안녕하세요. 박성준 연구원입니다. 오늘 리뷰할 논문은 Vision-Language 모델의 compositional 이해 능력을 개선한 논문입니다.
Introduction
CLIP과 같은 Vision-Language 모델은 이미지와 텍스트를 함께 학습하는 것으로 Classification, Detection, Segmentation 등의 다양한 task에서 zeroshot 수행이 가능하며 zeroshot으로도 높은 성능을 달성했습니다. 하지만, VLM을 학습하는 contrastive learning의 특성 상 복합적인 언어 이해 능력에는 아직 한계가 존재합니다. 특히 객체의 속성(색, 재질, 크기 등)과 객체의 상태 그리고 객체들 사이의 관계(공간적 위치 관계, 행동의 주체-대상 관계 등)에 대한 이해를 필요로하는 Structured Vision & Language Concepts (SLVC) 개념은 VLM에 어려움이 있습니다. 이러한 Compositional Understanding이 약한 이유로 VL 모델이 학습하는 contrastive learning이 object bias가 있기 때문입니다. contrastive learning은 무작위 배치에서 이미지-텍스트 쌍을 맞추게 되는데 이때 한 배치 내에 동일한 객체의 구성을 가지고 있을 확률이 낮기 때문에 모델이 이미지나 텍스트를 단순히 객체들의 모음으로만 이해해도 충분하기 때문입니다. 또한 특성과 관계를 라벨링한 데이터셋도 많지 않기 때문에 학습에도 한계가 있습니다. 즉, 기존의 VLM은 객체 식별에는 강하지만 객체들의 특성이나 상호 관계를 구분하는 것은 약합니다. 저자는 이를 해결하기 위한 새로운 학습 방식을 제안합니다.
저자가 말하는 기존 모델이 가지고 있지 않은 SVLC 정보를 학습할 때에 신경써야할 문제는 바로 catastrophic forgetting 문제입니다. SVLC 개념은 신경만 모델에서 공통적으로 나타나는 현상으로 새로운 데이터를 학습하게 되면 기존에 잘 알고 있던 정보를 잊게되는 문제입니다. 특히나 광범위한 정보를 학습하고 zeroshot으로 활용하는 CLIP과 같은 VLM은 새로운 정보를 학습하며 기존 정보를 잃지 않아야 합니다.
따라서 저자는 추가 데이터 없이 VLM의 SVLC 이해 능력을 향상하는 데이터 기반의 접근법을 제안합니다. 저자의 아이디어는 다음과 같습니다. 이미지의 구조적 이해는 여전히 어렵지만 언어의 구조는 비교적 잘 학습되므로 이 언어의 구조에 대한 이해력을 바탕으로 VLM의 SVLC 능력을 향상시키는 것입니다. 언어의 구조를 잘 알고 있는 LLM을 활용하여 기존 이미지-텍스트 쌍의 텍스트를 manipulate하는 것으로 모델이 텍스트에 내재된 SVLC 정보를 학습할 수 있도록 하는 방법입니다. 구체적으로는 텍스트의 정보를 증강하여 원본 텍스트와 같은 의미를 갖는 POS 문장과 속성이나 관계가 다른 조작된 NEG 문장을 활용한 hard negative를 활용한 학습을 통해 모델이 SVLC 정보를 잘 이해할 수 있도록 학습합니다.
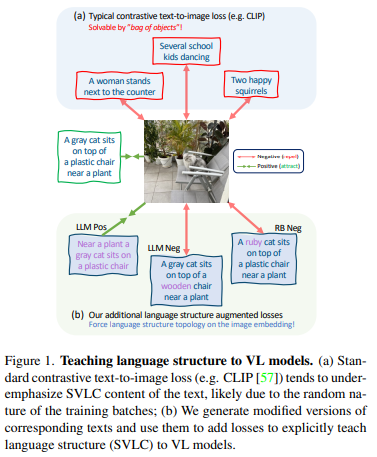
Figure 1은 저자가 제안하는 추가적인 학습 방법을 보여주는 그림입니다. 예를 들어 “회색 고양이가 플라스틱 의자 위에 앉아 있다”라는 문장이 주어지면 “회색”을 “루비색”으로 바꿔 잘못된 캡션을 생성하여 NEG로 학습하면 모델이 자연스럽게 고양이의 색깔 개념을 학습할 수 있습니다. 마찬가리고 “플라스틱”을 “나무”로 바꿔서 의자의 재질 개념을 학습할 수 있고 같은 의미의 다른 단어로 구성된 문장을 학습하는 것으로 SVLC에 대한 이해력을 높일 수 있습니다. 저자는 추가로 LoRA를 사용하여 미세조정하는 것으로 모델의 기존 지식을 훼손하지 않고 SVLC 개념을 학습할 수 있습니다.
