안녕하세요 오늘은 여러 모달리티를 잘 엮어서 하나의 범용 표현 모델을 만든 논문을 들고왔습니다. 사실 최초 읽은 이유는 audio 모달리티에 대한 얻을 수 있는 인사이트가 없나 읽어본거긴 하지만 제 기준에서 뭔가 접목할만한 아이디어가 보이진 않았습니다. 저자가 논문 제목에도 넣었고 figure에도 포켓몬을 넣은거로 보아 일본 애니를 좋아하는 것 같습니다.. 깃허브에도 원피스처럼 로고를 넣어둔것이 인상적이네요.
그럼 리뷰 시작하겠습니다.
Abstract
저자의 해당 논문 연구는 무한히 확장 가능한 모달리티를 구축할 수 있는 확장성 있는 방식을 탐구한다고 합니다. 저자는 ONE-PEACE 라는 4B 파라미터 규모의 비전,오디오,언어 모달리티를 통합한 모델을 공개했는데 해당 모델의 아키텍처는 크게 modality adapters, shared self-attention layers, modality FFNs 로 구성됩니다.
저자는 사전학습을 위해 두가지 모달리티에 대해 사전학습 task 를 설계하였는데
- cross-modal aligning contrast – 서로 다른 모달리티의 의미 공간을 정렬
- intra-modal denoising contrast – 모달리티 내부에서 세밀한 정보를 포착하기 위함
이러한 확장 친화적인 아키텍처와 사전학습 task 덕분에 ONE-PEACE는 이론적으로 무제한의 모달리티까지 확장이 가능하다고 합니다. 또한 비전이나 언어에서 사전학습된 어떤 모델도 초기화에 사용하지 않았음에도 다양한 단일 모델 및 멀티 모달 과제에서 최고 수준의 성능을 달성했다고 어필하고 있습니다.
구체적으로 이미지분류, 시맨틱 분할, 오디오-텍스트 검색, 이미지-텍스트 검색, 오디오 분류, 오디오 질문 응답(AVQA) 그라운딩등을 평가하였습니다.
Introduction
Representation 모델들은 컴퓨터비전, 음성 처리, 자연어 처리 등 다양한 분야에서 큰 주목을 받아왔습니다. 이러한 모델들은 대규모 데이터로부터 학습되며, 다양한 다운스트림 태스크에서 강력한 일반화 능력을 보입니다. 특히 대규모 언어 모델의 폭발적인 성장은 표현 모델에 대한 수요를 더욱 증폭시켰다고 합니다. 최근까지 (저자의 논문 발표기준이니 2023 후반기) 표현 모델들은 LLM 이 다른 모달리티를 이해하여 상호작용할 수 있도록 하는 데 핵심적인 역할을 수행해왔다고 합니다.
그러나 각 모달리티가 가진 고유한 특성 때문에 기존 연구들은 주로 개별 모달리티 전용 아키텍처와 사전학습 태스크를 활용한 단일 모달 표현 모델을 구축하는 데 집중했다고 합니다. 뭐 이후에 멀티모달로 이미지-텍스트 오디오-텍스트 쌍을 효과적으로 활용하는 논문들에 대한 언급들로 인트로를 구성했습니다 다만 여전히 vision, audio, language 를 동시에 다루는 일반화된 모델 연구는 드물다고 합니다.
저자의 논문에서는 무한히 확장 가능한 표현 모델을 구축할 수 있는 확장성 있는 방식을 탐구합니다. 저자는 범용 모델이 3가지 조건을 충족해야 한다고 주장합니다.
- 다양한 모달리티를 수용할 유연한 아키텍처
- 각 모달리티 내의 정보 추출뿐만 아니라 모달리티 간 정렬을 보장
- 특정 모달리티 전용 설계 없이 여러 모달리티에 적용 가능해야함
이러한 동기에서 ONE-PEACE 라는 모델을 제안합니다. ( 하나의 모델로 평화롭게 통합했다는 의미인 것 같습니다.)
저자의 아키텍처를 pretrain 하기 위해서 두가지 modality-agnostic한 사전학습 설계를 만들었습니다.
