구글 딥마인드에서 ICRA 2025에 게재한 방법론으로 affordance가 실제 로봇 작업에서 어떻게 활용 가능할 지 연구한 논문입니다.
Abstract
해당 연구는 로봇 조작의 일반화를 위한 intermediate policy representations에 대한 연구를 수행합니다. 기존의 연구를 통해 text나 goal 이미지, trajectory를 사용하는 방식이 어느정도 효과가 있음을 보여주었으나, 충분한 맥락 정보를 제공하지 못하거나, 너무 특화된 정보를 제공하여 강인한 policy를 만들기에는 어려움이 있었습니다. 저자들은 affordance를 조건으로 활용하는 방법을 제안하며, 계층적 모델인 RT-Affordance를 통해 주어진 언어 작업에 대해 affordance plan을 세운 뒤, 이를 조건화하여 로봇 조작을 위한 policy를 만들도록 합니다. RT-Affordance 모델은 서로 다른 도메인의 데이터인 대규모 웹 데이터와 로봇 trajectory를 연결해주며, 고비용의 trajectory 데이터 가 아닌 저렴한 affordnace 이미지로 학습하였음에도 새로운 작업에 대한 적용이 가능하도록 하였습니다. 저자들은 다양한 작업에서 RT-Affordance가 기존 방법론 대비 50% 이상 성능 개선이 이루어졌음을 보였으며, affordance 정보가 새로운 환경에도 강인하게 작동하는 데 도움을 주었음을 실험적으로 보였습니다.
Introduction
최근 로봇의 polices를 학습하기 위한 대규모 사전학습된 모델이 등장하기 시작하였으며, VLA(Vision-Language Action) 모델은 VLM과 로봇 데이터의 결합으로 다양한 물체와 장면, 작업과 결합되어 일반화를 위한 연구가 이루어지고 있습니다. 그러나 VLA는 아직 연구실 수준에서만 검증된 상태로, 실제 현장 적용에는 고비용 로봇 데이터 수집의 제약으로 인해 일반화에 한계가 따릅니다.

이를 해결하기 위해 로봇 작업에 대한 유용한 가이드를 제공하는 policy representation 연구가 이루어지고 있습니다. 이는 고차원의 입력에 대한 저차원 행동 정보를 모델이 직접 추론하지 않고, 중간에 언어 설명, goal image, goal sketches, trajectory sketches 등을 추론하도록 하여 mid-level 추상화가 가능하도록 하는 방식입니다. 작업에 대한 언어 설명을 사용하는 방식이 가장 흔한 방식이지만, 언어 정보를 조건으로 활용하는 작업으로는 충분한 정보를 제공하기 어려웠으며, 이에 대한 대안으로 최종 작업을 위해 공간적 맥락 정보를 제공할 수 있는 goal image를 활용하는 연구가 이루어졌습니다. 그러나 이러한 방식도 고차원의 이미지 정보이므로 학습의 어려움이 있었고, 로봇을 직접 조작하여 원하는 goal 이미지를 생성해야하므로 추론시에 목표 이미지를 제공하는 것이 번거롭다는 문제가 있었습니다. 따라서 이 외에도 trajectory sketches 등을 이용하여 공간적인 계획을 가이드로 활용하려는 연구가 이루어졌습니다. 그러나 이러한 방식도 “어떻게” 조작할 지에 대한 충분한 정보를 제공하지 못하였으며, 이러한 문제를 해결하기 위해 저자들은 affordance를 활용하는 RT-Affrodance를 제안하였습니다.
RT-Attention은 언어 정보와 visual affordance 정보를 함께 조건으로 활용하는 계층적 모델입니다. visual affordance는 작업의 주요 단계마다 로봇의 end-effector pose를 나타내며, 사용자로부터는 언어 정보만 입력받아 동작합니다. 주어진 언어 기반 작업에 대해 affordance를 예측한 뒤, 이를 intermediate representation으로 활용하여 policy를 가이드하도록 학습됩니다. 초기 affordance 예측 모듈은 web-scale의 라벨링된 데이터를 학습 가능하며, 저자들은 비교적 적은 affordance 데이터셋을 활용하여 성능을 향상시켰습니다. 이를 통해 비교적 더 많은 비용이 요구되는 로봇 teleoperation 데이터의 필요성을 줄이고, 새로운 작업으로 확장이 가능하도록 하였습니다.
