이번에 소개드릴 논문은 CVPR2024에 게재된 MobileCLIP이라는 논문입니다. 지난주에 리뷰한 논문도 애플에서 쓴 논문이고 지금 소개드릴 논문도 애플의 논문입니다. 애플이 2023년도에 CVPR이었나 탑티어 학회에서 FastViT라는 논문을 낸적이 있었는데, CLIP을 시작으로 multi-modal 쪽 연구가 활발히 진행되고 있어서 그런지 애플도 꾸준히 CLIP의 경량화 모델을 만들어 내려고 노력하고 있는 듯 보입니다. 특히 FastViT 때도 그랬지만 애플은 항상 backbone 관련 논문을 낼 때 애플 아이폰에서 latency를 측정하곤 하는데, 이번에도 애플 아이폰12 pro max에서 MobileCLIP에 대한 latency도 측정하는 모습이네요.
아무튼 지난주에 제가 작성한 Data Reinforcement 개념이 MobileCLIP에서 똑같이 활용되니 지난주 리뷰를 읽으셨다면 해당 리뷰도 상당히 쉽게 이해가 될 것이라고 생각됩니다.
Intro
인트로 굵고 짧게 요약드리겠습니다. 저자들의 목적은 모바일 디바이스에 적합한 aligned image-text encoder를 만드는 것입니다(논문 제목부터가 MobileCLIP인 것에서 저자들이 하고자 하는 것이 명확하죠).
근데 아마 모든 분야에서 경량화 하면 항상 발생하는 것이 아래 문제입니다. 첫째로는 정확도와 속도의 trade off 관계를 해결해야하는 것이죠. 둘째로는 작은 모델일수록 모델 자체의 캐파시티가 떨어져 도달할 수 있는 성능에 한계가 있다는 것이고 이를 극복하기 위해서는 무언가 더 나은 학습 기법이 필요로 하다고 저자들은 주장합니다.
그럼 가벼운 모델을 학습시킬 때 해당 모델의 성능을 어떻게 끌어올릴 수 있을까요? 가장 직관적이고 많이 활용하는 방식은 Knowledge Distillation 입니다. 무거운 모델의 knowledge를 가벼운 student model에게 전이하는 것이죠.
근데 이제 지난주 리뷰에서 설명드렸지만 무거운 모델을 student model 학습할 때 항상 같이 추론시켜서 knowledge를 추출하는 과정이 상당히 비효율적입니다. 가벼운 모델은 빠르게 학습이 가능하지만, 무거운 모델을 forward 해야하기 때문에 메모리도 많이 들고 학습 시간이 배가 넘게 걸리게 됩니다.
그래서 애플은 지난주에 제가 리뷰한 논문을 통해 Dataset Reinforcement라는 개념을 새로 제안하였습니다. 즉 다양한 augmentation을 적용한 데이터를 다수의 Teacher model에게 전달해주고 이들의 knowledge를 앙상블해서 학습 데이터에 같이 저장해두는 것이죠. 이렇게 knowledge와 augmentation에서 활용한 인자등을 잘 저장해두었다가 student model을 매번 학습시킬 때 해당 데이터를 입력 데이터와 같이 불러와 학습 때 활용한다는 것입니다. 이렇게 되면 student model을 매번 새로 학습시킬 때마다 데이터만 불러와서 student model은 그저 forward와 미리 뽑아둔 teacher model의 knowledge를 비교 학습하는 방식을 취할 수 있어 학습 시간이 매우 효과적으로 줄어든다는 것입니다.
마찬가지로 mobileCLIP을 만들 때 역시 이 dataset reinforcement 기법을 활용합니다. 참고로 2023 ICCV에 게재된 Dataset Reinforcement는 Vision backbone만을 고려한 방식이라 학습 데이터도 ImageNet 기반으로 진행하였고 데이터의 모달리티도 Image만을 활용했었습니다.
그러나 지금 논문은 text와 image 모달리티를 모두 활용하는 것이기 때문에, multi-modal dataset에 알맞는 dataset reinforcement가 새롭게 필요합니다. 그래서 MobileCLIP 논문의 가장 핵심 contribution은 multi-modal dataset을 어떻게 reinforcement 할 수 있는가에 있습니다.
결론부터 말씀드리면, 저자들은 image-text dataset인 DataComp라는 데이터셋에 합성 캡션과 사전학습된 CLIP 모델의 앙상블로부터 추출한 임베딩을 추가하는 방식으로 데이터셋을 강화하였다고 합니다. 이를 통해 저자들은 빠르고 효율적으로 모델을 학습시키기 위한 DataCompDR-12M이라는 데이터셋과, 모델 성능을 극한까지 끌어올리기 위한 DataCompDR-1B 데이터셋을 만들게 되죠.
