안녕하세요 황찬미입니다 !
두번째 x-review로 transformer를 ODtask로 사용한 DETR에 대해서 리뷰하겠습니다!

1. Intro
Faster R-cnn과 같은 전통적인 OD모델은 앵커박스나 region proposal같은 엄청나게 많은 후보박스를 만들고 그 후보에 대하여 NMS를 처리하는 등의 휴리스틱한 방식으로 객체탐지를 진행해왔습니다.
즉 모델이 내어놓은 결과를 이후에 사람이 만든 규칙으로 정리하는 흐름 입니다. 이러한 방식은 모델이 발전하면서도 계속 사용된 단계이니만큼 성능이 나름 검증되고 중요한 과정이지만 사람이 직접 설정하는 단계이기 때문에 해당 설정에 대해 성능이 좌우될 수 있다고 합니다.
what is DETR?
저자들이 논문을 통해 제안하는 DETR은 앞서 말한 휴리스틱의 단계를 없애고 direct set-based prediction으로 바꿉니다. 한 이미지에 대하여 고정된 길이(N)의 예측 슬롯을 한번에 출력하고 각 예측 슬롯은 객체 1개 또는 배경(no object)을 출력하도록 학습됩니다.
또한 이미지에서 탐지된 객체들은 원래 순서라는 개념이 없는 박스들의 모음이기 때문에 학습도 순서에 영향을 받지않게(순열불변) 설계해야 합니다.
이를 위해 DETR의 핵심인 헝가리안 이분매칭(bipartite matching)과 집합기반 손실(set-based loss)을 사용합니다. 모델의 N개의 예측과 M개의 GT박스간의 cls loss + loc loss(L1+GIoU)로 만든 cost를 기준으로 1:1의 최적의 매칭을 찾습니다. 최적의 매칭이 정해지고 나면 매칭된 쌍들에 대한 손실을 전부 합쳐서 한번에 학습됩니다. 이를 통해 NMS나 앵커박스 같은 휴리스틱한 밥법 없이 end-to-end로 최종 박스 set을 직접 맞추게 됩니다. 다시 말하자면!
- 중복제거를 뒤에서(like NMS) 하지말고
- 앞에서(학습때) 아예 중복을 내지 않게 만들어버린다! 라는 개념입니다
저자들은 이렇게 하면 하나의 GT박스에 여러 예측 박스가 만들어지는 near-duplicates(유사중복)문제가 자연스럽게 사라져서 모델이 중복없이 결과를 내도록 학습된다고 합니다.
why use Transformer?
DETR은 트랜스포머 구조를 사용합니다. 다음에서 자세히 다루겠지만 흐름을 간단하게 먼저 요약하자면
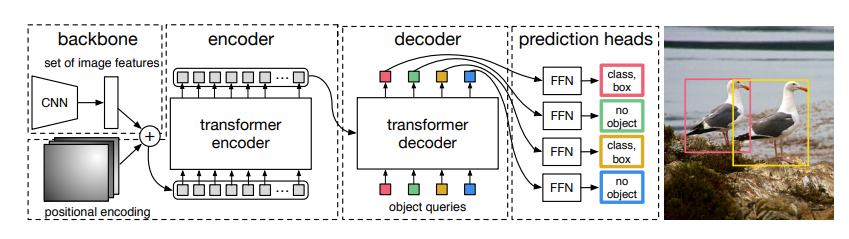
1.CNN을 백본으로 하여 이미지에서 피처맵을 뽑고
2.피처맵을 트랜스포머 인코더의 입력으로 넣어주어 self-attention을 통해서 피처맵의 전역정보를 섞어줍니다.
3.다음으로 트랜스포머의 디코더에 넣어주어 learnable한 오브젝트 쿼리들을 입력으로 받아 각 쿼리마다
4.FFN을 통해 예측set(cls,bbox)을 병렬로 출력합니다.
