안녕하세요. 이번에 소개드릴 논문은 Visual Navigation 분야의 연구로 ICRA 2023에 게재된 GNM: A General Navigation Model to Drive Any Robot 입니다. Visual Navigation 분야는 저에게 아직 낯선 영역이라 이번 논문을 이해하고 리뷰로 정리하는 과정이 쉽지 않았습니다. 논문 분량이 약 6페이지 정도로 길지는 않지만 하루 종일 붙잡고 읽어도 내용의 흐름을 따라가는 데 꽤 많은 시간이 걸렸습니다. 그만큼 논문 속의 개념들이 단순히 읽는 것만으로는 잘 와닿지 않았고 2000년 초반에 나온 잘 정리된 서베이 논문들을 통해 간단한 개념들을 스스로 정리하면서 읽으니깐 그나마 아주 조금씩 감이 잡히기 시작한 것 같습니다. 처음 접하는 개념들이 많아 이해에 어려움이 있어서 바텀업 방식으로 Visual Navigation관련 논문을 읽을까 하다가 이 논문부터 타고 타고 탑다운 방식으로 공부해도 괜찮을 것 같아서 바로 해당 논문을 읽게 되었습니다. 아직 제가 완벽히 이해하지 못한 부분도 있을 수 있습니다. 혹시 리뷰를 읽는 과정에서 잘못된 내용이나 보완이 필요한 부분이 보인다면 댓글로 피드백을 주시면 감사하겠습니다.
바로 리뷰 시작하도록 하겠습니다.
Introduction

해당 논문은 로봇에도 CLIP 같은 범용 모델이 가능할까? 라는 질문에서 출발합니다. 현재 NLP나 컴퓨터 비전 분야에서는 이미 대규모 데이터 셋으로 학습된 모델들이 좋은 일반화 능력을 보여주고 있습니다. 이런 일반화 성능은 대체로 한번 수집된 뒤 여러 목적으로 재사용되는 다양한 데이터셋으로부터 일반적인 패턴을 학습하기 때문에 가능합니다. 그래서 대규모 모델들은 이런 일반적인 데이터셋에서 학습된 표현을 재사용해서 새로운 태스크에 대해 파인튜닝이 가능하고 혹은 zero shot 전이가 가능하게 됩니다. 그런데 이런 접근이 로보틱스 분야에서는 잘 안 통한다는 게 저자들의 문제의식입니다. 이유는 로봇 연구는 각자 사용하는 환경과 플랫폼이 너무 다양하기 때문에 하나의 거대한 통합 데이터셋을 만들기 어렵기 때문이라고 합니다. 보통 end-to-end 방식으로 학습되는 로봇 제어 정책 같은 경우에는 로봇마다 센서 구성이나 움직임 특성이 다르기 때문에 새로운 로봇을 학습하기 위해서는 해당 로봇에 맞는 매번 새로운 데이터 수집이 필요한데 결국 이것이 연구자마다 자기들만의 로봇용 데이터만 가지고 실험하게 되고 전체적으로 봤을 때 로봇 연구가 파편화된다라는 문제를 언급합니다. 그래서 저자들은 이런 문제를 언급하면서 만약 로봇 간에 공유 가능한 일반적 데이터셋을 만들고 그걸 기반으로 모델을 학습한다면 다양하고 새로운 로봇에도 쓸 수 있는 내비게이션 정책을 만들 수 있지 않을까? 라는 질문을 던집니다. 그럼 여기서 중요한 건 로봇 간 이질성을 어떻게 다루느냐입니다.예를즐어 이질성이라고 하면면 로봇에 달린 카메라 하드웨어가 무엇인지, 뷰 포인트, 로봇의 물리적 형태적 특성 등등 이 있습니다. 여기서 저자들은 그 차이를 인정하되, 그 안에 존재하는 공통된 추상적 구조를 활용하고자 합니다. 예를 들어 바퀴형 로봇, 사족보행 로봇, 드론은 생김새도 다르고 움직임도 다르지만 결국 모두 환경을 탐색하고 -> 목표로 가고 -> 충돌을 피한다는 동일한 추상적인 목표를 가지고 있습니다. 이처럼 로봇 간에 가지는 공통된 추상적인 구조를 활용하고 대규모 데이터를 통해 내비게이션 정책을 학습한다면 다양하고 새로운 로봇 구조에도 폭넓게 일반화 할 수 있을 것이다라고 저자는 언급하면서 GNM이라는 General Navigation Model을 제안하고 이를 여러 로봇으로부터 수집한 통합 데이터 셋으로 학습을 하게 됩니다. 그래서 결국 해당 논문은 다수의 로봇 데이터셋으로부터 단일 일반 정책을 학습할 수 있는 프레임워크를 제시하고 이 정책이 다양한 이질적인 데이터셋으로부터 효과적으로 학습하고 새로운 로봇 플랫폼으로 일반화 할 수 있음을 보여준다라고 보시면 좋을 것 같습니다. 학습은 여러 로봇에서 수집한 멀티로봇 데이터셋으로 학습됩니다. 총 6대의 로봇에서 약 60시간의 실내·실외 주행 데이터를 수집해서 GNM을 학습하고, 이를 4종의 서로 다른 로봇에서 실험을 진행합니다. (그 중에 2종은 학습데이터에 한번도 등장하지 않은 신규로봇임)
이어서 데이터셋에 대해서 자세하게 설명드리도록 하겠습니다.
Multi Robot Training Dataset
GNM의 목표는 단순히 특정 로봇을 잘 조종하는 게 아니라 로봇이라면 누구나 공통적으로 학습해야 하는navigational affordance를 일반화된 형태로 학습하는 것입니다. 그래서 저자들은 동역학, 센서 구성, 행동 특성이 제각각인 여러 로봇에서 얻은 데이터를 모았습니다.