그리고 저자들은 모바일 환경에서 적합한 Image-text encoder를 만들기 위해 latency와 accuracy 사이의 trade off 관계를 고려한 모델 구조를 새로 제안하는데 architecture와 관련된 contribution의 novelty는 제가 느꼈을 때 앞서 언급한 dataset reinforcement와 비교해서는 weak contribution이라고 저는 생각이 듭니다. 기존의 애플의 논문인 FastViT의 기법들을 text encoder 설계할 때 활용했다? 정도로 보여서요.
아무튼 해당 논문의 2가지 contributions (multi-modal dataset reinforcement, architecture design)에 대해서는 바로 밑에 method에서 더 자세히 설명드리겠습니다.
Multi-modal Reinforcement Training
우선 multi-modal dataset을 어떻게 reinforcement하였는지에 대해서 다뤄보겠습니다. 저자들의 dataset reinforcement는 크게 2가지로 구성되어있습니다. 첫째로, 이미지 캡셔닝 모델의 지식을 활용하고자 SOTA 이미지 캡셔닝 모델로 합성 캡션들을 생성하였다고 합니다. 또한 사전학습된 CLIP 모델의 앙상블을 이용하여 image-text alignment의 knowledge distillation을 수행하기 위한 image/text 임베딩을 추출합니다.
상당히 간단하죠? 이 과정에 대해서 그림으로 나타내면 다음과 같습니다.
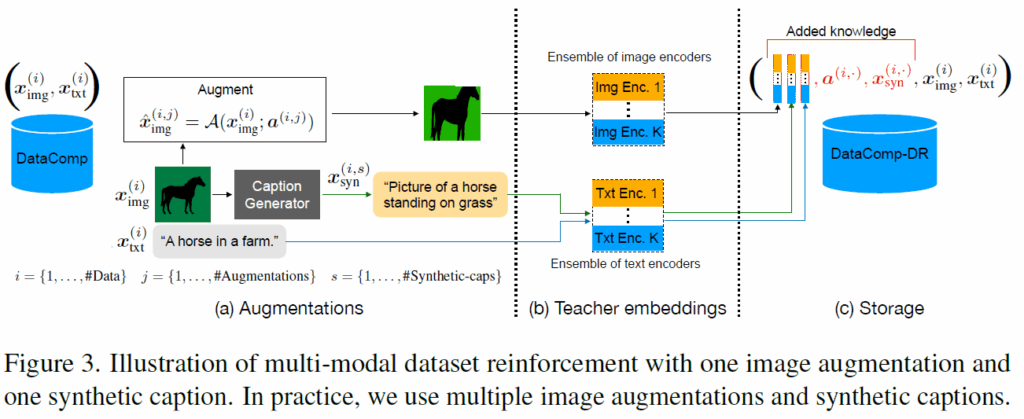
일단 Dataset을 augmentation 과정에서 image에다가 random crop & resize, random erase&augment 등등 다양한 augmentation을 취해주었던 기존의 dataset reinforcement 방법론에서 이번에 조금 더 새롭게 추가된 것은 사전학습된 이미지 캡셔닝 모델을 활용한다는 점입니다.
기존에 CLIP을 학습시킬 때 사용했던 Image-text dataset은 웹 크롤링을 해서 모은 것이다보니 내재적인 노이즈가 존재합니다. 허나 최근에는 DataComp와 데이터 필터링 네트워크들을 통해 웹 기반의 데이터셋의 퀄리티가 많이 향상되었다고 하네요. 그러나 저자들은 비록 데이터셋이 필터링을 거쳐 노이즈는 많이 줄어들긴 했지만 image에 대응되는 caption은 여전히 충분한 서술이 잘 되지 않는다고 주장합니다.
그래서 저자들은 visual image에 대한 시각적 묘사를 더 향상시키기 위해, CoCa라고 하는 이미지 캡셔닝 모델을 사용하여 각 이미지 별로 다양한 합성 캡션을 생성하였다고 합니다.

위에 그림5가 실제 데이터셋의 GT 캡션과 CoCa라는 모델을 통해 생성한 합성 캡션의 예시라고 합니다. Real Caption의 경우에는 합성 캡션에 비해 일반적으로 더 구체적으로 서술되어 있지만 반대로 노이즈도 더 크다고 합니다. 그림 5의 예시에서 real caption이 “A four bedroom town house 20 paces from the beach”라고 표기되어 있는데 저 해변가 그림에서는 해당 캡션의 beach 말고는 전혀 매칭이 안되는 모습이죠.
