안녕하세요. 지난주에 이어 이번에도 토큰 프루닝(token pruning) 관련 논문을 들고 왔습니다. 오늘 소개해 드릴 논문은 2021년 NeurIPS에 발표된 DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification입니다.
해당 논문은 Object Detection이 아닌 Image Classification 태스크에서 Vision Transformer(ViT)의 효율성을 높이기 위한 토큰 프루닝 기법을 다룹니다. Object Detection 분야에서 ViT의 토큰 프루닝을 다룬 연구가 아직 많지 않아, 인용 수가 많고 가장 기반이 되는 이 논문을 선택하게 되었습니다.
특히, 제가 직간접적으로 접했던 많은 후속 연구들에서 DynamicViT를 주요 벤치마킹 모델로 삼아 성능을 비교하는 경우가 많았습니다. 그래서 이번 기회에 읽어보고 리뷰로 들고오게 되었습니다.
바로 리뷰하도록 하겠습니다.
Introduction
토큰 프루닝, 경량화, 최적화는 항상 모티베이션은 대부분 동일한 것 같습니다.저자들은 먼저 컴퓨터 비전 분야에서 CNN의 시대가 지나고 Transformer가 대세가 되고 있다는 점을 짚으면서 이야기를 시작합니다. 그런데 CNN 시절에도 모델을 더 빠르고 가볍게 만들기 위한 노력이 많았듯이, 이제는 Vision Transformer(ViT)를 어떻게 하면 더 효율적으로 만들 수 있을까 하는 것이 중요한 과제가 되었다고 말합니다.
일단 CNN에서는 보통 중요도가 낮은 필터를 pruning하는 방식을 많이 썼다고합니다. 반면에 ViT는 이미지를 여러 개의 독립적인 패치(토큰)로 나눠 처리하기 때문에 프루닝을 하는데 있어서 CNN과는 다르게 바로 덜 중요한 토큰 자체를 버리는 방식으로 접근이 가능해집니다.
이게 가능한 결정적인 이유는 ViT의 self-attention 메커니즘이 가변적인 길이의 토큰 시퀀스를 처리할 수 있기 때문입니다. 디멘젼을 건들지 않는 이상 일부 토큰이 없어져도 구조적으로 문제가 생기지 않기 때문이라고 보시면 됩니다. 반면에 CNN은 정해진 격자 위에서 연산하기 때문에 일부 픽셀을 뺀다고 해서 계산이 빨라지지는 않는다는 점을 명확히 대조해서 설명합니다. 저자는 CNN에서 픽셀 일부를 제거한다고 해도 합성곱 연산은 여전히 고정된 이웃 구조를 사용하므로 병렬 연산을 통한 가속이 어렵다고 합니다.
그래서 ViT의 self-attention 메커니즘이 가변적인 길이의 토큰 시퀀스를 처리할 수 있다는 특성을 활용해, 아래 그림 처럼 CNN이 계층적으로 다운샘플링하는 것처럼 토큰을 점진적으로 제거해보자는 아이디어를 구현한 것이 바로 DynamicViT라고 보시면 좋을 것 같습니다.
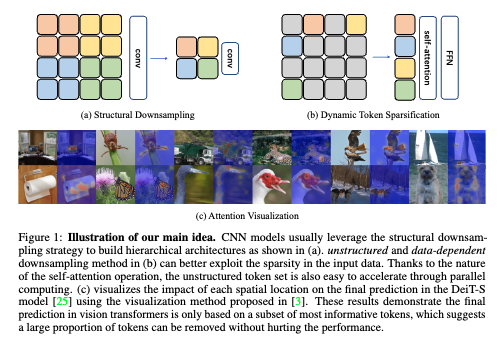
서두 내용만 들으시면 트랜스포머는 당연히 가변길이 토큰 시퀀스를 처리할 수 있고 이거를 토큰 프루닝에 활용하는 것은 당연한게 아닌가? 라는 생각이 들 수 있습니다. 최근의 토큰 프루닝 관련 연구들은 이 특성을 당연한 전제 조건으로 여기고 토큰 프루닝을 적용해 단순히 ViT의 효율성을 높이는 데 집중합니다. 하지만 이 논문이 2021년에 발표되었다는 점을 감안하면 당시에는 ViT의 근본적인 메커니즘을 CNN의 효율적인 계층 구조와 연결하여 토큰 프루닝이라는 새로운 가속화 방향을 처음으로 구체화했다는 점에서 그 당시에는 새로운 접근이지 않았나 싶습니다.
