안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 2024년 IEEE TRANSACTIONS ON MULTIMEDIA(TMM)에 발행된 논문으로, Video Scene Graph Generation을 다룹니다. CVPR 2024에서 제안된 OED 이외에 DETR 기반의 VidSGG 모델은 어떻게 구성되는지 궁금해서 읽어보았습니다. 전반적으로 multi-step VidSGG에서 DETR 기반의 1-stage 방법론으로 어떻게 적용시킬지 고민한 흔적이 보이는 논문이었습니다. 리뷰 시작하겠습니다.

Introduction
Scene Graph Generation(SGG)은 이미지, 비디오와 같은 비정형 데잍러의 정보를 그래프 자료구조 형태로 기술하는 작업입니다. 보통 Scene Graph에서 각 노드는 object instance를 의미하고, 두 노드 사이 간선(edge)는 이들의 visual relation을 기술합니다. 데이터의 정보를 이렇게 그래프 형태로 잘 기술할 수 있다면 retrieval, captioning, VQA, generation 등 다양한 고차원적인 vision application에 활용이 가능하다고 합니다.
딥러닝이 발전함에 따라 이미지 데이터에서의 SGG 성능이 상당히 개선되었고, 자연스럽게 3D, video 등 다른 형태의 데이터에서도 SGG을 수행하고자 하는 시도가 이어졌습니다. 비디오의 경우에는 새롭게 temporal 정보가 추가되므로, 시공간적 정보를 잘 모델링해서 물체들 간 relation을 예측해내고자 하는 시도가 이어졌습니다. 하지만 기존 방법론들의 경우 예측 프레임워크가 여러 단계로 나뉘어져 있다는 한계가 있었습니다. 보통 1. Faster R-CNN과 같은 사전학습된 기성 object detector를 사용해 프레임 별 object detection을 수행하고, 2. 프레임들 간 검출된 물체들을 tracking하거나(3D를 사용하거나 알고리즘을 돌린다고 합니다) 어텐션/그래프 신경망을 활용해 시공간 문맥 정보를 모델링하고 3. 시공간 정보를 활용해 relation을 후처리 하는 방식으로 예측이 수행되었다고 합니다.
하지만 이렇게 프레임워크를 여러 단계로 나뉘어진 형태로 구성하게 될 경우에는 각 모듈이 독립적으로 최적화되어 각 subtask를 위한 모듈 간 협력/상호작용이 어려워집니다. sub-optimal한 예측을 수행할 수밖에 없죠. 본 논문의 저자는 TPT(Temporal Propagation Transformer)라는 transformer 구조 기반의 통합 아키텍처를 제안합니다.
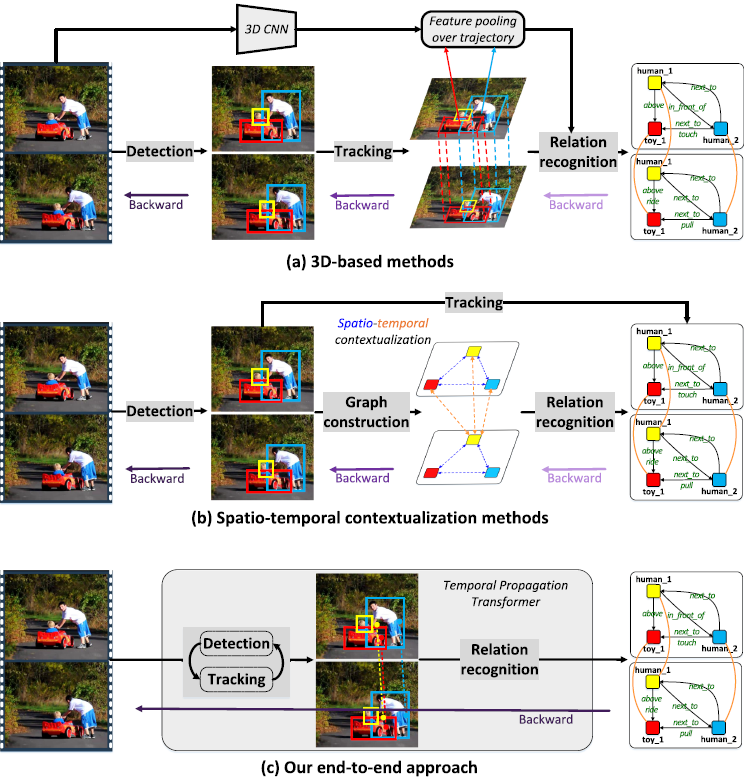

위 Fig. 1. 에서 확인할 수 있듯, 기존의 주류 방법론들(3D 기반 or 시공간 contextualization) 방법론들과 달리 제안하는 프레임워크(c)는 object detection, tracking, relation recognition을 단일 프레임워크로 수행합니다. 먼저 DETR에 이전 프레임의 탐지 결과를 반영하는 query propagation module(QPM)을 도입하여 물체들이 공동으로 detection될 수 있게 하고, 각 프레임에서 예측된 object instance들을 기반으로 relation proposal(서로 관련이 있을 가능성이 있는 object pair 생성)을 수행한 뒤 relation classification을 하는 방식으로 동작합니다. 이 과정에서, 이전 프레임들의 정보를 활용해 object representation을 보강하는 Temporal Dynamics Encoder(TDE) 및 이전의 relation 예측 결과를 반영해 현재의 relation proposal set을 보완하는 Relation Propagation 전략을 제안하였습니다.
