안녕하세요 이번에 소개할 논문은 Text-Video Retrieval 모델들의 핵심 모듈인 Cross-modality interaction이 성능에 어떻게 영향을 미치는지에 대한 분석이 부족하다는 것을 문제 정의 삼아 이를 분석하고 새로운 모듈을 제안한 논문입니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
Text-Video Retrieval (TVR)에서는 서로 다른 모달리티 간의 정렬을 맞춰주는 것이 중요한데 이를 위해서는 Intra-modal Representation을 통해 텍스트 자체 또는 비디오 자체의 의미를 학습하는 것이 중요하며, 또한 Cross-modal Interaction 을 통해 이 두 모달리티 간의 의미론적 관계를 정확히 일치시켜주는 과정이 필요합니다.
따라서 대규모 이미지-캡션 쌍으로 학습된 CLIP을 활용하는 연구가 TVR에서는 많이 진행되고 있습니다. 하지만 CLIP은 정적인 이미지를 통해 학습된 모델이고 비디오는 본질적으로 시간의 흐름에 따라 여러 프레임으로 구성된 순차적인 데이터이기 때문에 TVR 태스크에서도 이러한 특성을 고려해야합니다.

저자는 TVR에서 필요한 특성 2가지를 위 그림 1을 통해 설명하고 있습니다.
1. Local Context Assumption
비디오를 설명하는 텍스트는 비디오 전체를 함축하는 내용이 아닌 비디오 내의 특정 구간을 설명하는 내용이 될 수 있습니다. 예를 들어 그림처럼 “남자가 해변에서 오토바이를 탄다”는 쿼리가 비디오의 특정 장면과 일치할 수 있습니다. 따라서 1번 특성에 따라 TVR은 텍스트 쿼리가 비디오의 전체적인 내용뿐만 아니라 특정 시점의 짧은 장면과도 정확하게 매칭될 수 있도록 fine-grained matching이 필요합니다.
2. Semantic Hierarchy Assumption
사람이 비디오에 대해 내용을 서술할때 작성된 문장들은 자연스럽게 계층적인 구조를 가져, 같은 비디오라도 다양한 관점으로 묘사할 수 있습니다. 예를 들어, “여자가 다리에서 떨어진다”는 쿼리와 “MRF 타이어 광고”라는 쿼리 모두 특정 비디오와 관련될 수 있습니다. 따라서 텍스트와 비디오 간의 다양한 의미적 수준에서의 일치(semantic hierarchy matching)가 필요한데, 이는 단일 벡터 특징으로는 표현하기 어렵다고 저자는 말하고 있습니다.
따라서 저자는 기존 방법론들에서 사용하던 interaction에 대해 비교 분석하며, 기존 방식들의 단점을 보완할 수 있는 Token-wise Interaction과 Channel DeCorrelation Regularization을 제안합니다.
2. Method
저자가 제안하는 프레임워크는 위 그림 3에 나와 있습니다.
먼저 텍스트와 비디오 모두에 대해 피처를 뽑고 이에 대해 cross-modality interaction stage(초록색 박스) 에서 Weighted Token-wise Interaction (WTI)을 통해 두 모달리티의 상관 관계를 학습합니다. 추가적으로 특징 벡터의 각 채널 간의 중복성을 줄여 의미론적 관계(semantic hierarchy)를 학습하기 위해 Channel DeCorrelation Regularization (CDCR)(주황색 박스)을 추가하여 성능을 향상시킵니다.
2.1 Feature Extractor
특징 추출에서는 CLIP 인코더를 사용하여 텍스트 피쳐 et = Et(t)와 비디오 피쳐 ev=Ev(v)를 추출합니다.
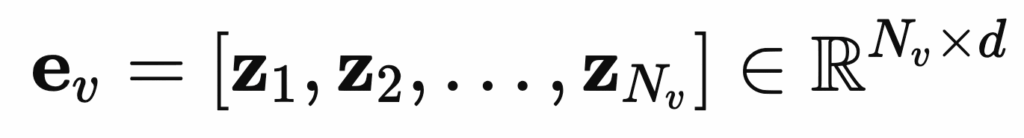
2.2 Study of Interaction Mechanisms
다음으로 각 인코더를 사용해서 추출한 피쳐를 가지고 어떻게 interaction 모듈을 설계할 수 있는지 설명드리겠습니다.
