안녕하세요. 오늘 리뷰할 논문은 SIM-COT: Supervised Implicit Chain-of-Thought입니다. 아직 학회에 게재된 논문은 아니지만 InternVL으로 유명(?)한 InternLM의 논문으로 LLM의 CoT에 관한 연구입니다.
Introduction
“측정할 수 있는 것은 측정하라. 그리고 측정할 수 없는 것은 측정 가능하게 만들어라” – 갈렐레오 갈릴레이
LLM의 추론 능력은 명시적(explicit) prompting (Chain-of-Thought, CoT)를 통해 더욱 강화됩니다. 이러한 explicit CoT는 LLM이 복잡한 문제를 단계별로 해결하도록 유도하는 것으로 추론 능력을 향상시키고 논리적 추론이 필요한 수학 문제 풀이, 프로그래밍 등의 문제를 잘 해결할 수 있도록 해주었습니다. 하지만, 이러한 CoT도 단점이 몇가지 존재합니다. 중간 추론 단계를 언어로 prompting하기에 다양한 중간 추론 단계가 있는 경우 prompt로 주지 않은 방법은 잘 거치지 않는 다는 단점이 있습니다. 이를 해결하기 위해 중간 추론 단계를 길게 작성하면 추론 비용이 증가하고 불필요하게 추론하는 over-thinking현상이 나타날 수도 있습니다.
이러한 명시적인 CoT의 유연함 부족, 비효율성을 해결하기 위해 함축적(implicit) CoT가 최근에는 연구되고 있습니다. 이 방법은 추론 과정을 자연어(text token sequence)를 사용하는 대신 연속적인 잠재 공간(continuous latent space)에서 표현하는 방법입니다. 이렇게 CoT를 사용하면 latent representation가 하나의 text token보다 더 많은 정보를 담고 있기 때문에 적은 수의 잠재 벡터(latent vector)만으로도 효율적인 CoT가 가능해집니다. 하지만, implicit CoT는 explicit CoT보다 속도가 빠르고 효율적이지만 성능이 낮기 때문에 explicit CoT를 대체하기에는 한계가 존재했습니다.
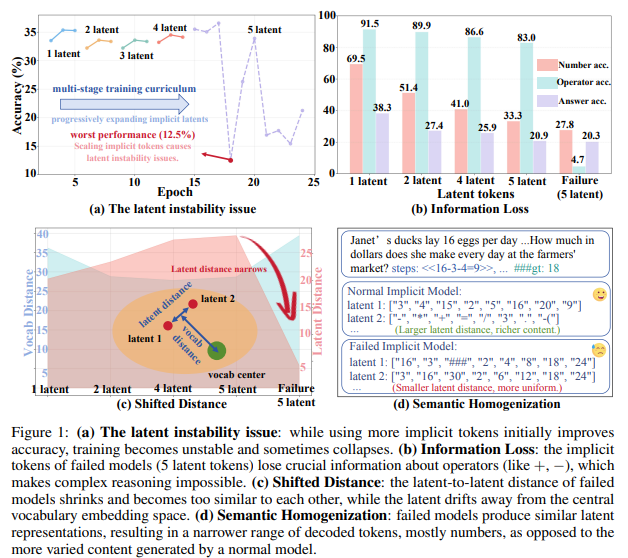
저자는 성능 격차를 줄이기 위해서 implicit CoT에서 사용하는 latent token의 수를 늘리는 것으로 속도와 성능 사이의 최적의 trade-off를 찾으려 노력했습니다. 하지만, Figure 1의 (a)를 확인하면 implicit CoT에는 latent instability 문제가 존재합니다. latent token의 수를 늘리면 초기에는 정확도가 향상되다가 학습이 불안정해지다가 collapse하는 현상을 말합니다. (b)는 latent token이 늘어남에 따라 숫자와 연산자(operator)의 정확도를 확인할 수 있습니다. 정상적인 복잡한 추론을 수행할 때에는 숫자 정보와 연산자(operator) 정보를 잘 표현해야 하지만, failure의 경우에는 operator에 대한 정보를 거의 잃어버리는 것을 확인할 수 있습니다. (c)는 latent space 내에서 latent distance 감소와 latent representation이 중심으로부터 멀어지는 drift 현상을 보여주고 있습니다. 즉, 여러 벡터들이 임베딩 공간의 중심부로부터 멀어지고 있습니다. (d)는 semantic homogenization의 예시입니다. 정상 모델은 숫자 정보와 연산자 정보가 뚜렷하게 구분되지만, 실패한 모델은 의미적으로 비슷해져서 다양한 정보를 담을 수 없게 됩니다.