정리하면 저자는 언어의 구조적 이해능력을 활용하여 VLM이 시각 장면의 구조를 더 잘 이해할 수 있도록 학습하는 방법을 제안한 논문입니다. 추가적인 데이터 없이 기존 데이터를 재활용할 수 있는 효율적인 미세조정 방법을 제안합니다.
Method
저자가 제안하는 프레임워크는 결국 기존 VL 모델의 SVLC 이해 능력을 키우기 위함입니다. 사전학습된 모델을 미세조정할 때랑 스크래치부터 학습할 때 모두 사용가능하며 두가지 학습방법에서 모두 효과적입니다.
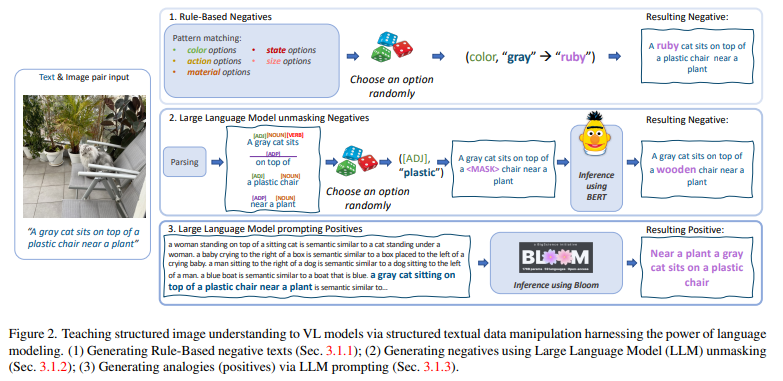
Figure 2는 저자가 제안하는 방법론을 보여주는 그림입니다. 먼저 텍스트를 변환하여 SVLC 정보에 집중할 수 있도록 데이터를 증강합니다. 두가지 방식을 활용하는데 첫번째는 원본 문장의 의미를 살짝 바꿔 Negative Sample을 생성하는 증강 방법이고 두번째는 의미는 유지한 채로 단어의 선택을 바꾸는 Positive Sample을 생성하는 방법입니다.
Rule-based Negatives
Negative 샘플을 생성하는 가장 직관적인 방법으로 사전에 정의된 규칙을 활용하여 특정 단어를 다른 단어로 바꾸는 것입니다. 먼저 텍스트를 분석하여 품사와 속성을 식별하고 저자가 원하는 SVLC와 관련된 단어(색, 재질, 크기 등)를 찾습니다. 그 후 미리 만들어둔 속성 유형 별 대체 단어를 선택하여 동일 품사 속성인 단어로 교체합니다. 예를 들어 “A big brown dog”에서 brown을 yellow로 변형하여 “A big yellow dog”로 만들게 됩니다. 이러한 작업을 여러 SVLC 특성에 적용하는 것으로 문장 내 단어 하나가 다른 다른 의미의 여러 문장을 생성하여 Negative로 학습합니다.
LLM-based Negatives via Unmasking
또 다른 Negative 샘플을 생성하는 방법은 바로 LLM이 가지고 있는 unmasking 능력을 활용하는 것입니다. 문장 속 SVLC 특성에 해당하는 단어를 마스킹하고 그 마스킹된 위치에 들어갈 단어를 LLM을 예측하여 원본 단어와 다른 단어를 넣어 Negative를 생성하는 방법입니다. LLM이 문맥에 맞게 단어를 생성하기 때문에 맥락에 맞는 즉, 문장에 문법적 오류가 없는 의미가 달라지는 문장을 생성하게 됩니다. 따라서, LLM의 unmasking을 통해 생성된 문장은 효과적인 Negative 문장으로 사용될 수 있습니다.
두 가지 방법으로 생성된 문장은 모두 Hard Negative로 학습할때 모델이 SVLC에 대한 이해능력을 향상시키는데 도움을 줍니다.
