이번에 소개드릴 논문은 Multimodal Large Language Model(MLLM)에 대한 분석 실험을 한 논문으로 카이스트에서 작성한 논문입니다. 아직 어디 게재된 것 같지는 않고 arxiv만 올라온 논문이긴 합니다. 근데 내용이 단순하면서도 시사하는 바가 좋은 것 같아서 읽고 리뷰로 작성하게되었습니다.
Intro
우선 MLLM은 보통 사전학습된 LLM과 Vision Encoder가 있고 이들의 모달리티를 서로 연결해주는 가벼운 크기의 projector라는 개념으로 구성이 되어있습니다. 이 MLLM은 두 모달리티를 활용하는만큼 다양한 분야로 확장이 가능하며 여러 테스크들에 대해서 좋은 성능을 보여주고 있죠.
하지만 MLLM에도 문제점이 있는데, 많은 연구들이 여전히 MLLM이 객체 수를 카운팅하거나 어느 위치에 있는지를 찾는 등 비전 중심의 task에서 잘 동작하지 못함을 지적하고 있습니다.

예를들어서 영상 속 세부적인 영역들까지 유심히 들여다봐야 대답할 수 있는 상황에서 기존의 LLaVA와 같은 MLLM들은 잘못된 답변을 하기 쉽다는 것이죠. 이를 해결하기 위해 이전 연구들에서는 더 강력한 비전 인코더와 더욱 다양한 projector등을 도입하여 더 강력하고 풍부한 시각적 표현력을 LLM에 전달하려고 시도하였습니다.
근데 보통 더 좋은 표현력을 가지는 비전 인코더 또는 projector라 함은 결국 모델들의 크기가 커진다는 것을 의미하는 것이고 이는 효율성 관점에서 단점으로 작용합니다. 그래서 저자들은 보다 강력한 Vision Backbone을 도입하기 보다는 기존의 MLLM의 framework 자체의 문제점은 없는지를 검토하게 됩니다.
이를 통해 한가지 문제점을 제시하는데 이는 기존의 MLLM들이 언어 모델링 관련된 목적 함수를 통해서만 fine-tuning된다는 것이죠. 즉, 텍스트 기반 출력에 대한 지도만을 가지고 학습하기 때문에 시각적 토큰들은 오직 간접적으로 언어 중심의 지도를 통해 학습을 받고 있으며, 이러한 시각적 지도가 부재한 상황에서 저자들은 과연 MLLM이 시각적 정보를 잘 포착하고 유지할 수 있는지에 대한 질문을 던지고 있습니다.
저자들은 한가지 가정을 하였는데, 텍스트 중심의 지도학습은 모델이 오직 시각적 디테일을 텍스트 예측에 맞추어 유지하고 있다는 것입니다. 조금 더 구체적으로, “A photo of a group of people holding a large flag”라는 캡션이 있을 때, 이 캡션만으로는 시각적 토큰이 굳이 flag의 색상은 무엇이고, 사람들이 정확히 몇명이 있으며, 전반적인 공간적 레이아웃이 어떻게 되는지 등을 전혀 고려할 필요가 없다는 것이죠. 따라서 텍스트만을 활용한 지도학습의 경우 visual modality를 text modality에 효율적으로 alignment를 맞출 수는 있겠으나, 반대로 visual feature만이 가지는 풍부하고 세부적인 의미론적/구조적 정보는 잃어버리게 되기 싶다는 말입니다.
이 문제를 해결하기 위해 저자들은 MLLM에서 시각적 pathway에 곧바로 지도하는 규제화 전략을 제안합니다. 이 규제화 전략이라고 하는 것이 복잡하거나 그런 것은 아니고 그냥 간단하게 이야기해서 Vision Encoder의 visual token과 MLLM의 visual token끼리 서로 knowledge distillation하는 것을 말합니다. 이를 통해 시각적 인코더가 제공하는 세부적인 시각적 속성이 버려지는 것을 막을 수 있다고 하네요.
사실 이게 해당 논문의 결론이라서 끝이라고 하면 당황스러우실 수 있는데 이 과정까지 도달하기 위해 진행했던 실험들 그리고 MLLM에서 Vision-specific task를 더 잘하기 위해서는 어떤식으로 접근하면 좋은지에 대한 내용들을 전달하고 있어서 가볍게 읽어보시면 좋을 듯 합니다. MLLM이 결국 text와 image 두 모달리티를 둘다 잘 이해하고 이를 바탕으로 output을 예측하는 모델인데 아까 위에서도 설명드렸다시피 image쪽을 더 잘 이해해야만 대답할 수 있는 상황들에 대해서 그런 것들을 놓치는 경우가 종종 있어서 이런 문제에 고민이 있으셨던 분들이라면 더 재밌게 보실 것 같네요.
