안녕하세요 이번주도 저번 주에 이어서 토큰 프루닝 관련 논문을 들고 왔습니다. 아마 이번주를 마지막으로 다음 주 부터는 토큰 프루닝 관련 논문보다는 다른 분야의 논문을 찾아서 리뷰할 것 같습니다.
먼저 해당 논문은 2024년에 구글 딥마인드에서 발표한 Token Cropr Faster ViTs for Quite a Few Taskscopr 이라는 논문입니다. 일단 해당 논문은 지금까지 제가 리뷰했던SViT,ToSA,HiRED,Dynamic ViT에서 그나마 SViT와 ToSA라는 친구와 결이 비슷한 논문이라고 볼 수 있겠습니다. 해당 논문은 기존 classification에서의 프루닝과 달리 dense 한 태스크에서 최대한의 정보보존을 목적으로 image classification 뿐만 아니라 segmentation과 같이 픽셀단위로 무언가를 하는 태스크에도 이러한 방식의 토큰 프루닝 방식이 효율적이고 유용할 수 있다 라는 것을 보여주는 논문이라고 생각하시면 좋을 것 같습니다.
바로 리뷰 들어가도록 하겠습니다.
Introduction
먼저 모든 프루닝 방식을 제안 하는 방법론은 서두에 던지는 질문은 항상 동일한 것 같습니다. 어떻게 하면 빠르면서도 성능 손실은 최소화하고 분류뿐 아니라 segmentaion이나 object detection과 같은 다양한 비전 태스에도 적용할 수 있는 토큰 프루닝 기법을 만들 수 있을까? 라는 질문인데
먼저 빠르면서도 성능 손실은 최소화하는 측면에서는 ViT의 핵심은 셀프 어텐션의 토큰의 제곱의 비례로 증가하는 연산량의 한계를 언급합니다. 결국 여기서 발생하는 문제는 ViT는 풍부한 피쳐 표현을 뽑아 낼 수 있기 때문에 고해상도 이미지를 처리해서 더 세밀하고 풍부하고 많은 정보를 뽑아내고 싶어하는 요구가 점점 커진 다는 것입니다. 결국 고해상도를 처리하면 그만큼 연산량이 폭증하기 땜누에 이를 해결하기 위해서 불필요한 배경 토큰들을 일찍 제거함으로써 좀더 주의해서 봐야하는 대상 물체에 대해 토큰을 집중해서 연산한다면 ViT의 연산량 문제를 개선할 수 있다는 것이 프루닝 방식의 시작점이게 됩니다.
그럼 자연스럽게 어떻게 태스크와 무관한 토큰을 정확하고 효율적으로 골라낼 수 있을까?에 대한 질문이 생기게됩니다. 기존 연구들은 휴리스틱 기반의 어떤 토큰들의 통계와 같은 간접적인 지표를 활용해서 토큰을 골라내는 방식, 혹은 adaptive하게 토큰을 골라내서 pruning 하고 merging하는 여러가지 방식이 있었는데 대부분의 이러한 방식들은 이미지 분류에만 초점을 두었기 때문에 토큰들의 정보 손실 발생 측면에서 세그멘테이션처럼 픽셀 단위 예측이 필요한 dense task에는 사실상 적용이 불가능했습니다.
그래서 저자들은 빠르면서도 성능 손실 최소화는기본이고 다른 비전 태스크에 확장까지 어떻게 할 수 있을 지에 대해 고민을 하면서 Cropr 이라는 방법론을 제안합니다.
