이번 리뷰 논문은 IL이 가진 문제점, 장기적인 작업에 따른 일반화와 강건함을 가지기 위해서는 대량의 시연 데이터가 필요하다는 단점을 극복하기 위한 방법을 제시합니다. 적은 시연 데이터 (10 demo)만을 이용하여 강건한 장기 작업에 대한 효과적인 결과를 보여줍니다.
Intro

실생활에 로봇이 자율 작업을 수행하기 위해서는 로봇이 차를 준비하거나, 커피를 만들거나, 방을 청소하는 것과 같이 복잡하고 장기적인 작업을 해결해야 합니다. 이러한 작업은 여러 객체 간의 상호 작용을 조정하고 시간 경과에 따라 구조화된 작업 시퀀스로 구성되어 수행되어야 하빈다. 최근 policy learning이나 large-scale demonstration collection의 발전으로 low-level manipulation의 발전을 보이지만, 여전히 샘플 효율성과 구성 일반화에 어려움을 가지고 있습니다. 이러한 어려움은 장기 작업의 일반화를 보장하기 위해서는 길고 단일 궤적에 대한 다양성을 확보한 비현실적인 대규모 시연 데이터를 요구하게 되기 때문이라고 볼 수 있죠.
이러한 장기 작업의 문제점을 해결하기 위한 가장 단순하면서 명확한 방법은 장기 작업을 서브 작업으로 분해하여 별도로 학습하는 방향으로 해결하는 방법을 볼 수 있습니다. 하지만 해당 방법은 다음과 같은 문제를 가지고 있습니다. 1) 작업을 독립적으로 학습할 수 있는 하위 작업으로 효율적으로 분할하는 방법, 2) 각 서브 작업에 대한 정책의 distribution shift에 대한 강건성, 3) 각 sub-policies 간의 전환 시점을 파악 가능한 방법을 해소해야 합니다.
저자는 이러한 문제점을 해소하기 위해서 affordance-centric perspective를 활용합니다. 먼저, 다중 객체들이 포함된 장기 작업을 어포던스에 맞춰진 하위 작업으로 분할합니다. 각 하위 작업들은 찻 주전자로 따르거나 컵을 잡는 것과 같이 국소적인 객체 상호 작용에 따른 정의로 구분됩니다. 이러한 분해는 기능적으로 구별가능한 상호 작용에 초점을 맞춘 하위 정책의 독립적인 훈련을 가능하게 합니다.
그 다음, 장기 작업을 분해하여 얻어진 하위 정책들의 distribution shift 문제를 해결합니다. 해당 문제는 기존 모방 학습에 흔하게 사용되는 영상 기반 혹은 전역 좌표계를 이용한 표현을 이용하는 경우에 더욱 두드러집니다. 독립적을 학습된 영상 기반의 정책은 추론 과정에서 발생 가능한 객체의 시각적인 변화를 전부 커버하지 못하며, 특히, 전역 프레임을 활용하는 경우에는 모든 공간 구성을 포괄하기 위해서 수 많은 시연 데이터를 요구하게 됩니다.
이러한 문제를 해결하기 위해서 저자는 Oriented affordance frames을 제시합니다. 이는 물체 중심 좌표계로 수행하고자 하는 작업과 과련된 객체에 대한 어포던스에 고정되어 로봇의 tool frame을 향해 정렬된 좌표계입니다. 해당 프레임은 작업의 기능적인 구조만 유지하고 불필요한 세부 사항을 제거하는 효과를 줄 수 있습니다. 도구의 프렘을 회전시키면서 각 하위 정책에 대한 일관된 좌표 공간에서 학습되므로 로봇이 tool을 활용하는 경우에도 분포를 유지할 수 있게됩니다.
이러한 상대적 프레임에 정책을 고정함으로써, 대규모 시연 데이터 없이도 공간적 변화에 대한 일반화가 가능하며, 다른 형태를 가진 클래스에서도 일반화된 성능을 가질 수 있게 됩니다. 상대적 프레임을 이용하는 여러 연구가 있었지만 해당 연구에서는 closed-loop behaviour cloning까지 제시합니다.
+ closed-loop behaviour cloning: 행동 중 외부 변화에 대응이 가능한 BC라고 보면 됩니다.
