이번에 소개할 논문은 2025 ICCV에 accept된 논문으로, text-video retrieval 분야에서 정확성과 효율성을 모두 달성한 연구입니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
Text-to-Video Retrieval (T2VR)은 주어진 텍스트 쿼리와 의미적으로 일치하는 비디오를 검색하는 것을 목표로 합니다.
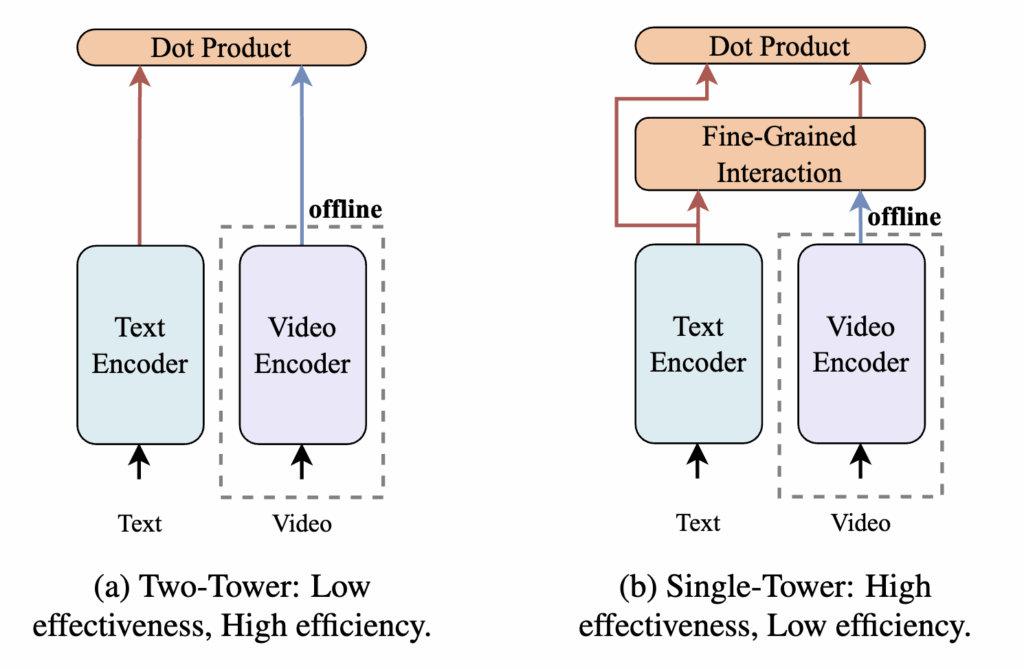
최근 CLIP 기반 연구들은 주로 위 그림처럼 Two-Tower와 Single-Tower 두 가지 프레임워크로 연구가 진행되어왔습니다. Two-Tower 방식은 텍스트와 비디오를 독립적으로 인코딩한 후 단순한 dot product로 유사도를 계산하기 때문에 계산이 빠르고 비디오의 피처를 미리 뽑아 놓을 수 있어 효율성이 높다는 장점이 있습니다. 하지만 세밀한 상호작용이 부족해 정확도가 낮은 한계가 있습니다. 반면 Single-Tower 방식은 텍스트와 비디오 간의 fine-grained interaction 모듈을 통해 더 정교한 매칭을 수행하여 정확도는 높지만, 텍스트 쿼리가 주어져야만 interaction이 가능해 미리 비디오 피처를 뽑아 놓을 수 없어 연산 비용이 크고 효율성이 떨어지는 한계가 있습니다.