- Cross-modal contrastive learning 비전-언어, 오디오-언어 쌍을 학습하고 모달리티 간 의미 공간을 효과적으로 정렬
- Intra-modal denoising contrastive learning masked prediction + contrastive learning의 결합으로 모달리티 내부의 세밀한 표현 학습을 강화
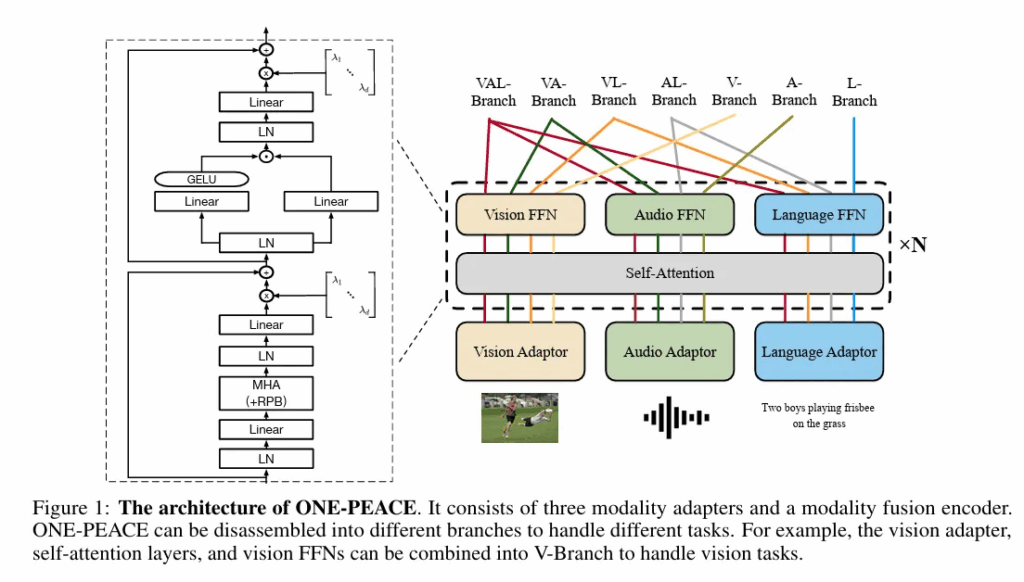
저자 모델의 전체적인 구조입니다. 왼쪽 구조는 기본적인 Transformer 블록 내부 구조라고 생각하시면 됩니다. 오른쪽 구조는 각 모달리티의 어댑터 + attention + 모달리티 FFN 으로 구성이 되어있습니다. Vision/Audio/Language Adaptor 가 최초입력을 feature sequence로 변환하며 이를 cross-modal interaction을 위한 self attention에 태웁니다. 이후 상단의 VAL, VA, V 등의 branch 는 특정 모달리티 조합을 처리하는 경로라고 생각하시면 됩니다. 즉 V-Branch 는 Vision 전용 태스크를 수행합니다. 해당 figure만 보면 매우 간단하다고 생각할 수 있습니다.
Method
Modality Adapters : 각 모달리티를 모델이 공통적으로 처리할 수 있는 feature sequence로 변환하는 전처리 블록으로 서로 독립적으로 작동하므로 transformer, CNN, RNN 등 자유롭게 선택 가능합니다.
- Vision Adapter hMLP stem을 사용해 이미지를 패치화한다고 합니다. 간단하게 설명드리면 ViT류 모델에서 이미지의 입력을 CNN 대신 MLP 를 계층적으로 쌓은 구조로 설계한거라고 이해하면 됩니다. 최종 표현은 이렇습니다.
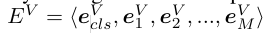
- Audio Adapter 입력 오디오를 16Khz로 샘플링하고 정규화한 후 CNN 기반의 feature extractor를 사용했다고 합니다. 오디오의 임베딩 스페이스에 positional encoding은 컨볼루션 레이어로 relative position 정보를 추출하여 더해줬다고 합니다. 최종 표현은 이렇습니다.
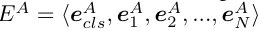
- Language Adapter 텍스트를 BPE 방식으로 분할하여 CLS 와 EOS 를 삽입한다고 합니다. 최종 표현은 이렇습니다.
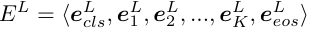
Cross-Modal Contrastive Learning
이미지와 텍스트, 오디오와 텍스트 쌍을 대조학습을 기반으로 학습합니다. 각 모달리티의 CLS 토큰 출력을 통해 진행하며 기존 CLIP LOSS를 각 모달리티에 사용한다고 생각하시면 됩니다.
