안녕하세요, 지난주에 X-sim이라는 연구에 대한 리뷰를 작성했는데요, 현실에서의 사람의 행동에 의한 물체의 trajectory 변화를 reward로 활용해 PPO 알고리즘으로 학습한 policy를 vision based 모델에 distill하고 더 나아가 sim to real gap을 해소한 연구였습니다. 해당 연구 뿐만 아니라 현재 대부분 로봇을 학습할 때 PPO 알고리즘은 표준처럼 사용되고 있는 알고리즘입니다. PPO 알고리즘은 actor critic 방식으로 TRPO를 변형한 방법인데, 이를 위해 알아야할 내용들이 많아서 TRPO와 PPO 알고리즘을 공부하기 전 까지의 강화학습 내용을 복습하고 흐름에 맞게 어떤 한계점들이 있었고 어떻게 해결했는지를 정리하려고 합니다. 사실 수학적으로 자세하게 공부하기에는 아직 시간적으로도 무리가 있고 전부 적기에도 빡세서 제 머리속의 컨셉(?)적인 부분들을 흐름에 따라 정리하는 글이 될 것 같습니다. 이후 읽어야하는 TRPO와 PPO 알고리즘은 각각 읽고 심층 리뷰를 적어보도록 하겠습니다 하하,,
MDP
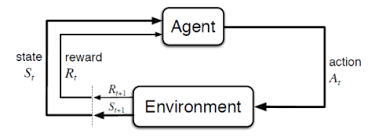
PPO는 앞서 말했듯 강화학습이 발전함에 따라 기존의 한계들을 해결하거나 알고리즘을 개선해나가며 등장한 알고리즘이기 때문에 PPO가 등장하기까지의 배경을 설명하면서 정리해보고자 합니다. 강화학습 문제는 보통 MDP(Markov Decision Process)로 모델링이 됩니다. MDP는 s(상태), a(행동), r(보상), p(전이확률), gamma(할인율)의 요소들을 가지고 있습니다. 각각 에이전트가 처한 상황, 그 상황에서 취할 수 있는 행동의 집합, 행동을 취했을 때 환경으로부터 얻는 피드백, 그 행동을 취했을 때 다음 상태로 전이될 확률분포, 시간에 따른 현재의 보상의 중요도를 의미합니다. 강화학습 에이전트는 보통 MDP라는 정해진 틀 안에서 환경과 상호작용하며 장기적으로 봤을때의 누적 보상을 최대화하는 정책을 찾아가는 학습을 합니다.
이 때 가치함수와 Q함수의 개념이 등장하는데 가치함수는 주어진 정책을 따를 때 s인 상태에서 앞으로 얻을 수 있는 누적되는 보상의 기댓값을 의미하며, Q함수는 s인 상태에서 특정 행동 a를 취했을 때 얻을 수 있는 누적되는 보상의 기댓값입니다. 둘의 차이는 “현재의 상황이 얼마나 좋은 상황인지 vs 현재의 상황에서 어떤 행동을 하는것이 얼마나 좋은 것인지”에 대한 차이라고 생각하시면 될 것 같습니다.
Q-Learning

Q-learning은 앞서 말한 Q함수를 학습하고 MDP상에서 최적의 정책을 찾아내는 강화학습 알고리즘 입니다. 에이전트가 t일때의 상태 s_t에서 특정 행동 a_t를 취하고 나서 r_t+1과 s_t+1을 얻고, 벨만 최적 방정식에 기반한 업데이트를 진행합니다. 실제로 행동을 하며 얻은 보상들과 다음 상태에서의 최적의 추정을 계속 반복하며 Q(s,a)에 대한 표를 채워나가면서 최적의 정책을 만들어 갑니다. Q-learning은 MDP모델을 모르는 상태에서도 학습이 가능한 model-free 학습 방법이고, 이산적인 상태와 행동을 가지는 문제를 해결할 때 사용할 수 있습니다. 다만 상태나 행동이 연속적이면 Q값을 모든 경우에 대해 실행하고 표로 저장해야 하는데, 이는 불가능하기 때문에 연속적인 공간에서의 문제를 해결하기가 매우 어려웠습니다. 뿐만 아니라 Q-learning의 업데이트 수식의 특성상 Q값이 과대평가되는 문제또한 존재했습니다. 이를 위해 Double Q-learning과 같은 두개의 Q값을 통한 교차 검증 느낌의 업데이트하는 기법이 등장하기도 했지만 여전히 연속적인, 복잡한 문제를 해결할 수 없는 문제가 있었습니다.