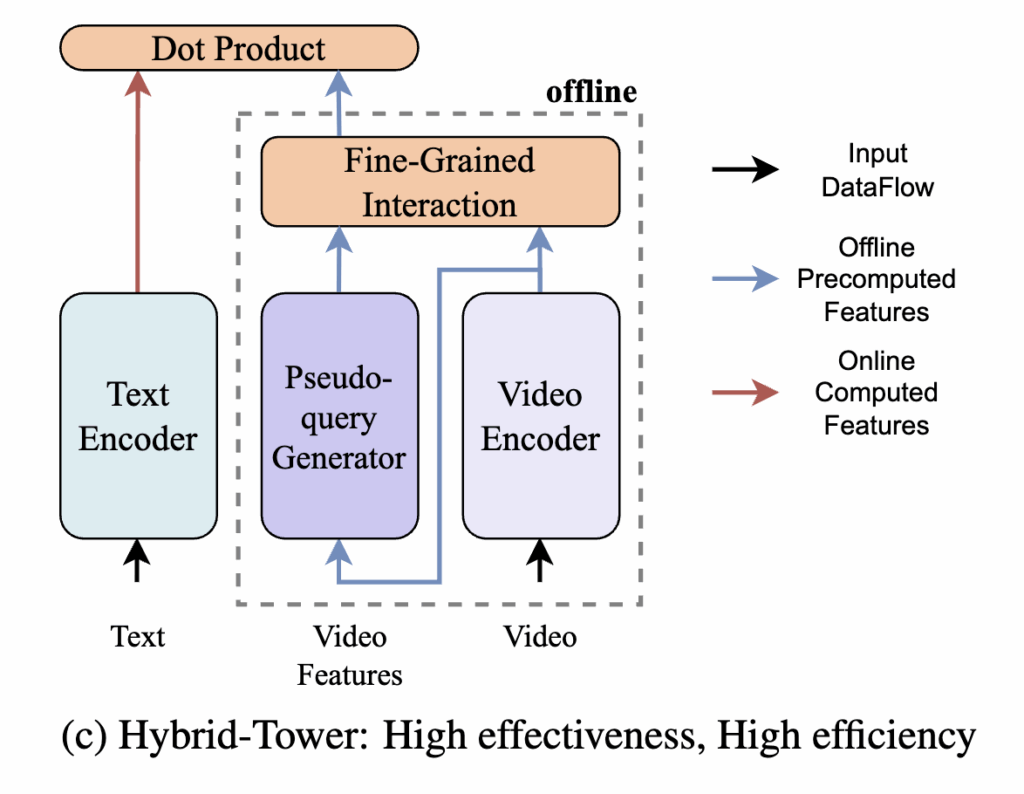
따라서 저자는 이러한 두 접근의 장점을 결합하여, 정확성과 효율성을 동시에 달성할 수 있는 새로운 Hybrid-Tower 프레임워크를 제안합니다. 이 프레임워크의 핵심은 Pseudo-query Interaction and Generation(PIG)인데, 이는 실제 텍스트 쿼리가 주어지기 전에 비디오와 관련된 pseudo-query를 생성하여, 비디오 피처가 Single-Tower 모델처럼 pseudo-text 쿼리와 상호작용을 수행할 수 있도록 합니다.
PIG는 두 가지 구성 요소로 이루어집니다:
(i) pseudo-query generator – Multi-grained Visual Features 와 Informativeness Token Selection을 활용하 여 pseudo-query 생성
(ii) pseudo-interaction fusioner – 생성된 pseudo-query와의 상호작용을 통해 최종 비디오 표현을 개선하는 모듈
저자의 주요 Contribution은 다음과 같습니다
- Hybrid-Tower 프레임워크 제안: 저자의 모델은 Single-Tower의 정확성과 Two-Tower의 효율성을 동시에 고려하도록 설계
- PIG(Fine-grained Pseudo-query Interaction and Generation) method 제안 : 각 비디오에 대한 pseudo-query를 생성하는 Pseudo-query generator 모듈과 pseudo-interaction fusioner로 구성
- MSRVTT-1k , MSRVTT-3k MSVD , VATEX, DiDeMo 등 다섯 가지 벤치마크에서 실험을 수행. 그 결과로 제안된 방법이 Single-Tower 모델과 비슷한 SOTA에 가까운 성능과 Two-Tower 모델의 SOTA 효율성을 동시에 달성함
2. Method
2.1 Preliminaries
Nv개의 비디오 클립과 Nt개의 텍스트로 구성된 데이터 세트, D = {vi, tj }가 주어지면 각 비디오 클립에는 하나 이상의 해당 텍스트 query가 있습니다. T2VR 는 주어진 텍스트 query와의 유사도를 기반으로 가장 유사한 비디오의 순위를 정하는 것입니다. T2VR 모델은 일반적으로 텍스트 인코더 ϕt와 비디오 인코더 ϕv를 사용하여 비디오와 텍스트를 cross-modal feature space로 임베딩합니다.
