당분간 최근 Video Text Retrieval 를 정리해보려고 합니다.

- Conference: ICCV 2023
- Authors: Bo Fang, Wenhao Wu, Chang Liu, Yu Zhou, Yuxin Song, Weiping Wang, Xiangbo Shu, Xiangyang Ji, Jingdong Wang
- Affiliation: Chinese Academy of Sciences, The University of Sydney, Baidu Inc., Tsinghua University, Nanjing University of Science and Technology
- Title: UATVR: Uncertainty-Adaptive Text-Video Retrieval
1. Introduction
최근 Text-Video Retrieval 연구는 텍스트와 비디오를 같은 임베딩 공간으로 매핑하여 유사도를 계산하는 방식으로 발전해왔습니다. 하지만 하나의 비디오는 여러 사건과 장면을 포함하고, 하나의 문장도 다양한 수준의 의미를 담고 있기 때문에, 어떤 수준에서 서로를 매칭해야 하는지 명확하지 않은 불확실성(uncertainty) 이 존재합니다.
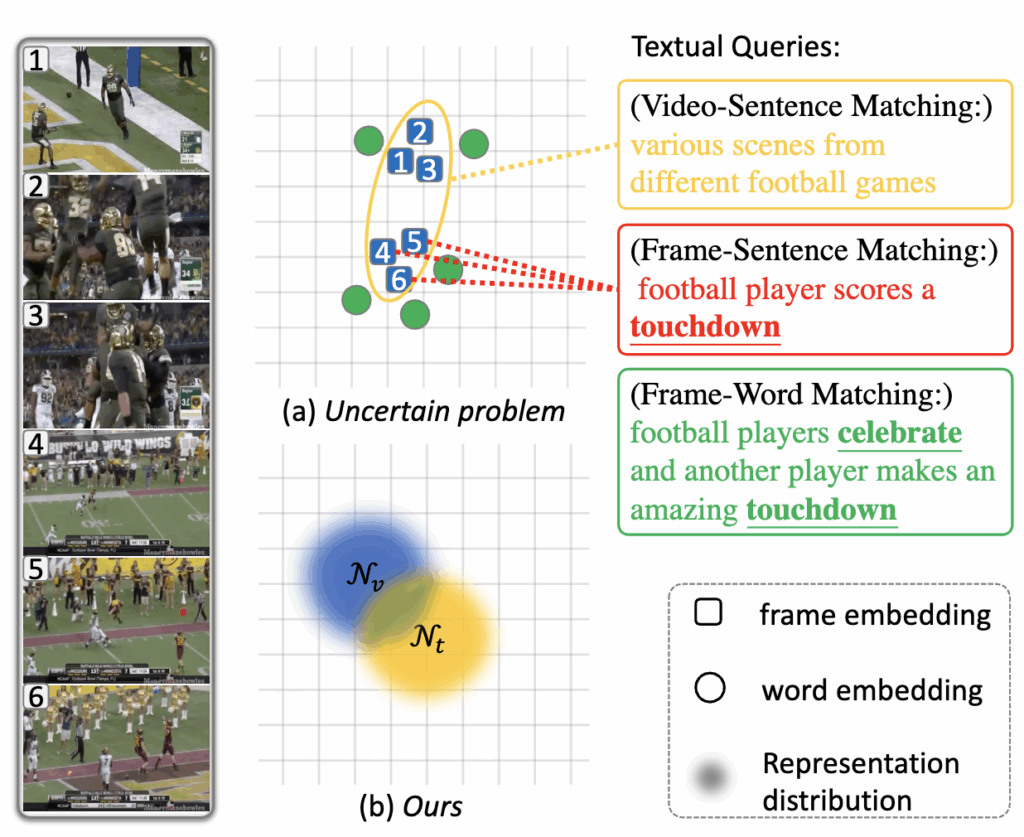
예를 들어, “축구 경기에서 선수가 터치다운을 성공하고 환호한다”라는 문장이 있을 때, 어떤 프레임은 ‘선수의 달리기’를, 또 다른 프레임은 ‘터치다운’이나 ‘환호’ 장면을 보여줍니다. 이때 단어 수준으로 볼 것인지, 문장 수준으로 볼 것인지에 따라 매칭 결과가 달라지게 됩니다. 기존 연구들은 이러한 다양한 수준의 의미 차이를 고려하지 못했죠.
그래서 저자들은 UATVR(Uncertainty-Adaptive Text-Video Retrieval) 을 제안했습니다. 이 모델은 매칭 과정을 확률 분포로 표현하는 새로운 접근을 사용합니다. 즉, 하나의 문장과 비디오를 각각 하나의 점이 아니라 확률적 공간상의 분포로 표현하여, 여러 가능한 의미 조합을 동시에 고려할 수 있게 했습니다. 또한, 모델 내부에 추가 학습 토큰을 넣어 텍스트와 비디오의 여러 수준의 의미를 통합적으로 학습하도록 설계했습니다.
이 방식 덕분에 UATVR은 “하나의 문장–하나의 비디오”로만 생각하던 기존 구조를 벗어나, “하나의 문장–여러 비디오”, 혹은 “하나의 비디오–여러 문장” 같은 현실적인 일대다 관계를 처리할 수 있게 되었습니다. 자세한 리뷰 시작하겠습니다.
2. Method
2.1 Preliminary
Text-Video Retrieval(TVR)은 텍스트와 비디오를 공통 임베딩 공간으로 매핑해, 관련 있는 쌍의 유사도는 높이고 무관한 쌍은 낮추도록 학습하는 것을 목표로 합니다.
텍스트 t_i는 단어 임베딩 [w_i^0, w_i^1, ..., w_i^N], 비디오 v_i는 프레임 임베딩 [f_i^1, f_i^2, ..., f_i^M]으로 구성됩니다. 비디오 전체 표현은 모든 프레임 임베딩을 평균 풀링(mean pooling)한 값으로, 문장은 [CLS] 토큰 w_i^0으로 표현하며, 두 임베딩의 내적을 통해 유사도 s(t_i, v_i)를 계산합니다.
