모달들의 임베딩을 구합니다.
오디오 → VGGish 모델을 이용 (VGG 계열 오디오 처리 네트워크)
비디오 → 사전 학습된 ResNet-18 을 프레임에 적용하고 그 파라미터는 고정합니다.
질문 → VisualBert 를 활용하여 단어 수준의 질문 임베딩 벡터를 획득합니다.
차원을 맞추기 위해서 각각의 벡터에 별도의 선형 층을 적용하게 됩니다.
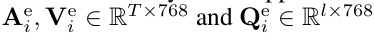
즉 Uni modal 에서 뽑았던 임베딩들 ( VGGish, ResNet, VisualBERT) 에서 생성된 애들을 다시 VisualBERT에 넣어 각 A,V,Q,M 의 벡터들을 생성한다고 생각하시면 됩니다.
다중 모달 학습의 경우에는 질문 임베딩을 쿼리로, 비디오 및 오디오 임베딩을 문맥으로 사용하여 결합합니다. 그 후 VisualBERT 를 활용하여 모달 간 상호작용을 수행합니다. 이후 선형 레이어를 하나 적용해서 multi-modality logit 을 얻게 됩니다.
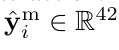
Uni-modal Bias Learning
AVQA 에는 오디오,비디오, 언어 각각의 유해한 단일 모달 편향이 존재할 수 있기 때문에 이러한 편향을 포착하기 위한 bias learner를 활용합니다. 구체적으로는 서로 다른 MLP 계층을 편향 학습기로 사용하고 이들은 각각 오디오, 비디오, 질문 모달리티의 입력으로부터 대응되는 로짓을 생성합니다.
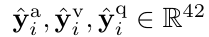
이러한 bias learner 들은 테스트 단계에서는 제거되고 훈련단계에서만 편향 학습을 보조하는 역할을 수행한다고 합니다.
Collaborative Debiasing
편향 학습을 제거하기 위해 저자는 Multifaceted cycle Collaborative Debiasing (MCCD) 전략을 제안합니다.
단일 모달과 다중 모달 로짓 간의 불일치를 확대한다고 합니다. 이를 위해 불일치 확대 손실을 만들고 역거리의 합으로 정의된다고 합니다.
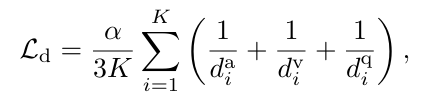
여기서 K 는 배치 사이즈이며, 알파는 밸런스 균형 계수입니다.
각 da, dv, dq 값들은 단일 모달과 다중 모달 로짓간의 유클리드 거리입니다.
직관적으로 단 하나의 모달리티 만으로 정답을 예측하려고 한다면
단일 모달 로짓 분포들이 서로 매우 유사해진다고 합니다.
따라서 MCDD는 단일 모달 로짓들의 분포를 제약하기위해 cycle guidance를 사용합니다.
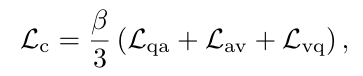
이러한 순환 유도 손실은 KL divergence을 기반으로 정의된다고합니다. 여기서 베타는 가중치를 조절하는 계수이며 각 Lqa, Lav, Lvq 는 각 모달리티별 상대 엔트로피입니다.
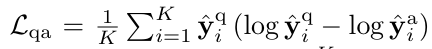
마지막으로 La 라는 답변에 대한 예측 손실을 합산하여 모델의 파라미터들을 최적화합니다.
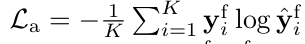
여기서 yi 와 y^i 는 다중 모달에 대한 로짓에 대한 원 핫 정답 레이블과 예측 로짓을 의미합니다.
Dataset and Evaluation
MUSIC-AVQA 데이터셋은 9288개의 음악 공연 비디오로부터 질문을 수집하여 개발되었으며 비디오는 유튜브에서 수집되었다고 합니다. 각각 단일악기, 동일 악기의 앙상블, 서로 다른 악기의 앙상블을 포함합니다.