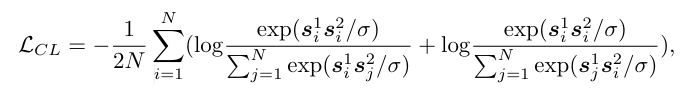
Intra-Modal Denoising Contrastive Learning
위의 cross modal contrastive learning 방식은 서로 다른 모달리티 간의 feature 정렬에 집중하는데 이는 각 모달리티 내부의 세밀한 정보를 학습하는 데 소홀하기 때문에, 다운스트림 태스크에서 최적의 성능을 내지 못하는 문제가 있어서 Intra-Modal Denoising contrastive learning을 도입했다고 합니다.
intra-modal 방식은 masked prediction과 contrastive learning 의 결합으로 볼 수 있는데, 이미지 패치, 텍스트 토큰, 오디오 파형과 같은 세밀 단위 feature 들 중 일부를 마스킹한 뒤 마스크 된 feature와 보이는 feature 사이에서 contrastive loss를 계산합니다.
동작 방식은 모달리티 어댑터를 통과한 임베딩 시퀀스에 대해 일부 단위를 무작위로 마스킹한 후 계산 비용과 메모리 절약을 위한 unmasked 단위만 모달리티 융합 인코더에 입력한다고 합니다.
인코더가 출력한 unmasked feature 들은 학습 가능한 mask 토큰과 연결되어 경량 transformer 디코더로 입력되어 mask된 feature를 복원합니다. 마스크를 적용하지 않은 원본 입력을 target feature로 하여 마스크된 feature와의 contrastive loss를 적용한다고 생각하면 됩니다.
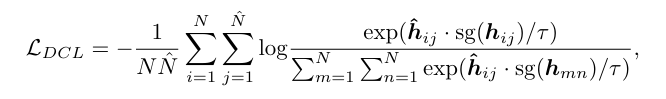
hij : 마스크된 단위 표현
h^ij : taerget 단위의 표현
sg : stop-gradient
N : 한 샘플 내의 마스크된 단위 개수
N^ : 전체 단위 개수
τ : 고정된 temperature 값
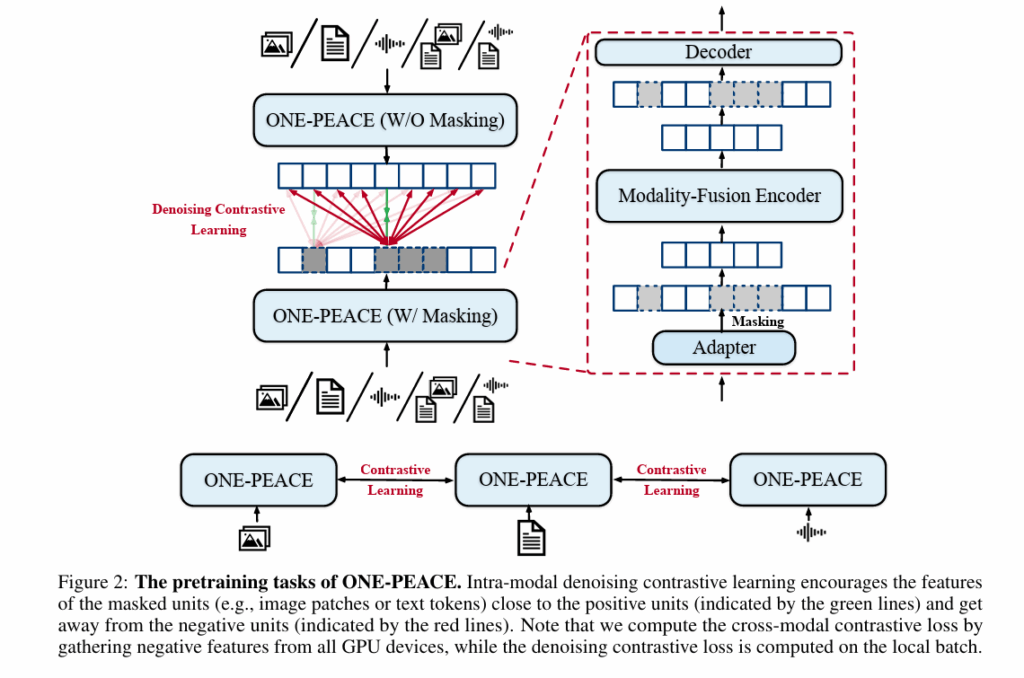
상단 (Denoising contrastive Learning) w/ masking vs w/o masking (원본) 이며 초록색 부분은 positive pair 빨간색 부분은 negative pair로 작동합니다. 즉 intra-modal 표현을 fine-grained하게 학습합니다.
하단 (Cross-modal contrastive Learning) image,text,audio 각각 one peace branch를 거쳐 global embedding을 뽑은 후 서로 다른 모달리티 간 contrastive loss를 수행합니다.