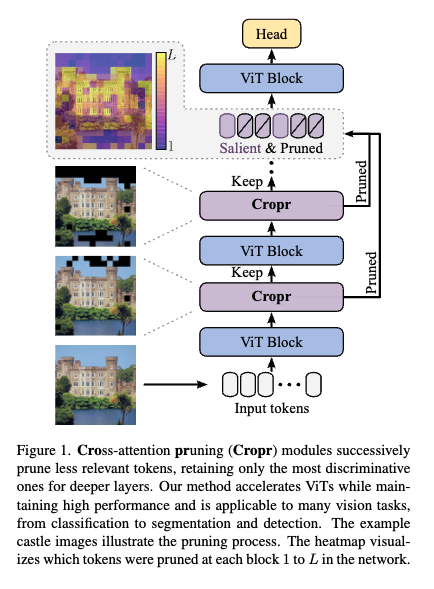
이후 메서드 파트에서 자세하게 설명드릴 예정이지만 여기서 간단하게 Cropr의 아이디어를 설명드리자면, 위 그림이 전부라고 보시면 될 것 같습니다. 핵심은 Cropr인데 이 부분에 대해서 설명을 드리면
먼저 Auxiliary Head라는 ViT 블록 중간마다 적용되는 작은 예측 헤드가 있는데 이 헤드는 이 토큰이 태스크에 얼만큼 기여도를 갖는지를 직접 학습하는 보조 헤드라고 보시면 됩니다. 그리고 이 보조 헤드들은 학습 때만 쓰이고 추론시에는 모두 제거하게 되면서 추론시 속도 측면에서는 오버헤드가 따로 발생하지 않습니다. 단순히 어떤 토큰이 중요한지를 선택하는 게이팅 모듈(selective module)에게 보조 신호만 주고 직접적으로 프루닝을 하지 않는 친구라고 보시면 좋을 것 같습니다. 그리고 dense한 태스크로의 확장을 위해서 정보 손실을 최소화 하기 위해서 프루닝된 토큰을 완전히 버리지 않고 마지막 블록 직전에 다시 합쳐 줍니다. 크게 위와 같은 방식으로 동작한다고 보시면 좋을 것 같습니다.
그리고 추가적으로 해당 방식이 기존 연구와는 또 다른 차별점이 있는데 기존의 Classification 태스크에서의 토큰 프루닝같은 경우에는 CLS 토큰 어텐션 점수에 의존하는 bottom-up방식의 접근이었다면 Cropr은 보조 헤드의 태스크 손실에서 신호를 받아 top-down 방식으로 토큰 중요도를 학습합니다.
바로 방법론에 대해서 설명하겠습니다.
Method
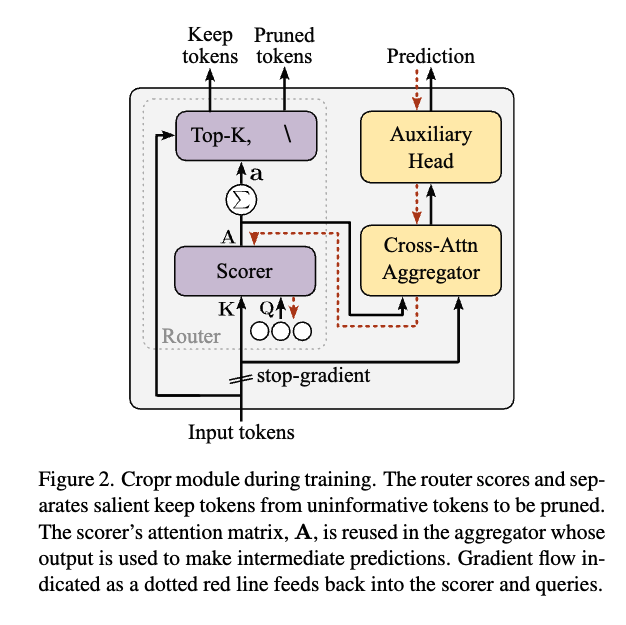
Router
먼저, Cropr 모듈은 크게 네 가지 구성 요소(Scorer, Selector, Aggregator, Task head)로 이루어져 있는데, 이 중 Router(Scorer + Selector)가 가장 핵심이 되는 모듈이라고 보시면 좋을 것 같습니다. 결국 이 Router가
Router안에서 위에 있는 친구가 Selector, 아래 있는 친구가 Scorer인데, scorer는 이름 그대로 각 토큰에 대해서 점수를 매기는 친구고 Selector는 해당 점수를 기반으로 점수가 높은 K개 토큰만 남기고 나머지는 제거하는 방식으로 동작하는 친구입니다.
각 모듈들에 대해서 구체적으로 설명을 드리자면 Scorer는 크로스 어텐션 기반으로 설계했습니다. 일반적인 크로스 어텐션 모듈은 QKV 프로젝션이나 다중 헤드, LayerNorm 같은 요소들이 들어가는데, 저자들은 이게 꼭 필요하지 않다는 걸 발견합니다. 즉, 불필요한 장식을 다 걷어내고 단순화해도 충분히 성능이 나오더라라는 것을 아래 처럼 보여줍니다.