즉, 문장 전체 의미와 비디오 전체 의미를 각각 하나의 벡터로 표현하고, 그 벡터 간의 내적값이 높을수록 두 콘텐츠가 잘 맞는다고 판단하는 기본 구조입니다. 모델은 배치 내 모든 텍스트–비디오 쌍의 유사도를 계산한 뒤, positive pair의 값은 높이고 나머지는 낮추는 CLIP의 InfoNCE Loss 같이 Symmetric Contrastive Loss 로 학습됩니다.
Fine-grained Interaction
하지만 위의 평균 풀링 기반 방식은 모든 프레임을 동일하게 취급하기 때문에, 한 문장이 표현하는 구체적인 순간(예: “점프하는 장면”)을 제대로 반영하지 못합니다. 즉, 비디오에는 여러 사건이 포함되어 있는데 문장은 그중 일부만 설명할 수 있다는 점이 문제이죠.
이를 보완하기 위해 최근 연구들은 다단계(multi-grained) 교차 모달 상호작용 방식을 시도했습니다. 문장–프레임, 단어–프레임, 또는 계층적 구조를 고려해 보다 세밀한 의미 매칭을 수행하려는 시도들이 있었죠.
해당 논문에서는 그중 단어–프레임(word-frame) 단위 매칭 방식을 사용했습니다. 즉, 텍스트의 각 단어 임베딩과 비디오의 각 프레임 임베딩 간 유사도를 모두 계산한 뒤, 양방향으로 최대 유사도를 평균내는 방식으로 전체 텍스트–비디오 유사도를 계산합니다.
결과적으로 이 Fine-grained Interaction 구조는 단순 평균 기반 모델보다 문맥적으로 더 정교한 매칭을 가능하게 합니다. 즉, 문장 속 “핵심 단어”와 비디오 속 “핵심 장면”을 정확히 짝지어주는 역할을 수행하게 됩니다.
2.2. Dynamic Semantic Adaptation
앞서 소개된 단어–프레임 단위 매칭은 세밀한 대응을 가능하게 하지만, 여전히 ‘어떤 수준의 의미를 매칭해야 하는가’라는 불확실성 문제를 해결하지는 못합니다. 이에 저자들은 다양한 의미 수준의 정보를 통합할 수 있는 Dynamic Semantic Adaptation(DSA) 모듈을 제안했습니다.
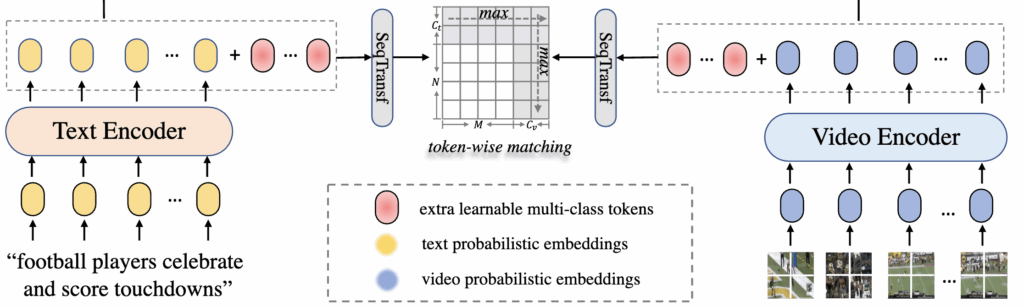
DSA는 텍스트와 비디오 각각에 여러 개의 학습 가능한 토큰(learnable tokens) 을 추가하여, 서로 다른 의미 수준(로컬–글로벌)을 동적으로 통합한다고 합니다. 예를 들어, 비디오의 모든 프레임 임베딩에 추가 토큰 C_v를, 텍스트의 단어 임베딩에 C_t를 삽입해 Transformer로 함께 처리함으로써, 문맥에 따라 더 중요한 의미 수준을 스스로 조정하죠. 상단 그림 중 빨간색으로 된 도형이 추가되는 learnable 토큰입니다
이후 유사도 계산은 기존의 단어–프레임 매칭 방식과 동일하되, 일반 토큰 외에도 추가된 학습 토큰까지 포함해 양방향 최대 유사도를 평균내는 방식으로 확장됩니다.
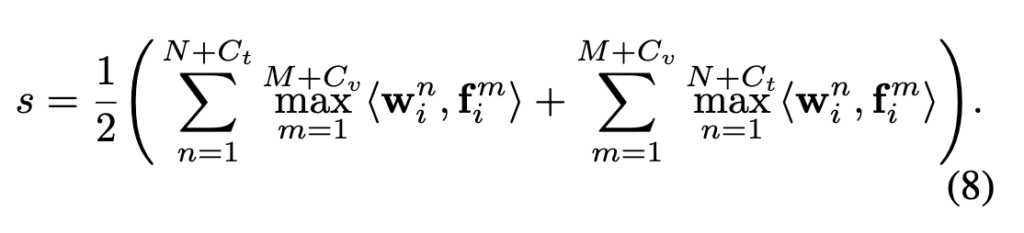
이 과정을 통해 모델은 단순히 단어–프레임 수준에 머무르지 않고, 문맥적·추상적 의미까지 함께 고려해 더 유연하게 매칭할 수 있습니다.
저자에 따르면, 이 모듈은 파라미터 증가가 거의 없고 학습 안정성도 높으며, 결과적으로 기존 Fine-grained 매칭보다 더 강력한 텍스트–비디오 정렬 성능을 보였다고 합니다.