Single Vector Dot-product Interaction (DP)
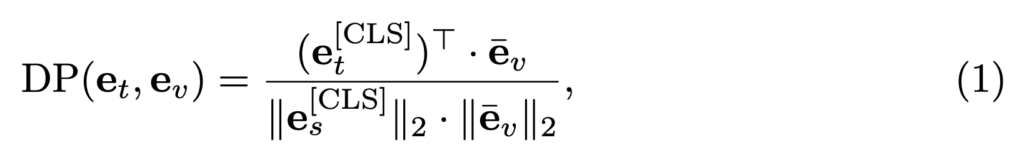
먼저 가장 간단한 방식으로 Single Vector Dot-product Interaction (DP) 방식이 있습니다. 이 방식은 단순한 Dot-product로 유사도를 계산하기 때문에 빠르게 계산할 수 있다는 장점이 있지만 긴 시퀀스 벡터를 단인 벡터로 압축하여 계산하기 떄문에 fine-grained한 정보가 손실될 수 있다는 단점이 있습니다.
Hierarchical Interaction (HI)
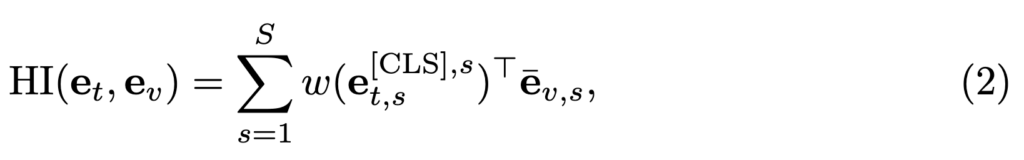
다음으로 Hierarchical Interaction (HI) 모듈은 Multi-level의 피처를 융합하거나 상호작용하여 앙상블 기법으로 유사도를 계산합니다. 이는 더 많은 정보를 가지고 비교할 수 있다는 장점이 있지만 세분화된 정보 학습을 위한 manual annotation 비용이 높다는 단점이 있습니다.
MLP on Global Vector (MLP)
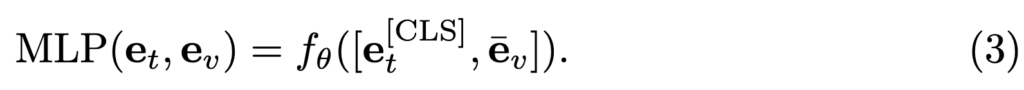
다음은 추출된 Global Vector에 대해 MLP 모듈을 추가설계하여 비선형 관계를 추가하여 유사도를 측정하는 방식이 있습니다. 비선형성을 추가하여 정확도를 높일 수는 있지만, 새롭게 학습해야하는 신경망은 명시적인 규칙이나 inductive bias 없이 데이터로부터 정보를 학습하기 때문에 충분한 supervision이 필요해 labelled data가 많이 필요하다는 단점이 있습니다.
Cross Transformer Interaction (XTI)
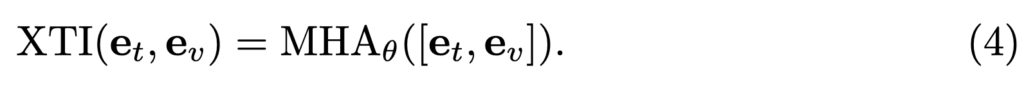
Cross Transformer는 self-attention 기법을 사용하여 텍스트와 비디오 토큰 간의 복잡한 관계를 모델링합니다. 하지만 이 모듈은 최적화하는 것이 어렵고 계산량도 크다는 단점을 가지고 있습니다.
Token-wise Interaction
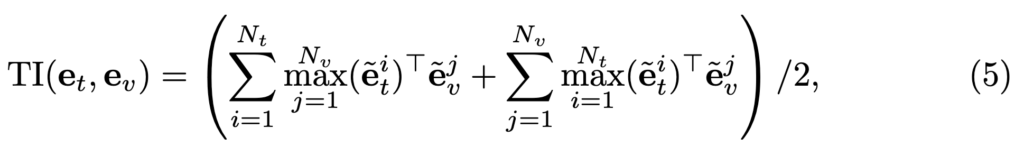
이 방식은 입력 데이터를 하나의 벡터로 압축하지 않고, 데이터를 토큰 단위로 나누어 fine-grained한 매칭을 수행하는 기법입니다. 이 기법은 추가적으로 학습해야할 파라미터도 없어서 MLP나 Cross Transformer 효율적이라는 장점이 있어 저자는 Token-wise Interaction을 기반으로 Weighted Token-wise Interaction (WTI) 모듈을 제안합니다.