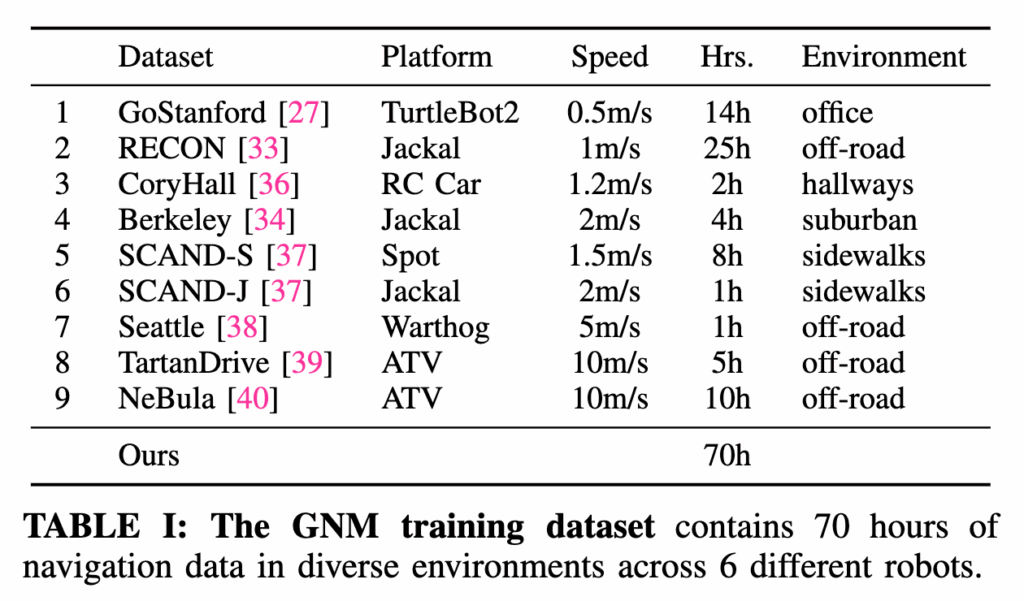
위 표처럼 총 9개의 서로 다른 내비게이션 데이터셋을 합쳐서 이질적인 내비게이션 주행 데이터셋을 구축합니다. 이 데이터셋은 실내 복도나 사무실 같은 구조화된 공간뿐만 아니라 캠퍼스, 오프로드 같은 거칠고 예측하기 어려운 환경까지 포함하고 있습니다. 어떻게 보면 학습 데이터 자체가 이미 다양한 로봇 + 다양한 환경 조합으로 구성되어 있는 셈입니다. 데이터 규모도 꽤 큽니다. 총 70시간의 실제주행 데이터가 포함되어 있고 여기에는 사람이 원격으로 조종한 수동 주행한 데이터와 로봇이 스스로 이동한 자율 주행 데이터가 모두 들어 있다고 합니다. 사용된 로봇은 총 6종이고 그중 4종은 상용 플랫폼이고 나머지 2종은 커스텀 제작된 로봇이라고 합니다.
- 상용 로봇: TurtleBot, Clearpath Jackal, Warthog, Spot
- 커스텀 로봇: Yamaha Viking ATV, RC Car
바퀴 달린 로봇부터 사족보행 로봇, ATV(전지형 차량)까지 폭넓은 범위의 플랫폼을 다루는 것을 보실 수 있습니다.속도도 다양해서느린 TurtleBot은 시속 0.2m/s 수준이고 빠른 ATV는 10m/s까지 달릴 수 있습니다. 한 종류의 로봇 + 한 환경이라는 제약을 완전히 벗어난 데이터셋이라는 점이 GNM의 핵심 기반이라고 보시면 될 것 같습니다.
그리고 비전 기반 내비게이션 정책을 학습하기 위해서 모든 데이터는 자기중심적 시점에서 수집된 전방 RGB 영상이랑 이에 대응하는 로봇의 명령 + 로컬 오도메트리 정보를 함께 포함합니다. 이 데이터만 가지고도 로봇의 행동을 이미지 입력만으로 재현할 수 있도록 합니다. 그리고 로봇마다 카메라의 위치나 시야각, 초점거리 등 카메라 파라미터가 다르기 때문에 이러한 다양한 데이터 셋으로 모델이 이런 변화를 일반화할 수 있다는 장점이 있습니다. (단, 모든 플랫폼의 센서는 단안 RGB 카메라)
그리고 저자는 이런 GNM 데이터셋이 확장성이 좋다고합니다. 원한다면 새로운 내비게이션 데이터셋을 추가로 섞을 수도 있고 혹은 특정 응용 목적에 맞게 일부 subset만 골라서 사용할 수도 있습니다.
결국 GNM은 단일 로봇을 위한 데이터가 아니라 여러 로봇에서 다양하게 수집한 데이터셋 위에서 학습된다는 점이 중요합니다. 그럼 해당 데이터 셋을 어떻게 학습을 해야 로봇간 일반화가 가능한 학습이 이루어질 수 있는지에 대해서 설명하도록 하겠습니다.
TRAINING A GENERAL NAVIGATION MODEL
해당 파트에 대해서는 완벽하게 이해하지 못한 부분이 있어서 설명이 매끄럽지 않을 수 있습니다.. 감안하시고 읽어주시면 감사하겠습니다.
일단 이 부분은 본격적으로 GNM이 어떤 방식으로 학습되는지 즉, 여러 로봇의 데이터를 가지고 어떻게 하나의 공통 정책을 학습할 수 있는가에 대한 핵심 설계를 설명하는 부분입니다.
저자들은 우선 실험의 기반이 되는 과제를 Image-Goal Navigation이라고 정의합니다. 이건 이름 그대로, 목표 위치에서 찍힌 이미지를 목표로 삼고, 현재 위치의 이미지를 가지고 에서 그 목표에 해당하는 이미지 지점까지 이동하는 과제라고 보시면 될 것 같습니다. 로봇은 이 이미지를 찍은 곳까지 가라는 형태의 목표를 받게 됩니다.
여기서 중요한 건 이 방식이 좌표 기반의 내비게이션(PointGoal)이나 GPS, semantic label에 의존하지 않는다는 점입니다. 따라서 절대 위치 정보 없이, 오직 단순하게 시각 정보만으로 학습할 수 있다는 것이 특징입니다.
논문에는 정리되어있지 않지만 각각 내비게이션 방식들에 대해서 언급하고 넘어가자면 먼저 PointGoal navigation은 목표가 좌표값(x, y) 형태로 주어지는 방식입니다. 예를 들어, 로봇에게 현재 위치에서 (3.5m, 2.0m) 떨어진 곳으로 이동하라라고 명령하는 식으로 동작합니다. 이 경우에는 로봇은 자신이 현재 어디 위치에 있는지 절대적인 위치를 알아야 하고 보통은 SLAM이나 사전에 데이터베이스게 구축된 지도 정보를 이용해 현재 위치와 목표까지의 상대적인 방향을 계산해야 합니다. 비슷한 개념으로 GPS navigation도 있는데 이것도 비슷하게 GPS정보를 직접 사용해 경로를 계산하는데 마찬가지로 숫자 기반의 절대 위치 목표를 사용한다는 점에서 PointGoal과 유사합니다. 둘 다 위치좌표를 알아야 하기 때문에 환경 변화나 GPS 신호가 약한 상황에서는 일반화가 어렵다는 문제가 있습니다. 반면에 Semantic navigation은 좌표 대신 의미(semantic label)로 목표를 지정합니다. 예를 들어 의자를 찾아라 또는 창문 근처로 가라 같은 명령을 주는데 이 과정에서 목표를 인식하기 위해 semantic segmentation이나 object detection이 필수적이고 결국 사전에 정의된 semantic label에 의존하게 됩니다. 이것도 마찬가지로 새로운 환경에서 등장한 객체나 장면은 인식하지 못한다는 한계가 있습니다.