다시 돌아워서 DynamicViT의 핵심 동작 방식에 대해 간단하게 설명하고 넘어가자면, 먼저 가벼운 예측 모듈이 이미지마다 어떤 토큰이 덜 중요한지 판단해서 마스크를 만들고, 이 모듈을 여러 레이어에 걸쳐 배치해 점진적, 계층적으로 토큰을 제거합니다. 학습 시에는 Gumbel-Softmax와 Attention Masking이라는 똑똑한 장치를 써서 end-to-end 학습과 병렬 처리 문제를 해결합니다.
위 동작 방식을 들었을 때 지금까지 리뷰했던 SViT, ToSA, HiRED 에서 적용하는 프루닝 방식과 크게 다를게 없어보입니다. 특히 SViT 같은 경우에는 태스크만 다를 뿐 정말 비슷하다고 느껴집니다. 결국 해당 논문이 제가 서베이했던 논문중에서 토큰 프루닝과 관련해서 인용수가 가장 많았던 것으로 기억하는데 그 이유가 여기있지 않았나 싶습니다.
이따가 실험파트에서 다룰 예정이지만 결과적으로 토큰을 66%나 버렸는데도 GFLOPs은 최대 37% 줄고 처리 속도는 40%나 빨라졌는데, 정확도 하락은 0.5% 이내였다는 점을 강조하면서 이 연구가 ViT에서 토큰 프루닝을 통해 연산 효율을 크게 높일 수 있다는 가능성을 보여줍니다.
일단 related work 관련 부분인데요 해당 부분에선 DynamicViT가 어떤 연구들 위에 서 있고, 또 어떤 점에서 새로운지에 대해서 설명하고 넘어가도록 하겠습니다. 일단 Vision Transformers의 흐름에 대해서 언급을 하고 넘어가겠습니다. NLP에서 시작된 Transformer가 DETR를 거쳐 ViT로 이미지 분류에 성공적으로 안착했고, DeiT 덕분에 대규모 데이터 없이도 학습이 가능해졌다는 흐름을 설명합니다. 저자는 여기서 핵심이 대부분 이런 모델이 이미지를 패치로 나누는 공통점을 가지고, 바로 이 지점이 자신들의 토큰 sparsification(프루닝을 sparsification이라고도 표현합니다.) 아이디어가 적용될 수 있는 기반이라고 말합니다. 이후 등장한 모델 가속화, 경량화 등 연구들을 언급합니다. 양자화, 지식 증류 등 여러 기법이 있지만, 저자는 대부분 NLP Transformer에 집중되어 있거나 ViT의 근본적인 문제인 너무 많은 토큰 수를 직접적으로 다루지는 못했다고 지적합니다. 저자들이 가장 강조하는 차별점은 기존 CNN 가속화가 뉴런이나 필터를 프루닝했다면, DynamicViT는 정보량이 적은 이미지 패치, 즉 ‘토큰’을 프루닝한다는 점에서 완전히 새로운 접근이다 라는 것을 차별점으로 둡니다.
결론적으로 저자들은 ViT는 토큰 기반이라 CNN과는 다른 방식의 가속화가 가능하고, 우리는 이미지 데이터의 특성을 활용해 불필요한 토큰을 동적으로 제거하는 새로운 방법을 제안한다! 라는 것을 해당 논문을 통해서 보여준다고 생각하시면 좋을 것 같습니다.