또한, 저자는 각 하위 정책을 데모 궤적의 길이로부터 직접 학습된 self-progress prediction을 수행하여 별도의 중재 정책이나 외부 감독 없이 하위 정책 간에 자율적으로 전환 가능하도록 하여 장기 작업 중 부드러운 전환이 가능하도록 합니다.
해당 연구에서 제시하는 핵심 기여는 다음과 같습니다.
(1) We introduce the concept of the oriented af- fordance frame, a local, task-aligned reference frame that enables sub-policy learning to be both spatially invariant and compositionally robust.
(2) We develop a perception pipeline that leverages pre-trained vision foundation models to detect and track these affordance frames without reliance on fiducial markers, supporting real-world deployment.
(3) We augment each sub-policy with a continuous self-progress prediction signal, enabling automatic and reliable arbitration between sub-tasks without requiring a high-level controller.
또한, real world experiment를 통해서 affordacne-centric approach이 sub-task 당 단 10 demo만으로도 샘플 효율적인 정책 학습이 가능함을 보이며, 기존 기법 (영상 기반, global frame)보다 뛰어남을 보여줍니다.
Method
해당 연구에서는 아래와 같은 목적을 가진 state-conditioned robotic policies \pi(a_t | s_t) 를 학습시큰 것이 목적입니다.
(1) 높은 샘플 효율성, 10개의 시연 데이터만으로도 학습이 가능해야함
(2) 작업 관련된 객체의 공간적 구성에 불변
(3) 객체 형상 혹은 외형 변화에 불변 ~ intra-class에 강인
(4) 하위 정책들이 장기 작업에 따른 구성이 가능해야함
저자는 위 목적을 해결하기 위해서 기존 널리 사용되는 영상 혹은 포인트 클라우드 기반의 state representation을 대체하는 것을 제시합니다. 기존 방식 대신에 state s_t로 현재 작업관 관련된 tool frame의 pose를 oriented affordance frame으로 상대적인 표현을 사용하자고 합니다.
Oriented Affordance Frames for States and Actions
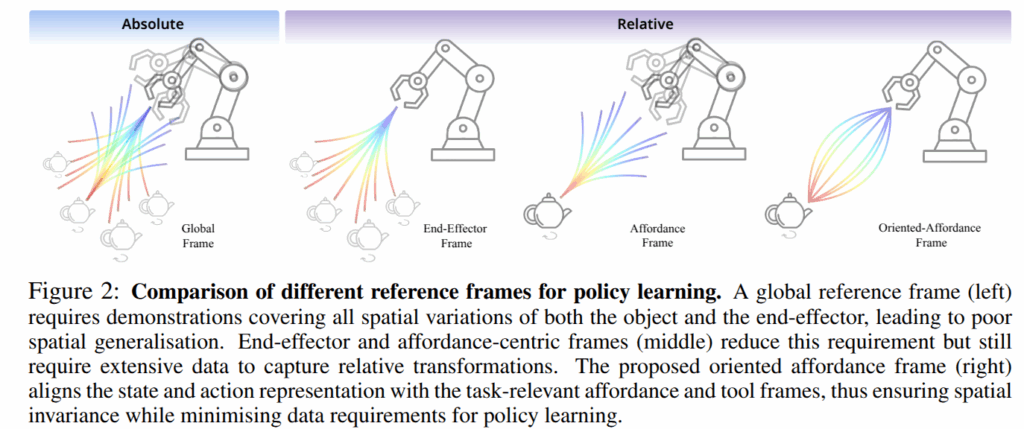
좌표계에 대한 영향력에 대해서 설명하기 위해서 fig 2를 살펴보도록 하겠습니다. 먼저, fig 2의 맨 왼쪽인 fixed global coordinate (absolute)로 state와 action을 표현하면, 시연 궤적은 공간적 일반화를 달성하기 위해서 객체 및 로봇 자세의 변화를 밀도있게 커버해야만 합니다. 만약 객체가 학습 때, 보지 못한 위치에 등장하게 되면 정책은 실패할 가능성이 높겠죠.
이를 해소하기 위한 방법으로 relative coordinates를 사용하는 방법입니다. 예를 들어 로봇의 행동을 현재 end-effector에 상대적으로 표현(fig 2-2번째)하거나, 작업 관련된 물체의 자세를 end-effector에 상대적으로 표현(fig2-3번째)하는 방법으로 볼 수 있습니다. 이러한 표현은 일반화 문제를 어느 정도 완화시킬 수 있지만 여전히 각각 물체의 모든 자세를, 로봇의 모든 자세를 포함하는 시연 데이터를 요구하게 됩니다.
