안녕하세요. 오늘 리뷰에서는 24년도 AAAI에 게재된 AVQA 관련 논문을 소개해드리겠습니다. 제가 지금 진행중인 실험들과 결이 비슷해 자세히 읽어보게 되었습니다. 바로 리뷰 시작하겠습니다.
1. Introduction
Audio-Visual Question Answering은 비디오의 시각 정보와 음성 정보를 활용해 입력된 텍스트 질문에 대한 올바른 정답을 내뱉어야하는 task입니다. Audio-visual이 함께 관여하는 task는 AVQA 이외에도 audio-visual segmenation, audio-visual event localization 등이 있는데 이들은 오디오를 기준으로 spatial, temporal 정보 각각을 잘 파악하는 것이 목적입니다.
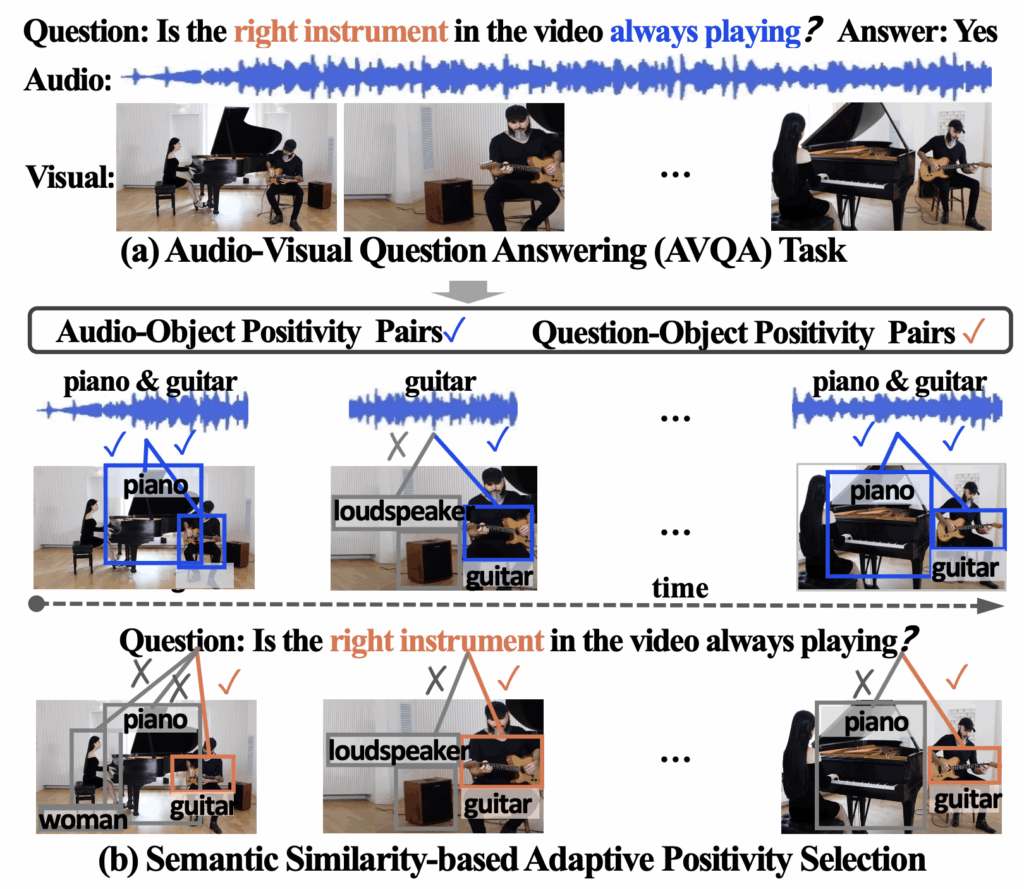
반면 AVQA는 질문이라는 text 모달리티가 추가되기에 이 질문을 기준으로 오디오와 비디오의 spatio-temporal 정보를 동시에 이해할 수 있어야 합니다. 앞선 두 task도 spatio-temporal 정보를 동시에 봐야하긴 하겠지만, AVQA가 특히나 두 특성을 동시에 모델링해야한다는 것이 저자의 의견입니다. 위 그림 1-(a)의 AVQA 설명을 보시면, “Is the right instrument in the video always playing?”이라는 질문에 올바른 대답을 하기 위해 ‘오른쪽 악기’인 기타를 공간 축에서 잘 찾고, ‘항상 연주되는지’ 파악하기 위해 시간 축에 동시에 집중해야하는 것입니다.
