이번에 소개할 논문도 Text-Video Retrieval(TVR) 연구의 논문입니다. 이 논문은 기존 TVR 연구들이 텍스트와 비디오 간의 “대칭적 관계”를 가정했던 한계를 지적하며, “정보 비대칭성”이라는 근본적인 문제에 주목해서 이를 해결하고자 합니다. 특히 모델 중심이 아닌 데이터 중심(data-centric) 접근 방식을 통해 문제를 해결하고 분석하면서, 결국 데이터의 질과 표현력을 높이는 게 TVR 의 정확도를 올리는데 얼마나 중요한지 잘 보여줍니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
Text-Video Retrieval(TVR)은 사용자가 자연어 쿼리(text query)를 통해 의미적으로 관련된 비디오를 찾을 수 있게 해주는 기술로, 비디오 검색 및 추천 시스템에 필수적입니다. 일반적으로 이 태스크는 텍스트와 비디오를 joint embedding space로 인코딩하고 코사인 유사도와 같은 메트릭을 사용하여 유사성을 계산하는 방식을 사용합니다. 그러나 이 분야의 발전에도 불구하고 텍스트-비디오 검색은 종종 간과되는 문제인 정보 비대칭성으로 인해 근본적인 한계를 지닙니다.
비디오는 시각적인 장면, 행동, 상호작용 등 다양한 요소를 담고 있습니다. 반면, 비디오를 설명하는 텍스트 쿼리나 캡션은 이러한 비디오의 복잡하고 다양한 내용 중 일부만 간결하게 서술하는 경향이 있습니다. 따라서 텍스트가 비디오의 모든 세부 정보를 담기에는 어려움이 있고 저자는 이를 정보 비대칭성 문제라고 언급하고 있습니다.

예를 들어, 그림1에서는 MSR-VTT 데이터 세트의 일부 샘플을 보여주는데, 비디오의 일부 주요 장면이 충분히 설명되지 않거나 완전히 생략될 수도 있습니다. 따라서 저자는 이러한 정보 비대칭 문제를 텍스트를 추가하여 이 문제를 해결하는 데이터 중심적 접근 방식을 제안합니다.
저자의 방식은 학습 단계(training)와 검색 단계(retrieval)로 나눌 수 있습니다.
먼저 학습 단계에서는 사전 학습된 Vision-Language Model(VLM)과 event-aware segmentation을 활용하여 비디오의 의미적으로 중요한 순간들을 포착하고, 해당 구간에 대한 event-level 캡션을 생성합니다.
검색 단계에서는 Large Language Model(LLM)을 활용해 텍스트 쿼리를 확장,다양화함으로써 대상 비디오가 가진 의미적 복잡성을 보다 다양하게 표현할 수 있도록 합니다.
2. method
프레임워크는 크게 세 가지 부분으로 나뉩니다.
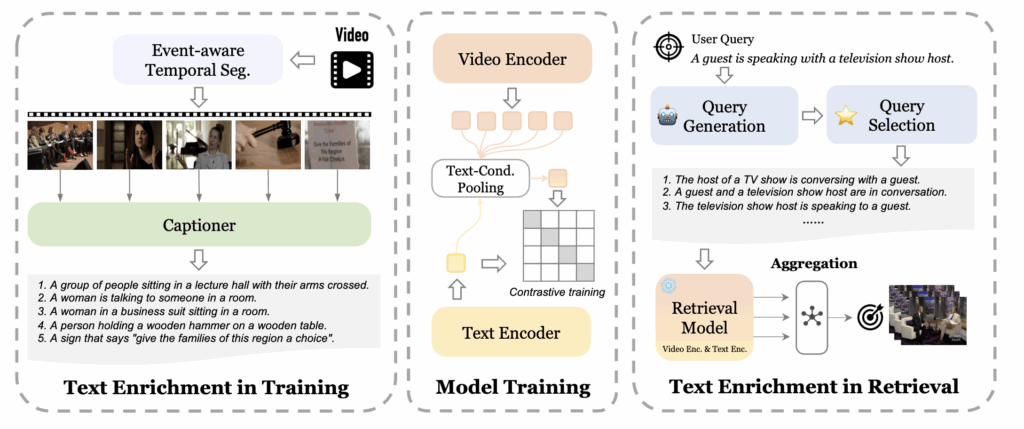
- Text Enrichment in Training : 학습 단계에서의 텍스트 강화를 부분으로 모델 학습에 사용되는 텍스트 데이터를 생성합니다.