++ 이해가 안가는 분들을 위해 단순한 예시를 들어보겠습니다. 자신 책상 위의 마우스를 위치를 숫자로 설명한다고 생각해보세요. 가장 모두가 찾을 수 있는 방법은 경도 위도를 사용하는 방법을 들 수 있겠죠. 이는 작업과 무관하게 약속된 전역 좌표계를 사용한다고 볼 수 있습니다. 근데… 경도 위도를 이용하게 된다면 로봇이 모든 영역에 맞게 다 학습을 해야합니다.
그럼 상대 프레임을 이용하는 경우는 어떤 경우일까요? 작업을 수행하는 나를 중심으로 상대적으로 마우스가 얼마나 떨어져 있는지를 표현하는 방법으로 볼 수 있습니다.
fig 2에서 ee-frame은 ee를 원점으로 작업 객체를 표현하는 방법, affordacne frame은 객체의 affordacne를 원점으로 보는 방법으로 볼 수 있습니다. 근데 여기서 문제가 다시 생겨요. 두 방법 모두 원점이 아닌 대상은 자유롭다는 문제가 발생합니다.
저자는 이를 해결하기 위한 방법을 제시합니다. 방법은 아래에서 다시 풀어드릴게요
Affordance Frames: Relative reference frames은 EE에 중심을 두거나, 작업 관련 물체의 affordacne의 중심에 둘 수도 있습니다. 특히, 객체는 여러 작업에 특화된 affordance를 가질 수 밖에 없습니다. 예를 들어, 컵을 집기 위해서는 손잡이에 affordacne를 가지지만, 붓기 작업을 수행하기 위해서는 컵 중앙에 어포던스를 가지게 됩니다. 저자는 어포던스 프레임을 활용하지만, 이전 연구와 다르게 현재의 tool frame을 향하게 하여 BC에 활용합니다.
Tool Frames: 다중 객체 작업에서 로봇은 객체와 직접 상호 작용(e.g. 들기, 밀기, 열기…)하거나 도구 객체를 들고 대상 객체와 작용합니다. 저자는 대상 객체에 정의된 affordacne frame 뿐만 아니라 도구 객체에 tool frame을 정의합니다. tool frame은 fig 3과 같이 ‘들기’ 작업에서는 ee frame과 동일하지만, 도구를 잡은 뒤에는 tool frame은 주전자의 입구나, 수저의 머리 부분에 tool frame이 위치하게 됩니다.
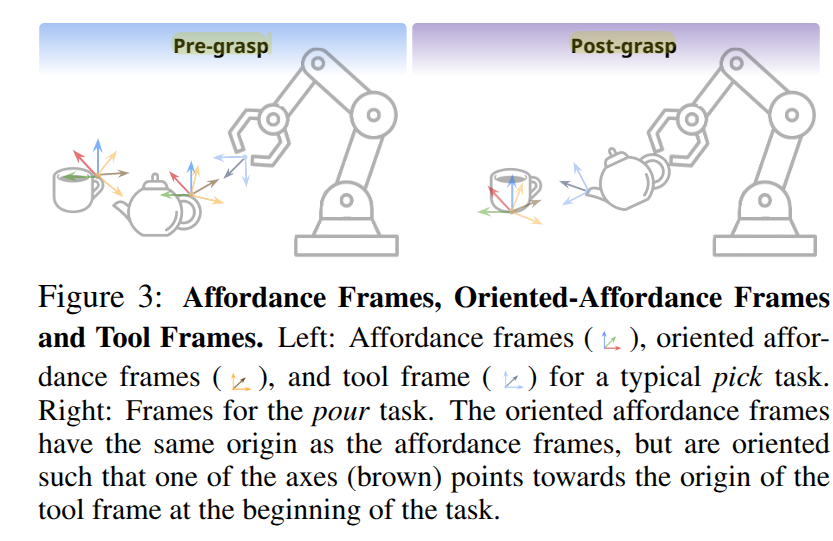
Oriented-Affordance Frames: 자, 그럼 affordance frame과 tool frame이 주어져 있으면, 본 논문의 핵심 개념인 oriented-affordance frame을 소개 할 수 있습니다. 해당 표현은 대상 객체의 affordance frame 중 한 축 (여기서는 x 축을 “funnel” axis로 일관되게 사용)이 tool frame의 원점을 향하도록 회전시켜 얻습니다.