저자들이 주장하는 contribution을 요약하면 다음과 같습니다 :
- 우리가 아는 한, 제안하는 TPT는 Video SGG를 위한 최초의 Transformer 기반 end-to-end 프레임워크이다.
- TPT는 latent object query를 통해 프레임 간 video object간 정보를 연결한다. 이는 기존과 비교해 시공간적 정보 모델링 과정을 크게 단순화한다.
- 특히, 어텐션 메커니즘을 활용해 이전 프레임들의 representation으로 object representation을 보강하는 TDE(temporal dynamic encoder)를 고안했으며, 이전의 relation 인식 결과를 활용해 현재의 relation proposal set을 보완하는 RP(Relation Propagation)전략을 도입했다. 이를 통해 TPT는 end-to-end로 joint training이 가능해졌다.
- VidHOI와 Action Genome 데이터셋에서 다양한 실험을 통해 TPT의 효과를 검증하였다.
결국, VidSGG를 수행하기 위해 DETR 기반의 모델을 제안했다고 생각하시면 됩니다. 단순한 DETR과 다른, 집중할 포인트는 1. 어떻게 temporal 정보를 모델링하는가 2. 어떻게 relation 예측을 수행하는가 정도가 되겠네요. 이어서 Method 살펴보겠습니다.
Method
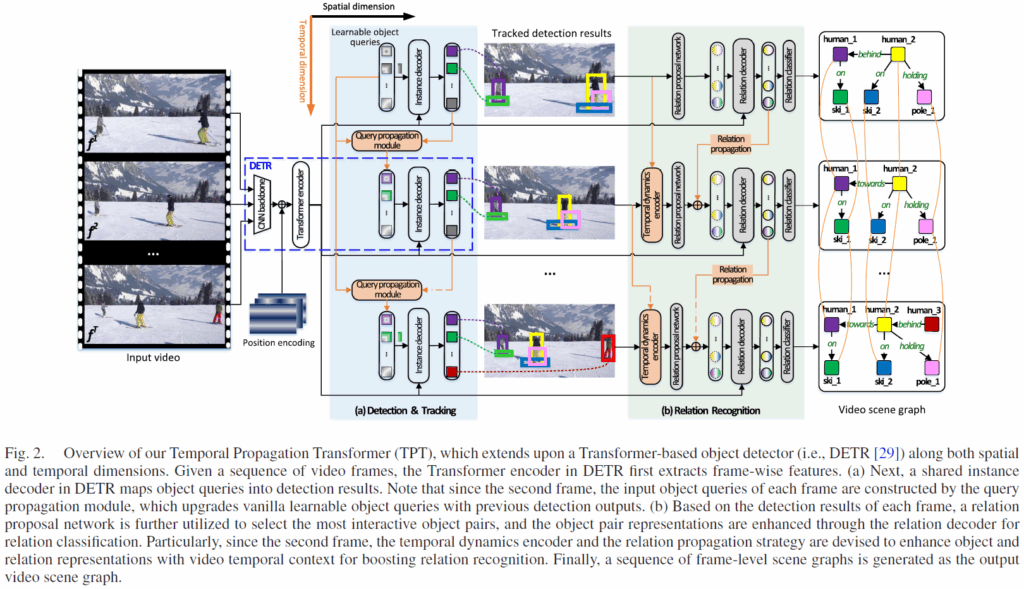
전체적인 구조는 DETR 구조를 수정하여 temporal 축으로 object 정보를 순차적으로 업데이트하며 검출할 수 있게 하였고, 이후 relation proposal -> relation classification을 하는 흐름입니다.
입력 비디오의 프레임들이 주어지면 이를 CNN 백본 및 transformer 인코더를 통과시켜 visual feature를 정제합니다(당연히 트랜스포머 인코더 입력 부분에 positional encoding 추가해줍니다). 이후 시간 축을 따라 비디오 프레임들이 하나씩 shared object detector에 입력되는데, 이 때 각 frame들의 object query들은 Query Propagation Module(QPM)을 통해 점진적으로 업데이트됩니다. 이는 object instance들이 프레임을 거치며 tracking되는 효과를 주기 위함이라고 합니다(기존 방법론들이 3D conv나 매핑 알고리즘으로 프레임 간 object tracking을 수행한 것의 연장선인 듯 하네요). 각 frame의 spatial dimension에서는 2단계를 거쳐 관계 인식을 수행합니다. 2-stage detector가 물체를 검출하는 과정과 유사하게, 먼저 Relation Proposal Network를 사용해 각 frame의 탐지 결과를 기반으로 가장 상호작용 가능성이 높은 object pair를 선택하고, 그 다음 relation decoder를 통해 representation을 처리하며 relation classification을 수행합니다. 이 과정에서 두 번째 프레임부터는 temporal dynamic encoder(TDE)과 relation propagation(RP) 전략을 추가하여 시간적 문맥을 추가적으로 반영해줍니다. 최종적으로는 프레임 단위 scene graph를 출력하게 됩니다.