ONE-PEACE 의 전체 사전학습 과정을 두단계로 나눕니다.
- Vision-Language Pretraining
- Audio-Language Pretraining
1번 단계에서는 이미지와 텍스트 쌍관련 Loss로 구성되어 있습니다.
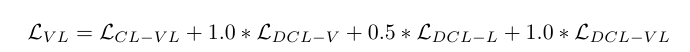
2번 단계에서는 오디오와 텍스트 쌍 관련 Loss로만 구성되어 있습니다.
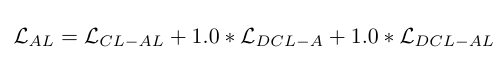
여기서 1과 0.5는 각각 loss 중요도를 조정한 하이퍼파라미터입니다.
추가적으로 이미지-오디오 쌍에 대해서는 직접 학습하지는 않지만 language 를 공통 anchor 로 사용하기 때문에 간접적으로 vision 과 Audio 의 의미 공간도 정렬된다고 설명합니다.
pretraining Datasets
데이터셋은 두 부분으로 나뉘는데, Iamge-text paris는 LAION-2B로 사전학습하며 Audio-Text paris는 다양한 공개 환경 소리 데이터셋으로 학습했다고 합니다.
ONE-PEACE는 대부분 랜덤으로 초기화하며 Audio Adapter의 특징 추출기만 WavLM 의 가중치를 사용했다고 합니다.
여기서 1과 0.5는 각각 loss 중요도를 조정한 하이퍼파라미터입니다.
추가적으로 이미지-오디오 쌍에 대해서는 직접 학습하지는 않지만 language 를 공통 anchor 로 사용하기 때문에 간접적으로 vision 과 Audio 의 의미 공간도 정렬된다고 설명합니다.
pretraining Datasets
데이터셋은 두 부분으로 나뉘는데, Iamge-text paris는 LAION-2B로 사전학습하며 Audio-Text paris는 다양한 공개 환경 소리 데이터셋으로 학습했다고 합니다.
ONE-PEACE는 대부분 랜덤으로 초기화하며 Audio Adapter의 특징 추출기만 WavLM 의 가중치를 사용했다고 합니다.
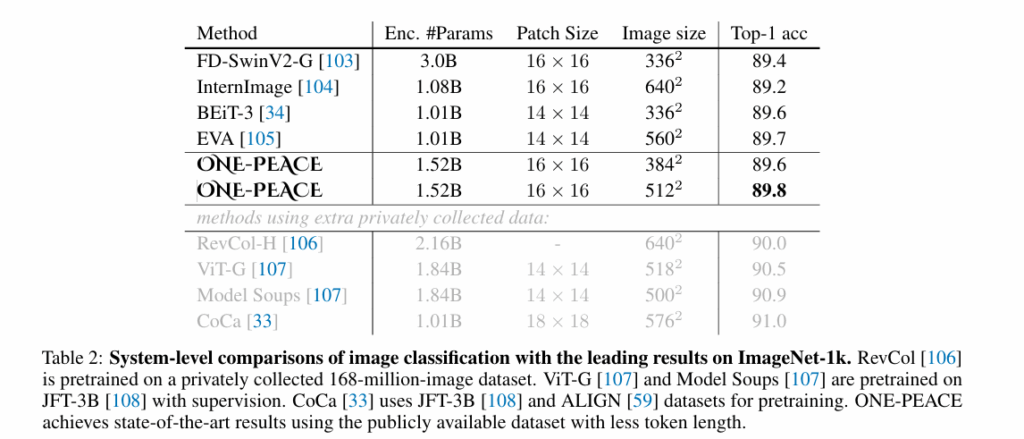
기존 대형 비전-언어 모델들과 비교한 ImageNet-1k 성능지표로 공개 데이터셋만 사용하고 랜덤 초기화한 모델로 동등하거나 더 나은 성능을 달성헀다고 합니다.
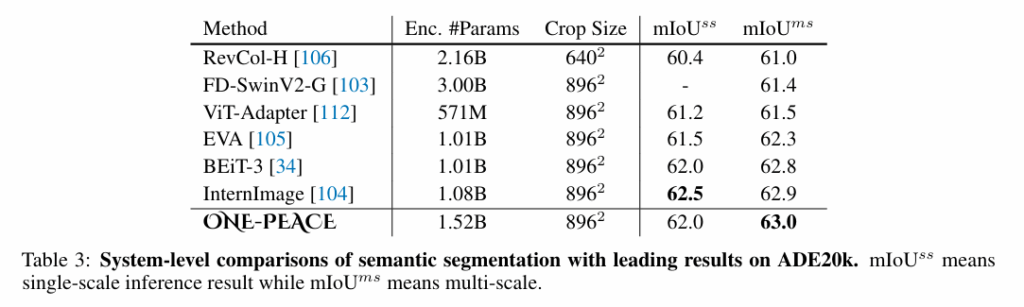
ADE20k segmentation 에서도 기존 모델들을 능가하는 성능을 보여준다고 합니다.
