안녕하세요. 두번째 X-review 작성자 최인하입니다. 이번에 읽은 논문은 SSD: Single Shot MultiBox Detector입니다. 논문을 읽으면서 object detection 분야에 관하여 몰랐던 개념들을 하나씩 찾아갈 수 있었던 것 같습니다. 최대한 공부하고 적었으나, 부족한 부분이 있을 수 있습니다. 관하여 댓글 남겨주시면 감사하겠습니다. 바로 시작해 보겠습니다!
Introduction
논문에서는 object detection 분야의 대부분의 알고리즘들이 image에서 bounding box를 만들고, box를 resample하고, high quality 의 classifier를 적용한다고 합니다. 하지만 이러한 방식은 embedded system이나 high-end hardware syetem에서는 계산량이 높아 real-time에서 적용하기 힘들다고 합니다. 따라서 object detection 분야에서 속도를 올리고자 하는 여러가지 시도가 있었지만, 속도와 accuracy간 트레이드오프 관계를 해결하지 못하였습니다. 이 논문에서는 이러한 문제를 해결하기 위해 다음과 같은 방식을 제시합니다.
- 여러개의 convolution layer를 통해 얻은 feature map에서 default box를 적용하여, object들의 scale에 대한 강건성을 확보하였다.
- 또한 bounding box proposal 단계를 생략하고, classification과 localization을 한번에 수행하는 단일 네트워크를 사용하여 속도를 향상시켰다.
이러한 방식으로 SSD는 속도와 정확성 두 마리의 토끼를 잡을 수 있었습니다! 이제 더 자세하게 SSD알고리즘에 대해서 설명해 보겠습니다.
Model
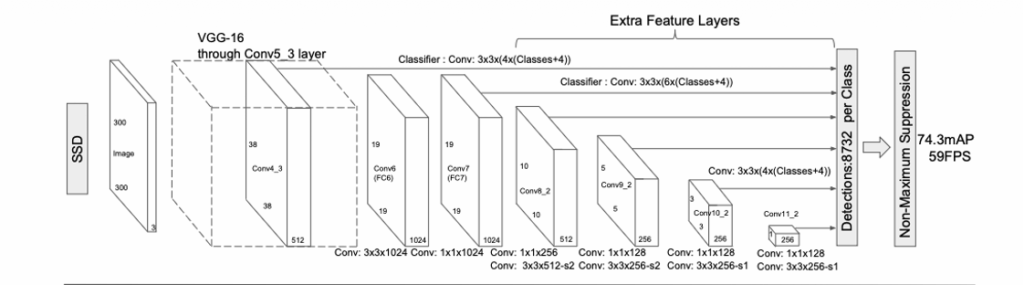
SSD 알고리즘을 그림으로 나타내면 위와 같습니다. convolution network에서 fixed size의 bounding box와 box안에 있는 object class에 대한 score를 예측하고, 이어서 최종 detection을 위해서 NSM(Non-maximum suppression)을 수행합니다. base network로는 VGG-16을 사용했습니다.
Multi scale feature maps for detection
논문에서는 Base network(VGG-16)에서 dense한 구조를 가져간 것 같습니다. (제가 첫번째 x-review에서 작성한 VGG dense evaluation 구조) 뒤에서 더 자세하게 설명하겠지만, conv layer를 통과하면서 커지는 receptive field를 통하여 각각의 feature map 마다 multiple size detection을 수행합니다.
Convolution predictors for detection
각각의 feature map에 대하여 3 x 3 small convolution filter를 사용하여 detection을 진행한다고 합니다. 이 filter는 각각의 pixel 위치마다 category 점수와 default box의 offset을 계산을 수행합니다.
Default boxes and aspect ratios
이 부분에서는 default box를 어떻게 사용하는지 설명합니다. 저자는 default box가 Faster R-CNN에서의 Anchor box와 유사하다고 합니다. 즉 object의 크기에 대해서 강건성을 가져가기 위해 사용됩니다. SSD에서 default box는 각각의 feature map을 슬라이딩하며 대응되는 pixel에 고정됩니다. 즉 feature map의 pixel 마다 default box의 shape offset과 각각의 box의 해당 class의 객체가 존재할 확률인 per-class score를 예측합니다. 구체적으로 설명하면 각각의 box는 개수 k와 location으로 정의됩니다. 따라서 feature map의 위치마다 (c+4)k개의 filter가 적용됩니다. (여기서 c는 class의 수, 4는 default box와 GT box의 offset 즉 x, y, w, h) 따라서 m x n 크기의 feature map에서 (c+4)kmn 개의 output이 형성됩니다!