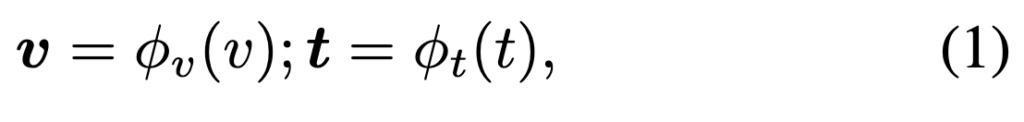
최근 CLIP 기반 T2VR 연구들은 주로 CLIP의 비디오 인코더에 temporal 모듈을 추가하여 시간 정보를 강화하는 방향으로 연구가 진행되고 있습니다. 이러한 모델 중 CLIP-VIP는 video proxy tokens과 추가적인 attention 기법을 통해 비디오의 temporal 정보를 고려하며 높은 성능을 보여주었으며, 저자는 본 연구에서 이를 backbone 모델로 활용했다고 합니다.
2.2 Overall Framework
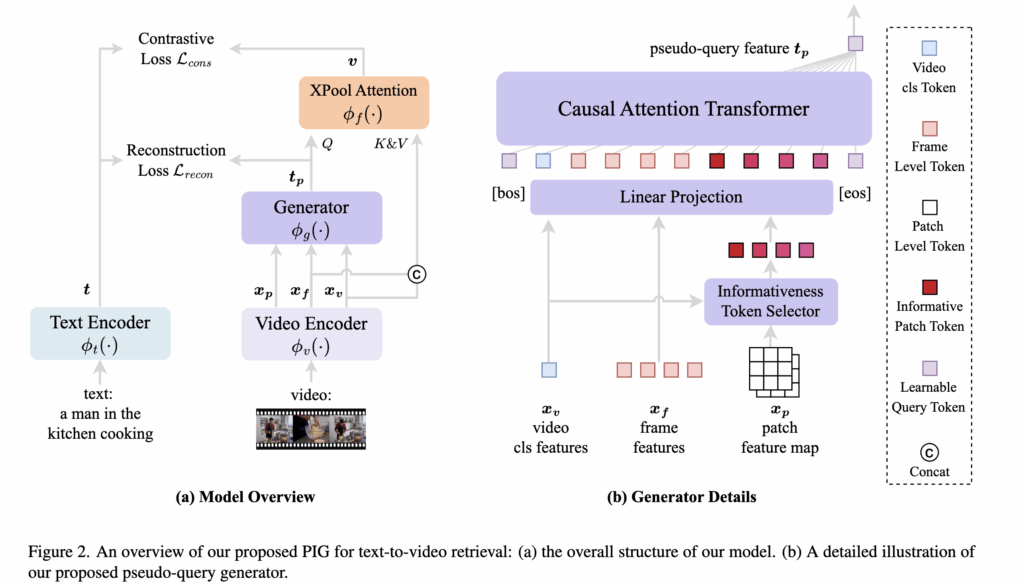
저자가 제안하는 모델은 그림 2와 같이 구성되어 있습니다. 그림에서 Generator로 표시된 부분이 바로 저자가 제안한 PIG 모듈이며, 이 모듈이 fine-grained pseudo-query generation과 interaction을 담당합니다.