DQN (Deep Q-Network)
더 복잡한 상황에서 최적의 Q-learning을 진행하기 위해 DeepMind가 DQN을 발표했습니다. Q-learning에 신경망을 접목하는 구조로 접근해서, Q함수를 신경망을 통해 근사하는 식으로 Q-Network를 통해 어떠한 상태s에 대해 각 행동별 Q값을 출력하는 함수로 표현했습니다. 해당 방법을 통해 학습을 진행할 때 학습이 불안정해지는 문제가 있었는데, 이를 샘플들을 저장해 두었다가 재사용하는 Experience Replay와 업데이트 주기가 느린 Q값을 계산하는데 쓰이는 Target Q-Network를 사용해 해결했습니다. 다만 아직도 행동 공간이 이산형인 문제에만 적용이 가능하기 때문에, 연속적인 행동을 학습할 수는 없었습니다. 또한 Q함수를 신경망을 통해 근사한다는 점을 제외하고는 기존의 Q-learning의 문제점들을 그대로 가져갔기 때문에 Q값이 과대평가되는 문제도 남아있었습니다. 여기서 짚고 넘어가야 할 점은 Q-learning과 DQN 모두 value-based 방법으로 정책 자체를 학습하는 것이 아니고 어떤 상태에서 어떤 행동을 하면 장기적으로 어떤 점수를 받을 수 있는지를 다 평가하고 업데이트 해둔 뒤에, 정책은 매 상황에서 최고의 잠재적인 점수를 따라 행동을 선택하는 방식이었습니다. 정책 자체를 네트워크로 직접 표현하지는 않기 때문에 로봇을 움직이는 연속적인 제어를 풀어야하는 문제는 접근이 불가능합니다. 이산적이지 않은 환경에 대한 점수를 다 계산할 수는 없기 때문입니다.
Policy Gradient
연속적인 공간에서 적용할 수 없다는 한계를 지닌 Q-learning의 본질적인 문제를 해결하기 위해서 정책 자체를 직접 학습하는 policy gradient 방법이 등장합니다. 정책 pi자체를 신경망을 통해 파라미터화 해서 정책 자체를 업데이트 하며 최적의 정책을 찾는 방법입니다. 특정 상태에 대해 취할 수 있는 행동에 대한 확률 분포를 신경망으로 표현해 에피소드의 누적 보상이 증가하는 방향으로 신경망을 조절하는 방법으로, 아래와 같은 식으로 나타내는 J를 최대화하는 theta를 찾는다고 생각하시면 됩니다.
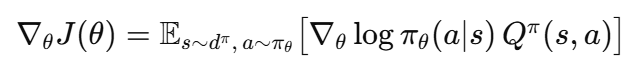
에피소드 상에서 Q(s,a)가 큰 행동을 할 확률을 높히고, 낮은 행동을 할 확률을 낮추는 과정을 수학적으로 표현한 식입니다. 이러한 방법은 정책 자체를 직접 다룰 수 있기 때문에 연속적인 환경에서의 문제도 자연스럽게 다룰 수 있게 됩니다. 로봇으로 예시를 들면 로봇의 관절들의 속도를 어떻게 출력해야 할지를 확률분포로 나타낼 수 있습니다. 또한 초기에는 무작위에 가까운 행동을 하지만 점점 확률 분포가 수렴하면서 자연스럽게 초기에 탐험을 많이하고, 수렴할수록 탐험이 적어지는 효과도 얻을 수 있습니다. 또한 정책 자체를 학습하기 때문에 정책의 변화를 추적하기도 용이합니다.