Training
Training 부분에서는 model 부분에서 설명했던 방법론들을 더욱 자세하게 설명하고, Loss function, default box 정의, data augmentation 과정을 설명합니다.
Matching strategy
Training 과정에서는 default box가 어떤 Ground truth information과 대응하는지 확인하고 그에 맞게 network를 학습시켜야 합니다. 따라서 논문에서는 IoU가 높은 default box와 Ground truth information을 matching 합니다. (이때 threshold 값은 0.5를 사용) 이러한 방식은 learning problem을 단순화한다고 합니다. (여러 positive box를 가지고 학습할 수 있으니까 그런 것 같습니다)
Training objective
SSD의 training에서 사용되는 Loss function은 localization loss와 confidence loss의 가중합으로 나타냅니다. (논문에서는 cross validation을 통해 alpha 값을 1로 설정했다고 합니다.)
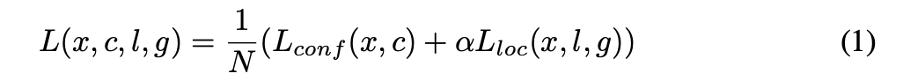
여기서 N은 number of default boxes이며, N이 0이면 loss가 0입니다.
- Localization loss
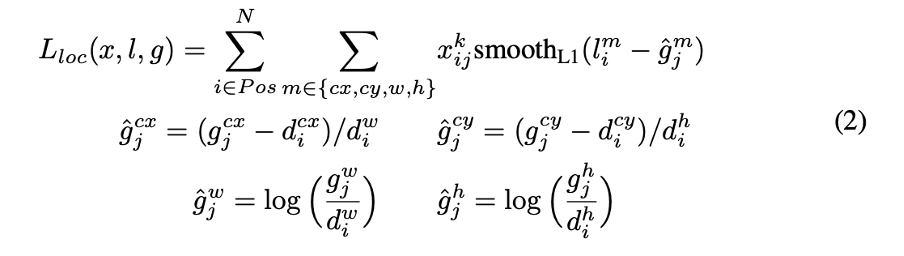
Localization loss는 Smooth L1 loss를 사용하며, bounding box regression을 통해 default box와 ground truth box와 유사하도록 학습합니다. bounding box regression에 대해서 설명해보겠습니다.
Bounding box regression
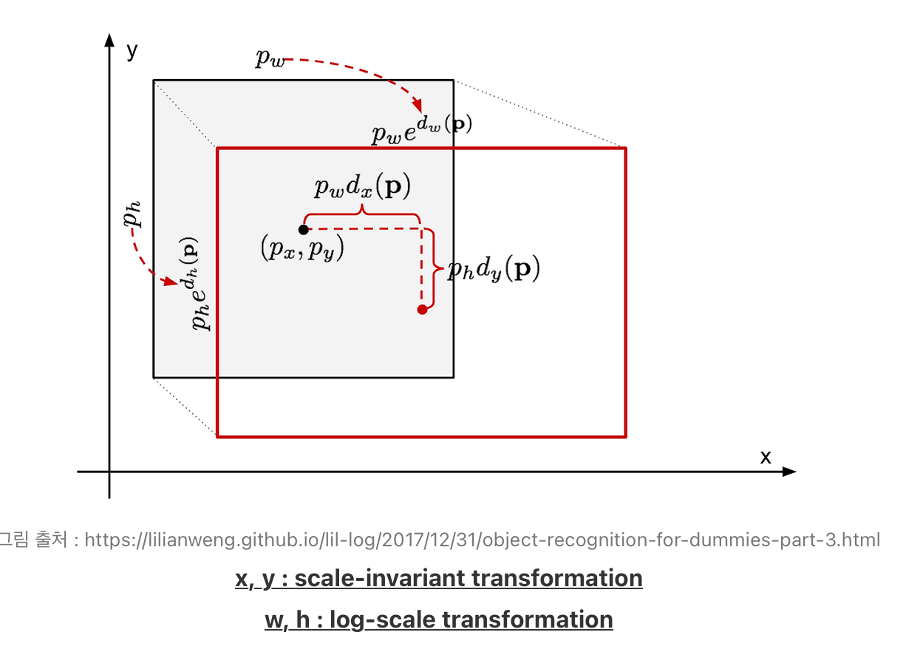
선별된 default box의 위치는 GT box와 일치하지 않습니다. 따라서 SSD에서 bounding box regression은 convolution filter를 통해 얻은 default box와 GT box의 offset과 default box 좌표 d와 GT box의 좌표 g를 통해 얻은 offset의 차이가 최소가 되도록 합니다. 따라서 구한 l(convolution filter를 통해 예측한 offset값)을 통해 default box를 GT box와 맞춰 줍니다. 이 과정을 그림으로 표현하면 다음과 같습니다.