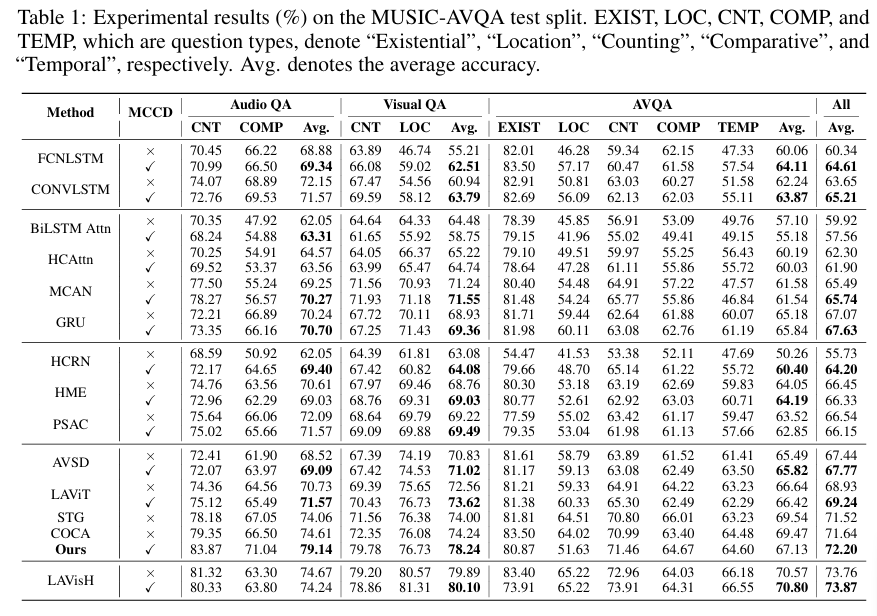
기존의 MUSIC-AVQA test 로 평가한 Table 이며 저자의 MCCD 방법론을 추가하면 전반적으로 성능이 향상됨을 알 수 있습니다.
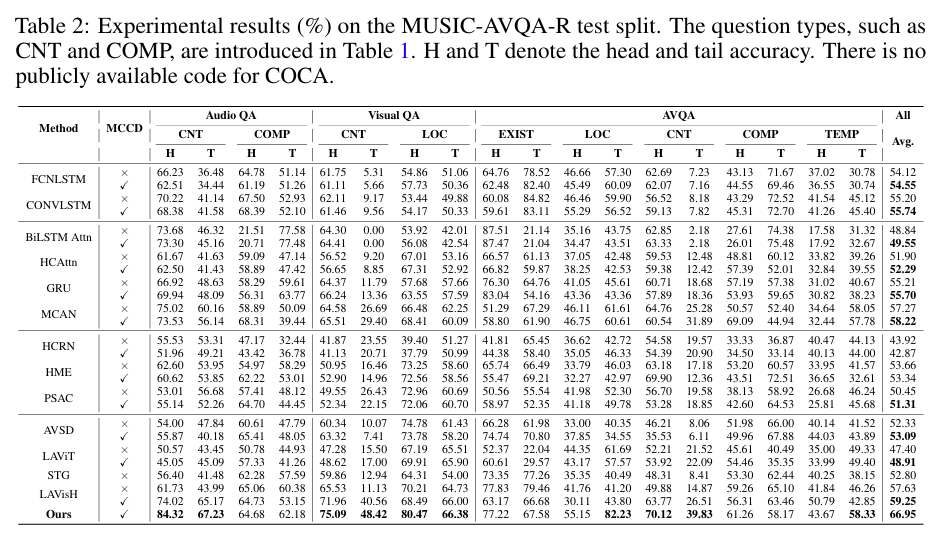
Table2는 저자의 데이터셋에서 평가한 지표입니다. 대부분의 모델이 Tail 성능이 급락하는 경향이지만 MCCD 를 적용하면 Head에서의 과적합이 줄고 Tail 에서의 성능이 보장되어 강건성이 올라간다고 합니다.
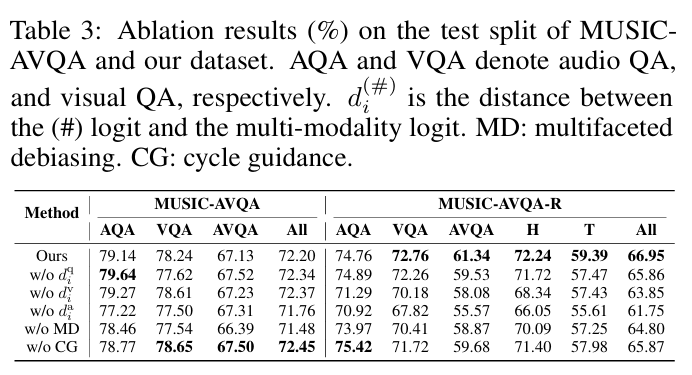
해당 표는 ablation으로 loss항에서 단일 모달 vs 멀티 모달의 거리항을 제거했을때 multifaceted debiasing 을 제거했을때 그리고 cycle guidance를 제거했을때의 성능으로 기존 데이터셋에서는 크게 변화가 없지만 저자가 제안한 논문에서는 각 method를 제거하면 전반적으로 성능이 하락함을 알 수 있습니다.