조금 더 자세히 알아보자면 학습은 에피소드를 단위로 진행됩니다. 에피소드가 시작되면 에이전트는 첫 번째 상태를 관측하고, 정책 네트워크(Actor)를 통해 행동을 선택합니다. 정책은 현재 상태를 입력받아 가능한 행동에 대한 확률 분포를 출력하고, 그 중 하나가 실제 행동으로 샘플링되어 환경에 전달됩니다.
환경은 이 행동을 받아 다음 상태, 보상, 그리고 종료 여부를 반환합니다. 이때 상태, 행동, 보상으로 이루어진 경험이 메모리에 저장되며, 한 에피소드 동안의 모든 경험이 축적됩니다. 에피소드가 종료되면 각 시점마다의 Rewards-to-Go가 계산됩니다. Rewards-to-Go는 특정 시점 이후부터 에피소드가 끝날 때까지 받을 수 있는 모든 보상의 합으로, 현재 보상과 미래 보상을 할인율을 곱해 더한 값으로 표현됩니다. 이는 해당 시점의 행동이 장기적으로 얼마나 좋은 결과를 가져왔는지를 나타내는 지표입니다. 실제 reward를 알 수는 없기 때문에 에피소드를 샘플링해서 G(s_t)로 근사해서 사용하는 구조입니다.
이 정보를 바탕으로 정책 그래디언트가 계산됩니다. 구체적으로, 선택된 행동의 로그 확률에 Rewards-to-Go를 곱한 값이 기울기 신호가 되어 정책 파라미터를 조정합니다. 좋은 결과로 이어진 행동은 확률을 더 높이고, 나쁜 결과로 이어진 행동은 확률을 줄이는 방향으로 학습이 이루어집니다. 마지막으로, 누적된 그래디언트에 학습률을 곱해 정책 파라미터를 업데이트하면서 학습이 마무리됩니다.
이 과정을 반복하면 정책은 점차 좋은 행동의 확률을 높이고 나쁜 행동의 확률을 줄여가며 개선됩니다. 직관적으로는 에피소드 전체를 복기하면서, “이 행동이 최종 성적에 얼마나 기여했는가”를 평가하고, 그에 따라 행동 습관을 고쳐나가는 과정이라 할 수 있습니다. 결국 Policy Gradient는 샘플링한 에피소드를 이용해 J(theta)의 기울기를 근사적으로 계산하고, 정책을 그 방향으로 개선하면서 시행착오 속에서 좋은 습관을 강화하는 방식으로 정책을 학습해 나갑니다.
하지만 policy gradient는 분산이 높다는 단점이 있습니다. 그래디언트를 추정해나갈때의 샘플 효율이 낮고 분산이 크기 때문에 수렴시키기 위해 정말 많은 에피소드가 필요합니다. 에피소드에서 얻은 샘플들을 진행하는 동안 모아서 에피소드가 끝나고 파라미터를 한 번에 업데이트 하기 때문에, 어떤 행동이 실제로 기여를 했는지에 대한 분산이 커서 수렴 자체가 불안정하고 느립니다. 그래도 연속적인 문제를 해결할 수 있는 발판이 마련됐기 때문에 강화학습의 발전 방향이 이러한 분산이 큰 문제를 완화하는 방향으로 진행됐다고 합니다.
Baseline and Advantage
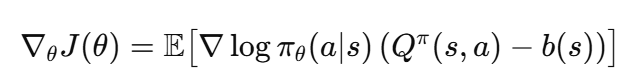
Policy gradient의 분산이 크다는 문제를 해결하기 위해 variance reduction이라는 연구 주제가 떠올랐고, 이를 해결하기 위해 baseline이라는 개념이 등장합니다. 수학적으로 위에서 보여드린 식의 우변에 기댓값은 Q^pi(s,a)에 상수값을 더하거나 빼도 같은 값이 나오게 됩니다. 따라서 위 식과 같은 b(s)라는 baseline함수를 도입합니다. 이를 통해서 Q(s,a)의 값을 그대로 받는것이 아니라 상대적으로 얼마나 이득인지로 받게 됩니다. 이 때 기준이 되는 b(s)를 V^pi(s)로 설정해서 해당 행동이 평균보다 얼마나 나은지, 얼마나 못한지를 얻게 됩니다. V^pi – b(s) = A^pi (Advantage)로 정의하고 정책 그래디언트 공식을 아래와 같이 표현합니다.