Weighted Token-wise Interaction (WTI)
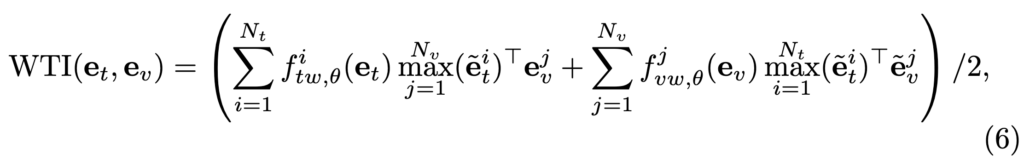
이 모듈은 MLP와 SoftMax 함수로 구성된 ftw,θ와 fvw,θ를 가지고 유사도를 계산합니다.
이 기법은 각 토큰에 대해 가중치 크기를 조정하기 때문에 각 토큰이나 프레임에 서로 다른 가중치를 부여할 수 있습니다.
2.3 Channel Decorrelation Regularization(CDCR)
다음으로 모델이 학습하는 피처의 채널 간의 중복성(redundancy)을 최소화하기 위해 추가된 CDCR 정규화 기법에 대해 설명드리겠습니다.
먼저 크기가 B인 텍스트-비디오 쌍의 배치가 주어지면 WTI 모듈을 통해 B x B 유사도 행렬을 생성합니다. 여기서 InfoNCE loss는 positive 쌍에 대해서는 거리를 가깝게 negative 쌍에 대해서는 거리를 멀게 하는 방식으로 Loss를 계산합니다.
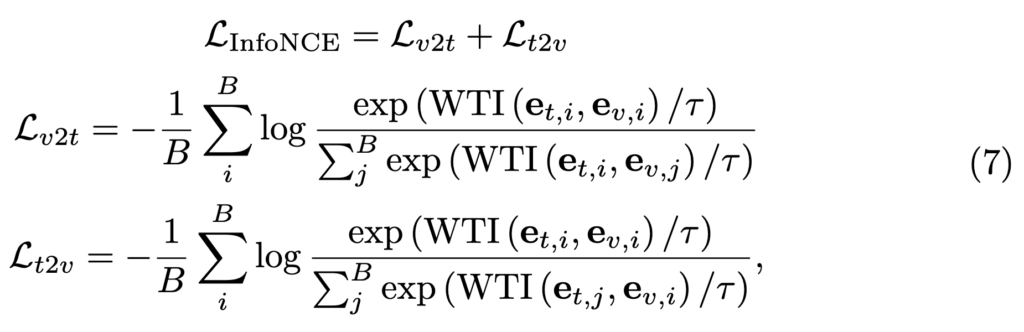
이러한 방식은 거시적인 관점에서 최적화를 진행하기 때문에 저자는 macro objective라고 표현을 하고 있습니다. 하지만 multi-modality retrieval 태스크에서는 이러한 거시적인 정보뿐만 아니라, channel-level과 같은 미시적인 관점(micro-views)에서 얻는 의미론적 정보도 중요하기 때문에 이를 고려하고자 공분산 행렬을 사용합니다.
먼저 피처간의 중복성(redundancy)을 공분산 행렬로 측정합니다. 여기서 ‘중복성’이란 서로 다른 채널(channel)들이 유사하거나 동일한 정보를 담고 있는 것들을 의미합니다.
이러한 중복된 정보를 담고 있으면 비효율적이기 때문에 측정된 중복성을 최소화하기 위해 ℓ2-norm 기법을 사용합니다. 이를 수식으로 나타내면 다음과 같습니다.