위 Figure 1의 여러 실험의 결과는 latent instability 문제의 원인을 보여주고 있습니다. 기존 implicit CoT는 단계별 supervision이 부족하여 내부의 latent representation이 다양해지지 않고 서로 비슷해지는 것이 이러한 latent instability의 문제입니다. 저자는 위 결과를 토대로 단계별로 supervision을 주는 것의 중요성을 강조하며 Supervised IMplicit-CoT(SIM-CoT)를 제안합니다. 아이디어는 굉장히 심플합니다. 결국 중간 추론 단계에서 supervision을 주는 것을 통해서 latent instability 문제를 해결하는 것이고 추가적인(auxiliary) decoder를 활용하여 implicit token과 explicit reasoning 단계를 정합합니다. 이 추가적인 디코더는 학습단계에서만 사용되기에 추론할 때에는 추가적인 비용없이 정확도와 안정성, 효율성을 제공하며 추가적인 디코더의 역할이 latent 벡터를 text로 사영(projection)시키는 것이기에 사람이 이해할 수 있는 형태로 디코딩하는 것으로 단계별 추론을 시각화, 디버깅하는 등 모델의 해석 가능성(interpretability)도 제공할 수 있습니다. plug-and-play 방식으로 보조적인 인코더를 추가하는 저자의 SIM-CoT는 기존 방법론과도 같이 적용할 수 있으며 학습을 안정적으로 만들어주는 동시에 정확도도 향상시키고, 추론시에는 추가적인 디코더를 사용하지 않기에 효율성까지 챙겼다고 볼 수 있습니다.
저자가 제안하는 SIM-CoT의 contribution은 다음과 같습니다.
- implicit CoT의 implicit instability문제를 분석하여 implicit instability의 문제가 단계별 supervision의 부족에 있음을 주장합니다.
- 단계별 supervision을 통해 LLM의 추론할 때 overhead를 최소화하면서 성능을 개선시키고, 설명 가능성도 얻을 수 있습니다.
- 여러 in-domain, out-of-domain 실험을 통해서 SIM-CoT의 일반화 능력을 증명하였으며, GPT-2, LLaMA3등 다양한 LLM에도 일관되게 적용할 수 있습니다.
Analysis of Implicit CoT: The Latent Instability Issue
먼저, 저저는 기존 implicit CoT의 한계를 분석합니다.
다시 한번 Figure 1을 분석해보겠습니다. (a)는 implicit token의 수를 점진적으로 늘렸을 때의 훈련과정을 보여줍니다. 초기(latent 1~4)에는 latent token의 개수가 증가함에 따라 성능이 좋아집니다. 이는 implicit CoT의 가능성을 보여줍니다. 하지만, token의 개수를 5개로 늘리는 순간 정확도가 급격하게 떨어지며 안정적으로 학습을 하지 못하고 있습니다. 이러한 implicit instability는 LLM이 implicit CoT에서의 token의 수에 굉장히 민감하게 반응하고 있음을 의미합니다.