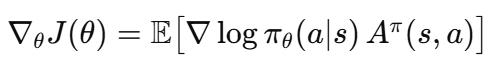
Advantage 개념을 사용하면서 분산을 크게 줄이고 평균대비 많이 높은 점수를 받은 경우가 정책 업데이트에 더 큰 영향을 주게 됩니다. 예를들어 똑같이 100이라는 score가 있을 때 100, 90, 50, 80을 받은 경우와 100, 50, 40, 50을 받은 경우 후자에 더 높은 점수를 받는 구조입니다.
여기서의 문제가 그렇다면 V^pi는 어떻게 알 수 있느냐? 입니다. 이를 위해 V^pi를 추정하는 모델을 함께 학습시키고, 이렇게 정책을 학습시키면서 value를 추정하는 다른 모델을 학습시키자는 흐름이 actor-critic 방법들입니다.
Actor-Critic
Actor-Critic은 이름 그대로 액션을 취하는 actor와 비평가 critic을 두고 각각 정책과 가치함수를 학습시키는 방법입니다. Actor는 정책을 생성해 현재 상태에서 어떤 행동을 취할지를 결정하고, Critic은 가치함수를 추정해 Actor가 생성한 행동에 대한 피드백을 제공합니다. 위에서 나온 advantage를 추정한다고 생각하시면 될 것 같습니다. Critic이 V^pi를 근사하도록 학습하면서 Actor가 critic에서 얻은 advantage를 통해 정책을 업데이트 하는 흐름으로 baseline을 자동으로 학습하면서 정책까지 최적화를 진행할 수 있습니다. 따라서 policy gradient의 문제를 효율적으로 해결해 나갈 수 있기 때문에 현대의 Deep RL은 대부분 Actor-Critic 구조를 갖습니다.
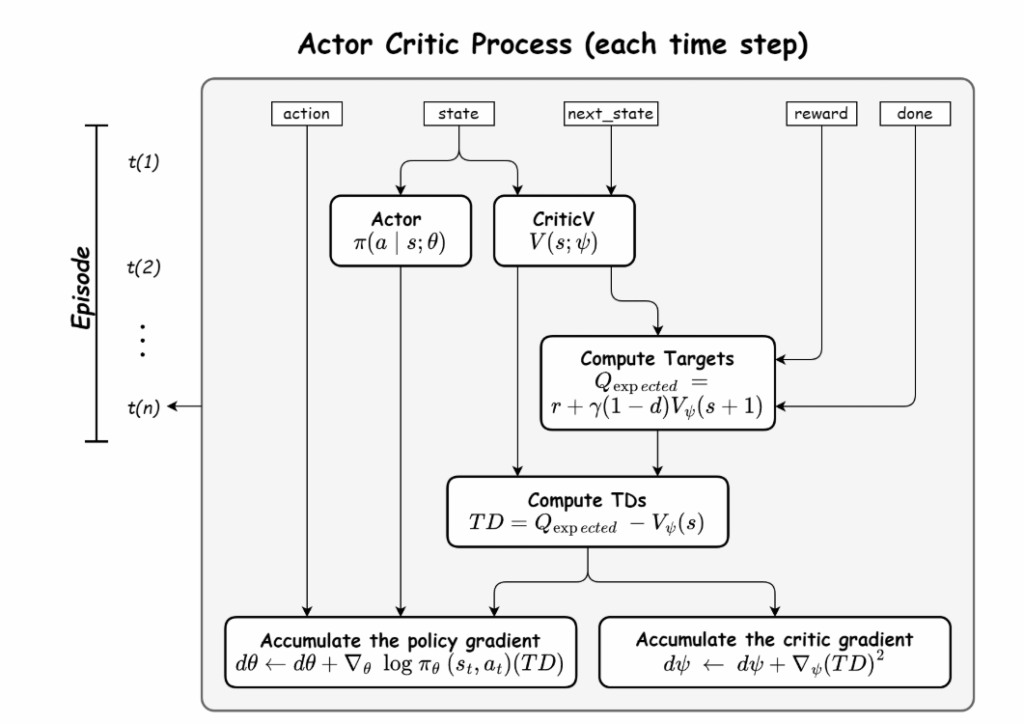
학습 과정은 다음과 같이 흘러갑니다. 먼저 에이전트가 환경으로부터 상태를 관측하면 Actor는 정책에 따라 행동을 선택합니다. 이 행동이 환경에 적용되면 보상, 다음 상태, 종료 여부가 반환되고 Critic은 현재 상태와 다음 상태의 가치를 추정합니다. 이후 목표값은 실제 보상과 다음 상태의 가치로 계산되며, 현재 Critic의 예측과의 차이를 TD 오차라고 부릅니다. 이 TD 오차가 actor critic 학습의 핵심 신호가 됩니다. Actor는 TD 오차를 활용하여 정책 자체를 업데이트합니다. 만약 TD 오차가 양수라면, 평균보다 더 좋은 결과가 나왔다는 것이기 때문에 해당 행동의 확률을 높이고, 음수라면 확률을 줄이는 식으로 학습합니다. Critic은 TD 오차의 제곱을 최소화하도록 학습하여 예측값을 점점 더 V^pi에 가깝게 학습합니다.