먼저, m개의 프레임 {f1,…,fm}으로 구성된 비디오 v가 주어지면, 이를 비디오 인코더 ϕv(⋅)에 입력하여 visual feature를 추출합니다. 저자가 backbone으로 사용하는 CLIP-ViP는 video proxy tokens를 사용해 video-level [CLS] 역할을 하는 토큰을 생성하고 이를 xv로 표현할 수 있습니다. 여기에 저자는 추가로 ViT layer에서 얻은 frame-level [CLS] 토큰(xf)과 patch-level token(xp)도 추출하면 아래 수식과 같이 표현할 수 있습니다.

2.3 Pseudo-Query Generator
먼저, 이전 단계에서 얻은 video-level 피처 xv , frame-level 피처 xf , patch-level 피처 xp를 모두 concat하여 생성 모듈 ϕg 에 입력하면 pseudo-text query tp를 얻습니다. 이를 수식으로 나타내면 다음과 같습니다.
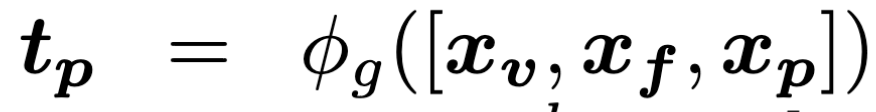
이 세가지 피처를 가지고 Transformer layer에 넣어 텍스트 쿼리 토큰의 shape과 동일하게 만들어 줄 수 있습니다. 하지만 패치 토큰에는 배경 영역이나 중복된 정보등이 있어 pseudo-query 생성에 noise로 작용할 수 있습니다. 따라서 저자는 Informativeness Token Selection(ITS) 모듈을 추가하여 비디오에서 중요한 패치 토큰만 선별하도록 설계했습니다.
Informativeness Token Selection (ITS)
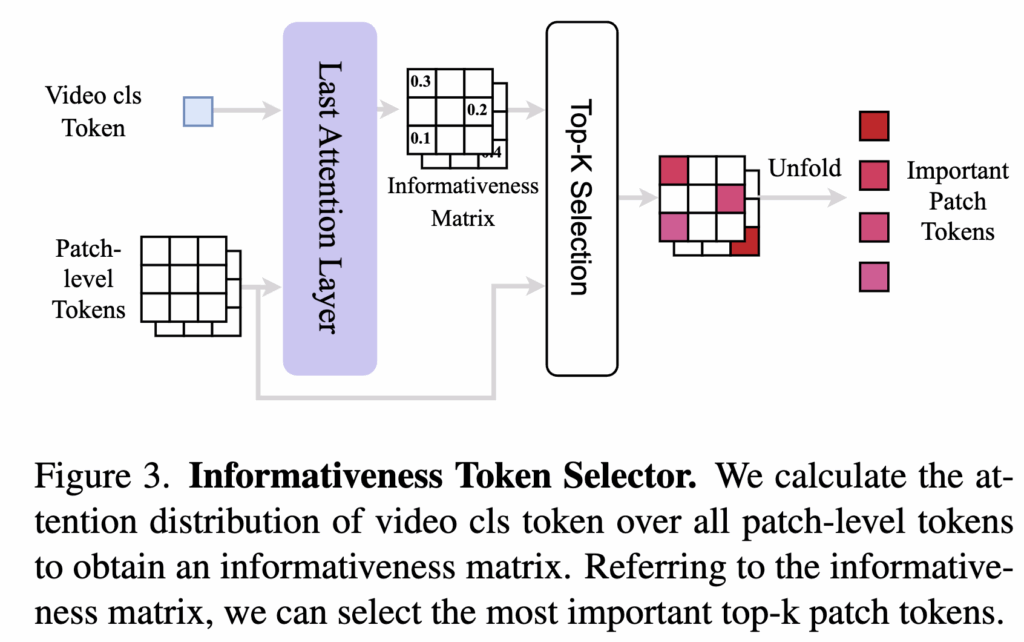
ITS는 비디오의 [CLS] 토큰이 각 patch-level token에 대해 계산한 attention score 중 top-k 토큰만을 선택합니다.