저자는 정책의 state와 action sequence를 모두 해당 표현으로 변경합니다. 이를 통해 일반화 가능하고 샘픟 효율적인 정책 학습이 가능하다고 주장합니다.
Frame Initialisation and Update: 각 작업 시작 전에 oriented affordance frame을 초기화 합니다. perception pipeline은 affrodance frame \mathbf{T}^W_{afford} \in SE(3) 를 추출합니다. 그리고 로봇의 forward kinematics과 쥐고 있는 도구 객체에 대한 지식을 기반으로 tool frame \mathbf{T}^W_{tool} \in SE(3) 의 포즈를 구할 수 있습니다. 그리고 나서 alg 1을 통해서 x 축이 tool frame의 원점을 향하도록 하는 회전 행렬 \mathbf{R}_{align} 를 계산하여 \mathbf{T}_{o-aff} = \mathbf{R}_{align} \cdot \mathbf{T}_{afford} 를 생성합니다.

State Representation: 정책을 위한 state s_t 는 \mathbf{T}^{o-aff}_{tool} \in SE(3)과 이진 그리퍼 state g_s \in {0, 1} , 고정된 oriented affordacne frame을 기준으로 대상 객체의 회전인 \mathbf{R}^{o-aff}_{aff} 로 구성됩니다.
Action Representation: 정책에 의해 생성되는 actions은 sequence of N = 16으로 표현되며, 각 시간에 따른 end-effector의 다음 포즈 시퀀스인 {T^{o-aff}_{ee}}_{\tau = t…t+N} 와 동일한 길이의 이진 그리퍼 시퀀스로 구성됩니다.
Intuitive Benefits of the Oriented Affordance Frame: 저자는 해당 표현이 적은 수의 시연으로도 효과적이라고 주장합니다. 이는 fig 4를 보면 어드 시원 궤적이든간에 “funnel axis”의 근처로 정렬되는 경향을 볼 수 있습니다. 즉, 여러 정책을 구성해도 작업이 끝날 때 로봇의 tool frame이 항상 분포 내에 있도록 보장 할 수 있습니다.
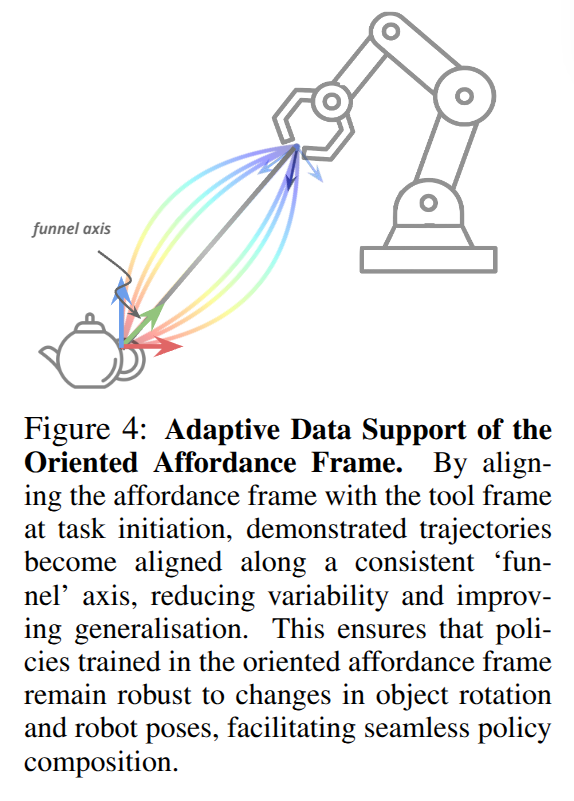
++ 자, 이전에 마우스 위치를 표현하는 방법을 예시를 다시 들어서 설명하도록 하겠습니다. 이전에 마우스를 중심으로 혹은 나를 중심으로 원점을 잡는 것을 상대 좌표라고 했죠. 근데 여기서는 둘 다 이용하는 방법을 사용해요. 마우스를 중심으로 잡지만 한쪽 축은 나를 바라보도록 강제하는 것이죠. 나를 바라보는 축 하나만으로도 마우스의 위치를 알려줄 수 있는거죠.