(b)는 서로 다른(숫자와 연산자)가 어떻게 영향을 받는 지에 대한 분석입니다. 저자는 숫자, 연산자, 최종 답변의 정확도를 각각 계산하여 확인합니다. 숫자가 증가함에 따라 전반적으로 성능이 감소하고 있습니다. 특히, 연산자의 성능이 크게 하락하는 것을 확인할 수 있습니다. 저자는 이러한 경향성을 통해 compositional reasoning은 implicit CoT만으로는 한계가 있기 때문에 세밀한 supervision의 필요성을 강조하고 있습니다.
(c)는 훈련 중 latent space 내 latent representation의 기하학적 특성을 분석한 결과입니다. 빨간색으로 칠해진 공간은 laten 거리이고 파란색으로 칠해진 공간은 vocab의 거리입니다. 모델이 collapse하기 시작하면서 latent 거리가 줄어들기 시작하는 데 이는 벡터들이 수렴하여 점점 동일해진다는 것을 의미하고 동시에 vocab의 거리는 증가하고 있습니다. 즉, 벡터들이 수렴하며 점점 동일해지고 있고 vocab의 임베딩 공간으로부터 멀이지게 수렴한다는 것을 의미합니다.
마지막으로 (d)는 정상적인 모델과 collapse한 모델의 token의 내용을 정성적으로 비교한 결과입니다. 정상적인 모델은 다양하고 의미 있는 내용들을 담고 있지만, collapse한 모델은 모델의 의미들이 비슷(homogeneous)해지고 있습니다. collapse한 모델은 모두 숫자만을 포함하고 있으며 연산자, 기호 등의 정보는 포함하지 않고 있습니다. 이는 앞서 분석한 내용과 동일한 내용을 저자가 위에서의 정량적 분석에 정성적 분석을 더해 저자의 주장을 강화하고 있는 내용입니다.
요약하면, supervision없이 학습하는 기존의 implicit CoT의 latent space는 학습을 진행하며 퇴화하고 단계 별로 구분되는 추론 단계를 표현하는 능력을 잃어버립니다. 저자는 이러한 분석을 토대로 latent space를 안정화하고 각 latent에 다양한 고유한 의미를 부여하기 위해 단게별 supervision을 도입하여 문제를 해결합니다.
Method
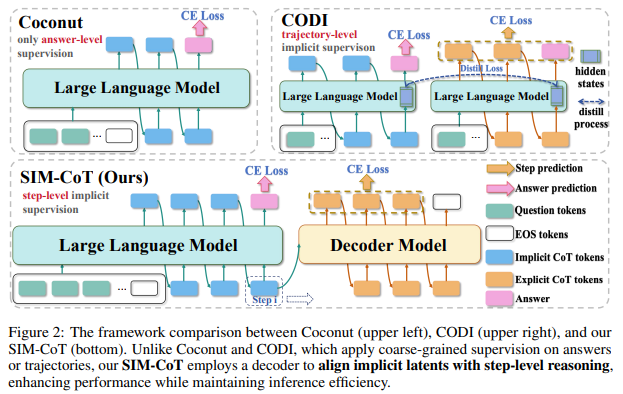
Figure 2의 Coconut과 CODI는 모두 기존의 implicit CoT 방법론입니다. Coconut과 CODI는 supervision이 있기는 하지만, Coconut는 정답 수준의 supervision, CODI는 좀 더 나아가 trajectory-level(궤적)의 supervision을 제공하지만, 단계적인 supervision을 제공하지 않아 결국 latent가 늘어날 수록 앞선 분석에서 확인할 수 있었던 implicit instability 문제를 보이게 됩니다.
저자가 제안하는 SIM-CoT는 단계별 implict supervision은 LLM에서 고정된 횟수의 추론 단계를 진행하며 각 단계의 last hidden state를 하나의 latent로 삼아 다음 토큰 벡터에 추가됩니다. 이렇게 K 번 단계를 진행한 후에는 explicit phase로 전환하여 vocabulary를 통해 최종 답변을 생성합니다. 이때 decoder는 학습에만 사용되고 추론시에는 사용되지 않습니다.