Preliminary
우선 MLLM은 Intro 처음에 소개드린 것처럼 크게 3가지 모듈( LLM, Vision Encoder, Projector)로 구분이 됩니다. 수학 기호로 표기하면 다음과 같이 표기됩니다 LM_{\theta}, V_{\psi}, P_{\phi} . 여기서 LM은 language model을, V는 Vision model을, P는 Projector를 의미하고 각 기호 아래첨자로 표기된 세타, 프사이, 파이는 각각 모델들의 learnable parameter를 의미합니다.
모델의 추론 과정은 보통 Vision Encoder는 frozen이 되어 있는 상태고 입력 영상을 Vision Encoder에 태워서 Visual token을 추출하게 됩니다.
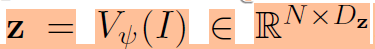
여기서 z가 vision encoder를 통해 나온 visual token입니다. 그리고 이 visual token들은 LLM의 입력으로 넣어주기 위해 language latent space로 projection해주어야 하는데 이 과정을 Projector가 진행하게 됩니다.
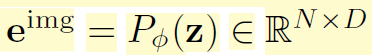
Projector를 통해 나온 output token e^{img} 는 LLM의 입력으로 사용될 vision token에 해당합니다. 그리고 입력 프롬프트로 들어오는 text도 text embedding을 추출하게 됩니다.
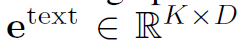
이렇게 img와 text 토큰을 concat하여 합친 다음에 LLM의 입력으로 들어가게 됩니다.
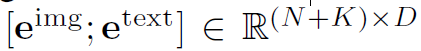
MLLM 모델의 학습 방식은 일반적으로 시각적 정보를 언어 모델에게 통합시키기 위해 2스테이지로 학습이 진행됩니다. 구체적으로 설명드리면 첫번째 단계와 두번째 단계의 목적 함수는 동일한데, 학습을 하는 대상이 달라집니다. 첫번째 학습 단계에서는 언어 모델은 freeze 된 상태에서 projector만을 학습시키며 두번째 학습 단계에서는 projector와 언어 모델을 둘다 학습시킨다고 하네요.
참고로 학습에 사용되는 목적 함수는 아래 수식2와 같으며 텍스트 출력에 대한 log-likelihood 값이 최대화가 되도록 학습이 됩니다
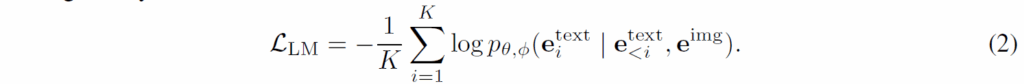
Method
MLLM의 구조 및 학습 방법에 대해 간략하게 알아보았으니 그럼 저자들의 방법론에 대해서 살펴보겠습니다. 결국MLLM의 학습은 위에 수식2번과 같이 언어 모델에서 나온 출력 텍스트 토큰만을 가지고 진행된다는 점에서, projector가 기존 Vision Encoder에서 추출한 세밀한 시각적 정보들을 LLM 모델에게 잘 전달해줄지에 대하여 저자들은 의문을 제기합니다.
즉, vison backbone에서 나온 visual token들이 text token들과 alignment를 수행할 때 text 중심의 목적 함수가 줄어드는 방향으로 projection되다보니 자신들이 원래 지니고 있던 세부적인, 유용한 정보들이 그 과정에서 사라지게 된다고 생각하는 것이죠.
그래서 저자들은 이를 실제로 판단하기 위해서 LLAVA 모델 내 LLM의 Visual token과 그들의 vision encoder인 CLIP ViT의 feature를 뽑아서 그 둘의 CKNNA 유사도를 계산하였다고 합니다.
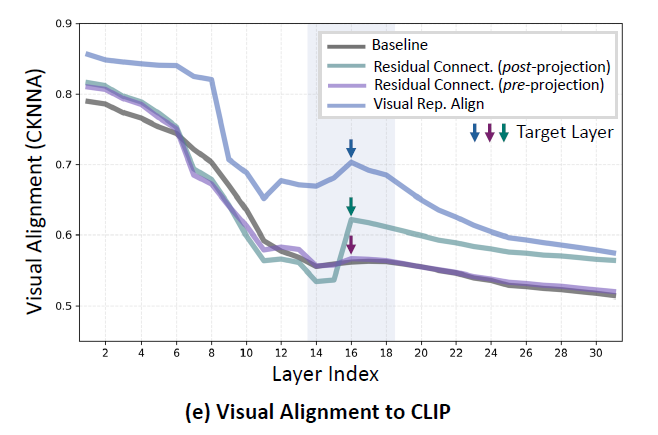
그 결과는 위와 같은데 일단 다른 라인들은 보실필요 없이 Baseline에 해당하는 line만 살펴보시면 되겠습니다. Baseline에서 살펴보시면 Layer Index가 초기인 경우에는 feature의 유사도가 서로 비슷하지만, 중간에서 후반부로 가면 갈수록 유사도가 급격히 떨어지는 것을 확인할 수 있습니다. 이 유사도가 떨어진다는 의미는 기존 Vision Encoder가 추출했던 시각적 정보가 LLM이 연산하는 Visual token과 다르다는 것이고 이 다르다는 것이 꼭 나쁜 것은 아닐 수 있지만 저자들이 생각하는 세밀하면서도 중요한 시각 정보의 유무차이로 인해 유사도가 떨어지는 것이 아닌가 하는 걱정을 하고 있습니다.