저자들은 다양한 실험을 통해 RT-Affordance가 다양한 실제 작업에서 효과적임을 보였으며, 언어 정보를 조건으로 사용하는 방식의 작업 성공률 15%보다 50%가량 성능 개선을 이루었습니다. 또한, 추가적인 로봇 시연 데이터가 없어도 새로운 작업으로 확장이 가능하였음을 보였습니다. 마지막으로, affordance model이 분포 변화에도 강인함을 입증하기 위해 out-of-distribution 환경에서 실험을 진행하였으며 10% 이내의 변화가 있음을 실험적으로 확인하였습니다.
Method
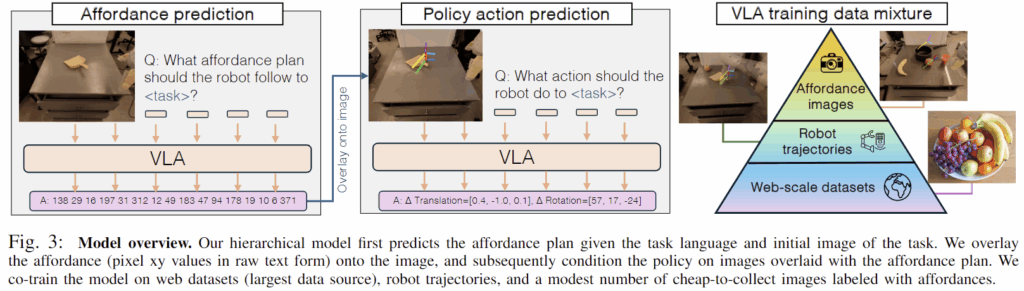
저자들은 (1) 다양한 작업에 대하여 유의미하고 compact한 intermediate representation, (2) 외부 데이터에 대하여 효과적으로 지식을 전이할 수 있도록 중계하며 일반화가 가능하도록 하며, (3) 새로운 작업에 대해서도 저렴하게 학습할 수 있도록 하는 것을 목표로 하였습니다. 저자들이 제안한 RT-Affordance(RT-A)는 계층적인 policy로, 먼저 affordance generator로 affordance plan을 생성한 뒤, 이를 조건으로 활용하는 affordance-conditioned policy를 통해 action을 생성합니다. 위의 Fig. 3이 이에 대한 개요입니다. 장면의 초기 이미지와 자연어 지시문이 주어졌을 때 affordance 예측 모델을 이용하여 affordance plan을 예측한 뒤, 이를 이미지에 투영하여 표현한 뒤, 이를 다시 언어 지시문과 함께 policy에 조건으로 주어 작업을 실행하게 됩니다.
Affordance-conditioned polices
전반적으로 affordance를 활용하여 로봇 작업을 위한 action을 생성하는 전반적인 과정에 대하여 먼저 설명드리겠습니다. 먼저 robot trajectory 데이터셋은 \mathcal{D} = \{ l, \{o_i,e_i,g_i,a_i\}^T_{i=0} \}로, l은 언어 지시, o_i,a_i, e_i,g_i는 이미지와 action, end-effector의 pose, 그리퍼의 상태에 대한 시퀀스 데이터를 가지고 있다고 가정합니다. 자연어 지시 l, 현재 이미지 o, affordance plan q가 주어졌을 때, affordance-conditioned policy \pi(a|l,o,q)를 학습하는 것을 목표로 하며, affordance plan q=(e_{t_1},e_{t_2}, ..., e_{t_n})는 주요한 시점에 해당하는 end-effector의 pose 시퀀스로 정의됩니다.