2.3. Adaptive Distribution Matching
앞서의 방식들은 모두 결정론적(deterministic) 매칭에 기반해, 하나의 문장은 하나의 비디오와만 대응된다고 가정합니다. 하지만 실제 데이터에서는 하나의 비디오가 여러 문장으로 묘사될 수 있고, 하나의 문장이 여러 비디오와 연결될 수도 있습니다.
이러한 1:N 관계를 모델링하기 위해, 저자들은 Adaptive Distribution Matching (DUA) 방식을 제안했습니다.
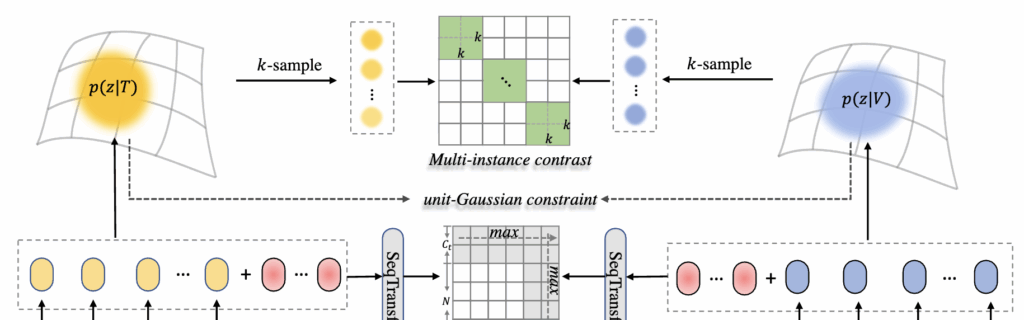
DUA는 텍스트와 비디오를 단일 벡터가 아닌 확률 분포로 표현합니다. 즉, 문장 t_i와 비디오 v_i를 각각 평균 \mu와 분산 \sigma를 가진 정규분포로 모델링하여,
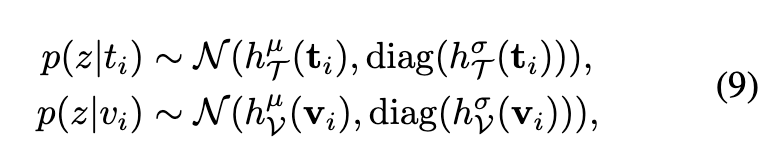
상단 수식에서 h_T와 h_V는 텍스트·비디오 인코더의 출력에 따라 평균과 분산을 계산하는 두 개의 독립적인 헤드 네트워크입니다.
이 분포들에서 여러 샘플(K개)을 추출해 각각을 확률적 임베딩(probabilistic embedding) 으로 사용합니다. 샘플링은 Reparameterization Trick을 이용해 다음과 같이 표현됩니다.
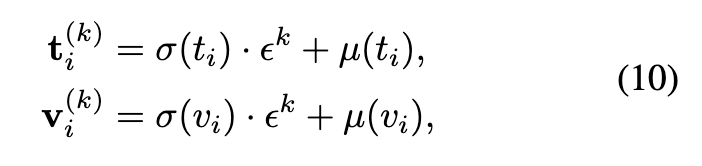
여기서 \epsilon^k \sim \mathcal{N}(0, I) 입니다.
즉, 하나의 텍스트–비디오 쌍으로부터 여러 확률적 표현을 만들어 ‘한 문장이 여러 비디오 묘사를 가질 수 있다’는 현실적인 관계를 시뮬레이션하는 것이라고 이해하면 좋을 것 같네요.
학습은 기존의 InfoNCE 손실을 확장한 Multi-Instance InfoNCE Loss 로 진행됩니다. 각 텍스트 임베딩 t_i^{(k)}에 대해, 해당 비디오의 모든 확률 샘플 v_i^{(k)}을 positive로,
다른 비디오의 샘플들을 negative로 정의합니다. 그 후 모든 조합의 유사도를 계산해 분포 간 불일치를 최소화합니다.
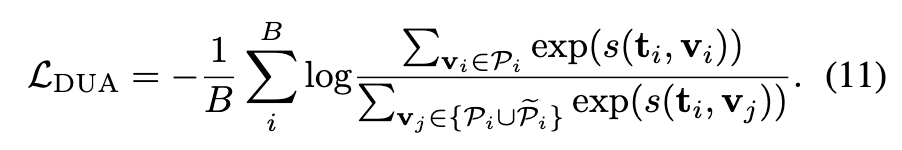
이 방식은 단순히 평균 벡터를 맞추는 기존 방법보다 훨씬 풍부한 확률적 관계를 학습할 수 있으며, 텍스트–비디오 간의 분포 수준 불확실성(uncertainty) 을 자연스럽게 반영할 수 있었다고 합니다. 결과적으로 DUA는 결정론적 매칭이 다루지 못하던 다양한 서술–장면 관계를 학습하게 해준 것이죠
2.4 Total Loss
마지막으로 저자들은 학습의 안정성을 높이기 위해, 추가적인 KL Divergence 손실을 도입했습니다. 이는 텍스트와 비디오 분포가 임의로 퍼지거나 한 점으로 붕괴되는 현상을 방지하기 위함이라고 합니다.
구체적으로, 학습된 확률 분포 p(z|t_i)와 p(z|v_i)가 표준 정규분포 \mathcal{N}(0, I)와 지나치게 멀어지지 않도록 제약을 주는 방식이며, 다음과 같이 정의됩니다.
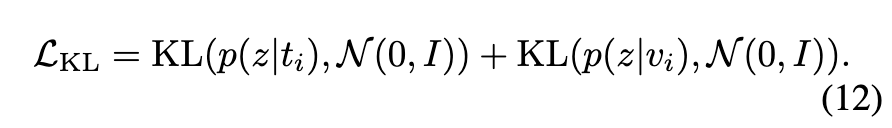
즉, 텍스트와 비디오 임베딩의 분산이 너무 작아져서 모두 같은 점으로 수렴하지 않게 하는 정규화 역할을 합니다.