그리고 위에 그래프 다시 보시면 16번째 레이어를 Target Layer라고 표현하고 있는데, 이 Target layer가 뒤에서도 소개드리겠지만 LLM이 Vision specific task를 수행하는데 있어 매우 중요하게 사용되는 layer라고 저자들은 주장합니다. 그 이유에 대해 저자들이 뒤에서 실험한 결과도 있고 앞선 연구에서도 언어모델의 중간 레이어단 특징을 활용하는 것이 비전 중심의 테스크를 수행하는데 있어 가장 좋은 성능을 얻을 수 있다는 점에서 저자들은 16번째 layer를 앞으로 자주 언급하게 됩니다. 그리고 실제로 이 미들 레이어를 중심으로 시각적 정보를 재보충하려고 하구요.
Residual connection with post-projection features
그러면 Vision Encoder가 가지는 고유의 시각적 정보를 어떻게 LLM의 Visual token에 전달할 수 있을까요? 저자들은 이 시각적 정보를 전달하기 위해 총 3가지 방법론을 제안합니다.
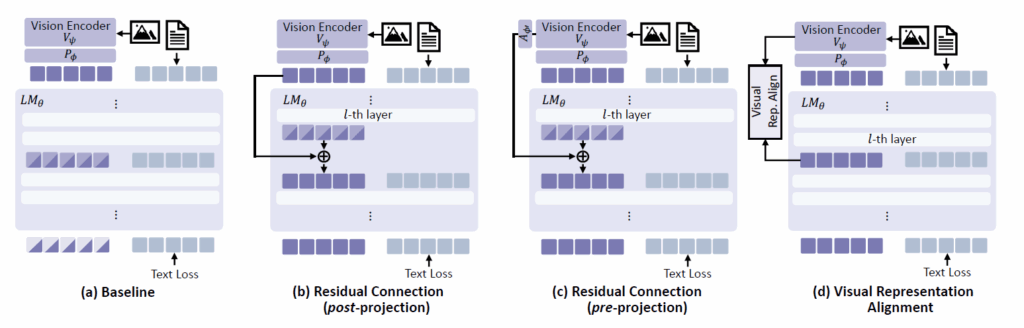
우선 제일 왼쪽의 Baseline은 기존의 MLLM의 framework로 Vision Encoder에 대한 시각적 정보를 LLM에 전달하는 과정이 없는 방식이고, b~d가 저자들이 실험에 사용한 방법들입니다. 우선 b부터 살펴보시면 Vision Encoder의 output token을 Projector를 태운 뒤 LLM의 중간 레이어에 residual connection을 수행하는 것입니다. 수식으로 표현하면 아래와 같습니다.

이러한 (b) 방식을 저자들은 Projector를 타고 나온 feature를 사용한다는 의미로 post-projection이라고 명칭합니다. 이러한 b 방식은 아까 위에서 보여드린 CKNNA 유사도 계산에서 Baseline 대비 더 높은 유사도를 가지고 있는 것을 아래 좌측 그림에서 확인하실 수 있습니다.
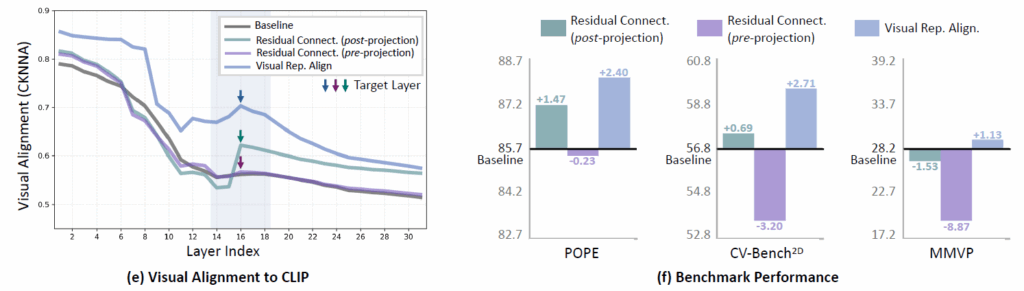
그리고 실제 Benchmark performance에서도 MMVP를 제외하고는 2개의 벤치마크에서 조금 더 좋은 성능을 보여주고 있는 모습입니다. 즉, Vision Encoder의 시각적 정보가 LLM에 추가되는 것은 MLLM의 성능에 긍정적인 영향을 미친다고 볼 수 있는 것이죠.
