
< Intro >
1. Zero-shot image classification
제로샷 이미지 분류는 한마디로 말하자면 학습데이터에 존재하지 않는 새로운 class에 대해 classification을 할수 있는 기술을 말합니다
전통적인 이미지 분류에서는 대규모의 라벨링된 데이터셋이 필수지만 사실상 세상에는 이러한 레이블링된 데이터셋은 제한적일 뿐더러 데이터를 라벨링하는것 자체도 많은 비용이 필요합니다. 심지어 새로 라벨링 한 데이터를 사용하기 위해서는 재학습도 진행해주어야 합니다
따라서 이와 같은 문제를 해결하기 위해 제로샷 학습기법이 등장했습니다!
[How to ?!]
이러한 제로샷 이미지 분류는 그럼 어떻게 분류가 되나?!
간단하게 설명하자면 이미지와 텍스트간의 연관성을 학습한 모델인 사전학습된 멀티모달 모델을 활용하여 unlabeled image에 대하여 분류를 수행합니다. 즉, 해당 이미지에 대하여 가장 잘 맞는 text라벨을 찾아내는 방식입니다
특히 앞서 말한 라벨링에 대한 비용을 크게 줄일 수 있고 새로운 클래스가 추가되더라도 재학습없이 바로 분류가 가능하다는 장점을 가집니다. 또한 텍스트를 다루는 부분을 대규모의 LM모델을 사용하게 되면 더 풍부해진 의미정보를 활용할 수도 있게 됩니다.
하지만 이런 멀티모달 모델의 성능에 따라 분류 성능이 좌우될수 있기도 하고 학습 분포와 상이한 도메인에 대한 편향이 생겨 생소한 클래스에 대한 분류 성능이 좀 떨어질 수도 있습니다.
2. Contrastive Learning
Self-supervised learning(자기 지도학습) 방법 중 하나로 유사한 데이터쌍은 가깝게, 다른 데이터쌍은 멀게 학습함으로 그 차이를 극대화하는 방법입니다
즉, 긍정샘플(실제 이미지-텍스트쌍)과 부정샘플(임의로 냅다 맺어진 이미지-택스트쌍)을 대조해서 학습하는데
- 긍정샘플 : 모델이 이미지-텍스트 간의 유사성을 최대화 하도록 학습
- 부정샘플 : 모델이 이미지-텍스트 간의 유사성을 최소화 하도록 학습
So, what is CLIP !
이미지를 분류하는 모델로, 이미지와 텍스트 쌍을 학습하여 학습되지 않은 새로운 클래스나 라벨에 대해서도 분류가 가능한 제로샷 이미지 분류 모델입니다. CLIP은 Contrastive Language-Image Pre-training의 줄임말로 대조학습(Contrastive learneng) 이라는 self-supervised learning을 통해 학습이 진행됩니다.
CLIP은 별도의 레이블 없이 웹에서 수집된 엄청난 양의 이미지-텍스트 쌍으로 학습합니다.
- 텍스트 : 공원에서 뛰어 놀고있는 강아지
- 이미지 : 텍스트에 대응하는 이미지
이때 뛰는, 강아지 등의 개념이 별도의 라벨 없이 쌍 자체에 내재하게 됩니다.