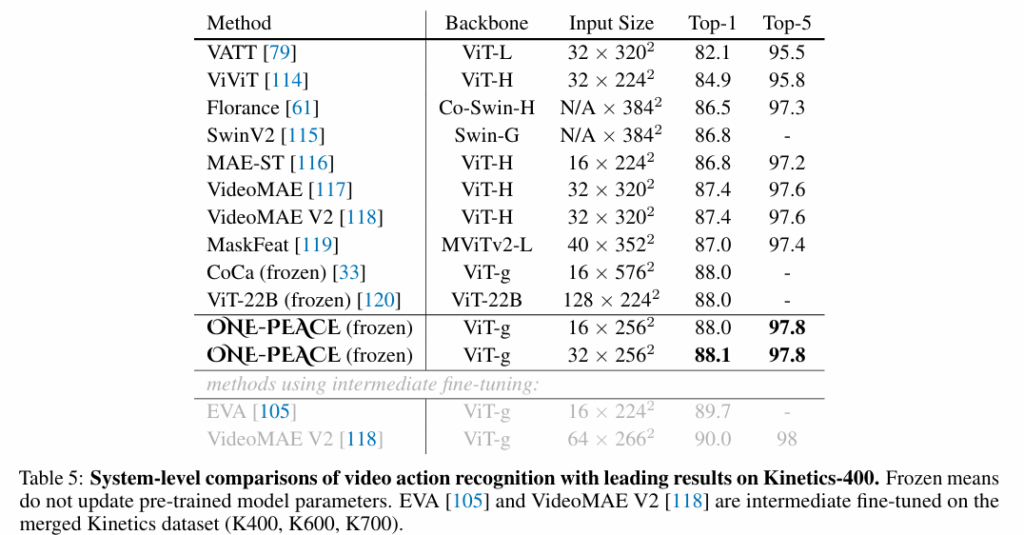
액션 인식에서도 기존의 방법론보다 더 나은성능을 보여주고 있습니다. 저 freozen 상태는 사전학습된 파라미터를 고정하고 단순 head만 학습하는 설정인데도 높은 성능으로 범용 표현 모델로서의 높은 전이 성능을 입증한다고 합니다. 아래 회색 부분들은 추가 데이터셋으로 학습한 모델로 해당 모델들보다는 성능이 낮습니다.
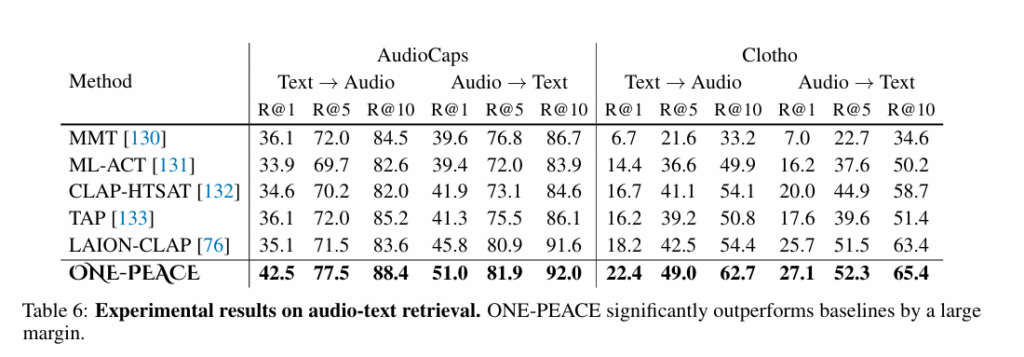
오디오-텍스트 벤치마크에서도 평가했는데 기존 방법론들 대비 큰폭으로 성능이 향상된 것을 알 수 있습니다.