근데 이러한 b 방식의 residual connection은 결국 projector를 타고 나온 visual embedding을 잔차 연결 해준 것이라 여전히 projector를 타고 나온 시각 토큰과 encoder의 시각 토큰 사이의 차이가 해결된 것은 아니었습니다.
쉽게 말해 Projector를 통과하는 과정 자체에서 Vision Encoder의 고유한 특징 정보가 손실될 수도 있다는 것이었죠. 그래서 저자들은 vision encoder의 고유의 시각적 표현이 그대로 전달되었으면 하는 바람에 projector를 타고 나온 특징이 아닌 vision encoder에서 추출한 특징을 곧바로 전달하는 실험을 추가로 진행하게 됩니다.
그 과정이 바로 아래 그림과 같은 (c)의 그림입니다.
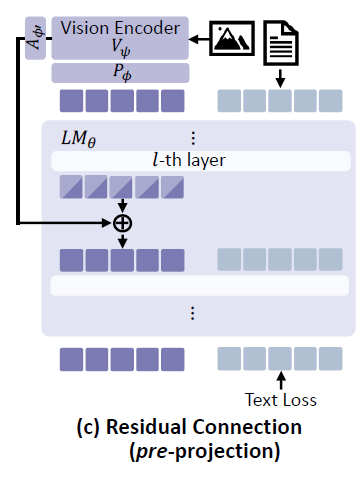
Vision Encoder에서 Projector를 통과해서 나온 token이 아닌, Vision Encoder의 output에서 곧바로 또 다른 Adapter?를 추가하여 LLM의 visual token과 차원수를 맞춘 뒤 Residual Connection을 해주는 방식입니다. 즉 Projector를 통과하기 이전의 visual token을 전달해준다는 관점에서 Pre-projection이라고 저자들은 명칭하였습니다.
이 Pre-projection 방식은 위의 CKNNA 유사도와 3가지 벤치마크 성능 비교에서 Baseline과 Post-projection(b방식) 대비 긍정적인 결과를 얻지 못했습니다. 즉 유사도도 낮게 측정이 되며 정량적 성능도 크게 떨어지는 모습을 보이는 것이죠. 저자들이 추측하기로는 아무래도 projector를 통과하지 않은 feature이다보니 language token들과의 alignment가 맞지 않아서 멀티모달 특징 표현력에 오히려 방해가 된 것이 아닌가 생각합니다.
Representation alignment with encoder features
저자들은 post-projection(b)과 pre-projection(c) 방식의 실험을 통해 2가지 결과를 얻을 수 있었습니다. 첫째로 Vision Encoder만이 가지는 visual information을 LLM의 visual token에게 전달해주니 성능이 개선이 된다는 점이며, 둘째로는 이 Visual token을 전달할 때 text token들과의 alignment를 방해하게 될 경우에는 성능이 오히려 더 하락할 수 있다는 것이죠.
즉, 무작정 Vision Encoder의 정보를 넣으면 오히려 text token과의 alignment가 방해를 받을 수 있어 성능이 떨어지니 alignment를 깨지 않는 선에서 적당히 유의미한 정보를 전달해주어야만 합니다. 근데 이러한 적당히를 찾아내는 것은 말은 쉽지 실제로는 매우 어려운 문제입니다.
그래서 저자들은 마지막 실험으로 Visual Encoder의 token들을 LLM의 Visual token에게 전달해주는 방식 대신 역으로 LLM의 Visual token이 Visual Encoder의 token 정보를 배울 수 있도록 설계하였습니다. 이렇게하면, 기존의 Text-level에서 목적함수를 주던 것과 달리 visual token에게도 기존의 visual information을 너무 잃지 말라는 제약을 주기 때문에 text modality와의 alignment를 고려하면서 동시에 visual information의 손실을 예방할 수 있었다고 합니다.
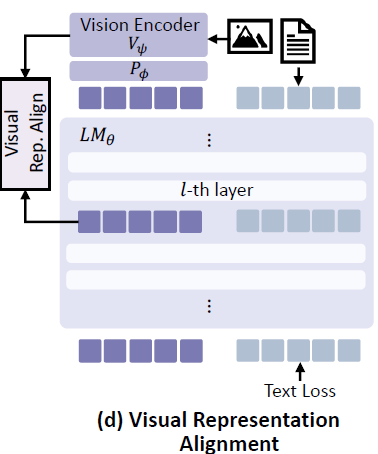
실제 구현 방식도 굉장히 단순한데, LLM의 visual token을 FC layer 3개로 구성된 새로운 Learnable Projector에 태워서 Visual Encoder와 동일한 차원의 벡터로 만든 다음 Visual Encoder의 token과 코사인 유사도 계산을 진행하는 것입니다. 이때 Visual Encoder는 같이 학습되는 것이 아닌 freeze 되어있습니다.