- Model Training : 추가 생성한 텍스트 데이터를 사용하여 모델을 학습시킵니다.
- Text Enrichment in Retrieval : 이는 검색 단계에서의 텍스트 강화를 하는 단계로 GPT-4를 사용하여 User Query를 다양하게 하고 이중에서 선별하여 검색 성능을 향상시킵니다.
구체적인 방법은 아래에서 설명드리겠습니다.
2. 1 Model
먼저 저자가 사용하는 모델은 X-Pool 모델인데 이는 사전 학습된 CLIP을 백본으로 사용하고 text-conditioned pooling을 도입하여 주어진 텍스트 쿼리와 의미적으로 가장 유사한 비디오 프레임에 가중치를 주고 관련 없는 정보는 가중치를 낮게 하는 방법론입니다.
X-Pool은 모델 아키텍쳐 관점에서 정보 비대칭성을 어느 정도 해결하여 성능을 향상시킬 수 있었습니다. 하지만 여전히 데이터셋 자체에 정보 비대칭 문제가 있기 때문에 이를 해결하지 않으면 정보를 더 향상시키기에는 어려움이 있습니다.
예를 들어 쿼리 A에와 관련이 없다고 간주되는 프레임은 쿼리 B와 관련이 있을 수 있습니다. 하지만 쿼리 B가 학습데이터에 없다면 이 정보는 모델 학습 과정에서 학습이 안될 가능성이 높습니다. 따라서 이러한 상황에서는 비디오의 임베딩이 쿼리 A에 치우치는 문제가 발생하고 쿼리 B가 주어졌을 때 정확한 비디오를 찾는데 어려움이 있을 수 있습니다.
따라서 텍스트 쿼리가 비디오의 모든 장면들을 잘 서술하고 정보가 고르게 마이닝 될 수 있도록 video temporal segmentation module과 image captioning module을 도입합니다.
2.1 TRAINING PHASE
video temporal segmentation module은 Kernel Temporal Segmentation (KTS) 알고리즘을 사용하여 구성합니다. KTS는 비디오를 여러 개의 겹쳐지지 않는 ‘장면’ 또는 ‘이벤트’로 나누는 알고리즘입니다. KTS는 frame descriptors의 연속적인 흐름을 분석하여, 비디오의 내용이 언제 어떻게 변하는지 감지하는데, frame descriptors는 각 프레임의 시각적인 특징을 숫자로 표현한 것이고 이는 사전 학습된 CLIP 모델을 사용하여 이러한 특징을 추출합니다. 이를 수식으로 살펴보면 다음과 같습니다.
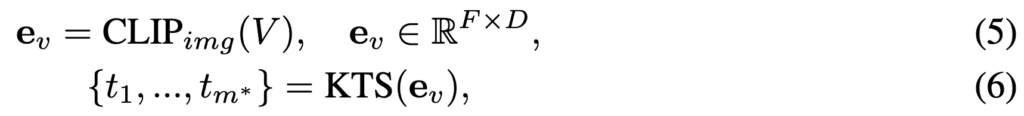
먼저 F개의 프레임을 가진 비디오 V ∈ R{F ×H×W ×3}가 주어졌을 때, CLIP을 통해 F개의 피처를 뽑습니다. 그리고 KTS 알고리즘을 통해 tm개의 변경 지점 위치를 뽑아내게 됩니다. (자세한 KTS 알고리즘은 생략하겠습니다.)
이를 통해 비디오를 여러 세그먼트로 분할 했다면, 각 프레임에 대해 이미지 캡셔닝 모듈을 사용하여 캡션을 생성합니다.
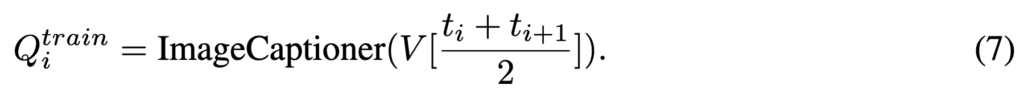
위 수식과 같이 ti와 ti+1 사이의 중간 프레임 인덱스를 사용하여 해당 세그먼트의 대표 이미지를 선택하여 이를 이미지 캡셔닝 모듈의 입력으로 사용했습니다. 이러한 방식으로 텍스트를 추가하여 확장된 데이터셋을 얻을 수 있습니다.