Method
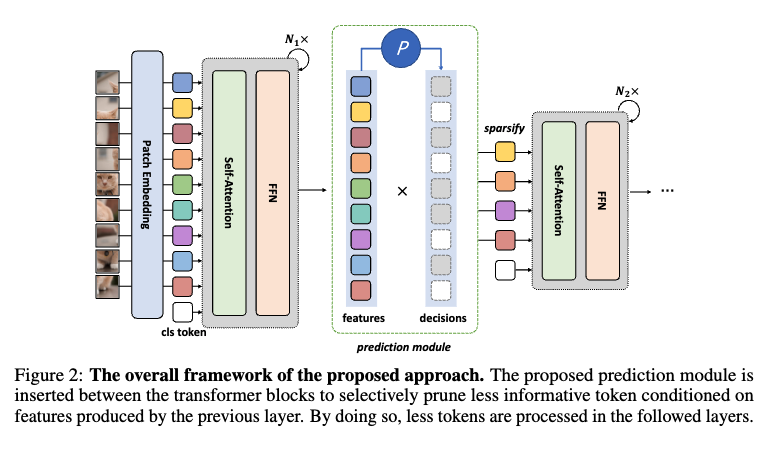
DynamicViT의 핵심은 ViT의 여러 계층 사이에 삽입된 가벼운 예측 모듈입니다. 이 것을 보통 게이팅 모듈이라고 합니다. 이 모듈의 역할은 각 토큰을 보고 이 토큰을 계속 가져갈지 아니면 버릴지를 결정하는 것이라고 생각하시면 좋을 것 같습니다. 해당 토큰을 keep할지 drop할지는 아래의 2가지 정보를 보고 판단하게 됩니다.
Local Feature: 각 토큰 x가 가진 고유의 정보를 MLP에 통과시켜 얻습니다.
z_{\text{local}} = \text{MLP}(x) \in \mathbb{R}^{N \times C'}
Global Feature: 현재까지 살아남은 모든 토큰들의 정보를 평균 내어 만든, 이미지 전체의 맥락 정보입니다. 여기서 \hat{D}는 현재까지의 토큰 유지 여부를 나타내는 마스크(1이면 유지, 0이면 제거)입니다.
z_{\text{global}} = \text{Agg}(\text{MLP}(x), \hat{D}) \in \mathbb{R}^{C'}
이렇게 계산된 개별 토큰의 정보(z_local)와 전체 맥락 정보(z_global)를 합친 뒤 , 또 다른 MLP와 Softmax 함수를 통과시켜 각 토큰을 유지할 확률(πi,1)과 버릴 확률(πi,0)을 최종적으로 계산합니다.
\pi = \text{Softmax}(\text{MLP}(z)) \in \mathbb{R}^{N \times 2}이 확률에 따라 새로운 결정 마스크 D가 정해지면, 기존의 누적 마스크 \hat{D}에 원소별 곱을 해서 업데이트합니다.
\hat{D} \leftarrow \hat{D} \odot D이는 한 번 버려진(D^i=0)토큰은 다시 사용되지 않는 다는 것을 의미합니다.
위처럼 이렇게 개별 토큰의 정보와 전체적인 맥락을 함께 고려하기 때문에 더 정확한 판단을 내릴 수 있게됩니다.
또한, 토큰 제거는 한 번에 이루어지는 것이 아니라 계층적으로, 그리고 점진적으로수행됩니다. 예를 들어 12개의 레이어가 있다면 4, 7, 10번째 레이어를 통과하기 전에 각각 토큰을 솎아내는 식으로 동작한다고 보시면 됩니다. 이렇게 하면 모델이 깊어지면서 조금 더 정제된 정보를 바탕으로 판단할 수 있게 되고, 한 번 버려진 토큰은 이후 계산에서 완전히 없애버리기 떄문에 연산 효율도 챙길 수 있게됩니다.
근데 이러한 아이디어를 실제로 학습을 시키게 되면 발생하는 두가지 문제점은 저자는 언급합니다.