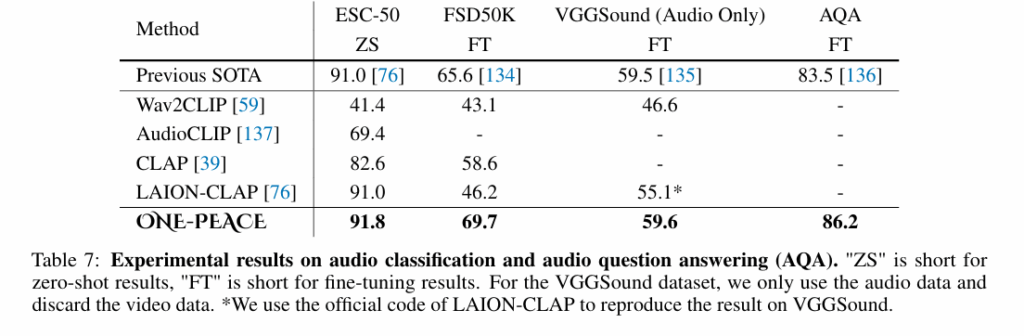
해당 table은 오디오 관련 task로서의 성능을 보여주며 zero shot 수치는 추가 학습 없이 진행된 수치이므로 ECS-50 데이터셋의 난이도가 쉽더라도 91.8의 높은 일반화 성능을 보임을 알 수 있습니다.
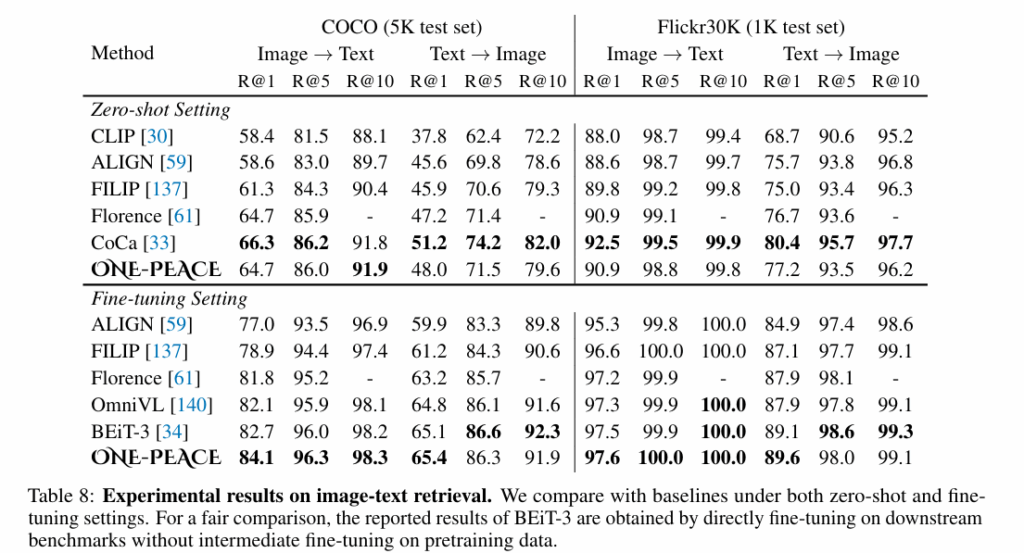
텍스트-비디오 검색 성능도 존재하는데, 기존 모델들과 비슷한 수준의 성능을 보이고 있습니다. 특히 zero shot 에서는 다른 모델이 근소하게 앞서던 성능이 fine tuning 이후에는 모두 저자의 모델이 앞섬을 확인할 수 있습니다.
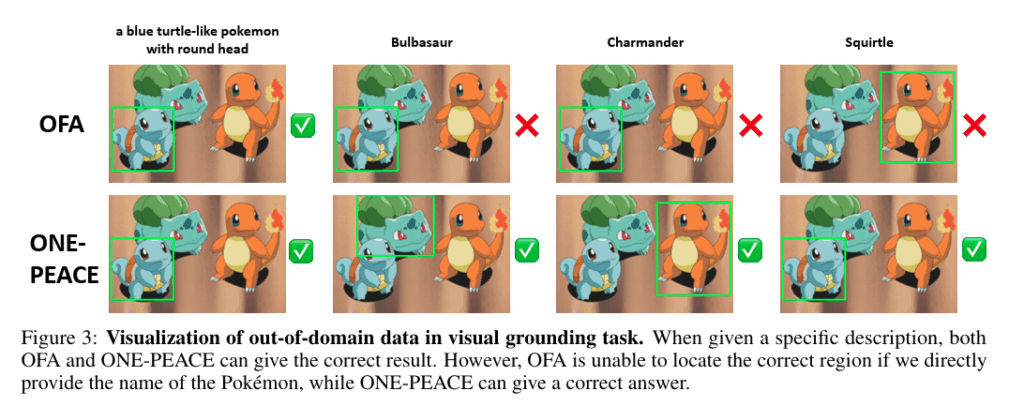
해당 figure는 저자의 모델이 기존 모델대비 visual grounding 능력도 뛰어남을 보여줍니다. 특히 OOD 데이터 상황에서도 일반화 성능을 보여주는 figure입니다. 기존 모델도 파란 거북이 같은 포켓몬을 찾기는 하지만 객체 이름을 넣으면 혼동하지만, 저자의 모델은 이름과 표현을 줘도 오답을 내뱉지 않는 모습입니다.