CLIP은 이미지와 텍스트를 같은 임베딩 공간에 Projection해주는데 이미지 인코더는 이미지를 벡터로 임베딩하고 텍스트 인코더도 텍스트를 벡터로 임베딩합니다. 이렇게 같은 공간에 임베딩 해줌으로 두 모달리티 간의 유사도를 직접적으로 학습할 수 있게됩니다
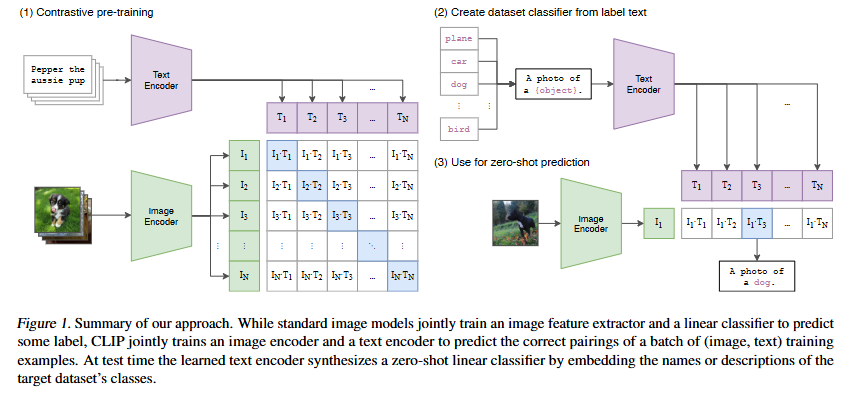
그림은 CLIP의 구조도로 이미지와 텍스트를 각각의 인코더에 통과시켜 같은 임베딩 공간으로 projection시킨 뒤 두 벡터간의 코사인유사도를 계산합니다
- 이미지 인코더 : ViT기반으로 이미지 패치간의 시각적인 특징을 추출한다
- 텍스트 인코더 : 트랜스포머 기반 LM으로 텍스트의 문맥 정보와 의미를 포착한다
같은 임베딩 공간에서 이미지-텍스트 간의 의미적인 연관성을 학습하는 것 이기 떄문에 두 표현을 정규화 해주어야 합니다
이후 코사인 유사도를 사용해서 대칭적인 대조학습 loss(Contrastive learning loss)를 사용해 학습을 진행하는데
즉 CLIP은 텍스트와 이미지를 각각 인코딩한 후 같은 임베딩 공간에서 진짜 짝(pos pair)의 코사인유사도를 높이고 가짜 짝(neg pair)의 유사도를 낮추면서 학습을 진행합니다. 이 과정을 수억개의 이미지-텍스트쌍의 데이터를 사용하여 학습하면 모델은 이미지에 언어적으로 정의된 많은 개념을 자연스럽게 학습하게 되는 것입니다.
< Method >
CLIP의 핵심은 이미지와 매칭되어있는 자연어 txt속에 담긴 Supervision으로부터 시각적인 perception을 학습하는 것입니다.
구체적인 학습방식은 1.충분히 큰 데이터셋 구축하고, 2.이미지와 텍스트가 각각의 인코더를 통과하여, 3.대조학습이 수행되는 순서로 진행됩니다.
1. Large Dataset
기존 연구들에서 사용한 coco등과 같은 데이터셋은 현대기준에서는 매우 작은 규모이거나 품질이 정리되어 있지 않은 경우들이 많기 때문에 supervision을 사용합니다
인터넷에 공개된 다양한 이미지-텍스트쌍 무려 4억개를 수집하여 새로운 데이터셋을 구축하는데 이때 아무 텍스트나 긁어오는게 아니라 50만개의 쿼리를 먼저 정의하고 각 쿼리당 최대 2만 쌍의 데이터를 수집함으로 클래스 균형을 맞추어 줍니다
-> 이 데이터셋을 WIT(WeblmageText)라고 부릅니다
2. Encoder 선택
대조학습을 진행하기 위해서는 각각의 이미지와 캡션이 같은 공간에 임베딩 되야하는데, 입력된 이미지와 캡션이 각각의 encoder를 통과하여 latent vector를 얻고 이것을 선형 투영과 정규화로 임베딩됩니다.