Pseudo-Query Generator
최종적으로, 원래의 비디오 피처 xv, 프레임 피처 xf , ITS를 통해 선택된 패치 피처 xi 를 concat하여 pseudo-query generator의 입력으로 사용할 수 있습니다. 하지만 저자는 pseudo-query를 최대한 text 토큰과 일치시켜주기 위해 Pseudo-query generator의 모듈을 CLIP의 Text Encoder의 가중치를 사용하여 초기화하고, bos 토큰과 eos 토큰을 같이 입력으로 넣어 모듈의 최종 출력에서 [EOS] 토큰을 pseudo-query feature tp로 사용합니다.
Pseudo-Interaction Fusioner
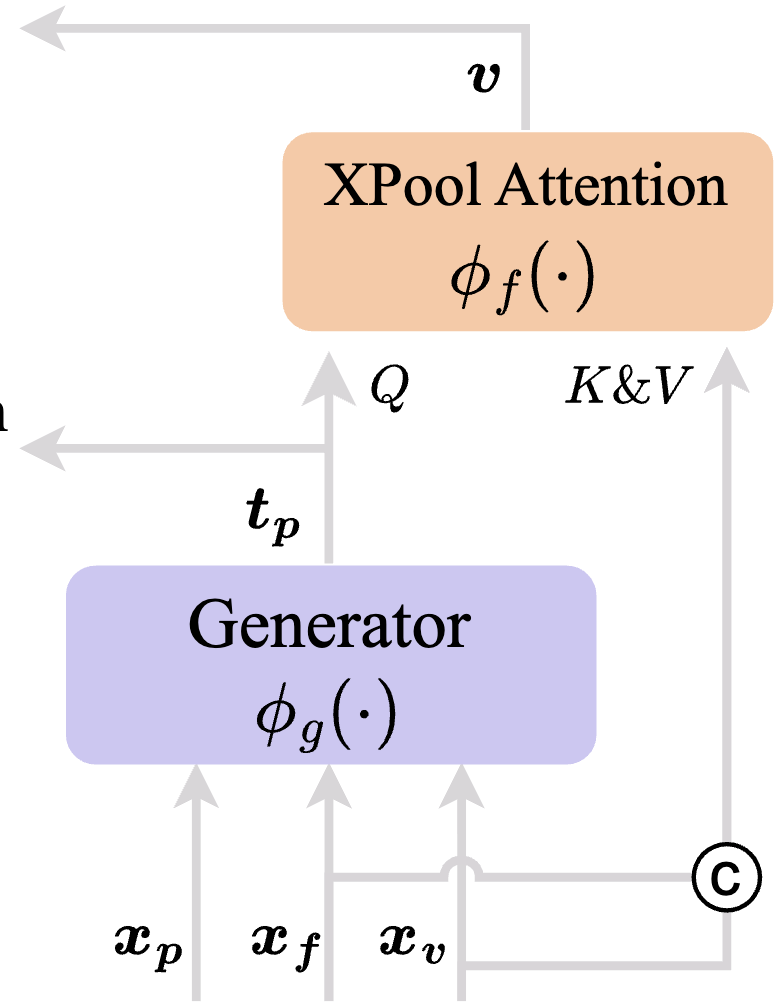
이후 생성된 tp를 활용하여 비디오 피처를 강화하기 위해 Pseudo-Interaction Fusioner를 수행합니다. 이 모듈은 XPool Attention으로 구성되며, tp를 쿼리로, xv와 xf를 키와 밸류로 사용하여 텍스트 쿼리 기반으로 향상된 비디오 표현을 추출합니다
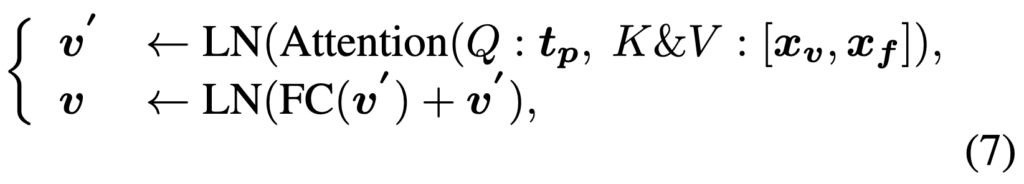
2.4 Training and Inference
다음은 학습과 추론 단계에 대한 설명입니다. 먼저 학습은 두 단계로 진행됩니다.