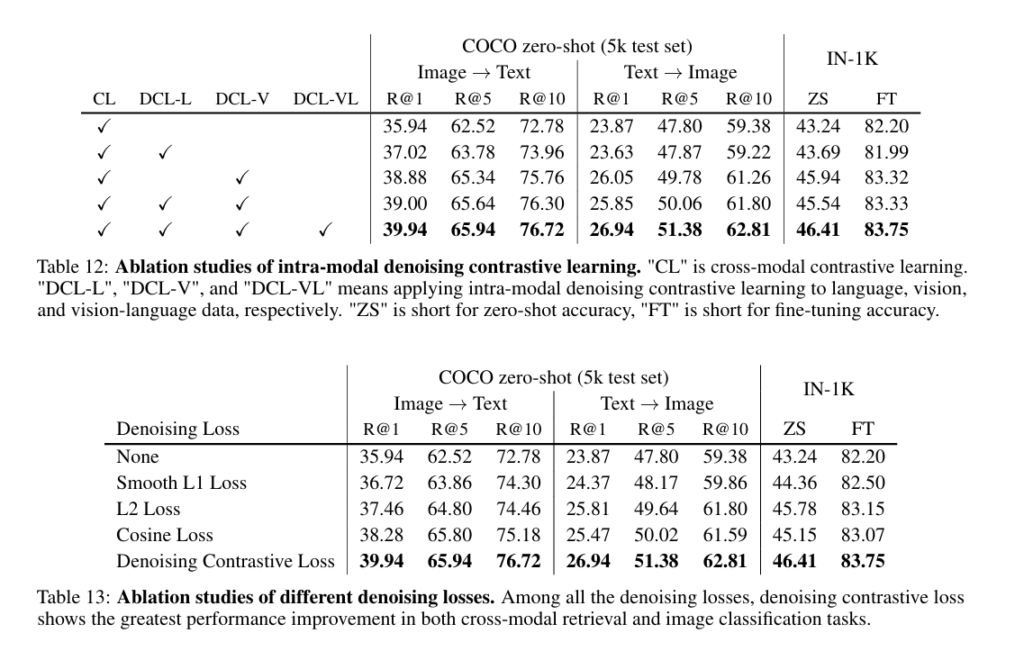
해당 Table 은 Loss 부분 ablation으로 각각 DCL을 추가할수록 성능이 올라감을 보이는 Table 12와 단순 loss보다 contrastive loss로 denoising loss를 사용함이 제일 성능이 좋음을 보여줍니다.
Conclusion
저자가 여러 모달리티에 확장 가능한 범용 모델을 구현했으며 여러 분야에서 뒤쳐지지않는 성능을 보여 나름 의미있는 논문이라 생각합니다. 다만 마지막에 한계점 언급으로 제로샷 이미지-텍스트 리트리벌이나 비전-언어 이해에 대해서는 기존 모델 대비 떨어지는 성능을 사전학습에 사용된 데이터량이 적은점, 그리고 언어 사전학습 모델을 초기화에 사용하지 않은 점등을 언급합니다. 저자의 모델이 vision & languagerandom init으로 시작하지만 타 모델들과 견줄만한 성능을 낸 contribution이 있으며 저자는 새로운 다운스트림 task로의 확장이 유연하고 더 다양한 모달리티로 확장이 가능함을 언급하고 있습니다. (비디오, 3D point cloud)
안녕하세요, 신인택 연구원님 좋은 리뷰 감사합니다.
어찌보면 당연한 질문이지만 Vision-Audio 쌍을 학습하지 않아도 간접적으로 정렬된다고 언급했는데, 그래도 명시적으로 정렬해주는 것이 성능이 더 좋을 것 같은데 학습하지 않는 이유가 있나요? 데이터셋에 라벨이 존재하지 않기 때문인가요?
감사합니다.
안녕하세요 성준님 답글 감사합니다.
질문에 대한 답변으로 명시적으로 오디오-비전 쌍을 정렬해주는 것이 성능이 더 좋을 수 있습니다.