Text Analogies via LLM Prompting
뒤의 두가지 방법이 모두 Hard Negative를 생성하는 방법이었다면 이번에는 Positive를 생성하는 방법입니다. 이때는 원본과 의미는 같지만 표현이 다른 문장을 생성합니다. 마치 analogy(유추) 문제처럼 한 장면을 설명하는 두가지 표현의 문장 쌍을 생성합니다. 저자는 이를 위해 대규모 언어 모델인 BLOOM을 사용했습니다. BLOOM에 예시 문장 쌍 몇가지와 함께 프롬프트를 입력하여 의미가 같고 문장 구조와 표현이 다른 문장을 생성해 이것을 Positive Sample로 학습합니다. 이 방식을 통해 생성한 문장을 원본 이미지를 설명하는 문장이기 때문에 같은 의미로 학습하고 같은 의미를 같는 두가지의 표현을 학습할 수 있어 SVLC 특성을 이해할 수 있습니다.
Losses
text-to-image 유사도는 코사인 유사도로 계산됩니다.
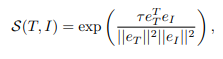
일반적으로 대규모 VLM이 학습할 때 사용하는 Contrastive Loss를 통해 학습됩니다.
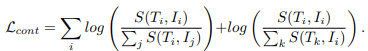
CLIP은 원래 위의 Contrastive Loss를 통해서만 학습하지만 저자는 저자가 생성한 3가지 방식의 증강된 문장들을 일반적인 Contrastive Loss만을 사용하여 학습하는 것보다 저자가 제안하는 몇가지 Loss를 함께 활용하여 학습하는 것이 더 효율적이라고 주장하고 있습니다.
먼저 저자가 제안하는 Negative Loss입니다.
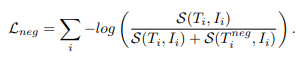
Negative Loss를 추가하는 것으로 모델은 원래의 텍스트와 증강된 Negative 텍스트와의 구별력을 더 확실하게 얻을 수 있습니다. 이 Negative Loss를 추가하는 것으로 모델이 SVLC에 대한 이해를 기를 수 있습니다.
다음 저자가 제안하는 Analogy Loss 입니다.
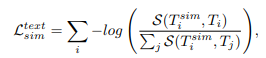
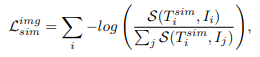
이 Loss는 텍스트-텍스트 유사도와 텍스트-이미지 유사도를 기반으로 Contrastive Loss를 적용합니다. 텍스트-텍스트 Loss가 언어적 의미의 일치를 학습하고 텍스트-이미지 Loss는 시각적 대응을 잘 유지할 수 있도록 학습하는 것이기 때문에 일반적인 Contrastive Loss를 조금 더 강화하는 효과를 갖습니다.
최종적으로는 위의 Loss들을 합한 형태의 Loss를 사용합니다.
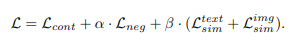
마지막으로 저자가 특정 task에 대해서 finetuning을 할때는 LoRA를 사용합니다.
Experiments
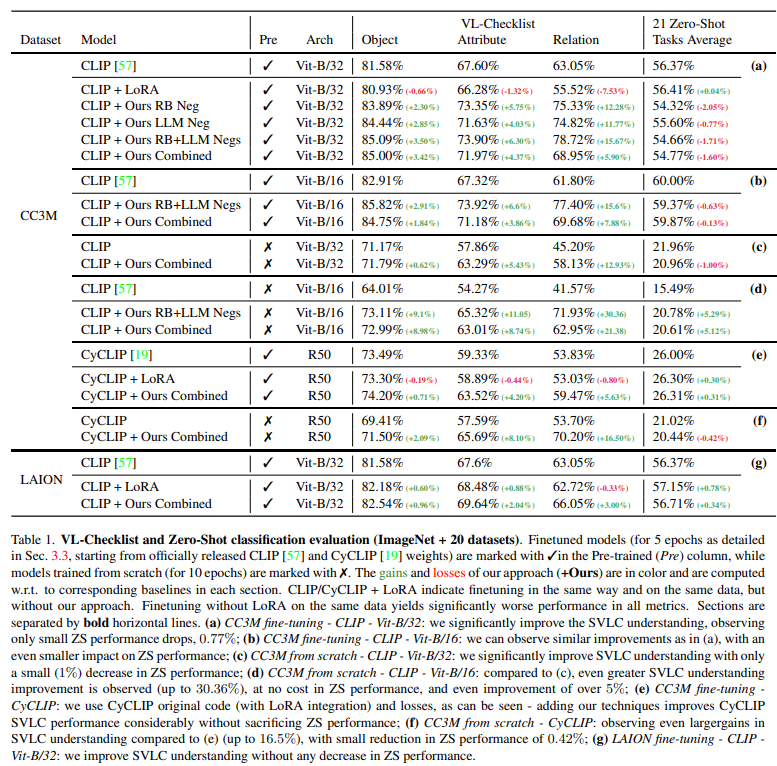
VL-Checklist는 Visual Genome, SWiG, VAW 등의 여러 VL 데이터셋을 모아서 이미지 당 두개의 캡션을 제공합니다. 하나는 positive, 하나는 negative입니다. 두 문장은 하나의 서로 다른 단어를 가지고 있으며, 이를 모델이 구분하는 것을 통해서 모델이 SVLC 특성을 잘 이해하고 있는 지를 확인할 수 있습니다. 표1에서 나와있는 것처럼 Object(객체), Attribute(속성) Relation(관계)로 SLVC를 평가합니다.