- Confidence loss
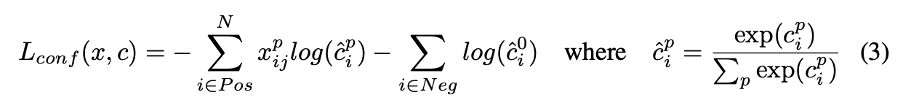
Confidence loss는 위에서 보이는 것과 같이 cross entropy loss를 사용합니다.
Choosing scales and aspect ratios for default boxes
이 부분에서는 SSD 알고리즘이 다른 scale의 object를 default box를 통해 어떻게 detection 하는지 자세하게 설명합니다. 결론부터 말하자면 SSD는 convolution layer를 통해 얻은 여러개의 feature map을 모두 detection에 사용합니다. 이는 상위 feature map의 공간적인 측면과 하위 feature map의 detail한 측면을 모두 고려할 수 있습니다. 또한 서로 다른 feature map의 receptive field를 이용하여 default box가 특정 feature map에서 객체의 scale을 고려할 수 있도록 합니다. 이제 아래의 사진을 보시면,
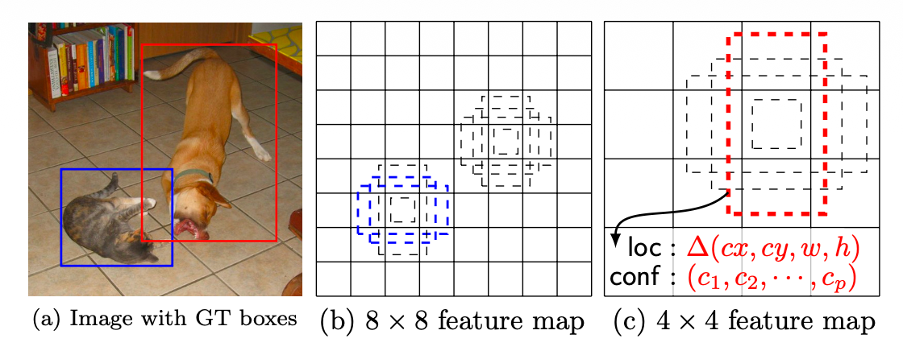
Input image의 강아지의 scale이 고양이의 scale 보다 크므로 더 작아진 feature map에서 matching 되었습니다. 이는 각 default box가 다른 scale을 가지고 있어서 dog의 GT box와 match 되지 않았고, 학습 때 negative로 고려되는 상황을 의미합니다. 그러면 default box의 scale과 aspect ratio는 어떻게 정해질까요? 논문에서는 다음과 같이 설명합니다.
Scales for default box
m개의 feature map을 training에 사용하면, 각 feature map에 대한 default box의 scale은 다음과 같은 식으로 정해집니다.