결과적으로 더 빠르고 가벼운 Router를 설계할 수 있었던 셈입니다. 위 부분의 이유에 대해서 저자는 별다른 이유를 언급하지는 않았지만, 저도 관련해서 진행했던 실험들 중에서 selective module이 토큰들간의 관계성을 더 잘 고려할 수 있도록해서 토큰의 중요도를 더 잘 판별하도록selective module을 이것저것 바꿔보는 실험을 진행했는데 실험을 했을 때 단순한 MLP가 가성비가 제일 좋았습니다. 그래서 제 개인적으로 생각하기엔 저 라우터가 블록 사이에 삽입되기 때문에 사실 매 블록마다 이미 ViT라는 블록내에서 충분히 토큰들간의 관계성을 이미 고려하고 나와서 저 라우터에서 또 토큰들간의 관계성을 보기위해 복잡한 연산을 하는 것 대비 단순하게 설계한 어텐션 모듈을 썼을 때 비슷한 성능이 나오는 게 아닐까 싶습니다. 그래서 저는 저 scorer도 어텐션 기반이 아니라 단순 MLP로 적용했을 때에 대한 결과가 궁금하다는 생각이 듭니다. 다시 돌아와서 점수는 단순히 쿼리 축 방향으로 어텐션 행렬을 합산해서 얻습니다. 뽑아낸 어텐션 맵에서 열축으로 더한다고 보시면 됩니다. Top-K방식으로 잘린 토큰은 버려지고, 중요한 토큰만 남아 다음 블록으로 넘어가게 되는 방식으로 동작한다고 보시면 좋을 것 같습니다.
Aggregator & Auxiliary Head
다음은 Aggregator입니다. Scorer가 매긴 점수가 단순히 어텐션 스코어가 아니라 실제로 태스크에 기여하는 정도를 반영하도록 학습을 유도해야합니다. 그래서 Aggregator는 어텐션 가중치를 이용해 입력 토큰의 가중 평균을 구하고, 이를 보조 헤드(auxiliary head)로 넘깁니다.
이 보조 헤드는 중간 예측을 수행하면서 학습 신호(gradient)를 Aggregator와 Scorer로 되돌려주게 됩니다. 결국 학습 과정에서 모델은 점점 어떤 토큰이 판별력을 가지는지 배우게 되는 구조라고 보시면 좋을 것 같습니다.
그리고 중간 예측이라고 설명해서 헷갈리실 수 있을 것 같은데 보조 헤드는 최종 태스크를 흉내내는 작은 예측기라고 보시면 좋을 것 같습니다. 해당 모델이 풀고자 하는 태스크 예를 들어서 분류, 세그멘테이션, 객체 탐지에 맞춰서 중간 블록에서 토큰만 가지고도 그 태스크를 풀어보는 역할을 한다고 생각하시면 좋을 것 같습니다.
Stop-Gradient
마지막으로 stop-gradient에 대해서 설명을 드리자면 Scoring과 Aggregation 블록 앞에서 저 중간 예측에서 발생한그래디언트 흐름을 끊어버립니다. 보조 헤드에서 나오는 그래디언트가 백본 인코더까지 흘러가면 충돌이 생길 수 있기 때문에 보조 태스크와 본 태스크가 서로 간섭하면 학습이 꼬일 수 있는 문제를 stop-gradient로 차단시켰다고 보시면 됩니다. 결과적으로 Cropr는 보조 손실을 활용하면서도, 인코더는 본 태스크에는 영향을 미치지 않게 됩니다.
dense 태스크로의 확장
Cropr의 강점 중 하나는 다양한 비전 태스크에 쉽게 적응할 수 있다는 점인데 저자들은 이를 위해 유연한 쿼리 메커니즘을 사용했습니다.(Perceiver IO에서 영감을 얻었다고 합니다.) 이 방식을 사용하면 학습 가능한 쿼리 개수와 보조 헤드,손실 함수만 조정하면 바로 다른 태스크에 맞게 커스터마이징할 수 있다고 합니다.