이와 다르게 Image-Goal navigation은 훨씬 단순하면서도 일반화하기에 좋은 접근입니다. 여기서는 목표가 좌표나 라벨이 아니라 그 장소의 이미지 자체로 주어지는데 예를 들어 이 사진이 찍힌 위치로 가라라는 식으로 동작하고 로봇은 현재 카메라 영상(o_t)과 목표 이미지(o_G)를 비교하면서 지금 내가 보는 장면이 목표에 얼마나 가까운가를 학습하게 됩니다. 결국 이 방식은 지도나 위치 정보 없이 수행되는 오직 시각 정보만으로 학습 가능한 general framework라는 특징을 갖습니다. 중요한 건 이렇게 이미지 자체를 목표를 삼는 네비게이션 방식을 해당 논문이 제안한 것은 아니고 일반화할 수 있도록 학습하기 위해서 이를 기반으로 프레임워크를 구축했다라고 이해하시면 좋을 것 같습니다.
결국 위와 같은 방식의 접근은 어떤 데이터셋이든 이미지 + 로봇 행동 형태로만 되어 있다면 그걸 그대로 학습에 쓸 수 있다는 장점이 있습니다.
그래서 결국 GNM이 하려는 일은 간단하게 말하자면 로봇의 현재 시점 이미지(o_t)와 목표 이미지(o_G)를 입력받아서 목표로 가는 행동을 예측하는 정책 π(o_t, o_G)를 학습하는 것 입니다. 이 정책은 자기중심적 시각 정보만을 사용하고 로봇이 지금 보고 있는 화면과 가야 할 위치의 화면만으로 길을 찾아야 합니다.
근데 서두에 말한 문제처럼 로봇마다 제어 방식,동역학,센서 위치가 모두 다르기 때문에 이런 정책을 여러 로봇에 동시에 적용하려면 문제가 생기게 됩니다. 그래서 저자들은 멀티로봇 학습에서 꼭 필요한 두 가지 핵심 설계 포인트를 제시합니다.
- 공통 행동 표현(Action Representation) 설계
로봇마다 명령 형태가 제각각이라면 예를 들어 어떤 로봇은 선속도,각속도 명령을 받지만, 다른 로봇은 조향각과 스로틀 값을 받게 되는 경우 하나의 정책이 그 차이들을 학습하기 어렵습니다. 그래서 GNM은 이런 차이를 없애고 모든 로봇이 공통적으로 이해할 수 있는 행동 표현을 설계합니다. 이거를 논문에서는 공유된 추상화라고 표현하는데 각 로봇의 실제 제어 명령은 달라도 정책이 작동하는 행동 공간은 공통된 형태로 바꾸는 것이라고 합니다. 따라서 저자는 이를 위해 중간 수준 행동 공간(mid-level action space)을 정의합니다. 정책은 저수준 제어 명령(속도나 조향각)을 직접 내보내는 대신에 로봇의 오도메트리 정보를 통해 쉽게 계산할 수 있고 데이터셋마다 일관된 형식으로 만들 수 있는 상대적인 이동 경유점(relative waypoint)과 yaw 변화량을 예측하도록 합니다. 그리고 현재이미지와 목표이미지가 얼마나 멀리 떨어진 위치인지를 판단할 기준이 필요하기 때문에 목표까지의 시간 거리(d)도 함께 예측을 하게 됩니다. 즉 로봇별 데이터를 같은 표현으로 보이게 만들어서 정책이 공통된 패턴을 훨씬 쉽게 학습하도록 설계한 것이라고 보시면 좋을 것 같습니다. 따라서 로봇 종류에 상관없이 일관된 행동 공간에서 학습이 가능하게 됩니다. 그 다음 로봇마다 최고 속도나 기동성이 다르기 때문에 각 로봇의 최고 속도를 α로 두고 waypoint를 p^ = (1/α)p 형태로 스케일링해서 모든 로봇이 동일한 속도 단위에서 비교 될 수 있도록 맞춰줍니다. 이렇게 하면 모델은 빠르거나 느린 로봇을 따로 구분하지 않고 행동 패턴 자체를 학습하게 됩니다. 그 다음 실제 실행할 때에는 GNM은 정규화된 행동(waypoint + yaw)을 출력하고 각 로봇의 하위 제어기가 이를 실제 동작으로 변환합니다. 즉, 정책은 정규화된 추상 행동을 내보내고 로봇의 하위 제어기가 그걸 unnormalize해서 자신에게 맞는 속도나 명령으로 바꾸는 구조라고 보시면 좋을 것 것 같습니다. 결과적으로 GNM은 로봇별 저수준 제어를 직접 학습하지 않고 모든 로봇이 공통적으로 이해할 수 있는 중간 표현만 학습하는 모델이라고 볼 수 있습니다. - 로봇 특성(Embodiment) 정보의 요약 벡터 제공
정책이 실제로 새로운 로봇 위에서 돌아가려면 내가 지금 어떤 로봇을 제어하고 있는가를 어느 정도 인식해야 합니다. 예를 들어, TurtleBot은 제자리 회전이 가능하지만 조그만 요철에도 멈춥니다. 반면 RC Car는 작은 요철은 넘을 수 있지만 급회전은 거의 불가능합니다. 이 두 로봇에게 동일한 waypoint를 주면 당연히 결과가 달라지게됩니다. 따라서 정책이 이런 차이를 전혀 모르고 행동한다면 제대로 된 제어는 불가능하게 됩니다. 그래서 저자들은 로봇이 최근에 본 이미지 시퀀스를 보고 스스로 특성을 추론하게 하자라는 아이디어를 도입합니다. 즉, 로봇의 카메라가 과거 k개의 프레임을 연속으로 관찰했다고 할 때 이 시각 정보를 압축해 하나의 Embodiment 컨텍스트(Cₜ)로 만듭니다. 이 벡터에는 로봇의 구동 특성, 속도, 회전 반경, 시야 높이 등 시각적으로 추론 가능한 물리적 특징들이 자연스럽게 포함됩니다. 정책은 이 컨텍스트를 입력으로 함께 받아서 자신이 지금 제어 중인 로봇의 특성에 맞는 행동을 하도록 스스로 조정하도록 합니다. 저자들은 다양한 컨텍스트 구성 방식을 실험적으로 비교했는데 그중 가장 효과적인 방법은 시간적으로 연속된 k개의 과거 관찰값을 사용하는게 가장 좋았다고 합니다.
위 부분에 대해서 GNM이 실제로 어떻게 학습되고 또 어떤 구조로 동작하는지를 구체적으로 설명을 드리도록하겠습니다.