그러나 Synthetic caption의 경우에는 실제 해당 이미지만을 보고 모델이 생성하는 것이기 때문에 엄청 구체적인 설명은 아닐지어도 영상과 그에 대응되는 캡션이 서로 엉뚱하지는 않다는 것이 저자들의 설명입니다. 즉 노이즈를 완화시킬 수 있다는 것이죠.
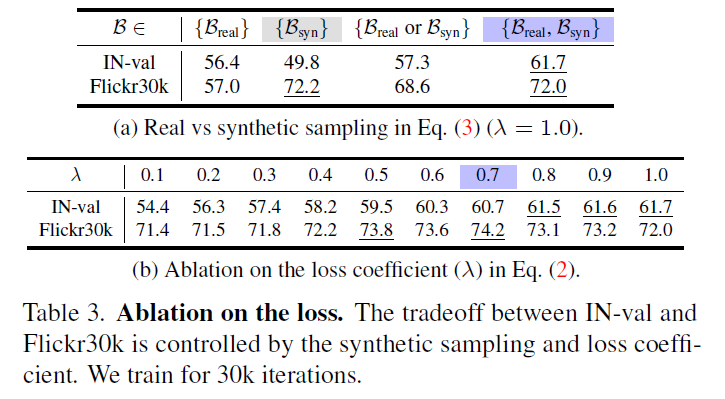
실제로 저자들이 합성 캡션 데이터를 추가하여 dataset reinforcement를 진행하고 이를 토대로 MobileCLIP을 학습시켰을 때의 ImageNet zero shot classification 성능과 Flickr30K zero-shot image retrieval 성능을 위에 표에서 볼 수 있습니다.
Synthetic caption만을 가지고 학습시킬 때와, Real Caption만을 가지고 학습을 시켰을 때를 비교해보면, real caption을 쓰는 경우 ImageNet에서의 성능이 더 높게 나오지만(56.4 vs 49.8 accuracy), Flickr30K 데이터셋에서의 retrieval 성능의 경우는 반대로 합성 셋을 사용하는 것이 더 좋은 성능을 보여줍니다 (57.0 vs 72.2 recall).
이런 식으로 각각 수행하는 task나 데이터셋 별로 모델의 zero-shot 성능 경향이 크게 달라지게 되는데, 이 둘을 적절히 섞어서 학습시키는 경우 Image classifiaction과 retrieval에서 모두 다 좋은 성능을 보여주는 것을 확인할 수 있었습니다. 특히 ImageNet에서는 61.7%의 정확도로 real-caption만 쓰는 것보다 5.3% 더 높은 성능 향상을 보여주네요.
정리하자면 text 모달리티의 경우, 기존 GT text caption에다가 어떠한 augmentation을 취하는 것이 아닌 SoTA 이미지 캡셔닝 모델을 통해서 데이터를 증강시켰다고 보시면 될 것 같습니다.
그리고 Image 모달리티에서는 기존의 연구처럼 다양한 영상처리 관점에서의 image augmentation을 수행하게 됩니다. image augmentation과 관련해서 저자들은 아래 수식으로 설명합니다.
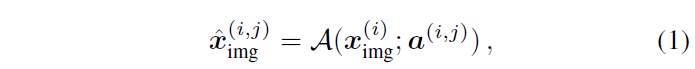
여기서 x^{i}_{img}, a^{(i,j)} 는 각각 i번째 원본 이미지 샘플과 i번째 이미지에게 적용되는 j번째 augmentation 종류를 의미합니다. 이를 토대로 \hat{x} 이 augmented image가 되는 것이죠.
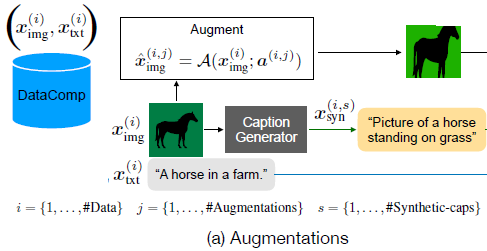
다시 그림 살펴보겠습니다. Data augmentation에서는 결과적으로 Image Data에 대해 #개의 Data augmentation을 랜덤하게 적용하고, text에 대해서도 이미지 캡셔닝 모델을 통하여 합성 캡션을 생성합니다(해당 캡션이 몇번째 캡션인지는 문자 s를 통해서 표기합니다.).
Ensemble Teacher
다음은 teacher model의 knowledge를 student model에게 distillation하기 위해서 수행되는 teacher embedding 추출 과정입니다.
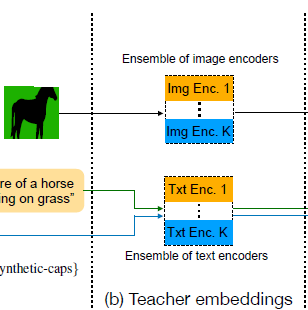
그냥 직관적으로 살펴보시면 augmentation이 수행된 이미지와 GT Text/합성된 Text를 k개의 teacher model에게 입력으로 주어서 이들의 output embedding을 저장해두는 것입니다.