2.2 RETRIEVAL PHASE
기존 텍스트-비디오 검색에서는 하나의 텍스트 쿼리를 사용하여 대상 비디오를 검색했습니다. 하지만 앞서 소개한 정보 비대칭성 문제로 인해 하나의 텍스트 쿼리로는 정확한 비디오 검색이 부족하니 저자는 여러 개의 텍스트 쿼리를 통해 검색을 하는 텍스트 쿼리 확장을 적용합니다.
이 단계에서는 LLM(GPT-4)을 사용하여 주어진 텍스트를 이해하고 추론하도록 하여 텍스트를 더 다양한 장면으로 서술하도록 프롬프트를 줍니다. 프롬프트 예시는 다음과 같습니다.

그리고 수식으로 살펴보면 다음과 같습니다.
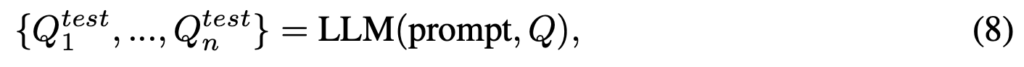
여기서 n은 10으로, 즉 LLM을 통해 10개의 쿼리를 생성하게됩니다. 이후 이렇게 생성된 생성된 쿼리로 비디오 검색을 할 단계입니다. 이 때 생성된 쿼리를 선택하는 방식을 두 가지 방법으로 나눠 비교합니다.
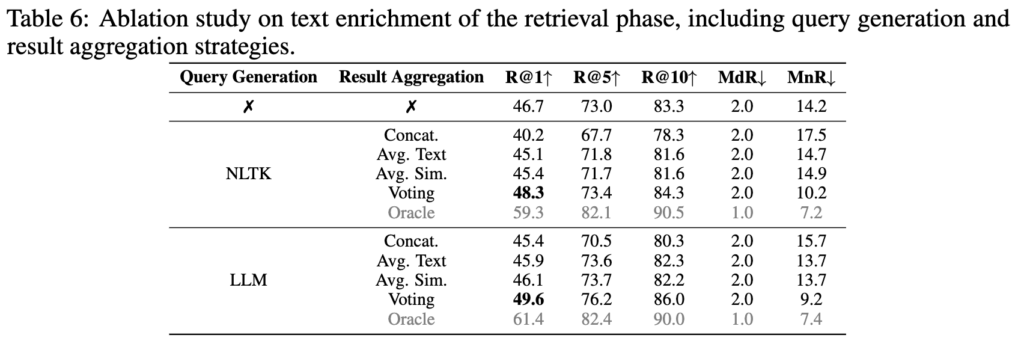
먼저 가장 간단한 방식은 원본 텍스트에 생성된 쿼리를 추가하여 더 긴 텍스트를 만드는 방식입니다. 예를 들면 텍스트 쿼리를 concat 하거나 텍스트 임베딩을 mean pooling 하는 방식이 있는데 이는 성능이 좋지 못했다고 합니다. (표6 참고)
다른 방식은 각 쿼리를 독립적으로 사용하여 검색을 한 다음 가장 성능이 좋은 쿼리를 선택하는 것 입니다. 즉 원본 쿼리, 추가된 10개 쿼리에 대해 기존 1대1 방식으로 계산을 하고 majority voting으로 결과를 종합하는 방식입니다. 성능을 비교해 본 결과 이 방식이 가장 좋은 성능을 보였다고 합니다. (표6 참고)
2.3 QUERY SELECTION MECHANISM
위에서 설명 드린 majority voting 방식이 성능 향상에는 도움이 되지만, LLM hallucination으로 인해 생성된 쿼리 자체에 노이즈가 있을 수 있고 계산량도 기존 보다 11배 증가 하기 때문에, 이 문제를 해결하고자 저자는 QUERY SELECTION MECHANISM을 추가합니다.