저자들은 img encoder로는 ResNet 계열과 ViT 계열을 약간의 수정을 통해 사용해보았고, txt encoder로는 비교적 소형transformer를 사용하여 출력값으로 최상층의 [EOS] 토큰위치의 벡터를 최종 표현으로 활용했습니다
(논문에서 별도의 언급이 없으면 실험적으로 ViT-L/14@336px를 img encoder로 사용한다)
3. contrastive learning
(여기서 잠깐! 캡션이란? 이미지와 함께 붙어있는 자연어 설명문으로 사진 밑에 적어두는 한~두문장의 설명이나 블로그,인스타 글이나 이미지의 제목이나 간략한 설명같은 것들을 의미합니다. 즉 그 이미지와 짝지어진 텍스트 자체를 말합니다. 계속 설명없이 사용되길래 정확히 정의하고 쭉 읽으면 좋을것 같아서 적어보았습니다~)
초기에는 각 이미지 별로 해당 이미지에 맞는 문장(캡션)을 예측한다는 접근을 사용했는데
-> 즉 CNN으로 이미지를 인코딩하고 transformer의 텍스트 디코더를 합쳐서 이미지를 입력하고 그에 맞는 문장을 생성하는 형태로 학습했습니다.
하지만 트랜스포머의 언어모델은 연산비용이 너무 크고, 학습속도도 느리고, class구분 능력도 별로였습니다. (텍스트(캡션)을 단어 단위로 맞히는 것 자체가 너무 어려운 문제였던 것..)
따라서 CLIP은 텍스트 전체를 하나의 단위로 보는 방식으로 접근하여 캡션의 세부 단어를 예측하는 것 보다 이 이미지가 이 캡션과 쌍이 맞는지를 구분하는 것으로 집중했습니다.
따라서 문장 단위의 matching만 판단하는 contrastive learning을 수행합니다
대조학습으로 학습을 하게 되면서 사전학습의 task가 훨씬 단순해지고 확장성이 좋아졌는데 저자들은 이러한 접근으로 ImageNet 제로샷 전이 효율이 4배나 향상했다고 합니다.
학습의 구조는 한 배치 안에서의 대조학습으로 한번의 학습때 하나의 배치(N개)가 들어가면 이론상 가능한 조합은 (NxN)개가 됩니다. (진짜 짝은N개, 가짜 짝은 N^2-N개)
따라서 이 모델의 목표는 진짜 짝의 코사인 유사도를 높이고, 가짜 짝의 코사인 유사도는 낮추는것이 된다. 이 N^2쌍에 대한 점수 행렬을 기반으로 대칭 cross-entropy loss를 계산합니다
-> 이 구조를 mulit-class N-pair loss라고 말한다.
CLIP은 4억 쌍의 엄청큰 데이터셋으로 한 배치 않에서도 많은 negative pairs들을 다루기 때문에 훈련데이터셋에 오버피팅될 위험이 적습니다.
따라서 사전학습된 가중치 없이 처음부터 학습을 하고, 비선형 projection헤드(MLP헤드같은 것)를 제거해서 하나의 선형층으로 바로 공통임베딩 공간으로 보내주고, 데이터셋 대부분이 원래 한문장으로 구성되어 있기 때문에 긴 캡션에서 한 문장으로 샘플링을 하는 전처리같은 기법도 제거함으로 불필요한 랜덤성도 줄이고(텍스트 변환 함수 제거), 복잡한 증강 없이 리사이즈와 랜덤 정사각형 크롭만 진행하고, softmax전의 출력값인 logit의 스케일을 조절하는 온도파라미터를 튜닝값이 아닌 학습파라미터로 모델이 직접학습하게 해주었다.
-> 즉, 불필요한 구성요소를 걷어냄으로 연산의 효율을 높이고 구현의 복잡도를 낮추었다.
4. using CLIP
그럼 이 CLIP을 실제 task에 어떻게 사용할수 있을까?
요약하자면 클래스의 라벨들을 텍스트로 만들고, 해당 이미지랑 가장 잘 맞는 텍스트를 고르게 합니다-> 제로샷 분류!!
자세히 살펴보자면 dog, flower, plant같은 라벨들을 전부 가져와서 프롬프트를 사용하여 문장화를 진행하는데 예를들자면 “a picture of a {class}”같은 템플릿에 클래스를 끼워넣어 텍스트 후보들을 만듭니다.