최종 학습 Loss는 지금까지 제안된 세 가지 Loss 인 Dynamic Semantic Adaptation(DSA), Adaptive Distribution Matching(DUA), 그리고 KL Regularization를 함께 결합한 형태입니다.
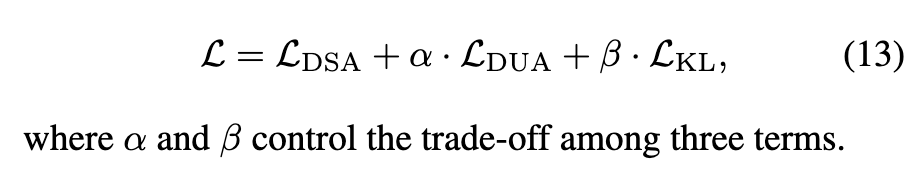
정리하자면, (1) DSA를 통해 의미 수준을 동적으로 조정하고, (2)DUA로 텍스트–비디오 분포 간 불확실성을 학습하며, (3) KL 항으로 학습된 분포의 안정성을 유지하는 것이라고 할 수 있겠네요!
3. Experiment
3.1 Settings
Datasets
MSR-VTT, MSVD, DiDeMo, VATEX
Evaluation Metrics
R@K (K = 1, 5, 10), MdR (Median Rank), MnR (Mean Rank)
3.2 Benchmarks
Table 6 – MSR-VTT 9K
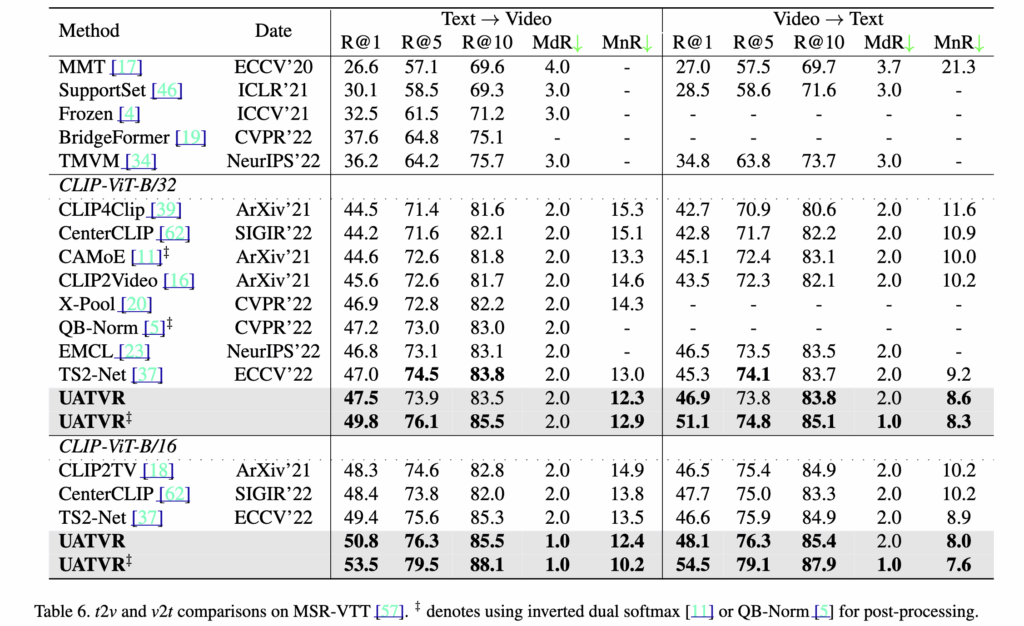
Table 6은 MSR-VTT 1k-A 테스트셋에서 UATVR과 기존 방법들을 비교한 결과입니다. 테이블의 구분은 CLIP 기반 사전학습(Pre-trained) 과 from-scratch 학습 모델이며, UATVR은 CLIP을 활용한 전자의 범주에 속합니다.
ViT-B/32에서는, UATVR은 기존 최고 성능인 TS2-Net을 Text→Video에서 R@1 47.5 → 47.2%, Video→Text에서 R@1 46.9 → 46.5%로 모두 상회했습니다.
ViT-B/16에서는 향상이 더욱 뚜렷한데, R@1이 50.8 %로 1.4% 상승했고, Video→Text에서도 1.5%개선되어 54.5%를 기록했습니다. 또한 MdR 1.0, MnR 12.4로, 검색 오차가 크게 줄어들며 가장 안정적이고 강인한 검색 성능을 보였다고 합니다.
Table 7,8,9 – MSVD, DiDeMo, VATEX
UATVR은 MSR-VTT 외에도 VATEX, DiDeMo, MSVD 세 가지 TVR 벤치마크에서 추가 실험을 진행했습니다. 각 데이터셋에 최적화된 하이퍼파라미터를 사용하지 않았음에도 일관된 성능 향상을 보였습니다.