Notation
저자는 \mathcal{V}를 vocab 집합, E를 토큰 임베딩 행렬이라고 할때, 입력 질문을 x = (x_1,...x_T) \in \mathcal{V}^T이라고 정의합니다.
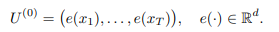
저자는 \mathbf{x}_{1:t}에 대해 autoregressive LLM를 실행하며 last hidden state를 h(\mathbf{x}_{1:t})로 정의합니다.
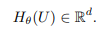
학습할때 supervision로 i번째 explicit 추론 단계 문장을 s_i라고 정의하고 최종 답변을 a라고 정의합니다. decoder의 매개변수는 \phi이고 LLM의 매개변수는 \theta로 정의합니다.
Implicit Phase
저자는 reasoning 단계의 수를 K로 사전에 정해 고정합니다. 각 단계에 LLM은 이전까지의 context를 입력으로 받아서 last hidden state h_i를 구합니다. 그런 다음 h_i를 다음 latent token으로 concat하여 입력합니다.
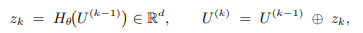
\circ는 concat입니다. 이러한 구성은 implict CoT를 구성하여 연속적인 hidden state들의 sequence로 autoregressive하게 입력됩니다.
Explicit Phase
implicit token을 모두 생성하면, explicit decoding 단계로 들어갑니다. W_o를 output projection 행렬 즉, LM 헤드라고 할때 teacher forcing 기법을 통해 학습합니다.
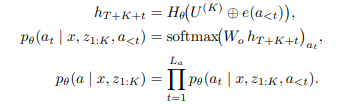
Training-Time Deocer & Step-level Supervision
implicit CoT에서 latent 벡터 z_k를 생성하지만 구체적으로 이 벡터들이 무슨 추론 단계를 의미하는 지는 보장하지 않습니다. 저자는 이때문에 학습이 불안정해지거나 collapse한다고 말합니다. 따라서 decoder를 붙여서 latent z_k가 대응되는 텍스트 reasoning step s_k를 생성하도록 강제합니다.
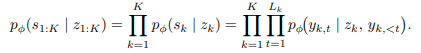
위 수식은 step-level likelihood로 latent z_k가 주어지면, 그것이 대응하는 구체적인 reasoning s_k를 생성하는 것을 나타내는 수식입니다.
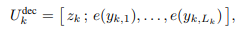
위 수식은 decoder의 입력 시퀀스를 보여줍니다. latent + reasoning token 을 입력 시퀀스로 입력받습니다.
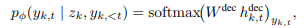
위 수식은 일반적인 LM과 동일한 방식으로 step-level 디코딩이고, latent z_k를 prefix로 입력하여 latent z_k에 기반한다는 것을 학습한다는 점만 다릅니다. h^{dec}_{k,t}는 디코더가 t번째에서 추출한 hidden state입니다. [late]W[/latex]는 LM 헤드입니다.
학습 단계의 loss는 다음과 같습니다. k번째 step 토큰에 대한 negative log-likelihood로 latent z_k가 대응하는 reasoning token s_k를 얼마나 잘 생성하는 지를 학습합니다.
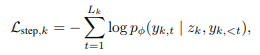
Objectives
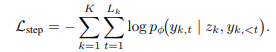
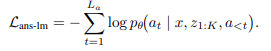
step-level supervision은 위에서 설명한 loss와 동일합니다. ans-lm loss는 최종 답변 생성을 학습하는 loss입니다. prefix가 추가된 것 외에는 일반적으로 LM이 학습할때 사용하는 크로스 엔트로피 loss와 동일합니다.
최종 loss는 다음과 같습니다.
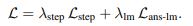
수식은 좀 복잡하지만 사실은 굉장히 간단한 구조입니다. 결국 LLM에 디코더를 붙이고, 각 layer의 hidden state를 latent token으로 사용, autoregressive하게 디코더를 학습하여 단계별 latent token이 explicit한 출력 token을 따라갈 수 있도록 학습하는 겁니다.