이러한 AVQA를 잘 수행하기 위해 저자는 비디오 속 object에 집중합니다. 이때 저자가 object에 집중하는 이유는 아래와 같습니다.
- 객체는 근본적으로 human cognition의 기본 단위
- 대부분의 소리는 객체로부터 발생하기에 질문과 연관성을 잇기 좋음
- 객체는 시각적으로 명확한 형태를 갖기 때문에 공간축에서 분리하기 쉬움
위와 같은 이유로 본 논문은 object를 키워드 삼아 방법론을 설계하며, 좀 더 세부적으로는 각 프레임에서 1) 어떤 객체가 지금 소리를 내고 있는지(audio-object), 2) 어떤 객체가 질문과 관련있는지(question-object)를 명확히 모델링 하는것이 목적으로 삼게됩니다.
여기까지 정리했을때, 본 논문은 기존 방법론에 큰 부족함이나 문제가 있어 이를 지적하며 출발하는 논문은 아닌 것으로 보이고, 기존 방법론에서 더 나아가 AVQA에 object라는 개념을 명시적으로 도입해보겠다는 컨셉으로 이해해볼 수 있습니다. 바로 방법론으로 넘어가기 전, 그래서 어떤 모듈들을 제안하는 것인지 간단히 설명드리겠습니다.
우선 사람이 AVQA를 수행한다고 생각해보았을때, 먼저 질문을 잘 읽고 비디오와 오디오로부터 무슨 정보에 집중해야하는지 이해해야 합니다. 이를 이해했다면 다음으로 그 정보를 비디오와 오디오에서 찾고, 찾아낸 정보를 잘 엮어 최종 답변을 내뱉게 될 것입니다. 아까 보여드렸던 위 그림 1-(b)로 설명드리면, 질문 중 “right instrument”에 집중하여 이것이 비디오에서 기타임을 인지하고, “always playing”에 집중하여 오디오를 시간 축 전반에 걸쳐 들을 것입니다. 이러한 정보를 취합한 후 “yes”라는 답을 내놓을 수 있게 되는 것이죠.
저자는 위와 같은 과정을 모델에도 그대로 적용시켜줍니다. 먼저 Question-conditioned Clue Discovery (QCD) 모듈을 도입하여 질문 속 오디오, 비디오 모달리티와 관련된 키워드를 뽑아내게 됩니다. 실제로 자연어 수준에서 뽑는 것은아니고 단순히 cross attention을 통해 유의미한 단어를 강조하는 형태이긴 합니다. 이후 Modality-conditioned Clue Collection (MCC) 모듈에서는 키워드가 강조된 문장을 토대로 오디오, 비디오에서 질문과 유관한 부분을 다시 강조해주는 것입니다. 이 MCC 모듈도 마찬가지로 cross attention을 통해 수행됩니다. 이러한 두 모듈을 통해 오디오, 비디오, 텍스트 간 multi-modal relation을 파악하게 됩니다.
다음으로, 논문의 핵심 키워드인 object-aware adaptive positivity learning 기법이 등장합니다. 우선 본 기법의 목적은 cross-modal feature 강화를 guide하기 위함입니다. 저자는 object에 초점을 맞추어 방법론을 설계한다고했는데, 그림 1-(b)의 가운데 프레임을 보시면 질문과 관련 없는 “loudspeaker”가 존재하는 것을 볼 수 있습니다. 질문과 오디오 모두에 무관한 방해요소 객체가 등장한 것이죠. 이렇게 질문/오디오와 비디오 속 객체의 유사도를 고려해 객체의 positivity를 따지게 됩니다. Question-object 쌍 관점으로, 또 audio-object 쌍 관점으로 얼마나 유관한지를 positivity로 정의한다는 의미입니다. 앞서 나온 loudspeaker는 두 모달 관점에서 positivity가 낮은 객체일 것이고, 대조학습을 통해 유사도가 낮아지도록 학습하는 것입니다.