Actor-Critic 알고리즘은 강화학습의 발전사에서 중요한 전환점으로 자리 잡았습니다. 단순히 정책을 직접 학습하는 Policy Gradient는 분산이 크고 샘플 효율이 낮다는 단점이 있었고, Q-learning과 같은 값 기반 방법은 연속적인 행동을 다루는 데 한계가 있었습니다. Actor-Critic은 이 두 접근을 결합하여 Critic이 baseline 역할을 하도록 함으로써 정책 그래디언트의 분산을 줄이고, 동시에 연속 제어 문제에도 자연스럽게 적용할 수 있게 만들었습니다. Critic이 제공하는 가치 추정은 일종의 “평균적인 기준선”이 되어, Actor가 단순히 원점수(Q값)에 의존하지 않고, 평균 대비 얼마나 더 나은지를 학습할 수 있게 합니다. 이로 인해 학습 과정이 훨씬 안정적이고 효율적으로 바뀌게 됩니다.
다만 Actor-Critic 구조도 두개의 네트워크를 동시에 학습시키기 때문에 많은 하이퍼 파라미터 튜닝이 필요하고 Critic이 정확한 가치를 추정하지 못 하는 순간 actor가 잘못된 정책을 업데이트하게 되는 문제가 있습니다. Critic이 특정 상태를 과대평가하거나 과소평가하면 엉뚱한 행동이 강화되기 시작하면서 policy collapse 현상이 일어날 수도 있고, 정책이 수렴하기 까지 굉장히 많은 데이터가 필요하기 때문에 안정성, 효율성 문제가 여전히 남아있었습니다. 이를 위해 정책이 한 번에 크게 변화하지 않도록 보장하는 기법이 연구되기 시작하고 TRPO라는 알고리즘이 등장했습니다. 다만 TRPO는 굉장히 수학적으로 복잡하고 실제로 구현도 매우 복잡해 구현체도 거의 없다고 합니다.. 그래도 현재 대부분 사용되는 PPO의 Trust Region이라는 개념을 처음 도입하고 PPO도 TRPO를 clipping 해서 단순화한 느낌이라고 하니 굉장히 중요한 것 같습니다. Policy collapse 현상을 막기위해 현재의 policy와 업데이트 후의 policy의 KL divergence를 임계값 아래로 내려서 급격한 변화를 막으며 한 방향으로 효율적이고 안정적인 학습이 가능한 알고리즘인데,, 아직 제대로 숙지가 안돼서 TRPO와 PPO는 다음주 리뷰로 작성하도록 하겠습니다 하하..