Image Classification
분류에서는 구조가 굉장히 단순하다고 합니다. Scorer는 쿼리 하나(N=1)만 두고 마치 CLS 토큰 하나로 classification 하듯이 Aggregator는 단일 토큰만을 출력하고 이를 LN + MLP를 거쳐 최종 분류 헤드처럼 처리합니다. 결국 최종 출력은 클래스별 로짓(logits)이 되고, 학습은 소프트맥스 크로스 엔트로피 손실로 진행된다 라고 이해하시면 좋을 것 같습니다.
Cropr가 중간에 붙어도 분류 헤드 하나 더 있는 느낌이라 구현도 간단하고 직관적인 것 같습니다.
Semantic Segmentation
세그멘테이션 또한 단순합니다. 앞서 언급한 토큰 하나만 가지고 분류를 진행하는 Image Classification 과 달리 세그멘테이션은 픽셀 단위의 desne한 예측이 필요하기 때문에, 토큰을 많이 잘라내는 건 위험하다는 것을 고려를 해야합니다. 일단 메인 헤드와 보조 헤드는 Segmentation의 선형 헤드를 똑같이 그대로 씁니다. 그리고 Scorer는 토큰마다 하나의 쿼리를 두고 그냥 펼쳐진 토큰을 다시 spatial한 맵으로 바꿔줘서 처리를 합니다. 출력은 분류와 동일하게 LN + MLP를 거치지만 각 패치 위치별로 독립적으로 처리된다고 보시면 됩니다. 이후 마찬가지로 각 패치에 대해 소프트맥스 크로스 엔트로피 손실을 적용하게 됩니다. 그리고 계산 복잡도를 줄이기 위해 보조 헤드에서는 업샘플링을 하지 않습니다. 보통 Segmenter는 로짓을 입력 해상도로 올려서 학습하지만 Cropr는 라벨을 오히려 피처맵 해상도로 다운샘플링해서 씁니다. 이렇게 하면 같은 다운샘플링된 라벨을 여러 Cropr 모듈에서 재사용할 수 있어서 효율적이라고 합니다.
Last Layer Fusion (LLF)
그리고 앞서 서두에 말씀 드렸던 Cropr의 중요한 포인트 중 하나는 dense task에서도 성능을 유지한다는 점입니다. 이 부분에서 중요한 역할을 하는 친구가 Last Layer Fusion (LLF)입니다.
계속 언급했던 것처럼 시맨틱 세그멘테이션처럼 픽셀 단위 예측이 필요한 태스크에서는 토큰을 무작정 잘라내면 문제가 생깁니다. 많은 입력 정보가 사라져서 픽셀 단위 정밀도가 떨어지고 특히 업샘플링을 수행하는 세그멘테이션 헤드들은 공간 spatial feature map을 필요로 하는데, 프루닝 과정에서 이 맵 자체가 보존되지 않기 때문입니다. 어떻게 보면 프루닝과 dense task는 상극이기 때문에 지금까지 단일 dense task를 위한 토큰 프루닝 연구가 많이 없지 않았나 싶습니다.
먼저 LLF의 아이디어를 설명드리면 모든 Cropr 모듈에서 잘려나간 토큰을 완전히 버리지 않고 저장해 둡니다. 그리고 마지막 블록 직전에 이 토큰들을 원래의 공간적 위치에 맞게 다시 삽입합니다. 즉, 잘려나간 토큰은 중간 블록 계산은 건너뛰되 마지막 블록에서 복원되는 구조입니다.
SViT와 다른 점은 SViT는 매 블록마다 scatter하고 gather를 하는데(블록에만 사용하지 않고 블록 이후에 바로 합침) 반면에 Cropr은 맨 마지막 블록직전에 gather를 하고 프루닝된 토큰들과 남겨진 토큰들이 합쳐져서 하나의 시퀀스로 최종 블록에 들어가게 됩니다.
이렇게 하면 마지막 ViT 블록이 유지된 토큰과 복원된 토큰을 함께 처리하게 되고,덕분에 프루닝된 토큰들도 깊은 레이어의 문맥 정보를 참조할 수 있게 됩니다. 그리고 설명을 너무 장황하게 해서 그렇지 사실 파라미터가 존재하는 어떤 네트워크나 이런 것도 아니고 단순히 concat하는게 전부입니다.