Experiments
저자는 기존 연구들을 따라 GSM8K-Aug 데이터셋 등을 사용하여 CoT 모델을 학습하고 평가합니다. GSM8K 데이터셋은 수학 데이터셋으로 LLM의 논리적 추론 능력을 확인할 수 있는 데이터셋입니다. 일반적으로 구조화된 수식 표현의 연쇄를 확인할 수 있습니다. <<12*3=36>><<9*2=18>><<17*2=34>><<36+18+34=88>> 와 같은 수식을 평가하는 데이터셋입니다. 그 외에도 SVAMP는 초등학교 수준의 산술 단어 문제를 평가하는 데이터셋으로 모델의 강건성을 평가할 수 있고, GSM-Hard는 GSM-8K 데이터셋의 변형으로 좀 더 큰 숫자와 복잡한 숫자의 연산을 평가할 수 있습니다. MultiArith는 여러개의 문장을 종합하여 두 단계 이상의 연산을 수행해야하는 문제들로 구성된 데이터셋입니다.
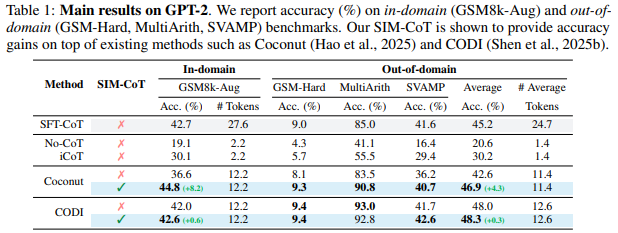
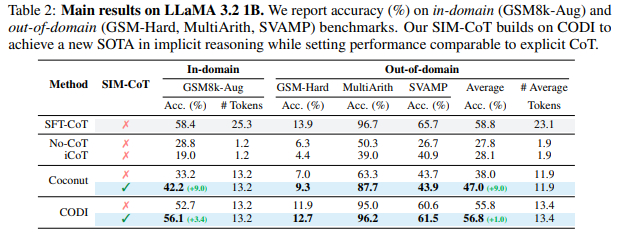
Table 1,2는 각각 GPT-2와 LLaMA 3.2 1B 모델에 저자가 제안하는 방법록은 적용했을 때의 성능을 확인할 수 있습니다. plug-and-play 방식으로 기존 연구인 Coconut과 CODI에 추가적으로 사용할 수 있으면 SIM-CoT를 적용했을 때에 높은 성능 향상을 보이는 것을 확인할 수 있습니다. 실험 결과를 통해 저자는 저자가 제안하는 SIM-CoT가 저자가 의도한 대로 효과적이었음을 주장하고 있습니다.
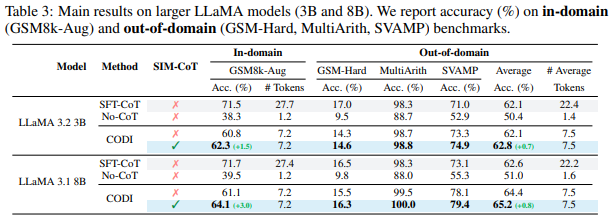
Table 3는 in-domain과 out-of-domain 상황에서의 성능입니다. 저자가 Introduction에서 설명한 것과 같이 SIM-CoT는 일반화 능력에 효과적이기 때문에 In-domain과 out-of-domain 상황 모두에서 성능 개성되는 것을 확인할 수 있습니다. Table 1,2,3 모두에서 SIM-CoT를 적용한다고해서 Average Token이 늘어나는 것이 아니기 때문에 효율적인 측면에서도 강점이 있음을 저자는 실험을 통해 보이고 있습니다.