강화학습을 공부하고 나서 손놓고 있다가 다시 공부하려니 복습을 쭉 하고 이후 Actor Critic, TRPO, PPO를 공부하고 리뷰를 작성해야겠다 생각했는데 생각보다 잊어버린 개념이 많고 policy gradient 방법론부터 공부하려니 시간이 많이 걸려서 2부로 나눠야 할 것 같습니다..
안녕하세요. 강화학습 공부해야겠다라는 생각만 하고 바쁘다는 핑계로 전혀 안하고 있었는데, 이렇게 공부하신 내용을 정리하는 글을 읽게 되어서 정말 좋았네요.
비록 해당 글에서 수학적으로는 아직 충분히 이해할만한 공부량이 부족했고 또 리뷰에 담기에도 내용이 방대해서 글 작성시에는 개념적 흐름 위주로 작성해주셨다고 하긴 했지만, 그럼에도 궁금한게 있어 질문 드립니다.
Q-learning 관련하여 작성해주신 글 내용에 다음과 같은 내용이 있습니다. “뿐만 아니라 Q-learning의 업데이트 수식의 특성상 Q값이 과대평가되는 문제또한 존재했습니다” 여기서 Q-learning의 업데이트 수식이 전혀 언급되지 않다보니 왜 과대평가 된다는 것인지 이유를 전혀 모르겠어서요. 그리고 또 과대평가 된다는 말의 의미도 사실 약간 이해가 될 듯 하면서도 애매하게 모르겠네요. 과대평가 된다는 말은 어떤 상태에 대해서 선택할 수 있는 action이 여럿 존재하는데 정답에 해당하는 action이 있음에도 불구하고 잘못된 action에 대해 reward 값을 크게 계산하는 문제를 말하는건가요? 약간 딥러닝으로 치면 local minia와 global minima 같은 느낌인지요..?
그리고 Actor-Critic 알고리즘까지 읽다보니 제가 느꼈을 때 Q-learning과 같은 예전 방법들은 완전 초창기 강화학습의 방식이고 현재는 이제 전혀 안쓰는? 그런 방법론이라고 이해하면 되는 걸까요? 즉 최근 action 연구들에서 가져다쓰는? 강화학습 방식은 다음번에 작성해주실 TPRO, PPO 알고리즘들이고 오늘 소개해주신 내용들은 그냥 약간 강화학습의 발전사 느낌?으로 이해하고 현재의 강화학습에서는 잘 안쓰는 개념이라고 생각하면 되는지 여쭤봅니다.
감사합니다.
안녕하세요 정민님 리뷰 읽어주셔서 감사합니다.
수식을 적고 설명하는 순간 너무 복잡해질것 같아 최대한 컨셉만 담으려다보니 너무 생략이 됐네요 하하…
Q-learning 정책이 이상적으로 학습됐다면 Q(s,a)가 모든 상황s에서 항상 최고의 보상을 취할 수 있는 액션 a를 선택하게 됩니다. 다시말하면 특정 상황s에서 최고의 보상 a를 택할 확률이 가장 큽니다.
학습 과정은 특정 상황 s_t에서 가능한 액션중 s_t+1에서 보상이 가장 큰 행동을 취할 확률을 높히는 방향으로 진행되는데, 이 때 s_t+1에서의 보상을 추정하는 과정에서 모델이 덜 학습돼서 실제로는 하면 안되는 행동의 보상을 가장 크게 예측할경우 잘못된 방향으로 학습을 진행하게 됩니다.
local minima보다 더 심하게 정답인 액션을 취할 수 있는 확률분포 자체가 이상한 방향으로 팍 튀어버린다고 이해하시면 될 것 같습니다.
두번째 질문에 대한 답은 일단 그렇다고 할 수 있을 것 같습니다. 퍼셉트론부터 시작해서 현재는 뿌리는 같지만(?) 굉장히 발전된 모델들을 활용하는것 처럼 Q-learning이라는 강화학습의 가장 기본적인 알고리즘에서부터 각종 문제점들을 해결하고 새로운 요소들을 추가하면서 최근에는 PPO, TRPO와 같은 actor critic 모델들을 위주로 연구가 진행되고 있고, LLM 같은 경우는 더 발전된 GRPO (actor critic 구조가 가지는 LLM reward 계산의 어려움을 해소했다고 합니다)와 같은 방법들도 등장했습니다.