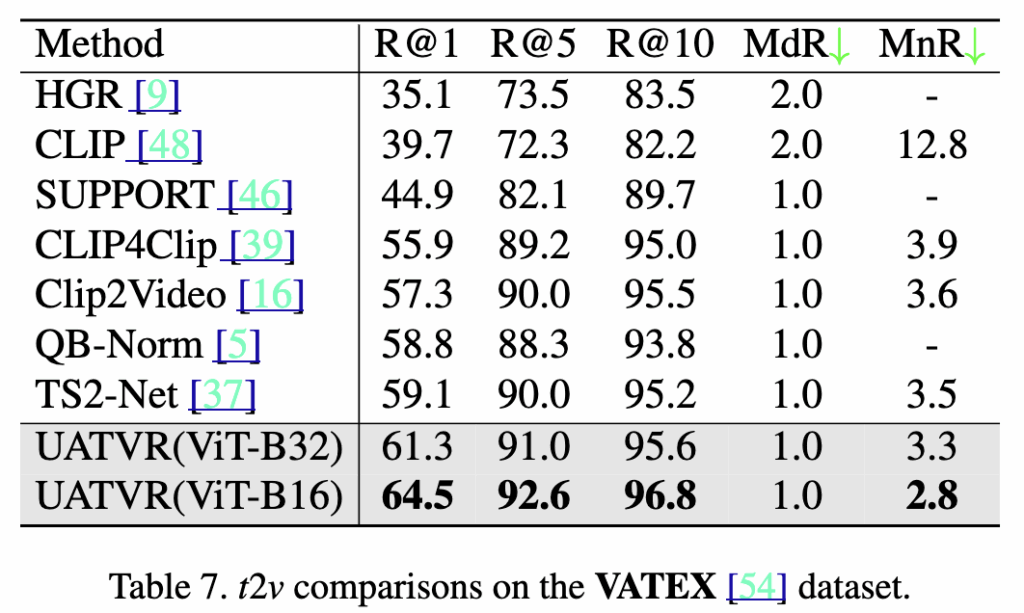
기존 최고 성능인 TS2-Net(R@1 59.1%)을 크게 넘어, UATVR(ViT-B/16) 은 R@1 64.5%, MnR 2.8로 SOTA를 달성했습니다.
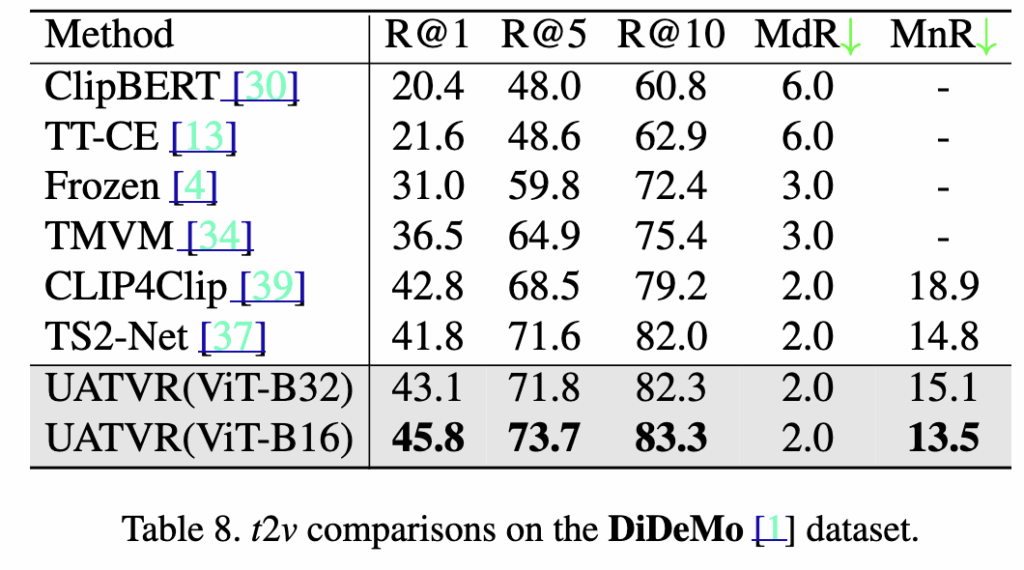
UATVR(ViT-B/16)이 R@1 45.8%, MnR 13.5로, TS2-Net 대비 +1.7% 성능 향상을 기록했습니다.
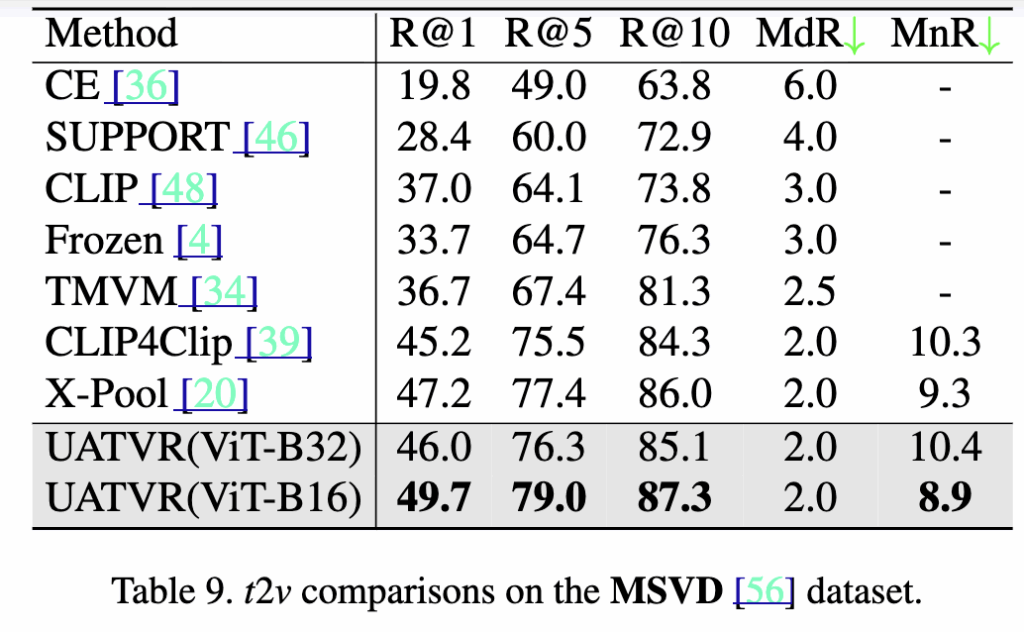
기존 X-Pool(47.2%)보다 높은 R@1 49.7%, MnR 8.9를 달성했습니다.