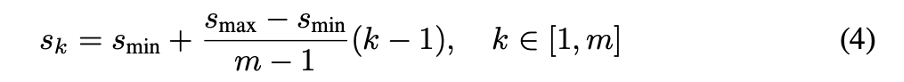
여기서 s(min) 값은 0.2이고 s(max) 값은 0.9입니다. 여기서 이 의미는 상위 layer의 feature map에서의 default box의 scale은 0.2 하위 layer의 feature map에서의 default box의 scale은 0.9라는 의미입니다. 예시를 들어 설명하면 상위 layer의 feature map의 크기가 14 x 14이면 default box의 scale은 2.8 x 2.8로 설정이 됩니다. s(min)부터 s(max) 까지의 범위는 일정하며, m=6 일 때 s 값은 [0.2, 0.34, 0.48, 0.62, 0.76, 0.9]가 됩니다.
aspect ratios for default box
Default box의 가로 세로 비율을 구하는 식은 다음과 같습니다.
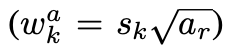
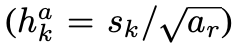
이때 ar의 값은 {1,2,3,1/2,1/3}입니다. (총 5개의 비율을 사용했습니다.) 저자는 추가적으로 default box scale을 추가해서 총 6개의 default box의 scale을 사용하였습니다. 추가한 default box의 scale은 다음과 같습니다.
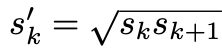
이제 default box의 scale과 aspect ratio를 구하는 법을 알았으니, default box의 중심점을 구하는 방식에 대해서 설명해보겠습니다. 중심은 다음과 같은 식으로 구해집니다.
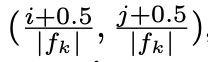
이 식에서 fk는 k번째 feature map의 size입니다. 이로써 default box의 scale, aspect ratio, center까지 구하는 법을 다 알았습니다. 저자는 default box의 설계는 특정 dataset에 fit하게 설정할 수 있으며, 이러한 설계는 열린 문제라고 합니다.
Hard negative mining
Matching 을 수행하면 대부분의 default box는 negative 합니다. 이는 학습 때 불균형을 유발할 수 있습니다. 따라서 논문에서는 모든 negative를 사용하는 것이 아닌 각각의 default box를 highest confidence loss 순으로 정렬하고, 그 중 높은 것으로 골라서 negative와 positive의 비율을 3:1로 하고 학습을 진행합니다. 저자들은 이러한 방식이 faster optimization과 stable learning을 이끈다고 합니다. (즉 Hard negative 데이터를 학습에 사용함으로써 조금 더 false positive에 강건해지는 점을 이용한 것 같습니다)
Data augmentaion
논문에서는 SSD model을 더욱 더 object size 와 모양에 강건하게 만들려고 다음과 같은 augmentation 을 진행했다고 합니다.
- Original input image
- IoU가 최소 0.1, 0.3, 0.5, 0.7, 0.9 가 되는 sample patch 사용
- Randomly sample a patch
- 각각의 sample patch를 original image의 0.1~1 비율로 사용
- aspect ratio를 1/2 ~ 2로 사용 그리고 horizontally flipped을 0.5의 확률로 사용

Table 2에서 확인할 수 있듯이 data augmentation을 진행하면 최대 8.8% 성능 향상을 얻을 수 있는 것을 볼 수 있습니다.
Experimental Results
앞에서 SSD 모델의 방법론과 학습 방식에 대해 말했으니 이제는 실험 결과입니다. 앞에서 언급한 것 처럼 SDD는 ILSVRC CLS-LOC dataset으로 pre-trained 시킨 VGG-16(dense)을 base network로 사용하였고, base network의 5번째 max pooling 과정을 (fc layer에 들어가기 전 pooling 과정) 2 x 2 stride 2에서 3 x 3 stride 1으로 바꾸었다고 합니다. (이는 해상도를 확 줄이지 않으면서 object detection을 하기 위한 목적으로 보이는 것 같습니다) 하지만 이로 인해 receptive field가 커지지 않는 점을 고려해서 논문에서는 atrous 알고리즘(dilated convolution)을 사용함으로써 feature map의 크기는 유지하면서 큰 receptive field를 가져갑니다.
이제 다음 내용은 다양한 dataset으로 test를 수행한 성능평과와 분석에 관한 내용입니다. 워낙 test 결과가 많아서 몇가지 가져와 봤습니다.