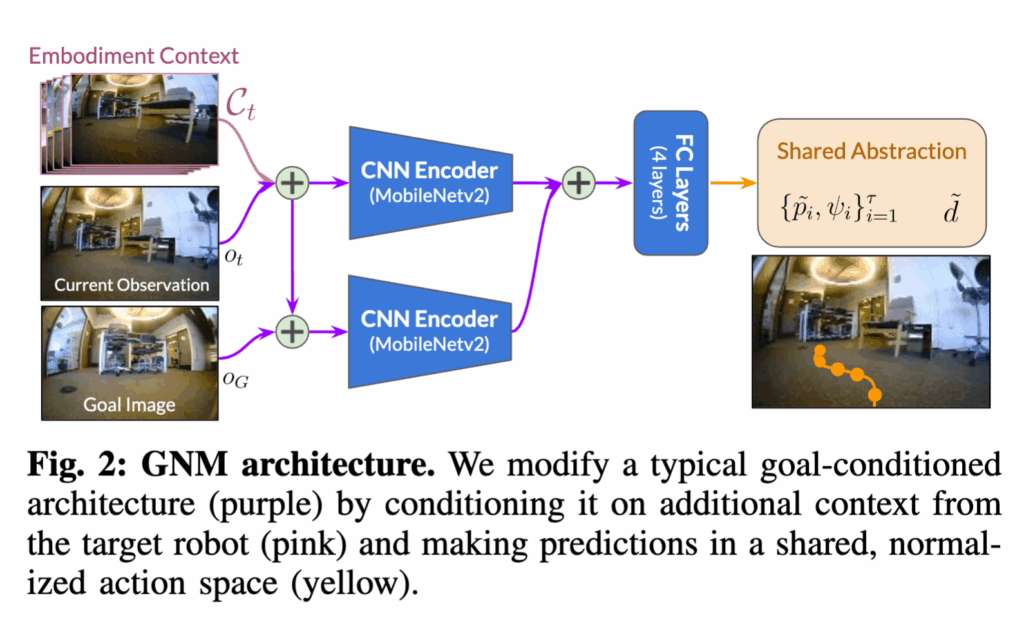
먼저 모델 구조를 보시면 입력은 현재 이미지(o_t)와 목표 이미지(o_G), 그리고 과거 5개의 연속 프레임(Cₜ)이며고
출력은 정규화된 경유점(waypoints)과 목표까지의 시간 거리(temporal distance)입니다.
즉, 지금 보고 있는 장면과 목표 이미지를 비교하면서 다음에 어디로 가야 할지와 얼마나 남았는지를 동시에 예측하는 구조라고 보시면 됩니다. 입력 영상은 85×64 RGB 크기로 통일되어 있고 시각 특징 추출을 위해 두 개의 MobileNetV2 인코더를 사용합니다. 하나는 현재 시점 이미지 + 컨텍스트용, 다른 하나는 목표 이미지용입니다.두 인코더의 출력 임베딩을 이어 붙인 후에 세 개의 FC layers를 통과시키면 waypoints, 목표까지의 시간 거리 두 가지 출력을 동시에 얻게 됩니다. 전체 학습은 L2 회귀 손실을 사용하는 방식으로 진행됩니다.
GNM이 학습이 끝나면 지금 내가 보고 있는 장면(o_t)과 목표 장면(o_G)을 입력받아 다음 어디로 가야 하는지를 예측할 수 있는 정책이 됩니다. 그런데 현실에서는 현재 위치에서 목표까지 한 번에 바로 이동하는 것은 불 가능합니다. 왜냐면 중간에 벽이 있을 수도 있고 복잡한 복도 구조나 여러 갈림길이 있을 수도 있습니다. 그래서 GNM은 한 번에 마로 목표까지 가는 게 아니라 중간 경유지(subgoal)를 단계적으로 밟아가자는 방식을 사용합니다. 이걸 가능하게 하는 구조가 바로 위상 그래프(Topological Map)라고 보시면 좋을 것 같습니다. GNM은 학습 단계에서 두 이미지(o₁, o₂)가 서로 얼마나 이동 가능한 관계인가(멀리 떨어져있는가)를 시간 거리로 학습했고 그래서 GNM은 이 이미지에서 저 이미지로 갈 수 있다면 위상그래프에서 노드간 연결(엣지 생성)하고 너무 멀어서 갈 수 없다면 연결 안 하는 방식으로 수많은 이미지들(로봇의 과거 관찰들)을 노드로 하고 그 사이의 연결 관계(이동 가능성)를 엣지(간선)로 만든 그래프를 구성할 수 있습니다. 그래서 실제로 데이터셋의 주행 trajectory로 부터 이미지-목표 쌍을 생성하는데 이때 postive 쌍, negative 쌍을 구성합니다. positive 쌍 같은 경우에는 같은 주행 trajectory에서 추출된 (o_t,o_G)쌍 즉, 실제로 토폴로지 그래프에서 연결된 위치쌍이 되는 것이고 target 시간 거리 값은 작게 설정이됩니다. 서로 다른 주행 trajectory에서 추출된 (o_t,o_G)쌍은 negative 쌍으로 target 시간 거리 값은 엄청 크게 설정이 되고 토폴로지 그래프에서는 연결되지 않은 위치쌍으로 어떤 지점을 경유해서 가야하도록 학습이 됩니다. (target 시간거리는 특정 임계 값에 따라 그래프 연결할지 말지 임계값으로 튜닝할 수 있음, 임계값이 작아지면 그래프가 조밀해짐) 결과적으로 GNM의 예측을 바탕으로 토폴로지 맵을 생성하고 이를 실제 운용과정에서 사용하게 됩니다. 앞서 언급한 내용은 GNM이라는 논문에는 자세하게 나와있지는 않고 VING라는 논문에 자세하게 나와있어서 해당 논문을 읽고 자세하게 리뷰를 하려고 했으나 아직 이해하는데 한계가 있어서 일단 최대한 이해한 수준에서 작성한점 양해 부탁드립니다..하하
그래서 실제 로봇이 움직일 때 로봇이 현재 시점 → 목표 장면까지 가는 과정을 설명드리자면 일단 처음으로 현재 위치와 목표를 토폴로자 그래프에 매칭을 합니다 로봇은 지금 카메라로 본 장면(o_t)이 그래프의 어떤 노드(이미지)와 가장 비슷한지를 찾습니다. 또 목표 이미지(o_G)도 그래프의 어떤 노드에 가장 비슷한지를 찾습니다. 만약 내 현재 위치는 그래프의 A 노드 근처고, 목표는 F 노드 근처라면시작점과 도착점을 그래프 위에 매핑합니다. 이제 A에서 F까지 가야 하는데 두 노드가 한번에 연결된 것이 아니라면 결국 그 사이에 어떤 노드를 경유해야합니다 이과정애서 대부분 알고리즘 수업이나 코테 시험 준비를 했다면 한번쯤은 봤을 Dijkstra 알고리즘으로 최적의 중간 경로를 찾게 됩니다. 그래프 상에서 가장 이동 가능성이 높은 경로(= 시간 거리가 최소인 경로)를 찾아야 합니다. Dijkstra 알고리즘을 통해서 찾으면 로봇은 A -> B -> C -> D -> F처럼 중간 경유지(subgoal) 경로를 얻을 수 있게 됩니다. 그 다음 정책(π)에 현재 장면과 하위 목표(subgoal) 입력하게 되면 로봇은 이제 현재 장면(o_t)과 바로 다음으로 가야 할 subgoal 장면(s₁) GNM 정책에 입력하게 됩니다. GNM은 이 두 이미지를 비교하고 이 subgoal까지 가려면 앞으로 1m 가고, 오른쪽으로 15도 회전해라 같은 정규화된 waypoint 시퀀스를 예측합니다. 즉, 당장 다음 단계에서 어떻게 움직여야 하는지를 알려주는 역할이에요. 그다음 또 B -> C까지 다시 GNM에 태우고 정규화된 waypoint를 예측하고 해서 총 4번 수행하여 F까지 도달하게 됩니다. 근데 이과정 사이에서 GNM이 예측한 waypoint는 일종의 정규화된 계획된 이동 경로일 뿐이지 이건 실제 모터 명령이 아닙니다. (공통 행동 표현-로봇 간 공유된 추상화임) 그래서 각 로봇의 하위 제어기 예를 들어 PID 제어기나 MPPI 제어기가 이 waypoint를 실제 로봇에 맞게 로봇 속도나 조향각으로 변환합니다.