그림 1-(b)에서 파란색 박스는 question-object postivity가 높은 객체들, 주황색 박스는 audio-object positivity가 높은 객체들을 의미합니다. 사전 정의한 threshold보다 feature similarity가 높으면 positivity pairs, 낮으면 negativity set으로 포함시키는 것입니다.
이렇게 positivity, negativity 객체를 지정하였다면, 이후엔 대조학습을 통해 positive끼린 가깝게, negative끼린 멀게 임베딩 공간을 조정해줍니다. 이 대조학습을 수행할때 spatial 축에서는 질문/오디오와 관련된 여러 객체가 positive로 선택될 수 있고, temporal 축에서는 positive 객체 집합이 시간이 지남에 따라 동적으로 변화하게 됩니다. 이 기법을 통해 모델은 객체 관점에서 유관/무관한 특징을 잡아낼 수 있게 되고 결국 audio-visual scene understanding 능력이 향상되게 되는 것입니다.
이제 contribution을 정리하고 방법론으로 넘어가겠습니다.
Contributions
- The first to explore the fine-grained audible object clues in the AVQA task and present an object-oriented network
- Propose an object-aware adaptive-positivity learning strategy including two contrastive loss
2. Methodology
각 모달 인코더로부터 feature를 추출하고, multi-modal feature interaction을 수행하는 과정과 방법론의 핵심인 object-aware adaptive-positivity learning 기법 순서대로 작성해보겠습니다. Introduction에서 각 모듈의 motivation은 자세히 설명드렸으니 forward 흐름 위주로 간단하게 설명드리겠습니다.
우선 QCD 모듈을 거쳐 키워드를 반영한 특징을 만들어주고, 중간에 이를 활용해 positivity 관련 대조학습을 수행합니다. 최종적으로는 앞선 QCD 모듈에서 나온 feature를 MCC 모듈에서 정답을 만들어내는 순서네요.
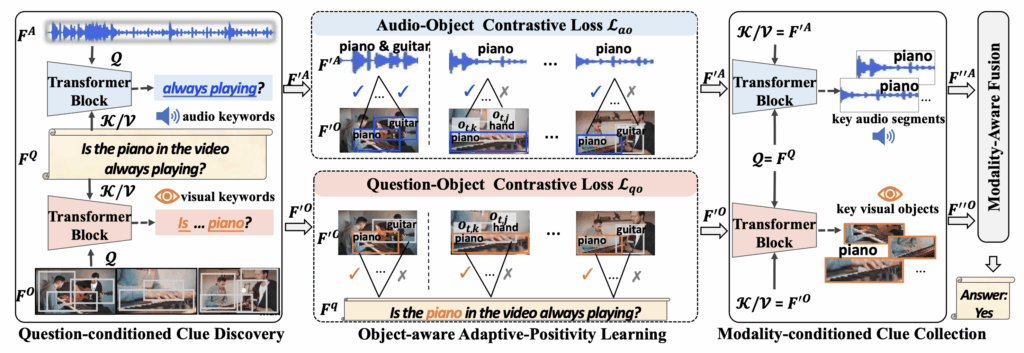
2.1 Backbone Network
비디오를 입력받아 먼저 T개의 segment로 쪼개게 됩니다. 각 segment로부터 오디오 feature F^{A} \in{} \mathbb{R}^{T \times{} d}, 객체 feature F^{O} \in{} \mathbb{R}^{T \times{} N \times{} d}를 추출합니다. 여기서 N은 한 segment에서 DETR이나 Faster R-CNN과 같은 off-the-shelf object detector가 뽑은 객체의 임베딩 feature를 의미합니다. 다른 방법론들처럼 ResNet이나 CLIP으로부터 frame feature, patch feature를 뽑아 쓰지 않고 오로지 객체 영역의 feature만을 가져오는 것이 특이한 점이라고 볼 수 있습니다.