여기서 중요한 부분은 디코더 내부의 쿼리간의 셀프어텐션과 인코더출력&디코더간의 크로스어텐션 입니다. 먼저 쿼리&쿼리간의 self attention은 각 쿼리들끼리 쉽게말해 서로가 같은 객체를 예측하지 않도록 중복을 조절합니다. 인코더의 출력과 쿼리간의 cross attention은 전역정보가 담긴 인코더의 출력에서 각 쿼리가 필요한 정보들에만 집중을 하게 됩니다. 결과적으로는 이러한 트랜스포머의 어텐션과정으로 처음부터 각 예측 슬롯이 겹치지 않는 예측 슬롯 set을 출력하는게 가능해집니다. 각 단계별 세부적인 내용은 섹션2에서 더 자세히 다루도록 하겠습니다.
2. DETR architecture
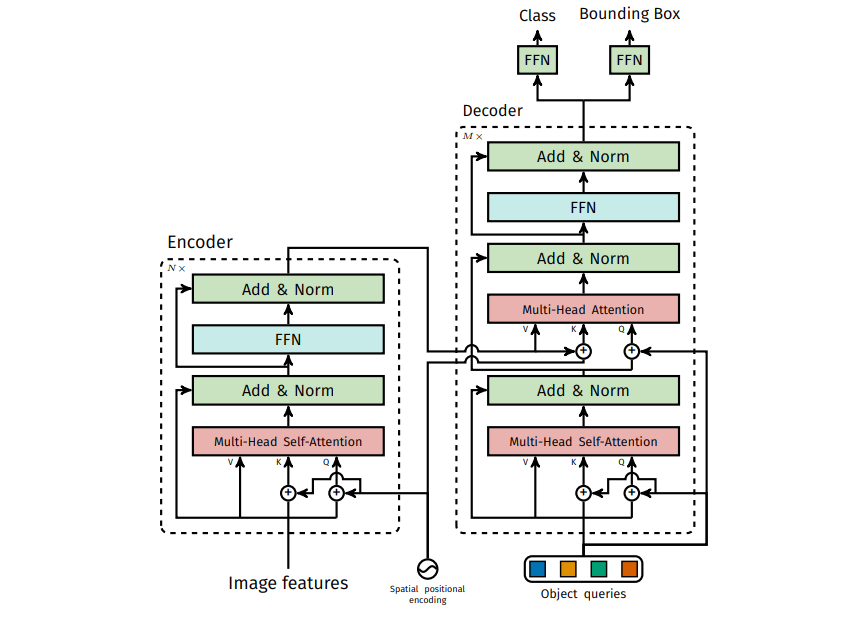
1) Backbone
입력 이미지를 일반적인 CNN백본(eg.resnet50)을 통해 낮은 해상도의 단일 피처맵을 생성합니다
- 입력 img X(H0,W0,3) -> 출력 피처맵 f(H=H0/32, W=W0/32, 2048)
2) TF Encoder
인코더에서는 피처맵에 대해 self-attention으로 전역적인 문맥정보를 취합합니다.
- 2048의 채널을 가지는 피처맵을 d=256으로 채널을 축소하여 새로운 특징맵Z_0을 만들고
- 트랜스포머의 인코더는 토큰 시퀀스를 입력으로 기대하기 때문에 Z_0을 평탄화를 진행하여 길이가 (HW)인토큰 시퀀스(HW X d)로 변환합니다
- 트랜스포머는 순열 불변한 특징을 가지기 때문에 입력될때 K,Q에 위치정보를 함께 임베딩해준다.
- 인코더는 6개의 transformer 블록(기본TF모델과 같음)으로 이루어져있으며 Multi-head self-attention으로 전역적인 문맥정보를 취합합니다. 이후 FFN으로 취합된 정보를 보정하여 디코더의 Cross-attention으로 보내집니다.
3) TF decoder
디코더에서는 learnable한 오브젝트쿼리 N개를 입력으로 받아 디코더 layer를 거칠수록 1슬롯-1객체로 수렴하게 됩니다. 흐름을 다시 살펴보자면
- 먼저 학습 가능한 obj 쿼리 N개를 디코더의 입력으로 넣어줍니다. 이때 N은 최대 예측슬롯 수 입니다. (기본N=100)
- 각 디코더 층에 입력될때 쿼리 간의 역할분담을 위해 learned query positional embedding을 쿼리에 더해줍니다.