주요한 시점은 로봇이 물체와 접촉하기 직전과 같은 순간이 포함되며, 이를 추출하는 다양한 방법이 있으나, 저자들은 확장성을 고려하여 그리퍼의 상태가 변화하는 순간(열림→닫힘 or 닫힘→열림)이나 trajectory의 마지막 순간 같이 객체와 상호작용이 이루어지는 순간을 주요한 시점으로 정의하는 단순한 방식을 이용하였습니다.
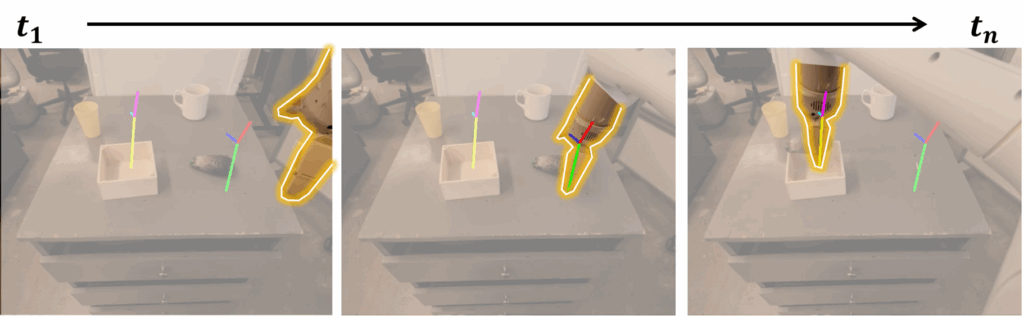
이러한 affordance plan을 활용하므로써 언어 정보만을 이용하는 방식에 비해 동작에 대한 정밀한 공간적 정보 뿐만 아니라 접촉 및 자세 정보와 같이 로봇 조작에 필수적인 정보를 고려할 수 있습니다. 저자들은 behavioral cloning 방식으로 학습을 수행하며 RT-2와 유사하게 web-data를 함께 학습합니다. affordance 정보를 policy 학습에 활용하는 방식은 토큰화된 text값으로 표현하여 policy 학습의 입력으로 사용하는 방식과 visual operator \psi(o,q)를 이용하여 이미지에 표현하는 방법이 있으며, 저자들은 기존 연구(구글 딥마인드의 이전 연구들로(1, 2), 공간 및 로봇 작업에 대하여 VLM이나 policy를 유연하게 일반화하기 위해 그림 위에 행동 후보나 궤적을 시각적으로 표현하고, 이를 모델이 해석하거나 반복적으로 조정하도록 하는 방식의 연구로 보입니다.)와 유사한 방식을 활용합니다. 로봇 그리퍼의 pose e_i에 대해 그리퍼의 양 끝, 그리퍼가 달린 로봇 팔의 3D 위치를 2D 이미지에 투영하여 시각적으로 표현한 방식으로, 위의 그림을 통해 예시를 확인하실 수 있습니다. 또한 각 affordance에 대하여 고유 색상을 지정하여 영상에 중첩하여 표현합니다. 이러한 방식은 카메라의 intrinsic 파라미터와 extrinsic 파라미터를 알고있다는 전제가 있으며, 저자들은 로봇 플랫폼에서 쉽게 취득이 가능하다고 보고 이러한 방식을 적용하였습니다. 그리고 만일 외부 및 내부 파라미터를 구하기 어려울 경우에는 affordance pose를 토큰화된 text로 변환하여 입력하는 방식을 이용할 수 있습니다. 이후 추론 과정에는 affordance plan과 언어 지시를 사용자에게 요청하여 조건으로 활용하였으며, 이러한 방식이 goal 이미지나 trajectory에 대한 sketches를 요청하는 방식에 비해 더 낮은 차원의 데이터이므로 취득이 용이하다고 어필합니다.
Learning to predict affordance
다음은 affordance plan에 대하여 학습하는 방식에 대해 설명드리겠습니다. 저자들은 사람에게 UI 인터페이스 상에서 이미지에 직접 표시하는 방식으로 affordance plan을 수집합니다. 이러한 방식은 목표 이미지나 trajectory sketch를 제공하는 방식보다 비교적 단순하고 차원도 낮아 유리하며, 나아가 모델이 affordance plan을 자동으로 예측하도록 학습할 수 있으므로 test시에는 사람이 affordance를 제공하지 않아도 작동이 가능합니다.