Cropr는 학습 과정에서 보조 헤드와 크로스 어텐션 블록을 사용하기 때문에 처음에는 이거 오히려 무겁지 않나?라는 의문이 들 수 있지만 학습과 추론시 보조 헤드의 사용을 분리함으로써 추론시에는 연산 효율을 챙겨갑니다. 학습 시에는 보조 헤드와 Aggregator가 Scorer를 훈련시키는 데만 사용이되고 추론 시:에는 이 부가적인 모듈은 전부 제거되고 Router(Scorer + Top-K Selector)만 남는다고 보시면 됩니다.
Experiments
먼저 Cropr의 기본 성능을 확인하기 위해 ImageNet-1k에서 실험을 진행했습니다.
image Classification
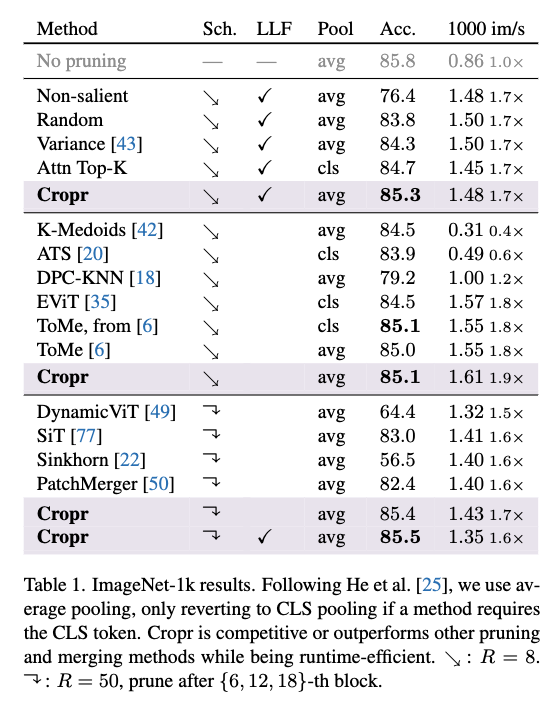
맨 위에서부터 4개가 Baseline이라고 보시면 되는 Baseline과 비교 했을 때 Cropr는 Random / Variance / Attn Top-K보다 성능이 더 좋게 나오는 것을 확인 할 수 있습니다. 그리고 Cropr를 거꾸로 뒤집은 non-salient selector(즉, 중요한 토큰을 잘라내는 방식)는 예상대로 랜덤보다도 성능이 더 나빴빴는데 저자는 Cropr의 토큰 선택이 단순히 운이 아님을 보여주기 위해서 넣은 것 같습니다.
기존 연구들와 비교 했을 때 Cropr는 LLF 없이도 기존 연구들 보다 더 좋은 성능을 보입니다. 특히 저자는 K-Medoids나 ATS는 프루닝했음에도 오히려 baseline보다 느려졌다는 점을 언급하면서 대조적으로 Cropr는 성능이랑 효율을 둘다 챙길 수 있다라는 점을 강조합니다.
결론적으로 분류에서 Cropr는 성능 손실이 0.3~0.7pt 정도에 불과하면서도 1.6~1.9배 속도 향상을 달성한 것을 보실 수 있습니다.
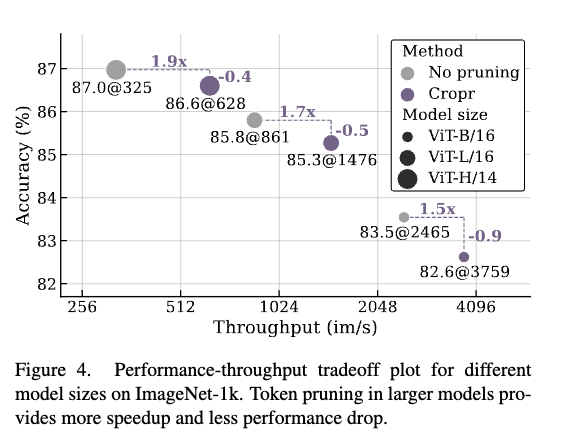
위는 Cropr가 모델이 커질수록 어떤 양상을 보이는지에 대한 결과인데 ViT-B에서는 −0.9pt 성능 손실,ViT-H에서는 −0.4pt로 줄어드는 것을 볼 수 있는데 결국 모델이 클수록 토큰을 조금 더 잘라내도 성능에 덜 민감하다는 것을 보여줍니다. 저자는 이 이유에 대해서 깊은 네트워크일수록 프루닝이 여러 레이어에 분산되기 때문이라고 합니다. 또 속도 측면에서도 ViT-B에서 1.5배 빨라졌다면 ViT-H에서는 1.9배 빨라졌는데 결과적으로 모델이 커질수록 Cropr의 효율성이 더 두드러진다라는 것을 보여주는 표라고 보시면 좋을 것 같습니다.