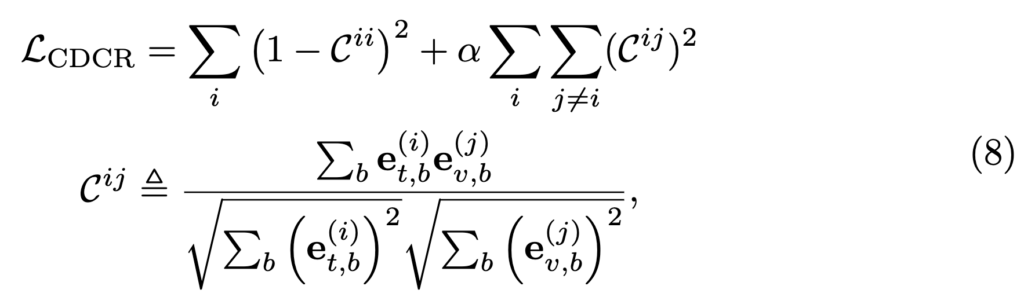
여기서 Cij는 b-번째 배치(batch)에서 텍스트 피처의 i-번째 채널 et,b(i)와 비디오 피처의 j-번째 채널 ev,b(j) 간의 정규화된 공분산(normalized covariance)을 나타냅니다. 이를 통해 각 채널이 고유한 정보를 담을 수 있도록 유도하고 계층적 표현을 학습할 수 있게 합니다.
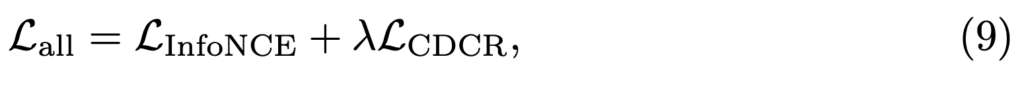
따라서 최종 Loss는 InfoNCE에 CDCR에 가중치를 곱해 정의합니다.
3. Experiments
다음으로 실험 결과를 살펴보겠습니다.
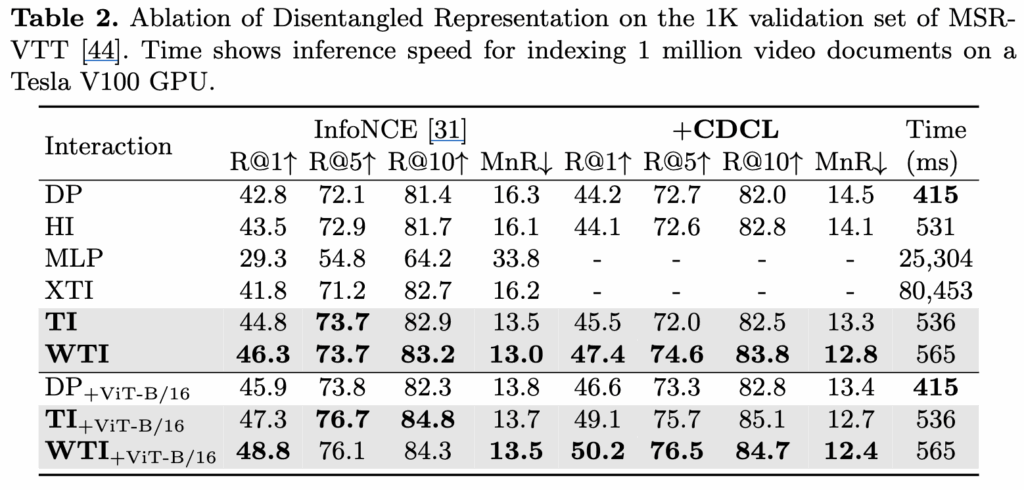
먼저 SingleVector Dot-Product Interaction (DP)과 비교했을 때, Token-wise Interaction (TI)은 dense한 관계만 추가했지만 R@1에서 2.0% 향상된 모습을 보였습니다. 그리고 저자가 제안하는 Weighted Token-wise Interaction (WTI)을 통해서 R@1이 3.5% 향상되는 것을 확인할 수 있고 이를 통해 제안하는 모듈을 통해 텍스트와 비디오의 각 토큰의 중요도를 조절하는 것이 도움이 된다는 것을 확인할 수 있습니다. 그리고 Hierarchical Interaction (HI) 보다도 더 좋은 성능을 보이고 있는데, 이에 대해 저자는 VIT 스타일을 사용하는 모델에서는 multi-level features보다 token representation이 더 중요하기 때문이라고 저자는 설명하고 있습니다.