논문에 직접적인 언급이 존재하지는 않지만 성준님이 추측하듯이 데이터셋 라벨의 부재때문일수도 있고 해주는 cost 보다 text라는 공통 매개로 간접적인 alignment를 맞춰주는 것이 나름 도움이 됐기 때문이라 생각합니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
1. 본 글에서 ‘Cross-Modal Contrastive Learning’은 이미지-오디오 쌍에 대해 직접 학습하지 않고, language를 공통으로 사용하기 때문에 간접적인 영향을 줄 수 있다고 설명해주셨습니다.
하지만, 이 방식이 이미지-오디오 태스크에서 실제로 효과적인지 궁금합니다. 혹시 이미지-오디오 태스크에 대한 별도의 실험 결과가 있나요?
2. 모델 구조 자체에 특별함은 없어 보이는데, 그럼에도 다른 모델보다 성능이 좋아 의문이듭니다. 저자가 설계한 아키텍쳐에 새로운 모듈 등이 있는지 궁금하고 실험에서 비교된 모델들이 2023년 기준 최신 멀티모달 모델들을 포함하고 있는지 궁금합니다.
감사합니다.
안녕하세요 의철님 답글 감사합니다.
1번 질문에 대한 답으로 논문에 해당 부분 성능이 리포팅되어있습니다.
제가 리뷰에 올리지는 않았지만 figure 5 에 zero-shot retrieval 성능으로 오디오와 이미지에 대한 예시 사진들이 올라와있습니다. figure 설명상 학습한적 없지만 ImageNet-1k 와 MSCOCO 에서 잘 동작하는 이미지들을 보여주고 있습니다. 예시로 vacuum cleaner 소리로 해당 사진을 찾는 것이나 유리가 꺠지는 소리에 해당하는 이미지등을 보여주고 이습니다. 다만 오디오-이미지 전용 데이터셋에 대한 평가를 진행하지는 않았고 cross-modal zeor shot capability를 강조하고 있습니다.
2번 질문에 대해서도 답해드리자면 사실 제가 보기에도 특별한 추가적인 방법론이나 신기한점들을 찾지는 못했으나 2023년 기준 주요 멀티모달 베이스라인 성능들이 리포팅되어있는 만큼 성능 차이가 단순히 구형 모델들과의 비교 때문은 아니라고 생각합니다.
이게 아카이브에 있긴하지만 깃허브에 1.1k star 보유하고 있고 데모나 코드공개가 잘 되어있어 성능확인은 가능할거라 생각합니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
제가 이해가 잘 안되어서 질문 합니다!
서두에 이러한 확장 친화적인 아키텍처와 사전학습 task 덕분에 ONE-PEACE는 이론적으로 무제한의 모달리티까지 확장이 가능하다고 한다고 하셨는데 뭔가 무제한의 모달리티 확장이란게 와닿지가 않아서 이 부분에 대해서 부연 설명해주시면 감사하겠습니다. 또 비전이나 언어에서 사전학습된 어떤 모델도 초기화에 사용하지 않았다는 것 pretrained된 비전이나 언어모델을 사용하지 않았는 것인가요? 만약에 스크래치 레벨로 시작하는거라면 언어 초기화를 하지 않은 것이 실제로 representation 정렬 측면에서 이점이 있었던건지 아니면 단순히 모델 독립성 측면의 선택인건지가 궁금합니다
감사합니다.
안녕하세요 우현님 답글 감사합니다.
우선 첫번째 질문에 대해서는 저도 추가적인 모달리티로 무엇을 더하면 좋을지 막 생각해보지는 않았으나, LiDAR 나 센서입력, depth 등도 추가가 가능할 것이라 생각됩니다.
저자의 모델이 무한히 확장 가능한 모델인 이유는 각 모달리티별 전용 어댑터를 이용하여 모든 모달리티를 같은 공간에 매핑시키고 이후 같은 트랜스포머 attention 구조를 사용하기 때문에 새로운 모달리티가 들어오더라도 어댑터만 설정해주면 되기 때문입니다.
그리고 이후 질문해주신 스크래치 레벨에서 학습하는 이유도 생각해보지 못했지만, 무제한으로 확장 가능한 모델을 만들기 위한 장치로 생각됩니다. 이미 학습된 모델들을 불러와서 사용한다면 이미 사전학습된 가중치나 gradient 들의 민감도가 다를 것이라 생각됩니다. 처음부터 스크래치로 모든 모달리티를 학습하는 행위가 안정적이지 않을까 생각합니다.
감사합니다.