Conclusion
저자는 AVQA 과제에서 편향학습을 모델 평가와 설계에서 처음으로 탐구했습니다. 새로운 데이터셋인 MUSIC-AVQA-R 을 구축하고 head 와 tail 그리고 전체 질문에서의 성능을 평가함으로써 모델의 강건성을 평가하여 그 contribution이 있습니다. 저자가 제안한 MCCD 방법들이 다른 모델들에도 쉽게 적용될 수 있으며 저자가 제안한 새로운 데이터셋으로 기존 방법론들을 평가했을때 성능이 낮아짐으로 강건성이 낮고 bias 에 쉽게 영향을 받는다는 것도 밝혀냈습니다.
다만 MUSIC-AVQA 의 구조적 제약으로 저자의 데이터셋도 정답 클래스가 42개로 제한되며 답변의 길이 또한 대부분 한 단어라는 제약이 존재합니다. 이는 실제 현실에서의 복잡한 QA와는 약간의 거리가 있음을 밝히고 있습니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
AVQA데이터셋의 splitting 방식에 대해 궁금한 점이 있습니다. 리뷰에서는 질문을 head와 tail로 나누어 ID/OOD 성능을 평가했다고 되어 있는데, 이때 구분 기준이 정답의 빈도인지, 아니면 질문 유형별 빈도에 따른 것인지 헷갈려 여쭤봅니다. 제가 이해를 잘 못해서 질문한 것일 수 도 있는데, 질문 유형의 정답 분포를 기반으로 분포변화를 도입했다고 나와있지만 또 뒤에는 각 질문들을 유형별로 그룹화 했다고 나와있어서 헷갈리는 것 같습니다. 데이터셋 splitting 방식에 대해서 좀더 자세히 설명해주시면 감사하겠습니다!
감사합니다.
안녕하세요 우현님 답글 감사합니다.
데이터를 split 한 기준은 질문 유형별 정답의 빈도라고 생각하시면 됩니다.
질문의 유형이 답으로 나올 수 있는 유형들로 정해져있는데, (ex. count, temporal .. ) 해당 답변에서 주로 나오는 답변을 분포로 보여주고, 해당 분포에서 평균개수의 1.2배를 기준으로 head 와 tail 로 나누게 됩니다.
감사합니다.
안녕하세요 인택님, 리뷰 잘 읽었습니다. AVQA task에 대해 조금이나마 알아갈 수 있는(?) 시간이었던 것 같습니다. 정말 간단한 질문 두 가지만 드리려고 합니다!
– introduction의 Q2:have existing methods overcome the data bias? 파트 중 STG 모델은
MUSIC-AVQA의 테스트 셋에서 질문 문장만 입력했을 때조차 54%의 정확도를 보였다고 했는데,
질문 문장만 입력했다는게 예를 들어”is playing?”만 입력해도 절반은 맞추는 결과를 얻었다는 뜻인가요?
– 기존의 사전 정의된 템플릿으로 학습을 시킨다면, 그 학습시킨 형태와 비슷한 질문에 대해서만 잘 대답을 할 것이고, 이러한 문제를 해결하기 위해 rephrasing을 적용했다고 이해하면 될까요?
안녕하세요 재윤님 답글 감사합니다.
우선 “is playing” 이라는 질문이 있는지는 모르겠으나 전체 질문 문장을 모델에 입력으로 줬을때, video, audio 에 대한 입력 없어도 기존에 존재하는 데이터 train test 분포의 특징만을 학습하여 그정도 성능이 나왔다는 것으로 이해하면 될 것 같습니다. 그리고 이러한 문제를 해결하기 위해서 rephrasing을 했다기보다 train val set 은 기존 데이터셋과 동일하게 두되, test 셋만 rephrasing 하여 학습때 bias를 학습하게되면 test 셋에서 성능이 급격하게 떨어지게 데이터셋을 구축하였다고 생각히시면 됩니다. 즉 질문 2에서 물어봤던 bias 자체를 데이터셋에서 없애기보다, 존재하게 두되 그걸 모델이 극복할 수 있는 모델인지를 검증하기 위한 MUSIC-AVQA-R (Robust) 를 만들었다고 이해하면 될 것 같습니다.
감사합니다.