다음으로 질문에 대해서는 LSTM을 통해 word-level feature F^{Q} \in{} \mathbb{R}^{L \times{} d}, sentence-level feature F^{q} \in{} \mathbb{R}^{1 \times{} d}를 얻을 수 있습니다. 여기서 L은 질문 내 단어 토큰의 개수를 의미합니다.
이렇게 추출한 3가지 모달리티의 feature들은 Question-conditioned Clue Discovery (QCD) 모듈에 먼저 입력됩니다.
2.1.1 Question-conditioned Clue Discovery
QCD 모듈은 사람의 AVQA 수행 과정을 따라 먼저 질문에 답하기 위해 어떤 키워드에 집중해야하는지 파악하는 역할입니다. 단순한 cross attention 연산으로 구성됩니다.
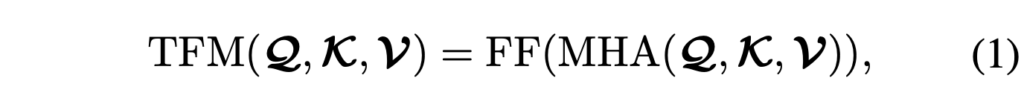
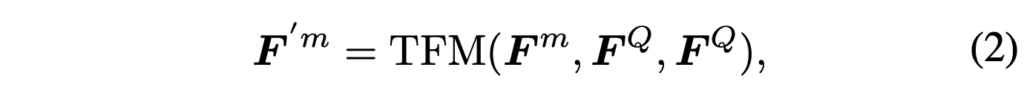
기본적으로 수식 (1)에서 TFM은 Transformer encoder를 의미합니다. 수식 (2)에서 m \in{} \{O, A\}로 객체와 오디오 feature에 대한 notation을 의미합니다. 즉 객체와 오디오의 feature F^{O}, F^{A}를 Query, word-level feature F^{Q}를 cross attention의 Key, Value로 두고 F'^{O} \in{} \mathbb{R}^{T \cdot{} N \times{} d}, F'^{A} \in{} \mathbb{R}^{T \times{} d}를 얻는 것입니다. 질문에 포함된 단어 중 집중하면 좋을 키워드(‘right instrument’, ‘always playing’)를 뽑아 이를 반영한 객체와 오디오 특징을 만들어준 것이죠.
2.1.2 Modality-conditioned Clue Collection
MCC 모듈에선 키워드를 기준으로 enhance된 객체와 오디오 특징 F'^{m}을 다시 활용합니다. F'^{m}을 이젠 Key, Value, sentence-level feature F^{Q}를 Query로 두고 아래 수식 (2)와 같은 cross attention을 수행합니다.
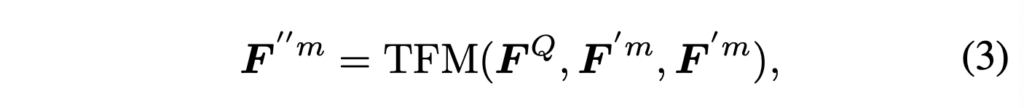
수식 (3)에서 얻은 F''^{m} \in{} \mathbb{R}^{L \times{} d}로, 질문이 오디오와 객체 특징에서 어떤 단서에 집중해야하는지 파악하는 역할이라고 보시면 좋을 것 같습니다. 본 모듈에선 앞선 예시에 따르면 객체 특징에서 ‘right instrument’가, 오디오 특징에서 ‘always playing’이 발생하는 부분에 attention을 크게 주며 aggregate 되도록 학습될 것입니다.