+++ 더 간단한 예를 들면 마우스와 나를 줄로 연결한다면 마우스의 위치는 줄의 길이로 표현이 가능하게 됩니다. 여기서 줄이 funnel axis(~fig 4의 회색선)라고 보시면 됩니다.
Policy Arbitration by Self-Progress Prediction
장기 작업을 구성하는 하위 정책 간의 모호성을 해결하기 위해 self-progress prediction이 가능하도록 하도록 합니다. 여기서는 Diffusion Policy가 예측하는 time을 시연 데이터의 길이를 [0, 1]로 정규화하여 학습을 진행합니다. 이를 통해 나온 스칼라 값은 작업의 진척도를 표현하는 수단으로 사용되며, 일정 임계값을 넘기게 되면 하위 작업을 완료했다고 가정하고 다음 단계로 작업을 진행합니다.
Experiment
로봇 학습의 특성상, 데모 영상을 이용항 정성적 평가도 중요합니다. 이에 대한 결과는 다음 링크에서 확인 부탁합니다. https://affordance-policy.github.io/.
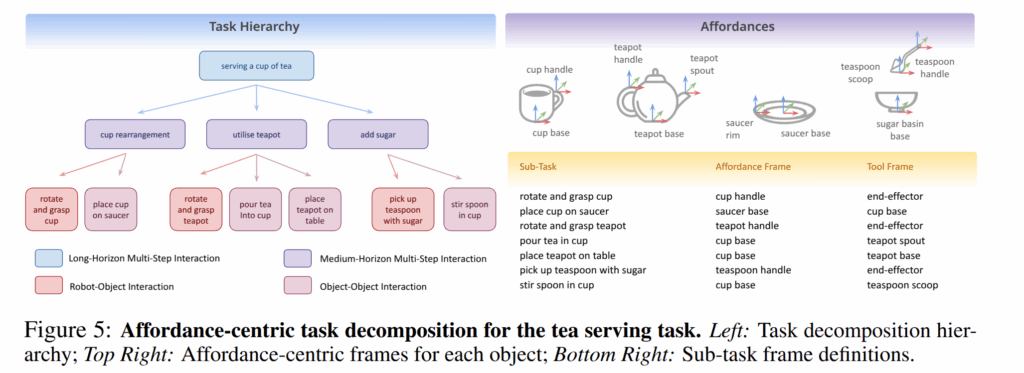
해당 실험에서는 fig 5와 같은 실험 세팅을 통해서 장기 작업을 구성했습니다. 대표적인 장기 작업은 tea making을 수행했습니다. 해당 장기 작업은 아래와 같은 7가지 하위 작업으로 분해하여 평가를 진행합니다.

하위 작업에 따른 affodacne와 tool frame은 fig 5의 오른쪽 같이 정의됩니다.
Perception System: 실험적으로 해당 표현이 효과가 있는지를 보기 위해서 2가지 타입에서 평가합니다.
1) Marker-based: ArUco marker로 affordacne를 ground-truth posed로 얻는 방법입니다. ~ 해당 기법을 메인으로 실험을 진행합니다. 이는 표현 기법에 대해서 제시하는 것이지 해당 문제를 푸는 것이 목적이 아니기 때문이라고 합니다.