정리하면 GNM은 현재 장면에서 목표 장면까지 직접 가는 게 아니라, 그래프 상에서 중간 subgoal들을 찾아가며 이동하는 방식으로 동작합니다. 여기서 GNM은 로컬(근거리) 제어를 담당하고 그래프는 전역(장거리) 경로를 관리하기 때문에 이 둘이 결합된 하이브리드 내비게이션 구조라고 보시면 좋을 것 같습니다.
DEPLOYING THE GNM ACROSS ROBOTS
이번 섹션은 학습된 GNM을 실제 다양한 로봇 위에 얹어서 실험했을 때 이 모델이 정말로 로봇에 구애받지 않고 일반화할 수 있는가를 검증하는 실험 부분입니다.
핵심적으로는 네 가지 질문(Q1~Q4)에 대한 답을 찾는 방식으로 구성되어 있습니다.
Q1.여러 로봇에서의 제로샷 일반화

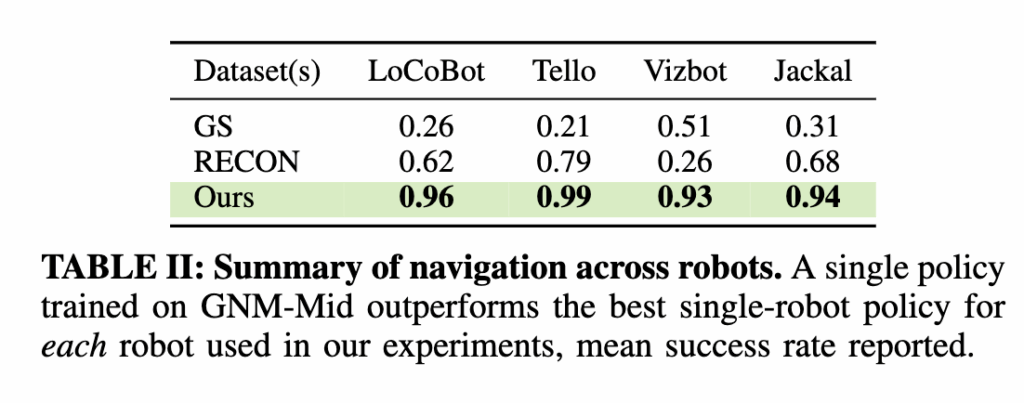
저자들은 하나의 동일한 GNM 모델을 추가 학습(finetuning) 없이 Vizbot, LoCoBot, Clearpath Jackal, DJI Tello(드론) 등총 4종의 완전히 다른 로봇 플랫폼 위에서 바로 실험했습니다. 결과적으로 표를 보시면 GNM이 드론(Tello) 같은 전혀 다른 구동 구조를 가진 로봇에서도 비행 데이터를 학습하지 않았음에도 불구하고 내비게이션을 수행했음 보입니다. 그리고 모든 로봇에서 싱글 로봇 정책보다 더 높은 성공률을 보입니다.
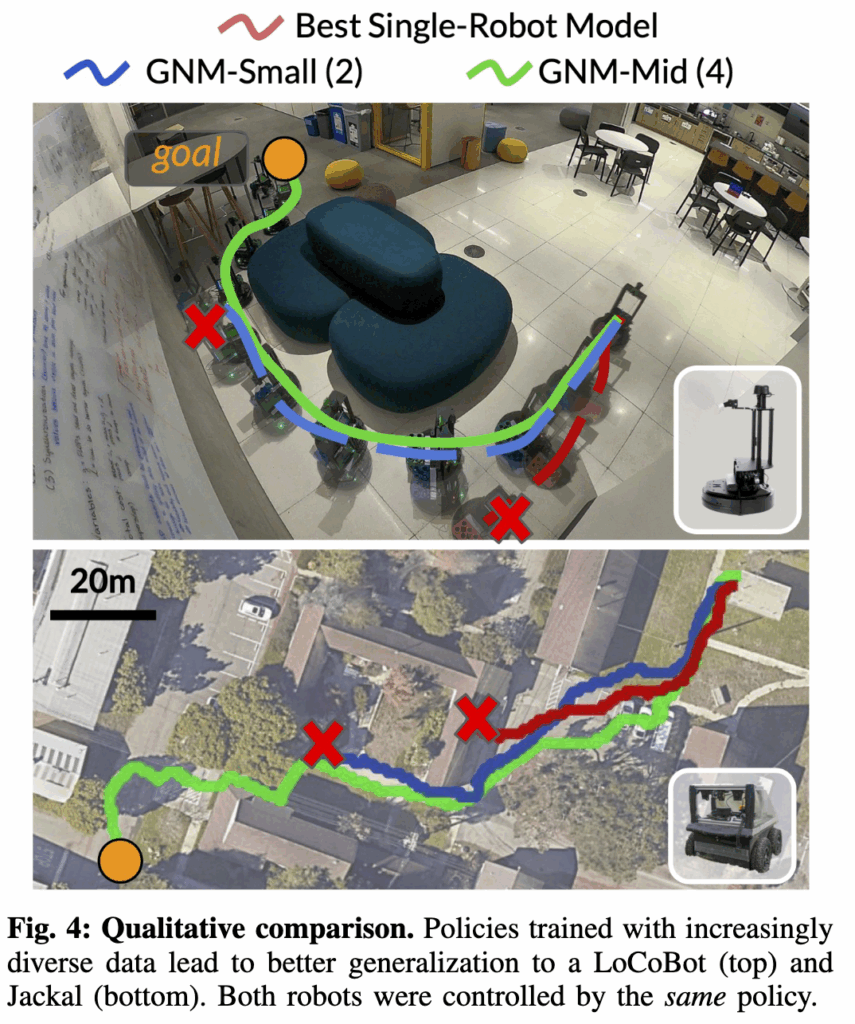
또 GNM이 학습 데이터에 없던 전혀 새로운 환경–로봇 조합(OOD)에서도 잘 작동했다는 점을 확인할 수 있습니다. LoCoBot(원래 실내)이 야외 인도에서, Jackal(원래 야외)이 실내 사무실에서 주행하는 식으로 테스트했는데 잘 작동하는 모습을 보입니다.즉, 단순히 환경적 일반화뿐 아니라 로봇 형태(embodiment)의 차이까지도 일반화 가능하여 동작이 가능하다라는 것을 보여줍니다.