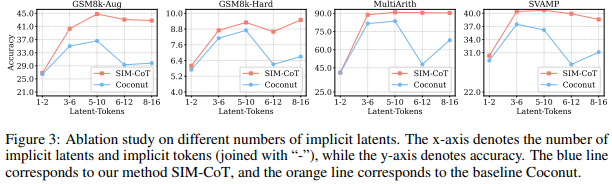
Figure 3는 Ablation Study입니다. 4개의 데이터셋에서 저자가 SIM-CoT를 적용하게 되면 latent token의 개수를 늘렸음에도 기존의 방법론은 implicit instability 문제가 존재하지만, SIM-CoT는 이를 해결하고 latent token의 개수가 늘어남에도 불구하고 성능이 잘 유지되는 것을 확인할 수 있습니다. 저자는 이를 통해 저자가 처음에 문제 삼았던 implicit instability 문제를 SIM-CoT를 통해서 해결했음을 강종하고 있습니다.
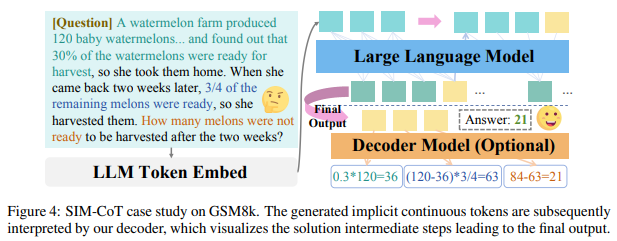
Figure 4는 정성적인 결과입니다. 저자가 생성하는 implicit continuous token들이 디코더에 의해 중간 풀이 단계를 서술하는 것을 확인할 수 있으며 이를 통해 최종 출력까지 이어지는 LLM의 논리의 흐름을 확인할 수 있습니다. 이 정성적 결과를 통해서 저자가 주장하는 설명 가능성을 보이고 있습니다. 리뷰에는 다루지 않았지만, 서로 다른 디코더에 대한 ablation study와 설명 가능성 분석 등 디테일한 설명이 appendix에 있으니, 본 리뷰를 읽고 관심 있는 분들은 논문도 한번 읽어보는 것을 권해드립니다.
아직 연구가 학회에 게재된 것은 아니지만, huggingface daily paper에서 높은 관심을 받고 있는 논문입니다. LLM에 관심있는 연구원분들에게 좋은 인사이트가 되었으면 합니다.
감사합니다.
안녕하세요 성준님 재미있는 논문 리뷰 감사합니다.
Figure1 (a)관련하여 질문이 하나 있는데, 그림에 범례가 없는것같아서 혹시 그래프의 색이 토큰의 갯수를 의미하나요..?
연보라색 그래프가 가장 토큰이 많은 경우같은데 해당 그래프만 긴 epoch를 학습한것으로 이해했습니다..
혹시 제가 이해한 방향이 맞는지 여쭤봅니다..
감사합니다
안녕하세요. 황유진 연구원님 좋은 댓글 감사합니다.
네 맞습니다. latent 1~5는 latent token의 수를 나타내는 것이며 latent token을 5개 사용한 연보라색의 경우 학습 epoch이 늘어남에 따라 학습이 수렴하지 않고 불안정해지는 것을 확인할 수 있습니다. 저자는 이를 implicit instability로 정의하고 있습니다. 표에서는 잘 보이지 않지만, latent token이 적은 경우에는 성능이 잘 수렴한다고 합니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
본문에서는 latent representation이 하나의 text token보다 더 많은 정보를 담고 있어 효율적인 CoT가 가능하다고 설명하셨습니다. 그런데 explicit CoT는 하나의 토큰으로 표현되기 때문에 다양성은 부족할 수 있지만, 그만큼 정확도가 더 높을 것이라고 생각됩니다. 그렇다면 latent token의 수를 늘려 더 다양한 정보를 활용하여 추론을 진행한다면 explicit CoT보다 더 좋은 성능을 낼 수 있는 것인지, 아니면 여전히 explicit CoT가 성능의 upper bound를 형성하는 것인지 궁금합니다.
감사합니다.
안녕하세요. 정의철 연구원님 좋은 댓글 감사합니다.