3.3 Ablation Study
Table 1 – Ablation Study
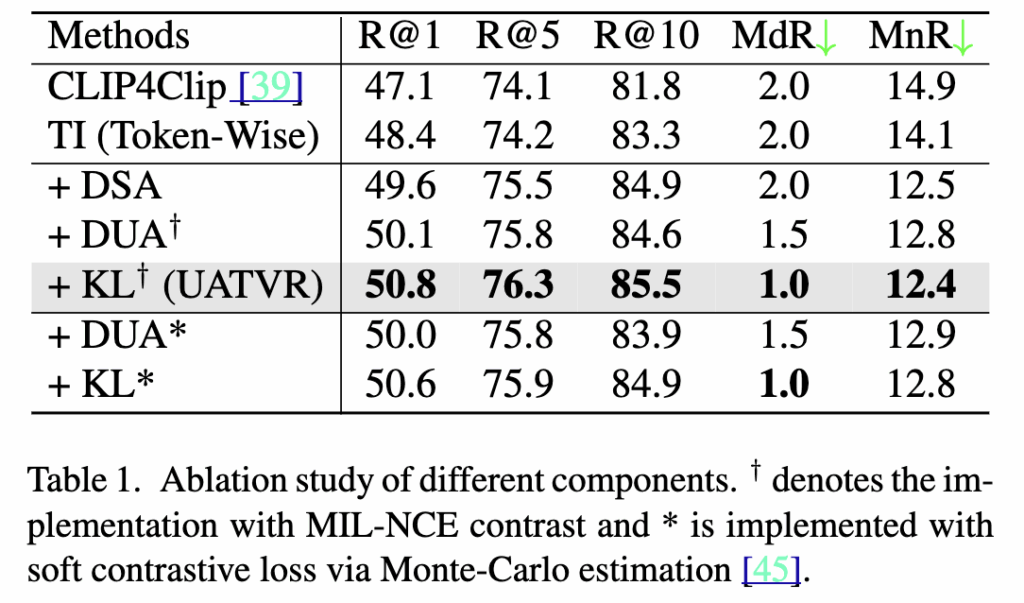
Table 1은 UATVR의 각 구성요소가 성능에 미치는 영향을 보여줍니다. 기본 구조인 Token-wise Interaction(TI) 은 R@1 48.4%를 기록했으며, DSA 추가 시 49.6%, DUA 적용 시 50.1%로 향상되었습니다. 최종적으로 KL 정규화 항까지 포함한 UATVR 전체 모델은 R@1 50.8%, MdR 1.0, MnR 12.4로 최고 성능을 달성했습니다.
이 결과는 제안된 불확실성 적응(uncertainty-adaptive) 접근이 텍스트–비디오 매칭의 정확도를 유의미하게 향상시켰음을 보여줍니다.
Table 2 – Time Complexity and Efficiency Analysis

Table 2는 각 구성요소가 계산 복잡도와 학습 비용에 미치는 영향을 비교한 결과입니다. 기존 CLIP4Clip 대비, Token-wise Interaction(TI) 과 DSA, DUA 모두 약간의 연산량 증가가 있지만, 여전히 한 쌍의 텍스트–비디오 입력에 대해 이차 시간 복잡도(quadratic time)에 머물러 있었다고 합니다.
파라미터 수는 CLIP4Clip 162.3M → DSA 162.8M, DUA 164.9M으로, 증가는 매우 미미하며 (약 1–2M 수준),
학습 시간 역시 75 → 84 GPU hours로 크게 늘지 않았습니다.
다시말해, 추가된 학습 토큰과 분포 모듈이 성능을 향상시키면서도 모델 크기나 시간 복잡도 측면에서는 부담이 거의 없음을 보여줍니다. 따라서 이 실험을 통해 저자들은 UATVR은 단순하면서도 효율적인 구조임을 보였다고 하네요
Table 3 – Effect of Learnable Tokens
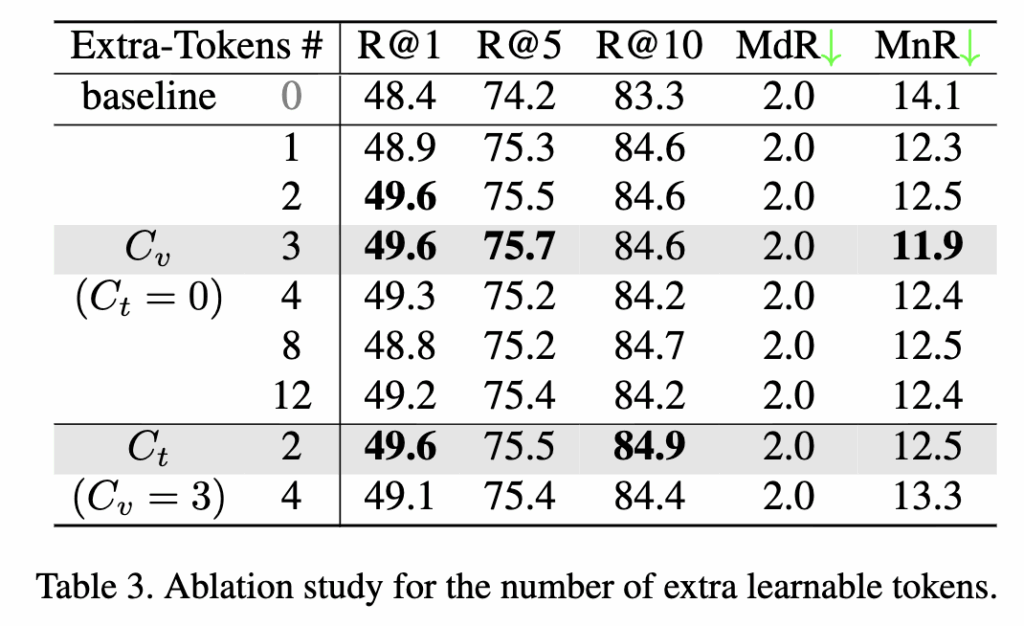
Table 3은 DSA 모듈에서 추가된 학습 가능한 토큰(C_v, C_t)의 개수가 성능에 미치는 영향을 분석한 결과입니다.