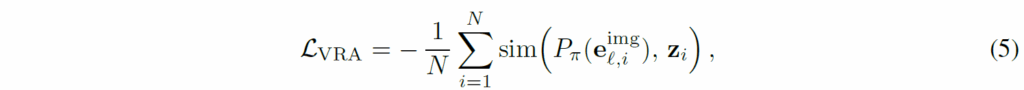
수식으로 표현하면 위와 같고 이 Visual token에 대한 규제화가 기존의 text 기반의 목적 함수랑 같이 적용된다는 점을 말씀드립니다.
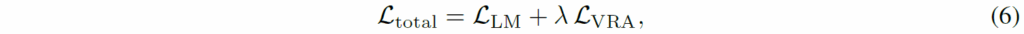
수식5를 통한 visual token의 규제화 추가 방식이 residual connection과 비교해서 상당히 높은 CKNNA 유사도를 보여주었는데, 이는 시각적으로 세부적인 의미적 정보들을 유지하는데 있어서 residual connection과 같이 더하는 방식보다는 규제화를 취하는 방식이 더 적합했음을 귀납적으로 보여준다고 보시면 되겠습니다. 그리고 CKNNA 유사도가 더 높은만큼 3가지 벤치마크에서도 Baseline대비 항상 더 좋은 성능을 보여주게 되는데 이 역시 Visual Encoder의 information이 LLM의 visual token에게 도움이 된다는 것을 의미합니다.
From Encoder feature to other VFMs
그리고 이 Visual Representation Alignment(VPA) 방식의 장점은 한가지 더 있습니다. 앞전의 residual connection 방식은 visual encoder의 feature가 LLM의 visual encoder한테 더해지는 과정이 있어야만 하기 때문에 학습 단계 뿐만 아니라 추론 단계에서도 따로 추가적인 연산 과정이 요구되었습니다.
반면, VPA 방식의 경우에는 규제화 또는 Knowledge Distillation의 방식으로 학습때만 사용하게 되고 추론 단계에서는 Adapter니 새로 추가한 Projector 같은 것들을 모두 제거해버릴 수 있습니다. 이 말은 반대로 생각하면 MLLM에서 사용된 Vision Encoder가 CLIP이더라도 VPA를 계산할 때 사용되는 Target visual token은 DINOv2와 같은 다른 Vision Foundation model을 사용해도 된다는 것입니다.
실제로 DINOv2나 SAM과 같은 vision modality만을 고려해서 학습한 모델의 경우 CLIP처럼 img-text 양쪽 모달리티를 고려해서 학습한 모델보다 vision image에 대한 더 세부적인 또는 구조적 정보와 같은 고유 정보를 더 잘 포착하는 경향이 있다고 합니다.
그래서 저자들은 굳이 Vision Encoder의 feature와 LLM의 visual token이 서로 alignment 맞아야 한다기 보다는 LLM의 Visual token이 놓치기 쉬운 visual information을 다른 Vision Foundation model을 보고서라도 잘 배우기를 바라는 것이죠.
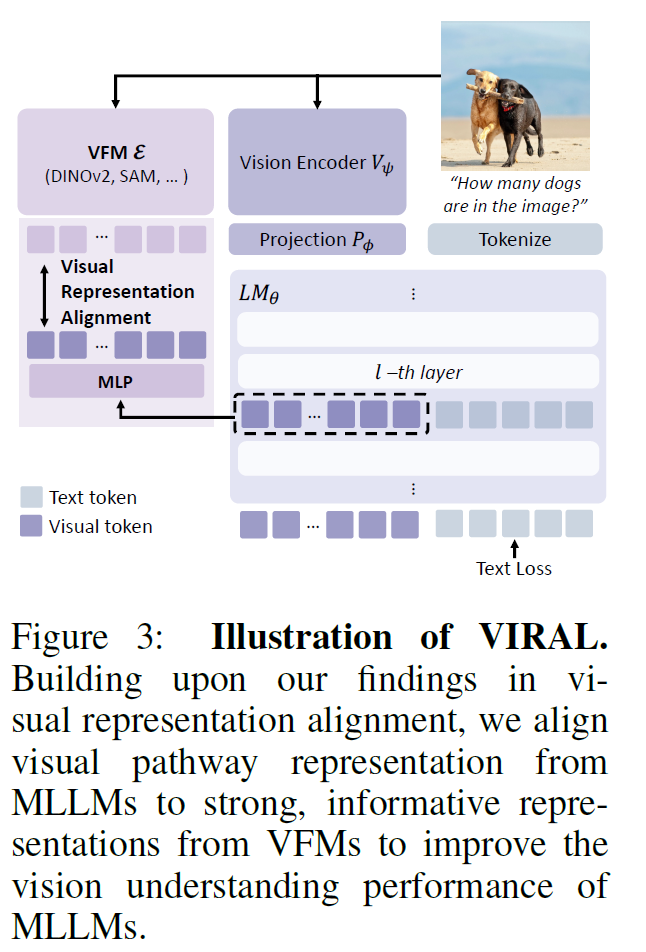
그래서 저자들이 제안하는 최종 방법론은 위의 그림과 같습니다. Vision Encoder와 별개로 DINOv2와 같은 Vision Foundation Model이 동일하게 feature를 추출합니다. 그리고 해당 feature에 대해서 LLM의 visual token이 3개의 FC layer로 구성된 MLP를 타고 나와 코사인 유사도를 계산하여 loss로 사용하는 것이죠.