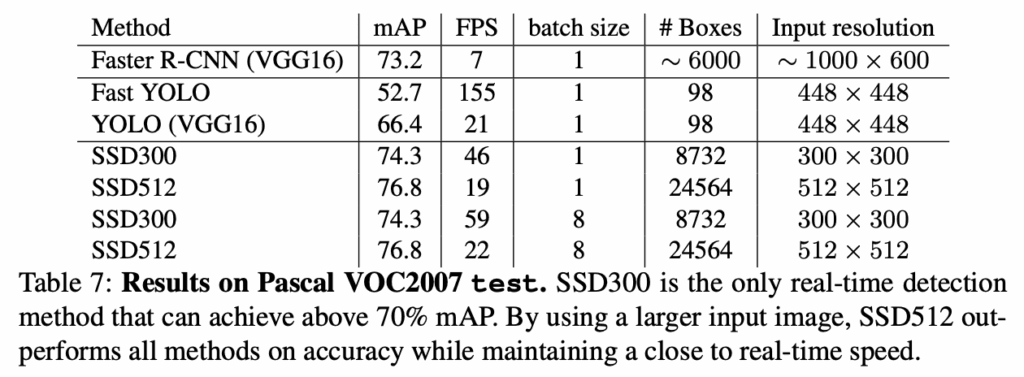
Table 7 에서는 결론적으로 SSD가 다른 object detection 알고리즘 보다 빠르고 정확하다는 것을 보여줍니다. 그리고 읽다가 좀 신기한 Table이 있어 가져왔는데

Table 3은 SSD의 main contribution중 여러 feature map을 활용하여 detection하는 이점을 확인하기 위해서 layer를 지워 가면서 결과를 비교했다고 합니다. Table을 보면 확실히 conv7 하나를 가지고 detection 을 수행하는 것 보다 여러 convolution layer를 사용하는 것이 성능이 좋은 것을 확인할 수 있습니다. 하지만 눈여겨보셔야 되는 점은 conv11_2 layer를 사용한 것이 conv10_2까지 사용한 것 보다 성능이 낮고, conv10_2까지 사용한 것이 conv9_2까지 사용한 것 보다 미미한 성능 향상을 보인 점입니다. 왜 그럴까요?
이는 논문에서 말하길 conv11_2 layer를 지난 feature map은 1 x 1의 해상도를 가지게 되는데 이 때 feature map에서 다루는 object의 scale은 매우 커지게 됩니다. default box는 이렇게 커진 object scale을 정확히 다룰 수 없고 따라서 detection에 있어서 성능 저하가 발생하게 됩니다!
Conclusion
결국 제가 생각하는 이 논문의 main contribution은 one-stage 알고리즘으로 classification과 localization을 동시 수행함으로써 빠른 속도를 챙겼고, 각각의 feature map에 detection을 수행함으로써 object scale에 대한 강건성, detection의 정확도를 올렸다! 따라서 두마리의 토끼를 다 잡을 수 있었다!
모두에게 익숙하실 SSD 논문 review 해봤습니다. 틀린 부분이나 궁금하신 점 댓글 남겨주시면 감사하겠습니다.
긴 글 읽어주셔서 감사합니다!
안녕하세요 인하님 리뷰 감사합니다
글에도 보인것 같긴 한데, SSD가 제안한 one-stage 방식이 Faster R-CNN과 같은 방식 보다 빠르면서도 높은 성능을 보이는 이유는 무엇인가요?
또 Hard negative 데이터를 학습에 사용함으로써 조금 더 false positive에 강건해지는 이유가 무엇인지 조금만 풀어서 설명해주실 수 있을까요?
3:1의 비율이 1:1, 2:1로 달라지면 어떤 현상이 일어나는지, confidence loss 기준으로 정렬하는 이유는 무엇인지 궁금합니다!
안녕하세요 인하님 좋은 리뷰 감사합니다^^
Localization Loss를 표현한 수식에서, offset을 구한다면 단순히 GT box의 값과 default box의 값들(cx,cy,w,h)을 빼면 되는거 아닌가 라는 생각이 드는데, 중심 좌표에는 추가로 너비/높이를 나누고 또 w,h의 오프셋은 로그를 취해준 이유가 궁금합니다.