- 디코더도 기본 TF모델과 같이 6층으로 구성되어 있으며 디코딩의 각 단계에서 모든 N개의 쿼리가 각 층에서 병렬로 갱신됩니다. 각 블록 내부를 자세히 보자면
(1) 인풋 쿼리간의 Multi-Head Self-Attention으로 쿼리들끼리 상호작용하여 중복없는 표현을 위한 역할분담이 생기게 됩니다.
(2) 쿼리와 인코더를 통한 전역문맥(K,V)간의 Multi-Head Cross-Attention으로 인코더 메모리에서 각 쿼리가 필요한 부분만을 끌어옵니다.
(2) 이후 FFN을 통과하여 쿼리별로 비선형 변환을 통해 표현을 정제해줍니다.
4) FFN for prediction
디코더의 출력 쿼리는 동일한 파라미터를 공유하는 예측 FFN을 통해 각 쿼리마다 클래스 logit과 박스의 좌표를 출력합니다.
- cls head: 선형층 -> softmax를 통해 클래스 개수k+배경1의 로짓(점수)를 출력합니다.
- Box head : 3개 층으로 이루어진 MLP에 넣어 이미지 크기로 정규화 된 x,y,h,w를 예측합니다.
5) Loss
디코더를 한번 통과하면 N개의 예측을 가진 집합을 산출하게 됩니다. 이때 예측과 정답 박스간 1:1매칭을 통해 중복없이 직접 학습하게 되어 별도의 NMS없이 end-to-end 학습을 가능하게 합니다.
- 먼저 1. 헝가리안 매칭 단계에서 해당 디코더의 예측 집합에 대해 총 비용이 최소가 되도록 하는 최적의 순열(시그마헷)을 찾습니다. 아래의 수식이 최적의 매칭(시그마헷)을 찾는 식인데
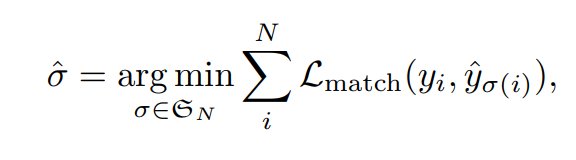
- 여기서의 L_match는 각 예측$$\hat{y}j$$ – 정답$$y_i$$ 쌍의 매칭비용(분류+박스)이고 이때 box loss는 L1+GIoU로 구성되어 있습니다.
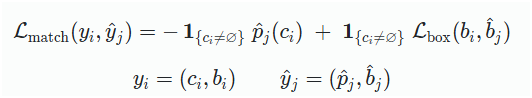
- 위의 매칭으로 얻은 최적 순열에 대해 매칭된 예측–정답 쌍만을 사용해 학습손실인 2. 헝가리안 매칭 비용 을 계산합니다. (아래의 수식)
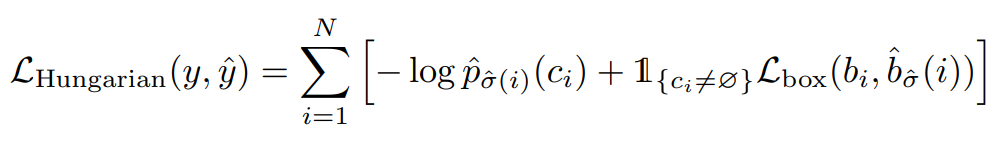
- 시그마 안의 로그항(앞항)은 매칭된 예측 슬롯이 정답 클래스ci에 높은 확률을 주도록 강제하는 cls loss(CE)입니다. 정답이 배경(no obj)인 경우에도 해당 슬롯이 배경을 정확히 예측하도록 학습됩니다.