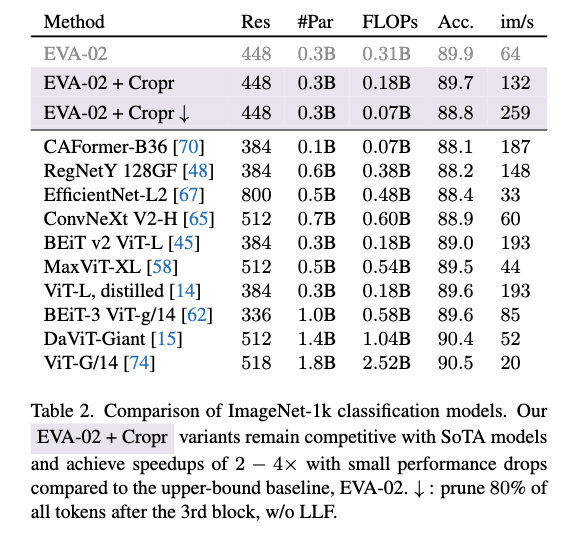
그리고 Cropr를 최신 오픈소스 대형 모델 EVA-02-L에도 적용해 검증했는데 위 표가 해당 결과를 나타내는 테이블이라고 보시면 됩니다. 먼저 일단 베이스가 프루닝 없는 상태 즉 89.9% 정확도랑 비교를 했을 때 Cropr 적용하면 89.7% 정확도를 보이는 것을 확인할 수 있습니다. 베이스 대비 0.2퍼 밖에 하락하지 않았고 FLOPs는 41% 감소하고 속도는 약 2배 이상 향상 된 것을 확인 할 수 있습니다. 그리고 아래 화살표 표시 된 거는 단순히 더 공격적으로 프루닝하고 LLF사용 안한 버전이라고 보시면 되는데 해당 실험도 정확도 1.1퍼 감소하였지만 다른 모델과 비교했을 때에는 전혀 큰 하락폭이 아니면서도 FLOPs 는76% 감소, 속도는 4배이상이나 향상했네요,,,
Sementic segmentation
앞에서는 단순 이미지 분류 태스크에 대한 실험결과를 리뷰했딴면 해당 파트에서는 서두에 저자가 해결하고자 하는 dense 한 태스크에서도 Cropr을 사용한 토큰 프루닝의 확장가능성을 segementation 실험을 통해 보여주는 부분입니다. 일단 ADE20k 데이터셋에서 EVA-02-L을 인코더로 교체해 Segmenter를 파인튜닝했다고 합니다.
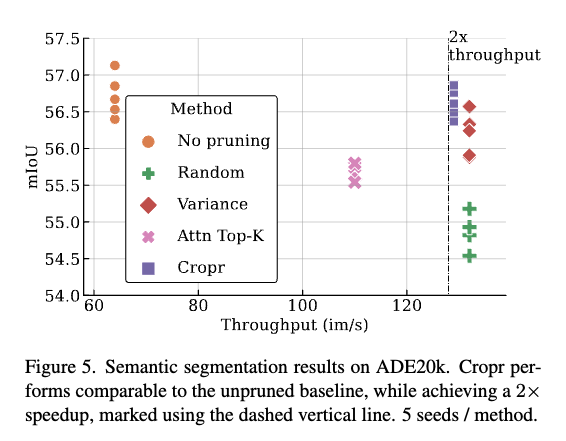
일단 Cropr는 56.6% median mIoU를 보이는데 baseline보다 단 0.1퍼 낮지만, 속도는 2배 향상되었다라는 것을 보여줍니다. dense task에서도 Cropr는 성능 손실 거의 없이 속도 개선을 했다는 것을 보여주는 실험표라고 보시면 좋을 것 같습니다.