먼저 query selection이 정말 효과가 있는지 확인하기 위해 Oracle Query를 사용하여 가능성을 분석합니다. Oracle Query는 쿼리 세트({Q, Q_{test_1}, …, Q_{test_n}} 중에서 특정 비디오에 대해 가장 정확한 검색 성능을 내는 쿼리를 선택하는 것을 의미합니다. 이 방식을 통해 46.7%에서 61.4%로 향상되는 것을 확인하며, 저자는 텍스트 쿼리를 다양하게 하는 것(1)과 효율적인 쿼리 선택(2)이 성능 향상에 도움이 될 수 있다는 것을 보여주며 쿼리 selection의 가능성을 보여줍니다.(표6 참고)
저자는 query selection을 할 때 두 가지 측면을 고려하여 설계를 하였습니다.
첫번째는 관련성 (Relevance)입니다. 이는 생성된 쿼리가 원본 텍스트 쿼리의 의미를 정확하게 전달하고, illusions을 최소화해야 한다는 내용입니다. 그리고 두 번째는 다양성 (Diversity)입니다. 이는 텍스트 쿼리가 다양한 방식으로 표현되어, 대상 비디오의 의미적 복잡성을 더 폭넓게 포괄해야 한다는 내용입니다.
그래서 저자는 첫 번째 측면은 LLM을 통해 원본 쿼리와 관련되도록 프롬프트를 설계하였고 두 번째 측면을 고려하기 위해 쿼리 selection에서 Farthest Query Sampling (FQS) 알고리즘을 사용하여 쿼리를 선택합니다. FQS는 선택된 쿼리들 사이의 최소 거리를 최대화하는 방식으로 쿼리를 반복적으로 선택하는 알고리즘입니다.
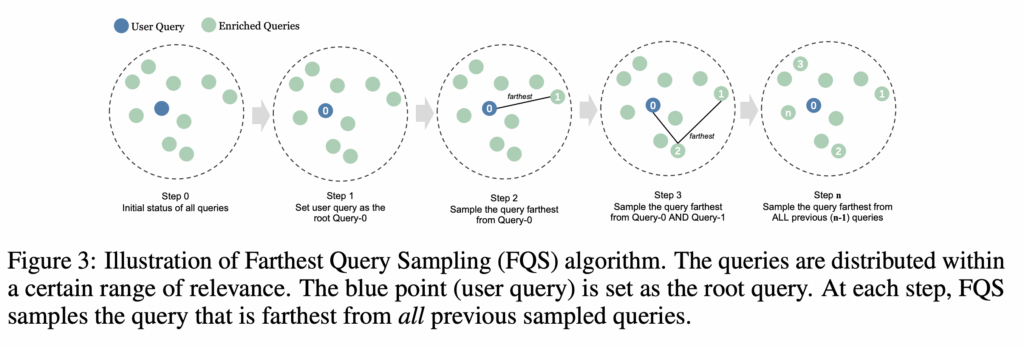
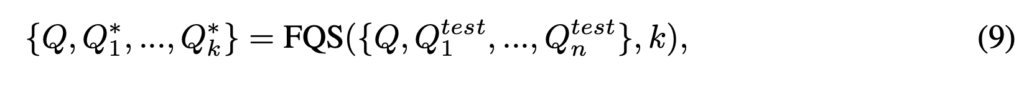
동작방식은 위 그림과 같은데 먼저 원본 쿼리 Q를 첫 번째 root query로 설정합니다. 이후 매 단계마다, 이미 선택된 쿼리들로부터 가장 멀리 떨어져 있는 쿼리를 찾아서 다음 쿼리로 추가합니다. 이를 반복하여 미리 정해진 k개의 쿼리를 선택합니다. 최종적으로 원본 쿼리와 선별된 k개의 쿼리에 대해 concat,avg,voting 등의 방식으로 검색에 활용할 수 있습니다.
3. Experiment
다음으로 실험 결과를 살펴보겠습니다.