첫 번째는 미분 불가능 문제입니다. 토큰을 ‘유지’ 또는 ‘제거’하는 결정은 0 아니면 1로 딱 떨어지기 때문에 미분이 불가능하고, 이는 모델 전체를 한 번에 학습시키는 end-to-end 방식을 방해한다고 합니다. 그래서 저자들은 이 문제를 해결하기 위해 Gumbel-Softmax라는 기법을 도입하고 이 기법을 통해 미분 가능한 방식으로 샘플링을 흉내 낼 수 있어, 예측 모듈까지 역전파가 가능해집니다.
두 번째는 병렬 처리 문제입니다. 이미지마다 버려지는 토큰 수가 제각각이면 GPU가 효율적으로 병렬 연산을 처리하기 어렵다는 문제가 있습니다. (앞서 트랜스포머의 토큰 시퀀스의 길이는 가변적이어도 된다라고 말씀드렸지만 병렬처리를 하기위해서는 배치 단위에서는 시퀀스의 길이는 동일해야합니다.) 이 문제를 해결하기 위해 저자들이 고안한 것이 바로 어텐션 마스킹(Attention Masking)입니다. 학습 중에는 토큰을 실제로 제거하지 않고, 대신 어텐션 행렬에서 제거될 토큰의 연결 고리만 끊어버리는 방식입니다. 즉 토큰 개수는 동일하게 유지하되 마스킹을 통해서 제거된 토큰이랑 다른 토큰 간의 상호작용만 차단하는 방식이라고 보시면 됩니다. 이렇게 하면 모든 이미지의 토큰 수는 동일하게 유지되면서도, 제거된 토큰이 다른 토큰에 아무런 영향을 미치지 않게 되어 마치 제거된 것과 같은 효과를 냅니다. 하지만 이는 실제로 연산량은 줄이지 않기 때문에 학습시에만 사용이 돼서 게이팅 모듈이 이 토큰은 살려야겠다 버려야겠다만을 판단할 수 있도록 해주고 실제로 추론할 때에는 어텐션 마스킹이 아니라 실제 남겨진 토큰들만 처리하는 방식으로 연산량을 줄이게됩니다. 그럼 추론시에는 단일 배치만 가능한거 아니냐라는 질문을 하실 수 있는데, 논문에서는 해당 내용에 대해 자세하게 언급하지는 않았지만 공개된 코드를 살펴보면 프루닝된 비율 내에서 TOP K개 만큼으로 토큰의 길이를 맞춰주는 방식으로 동작하게 됩니다. 그럼 또 여기서 드실 수 있는 의문은 학습시에도 TOP K 방식으로 사용하면 안되는 것인가에 대한 의문도 드실 수 있는데 일반적으로 TOP K 방식보다는 Target Ratio로써 loss계산시 페널티를 부여함으로써 게이팅 모듈이 해당 비율에 맞게 프루닝되도록 하는 것이 조금더 성능이 좋다고 합니다.
이제 학습과정에 대해서 설명드리도록 하겠습니다.
학습 과정에서는 여러 가지 손실 함수를 사용합니다. 기본적으로 이미지 분류를 위한 Cross-Entropy Loss를 사용하고, 토큰이 제거된 모델(학생)이 원래의 전체 모델(교사)의 동작을 따라 하도록 지식 증류(Knowledge Distillation) 기법을 사용합니다. DynamicViT는 토큰을 줄여나가는 과정에서 성능이 크게 떨어지지 않도록 교사 모델(teacher model)을 함께 두고 DynamicViT가 pruning 이후에도 살아남은 토큰들의 표현이 teacher 모델의 마지막 블록 토큰과 최대한 비슷해지도록 MSE 기반 distillation loss를 주는 방식으로 학습을 진행한다고 보시면 될 것 같습니다. 기본적으로는 원래의 백본 ViT를 teacher로 삼고, DynamicViT가 이 모델의 동작을 최대한 흉내 내면서 학습하는 구조라고 보시면 좋을 것 같습니다. 이렇게 하면 모델이 정답 레이블만 따라가는 게 아니라 teacher의 분포까지 고려하면서 안정적으로 학습할 수 있습니다. 마지막으로, 각 단계에서 유지되는 토큰의 비율이 사전에 정의한 비율 즉, 게이팅 모듈이 이정도 비율만큼만 남겨놓도록 정의한 비율과 비슷해지도록 비율 손실(Ratio Loss)을 추가합니다.