첫 번째 단계에서는 pseudo-query generator를 통해 생성된 tp가 실제 텍스트 쿼리 t와 유사하도록 학습합니다. 이를 위해 reconstruction loss를 사용하며, 이 단계에서는 인코더와 Fusion 모듈은 freeze 상태로 두고, generator의 가중치만 업데이트됩니다.
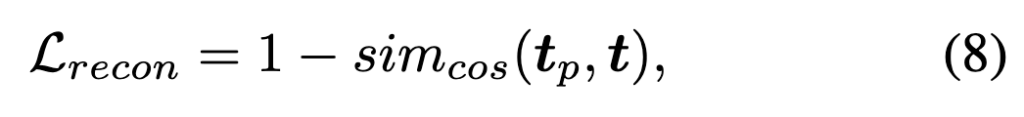
두 번째 단계에서는 generator 학습이 완료된 후, contrastive loss와 reconstruction loss에 가중치를 곱하여 최종 loss를 구성하고, 이를 통해 전체 모델을 fine-tuning합니다.
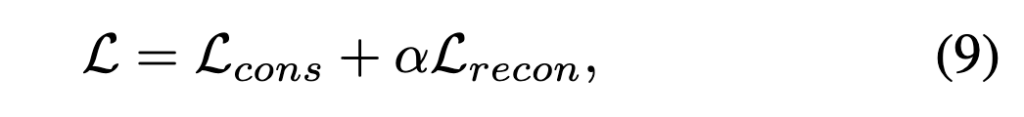
이 과정을 통해 저자의 모델은 텍스트 쿼리가 주어질때까지 기다릴 필요 없이 비디오 피처만으로 pseudo-query를 생성할 수 있습니다. 생성된 pseudo-query를 기반으로 fine-grained fusion을 수행하여 향상된 비디오 표현을 얻을 수 있고 미리 비디오 피처를 뽑아 저장할 수 있어 효율성을 고려한 프레임워크라고 할 수 있겠습니다.
3. Experiment
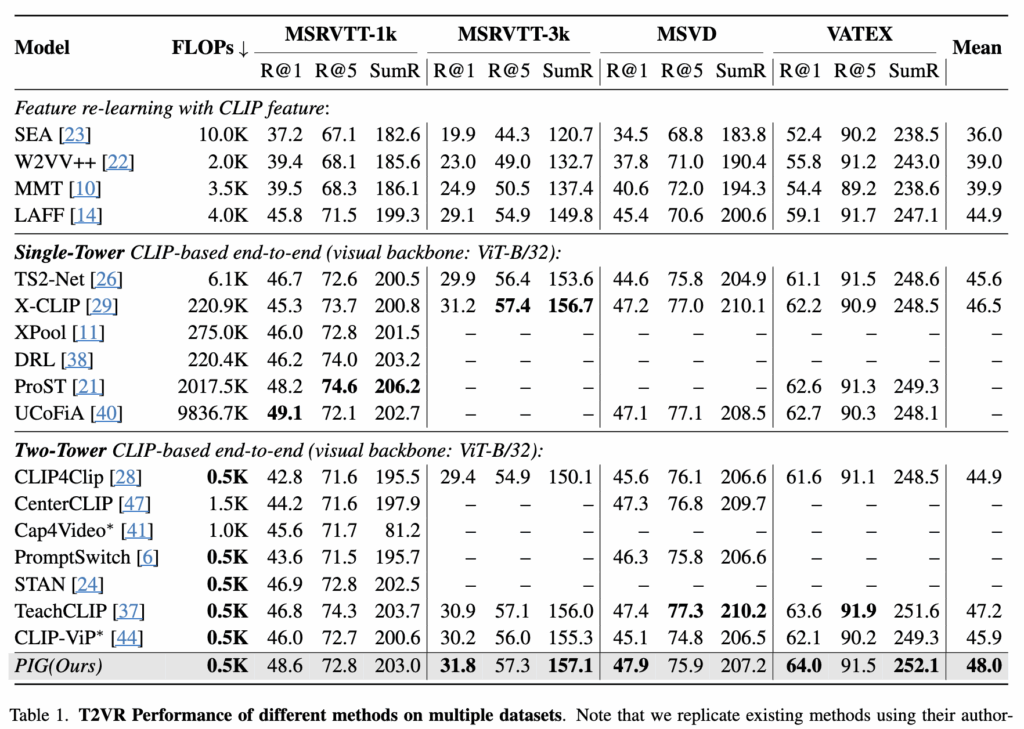