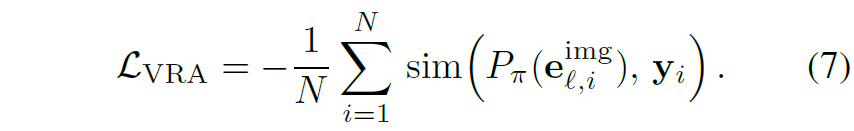
Experiments
그럼 실험 결과를 쭉 훑고 리뷰 마치겠습니다.
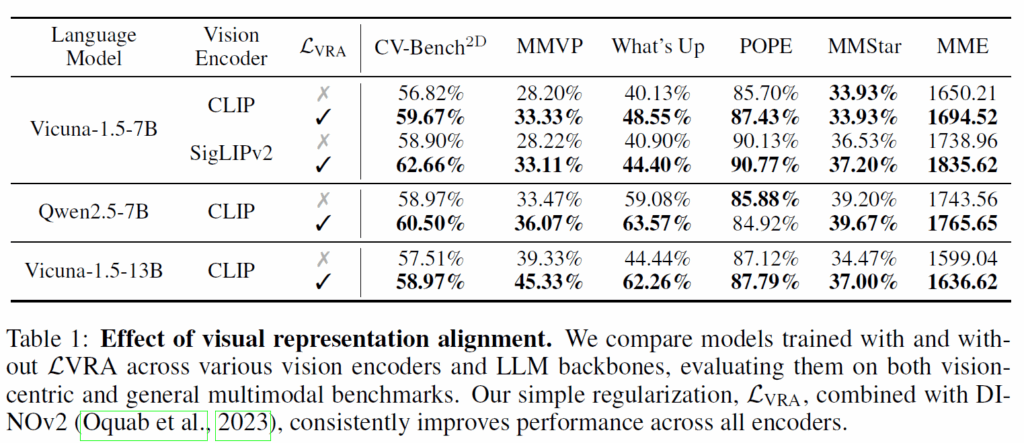
우선 표1은 기존의 MLLM에게 자신들이 제안하는 VRA loss를 적용하였을 때 성능이 얼만큼 개선이 되는지를 나타내는 것입니다. 언어모델을 무엇을 쓰든 그리고 CLIP이나 SigLIP 어떤 Vision ENcdoer를 사용한다 하더라도 VRA를 사용하였을 때 대부분의 벤치마크에서 성능이 향상됨을 볼 수 있었습니다.
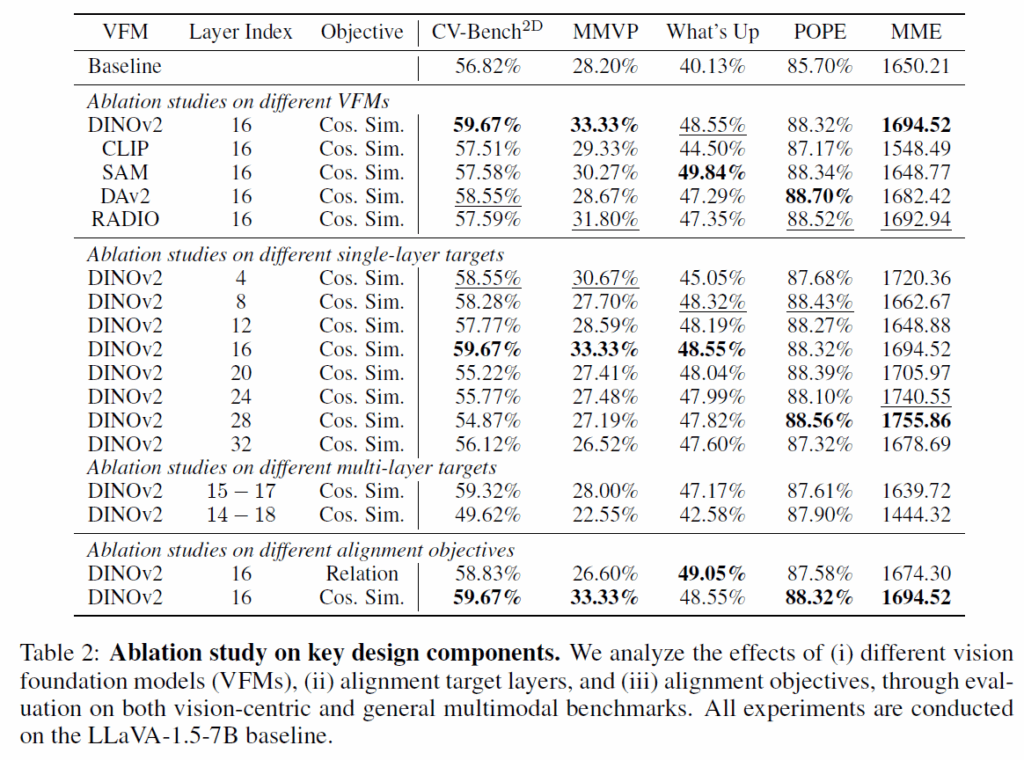
표2는 Vision Foundation model의 종류, 그리고 LLM의 여러 layer 중 몇번째 layer에 대하여 VRA loss를 사용하면 좋은지에 대한 실험 등이 나타나 있습니다.