Q2. 데이터셋 공유의 효과
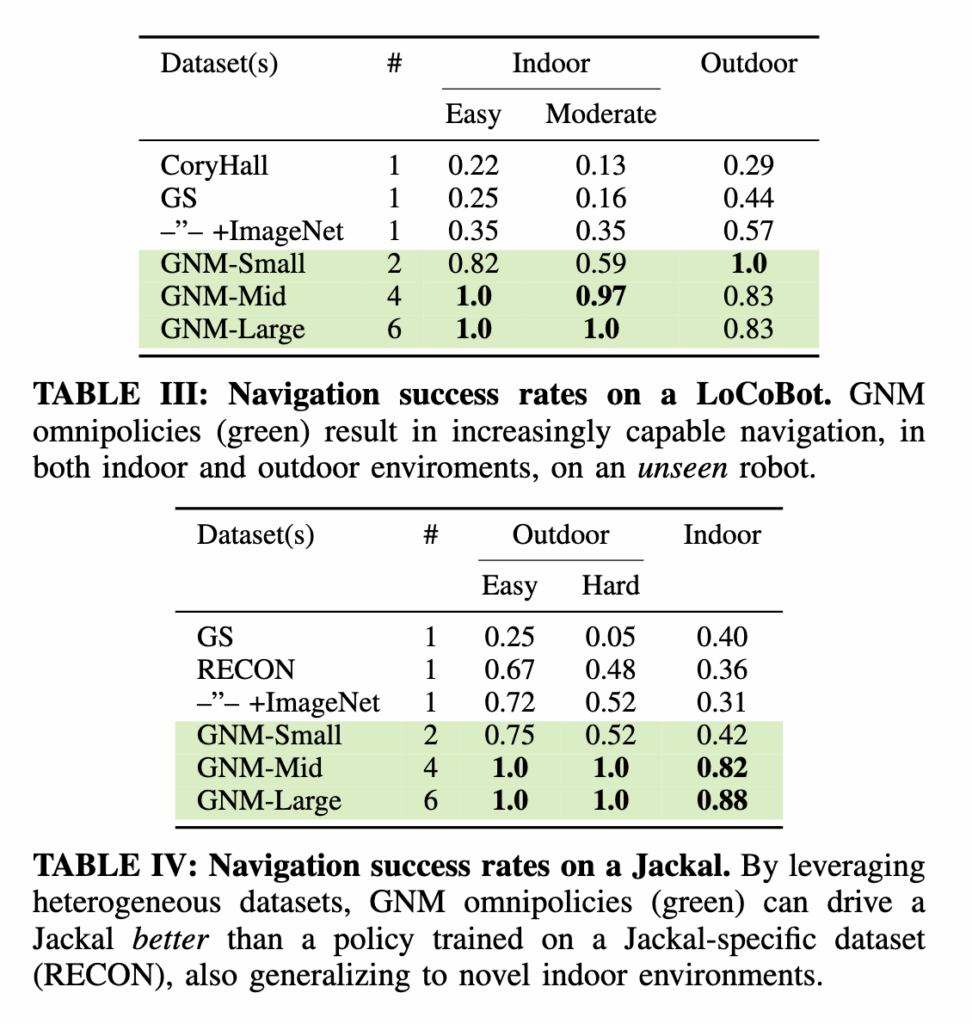
Jackal과 LoCoBot에서 수행된 평가 결과를 보면 데이터셋의 개수가 많아질수록 (GNM-Small -> Mid -> Large)성능이 꾸준히 향상되는 것을 확인할 수 있습니다. 그리고 추가된 데이터가 직접적으로 관련 없는 환경에서 왔는데도 전체 내비게이션 성능이 좋아지는 것도 보실 수 있습니다. 결국 모델이 로봇 간 공통적인affordance를 학습했다라고 보여주는 표인 것 같습니다.
Q3. 설계 선택(Design Choices) 분석

저자들은 LoCoBot을 대상으로 체계적으로 비교했습니다. Shared Action Space같은 경우 속도 명령 기반, 절대 waypoint, 정규화된(normalized) waypoint 세 가지를 비교했을 때 정규화된 waypoint가 가장 성능이 좋은 것을 확인할 수 있습니다. 근데 Action space같은 경우에는 Hard 환경을 리포팅 하지는 않았지만 저자는 특히 Hard 환경(좁은 통로, 급회전 구간 등)에서 두드러졌다고 합니다. 행동 표현을 정규화하는 것이 로봇간 서로 이질성을 통일하여 학습하는데 유리하다라는 것을 보여주는 표인 것 같습니다. 그리 Embodiment Context같은 경우에 로봇의 Context 정보를 담는 방식 중에서는 시간적으로 연속된 관찰(temporal context)을 활용한 경우가 가장 성능이 높았음을 확인하실 수 있습니다. 이류가 저자는 여기에 연속된 시각 정보 속에는 로봇의 속도나 회전 반경 같은 동역학적 특성이 암묵적으로 담겨 있기 때문이라고 합니다. 그리고 Policy Architecture같은 경우에는 논문 본문에서는 해당 구조에 대해서 언급이 없어서 해당 표를 이해하기 어려웠는데 최대한 이해한대로 설명을 드리면 단일 인코더(현재 관찰 이미지와 목표 이미지를 채널 방향으로 단순히 쌓는(stacking) 방식-> 하나의 인코더에서 동시에 처리), Siamese(두개의 독립적인 인코더로 현재 이미지와 목표이미지를 각각 처리한다음에 두 임베딩을 결합하는 구조), Conditional 구조(Fig2)를 비교한 결과 Conditional architecture가 가장 좋은 것을 확인할 수 있습니다. 관찰 정보가 정책 출력에 직접 영향을 미치는 구조가 더 일반화 가능한 표현을 학습하게 한다는 걸 보여준다는 것을 보여주는 것 같습니다.