실험 결과를 확인해보면 VL-Checklist에서 저자가 제안하는 방법이 성능이 많이 개선되는 것을 확인할 수 있습니다. 저자는 특히 B-32보다 B-16에서의 성능 향상에 더 집중하여 모델의 zeroshot 능력이 좋을수록 저자가 제안하는 방법론이 더 효과적임을 주장하고 있습니다. Zeroshot 성능이 유지되었다는 점도 저자가 강조하고 있는 강점중에 하나입니다. 일반적으로 새로운 정보를 학습하게 되면 catastrophic forgetting으로 인해 기존 정보를 잊어버리는 문제가 발생할 수 있지만, 저자는 제안하는 방법론은 Zeroshot 성능이 잘 유지되는 동시에 SVLC 능력이 향상되었음을 강조하면서 저자가 제안하는 방법론의 강력함을 주장하고 있습니다. Finetuning을 했을 때와 Scratch부터 학습했을 때도 비교하고 있습니다. Scratch부터 학습하면 SVLC의 능력은 더 드라마틱하게 증가하지만 Finetuning을 하는 것이 기존 성능을 유지하는 데에 있어 장점이 있는 것을 표1을 통해 확인할 수 있습니다.
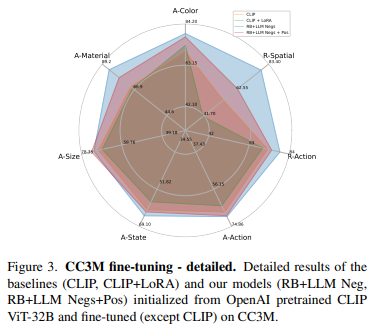
Figure 3은 SVLC 능력이 향상된 것을 확인할 수 있는 그림입니다.
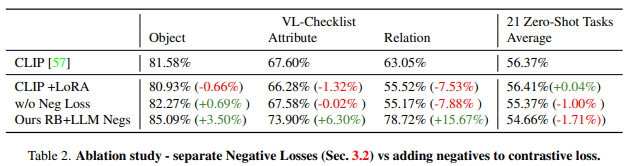
표2 는 Ablation Study입니다. Negative Loss를 사용해야 특히 Relation에서 성능이 많이 오르는 것을 확인할 수 있고 저자가 제안하는 Negative Loss를 추가하는 것이 Zeroshot 성능은 약간 하락하지만 전반적인 모델의 SVLC 성능을 향상시키는 데에 효과적임을 보이고 있습니다. 하락폭에 비해 상승폭이 높다는 점을 저자는 강조하고 있습니다.