단어만 덜렁 쓰는것 보다 문장으로 맥락을 만들어 주면 동음이의어같은 문제가 줄어들어 매칭의 정확도가 높아집니다
이후 각 인코더를 통과하여 코사인 유사도를 계산한후 유사도가 가장 높은 클래스를 예측합니다
즉, 라벨 대신 문장을 쓰기때문에 라벨이 새로 생겨도 문장을 통한 묘사로 새 태스크에 바로 적응할 수 있습니다.
< Analysis >
저자들은 앞으로의 분석을 하기에 앞서 보지못한 과제(unseen task)를 수행할 수 있는지를 측정하는 척도로 이 제로샷 전이를 통해 모델의 task학습 능력을 평가하는 시각을 제시합니다,
1. CLIP vs ResNet50
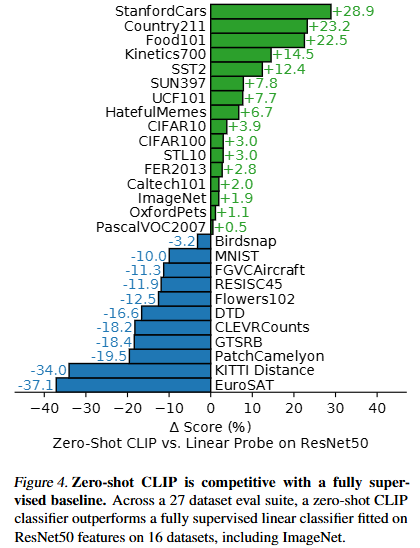
위의 그래프(fig4)는 27개의 주요 데이터셋을 사용한 성능결과입니다. 쉽게 보자면 양수막대는 Clip이 resnet보다 분류 잘했다!, 음수맥대는 Clip이 더 못했다! 정도로 일단 파악하고 더 자세한 분석을 이어서 살펴봅시다.
[Clip이 강한 분야]
먼저 fine-grained뷴류에 해당하는 Stanford Cars와 Food101데이터셋에서는 Clip이 20%이상 앞지른 반면 Flowers102와 FGVCAircraft에서는 10%이상으로 낮은 성능을 보였는데 저자들은 이러한 차이가 per-task supervision정보 양의 차이 때문이라고 추정합니다.
두번째로 ImageNet, CIFAR10, PascalVOC2007 같은 일반적인 객체 분류 데이터셋에서는 Clip이 유사하거나 약간 더 높은 성능을 보였습니다.
세번째로 Clip은 Kinetics700과 UCF101의 비디오 행동 인식(action recognition)과제에서도 좋은 성능을 보였는데 저자들은 CLIP이 동작(verbs) 관련 개념을 자연어를 통해 배우기 때문(supervision)이라고 설명합니다.
즉, 결론적으로 CLip은 단순하게 class인식뿐만 아니라 행동이나 상황까지 언어를 기반으로 확장된 recognition능력을 보여줍니다.
[Clip이 약한 분야]
반면에 Clip은 전문화되거나(specialized) 복잡하거나(complex) 추상적인(abstract) task들에서 약한 성능을 보이는데 위성이미지 분류나 림프절 종양탐지, 합성된 장면의 객체수 세기, 자율주행 관련 task, 가까운 차량과의 거리인식같은 task를 말합니다.
하지만 저자들은 이런 복잡하고 어려윤 task의 성능을 평가하는데 제로샷전이가 의미있는 척도인지는 의문이라고 합니다. 왜냐면 비전문가 사람도 림프절 종양 분류 같은 task에 대한 경험이 없기 때문에 사람조차도 few-shot(조금 배워야하는)분야이기 때문에 아마도 클립도 마찬가지이지 않을까~ 라고 생각한다고 합니다.