뒷 항은 실제 객체일때만 box loss를 적용합니다. (배경에는 박스항을 적용하지 x)
참고1) 헝가리안 매칭 알고리즘 : https://gazelle-and-cs.tistory.com/29
참고2) GIoU : https://gaussian37.github.io/vision-detection-giou/
3. Experiment
1) vs Faster R-cnn
- 아래의 정량평가 결과로 DETR이 faster r-cnn과 견줄만한 성과를 달성함을 확인할수 있습니다.
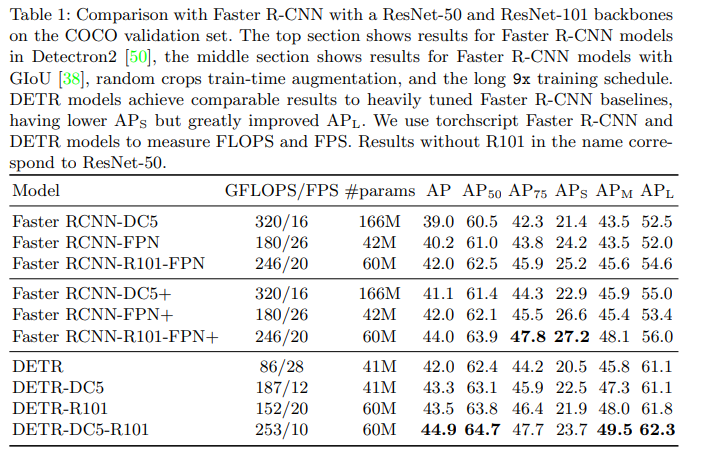
- 표를 살펴보기에 앞서 용어를 먼저 정리하자면 다음과 같습니다
-> DC5 : resnet의 마지막 레이어에서 stride대신 dilation을 사용한 버전
-> + : faster rcnn의 설정을 강화해준 버전(GIoU + 랜덤 크롭 + 9×(109ep))
-> R101 : 백본을 ResNet-101로 사용(기본은 ResNet-50) - 상단은 기본 레즈넷을 백본으로한 성능이고, 중단은 기본 레즈넷을 좀더 강화(GIoU 추가 + 랜덤 크롭 증강 + 9×(109ep) 긴 스케줄)한 성능이다. 하단은 DETR계열의 성능입니다.
- 중단 vs 하단 : 거의 DETR계열의 성능이 좋거나 거의 비슷하지만 작은 객체에서는 도드라지게 faster rcnn계열의 성능이 더 좋습니다.
-> 그 이유를 생각해보면 DETR은 최종 피처맵 하나만을 사용해서 트랜스포머 계산에 들어가기 때문에 작은객체가 뭉개지거나 bbox의 정밀도가 떨어질수 있습니다
2) Ablation
1. Encoder layers
아래의 표는 인코더 layer수를 바꿔가며 전역 이미지 수준의 self attention의 중요성을 평가했습니다.
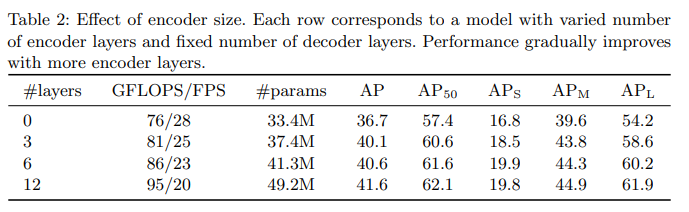
위의 결과로 인코더 층이 없으면 전체 AP가 대략 4포인트 정도가 하락하고 특히 큰 객체는 6포인트나 하락했는데 큰 물체는 각 픽셀들에 해당 객체에 대한 정보가 곳곳에 있기 때문에 self attention을 통한 보정의 효과가 크다고 볼수 있습니다.
-> 이것으로 저자들은 인코더의 self attention을 통한 전역적인 추론이 객체를 분리하는 것에 중요한 역할을 한다고 가설을 세웠고 아래의 시각화로 그 결과를 확인해보았습니다.