위는 프루닝 히트맵인데 보시면 모델은 즁요한 객체에 가장 많은 어텐션을 두는 것을 확인하실 수 있습니다. 근데 일부 배경 패치도 유지되었는데 이는 전체 태스크 수행에 여전히 의미가 있는 정보였기 때문으로 보인다고 저자는 언급합니다. 이게 실내인지 실외인지 판단하는데 있어서 배경도 의미있는 정보가 될 수 있는 것 처럼 배경이 상대적으로 덜 중요하긴 하지만 아예 버려서는 안되는 정보인 것 맞는 것 같습니다. 그리고 결과를 보시면 작고 분할하기 어려운 객체들조차도 일관되게 잘 예측이 되었는데 이 부분에 대해서 저자는 LLF 덕분에 초기에 프루닝된 토큰들도 마지막 블록에서 깊은 문맥 정보를 다시 참조할 수 있었기 때문이라고 해석합니다.
다음은 COCO 실험입니다.
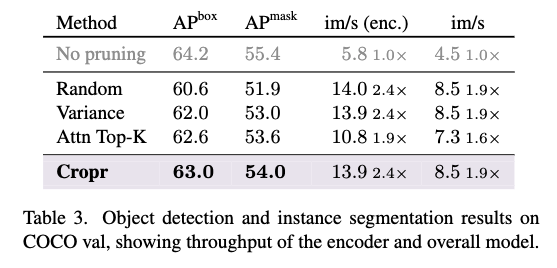
Cropr는 EVA-02-L 백본(Objects365로 파인튜닝된 체크포인트) + Cascade Mask R-CNN 헤드를 사용했습니다. 결과적으로 Cropr는 탐지/세그멘테이션 모두에서 랜덤·분산·어텐션 기반 프루닝 baseline을 넘어섰고. FLOPs는 2790 → 1273 GFlops로 줄었고, 인코더 속도는 2.4배 향상 전체 모델 속도는 1.9배 향상된 결과를 보실 수 있습니다.
마지막으로 ablation study 입니다.
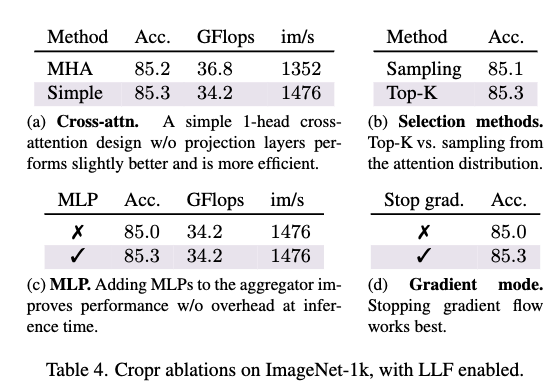
일단 (a)를 보시면 단순화된 크로스 어텐션(헤드 1개, QKV 프로젝션과 LN 제거)이 오히려 복잡한 MHA 설계(16헤드, QKV, LN 포함)보다 성능과 효율 모두 더 좋았다라는 것을 보여주고 (b)같은 경우에는 토큰 선택 방식에서도 단순한 Top-K가 샘플링 기반 선택보다 낫다는 것을 보여줍니다. (C)같은 경우는 Aggregator에 MLP + Residual을 추가하면 토큰 선택 품질이 올라가지만, 추론 시 Aggregator는 제거되므로 효율성에는 영향이 없다라는 것을 확인 할 수 있습니다. 마지막(d)는 Cropr에 stop-gradient를 적용하면 성능이 더 좋아졌다라는 것을 보여줍니다. 즉, 보조 헤드의 손실이 메인 인코더에 간섭하지 않도록 한 설계가 성능에 영향을 미친다라는 것을 알 수 있습니다.
다음은 마지막에 토큰을 합치는 부분에 대한 비교입니다.