2.1.3 Modality-Aware Fusion
사람의 AVQA cognition 과정을 모방한 QCD, MCC 모듈을 거쳐 얻은 특징으로 이제 최종 답변을 만들어야 하는 단계입니다. 이때 특정 질문은 오디오와 visual중 하나의 모달리티에 좀 더 집중할 수 있기에 이를 위한 modality-aware weight vector \beta{} \in{} \mathbb{R}^{1 \times{} 2}를 만들어줍니다. 만드는 과정은 단순히 질문 feature F^{Q}를 FC layer + Softmax에 태워주는 것입니다.
이어서 MCC 모듈에서 얻은 F''^{O}, F''{A}는 앞서 얻은 2개의 scalar \beta{}만큼 곱해지고 다시 FC layer에 태워 최종 fused feature f_{out} \in{} \mathbb{R}^{1 \times{} d}로 변환됩니다. 정답 예측은 이 f_{out}을 다시 FC layer에 태워 정답 vocabulary 차원으로 내리고, argmax를 통한 분류로 이루어집니다.
2.2 Object-aware Adaptive-Positivity Learning
단순한 Cross-entropy로 분류학습을 수행하는 기존 방법론들과 달리, 본 논문에선 모델에게 semantic positivity를 이해시키고자 합니다. 기본적으로 질문/오디오와 유관한 객체는 강조, 무관한 객체는 약화하는 방향으로 학습해야겠죠. 앞서 말씀드렸듯 무관 및 유관은 feature 간 유사도와 사전 정의된 threshold로 결정됩니다.
질문과 오디오 중 질문에 대한 positvity learning을 예시로 설명드리겠습니다. 전체 T개 중 번째 segment에 대해, sentence-level feature q = F^{q} \in{} \mathbb{R}^{1 \times{} d}와 객체 feature \{o_{t}\}_{i=1}^{N} = {F'_{t}}^{O} \in{} \mathbb{R}^{N \times{} d} 간 유사도 계산을 수행합니다. \{o_{t}\}는 결국 한 segment에서 추출한 객체 embedding들이라고 볼 수 있습니다.
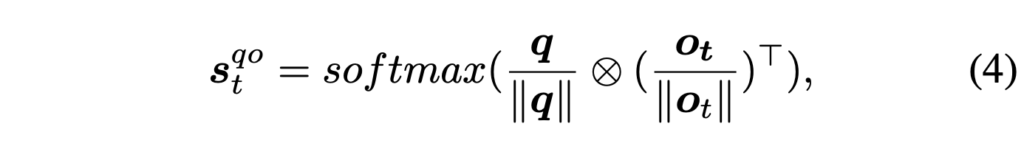
수식 (4)에서 얻은 s_{t}^{qo} \in{} \mathbb{R}^{1 \times{} N}는 한 segment 내 객체들과 질문간의 코사인 유사도를 의미합니다.
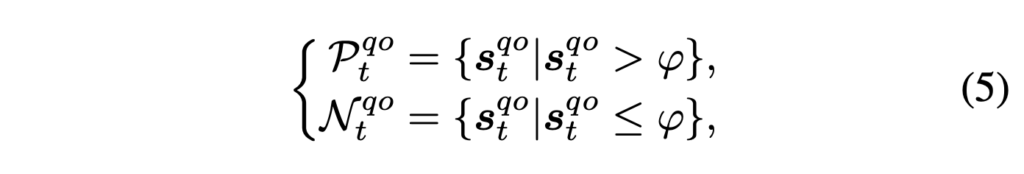
이 때 유사도가 사전 정의한 threshold \varphi{}보다 크면 해당 객체는 positivity pair \mathcal{P}_{t}^{qo}로, 작으면 negativity set \mathcal{N}_{t}^{qo}로 들어가게 됩니다.
만약 \mathcal{P}_{t}^{qo}로 들어간 객체가 K개라면, \mathcal{N}_{t}^{qo}로 들어간 객체는 자연스럽게 N-K개가 될텐데, 이 포인트를 두고 저자는 객체가 adaptive하게 선택된다고 이야기합니다. 처음 글을 읽었을땐 선택되는 개수가 adaptive할 뿐 \varphi{}는 직접 정해줘야하기에 완전한 adaptive라 보기엔 어려운 것 아닌가? 하는 생각이 들었는데요.