실제로 인코더의 마지막 레이어의 self attention의 가중치 분포를 4개의 참조점을 기준으로 시각화를 해보니 위의 그림처럼 각 참조점의 히트맵이 해당 객체를 서술하고 있음을 확인할수 있습니다. 이로써 인코더 단계에서 이미 객체가 분리되고 있음을 보여줍니다.
2. Decoder layers
디코더는 매 층마다 출력 뒤에 aux loss를 바로 걸어줌으로 해당 층에서 나온 예측이 GT와 어떻게 1:1로 매칭이 되는지 다이렉트로 피드백을 받습니다. 이 보조손실로 학습 초반부터 신호가 깊게 전달이 가능해지고 하나의 슬롯이 하나의 객체를 더 잘 전담할수 있도록 수렴을 돕습니다.
각 디코더 레이어에서는 초깃값인 obj쿼리들이 인코더의 출력과 함께 cross attention으로 이미지의 전역정보를 확인하고 self attention으로 쿼리들이 역할을 분배하는 과정을 거치게 됩니다. 이 과정을 통해 층이 깊어질수록 중복이 줄어들고 객체에 대한 경계나 클래스가 선명해집니다.
이와 같은 과정의 누적된 효과는 NMS의 필요성 감소와 연관됩니다 (아래의 표 참조)
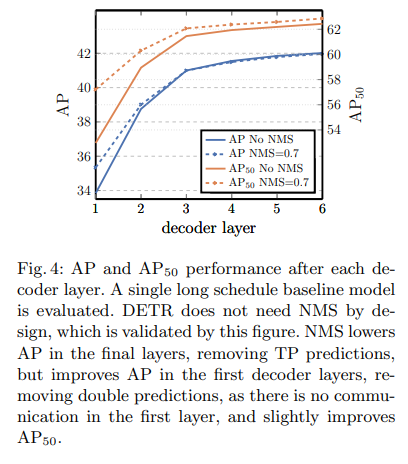
초기의 1~2층에서는 쿼리간의 분담이 아직 충분히 학습되지 않았기 떄문에 중복된 예측이 남아있어서 NMS가 도움이 될수 있지만 layer가 진행 될수록 self attention과 aux loss가 결합하여 중복억제를 직접학습하게 됩니다. 이러한 결과로 NMS를 통한 이득이 급격하게 줄어들어 최종 layer의 예측은 별도의 NMS없이도 중복이 거의 발생하지 않는 것을 확인할 수있습니다
디코더의 최종 출력을 서로 다른 색으로 시각화 한 결과를 아래의 그림으로 보면 디코더의 어텐션은 객체의 머리나 다리같은 꽤나 국소적인 부분을 서술하는 것을 알수있습니다

-> 이로인해 저자들은 인코더 어텐션으로 객체를 분리하고 그 정보를 디코더로 전달하면 디코더에서는 객체의 경계나 클래스를 추출한다고 말합니다.
3. positional encoding
- 포지셔널 인코딩은 두 종류로 구분되어 있습니다
- spatial positional 인코딩
인코더,디코더가 다루는 각 토큰이 어느 공간 위치에 있는지를 알려주는 벡터로, 트랜스포머 어텐션은 순열 불변이기 때문에 이 신호가 없으면 피처들을 단순 집합으로만 보고 공간적인 질서를 잃어버리게 됩니다. - output positional 인코딩(= 오브젝트 쿼리, 필수)
디코더 매층의 입력에서 이전 층의 출력을 obj쿼리 임베딩과 다시 더해서 새로원 쿼리를 만들고 그 상태로 self attentnion-> cross attention을 진행합니다. 이때 출력 pos는 학습형으로 사용되고 없으면 집합예측 슬롯 자체가 형성되지 않기 떄문에 학습이 불가능합니다.
쉽게 말하자면 오브젝트 쿼리는 N개의 검출 set을 만들 때 각 슬롯의 정체성(?)이라고 이해하면 됩니다.