먼저 저자가 강조하고 있는 효율성에 대한 결과를 FLOPs를 통해 살펴보겠습니다. 위 테이블을 통해 알 수 있듯이 저자의 모델은 Two-Tower 구조를 그대로 사용하기 때문에 검색 과정에서 계산량이 Single-Tower에 비해 매우 효율적이라는 것을 알 수 있습니다. 그리고 여기서 중요한 점은, 비디오 피처를 미리 오프라인에서 뽑아 저장할 수 있다는 것이고 이를 통해 실제 검색 시에는 매칭할 때만 연산이 이루어져 훨씬 빠른 속도로 계산을 할 수 있습니다.
또한 계산량 이외에도 정확도 측면에서도 Two-Tower 구조 방법론들보다 성능이 높은 것을 확인할 수 있고 Single-Tower 모델들과 유사한 정확성을 보여주고 있습니다. 다만 위에 있는 벤치마크 성능은 저자가 직접 해당 방법론들이 공개한 소스 코드로 실험은 한 결과라 신뢰성 측면에서 다소 아쉬움이 있습니다.
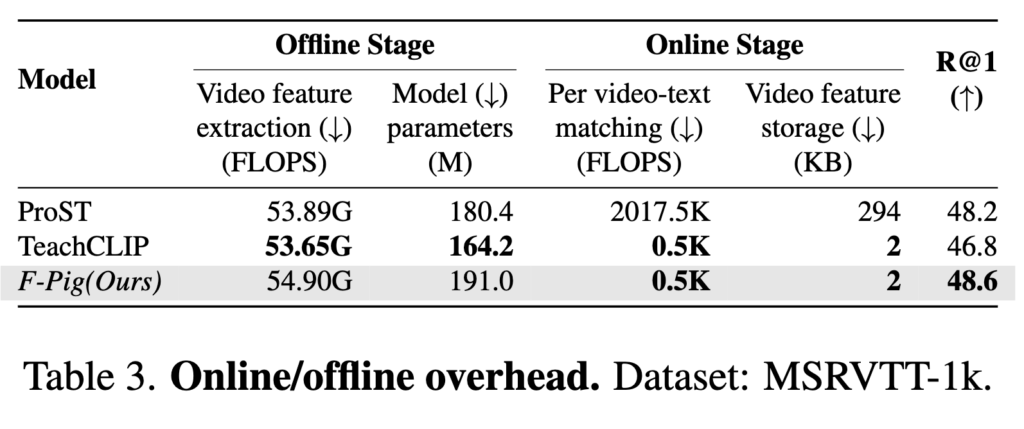
이 표에서는 ProST, TeachCLIP, 본 논문에서 제안하는 F-Pig의 efficiency과 effectiveness 을 비교한 결과입니다. 여기서 Offline Stage는 검색 쿼리가 들어오기 전에 미리 수행되는 작업에 대한 지표이고, Online Stage는 검색 쿼리를 입력했을 때 수행되는 작업에 대한 지표입니다.