Q4. 성능 저하 상황에서의 강건성
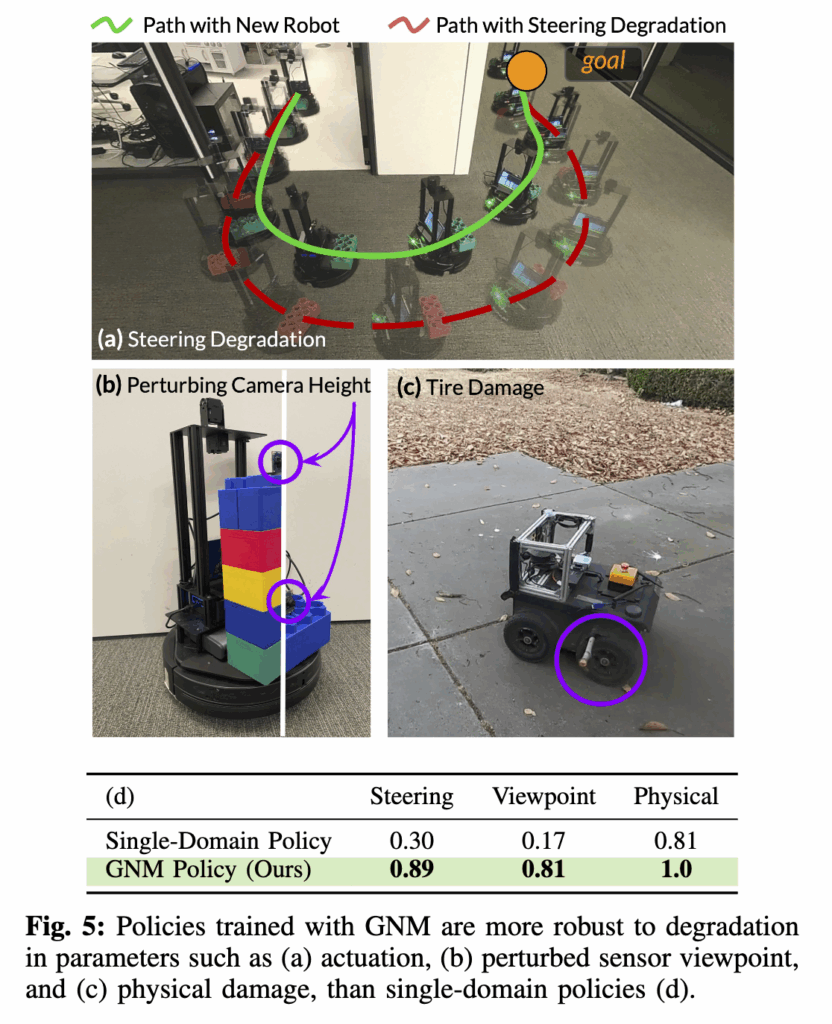
마지막으로 저자들은 GNM이 학습 데이터에서 보지 못한 센서나 기구적 변동에도 성능저하에 강인한지를 실험했는데 조향각 제약(steering degradation)을 인위적으로 가한 경우 GNM은 단순히 회전을 포기하지 않고 더 길고 부드러운 경로로 대체하여 이동했습니다(a). 이는 제약을 인식하고 합리적으로 대응한 것으로 보입니다. 또 카메라 높이나 위치를 바꾸거나(b) 로봇을 일부 손상(c)시킨 경우에도 GNM은 안정적으로 목표 지점에 도달했습니다.타이어 손상에도 결국 다양한 로봇 데이터로 학습된 정책이 센서 노이즈나 하드웨어 불확실성에도 일반화된 행동 패턴을 학습했다고 볼 수 있습니다.
Conclusion
논문의 마지막에서는 GNM이 단순히 또 하나의 내비게이션 모델이 아니라 사전 학습된 내비게이션 백본으로서 로보틱스 연구의 출발점이 될 수 있음을 강조합니다. 현재 비전 분야에서 CLIP, DINO 같은 모델이 다양한 태스크의 베이스 백본으로 쓰이는 것처럼 GNM은 로봇용 비전 백본으로 발전할 수 있도록 이러한 연구가 제안된 것 같습니다. 앞으로는 연구자가 새 로봇을 개발할 때 처음부터 데이터를 수집하는 대신 GNM을 불러와서 내 로봇에 맞게 조금 조정(fine-tune)하는 시대가 가능해질 수도 있도록 그런 연구의 시발점이 되는 논문인 것 같습니다.
이만 리뷰 마치도록 하겠습니다.
안녕하세요. 안우현 연구원님 좋은 리뷰 감사합니다.
연구자마다 자기들만의 로봇용 데이터만 가지고 실험하게 되고 전체적으로 봤을 때 로봇 연구가 파편화된다라는 문제가 이미지넷과 같은 대규모 로봇용 데이터셋이 없어서 그런 것 같은데, 로봇 연구에서 그런 대규모 데이터셋이 공개되지 않는 이유가 궁금합니다. 로봇 연구는 주변 환경이 달라지면 성능 차이가 심하기 때문인건가요? 그리고 GNM이 로봇에서도 적용할 수 있지만 자율주행 자동차, 무인이동체, 선박 등 다양한 분야에서 활용될 수 있을 것 같은데 로봇 이외의 도메인으로의 확장에 대한 언급이 있었는지 혹은 그런 연구가 있는지 궁금합니다.
감사합니다.
안녕하세요. 성준님 좋은 질문 감사드립니다.
먼저 말씀하신 것처럼, 저자들이 논문 초반에 지적한 로봇 연구의 파편화 문제는 사실상 ImageNet 같은 범용 대규모 데이터셋이 존재하지 않기 때문인 것 같습니다. 근데 제 개인적인 생각으로 이런이유는 이유는 단순히 데이터를 공개하지 않아서가 아니라 로봇 데이터의 특성상 통합이 근본적으로 어렵기 때문이라는 생각이 듭니다. 그래서 이러한 문제를 어느정도 완화하고자 이런 로봇 통합 연구를 진행하고자 했던 것이 아닐까 싶습니다.
그리고 두번째 질문에 대해서 답변 드리자면, 로봇 이외 도메인으로의 확장 가능성에 대해서는
논문 본문에서는 직접적인 언급은 없습니다. GNM의 실험은 전부 지상 주행형 로봇(ground robot 드론 포함)을 대상으로 진행되었고 입력도 전방 단안 RGB 카메라를 기본 전제로 합니다.
근데 논문 마지막 부분에 저자들은 현재 시스템은 ground robot을 가정하고 있지만 다양한 구동 방식이나 센서 종류를 포괄할 수 있는 확장된 설계가 향후 흥미로운 연구 방향이 될 것이다라고는 언급합니다!
감사합니다!
안녕하세요.
간단한 질문이 있는데, 리뷰 작성된 내용 중에서 다음과 같은 내용이 있습니다.
“일종의 정규화된 계획된 이동 경로일 뿐이지 이건 실제 모터 명령이 아닙니다. (공통 행동 표현-로봇 간 공유된 추상화임) 그래서 각 로봇의 하위 제어기 예를 들어 PID 제어기나 MPPI 제어기가 이 waypoint를 실제 로봇에 맞게 로봇 속도나 조향각으로 변환합니다.”