저자들은 언어 지시문 l과 장면의 초기 이미지 o가 주어졌을 때, affordance plan q을 예측하는 affordance 예측 모델 \phi(q|l,o)을 학습합니다. 학습에 사용되는 데이터는 policy 학습에 사용된 로봇 데이터 셋 \mathcal{D}에서 추출한 데이터와 object detection과 같은 기존의 web-data입니다. 그러나, 일부 작업에서는 추가적인 데이터가 필요할 수 있으며, 저자들은 고비용의 teleoperation 데이터 대신, 더 쉽고 많이 수집할 수 있는 이미지와 task 라벨로 이루어진 데이터 셋 \mathcal{D}_{aug} = \{ (o_i,l_i)\}^n_{i=0}를 구성하여 학습에 사용할 수 있습니다. 저자들은 이러한 방식을 통해 고비용의 로봇 teleoperation의 필요성을 줄일 수 있음을 실험적으로도 입증하였습니다.
Experiments
저자들은 실험을 통해 다음에 대해 검증하고자 하였습니다.
- Affordance-conditioned policy가 다양한 manipulation 작업에 효과가 있을 지?
- Affordance가 추가적인 로봇 teleoperation 없이도 효율적으로 새로운 작업에 대하여 학습 가능한지?
- Affordance 예측 모델은 새로운 객체, 카메라 시점, 배경으로 얼마나 잘 일반화 가능한가?
Setting
실험은 RT-1의 로봇 manipulator를 이용하며, Cartesian End-effector 제어를 활용하고, 단일 head-mounted 카메라로 구성됩니다. 로봇 시연 데이터는 다음 3가지를 이용합니다.: (1) RT-1의 데이터 셋; 기본적인 조작 평가, (2) MOO 데이터 셋; 다양한 객체 조작에 대해 평가 (3) 추가적인 trajectories 데이터;정교한 작업. 실험에는 PaLM-E를 기반 모델로 사용하였으며, affordance를 예측하는 모델은 수동으로 750장의 affordance 라벨을 annotation한 데이터로 affordance 전용 VLA를 학습하였습니다.
Learning to grasp novel objects efficiently
먼저 저자들은 새로운 객체에 대한 grasping에 대하여 실험합니다. 다양한 가정용 물체(쓰레받이, 주전자, 냄비 등)를 파지하는 벤치마크를 설계하였으며, 이러한 물체들은 복잡한 형상을 가지고 있어, 세밀한 part-level reasoning이 필요합니다. 또한, 평가에 해당하는 시나리오 물체는 학습에 사용되는 로봇 데이터에 포함되지 않은 unseen object categories 물체로 구성하였으며, 대상 객체를 테이블에 배치하고 2~3개의 장애물 객체를 함께 배치하여 환경을 구성한 뒤, 각 객체 카테고리별로 5번의 시도에 대한 성공률을 평가하였습니다.