아래는 해당 부분에 대한 수식입니다.
DynamicViT에서 최종적으로 남은 토큰이 교사 모델의 토큰과 유사하도록 함.
여기서 t_i와
는 각각 DynamicViT와 교사 모델의 마지막 블록 이후 i-번째 토큰을 의미하고 \hat{D}_{b,S}는 b-번째 샘플의 S-번째 프루닝 단계에서의 선택여부 마스킹 정보라고 보시면 될 것 같습니다.
그리고 아래는 게이팅 모듈이 사전의 정의한 keep ratio 비율에 프루닝을 하도록 MSE loss로 해당 비율 만큼만 프루닝 하도록 제약을 거는 손실함수라고 보시면 좋을 것 같습니다.
L_{\text{ratio}} = \frac{1}{BS} \sum_{b=1}^B \sum_{s=1}^S \left(\rho^{(s)} - \frac{1}{N} \sum_{i=1}^N \hat{D}_{b,s}^i \right)^2그래서 최종 손실 함수는 위의 손실들의 합으로 학습이 이루어진다고 보시면 됩니다.
결과적으로 위처럼 학습된 모델은 추론 단계에서. 학습 때와 달리 미분 가능성을 고려할 필요가 없기깨문에, 예측 모듈이 계산한 확률 점수가 가장 높은 토큰들만 딱 정해진 개수만큼 남기고 나머지는 실제로 버리는 방식으로 동작하게 됩니다. 그래서 결과적으로 추론시에는 연산량이 크게 줄어들어 추론 속도가 빨라지게 되는 것 입니다.
바로 실험파트로 넘어가도록 하겠습니다.
Experiments
일단 실험은 DeiT와 LV-ViT 같은 여러 Vision Transformer를 기반으로 진행되었고, 토큰은 3단계에 걸쳐 점진적으로 제거됩니다. 예를 들어서 keep ratio p를 0.7로 설정했다면, 1단계 후에 70%, 2단계 후에 49%(0.72), 3단계 후에는 약 34%(0.73)의 토큰만 남게 되는 식이라고 보시면 될 것 같습니다.
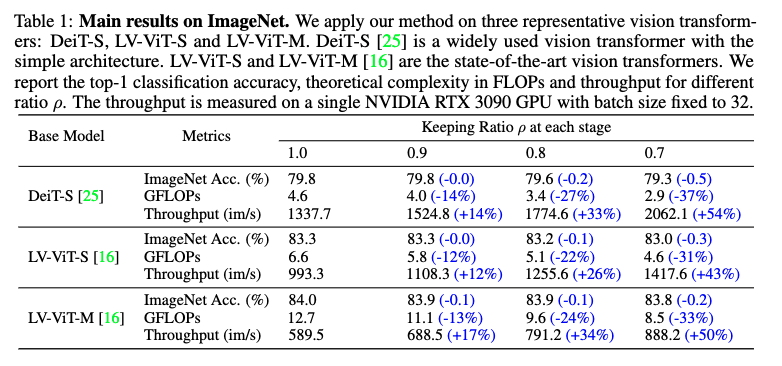
먼저 위 표를 보시면 성능 하락은 거의 없는데 속도는 엄청나게 빨라졌습니다. DynamicViT는 연산량(FLOPs)을 31% ~ 37%나 줄이고, 추론 처리량(Throughput)은 43% ~ 54%나 향상시켰습니다. 이렇게까지 효율을 높였는데도 불구하고 정확도 하락은 고작 0.2% ~ 0.5% 수준인 것을 확인 하실 수 있습니다.