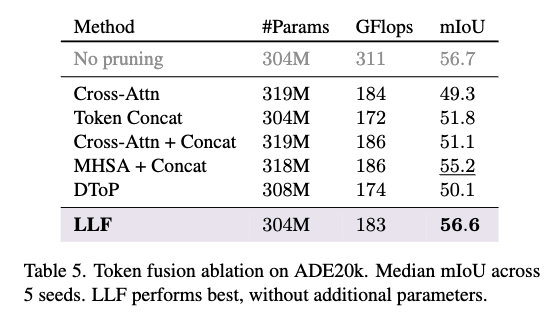
맨위의 cross-attn을 보시면 단순히 Cross-Attn만 사용해서 프루닝된 토큰을 재활성화하지 않으면 성능이 크게 떨어지는 것을 확인할 수 있습니다. 그리고 Token Concat, Cross-Attn + Concat, DToP 같은 방법은 토큰을 다시 합치긴 하지만 프루닝된 토큰과 유지된 토큰 간의 self-attention이 일어나지 않아 성능이 하락 폭이 큰편인데, 반면에 MHSA + Concat과 LLF는 self-attention을 허용하여 더 좋은 성능을 내는데, 특히 LLF는 추가 파라미터조차 없으면서도 MHSA보다 우수한 성능을 보입니다.
Conclusion
항상 프루닝 관련 논문에서 언급하듯 ViT에서 정보량이 적은 토큰을 과감하게 프루닝해도 잘 설계하면 성능을 거의 잃지 않고 오히려 추론을 2~4배 가속할 수 있다라는 점을 보여준 논문이라고 생각하는데 그래도 다른 기존 논문과의 차별점이라면 Cropr는 분류를 넘어, 시맨틱 세그멘테이션, 객체 탐지, 인스턴스 세그멘테이션 같은 dense task에도 적용 가능하다는 점에서 범용성을 입증했다는 점 같습니다. 물론 이전에 SViT도 있지만 해당 논문은 애초에 백본을 ViT Adapter를 붙혀서 저스트 dense한 태스크를 위한 연구지만 Cropr은 이미지 분류부터 dense task 아우를 수 있는 부분이 차별된 부분이라고 생각합니다. 그래서 해당 방식은 토큰 기반 접근이라는 특성상 비전 분야에 국한되지 않고 다른 모달리티에도 활용할 수 있는 가능성은 있다는 생각이 듭니다.
이만 리뷰 마치도록 하겠습니다.
안녕하세요. 리뷰 읽고 궁금한 부분이 생겨 질문드립니다.
그림2 살펴보니 selector 부분에서 Query를 learnable parameter로 지정해주는 것 같은데, 이 Query의 개수가 몇으로 설정되나요? visual token과의 내적한 다음에 Query 축으로 합 연산을 해서 score를 계산한다고 하니 이 Query는 visual token을 살리기 위한 비율은 아닌 것 같은데 Query의 개수는 몇인지 그리고 개수에 따른 ablation은 있는지 등이 궁급합니다.
그리고 내적한다음에 그냥 합 연산을 한다는 것이 또 어떠한 의미가 있는지도 궁금하네요.
감사합니다.
안녕하세요, 안우현 연구원님 좋은 리뷰 감사합니다.
추론 시에는 부가적인 모듈은 제거되기 때문에 추론속도는 빠를 것 같지만, 학습은 더 오래걸릴 것 같습니다. 프루닝 목적이 결국 추론시에 효율성을 고려하기 때문이라 생각되는데, 실험 결과에서의 속도도 추론시만 고려된 건가요?
LLF가 MHSA+concat보다 효율적이면서 동시에 더 좋은 성능을 보이고 있는데 간단하면서도 효과적인 것 같네요. ablation study에서 파라미터수 차이와 GFlops 차이를 보여주고 있긴하지만 큰 차이는 아닌것 같습니다. 혹시 im/s는 얼마나 차이나는지 논문에서 언급이 있었는지 궁금합니다.
감사합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
추론시 viT의 연산량을 줄이면서 세그멘테이션과 같은 dense task 에도 성능을 유지하는 토큰 프루닝 기법을 제안한 논문으로 이해했습니다.
뭔가 전체 성능에서 예상외로 간단한 LLF 가 성능 드랍을 가장 많이 막아준 것 같은데, 각 블록마다 해주는 것이 아닌 마지막에만 기존 정보를 돌려주는 방식이 어떻게 작용했을지 논문에 더 구체적인 설명이 있었는지 궁금합니다.
감사합니다.