Object Detection With Instance Temporal Association
TPT는 연속된 비디오 프레임에서 동일한 object instance를 식별하기 위해서 Query Propagation Module(QPM)을 사용합니다. 이를 통해 autoregressive한 방식으로 프레임이 진행됨에 따라 이전 프레임의 object 정보를 object query에 업데이트합니다.
쿼리 전파 모듈 (Query Propagation Module, QPM)
DETR 계열 object detector에서는 object query로 object detection을 수행합니다. object query는 각각이 특정한 물체 검출을 담당하는 학습 가능한 벡터로, CNN 백본 -> 트랜스포머 인코더를 거친 visual feature와 decoder 내부에서 cross-attention을 통해 입력 이미지에서 물체의 위치, 클래스 정보 예측을 담당합니다. 잘 학습된 object query는 특정한 특징을 가진 물체(ex : 이미지 좌하단에 있는 큰 물체)를 탐지하는데 특화된 일종의 prototype으로 생각할 수 있죠. 하지만 하나의 비디오 클립 내부의 개별 프레임들에 단순히 DETR 기반 검출을 돌려버리면 인접 프레임들 간 시간적 문맥 정보가 사라져서 프레임 간 탐지 결과의 시간적 연속성이 끊어질 수 있습니다. 저자들은 비디오 내 연속 프레임들의 detection 결과에 대한 시간적 인관성을 확보하기 위해 이전 프레임의 detection 결과를 활용해 prototype query를 보강하는 쿼리 전파 모듈(QPM)을 설계하였습니다. QPM은 위 Fig. 2에서 (a) Detection & Tracking 에서 주황색 부분에 해당합니다. 그림에서 확인할 수 있듯 이전 프레임의 instance decoder의 결과를 활용해 이후 프레임의 object query를 autoregressive하게 보강해줍니다. 자세한 내부 구조는 아래 Fig. 3. 과 같습니다.
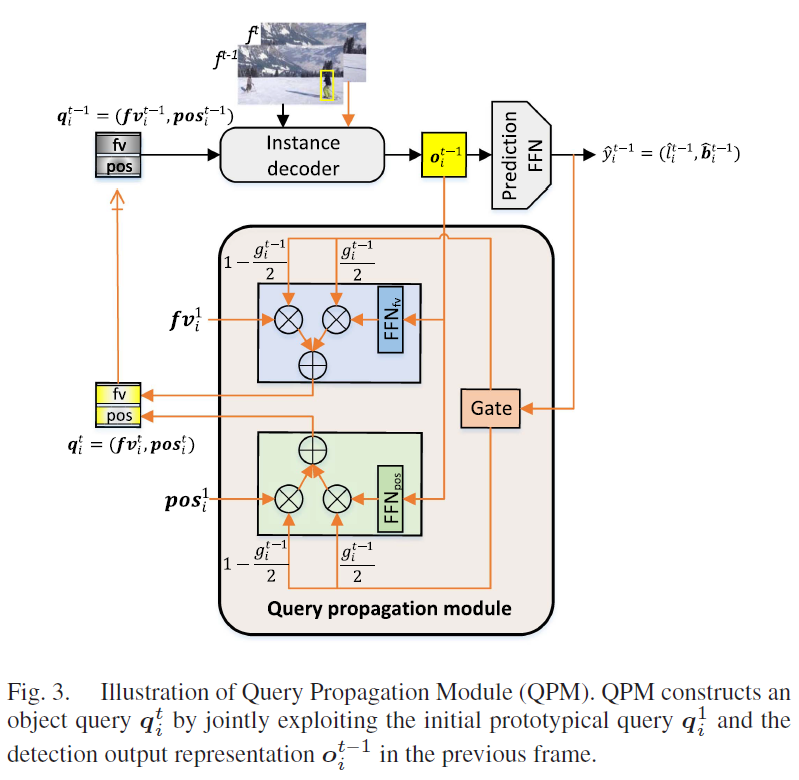
T개 프레임으로 구성된 입력 비디오를 video = [{f}^{1}, {f}^{2}, ... , {f}^{T}]라고 했을 때, 먼저 첫번째 프레임 {f}^{1}에 대해서는 일반적인 detection을 수행합니다. 이 때 object query를 {Q}^{1} = {{q}^{1}_{1}, ...,{q}^{1}_{M} }로 표기하겠습니다(쿼리는 feature vector와 position encoding으로 구성됩니다). 이후 두번째 프레임부터는 이전 프레임 {f}^{t-1}의 디코더 출력값을 활용해 다음과 같이 현재 프레임 {f}^{t}의 object query {q}^{t}_{i}=(f{v}^{t}_{i}, {pos}^{t}_{i})를 구성합니다.