그리고 아래는 당시 SOTA 모델들과의 비교 표입니다.
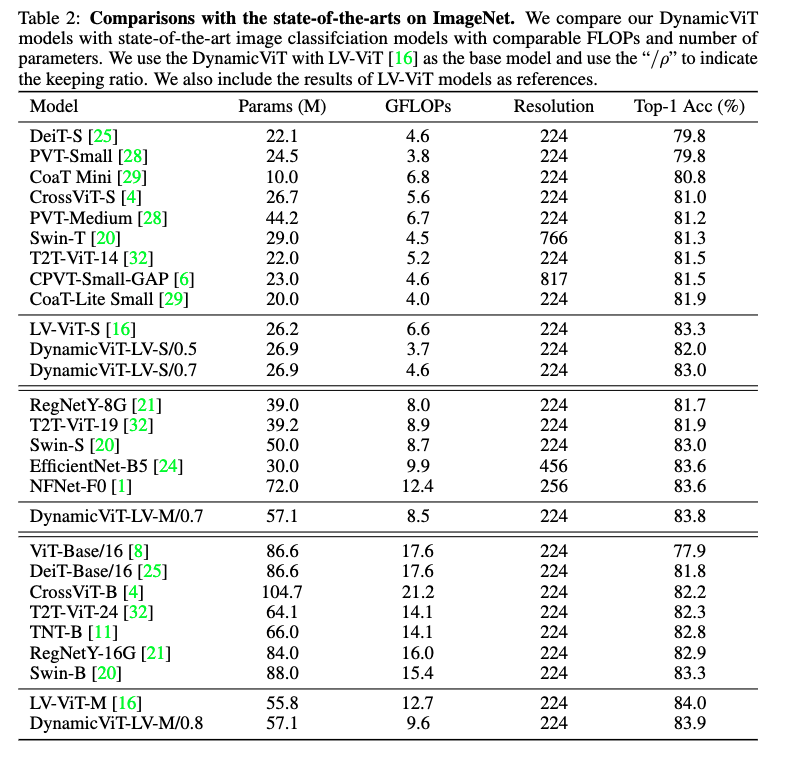
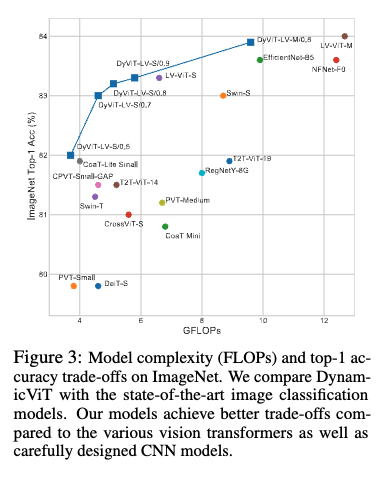
표 2와 그림 3의 비교 결과를 보면, DynamicViT는 기존의 강력한 CNN 모델인 EfficientNet-B5나 NFNet-F0보다도 더 적은 연산량으로 더 높은 정확도를 달성한 것을 확인 할 수 있었습니다.
또 Dynamic ViT의 기반인 LV-ViT 모델보다도 더 나은 정확도-연산량 효율 곡선을 보여주고 역시 저자는 DynamicViT의 토큰 프루닝 방식이 단순히 모델을 가볍게 만드는 것을 넘어, 불필요한 노이즈 토큰을 제거함으로써 오히려 모델이 더 중요한 정보에 집중하게 만드는 일종의 regularization 효과까지 가져올 수 있음을 언급합니다.