2. CLIP vs Few-shot
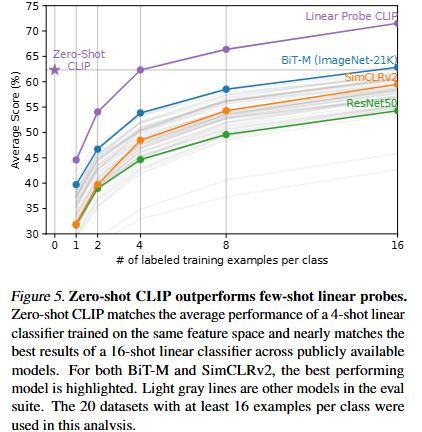
위의 그래프(fig5)는 Few-shot학습과의 비교입니다.
먼저 제로샷 Clip이 다른 모델들과의 비교를 본다면 텍스트 지식만으로도 4-shot모델과 동급의 성능을 보입니다. 두번째로 CLIP 자체 피처를 few-shot으로 학습시키면 점진적인 상승이 나타나며 16-shot쪽에서는 SOTA모델 급의 성능을 보입니다. 또한 같은 shot 조건에서도 Clip피처가 더 좋은결과를 보이는데 저자들은 이러한 이유를 Clip피처 자체가 이미 텍스트를 통해 시각적 지식을 충분히 내포하고 있기 떄문이라고 말합니다
3. representation learning capability
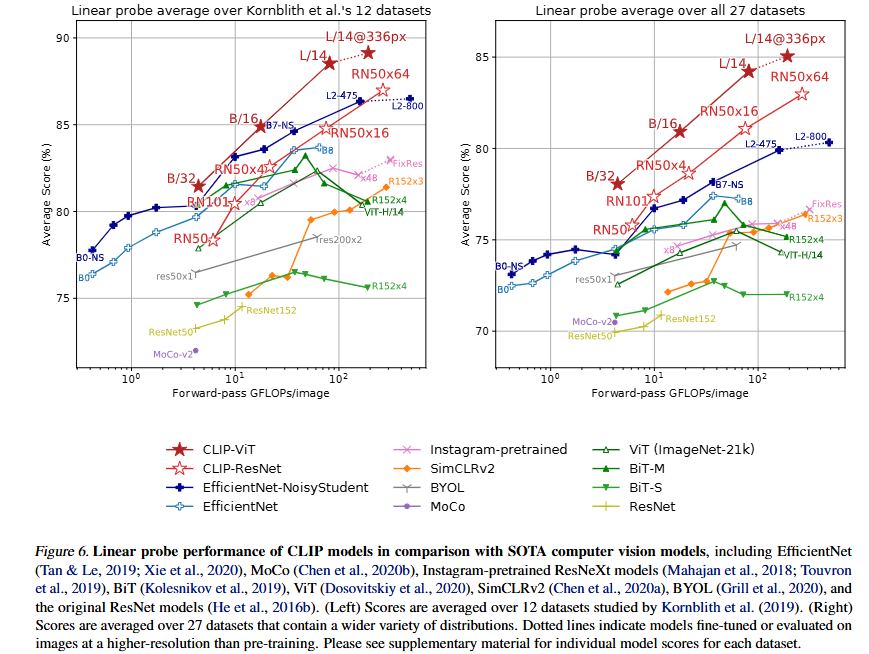
다음으로는 모델이 좋은 특징(feature)을 학습했는지에 대한 분석으로 사전학습된 모델을 고정시킨후 그 위에 단순한 선형층을 얹어서 피처의 품질만 평가하는 Linear probe방식을 사용했다고 합니다.
먼저 왼쪽의 그래프는 Kornblith et al.(2019)의 12개 전통적인 분류 데이터셋(CIFAR, Caltech, Pets 등)에 대한 평가입니다. 보면 Clip 전체적으로는 모델 크기를 키우면 성능이 우상향 하는 것을 볼수있는데 clip의 스케일링이 좋다는 것을 의미합니다. 즉 데이터나 연산량을 더 추가할수록 꾸준히 좋아지는 것이고 이건 일반화 능력이 안정적이라는 것을 말합니다. 또한 Clip vit계열이 앞서 언급한것 처럼 resnet계열보다 약 3배정도 효율이 좋습니다.