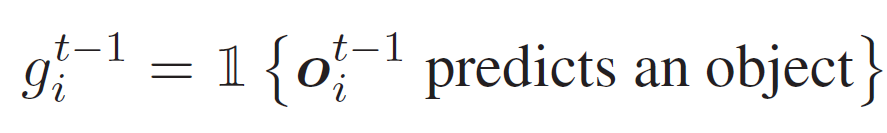

(1)번 수식에서 앞에 있는 bold 1은 예측값이 실제 GT object와 매칭되거나, inference 시 confidence score가 threshold보다 높을 때 1로 설정되고, 이외에는 0인 indicator입니다. 의미 있는 예측값에 대해서만 학습/추론을 진행한다고 생각하시면 됩니다. 수식 (2), (3)에서는 게이트 구조를 통해 프로토타입 쿼리 {q}^{1}_{i}와 이전 프레임에서의 탐지 결과를 퓨전해서 구성된 쿼리 {q}^{t}_{i}를 얻습니다. FFN 각각 은 2계층 feed forward network입니다.
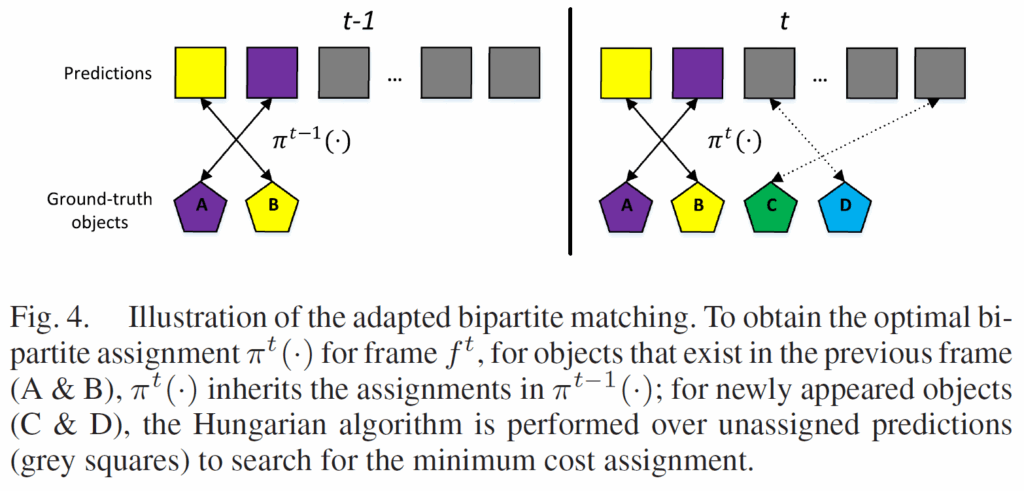
Adapted bipartite matching
DETR에서는 헝가리안 알고리즘을 통해 모델의 예측 set과 GT set 간 최적의 이분 매칭 할당이 이루어집니다. TPT 학습에서는 첫번째 프레임은 DETR과 동일하게 수행하고, 두 번째 프레임부터는 쿼리가 특정 object를 추적하도록 강제하기 위해 다음과 같이 {f}^{t}에 대한 bipartite assignment {π}^{t}(i)를 수행합니다.

수식 (4)에서 {π}^{t-1}(·)는 {f}^{t-1}에 대한 assignment이고, {ID}_{t->t-1}(i)는 {f}^{t}의 객체 {y}^{t}_{i}와 동일한 ID를 공유하는 {f}^{t-1} 내 객체의 인덱스로 설정됩니다. 이외의 새롭게 등장하는 object에 대해서는 할당되지 않은 예측값들을 대상으로 헝가리안 알고리즘을 사용하여 minimum cost assignment을 수행한다고 합니다. 전반적인 매칭 과정은 아래 Fig. 4.와 같습니다. 간단하게 이전 프레임의 매칭 결과를 유지하되, 새로 등장하는 object들만 새로 헝가리안 알고리즘으로 매칭을 수행한다고 보면 되겠네요.
Relation Recognition
각 프레임에서 물체들을 검출한 다음에는 검출한 물체들 간 관계 / 상호작용을 예측해야 합니다. TPT는 앞에서 탐지된 물체를 기반으로 2단계로 relation recognition을 수행합니다. 1. 먼저 relation proposal을 수행하고, 2. 그 다음 relation classification하는 방식으로 관계를 예측하게 됩니다. 이 과정에 Temporal Dynamics Encoder(TDE) 및 Relation Propagation strategy(RP)를 도입해 프레임들 간 시간적 일관성을 보강해준다고 합니다.