- at input vs at attention
- at input : 기존의 트랜스포머 방식처럼 입력 임베딩에 한번만 더해주기
- at attention : 매 어텐션레이어의 입력(Q,K)에 계속 더해주기 (레이어마다 포지셔널 신호를 주입해줌)
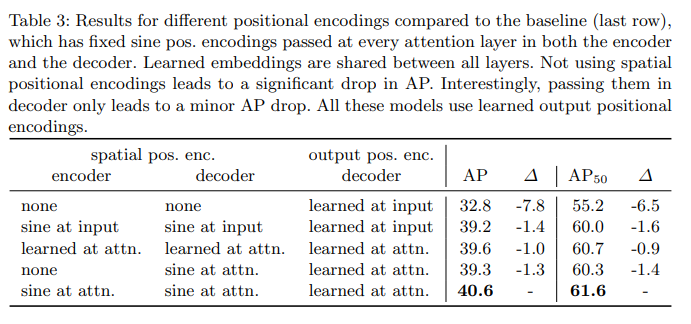
- 위의 표를 보면 가장 성능이 좋은 설정은 모든 인코더,디코더의 attention에 들어가기 직전에 spatial pos를 더해주고 매 층의 디코더의 입력 쿼리에는 output pos를 더해주는 방식입니다. spatial pos는 학습형이든 사인형이든 성능이 막 크게 차이나지는 않지만 더해주는 위치인 at input, at attention에서 크게 차이가 나는것을 확인할 수 있습니다.
4. Loss function
모델 아키텍쳐에서 언급했듯이 Loss는 3개지로 구성됩니다.
- clssification loss
- L1 loss → bbox distance
- GIoU loss
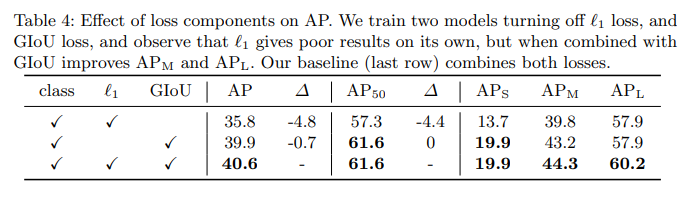
- 위의 결과는 cls loss는 필수이기 때문에 Giou와 L1 loss로만 ablation을 진행한 결과입니다.
-> L1 o , GIou x : -4.8포인트의 큰 성능저하가 있었고 특히 AP50에서 -4.4포인트로 박스 자체의 질이 떨어진다는 것을 확인할 수 있습니다.
-> L1 x , GIou o : -0.7의 작은 성능저하가 확인됩니다. - 이유를 추측해보자면 두 로스 다 Bbox와 관련이 있지만 GIoU는 박스간의 겹침 자체를 다루는 loss이고 L1은 박스 좌표의 오차를 줄임으로 정밀도를 보정하는데 도움이 되는 loss로 겹침 자체를 다루는게 아니라서 단독으로는 부족하지 않을까.. 그래서 결합하면 특히 큰물체에서 박스보정효과가 더 나타나는것이 아닐까? 하고 생각해보았습니다
4. analysis
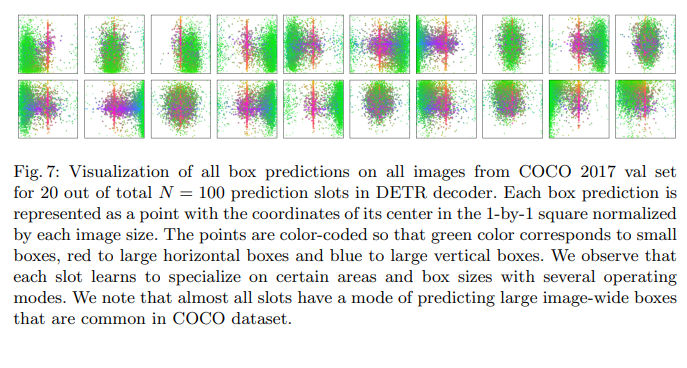
Fig7은 디코더의 100개의 출력 쿼리슬롯 중 20개만 시각화 한것으로 각 쿼리슬롯은 역할이 조금씩 다르게 전문화된 특성을 가지게 됩니다
위 그림만 살펴 보더라도 초록색은 작은박스, 빨간색은 큰가로박스, 파란색은 세로박스를 의미하는 정보인데 해당 정보들이 각 슬롯에 조금씩 다 다르게 반영된 것을 확인할 수 있습니다
여기서 주의할 점은 각 슬롯이 클래스를 나누어 전담하는것이 아니라 객체의 크기와 공간에 대한 정보를 나누어 가지게 되는것으로 각각이 다른 영역과 크기에 뭔가가 있을것이라고 분담하여 예측 정보를 전담하는 것입니다.