다음으로 오른쪽의 그래프는 저자들이 27개의 더 다양한 task와 도메인으로 확장하여 성능을 평가한 결과입니다. 추가된 데이터셋에는 OCR(문자인식), Geo-localization, Facial emotion, Action recognition과 같은 영역들이 포함됩니다.
오른쪽 그래프의 결과를 보면 기존의 모델들보다 더 큰 성능의 차이를 보이는 것을 알수 있습니다. 특히 왼쪽 그래프 보다 계산량이 작은 모델 조차도 성능이 좋음을 보입니다. 이것은 Clip이 단순히 imagenet스타일의 데이터에만 강한게 아니라 txt-img 사전학습 덕분에 다양한 task로 일반화가 가능한 표현들을 배웠기 때문입니다.
4. Robustness out of distribution
이미지넷에서 정확도가 90프로에 달하는 모델들도 조금만 다른 환경이 되면 성능이 급락하게 되는 견고성이나 일반화 성능이 떨어지는 경우가 많습니다.
저자들은 견고성을 두가지 척도로 확인하는데 Relative robustness(분포가 달라졌을때 정확도가 얼마나 유지되는지)와 Effective robustness(분포가 달라졌을때 원래 성능이 높아서 좋다기 보다 하락폭이 낮은지)로 확인하고 두가지 모두 고려해야 진짜로 강인한 모델을 만둘수 있다고 합니다.
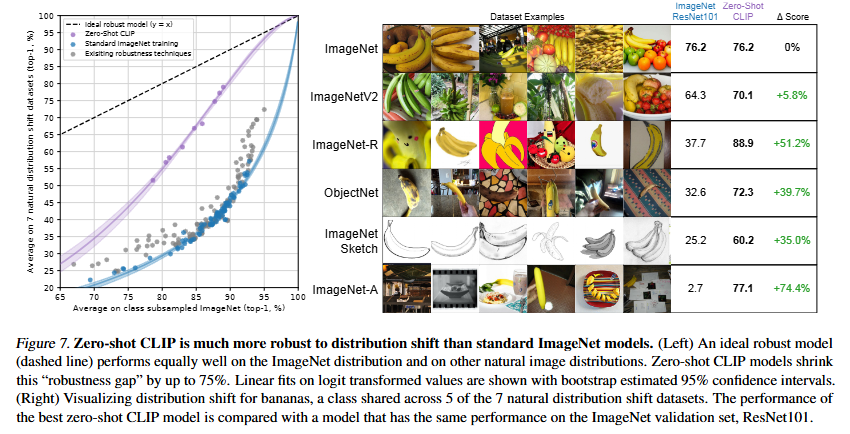
위의 fig7을 왼쪽의 그래프를 살펴보면 제로샷 clip이 분포이동 imagenet에서 기존 이미지넷 모델에 대비하여 견고한 성능을 보이는 것을 알수있습니다. 이것은 클립이 Effective robustness가 높다는 것을 의미합니다.
오른쪽의 표는 6개의 데이터셋처럼 분포가 달라졌을때의 클립의 견고성을 직관적으로 확인할수 있습니다. 특히 스케치나 그림같은 데이터에서도 인식률이 꽤나 유지되는 견고한 모델임을 보입니다.
5. Data Overlap
다음으로는 기초학습과 논문을 읽으면서 들었던 의문인 진짜 제로샷인지! 즉 test set 오염에 대한 분석입니다.
논문을 읽으며 4억쌍이나 되는 데이터셋을 학습하는데 그러면 훈련셋 안에 우연히 포함되어 있을 가능성이 있지않은가? 하는 생각을 했는데 저자들이 이 중복 여부를 측정해보았다고 합니다.