Temporal Dynamics Encoder (TDE)
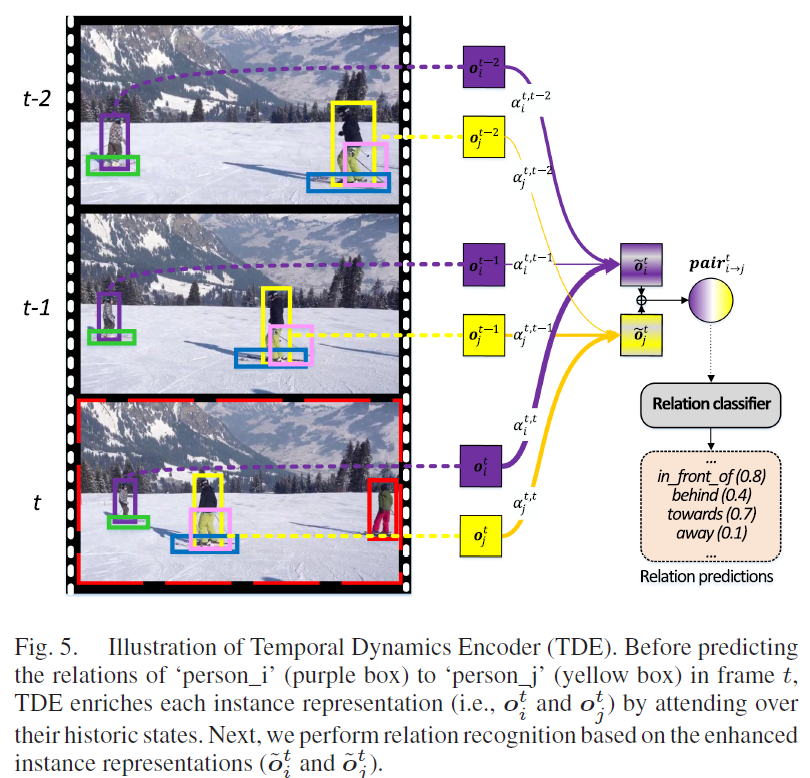
각 프레임 {f}^{t}에서 instance decoder로 얻은 detection output을 {O}^{t} = { {o}^{t}_{1}, ... , {o}^{t}_{M}} 라고 하면 TDE는 Fig. 5와 같이 생성된 trajectory를 따라 해당 instance의 과거 representation에 어텐션을 적용해 각 출력 instance representation을 풍부하게 만들어줍니다(수식5). α
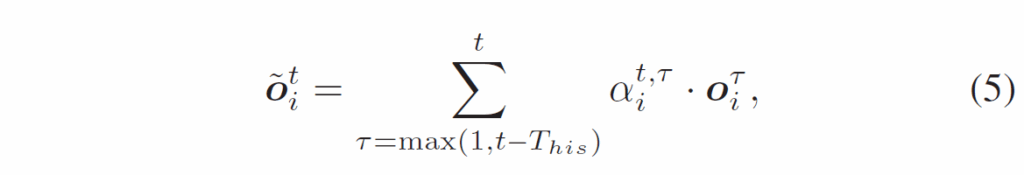
α는 attention weight로, 다음 수식과 같이 softmax로 정규화됩니다. {g}^{τ}_{i}는 위 수식 (1)에서 얻어져서 trajectory의 empty detection를 마스킹하는데 사용됩니다.
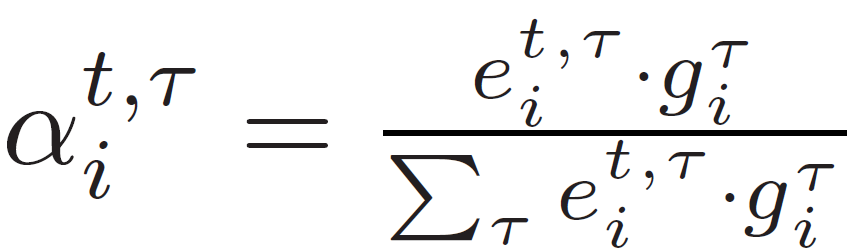
primary attention weight 는 다음과 같습니다.
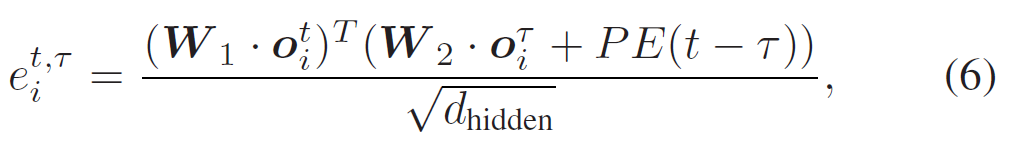
수식 (6)에서 PE는 positional encoding이고, {d}_{hidden}=256은 hidden dimension, {W}_{1}, {W}_{2}는 파라미터 행렬입니다. 복잡하게 써져있긴 한데, 실제 구현은 2계층 Transformer encoder로 간단하게 구현됐다고 합니다(보통 conference 논문들은 이런 디테일에 대해 다 알지? 모르면 레퍼런스 봐 이런 느낌인데 확실히 IEEE transaction계열 저널이라 그런지 이런 수식들이 엄청 꼼꼼하게 작성되어 있네요).
Relation Proposal Network
다음으로 탐지 결과를 기반으로 가능한 모든 subject-object pair를 구성합니다. 프레임에서 N개의 object instance가 탐지되면 가능한 relation 조합수가 총 N(N-1)개가 됩니다. 각 relation representation은 단순히 두 instance의 representation을 concat해서 처리합니다. relation proposal network는 <s-o> pair들을 입력받아 이들이 실제로 관계가 있는지, 상호작용 하는지에 대한 가능성을 예측합니다. 물체 검출과 동일하게 relation 예측에 대한 confidence score인 셈입니다. 구현은 간단히 2계층 FFN으로 했다고 합니다(sigmoid activation 활용). 학습 과정에서는 각 프레임에 대해 K개의 pair를 샘플링하고, 예측된 bounding box와 실제 GT간 IoU > 0.5면 positive, 그렇지 않으면 negative로 간주하고 focal loss(FL)로 해당 모듈을 최적화시킵니다.