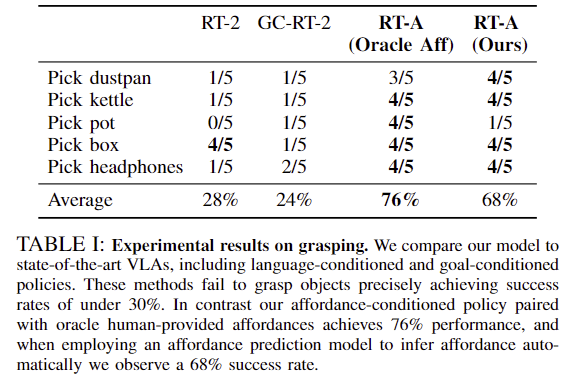
Table 1은 이에 대한 결과로, 기존의 방법론인 RT-2가 평균적으로 28%로 낮은 성공률을 보였으며, 이는 대상 객체를 식별하는데 성공했으나, 쓰레받이의 손잡이 대신 중앙을 잡거나 냄비도 바닥부분을 잡으려 하는 등 파지를 위한 충분한 정보가 부족하였다고 분석하였습니다. GC-RT-2는 RT-2가 사용하는 언어 조건을 goal 이미지로 변경한 방식으로, 이러한 경우의 성공률도 24%로 상당히 낮은 성능을 보였습니다. 이에 대해 저자들은 goal 이미지를 예측하는 방식이 파지에 적합한 위치 정보는 제공하였으나, rotation과 같이 실제 파지를 위한 충분한 정보는 제공하지 못한 것이라 분석하였습니다. 이에 반해, 저자들이 제안한 방식은 76%와 68%의 높은 성공률을 달성하였으며, 사람이 직접 affordance plan 정보를 제공하는 Oracle Aff 방식이 가장 좋은 성능을 보였습니다. Affordance plan을 모델이 예측하는 방식도 68%로 비교적 높은 성능은 보였으나, 일부 케이스에서 객체를 충분히 들어올리지 못하거나 동작이 멈추는 등의 문제가 있었다고 합니다.
Diverse task
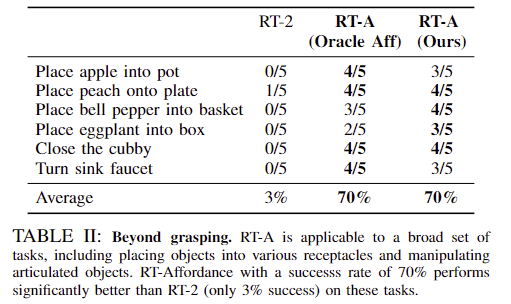
저자들은 grasping 외의 용기 안에 물체를 넣는 작업과 서랍과 같은 articulated 물체 조작 등 다양한 작업으로 확장 가능성에 대하여 실험하였습니다. 해당 작업도한 unseen에 해당하며, Table 2는 이에 대한 정량적 결과로 기존 방법론인 RT-2는 3%로 굉장히 낮은 성공률을 보였고, 저자들에 따르면 물체를 불안정하게 파지하거나 파지 이후 멈추는 경우도 있으며, 용기 안이 아니라 옆에 두는 등의 실패 케이스가 있었다고 합니다. 반면 affordance에 대한 예측을 이용한 실험 결과 성능이 크게 개선되어 70%의 성공률을 기록하였으며, 이러한 실험 결과를 통해 affordance가 다양한 로봇 작업에 대해 유용한 가이드르 제공할 수 있음을 어필합니다.
Robustness to out-of-distribution factor
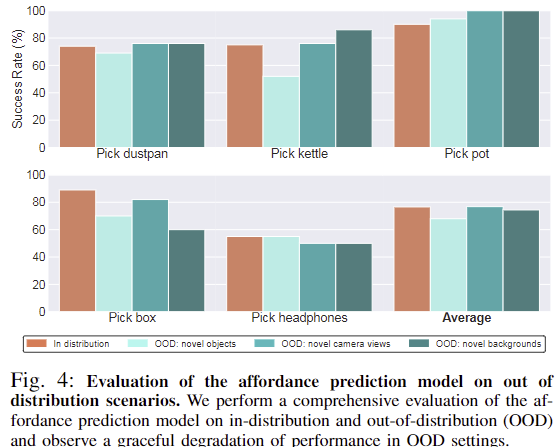
저자들은 out-of-distribution 상황에 대한 강인성 평가도 수행하였습니다. Table 1과 동일한 작업으로 설정하였으며, In-distribution은 동일한 객체 인스턴스, 동일한 view, 동일한 배경에 대해 학습되었으며, 객체 인스턴스와 카메라 view, 배경 3가지 요소에 대하여 OOD를 평가하였습니다. 위의 Fig. 4가 이에 대한 정량적 결과를 그래프로 나타낸 것이며, 아래의 Fig. 5는 정성적 결과입니다. 다른 방법론과의 비교는 따로 없었지만(OOD케이스가 아니더라도 28%로 낮은 성능이였습니다.) In-distribution과 비교했을 때 성능 저하가 10%내로 이루어졌다는 점을 통해 강인성을 보였습니다. 3가지 요소 중, view의 변화는 77%로 성능이 동일하였으며, 배경의 변화는 3% 감소, 객체 인스턴스의 변화는 논문에 정확한 수치가 나와있지는 않지만 10% 이내였습니다.