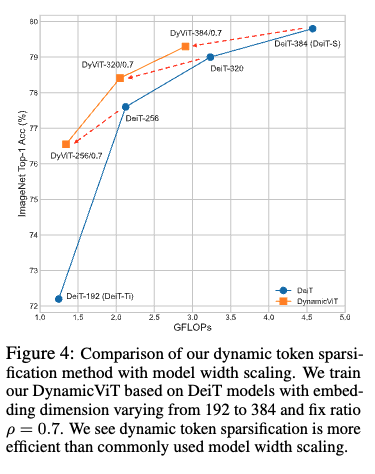
위 표를 보시면 단순히 작은 모델을 쓰는 것보다, 큰 모델에 DynamicViT를 적용하는 것이 훨씬 효율적이라는 것을 볼 수 있습니다. 어떻게 보면 성능을 올려놓고 거기서 프루닝을 해서 프루닝한 결과와 동일한 연산량을 가지는 모델과 비교를 하는 것이죠. 예를 들어, 중간 크기 모델인 DeiT-256에 DynamicViT를 적용했더니, 연산량은 가장 작은 모델인 DeiT-Ti 수준으로 줄어들었는데, 정확도는 무려 4.3%나 더 높았습니다. 즉, 같은 비용이라면 더 똑똑한 모델의 불필요한 부분만 덜어내서 쓰는 게 훨씬 낫다는 것을 보여줍니다.

위는 토큰 프루닝 과정을 시각화해서 보여준 것입니다. 위 표를 보시면 모델이 여러 단계를 거치면서 이미지의 배경(하늘, 바닥 등)처럼 정보량이 적은 토큰은 점차 버리고, 최종적으로는 핵심 객체(새, 강아지 등)에만 집중하는 모습을 확인할 수 있습니다. 저자는 DynamicViT가 단순히 연산량만 줄이는 게 아니라, 모델의 판단 과정을 단계별로 추적할 수 있어서 해석 가능성까지 보여준다고 합니다. 실제로 후속 연구들을 보면 각 레이어별 모델이 어느 부분을 더 집중해서 보는 지를 분석하고 해석하면서 프루닝을 레이어에 맞게 한다거나, 혹은 재활용한다던지를 고려해서 프루닝을 합니다. 토큰 프루닝에 있어서 통계, 그리고 그에 대한 분석이 중요한데 이는 추후 토큰 프루닝을 어떻게 더 효율적으로 할 수 있을지를 생각할 수 있도록 하는 시각화 결과라고 생각합니다.
DynamicViT의 핵심은 이미지에 맞춰 동적으로, 그리고 비구조적으로 토큰을 버리는 것인데 그렇다면 이게 정말 최선의 방법인지 확인해보기 위해서 여러 다른 프루닝 전략들과 성능을 직접 비교합니다.

여기서 structure는 CNN이 하듯이 중간에 풀링 레이어를 추가해 토큰 수를 줄이는 방식이고,static은이미지 내용과 상관없이 항상 정해진 위치의 토큰을 버리는 방식입니다. 그리고 무작위로 토큰을 버리거나, 어텐션 점수를 기반으로 버리기 등 다른 방법들도 비교 대상에 포함되었습니다.
결과적으로 DynamicViT의 프루닝 방식이 가장 높은 정확도를 기록했고 또 토큰을 한 번에 모두 버리는 것보다여러 단계에 걸쳐 점진적으로 버리는 방식이 훨씬 더 효과적이라는 것도 확인 할 수 있습니다.
conclusion
제가 토큰 프루닝 분야를 처음 접하면서 최신 논문부터 읽다 보니, 약간 탑다운 방식으로 전체적인 흐름을 따라가고 있는 것 같습니다. 이 DynamicViT 논문을 가장 먼저 읽었다면 좋았겠다는 생각이 드는데, 그 이유는 최신 연구에서는 당연하게 전제하는 내용들을 기존 CNN과 비교하며 왜 이러한 방법론이 등장했는지 그 배경을 깊이 있게 이해할 수 있었기 때문인 것 같습니다. 저자는 논문에서 ViT 가속화를 위한 새로운 길을 열었다고 주장하는데, 실제로 많은 후속 연구들이 DynamicViT를 인용하는 것을 보면 그 영향력을 실감할 수 있었던 것 같습니다. 특히 SViT 같은 논문은 DynamicViT에서 정말 많은 아이디어를 참고했다는 생각이 듭니다.