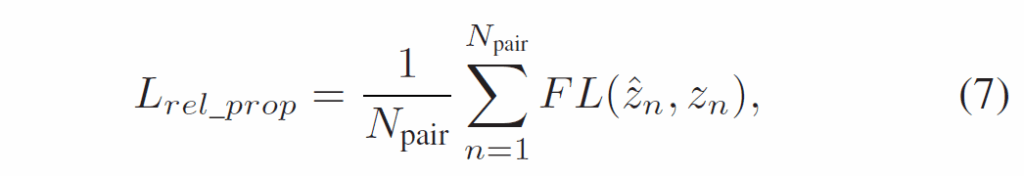
{z}_{n} ∈ {0, 1}은 GT label입니다. 추론 시에는 각 프레임에서 가장 높은 socre를 가진 top-k pair를 relation proposal로 남깁니다.
Relation Propagation Strategy (RP)
TPT에는 비디오의 연속된 프레임의 temporal consistency를 고려하여 relation의 시간적 문맥을 반영하기 위해 RP 모듈을 도입하였습니다. 두 번째 프레임부터 relation proposal network의 출력에 이전 프레임에서 예측된 top-K개의 pair를 보충합니다. 따라서 현재 프레임의 relation proposal set은 현재 프레임과 이전 프레임의 각 예측 set의 합집합으로 구성됩니다.
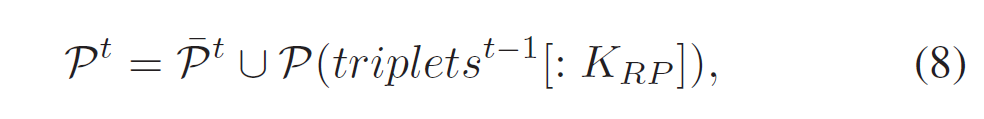
Relation Decoder (RD)
relation proposal 이후, relation classification이전에 transformer decoder를 거쳐 attention을 통해 K개의 object pair representation을 강화합니다. 단순히 relation representation과 이미지 feature 간 Cross-Attention을 수행합니다.
Relation Classifier
Relation Decoder에서 출력된 pair representation은 이제 마지막으로 relation classifier를 거쳐 relation class 분류를 수행합니다. relation classifier는 다음과 같이 focal loss로 학습합니다. {C}_{rel}은 relation/predicate category 수입니다.
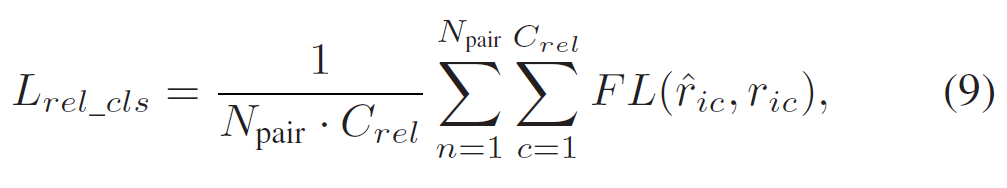
Training
학습 과정이 다단계로 나뉘어 있습니다. 처음부터 scratch로 모든 모듈을 한번에 학습을 돌려버리면 수렴이 잘 안되는 문제가 있지 않나 합니다. 1. 가장 먼저, 개별 프레임들로 object detection을 위한 DETR을 학습시킵니다. 2. 이후 DETR 기반 detector를 QPM모듈과 함께 파인튜닝합니다. 이 단계는 비디오 클립 단위로 수행됩니다. 3. 세 번째 단계에서는 1,2단계에서 학습된 모든 파라미터를 freeze하고 relation recognition을 위한 모듈들만 학습을 진행합니다. 4. 마지막으로, 전체 프레임워크를 전체 loss를 사용하여(freeze 풀고) 파인튜닝을 수행합니다.
프레임워크가 꽤나 복잡하게 구성되어 있고 서술이 디테일해서 method 부분이 좀 길어졌네요. 이제 실험 파트 보고 마무리하겠습니다.
Experiments
보통 VidSGG는 Action Genome에서 벤치마킹하는데, 해당 논문은 VidHOI라는 데이터셋으로 함께 벤치마킹하였습니다. DETR 기본 구조로는 Deformable DETR을 채택하였고, ResNet50 CNN backbone, object query 수는 300개를 사용했다고 합니다. 학습은 2080Ti 8개를 사용했다고 하네요.
VidHOI
해당 데이터셋은 VidOR을 기반으로 1FPS빈도로 키프레임 샘플링을 통해 구축되었다고 합니다. 학습용으로 6,366개 비디오(208,686개 키프레임), 테스트용으로 756개 비디오(24,667개 키프레임)로 구성되었다고 하네요. 78개의 object category와 50개의 술어(predicate) category가 있다고 합니다. 술어 카테고리의 경우 25개의 시간적 술어(pull, lift .. 데이터셋의 약 5%) 및 25개의 공간적 술어(next to, behind)로 구성된다고 합니다.
지표가 약간 특이한게, 보통 SGG계열은 PredCLS, SGdet, SGCLS 지표를 많이 사용하는데 여기서는 기존 연구를 따라서 4개 relation triplet set에 대한 mAP를 사용한다고 합니다. Full(전체 557개 삼중항 카테고리), Temporal(시간적 술어를 가진 207개 삼중항 카테고리), Spatial(공간적 술어를 가진 350개 삼중항 카테고리), Non-rare(25개 이상의 인스턴스를 가진 242개 삼중항 카테고리), 그리고 Rare(25개 미만의 인스턴스를 가진 315개 삼중항 카테고리)로 나타냅니다.