반면, MLP나 Cross Transformer Interaction(XTI)에서는 오히려 성능이 저하되는 모습을 보이는데, 저자는 이에 대해 이러한 함수들은 어떤 방식으로 매칭이 이루어져야 하는지에 대한 명확한 inductive bias가 부족하기 때문에, 학습 과정에서 최적화가 어려워진다고 분석하고 있습니다.
Effect of Channel DeCorrelation Regularization
다음으로 MLP와 XTI을 제외한 모듈에 대해 CDCR을 적용한 결과를 비교합니다. 표2 를 통해 알 수 있듯이 모든 모듈에서 성능이 향상되는 것을 확인할 수 있고 이를 통해 각 채널에 중복되는 정보를 줄여줌으로써, 더 구분력있는 특징 표현으로 성능이 오르는 것을 확인할 수 있습니다.
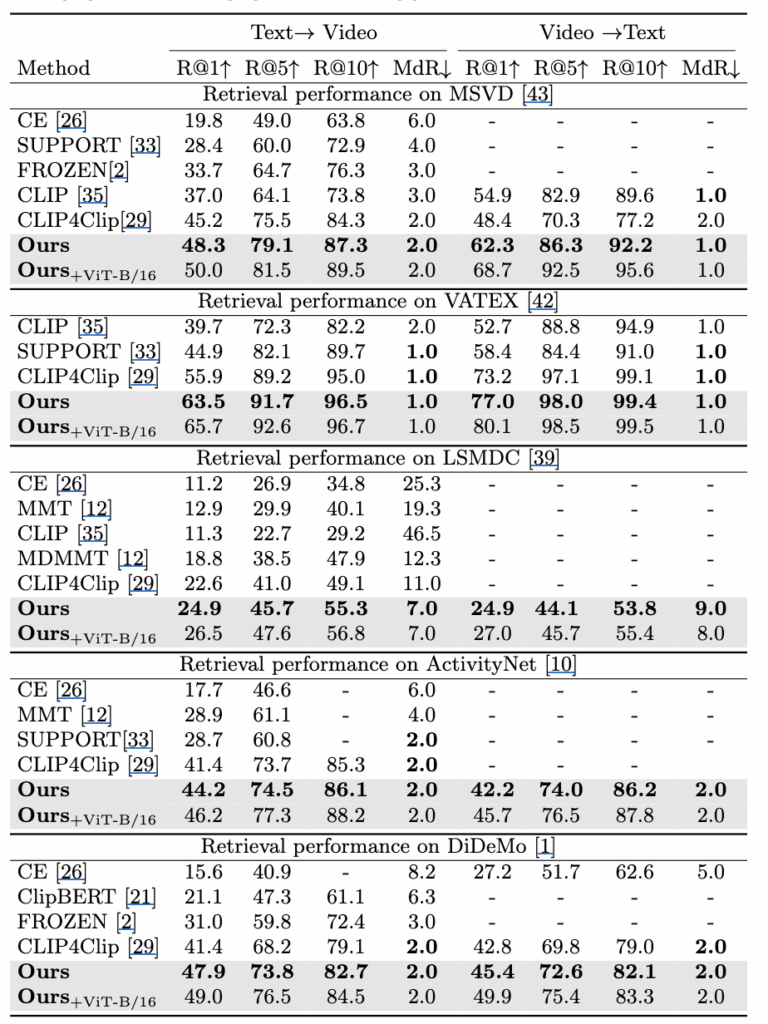
추가적으로 MSVD , VATEX , LSMDC, ActivityNet, DiDeMo 벤치마크 모두에서 일관된 성능 향상을 보여주면서 제안한 알고리즘의 효과를 잘 보여주고 있습니다.