여기서 정규화된 이동 경로는 어떤 값인가요? x축과 y축으로 몇 m이동하면 좋을지에 대한 translation과 어느 방향을 바라보는지에 대한 rotation값일까요?
안녕하세요 정민님 좋은 질문 감사합니다.
말씀하신 대로 정규화된 이동 경로는 로봇이 다음으로 얼마나 translation하고, 어느 방향으로 rotattion해야 하는지 를 공통된 단위로 표현한 값입니다. GNM은 로봇마다 속도나 제어 구조가 다르기 때문에, 각 로봇의 최고 속도(α) 로 이동량을 나누어서 스케일을을 정규화합니다.
따라서 모델이 예측하는 (x, y, ψ)는 실제 거리,각도 단위가 아니라, 상대적인 이동 방향과 회전량을 나타내는 값이고 이것를 가지고 이후 각 로봇의 하위 제어기(PID, MPPI 등)가 이 출력을 받아 자신의 동역학에 맞는 실제 거리, 각도 단위의 속도조향 명령으로 변환하게 됩니다.
감사합니다.
안녕하세요. 리뷰 잘 읽었습니다.
navigation task 에서 크게 pre-configured map의 유/무에 따라서도 방법론이 나뉘는 것으로 알고 있는데, 본 논문은 map 을 사전에 구성해 두는 방식일까요? 아니면 구성하지 않는 zero-shot 방식인가요??
(Topological Map 이 언급되는 것으로 봐서 미리 map 을 구성해두는 방식인거같기도 하네요)
그리고 결국 본 논문의 핵심 주장은 장소/로봇에 구애받지 않는 범용 모델? 인거같은데, 논문에선 이를 해결하고자 여러 로봇에서 다양하게 수집한 데이터셋으로 학습하는 방식을 사용하는것으로 이해했습니다. 단순히 여러 데이터셋으로 학습하였다~ 말고 논문에서 언급된 추가적인 테크닉이 더 있을까요? 가령 어떻게 학습했다던지, 모델에 테크닉이 추가되었다던지 등등이요?
감사합니다.
안녕하세요 석준님 좋은 질문 감사합니다.
먼저 map-based 방법론이 어떤 기하학적인 정보를 가진 map을 기반으로 한다고 했을 때, GNM은 사전에 구성된 metric map을 사용하지 않는 non geometric한 mapless내비게이션 방식인 것 같습니다. 다만 학습된 정책이 예측하는 시간 거리를 이용해 추상적인 topological graph을 동적으로 구성합니다. 즉, 미리 만들어둔 지도를 쓰는 게 아니라, 로봇이 학습 데이터에서 본 이미지들 간의 이동 가능성을 기반으로 노드(이미지)와 간선(연결 관계) 를 만들어 사용하는 구조입니다.
또 두 번째 질문과 관련해서, 단순히 여러 데이터셋을 합쳐 학습한 것 외에도 논문에서는 멀티로봇 학습을 위한 두 가지 핵심 테크닉을 제안했다고 생각을 하는데,
먼저 공통 행동 표현이라고 생각합니다. 이 방식은 로봇마다 제어 명령(속도, 조향각 등)이 다르기 때문에 이를 정규화된 waypoint + yaw 변화량 형태로 통일하여 학습합니다. 그리고 로봇의 최근 k프레임 시각 정보를 입력으로 받아, 로봇의 특성(속도, 회전 반경 등)을 스스로 추론하게 하는 기술도 어찌보면 해당 간접적인 기술로 볼 수 있지 않을까 싶습니다!
사실 GNM의 핵심은 단순한 데이터 통합도 있는데, 이질적인 로봇 간 차이를 흡수할 수 있도록 설계된 구조적 정규화 기법도 있고 이를 바탕으로 기하학적인 정보 없는상태에서도 장소와 로봇에 구애받지 않는 범용 내비게이션 정책을 실증한 것이 핵심이라는 생각이 듭니다!
감사합니다.
안녕하세요 우현님 리뷰 감사합니다.
내비게이션은 어느정도 백본처럼 활용할 수 있는 모델이 있는건가요? GNM이 23년도 논문이면 현재 여러 내비게이션 모델들의 기반이 실제로 되었는지 궁금하네요. 또 gibson같은 시뮬레이터 환경은 내비게이션 문제도 다뤘던것 같은데, 내비게이션의 경우는 시뮬레이션 데이터를 적극적으로 활용하는 편인가요?
안녕하세요 영규님 좋은 질문 감사합니다.
먼저 내비게이션은 어느정도 백본처럼 활용할 수 있는 모델이 있는지에 대한 답변은.. 제가 아직 내비게이션 분야를 이제막 공부하기 시작한 단계라 확실하게 답변드리기는 없지만, 현재 해당 논문을 읽었을 때 느꼈던 제 생각은 로봇 통합이 아직 어려운 문제이기도 하고 이로인해서 뭔가 범용적인 백본 예를들어DINO와 같은 그런 모델은 아직 없는 것 같습니다. GNM 자체가 아직 CLIP처럼 표준 백본으로 굳어진 단계는 아니지만, 그 아이디어인 멀티로봇 데이터 통합 학습과 행동 추상화 개념은 이후 여러 연구(GNM-2, ViNT, NoMaD 등)의 기반이 된 것 같습니다. 해당 모델들은 모두 GNM의 구조를 확장해 더 큰 데이터셋과 멀티센서 환경으로 일반화를 시도하고 있는 것 같습니다.
감사합니다.
안녕하세요 우현님, 좋은 리뷰 감사합니다!
내비게이션이라는 주제가 저에게는 생소했는데, 로봇 간의 공통된 내비게이션 백본을 제안한 논문이라는 점이 매우 흥미로웠습니다. 실험 파트 Q1에서, 비행 데이터를 학습하지 않았음에도 드론의 성공률이 높게 나온 것이 신기했습니다. 보편적인 로봇과 달리 드론은 위아래 이동을 고려해야 하는데, 그럼에도 GNM이 잘 작동한 이유가 무엇인지 궁금합니다.
감사합니다.
안녕하세요 예은님 좋은 질문 갑사합니다.
해당 내용에 대해 추가적인 설명을 드리자면 드론의 경우에도 실험에서는 고도를 고정(약 1m)시켜 수평면 위에서 이동만 수행하도록 설정했기 때문에, 사실상 지상 로봇과 유사한 2D 이동 문제로 단순화된 상태였습니다.
그래서 결국에는 지상에 굴러다니는 오로지 z축말고 x,y축으로만 이동하는 로봇 형태로 단순화해서 실험했기 때문에 드론에서도 평가했을 때 GNM이 잘 작동하지 않았나 싶습니다.
예은님 말씀대로 자유도를 높여서 위아래 이동을 고려해야하는 경우라면 동작하기 어려울 것 같기도 합니다.
감사합니다.