비디오 쪽 토큰 수 C_v를 늘리면 성능이 뚜렷하게 향상되며, C_v = 3일 때 R@1 49.6%, MnR 11.9로 최고 성능을 기록했습니다. 하지만 C_v가 4 이상으로 커지면 오히려 성능이 하락했는데, 이는 과도한 토큰이 의미적 대표성을 잃고 잡음(noise)으로 작용하기 때문이라고 하네요.
추가로 텍스트 쪽 토큰 C_t = 2를 더했을 때도 R@1 49.6%, R@10 84.9%로 적절한 개선을 보였습니다. 결과적으로 저자들은 최종 실험 설정을 C_v = 3, C_t = 2 로 설정하였습니다.
Table 4 & Figure 3. Distribution-Based Uncertainty Adaptation
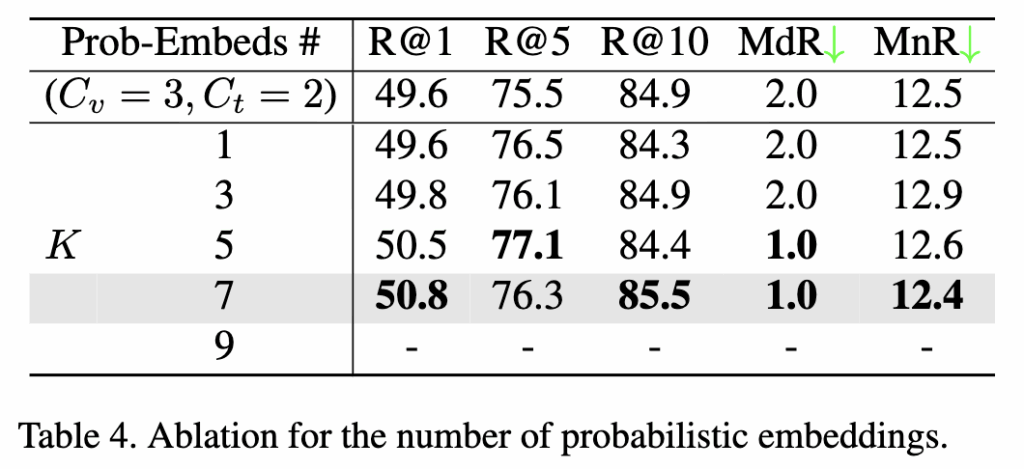
Table 4는 확률 임베딩 수 K에 따른 성능 변화를 보여줍니다. 확률 샘플 수가 많을수록 텍스트–비디오 간 분포를 더 정교하게 모사할 수 있지만, 계산량도 함께 증가합니다.
실험 결과, K=7일 때 R@1 50.8%, R@10 85.5%, MnR 12.4로 최고 성능을 달성했습니다.
K가 너무 작을 경우(1~3) 분포 표현력이 부족하고, 너무 클 경우에는 계산 효율이 떨어지는 것을 확인했습니다.
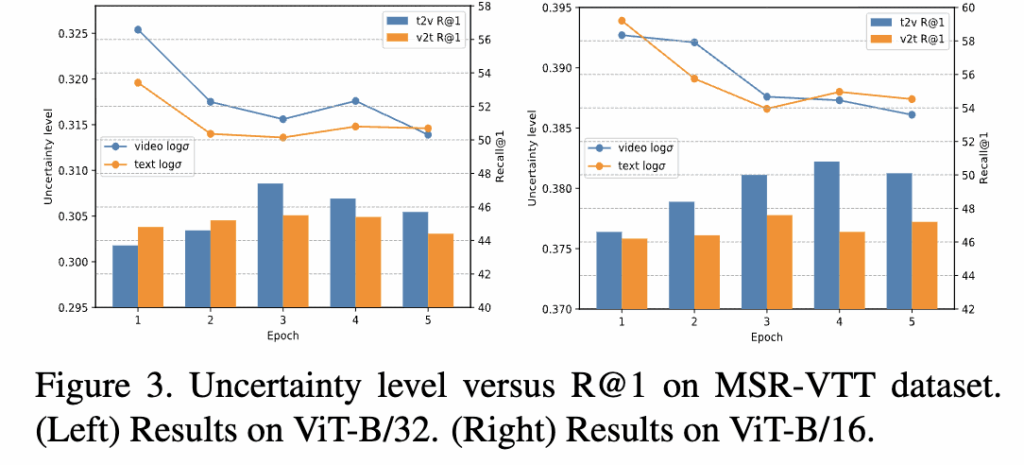
Figure 3은 불확실성 수준(uncertainty level) 과 R@1 성능 간의 관계를 시각화한 결과입니다. 비디오와 텍스트의 표준편차 σ로 계산한 불확실성이 감소할수록, R@1 성능이 꾸준히 향상되는 경향을 보였습니다. 이는 제안된 DUA가 모델이 학습 중 불확실성을 줄여가며 표현력을 높여줍니다.
3.4 Qualitative Results
Fig. 4 – Additional Learnable Tokens의 효과
상단 그림은 추가된 비디오 토큰이 프레임별 attention에 어떤 영향을 주는지 확인한 것입니다.
베이스라인 대비 추가 토큰을 도입하면 텍스트와 의미적으로 더 관련된 프레임에 높은 attention weight를 부여함을 확인할 수 있었는데요, 예를 들어, “some people are dancing”, “a man discusses his choreography of a play” 같은 문장에서 UATVR은 해당 장면(춤추는 프레임 등)에 집중하는 반면, 기존 모델은 덜 관련된 프레임에 분산됨. 즉, 텍스트 의존적 비디오 의미 집약(semantic aggregation) 이 향상된 것을 확인할 수 있었습니다.