세팅은 Detection 및 Oracle로 나뉘는데, Oracle의 경우 inference 시 실제 GT trajectory가 주어지고, Detection의 경우 trajectory를 예측한다고 합니다.Oracle 모드는 인스턴스 디코더로부터 최적으로 매칭된 예측값을 실제 GT object 정보로 사용해 구현됐다고 합니다.

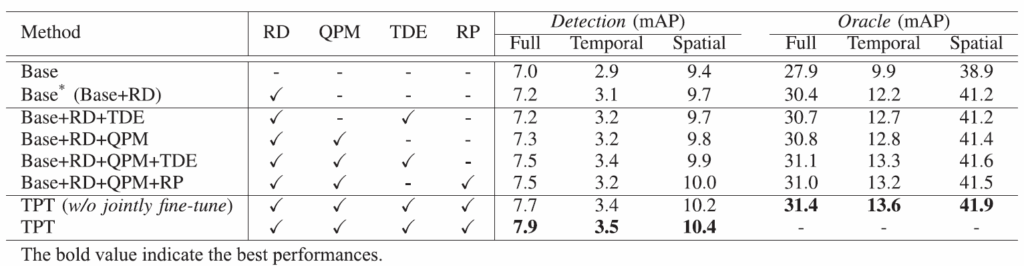
Table 1에 보면 ablation study가 함께 나와있습니다. Base는 사전학습된 DETR에 단순히 relation proposal network와 relation classifier를 붙인 거고, Base*의 경우 관계 디코더를 활용하여 저수준 이미지 특징에 attention을 추가해 relation feature를 강화한 것입니다. 이렇게 특징을 강화하면 공간적 / 시간적 relation recognition 모두에 도움이 됨을 확인할 수 있습니다.
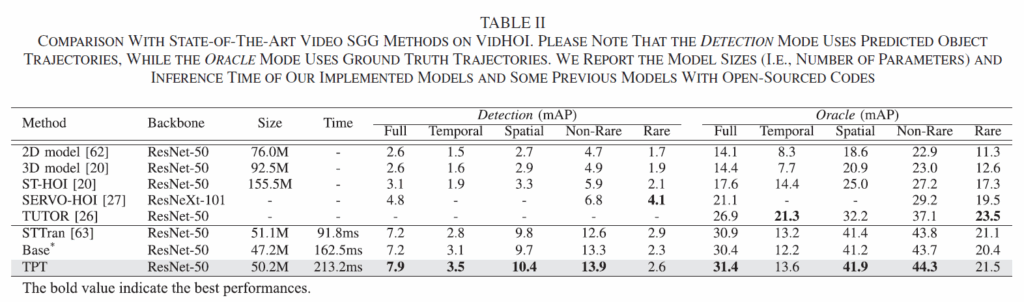
Table 2에는 다른 모델들과의 성능 비교입니다. 비교 모델들로는 i) 단일 대상 프레임에서 visual feature를 추출하는 기본 2D 모델, ii) 3D 백본으로부터 시간 정보를 인식하는 feature를 활용하는 3D 모델, iii) temporal feature pooling을 개선하고 추가적인 human pose 지식을 활용한 ST-HOI, iv) long-tail distribution 문제에 집중한 SERVO-HOI 등을 사용했다고 합니다. 제안하는 TPT가 전반적으로 대부분의 지표에서 우수함을 확인할 수 있습니다.
Action Genome

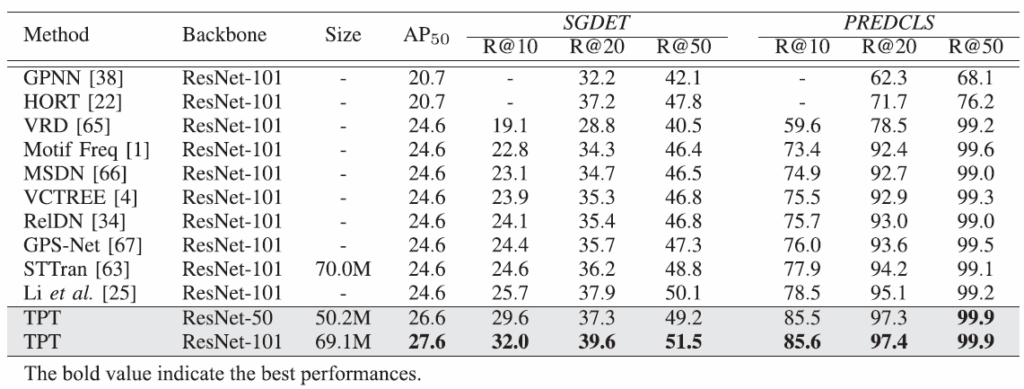
action genome에서의 결과 살펴보고 리뷰 마무리하도록 하겠습니다. Action Genome에서는 relation이 굉장히 sparsely하게 annotation되어 있어 평가를 위해 상위 예측에 대한 Recalls을 활용합니다. 본 논문에서는 SGDET 및 PREDCLS를 리포팅하였습니다. PREDCLS 세팅은 객체 정보(bounding box 및 class)가 주어진다고 가정하며, subject-object pair 간의 relation 예측을 평가합니다. SGDET는 원본 비디오로부터 scene graph를 예측하는 세팅입니다.