2) Large Vision Models: fig 9를 이용하여 각 frame을 추론
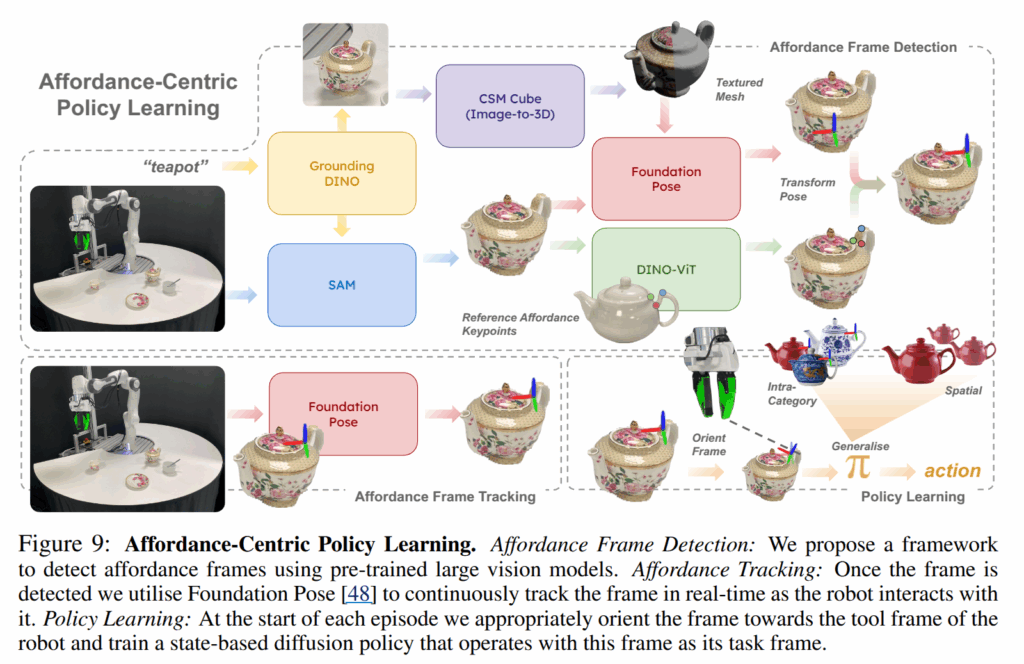
Policy Training: Diffusion Policy ~ 4,500 epochs, default parameters. 회전만 하이퍼 링크 내의 연구를 따르는 6D vector로 표현 (연속적인 회전 표현을 활용하기 위함이라고 함…)
state -> 16dim: oriented affordance frame (3+6D), binary gripper state (1D), object’s orientation relative to the oriented affordance frame (6D) = 16dim
action -> 11dim: 3D robot position, 6D robot orientation, 1D gripper state, 1D self-progress prediction x sequence of 16 actions = 176 dim
Results
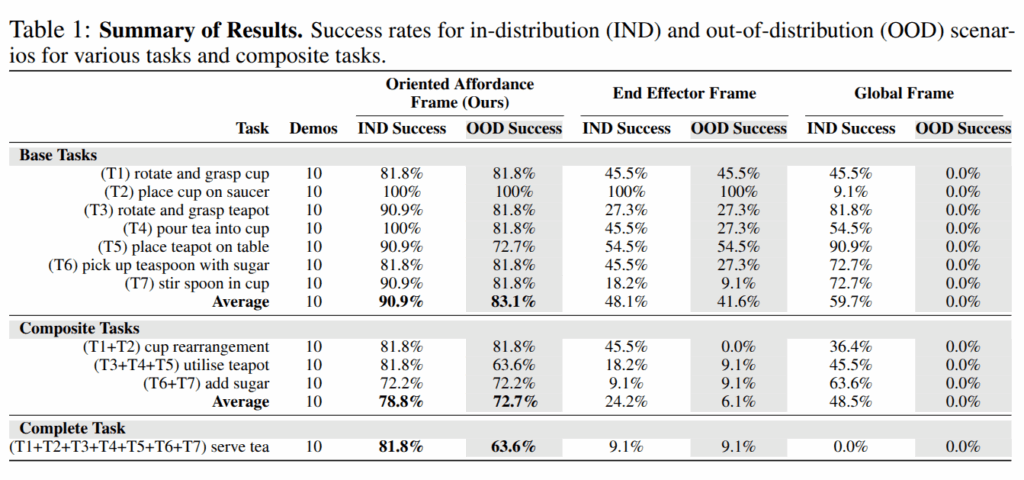
Sample-efficient Policy Learning from Only 10 Demonstrations: tab 1에서 보이는 바와 같이 10 demos를 사용하는 경우, 모든 경우에서 제안한 표현이 가장 높은 성능을 보여주고 있음.
특히, 공간 분포를 벗어난 OOD의 경우에서 global frame은 모든 경우에서 0%의 성공률을 보여주고 있음.