여기서 adaptive라는 키워드에 대해, 저자는 spatial 축, temporal 축에 따라 보충 설명을 해줍니다. 먼저 spatial 축에 대해서, 학습 초반에는 모델이 무엇이 진정 question-related 객체인지 분간하지 못해, 즉 유사도가 크게 유의미하지 않아 실제로는 negative인 객체도 다수 positive에 넣게 된다고합니다. 그러나 학습이 진행될수록, 질문 feature가 오디오, 비디오 정보를 보고 개선되며 실제로 관련있는 object만 positive하게 담기기에 adaptive라고 주장하는 것이었습니다.
다음으로 temporal 축에서는 매 segment 별로 question과 유관한 object가 다를 수 있습니다. 예를 들어 질문에 기타라는 악기가 언급된다고해서 기타가 언제 등장하든 무조건 유관하다고 지정하는 것은 suboptimal할 수 있습니다. 예를 들어 “기타 왼쪽에 있는 악기는 기타보다 소리가 큰가?”와 같은 질문도 실제 데이터셋에 포함되어있는데, 초반엔 기타에만 집중하더라도 학습함에 따라 기타 왼쪽에 있는 악기에도 점점 집중할 수 있어야 하며 동시에 손과 같은 무관한 객체는 유사도를 낮춰야 하는 것이죠. 제안하는 방식이 학습이 진행됨에 따라 이러한 특성을 가지기에 adaptive하다고 설명하고 있습니다.
아무튼 positivity, negativity set을 정의하였으면 이제 대조학습을 해야겠죠. 이 대조학습에 사용되는 question-object positivity contrastive loss \mathcal{L}_{qo}에 대해 알아보겠습니다.
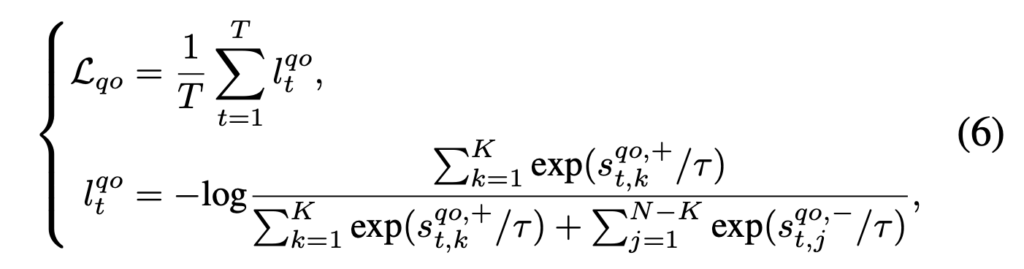
Contrastive loss \mathcal{L}_{qo}는 위 수식 (6)과 같으며, 다들 잘 아시는 수식이라 자세한 설명은 넘어가겠습니다. 식에서 +를 달고있는 샘플은 \mathcal{P}, -를 달고있는 샘플은 \mathcal{N}에 속하는 것입니다.
위와 동일한 과정으로 각 세그먼트에서의 audio를 기준으로 N개의 객체와 audio-object positivity contrastive loss \mathcal{L}_{ao}를 구할 수 있고, 최종 positivity learning loss \mathcal{L}_{pc} = \mathcal{L}_{qo} + \mathcal{L}_{ao}로 구성됩니다.
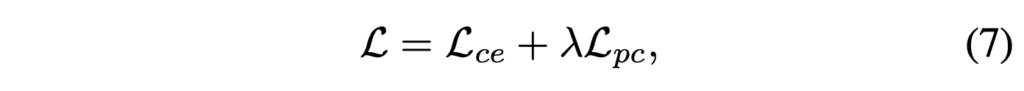
앞서 2.1.3에서 얻은 정답에 대한 Cross Entropy loss \mathcal{L}_{ce}와 더불어 모델 학습에 사용되는 최종 loss는 위 수식 (7)과 같습니다.