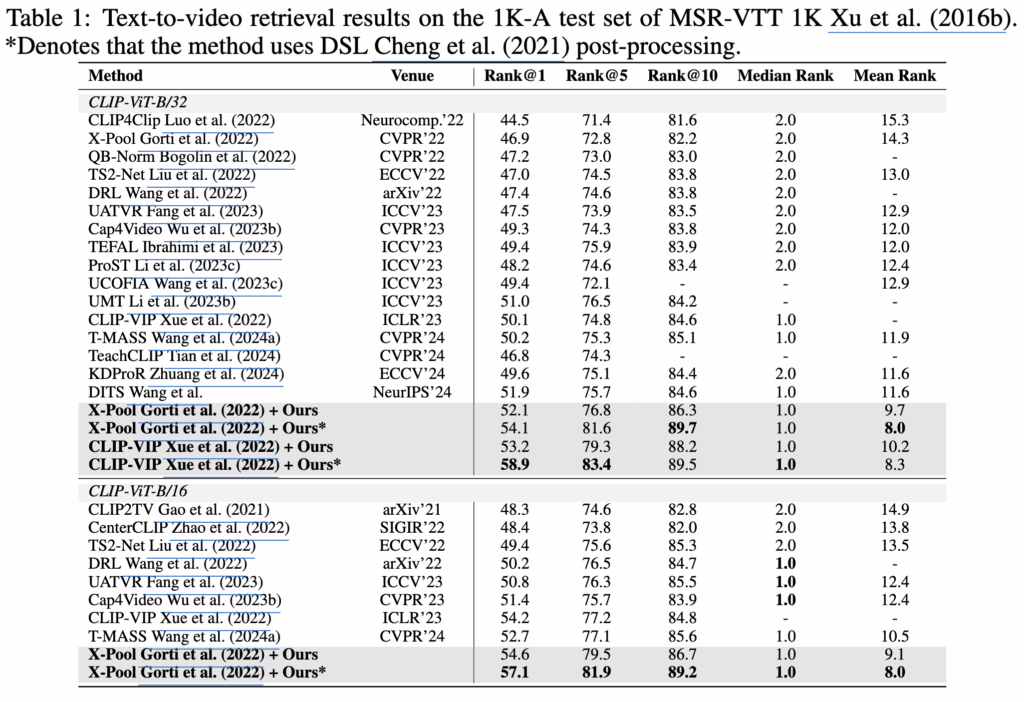
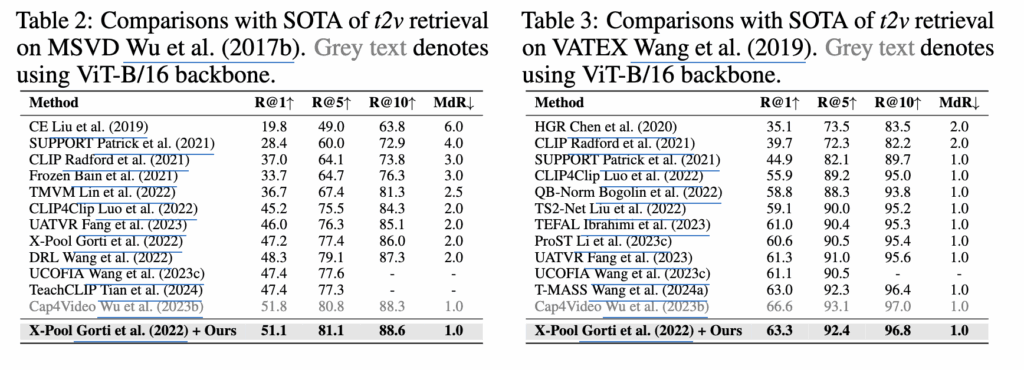
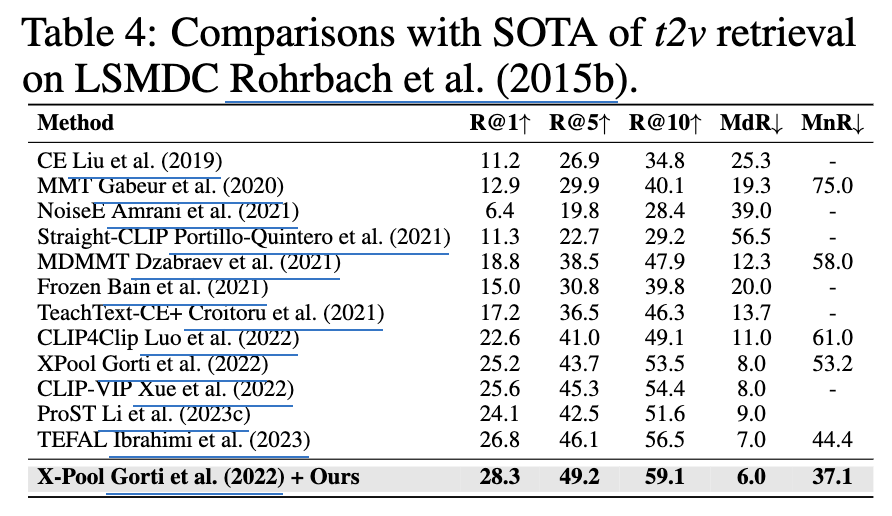
저자는 MSR-VTT, MSVD, LSMDC, VATEX 데이터셋으로 모델을 평가했습니다. 저자의 방법론은 ViT-B/32, ViT-B/16 백본 SOTA를 달성하는 것을 확인할 수 있습니다.