EE frame에서는 나은 결과를 보여주나, 장기 작업 구성에 대한 강인성 실험인 Composite Tasks, Complete Tasks에서는 처참함 결과를 보여줌
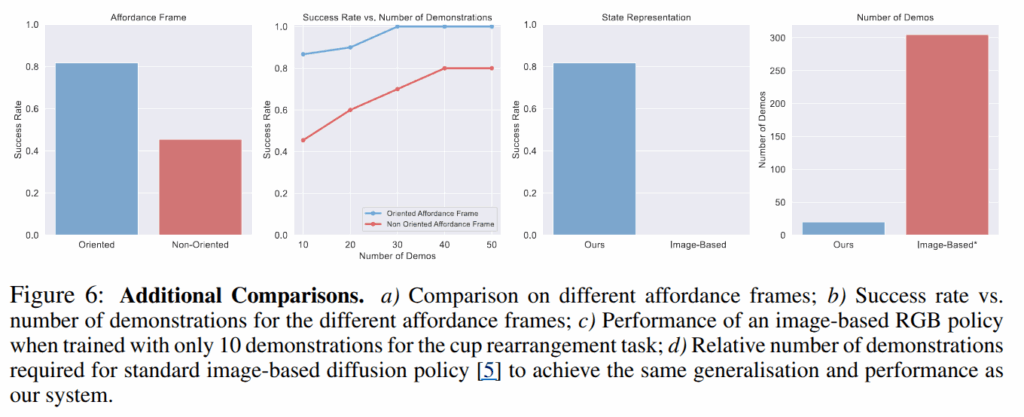
더 나아가, fig 6-1에서는 oriented의 필요성을 보이는 결과, fig 6-2에서는 demo 수에 따른 성공률을 통한 샘플 효율성에 대한 영향력, fig 6-3에서는 영상 기반과의 비교 실험, fig 6-4에서는 images-based policy가 제안한 방법의 성공률을 달성하기 위해서 300 demo를 요구함을 보임
Intra-Category Generalisation: 해당 실험에서는 VFM을 이용, fig 7~8에서는 해당 기법이 intra-categroy에 일반화를 보임을 보이고 있음


Task Composition and Self-Progress Prediction: 더 나아가, self-progress prediction에 대한 실험을 진행했다고 하나, 이에 대한 실패를 관찰하지 못했다고 합니다. 그냥 강건하다고 하네요?…
이해하고 나면 진짜 심플합니다… 하하… 깨어 있는 편이라고 생각했는데 더 깨어져야 할 것 같네요…
태주님 좋은 리뷰 감사합니다.
frame에 대한 변인을 하나 줄이는 방식으로 조금 더 효율적으로 표현하고자 한 것으로 이해하였습니다.
2가지 타입에서 평가한다고 하셨는데, 2) Large Vision Model에 대한 정량적 혹은 정성적 결과는 따로 없는 지 궁금합니다.
또한, 해당 논문이 10개의 Demo로도 장기 작업이 가능하도록 하는 것을 목표로 한다고 하셨는데, 이 10개의 데모 구성이 궁금합니다. 동일 물체와 동일 작업에 대해서 다른 위치에 있는 물체를 조작하여 목표를 달성하는 것일까요? 혹은 이에 대해 설명해주실 수 있을까요??
Q1. 2가지 타입에서 평가한다고 하셨는데, 2) Large Vision Model에 대한 정량적 혹은 정성적 결과는 따로 없는 지 궁금합니다.
A1. 처음부터 끝까지 VFM을 이용한 케이스는 fig 7을 보시면 됩니다. 추가 분석은 Supplementary에도 있으니 보시면 좋을 것 같습니다.
Q2. 또한, 해당 논문이 10개의 Demo로도 장기 작업이 가능하도록 하는 것을 목표로 한다고 하셨는데, 이 10개의 데모 구성이 궁금합니다. 동일 물체와 동일 작업에 대해서 다른 위치에 있는 물체를 조작하여 목표를 달성하는 것일까요? 혹은 이에 대해 설명해주실 수 있을까요??
A2. 10개 데모의 다양성 정도에 대해서 질문을 주신 것 같습니다. 해당 부분에 대해서는 작성된 내용이 없네요.
안녕하세요 태주님 좋은 리뷰 감사합니다.
다시 봐도 참신한 아이디어의 논문이네요!
읽고 데모 영상을 보면서 궁금한 점이 생겨서 질문 드립니다.
어떻게 보면 Self-Progress Prediction이 잘못되면 sub-task가 수행이 안돼서 완전히 잘못될 것 같은데…
데모 영상을 보면 100%가 채워지면 다음 task로 바뀌는 것 같은데 Self-Progress Prediction이 어떤 기준으로 평가가 되는지 궁금합니다.
감사합니다.