3. Experiment
이제 방법론에 대한 설명은 마치고, 실험 결과를 살펴보겠습니다.
3.1 Experimental Setup
신기하게도 본 논문은 MUSIC-AVQA 데이터셋 하나만을 벤치마크에 사용하고 있습니다. MUSIC-AVQA 데이터셋은 총 150시간 길이의 9,288개 비디오, 45K개의 QA 쌍으로 이루어진 대용량 데이터셋입니다. 각 질문은 existential, counting, location, comparative, temporal 이라는 5개 타입으로 분류됩니다. 기본적으로 분류 task이기 때문에 평가지표는 정확도입니다.
DETR, Faster R-CNN과 같은 object detector를 가져오기 때문에 관련 implementation detail을 설명드리겠습니다. 논문에서 정확한 언급은 없는데, 아마 off-the-shelf object detector라고 이야기하는 것을 보니 COCO 등으로 사전학습된 모델을 가져와 MUSIC-AVQA 데이터셋의 비디오 프레임들에 detection을 돌려 객체 박스 정보를 얻어온 것으로 보입니다.
Faster R-CNN에서는 프레임 당 36개 객체, DETR에서는 프레임 당 100개의 객체를 가져왔습니다. 또한 두 detector의 임베딩 공간이 다르기 때문에 pre-set threshold를 Faster R-CNN은 0.025, DETR은 0.011로 설정하였다고 합니다. 이 threshold는 리뷰엔 담지 않겠지만 0.000x 단위로 ablation이 이루어지는 것으로 보아 작은 scale에서 민감하게 성능에 관여하는 수치였습니다.
3.2 Comparison with State-of-the-args

아무래도 24년도 AAAI 방법론이다보니 비교되는 기존 모델들이 많지 않습니다. 기존 SOTA 모델인 COCA보다 저자가 제안하는 APL(Adaptive-Positivity Learning)이 전반적으로 더욱 높은 성능을 보여주고 있습니다. 특히 오디오와 visual 정보를 모두 잘 봐야하는 AV-QA 파트에서 기존보다 1% 높은 성능을 달성하며 APL의 강점이 드러나고 있는 모습입니다.
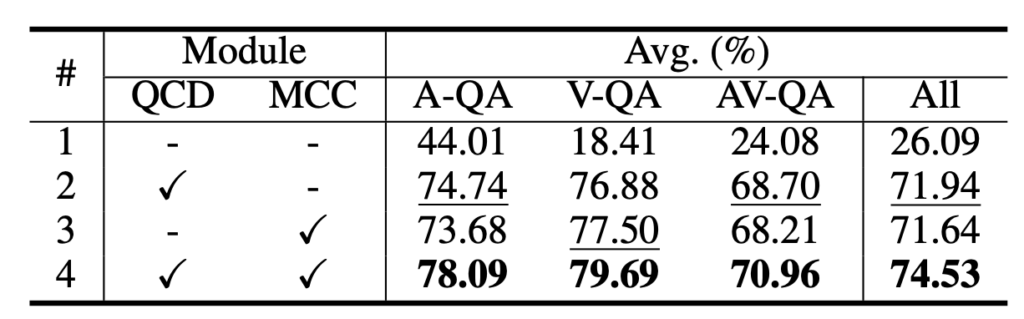
다음은 APL의 모듈별 ablation 성능입니다. Cross attention으로 구성된 두 모듈 QCD와 MCC가 모두 기본적인 성능을 보장해주며, 두 모달이 함께 쓰였을때 상호보완적으로 동작하며 각자만 썼을때보다 3% 높은 성능을 달성하게 됩니다. 지금 개인적으로 실험하고 있는 모듈들을 함께 썼을때 시너지를 내지 못해 고민중인데 모듈 간의 상호작용에 대한 분석이 더 필요할 것 같습니다.