우선 제일 위에 Vision Foundation model에 대한 실험으로 저자들은 DINOv2, CLIP, SAM, DAv2, RADIO 총 5가지 모델에 대하여 VRA loss 계산 실험을 진행하였으며, 대부분의 VFM들이 CLIP보다 더 좋은 성능 이점을 보여주었으나 특히 DINOv2가 다수의 벤치마크에서 높은 성능 향상도를 보였기 때문에 DINOv2를 최종 모델로 선정하였다고 합니다.
그리고 두번째 실험은 alignment를 맞추기 위한 LLM의 target layer를 몇번째 순서로 정할 것인지에 대한 실험인데, 재밌는 점이 총 32개의 layer로 구성된 LLM에서 중간번째에 해당하는 16번째 layer를 VRA loss 계산을 위한 target layer로 선정하였을 때가 5개 중 3개의 벤치마크에서 가장 좋은 성능을 보여주게 되었습니다. 특히 5개의 벤치마크 중 CV-bench, MMVP, What’s up이라는 벤치마크가 모델에게 spatial reasoning 또는 object counting 등을 요구하는 vision-centric task로 알려져있는데 이 세가지 벤치마크에서 가장 좋은 성능을 보여주는 모습입니다.
즉, 앞선 연구들에서도 나왔던 결과이긴 하지만 MLLM이 vision-specific task를 수행할 때에는 제일 마지막 단의 layer output을 사용하는 것이 아니라 중간 단계 또는 더 앞단계의 layer를 사용하는 것이 좋다라는 것을 확인할 수 있었네요.
마지막으로 표2의 맨 아래의 실험은 VRA loss를 설계할 때 visual token들 간의 코사인 유사도 기반으로 loss를 계산할지, 아니면 structural relationship을 비교하는 식으로 loss를 설계할지에 대한 실험입니다. structural relationship 계산하는 방식은 그냥 각각의 visual token들끼리 self-similarity map을 만든 다음에 해당 유사도 맵끼리 MSE loss를 계산하는 방식이라고 하는데, 이 방식이 이전 연구들에서 feature map distillation하는데 있어 효과적이라는 주장이 몇번 있었으나 저자들의 실험 환경에서는 코사인 유사도 방식이 더 나았다고 합니다.

위의 그림 5는 정성적 결과를 나타낸 것인데, baseline에 해당하는 LLaVA와 달리 저자들의 VRA loss가 적용된 경우 PCA 시각화에서도 전경과 배경이 더 구분이 잘 된다고 저자들은 주장합니다. LLaVA 결과와 비교하면 맞는 말인 것 같기는한데 무언가 낮은 해상도를 억지로 키워서 그런건지 시각화 결과가 살짝 애매하긴 하네요.
그 외에도 이미지 내 객체들의 수를 정확히 카운팅 한다거나 위치 관계를 정확히 알아야만 답변할 수 있는 어려운 문제들에 대해서도 잘 대답한다고 합니다.
결론
사실 저자들의 VRA loss는 결국에 feature map에 대한 distillation이었습니다. distillation하는 방식에 대해서도 기존에 많이 활용하는 코사인 유사도를 사용했고 새롭게 제안된 부분은 딱히 없다고 생각이 듭니다. 그런데 이제 MLLM이 visual information이 부족하다? 그리고 그 문제가 text 중심의 목적 함수만을 가지고 학습이 되어서 그렇다 라는 문제정의 그리고 이를 해결하기 위해 진행해 나갔던 실험들은 흥미롭게 잘 읽혔던 것 같습니다.
하지만 실험을 하면서 밝혀낸 내용들 중 적지 않은 부분들이 앞선 연구들에서 이미 잘 알려진 내용들로 보여서 이쪽 분야를 잘 아는 사람이라면 오히려 평가가 박할 수도 있겠다? 라는 생각도 들긴 할 것 같습니다. 저는 MLLM에 대해 많이는 알지 못하는데 그래서 그런지 재밌게 잘 봤습니다.
안녕하세요 정민님 재미있는 논문 리뷰 감사합니다.