Perceptual Hashing(pHash)라는 방법을 사용하여 학습 데이터셋의 이미지들과 평가 데이터셋의 이미지들을 비교하고 일부 유사도가 높은 이미지 쌍은 사람이 직접 눈으로 검증을 진행했다고 합니다.
결과적으로 평가데이터셋과의 중복도가 1% 미만이라고 합니다.(대형 벤치마크에서도 2%미만)
이로써 CLIP의 성능이 데이터의 중복때문이 아닌 실제 일반화로 인한 결과임을 증명했습니다.
(Perceptual Hashing(pHash)가 뭔지 간단히 찾아보니 픽셀단위로 비교하지 이미지를 비교하지 않고, txt를 파일이름으로 단순히 비교하지 않는.. 시각적인 유사도로 비교를 한다는…(?))
< Limitation >
마지막으로 저자들은 CLIP을 발표하며 이 때의 연구적인 과제와 한계점을 꽤나 솔직하게 언급합니다!
먼저 1.제로샷 CLIP의 성능 한계를 말합니다. 클립은 여전히 최신 EfficientNet-L2, BiT, SimCLR-v2 같은 강력한 모델에는 미치지 못한다고 이 제로샷으로 SOTA를 뛰어넘는 단계까지 가려면 현재의 모델보다 약 1000배(!!!!)는 더 많은 연산량이 필요하다고 생각합니다. 따라서 이후 연구의 방향은 더 적은 데이터와 연산량으로 clip같은 모델을 학습시키는 효율적인 학습이라고 합니다.
두번째로는 2.아주 완전히 진짜로 “제로샷”은 아니다 입니다. 사실 연구과정에서 여러번 검증셋을 사용했다고 아주 완전히 미지의 데이터를 본 적도 없는 상태로 평가된것은 아니라고 합니다.
세번째로는 3.평가 데이터셋의 편향문제 입니다. 성능을 평가한 데이터셋의 구성에도 약간의 문제가 있는데 clip에 유리한 데이터셋 구성으로 공정한! 범용적으로 제로샷 전이 능력을 공정하게 평가할수 있는 표준 데이터셋 새로운 밴치마크가 필요하다고 주장합니다
< conclusion >
이 논문을 한문장으로 요약하자면 대규모의 데이터와 자연어 supervision만으로도 범용적인 시각적 지능을 학습할 수 있다! 입니다. CLIP은 NLP의 성공을 비전에 옮길수 있을까?가 연구의 출발점이 되었고 결과적으로 성공적이였습니다!
단순히 아직까지 꾸준하게 대표적으로 사용되고 하다보니 방법만 간단하게 알고있었는데 이렇게 제대로 읽어보니 논문을 읽으면 읽을수록 언어를 사용해서 배우는 비전 이라는 시각이 몇번을 들어도 놀랍게 느껴졌습니다..!
안녕하세요. 황찬미 연구원님 좋은 리뷰 감사합니다.
CLIP 논문이 좀 길어서 항상 끝까지 정독하지 않고 중간중간 필요한 부분만 읽었던 것 같은데 리뷰해주셔서 더 자세하게 파악할 수 있었습니다. 리뷰를 읽으며 몇가지 궁금한 점이 생겨 질문합니다.
먼저, 견고성을 파악하는 두가지 척도인 relative robustness와 effective robustness에 대해 궁금합니다. 설명만 읽었을 때는 두가지 척도의 차이점과 견고성을 위해 두가지를 고려해야하는 이유가 궁금합니다. 그리고 CLIP의 Limitation 중 하나로 복잡하고 어려운 task의 zeroshot 성능이 낮은 것을 언급할 때 저자가 사람조차도 few-shot(조금 배워야하는) 분야라고 설명했는데, few-shot 실험 결과에는 복잡하고 어려운 task들의 성능이 없는 것 같습니다. 이 말은 해석하기에 따라 CLIP의 few-shot은 성능이 어느정도 보장된다는 의미를 내포하고 있다고 생각하는 데 few-shot 실험결과에서는 그러한 데이터셋들의 실험 결과가 없어서 혹시 논문에서 언급이 있었는지 궁금합니다.