이렇게 분담된 정보가 이후 최종 FFN을 통과하여 어떤 클래스인지가 결정됩니다.
5. conclusion
DETR은 휴리스틱한 파이프라인 없이 direct set-based 예측과 헝가리안 알고리즘 기반 이분매칭으로 구성된 간단한 트랜스포머 검출기로 COCO 데이터셋에서 Faster R-CNN과 비슷하거나 더 좋은 성능을 보였습니다
세미나나 이것저것 자료들을 보면 DETR을 기반으로한 어쩌고~ 하는 내용들이 많은데 od task에 있어서 앵커박스나 NMS같은 중요한 구조를 없애는 과감한 전환이 또 새로운 판도(?)가 될수 있구나하고 감탄하면서 이 논문을 보게 되었습니다
2020년도에 등장한 모델인 만큼 지금 시점에서는 작은객체 검출과 같은 논문에 등장한 문제들을 꽤나 해결했을것 같은데 후속문제들을 어떻게 해결했을지 이어서 공부하게될 od의 성장기가 은근히 기대가 됩니다
안녕하세요 찬미님! 좋은 리뷰 감사합니다.
object detection 관련된 논문을 읽고 작성해주신 논문을 읽으니 흥미로운 것 같습니다.
특히 NMS와 Anchor box 부분을 생략하고 최종 박스 set을 맞추는 부분이 흥미로웠던 것 같습니다!
아직 제가 transformer에 대해서 공부가 부족해서 정확히는 모르지만 읽으면서 궁금했던 점이 몇가지 있어서 댓글 남깁니다!
1. experiment 부분에서 성능은 좋지만 FPS가 매우 낮은 모습을 보고 의문이 생겼습니다. region proposal단계와 NMS를 생략 했음에도 불구하고 FPS가 낮은 이유를 one-stage detection 방식이 아니어서라고 이해해도 될까요? 아니면 다른 이유가 있을까요?
2. 왜 디코더의 최종 출력이 object의 극소적인 부분을 서술하는지 궁금합니다!
3. 쿼리의 수를 N=100으로 설정한 것 같은데, 이렇게 한 이유가 있을까요? 제가 생각하기에는 뭔가 N이 달라질 수록 모델의 성능에 영향을 줄 것 같은데.. (object 예측 슬롯이어서) 이러한 부분은 논문에서 언급되지는 않았나요?
리뷰 감사합니다.
좋은 리뷰 감사합니다. 몇가지 질문 남기도록 할게요.
1. 결국 loss 를 통학 학습이 진행되기 전에 최적의 매칭을 찾아야 하는데, GT값과 예측값이 잘못 매칭되는 등의 문제는 없을까요? 학습 단계에서 이로 인한 수렴성이 떨어지지는 않는지 궁금합니다.
2. 중간에 쿼리 간 self-attention이 중복을 조절한다고 서술해주셨는데, self-attention 과정에서 왜 중복을 억제하는 효과가 생기는지 더 자세히 설명해주시면 감사하겠습니다. 단순히 서로 상호작용을 하다보니 중복을 억제한다고 받아들이기에는 논리가 나이브한것같고, 더 자세한 설명이 필요할 듯 합니다.
3. aux loss가 구체적으로 어떻게 설계되고 작동하는지 더 자세한 설명이 가능할까요?
감사합니다.