이만 리뷰 마치도록 하겠습니다. 감사합니다.
우현님 좋은리뷰 감사합니다.
논문의 방법론에 대해 두 가지 궁금한 점이 있습니다. 첫째 Sparsification Stage의 영향에 관한 것입니다. 논문에서는 3단계의 계층적 희소화를 적용했는데 이 단계를 늘리거나 줄였을 때 모델의 정확도와 추론 속도 간의 차이가 얼마나 나는지 궁금합니다. 또한 DynamicViT에서 제안된 dynamic token sparsification가 이미지 분류 외에 detection이나 segmentation과 같은 다른 컴퓨터 비전 태스크에도 효과적으로 적용될 수 있는지, 만약 적용된다면 어떤 결과를 기대할 수 있을지 궁금합니다
감사합ㄴ디ㅏ
안녕하세요 우진님 댓글 감사합니다.
Q1. 3단계의 계층적 희소화를 적용했는데 이 단계를 늘리거나 줄였을 때 모델의 정확도와 추론 속도 간의 차이가 얼마나 나는지?
일단 table4에서 (c)에 모델의 정확도는 나와있습니다. 추론 속도에 대해서는 3 단계를 어떻게 나눴느냐에 따라 결과가 달라질 것 같습니다.
Q2. DynamicViT에서 제안된 dynamic token sparsification가 이미지 분류 외에 detection이나 segmentation과 같은 다른 컴퓨터 비전 태스크에도 효과적으로 적용될 수 있는지?
실제로 SViT 같은 경우에는 이런 classification에서 사용하는 토큰 프루닝을 object detection, segmentation으로 확장시킨 경우라고 볼 수 있겠고 실제로 해당 논문에서도 다른 비전 태스크에 효과적으로 적용할 수 있다고 확장성 측면에서 언급합니다!
감사합니다.
안녕하세요 우현님 리뷰 감사합니다.
간단한 질문이 있는데, Local feature 와 Global feature를 합친 뒤 MLP 를 태우고 softmax를 태우는 행위가
토큰을 유지할 확률과 버릴확률을 최종적으로 계산하게 되는 이유가 뭔가요?
두번째 궁금한 점은 TOP K 방식보다 Target Ratio 로 loss 계산시 패널티를 추가하는 것이 조금 더 성능이 좋다고 하셨는데, 그럼 TOP K 방식으로는 Loss 함수 구성을 못하는건가요? 뭔가 비슷한 역할일 것 같아서 질문드립니다.
감사합니다.
안녕하세요 인택님 답글 감사합니다.
먼저 개별 토큰만 참고해서 해당 토큰을 버릴지 말지를 정하는거에서 더 나아가 글로벌 피쳐 전역 정보까지 함께 줌으로써 선택 모듈이 이 토큰의 개별 정보와 전역정보를 포함해서 중요도를 판단할 수 있도록 하기 위해서 입니다.
그릭 두번 째 질문에 대해서는 Top K 방식도 마찬가지로 Loss를 설계할 수 있습니다. 논문에서는 직접적으로 언급되지는 않았는데 마찬가지로 Top k 방식도 비미분 방식이라 그레디언트가 흐르지않아 gumbel ,straight-through같은 장치를 넣어줘야하긴합니다. 다만 top-k는 결국 모듈이 자르는게 아니라 스코어 기반으로 자르는 것이고(top-k 모두가 좋은 토큰은 아닐 수 도 있으니깐) 반대로 ratio는 모듈이 전반적으로 다 판단하고 선택하는 것이기 때문에 그런 영향이 없지 않아 있을 것 같고 keep_ratio는 시그모이드 확률의 평균을 목표 비율 r에 맞추는 MSE 방식이라 학습이 상대적으로 유리하지 않아서 그런가 싶습니다.
감사합니다.