의철님이 언급해주신 것처럼 아직 implicit CoT가 explicit CoT에 비해 성능이 낮은 것은 사실입니다. 하지만, 리뷰에서 언급한 것처럼 explicit CoT에는 몇몇 한계가 존재하기 때문에 implicit CoT를 사용하여 성능을 explicit CoT의 수준까지 향상시키는 것이 현 implicit CoT 연구의 목표라고 볼 수 있습니다. 하지만, explicit CoT의 성능을 implicit CoT의 upper라고 보는 것은 아닙니다. implicit CoT는 explicit CoT의 명백한 단점을 보완한 방법론이기 때문입니다. 기본적으로 중간 단계를 유연하게 latent token을 통해 표현하기에 일반화 성능이 높고 더 효율적입니다. 이미 in-domain, out-of-domain에서는 explicit CoT과 비슷한 혹은 더 좋은 성능을 내고 있으며 아직 연구가 진행되고 있기에 더 발전할 가능성이 높다고 볼 수 있습니다. 결과적으로 implicit CoT는 아직 explicit CoT보단 성능이 낮지만, 더 효율적이고 explicit CoT의 단점을 보완한 방법이기에 성능이 더 좋아질 여지가 많이 남아있다고 보면 될 것 같습니다.
감사합니다.
안녕하세요 성준님, 흥미로운 리뷰 감사합니다!
1. 학습 때 보조 decoder를 붙여서 latent vector를 text로 사영을 잘 시키는 방향으로 학습되길 기대하고 추론 땐 이 디코더를 떼던데, 제가 잘 몰라서,, 혹시 이렇게 뒷단의 auxiliary 디코더를 뗐다 붙였다하는 학습법이 보통 LLM 앞단의 latent space 까지 representation을 잘 align시켜주는 결과를 가져온다는 건 저자들의 논문에서 처음 밝힌 게 아니라 원래 대중화된 컨셉인가요?
2. figure 1의 (c)에서 노란색 공간은 무엇을 뜻하는 지 궁금합니다!
3. trajectory-level supervision 과 step-level supervision 간의 정확한 차이가 무엇인가요? trajectory-level supervision이란 게 distill loss를 의미하나요?
4. U가 hidden state sequence고, z_k가 last hidden state이자 latent vector고, 이 z들을 latent CoT로써 사용하는 것으로 이해했습니다. 여기서 latent level의 z_1:k를 text level의 s_1:k로 decoder 써서 생성하는 과정에서 step-level supervision loss를 구성한 것으로 이해했습니다. 특히 step-level supervision에서 Negative Log-Likelihood의 의미가 그 z -> s 를 얼마나 잘 만들어내는지에 대한 확률이라고 해주셨는데, 해당 부분에 있는 p_phi 식에서부터 잘 이해를 못해서,,, 설명 한번만 더 해주시면 감사하겠습니다.
5. 저희 로보틱스 팀에서도 추후 VLA의 action latent space 에서 implicit CoT 를 활용한 학습을 고려할 때 써먹음직한 방법론인 것 같은데, VLA 쪽 도메인에서는 추론 속도도 관건이다보니까 생각이 들어서, 혹시 추론 속도와 관련된 실험은 없었나요?
박성준 연구원님. 좋은 리뷰 감사합니다.
결국 질문으로 입력하는 프롬프트를 learnable vector로 놓고, supervision을 사용해 latent space에서 이를 학습한 것으로 이해했습니다.
질문이 있는데, Figure 2를 보면 vector 형태의 prompt를 입력으로 LLM에 주면 autoregressive한 형태로 hidden state 출력하고 이를 다시 입력하고.. 이걸 K 단계 반복하는 것으로 보입니다. 여기서 autoregressive하게 순차적으로 출력하는것이 출력 단어들의 토큰이 순차적으로 출력되는거라고 보면 될까요? 아니면 맨 마지막 Answer(분홍색 부분)만 최종 출력물이라고 보면 되나요?