Fig.5 – Text-to-Video Retrieval 시각화
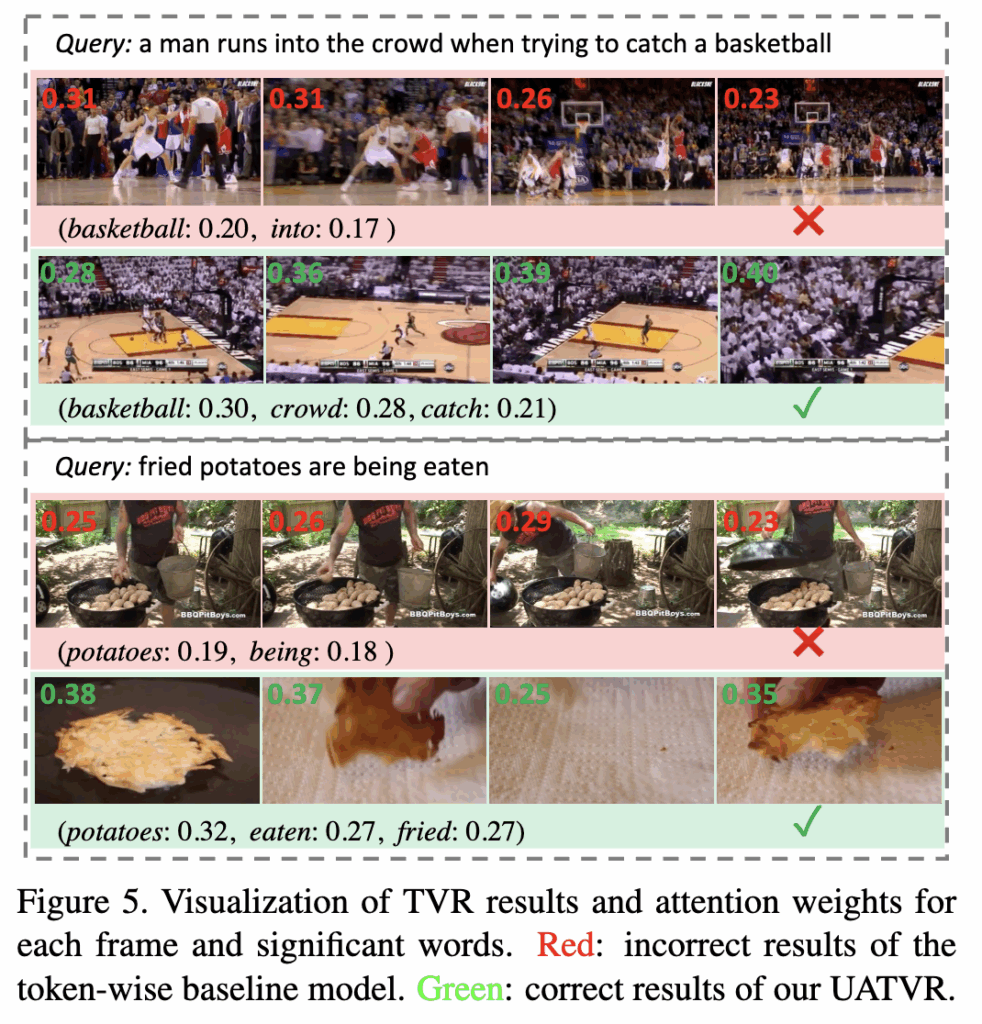
동일 query에 대해 UATVR과 token-wise baseline의 검색 결과를 비교한 그림이비다.
baseline은 basketball, potatoes 등 특정 단어에만 집중해 local context matching에 그치는 것을 볼 수 있는데요. 반면 UATVR은 crowd, fried, eaten 등 여러 개의 단서를 포착해, 복합적 (high-level) 추론 능력 을 보여주었습니다.
4. Summary
저자가 제안하는 UATVR은 기존 Text-Video Retrieval 모델들이 불확실한 캡션이나 다의적 장면에서 정확한 매칭을 수행하지 못하는 문제를 해결하고자 제안된 방법입니다. 이는 세밀한 프레임-단어 수준의 대응만으로는 다양한 의미 단서와 전역 문맥을 동시에 포착하기 어렵다는 한계를 지적하였죠. 따라서 저자는 불확실한 표현을 분포로 모델링하고, 동적으로 의미를 집약하면 보다 안정적이고 강인한 매칭이 가능하다는 가설을 세웠습니다. 이를 위해 추가 학습 토큰(Dynamic Semantic Adaptation)과 확률적 임베딩 기반 불확실성 적응(Distribution-based Uncertainty Adaptation)을 도입해 멀티그레인드 alignment을 수행하였습니다. 다만 데이터셋별 최적 하이퍼파라미터 설정에 민감하며, 모델 복잡도가 증가하는 점은 한계로 남지 않나 싶네요.
안녕하세요 주영님 좋은 리뷰 감사합니다.
모델의 추론 과정과 관련해 질문이 있습니다. 추론 시에는 인코더를 통해 얻은 임베딩 값을 사용하는지, 아니면 확률 분포 네트워크에서 생성된 확률적 임베딩(probabilistic embedding)을 사용하는지 궁금합니다.
추론 단계에서는 확률 분포 네트워크에서 생성된 확률적 임베딩(probabilistic embedding)을 사용합니다. 학습 시에는 각 모달(비디오, 텍스트)에 대해 평균 벡터와 분산을 예측하는 분포 형태의 표현)를 학습하고, 이를 기반으로 Reparameterization trick을 통해 샘플링된 확률적 임베딩을 사용합니다.
즉, 단순히 인코더의 deterministic feature를 사용하는 것이 아니라, 분포 기반 임베딩을 통해 불확실성을 내재한 표현 공간에서 유사도 계산이 이루어지는 것이 핵심이라고 할 수 있죠