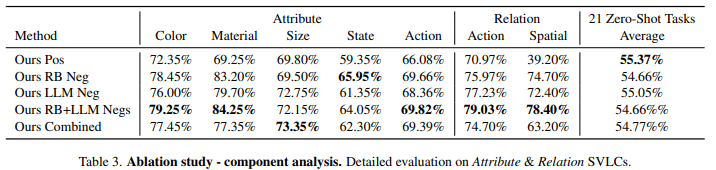
표3는 구성요소 별 Ablation Study입니다. 가장 주목할만한 점이 4번째와 5번째의 차이라고 생각되는데 둘의 차이는 Positive의 유무에 따른 차이입니다. Positive Loss를 추가하는 편이 Zeroshot 성능이 조금 더 높기 때문에 저자는 상황에 따라 Positive를 추가해도 되고 안해도 된다고 설명하고 있으며 기존 능력 보존과 SVLC의 향상의 적절한 균형을 맞추는 것은 Ours Combined라고 설명하고 있습니다. 제 생각에는 4번째가 제일 좋아보이긴합니다.
저자는 기존의 데이터만을 활용하여 VL 모델 특히 CLIP이 가지고 있던 단점을 보완하였고 새로운 데이터의 필요도 모델의 구조를 바꿀 필요도 없이 학습 효율성과 모델의 성능을 모두 보완했다는 점에서 괜찮은 논문인 것 같습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
Introdutcion에서 contrastive learning은 한 배치 내에 동일한 객체의 구성을 가지고 있을 확률이 낮아서 디테일한 정보를 학습하기에는 한계가 있다고 해주셨는데, 그렇다면 본 논문에서는 추가적인 데이터를 생성하고, 생성한 negative 샘플에 대해서 한 배치내에서 같이 학습을 진행하나요?
한 배치내에 positive/negative 관계를 두는 것이 더 효과적일 것 같은데, 구체적으로 학습 과정이 어떻게 되는지 궁금합니다.
감사합니다.
성준님 안녕하세요 좋은 리뷰 감사합니다.
1. 방법론의 컨셉과 그로인해 성능이 향상되었다는 것은 잘 나타나있지만, 정말 제안하는 컨셉으로 인해 성능이 향상된 것인지에 대한 궁금증이 있습니다. 예를 들어 문장에서 고양이의 색깔만 바뀐 문장이 들어왔을때 정말 그 색깔 단어에 집중을 잘 하게 되었는지 등에 대한 예시들이 있는지 궁금합니다.
물론 정량적 성능이 올랐다는 것 자체가 저자의 의도대로 동작했다는 것이라 이야기할 순 있지만, 뒷받침하는 분석 실험들이 어떤 방식으로 진행되었는지 궁금하여 여쭤봅니다.
2. 평가 task 관련하여, VL-Checklist는 pos, neg에 대한 이진 분류 정확도, 21 zero-shot은 이미지 분류 정확도가 맞나요? 그렇다면 표 1 (a)를 보았을때 CC3M 데이터셋에 대해서만 저자들의 방법론으로 학습하고 VL-Checklist 데이터들에 대해서는 별도로 학습하지 않는 것인지 궁금합니다.
좋은 리뷰 잘 읽었습니다. 감사합니다.
contrastive learning은 결국 단어 별로 embedding하기에, 객체들의 관계를 파악하기 어렵다는게 어찌보면 너무 당연한것이지만 한번도 생각해본적이 없었어서 인상 깊었습니다.
읽고 나서든 질문이 2가지 있습니다.
1. 위 실험들에서 데이터 증강을 얼마나 어떻게해서 실험한 것인지 궁금합니다.
예를 들어 rule-base로 negative로 한 실험에서는 한 이미지 당 몇가지를 바꾸어서, 몇개의 prompt를 추가로 negative로 만든건지 궁금합니다.
2. 추가된 데이터로 LoRA를 학습시킬때, 만들어낸 positive/negative pair만을 이용하여 fine-tuning하는지 아니면 원본 데이터+만들어낸 데이터로 학습하는지도 궁금합니다. 제 생각으로는 base model은 이미 원본 데이터로 학습되었기에 LoRA는 만들어낸 데이터만으로 학습시키는게 맞지 않나 싶은데 잘 모르겠어서 여쭤봅니다.
안녕하세요 성준님, 좋은 리뷰 감사합니다!
한 가지 질문이 있습니다. LLM의 unmasking 능력을 통해 negative를 생성하는 방법이 있었는데요, 마스킹 된 위치에 채운 단어가 실제 정답 단어와 같거나 유사할 확률도 있지 않나요? 이런 경우에는 negative로 쓰면 안 될 텐데, 유사한 단어들을 애초에 생성하지 않도록 하거나 필터링 하는 방법이 있다면 무엇인지 궁금합니다.
감사합니다.