안녕하세요 영규님. 좋은 리뷰 감사합니다.
강화학습 이름만 많이 들어봤지 이렇게 글을 읽은적은 처음이라 저한테는 아직 어려운 것 같습니다.
읽다가 기본적인 부분에서 궁금증이 생겨 이렇게 질문드립니다.
제가 이해하기로는 Q함수는 결국 장기적으로 봤을 때의 기댓값 즉 goal에 도착했을 때 agent가 얻을 수 있는 총 reward가 높아지도록 설계되는 함수로 이해했습니다. 그리고 기존의 Q-learning 방식은 행동이 연속적일 때 모든 행동을 취하고 표로 저장해야 하므로 연속적인 공간에서 문제를 해결하기가 어렵다고 이해했습니다. 따라서 DQN이 등장해서 신경망을 사용해서 Q함수를 근사한다고 하셨습니다. 이때 궁금한점은 이때 Q함수의 loss function이 궁금합니다. 그리고 제가 잘 몰라서 MDP를 모르는 상태에서 Q를 학습한다는게 잘 이해가 가지가 않습니다.. MDP가 주어져야 어떤 행동을 취했을 때 최종 reward가 가장 높은지 알 수 있는게 아닌가요?? MDP를 모른다고 가정하면 그냥 아무것도 없이 주어지는데 여기서 agent가 action을 취하면서 하나하나 학습하는건가요?
감사합니다.
안녕하세요 인하님 리뷰 읽어주셔서 감사합니다.
일단 Q-learning과 DQN으로의 접근은 이해하신 부분이 맞습니다. DQN의 loss function의 경우는 모델이 예측한 다음 상태의 보상과 액션을 취해서 다음 상태로 넘어갔을때 얻은 실제 보상과의 MSE로 사용합니다. 또 MDP가 주어져있지 않다는 것은, 게임이나 로봇환경과 같이 모든 환경에 대해 보상함수를 정확히 정의할 수 없는 경우를 의미합니다. 이런 경우에는 에이전트가 환경과 직접 상호작용한 결과를 데이터로 수집하고, 샘플을 만들어 이를 바탕으로 학습을 진행합니다. 이렇게 MDP 모델을 모를때 직접 시행착오를 겪으며 학습하는 방법을 model-free 방법이라고 합니다.
영규님 좋은 리뷰 감사합니다.
DQN의 경우 Q-Table 부분을 신경망으로 근사하여 어찌보면 Q값을 구하는 함수를 생성한 것이라 생각하였는데, 행동 a에 대한 value라 이산적인 상태와 행동에만 적절한 것이라 이해하면 될까요?
‘Q-learning의 업데이트 수식의 특성상 Q값이 과대평가되는 문제가 존재한다’고 하셨는데, 혹시 이유에 대해 설명해주실 수 있을까요?
‘단순히 정책을 직접 학습하는 Policy Gradient는 분산이 크고 샘플 효율이 낮다는 단점이 있다’고 하셨는데, 샘플 효율이 낮다는 것에 대하여 추가로 설명해주실 수 있을까요?
안녕하세요 승현님 리뷰 읽어주셔서 감사합니다.
우선 DQN이 이산적인 행동에만 적절한 것인가?에 대한 질문은 맞다고 대답할 수 있을 것 같습니다. DQN 네트워크의 구조가 출력층에서 가능한 행동의 개수만큼의 뉴런들이 각 행동의 Q값을 출력해서 max Q(s,a)를 구하는 구조입니다. 따라서 행동이 연속적인 경우에는 가능한 행동이 무한대이기 때문에 DQN으로 풀 수 없습니다. 그래서 Policy Gradient 방법이 등장해서 actor 자체의 action 확률 분포를 업데이트해가는 식으로 학습합니다.