저자의 모델은 Offline Stage에서 pseudo-query를 통해 비디오 피처를 향상 시킬 수 있기 때문에 미리 계산된 비디오 특징을 활용하여 빠르게 검색할 수 있습니다. 따라서 Online Stage에서 TeachCLIP과 동일한 수준으로 효율성을 달성할 수 있으며, 동시에 Single Tower 모델인 ProST보다도 높은 성능을 달성하며 efficiency과 effectiveness 모두 고려할 수 있음을 확인할 수 있습니다.
리뷰 잘 읽었습니다 몇 가지 궁금한 점이 잇어서 댓글 남기겠습니다.
pseudo-query generator가 CLIP text encoder를 초기화해서 [EOS] 토큰 출력을 pseudo-query로 사용한다고 했는데, 생성된 pseudo-query가 실제 텍스트 쿼리와 얼마나 semantic하게 align되는지 별도의 정성적/정량적 분석도 있었나요?
Pseudo-interaction fusioner에서 tp를 query로, xv/xf를 key-value로 사용하는 구조가 제안되었는데, 반대로 video feature를 query로 하고 tp를 key-value로 사용하는 설계하는 건 없나요? 왜 그렇게 설계했는지 아시나요?
안녕하세요, 주영님 질문 감사합니다.
저자는 생성된 pseudo-query와 실제 텍스트 쿼리를 t-SNE로 시각화한 결과, 두 쿼리가 비슷한 양상을 보이는 것을 확인하였습니다.
또한 Pseudo-interaction Fusioner에서 쿼리, 키, 밸류를 해당 방식으로 사용한 이유는 XPool의 어텐션 메커니즘을 그대로 따른 것입니다.
감사합니다.
안녕하세요 의철님 좋은 리뷰 감사합니다.
우선 소개해주신 방법론은, 검색 성능 향상을 위해 online 단계에서 했어야 하는 fine-grained interaction을 offline 때 미리 수행함으로써 성능과 효율성을 둘 다 잡은 방식으로 이해하였습니다.
저도 주영님의 첫번째 질문과 유사한 궁금증이 들었는데, recon loss를 통해 pseudo-query로서 만들어준 tp 값이 원본 텍스트 쿼리 특징과 유사해지도록 만들어준다면, 성능의 upper는 결국 실제 텍스트 쿼리가 입력된 상황에서의 검색 정확도일 것 같은데, 그에 대한 일종의 oracle 실험 성능은 없었는지 궁금합니다.
추가로 informativeness token selection 과정에서 토큰을 top 몇개만 추림으로서 성능과 효율성이 동시에 오른 것인지, 성능은 조금 떨어지되 효율성을 확실히 잡은 것인지 그 효과가 궁금합니다.
안녕하세요 현우님 질문 감사합니다.
말씀하신 것처럼, 실제 텍스트 쿼리를 사용했을 때의 결과가 있으면 좋겠지만, 본 논문은 실제 시나리오에서 적용 가능한 연구를 다루고 있어 oracle 실험 내용은 포함되어 있지 않은 것 같습니다.
Informativeness Token Selection에서는 패치를 16개만 선택했습니다. 다른 패치 개수에 대한 실험 결과는 없지만, 모든 패치를 선택하면 계산량이 증가할 뿐만 아니라 배경과 같은 불필요한 패치가 섞여 성능이 오히려 떨어질 수 있습니다. 따라서 본 방법은 성능과 효율성을 동시에 개선했다고 볼 수 있습니다.
감사합니다.
안녕하세요 의철님, 좋은 리뷰 감사합니다.
해당 방법론은 pseudo-query를 생성하여, 텍스트 쿼리와 유사한 특징을 가진 비디오 피쳐를 offline으로 미리 추출할 수 있다는 이점이 있다고 이해했습니다.
Pseudo-Interaction Fusioner 모듈이 XPool attention으로 구성되어 있다고 하셨는데, XPool attention이 무엇인지, 그리고 왜 이 구조를 선택했는지 궁금합니다.
감사합니다.