표를 보면 기존의 방법론들과 비교를 수행합니다. 베이스라인이 STTran밖에 없는게 좀 아쉽네요. TABLE에는 SOTA인데 최신 모델들은 STTran과 TPT보다 워낙 성능이 개선되고 있어서 해당 모델이 그렇게 성능이 뛰어나 보이지는 않습니다.
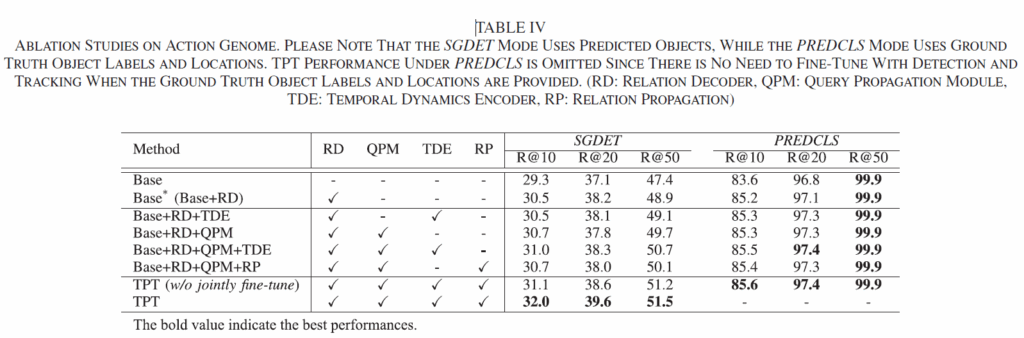
마지막으로 AG 데이터셋에서의 Ablation Study입니다. 여러 모듈들에 대한 ablation을 통해 각 요소들의 효과를 확인하였습니다.
Transaction 논문들은 읽을때마다 분석과 서술이 굉장히 촘촘하고 완성도가 높다는 느낌을 줍니다. 너무 수식적으로 풀어져 있어서 ‘어텐션 돌렸습니다’ 혹은 ‘신경망 태웠습니다’ 정도로 말로 이해가 가능한 부분들이 수식으로 이해하려니 답답한 느낌도 있긴 한데.. 이런 깐깐한 점들 덕분에 논문의 완성도가 높아지는 거겠죠. 전반적으로 논문의 완성도가 굉장히 높긴 하지만 리뷰 프로세스가 하도 길다 보니 항상 비슷한 시기 출판되는 conference 논문들보다는 성능이 아쉬운 것은 어쩔 수 없는 듯 합니다.
이만 리뷰 마무리하도록 하겠습니다.
감사합니다.
안녕하세요 재연님 리뷰 감사히 잘 읽었습니다!
제가 잘 모르다 보니 리뷰에서 계속 사용되는 temporal정보라는게 정확히 어떤 것을 의미하는지 궁금합니다! 그리고 TPT가 연속된 프레임의 temporal consistency를 고려하여 relation의 시간적 문맥을 반영하기 위해 RP 모듈을 도입하는 등의 비디오의 연속된 프레임에 대해서 계속 설명이 되는데 그럼 그 연속된 프레임에서만 동일한 object instance를 구분해 내는지, 아니면 꽤나 멀리 떨어진 프레임에서도 동일한 object instance라면 구분해낼수 있는지가 궁금합니다.
아직 잘 모르다보니 혹시 질문이 이상하면 바로잡아주세여ㅎㅎ! 감사합니다~
temporal 이라고 계속 언급하는것은 별다른 게 아니고 비디오의 시간 축 정보를 의미합니다. video 데이터는 image 데이터를 temporal(시간) 축으로 여러 장 쌓은 형태의 비정형 데이터입니다. 오디오나 텍스트 등 sequence 데이터에서 순서 정보를 잘 처리하는 게 중요하듯, 이미지에서 비디오로 데이터가 확장되면 추가적인 시간적 정보가 생기므로 비디오를 다루는 분야에서는 비디오를 하나의 시퀀스로 보고 시간적 정보를 잘 모델링 하고자 합니다. 비디오의 시간적 맥락을 활용하면 이미지 한 장으로는 알 수 없었던 추가적인 정보를 얻을 수 있으니까요.
보통 기존의 Video Scene Graph Generation에서는 frame이 시간 축을 따라 진행될 때 동일한 object를 계속 추적하는 방식으로 object를 처리했습니다. 계속 object를 추적하면 인접 프레임 뿐만 아니라 멀리 있는 프레임 간 동일 object도 식별할 수 있습니다.
찬미님은 아직 기초 교육 단계이다보니 이런 걸 물어보는게 부끄러운게 아닙니다. (너무 핑프가 아닌 선에서) 오히려 질문이 부끄럽지 않은 시기에 많이 물어보고 모르는걸 빠르게 채워나가는게 더 좋다고 생각합니다. 앞으로도 이해가 어려운 것들이 있다면 주변 선배/사수분들께 적극적으로 질문하면 좋을 듯 합니다