Q-learning의 과대평가와 같은 경우는 정민님 댓글에도 설명했듯이 Q값 추정이 부정확한 초기 단계에서 무조건 max값을 취하면서 업데이트 하는 수식 때문에 올바르지 못한 액션에 대한 잘못된 학습을 진행할 수 있습니다.
Policy Gradient같은 경우는 on policy 정책이라 데이터가 현재의 정책에서만 유효하고 업데이트가 될 때마다 에피소드가 끝날때까지 다시 경험을 수집해서 한 번에 업데이트를 하기 때문에 노이즈가 많이 중간중간 들어갈 수 있어서 샘플 효율이 낮고 분산이 큽니다.
영규님, 좋은 리뷰 감사합니다. 이제 점점 비전 분야에도 강화학습이 사용되는 영역이 넓어지는 느낌이라 언젠가 한번 제대로 다시 정리해봐야겠다는 생각을 막연히 하고 있었는데, X-Review로 작성해주시니 좋네요. 이후 TRPO와 PPO 정리글도 기대하겠습니다.
policy gradient 부분에 질문이 있는데요, 정책 pi를 신경망으로 모델링해 policy를 학습하는 과정에서 ‘특정 상태에 대해 취할 수 있는 행동에 대한 확률 분포를 신경망으로 표현해 에피소드의 누적 보상이 증가하는 방향으로 신경망을 조절하는 방법’이 구체적으로 어떻게 수행되는지 궁금합니다. 수식만으로는 이해하기 좀 어렵네요. 이에 대해 부연설명 해주시면 감사하겠습니다.
감사합니다.
안녕하세요 재연님 리뷰 읽어주셔서 감사합니다.
TRPO와 PPO는 생각보다 좀 빡세서 공부를 더 하고 써야할 것 같긴 합니다,, ㅋㅋㅋ
Policy Gradient의 학습 과정을 조금 더 부연설명 하자면 일단 신경망 자체는 입력으로 상태 s가 들어오고 출력으로 가능한 행동의 확률분포를 출력합니다. 즉, 모델 자체가 하는 일은 특정 상태에서 어떤 행동을 얼마나 자주 취하는가? 에 대한 분포를 예측하는겁니다. 학습시에는 특정 상황에서 s를 입력하고 확률분포를 따라 행동을 해가면서 에피소드를 진행합니다. 에피소드는 환경이 종료되는 특정 조건을 만족할 때까지 진행되는데, 끝날때까지의 (s, a, r)을 수집합니다. 에피소드가 끝나고나면 모아둔 데이터들로 부터 과거의 각 시점에서의 보상을 계산하고, 특정 시점에 어떤 행동이 장기적으로 좋은 행동이었나?를 계산해서 각 s마다의 확률분포를 업데이트합니다.
너무 내용을 압축적으로 담으려다보니 내용이 다 애매하게 담긴것 같습니다,, 하하
안녕하세요 영규님, 좋은 리뷰 감사합니다!
이전에 강화학습 기초를 얕게나마 공부했던 적이 있는데, 그때 이해가 안 됐거나 까먹은 점들이 많은 것 같습니다. 그런데 영규님께서 이렇게 흐름을 정리해주시니 정말 도움이 많이 되었습니다.
정리하자면, value-based 방식(Q-learning, DQN)은 연속적인 공간에서 풀 수 없다는 문제가 있었고, policy-based 방식(policy gradient)은 분산이 크며 에피소드가 끝나야만 업데이트를 할 수 있는 문제가 있었습니다. 이를 보완하는 actor-critic 방식에서는 critic이 벨만 기대방정식을 사용하여 가치함수를 예측하고 actor가 policy를 업데이트 함으로써 이 문제들을 해결했다는 내용으로 이해했습니다.
1. actor-critic에서 사용하는 TD target이 분산은 낮지만 편향이 존재한다고 알고 있습니다. 이런 편향이 policy collapse를 유발하는 건가요? policy collapse를 유발하는 요인이 궁금합니다.
2. critic의 추정 오류가 연속적인 행동 공간일 때 더 치명적일까요? 선택 가능한 행동이 무한하니 그럴 것 같다고 생각은 되는데 영규님의 의견이 궁금합니다.
감사합니다.