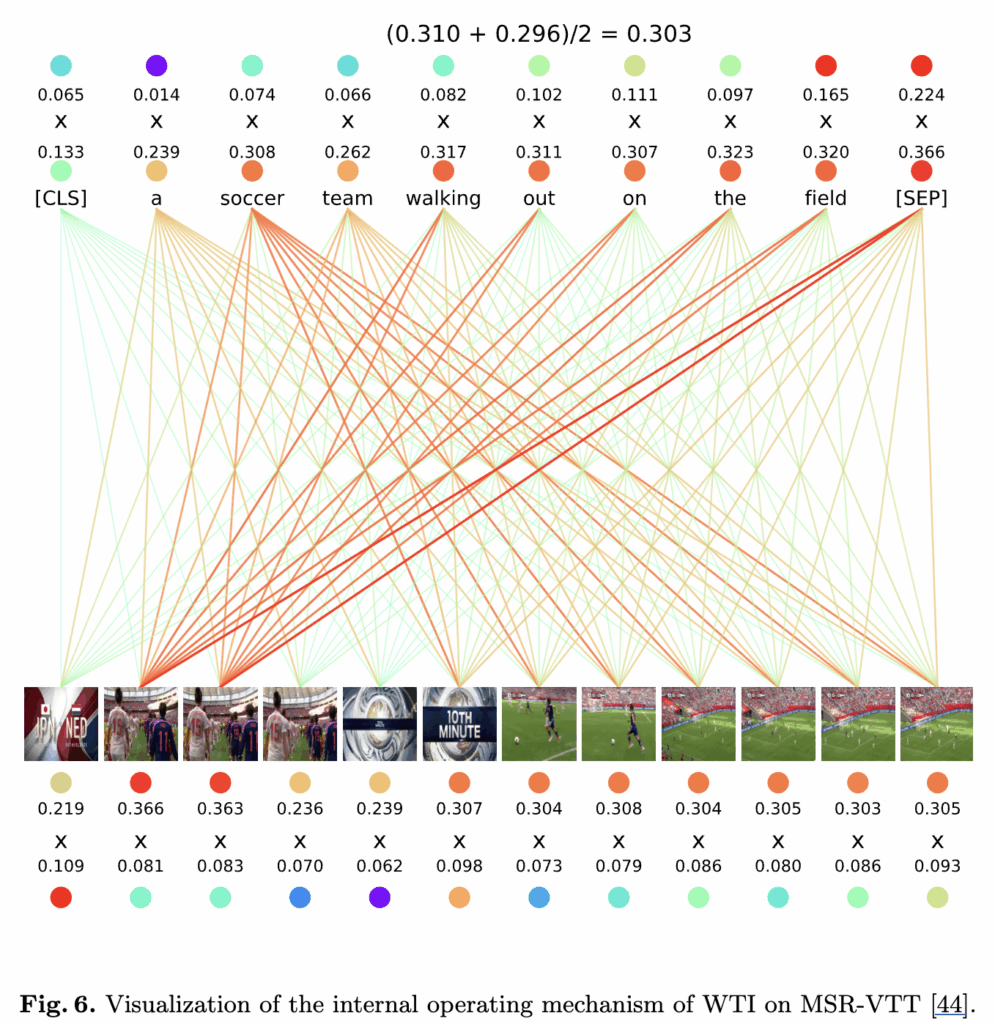
마지막으로 위의 시각화 결과를 통해 논문에서 제안하는 Weighted Token-wise Interaction (WTI) 모듈이 텍스트-비디오 검색에서 어떻게 작동하는지 보여주고 있습니다. 이는 주어진 텍스트 문장과 비디오 프레임 간의 각 토큰의 가중치(weight)가 최종 유사도 점수에 어떻게 기여하는지를 나타내는데 이를 통해 더 세부적인 정보를 활용하는 것을 확인할 수 있습니다.
리뷰 잘 읽었습니다
리뷰 첫 부분에 Local context 가정을 설명하셨는데, 이 논문에서 말하는 “비디오의 특정 구간과 텍스트의 일치”가 실제로 어느 정도 범위를 의미한다고 생각하시나요? (한두 프레임 수준인지, 한 씬 정도인지 궁금하네요)
의철님 안녕하세요 좋은 리뷰 감사합니다.
마침 저도 개인 연구에서의 Cross-modal interaction과 관련하여 결국은 multi-head 기반의 cross attention의 성능이 가장 좋다는 결론을 내리고 있었는데, 다른 interaction 방법들을 살펴볼 수 있어 도움이 많이 된 리뷰였습니다.
1. 2.2절에서 다양한 interaction 방식을 소개해주고 있는데, 실험에서 각 interaction 방식이 어떤 특징을 갖는지에 대한 분석은 따로 하고있지 않나요?
2. 수식 (6), (7)에서 텍스트 토큰에 max()가 취해지는데, 이건 문장 내 단어 중 무엇에 대한 max를 의미하는 것인지도 궁금합니다. (가령 feature의 norm 크기가 max인 것인지, 비디오 global 토큰과의 유사도가 max인 것인지 등)