Ablation Study
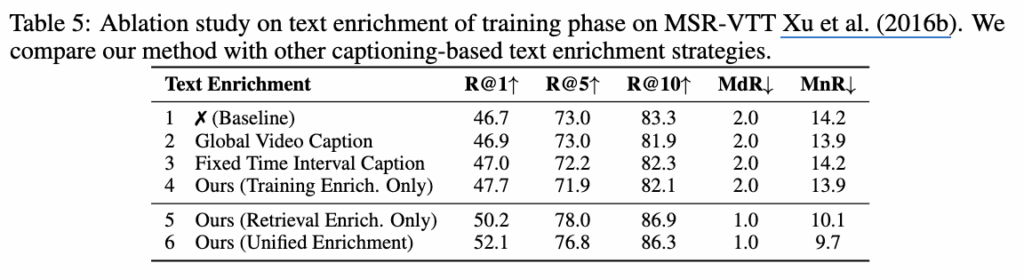
테이블 5에서는 쿼리 보강 모델에 대한 실험 결과입니다. Global Video Caption 모델은 비디오 캡셔닝 모델을 의미하며 Fixed Time Interval Caption 모델은 비디오를 고정된 시간 간격으로 분할하고, 각 세그먼트에 대해 캡션을 생성하는 모델입니다. 4번째 행의 결과가 저자가 제안하는 방식으로 캡션을 생성하는 방식입니다.
5행의 경우 학습 단계에서의 텍스트 보강은 없이, 검색 단계에서만 텍스트 보강을 적용했을 때의 성능이고 6행은 저자가 최종 제안하는 방식의 성능입니다. 이를 통해 비디오를 이벤트 단위로 분할하여 캡션하는 것이 효과적이며 검색 시 LLM을 활용하여 쿼리를 다양화하고 관련성 있는 쿼리를 선택하는 것이 효과적이라는 것을 알 수 있습니다
테이블 6에서는 검색 단계에서 쿼리 생성을 NLTK와 LLM(GPT-4)에 대해 비교하고 이 생성된 쿼리를 aggregation 하는 방식에 따른 성능 변화 결과입니다
결과적으로 LLM이 전반적으로 더 좋은 성능을 보였고 Concat이나 Avg 방식보다 Voting 방식으로 검색을 했을때 정확도가 올라가는 것을 확인할 수 있습니다.
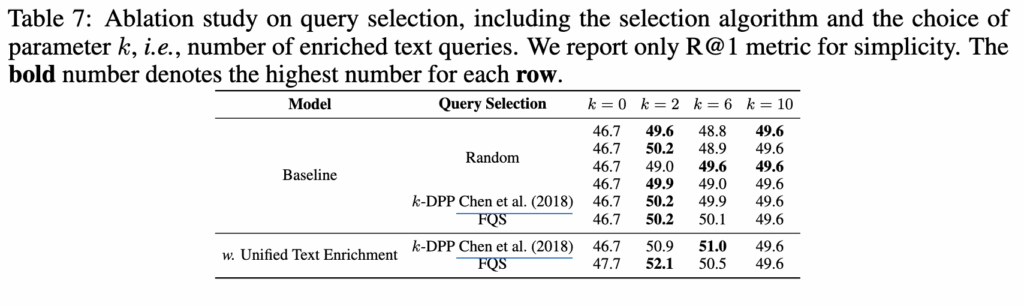
마지막으로 테이블 7에서는 생성된 쿼리 중 selection한 개수에 따른 성능을 분석한 결과입니다. 대부분의 경우 k=2에서 가장 좋은 성능을 보였으며 FQS 알고리즘을 사용했을떄 가장 좋은 성능을 보입니다. 이는 FQS가 초기 원본 쿼리를 시작점으로 해서 관련된 쿼리를 고르기 때문에 관련성을 보장하고 더 안정적인 성능을 보인다고 설명하고 있습니다.