Ablation study
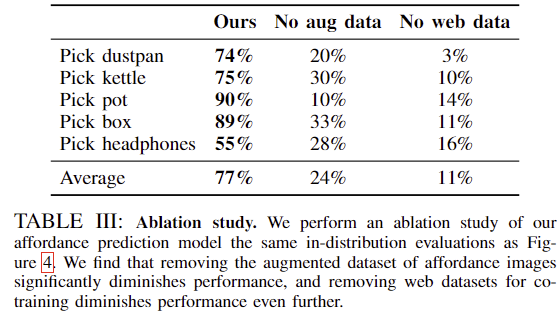
마지막으로, affordance prediction 모델에 대하여 ablation study를 수행한 결과입니다. 저자들이 제안한 데이터는 robot trajectories 데이터와 web data, 750장의 추가 데이터(aug data)로 학습이 이루어졌으며, Table 3은 aug 데이터와 web-data의 유무에 따른 성능을 나타냅니다. 실험결과 aug data와 web-data 모두 성능에 큰 영향을 준다는 것을 확인할 수 있었습니다. 로봇 데이터가 아님에도 성능에 큰 영향을 준다는 것이 인상적입니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
본문에서 말씀하신 것처럼, affordance 정보를 policy 학습에 활용하는 방식에는 1. affordance를 토큰화된 텍스트 값으로 표현하여 policy 학습의 입력으로 사용하는 방법과 2. visual operator를 이용해 이미지에 시각적으로 표현하는 방법이 있다고 하셨는데, 기존 연구에서 사용된 유사한 방식이 구체적으로 어떤 것인지 궁금합니다
감사합니다.
질문 감사합니다.
이미지에 시각적으로 표현한 기존 연구는 introduction에 있는 이미지에서 확인할 수 있듯, 영상 내에서 end-effector가 이동해야하는 궤적을 그리는 방식이라고 생각하시면 될 것 같습니다. 저자들은 이러한 방식보다도, 주요한 시점에 두 그리퍼와 팔이 붙어있는 윗 부분을 표현하는 방식이 더 비용이 덜 들면서도 접근 방향 등의 로봇 작업을 위한 정보를 제공할 수 있다는 점을 어필합니다.
안녕하세요, 승현님. 좋은 논문 리뷰 감사합니다.
teleoperation으로 제공되는 많은 양의 trajectory 정보를 직접 쓰는 대신, 저차원적인 affordance를 중간 표현으로 활용해 공간 정보를 제공한다는 점이 흥미로웠습니다.
리뷰를 보면서 teleoperation 대비 affordance를 쓰면 연산 비용 절감뿐 아니라 노이즈 감소 효과도 함께 얻을 수 있는지 궁금했습니다. 또한 논문에서 다룬 grasping이나 물체를 용기에 넣기, 서랍 열기와 같은 작업은 이해가 되었는데, trajectory 정보를 사용하지 않다 보니 천 접기나 액체 따르기 같은 더 복잡하고 연속적인 행위에도 확장이 가능한지 한계가 있는지도 궁금합니다.
다시 한번 좋은 리뷰 감사드립니다 🦾
질문 감사합니다.
제가 생각하기에 teleoperation를 사용하지 않고 affordance만을 이용하는 해당 방식을 적용할 경우 노이즈가 증가하게 될 것 같습니다. 그러나 확장성이 증가하여 다른 환경이나 다른 물체로의 확장에 유리하다고 생각합니다.
또한, 말씀하신 천 접기나 액체 따르기를 물체간의 상호작용 관점의 복잡함의 경우 말씀하신대로 도움이 될 것 같지만, 특정 형태로 접는 등의 정교한 작업으로 본다면 affordance 이후의 충분한 planning이 필요할 것이라 생각합니다.