Table2의 하단 두가지 실험에 대해 질문이 있습니다. 타겟이 structual relationship을 유사하게 하는것보다 feature map을 직접적으로 유사해지도록 학습하는게 유의미 했다고 확인했는데, 혹시 그 이유에 대한 분석이 있을까요? 혹시 structual 로 학습하는데 라인이 구불구불하여 이러한 점이 학습에 노이즈로 작동한건지 궁금합니다.
해당 실험 결과에서 MMVP 벤치마크 제외는 성능 변화가 적고 What’s up은 오히려 structual 만을 학습하는게 좋은 결과를 확인할 수 있는데, 혹시 해당 데이터셋의 특성때문에 Feature map에 노이즈가 많아 structual만을 이용하는게 좋았던건지 궁금합니다.
감사합니다
안녕하세요.
제가 기억하기로는 이론적인 분석은 없이 귀납적으로 증명했던 것으로 기억합니다.
라인이 구불구불하여 학습에 노이즈로 작동했다는 말의 의미를 제가 온전히 이해하지 못하여 그와 관련된 답변은 드리기가 조심스럽네요^^..
마찬가지로 MMVP와 what’s up 데이터셋의 각 특성에 대해서 저자들이 구체적인 언급이 없어서요. 모든 데이터셋에서의 항상 cos sim 기반 loss가 structual relationship 기반 loss보다 좋다는 것은 아니지만 저자들이 평가한 5가지 벤치마크 중에서 4개 이상이 더 좋더라 정도로 이해해주시고넘어가주시면 어떨까 합니다. 아무래도 벤치마킹 실험 양이 다른 주제보다 상대적으로 많은 VLM task라서 하나의 데이터셋을 붙잡고 분석하고 그러지는 않는 듯 싶네요.
안녕하세요 정민님 흥미로운 리뷰 감사합니다.
MLLM이 VQA나 Visual Grounding 에서 생각보다 visual hallucination 현상이 많은 것을 보고, 평소에 MLLM은 여전히 visual 적인 학습에서 부족한 점이 있는 건가? LLM 구조와 Visual encoder간의 align이 어떻게 잘 안 맞나보다 라고만 생각해왔었는데, 원인 분석과 문제 해결을 위한 실험을 보여준 논문인 것 같아 흥미롭게 읽었습니다.
질문이 2가지 있습니다.
1. 저자들이 제안한 방식이 visual encoder token을 LLM visual token에 일방적으로 전달하는 것 보단, LLM visual token 도 따로 projector를 구성해서 visual encoder token 벡터와의 cos sim으로 visual적인 목적함수 제약을 만들어낸 것으로 이해했습니다. 그런데, 학습 이후의 유사도 실험으로 보이는 (e) 실험에서, LLaVa 내의 LLM visual token과 CLIP ViT feature 간의 유사도 계산 시 학습 때 사용한 방식인 cos sim 말고 CKNNA 라는 유사도를 사용하는 이유가 무엇인가요?
2. method의 (e) 차트에서 target layer가 16번째 layer로 정해진 이유가, 유사도의 경향성이 점차 감소하다가 갑자기 상승하며 역전되는 부분이라서, 다른 layer보다 좀 더 visual alignment의 요충지가 된 것으로 이해했습니다. 실험파트의 table2에서 2번째 실험과 같이 보니 LLaVA 아키텍쳐에서만 해당되는 내용인 것 같아서,, Language model이 Table 1에 보이는 Vicuna, Qwen 등으로 layer index를 달리해보면 중간 layer가 요충지가 아닌 또 다른 결과가 나올 수도 있겠단 생각이 듭니다. 저자들의 이 부분 언급이 있었을까요?
감사합니다.
안녕하세요.
질문에 답을 드리면
1. 왜 실험에서 visual encoder의 token과 LLM의 visual token끼리 유사도 정량적 측정시 cos sim이 아닌 CKNNA를 사용하냐에 대하여 저자들이 특별히 그 이유를 설명하지는 않지만 제 생각에는 지금 모델이 학습 때 수식7번과 같이 cos sim으로 loss를 계산하여 학습하고 있거든요. 그러다보니 당연히 학습 때 두 토큰의 cos sim가 높아지도록 학습이 되다보니 유사도 정량 평가시에 cos 유사도를 사용하게 되면 자신들의 방법론이 당연히 높게 나올 수 밖에 없어서 다른 유사도 측정 방식을 도입한 것이 아닐까 싶습니다.
2. 음 일단 저자들이 특별히 언급한 부분은 없었습니다. 이전 연구들에서 vision 중심의 task를 수행할 때는 LLM의 뒷단 layer보다 중간단 layer의 feature가 더 효과적이었다는 실험적 결과들을 이미 도출해놓은 상태이고 저자들은 이를 한번 더 증빙한 셈이어서요. 이전 연구들이 어떠한 LLM을 가지고 접근했는지는 잘 모르겠지만 VLM 학습 framework이 대부분 유사하기 때문에 다른 LLM을 썼다 하더라도 Vision Encoder와 함께 학습되는 과정에서 유사한 결론이 도출되지 않을까 싶습니다.