그림 3은 postivity learning contrastive loss에 대한 ablation 실험 결과입니다. 질문의 각 카테고리별로 loss를 추가해감에 따른 성능 변화 추이를 보여주고 있습니다. 일단 논문에선 초록색 막대, 즉 모든 loss를 다 적용했을 때 가장 높은 성능을 달성했다고만 이야기하고있는데, 중간에 Visual Question 파트에선 loss를 붙일수록 성능이 떨어지는 것을 볼 수 있습니다.
자세하겐 question-object loss만 썼을때 성능이 가장 높고, audio-object loss를 붙이며 성능이 떨어지게 됩니다. 특히 Localization과 같은 spatial한 정보를 묻는 질문에 대해 성능이 떨어졌는데, 오디오 정보와 spatial 축에서의 align을 수행해주는 모듈이 하나 필요한 것인지 정도 생각이 들었습니다.
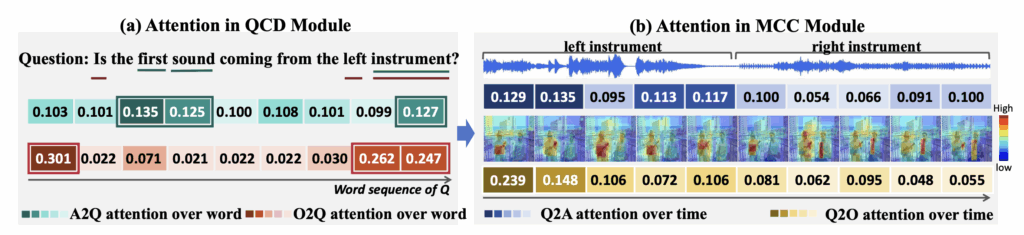
다음으로 그림 4-(a)는 QCD 모듈을 통해 질문의 키워드가 잘 분별되었는가에 대한 attention 수치를 보여줍니다. 실제로 audio, object를 기준으로 각 모달리티에서 중요한 정보가 가장 높은 attention 값을 가져가는 것을 볼 수 있습니다. Object-to-Query에선 “Is”라는 단어에 가장 높은 값이 할당되었는데 이에 대한 설명은 따로 없네요. 사실 단어별로 attention 값에 큰 차이가 없을 것으로 기대했는데, 생각보다 주요 단어가 잘 강조되고있는 것 같아 참고해볼만한 방식인 것 같습니다.
그림 4-(b)는 MCC 모듈을 통해 질문과 관련된 정보를 오디오, 비디오에서 잘 가져갔는가에 대한 attention 수치를 보여줍니다. 실제 오디오에서, 첫 5개 segment에서 ‘first instrument’가 소리를 내고있는데 오디오에서도 첫 5개 segment에 높은 attention 값을 주었고, 비디오에서도 상응하는 왼쪽 영역 악기에 weight를 많이 주고있는 모습을 볼 수 있습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요 현우님 글 잘 읽었습니다.
읽으면서 궁금한점이 있어서 질문드립니다.
Audio-object 쌍이 question-object 쌍과 매치되는 경향성의 차이가 존재할 것 같기도 한데, 단순 추측이기도하고 학습이 되어가며 해결이 될 수 있을 문제일 것도 같아 생각이 궁금합니다. (ex, 생소한 악기 이름 등)
질문이 더 있긴 했지만.. 두서가 없어 좀 더 생각해보고 질문드리겠습니다!
리뷰 잘 읽었습니다.
리뷰에서 “객체가 인간 인지의 기본 단위이므로 object 중심으로 설계해야 한다”고 가정한거 같은데, 실제 AVQA 질문들이 객체 중심적이지 않은 경우(예: 배경 소리, 음악 분위기 등)는 이 가정이 오히려 한계를 만들 수 있지 않을까요?
제가 잘 이해한 것이 맞나 싶다만, positivity를 판단하는 threshold는 직접 설정했다보니, 이 값이 detector 종류나 feature 스케일에 민감하다면 당연히 결과가 threshold tuning에 의존한 것은 아닌지 의문이 듭니다. 그렇다면 adaptive하다는 주장과도 모순되지 않나요?