감사합니다.
안녕하세요 찬미님 깔끔한 리뷰 감사합니다!
몇가지 궁금한점이 생겨 댓글 남깁니다
설명해주신 것처럼 모델의 학습방법은 최신 논문 대비 꽤나 간단한것 같습니다. CLIP이 Zero shot VLM 모델의 대표격이 된 것에 있어 CE loss등이 아닌 contrastive loss를 사용함의 이점이 무었인가요?
데이터셋을 구축할때 모집단을 잘 포집하는 방법은 랜덤 선별이라고 생각하는데요, WIT를 구축할때 50만개의 쿼리를 정의한 이유와 정의 방식이 궁금합니다. (랜덤 선별이 아닌 저자들의 주관이 반영되었다 생각하기 때문) 혹시 추가 정보가 있을까요?
학습방법에 대해 초기에는 생성을 이용했으나 연산량, class 분류 능력 한계 등의 이유로 분류테스크로 진행되었다고 이해했는데, 일종의 문제 단순화로 생각됩니다. 표현 공간을 단순화하므로서 발생하는 문제점이에 대해 언급이 있을까요? 예를 들어 분류의 경우 카테고리가 비교적 제한적으로 미리 정의되어 편향이 발생합니다. 실험부분에 살짝 언급된 의학 도메인 분류는 사람도 학습해야한다고 언급되는것도 이러한 한계의 당위성을 위해 작성된것 아닐까 하는데, limitation의 2번등의 문제에 대한 해결방법이나 저자들의 생각이 더 드러난 부분이 있었는지 궁금합니다….!
또한 위와같이 의학도메인 등 학습에 사용되지 않은 완전 새로운 분포에 대해 linear prob으로 clip 잠재성을 다룬 실험이 있었는지 궁금합니다. 없었다면 읽으시면서 찬미님은 혹시 어떤 실험이 좋았는지, 논리성을 높이기 위해 추가했으면 좋았을 실험이 있었는지 궁금합니다.
질문이 두서가 없었는데요,, 아무쪼록 깔끔한 리뷰 감사합니다!
안녕하세요 찬미님.
평소에 관심이 있던 논문이었는데 좋은 리뷰 감사합니다!
읽으면서 이해가 잘 안되는 부분 질문 드리겠습니다!
전문화되거나 추상적인 task에서 약한 성능을 보였다고 언급이 되어있는데 이런 task는 상대적으로 학습 되는 데이터의 수가 적어서 약한 성능을 보인 것이라고 이해하면 될까요? 즉 이런 전문적인 부분의 데이터는 인터넷에서 얻기 힘들어서?? 왜 약한지에 대한 설명이 잘 이해가 안가서 질문 드립니다.
좋은 논문 리뷰 감사합니다.
안녕하세요 찬미님^^ 좋은 리뷰 감사합니다!!
질문이 2가지 있는데,
1. ‘같은 임베딩 공간에서 이미지-텍스트 간의 의미적인 연관성을 학습하는 것 이기 떄문에 두 표현을 정규화 해주어야 한다’고 하셨는데, 여기서 정규화가 왜 필요한 건지 이해가 잘 안됩니다.. 이미지-텍스트 각 임베딩이 같은 multi modal embedding space에 투영되었다면 이미 같은 좌표계에 존재하는 셈이니까 그대로 사용해도 될 것 같은데 정규화를 또 해주는 이유가 있을까요?
2. 온도 파라미터로 softmax 전 logit값의 스케일을 조절한다고 하셨는데, 온도 파라미터가 무엇이고 왜 logit의 스케일을 조절해주어야 하는지 짧게나마 추가 설명 부탁드립니다..!!