저자들은 사전학습된 CLIP model들을 teacher network로 활용하였으며, CLIP model을 2개정도? 사용한 것으로 보이는데 이렇게 앙상블을 적용하는 이유는 이전에 ICCV2023에 게재된 dataset reinforcement 방법론에서 teacher model의 앙상블이 가장 knowledge distillation 수행하는데 있어서 좋은 teacher다 라는 점을 그대로 응용한 것으로 보입니다.
이렇게 추출된 teacher embedding은 원본 영상 및 그와 대응되는 GT text 데이터와 함께 저장이 됩니다.
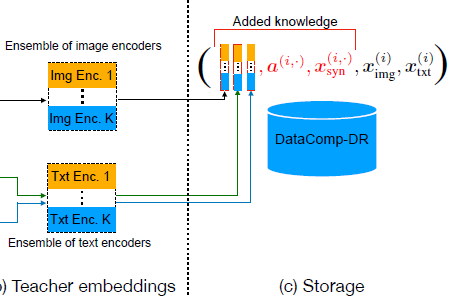
또한 teacher embedding을 추출하고자 입력으로 사용한 영상을 만들 때의 augmentation 인자 값들과 합성 캡셔닝도 같이 저장을 합니다. 이 과정은 단 한번만 진행하면 되는거라 이후에 다양한 구조, 사이즈의 student model을 학습시킬 때 reinforced dataset을 불러와서 학습시키면 되는 것이라 학습 비용을 상당히 크게 줄일 수 있습니다.
Training
그럼 이제 모델 학습이 어떻게 진행되는지를 알아보겠습니다. 사실 모델 학습은 매우 간단합니다. 우선 기존의 CLIP이 학습하는 방식인 Text embedding과 Image embedding 사이의 contrastive learning을 수행하는 loss가 하나 존재합니다.
거기에 저자들의 reinforced dataset의 경우에는 teacher model들의 embedding이 같이 제공이 되어 있습니다. 그래서 이 embedding을 학습시키기 위한 loss가 필요로 하게 됩니다. 저는 처음에는 그냥 student model이 추출한 image embedding과 text embedding이 있으면 이들 embedding 값을 teacher model의 image/text embedding과 코사인 유사도 등을 계산하는 방식 등을 채택할 것이라고 생각했습니다.
근데 그 방식보다는 저자들은 image embedding과 text embedding에 대해서 내적 연산을 통해 상관관계를 계산한 후 임베딩 벡터의 차원 축에 대하여 softmax를 취함으로써 유사도 행렬을 만든 뒤 student embedding의 유사도 행렬과 teacher embedding의 유사도 행렬 간 KL Divergence loss를 계산하는 식으로 진행하더라구요.
수식으로 나타내면 다음과 같습니다.
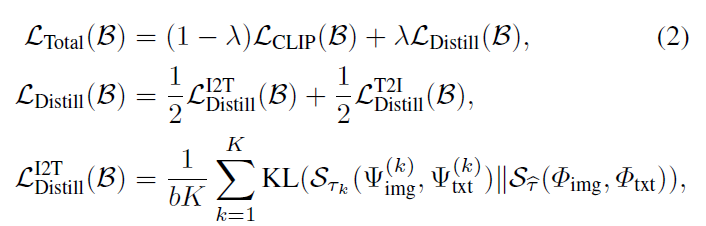
즉 Total loss는 CLIP loss와 Distill Loss로 구성이 되어있는데, 여기서 CLIP loss는 Image와 GT text에서 추출한 embedding 사이의 loss 계산이라고 이해하시면 되겠습니다. 그리고 Distill loss의 경우에는 바로 위에서 소개드린 KL Divergence loss인데 S_{\mathcal{T}_{k}}(U, V) 는 U와 V의 내적 계산 후 행축에 softmax를 취한 유사도 행렬이라고 생각하시면 되겠습니다. 저 삼지창?은 text와 image 모달리티에 대한 embedding을 의미하고 k는 k개의 teacher model의 순서를 의미합니다.
그리고 augment image와 real text/synthetic caption을 통해 loss 계산이 따로 진행되다보니 저자들이 데이터로더에서 iteration마다 읽어오는 데이터의 배치도 2종류가 됩니다. 즉, augment image GT text caption을 매칭시키는 배치와 augment image와 synthetic caption을 매칭시키는 배치로 따로 묶어서 전체 forward-backward 과정이 수행된다고 하네요. 그래서 최종적인 loss 계산은 아래 수식처럼 2종류의 배치의 합으로 진행이 된다 합니다.
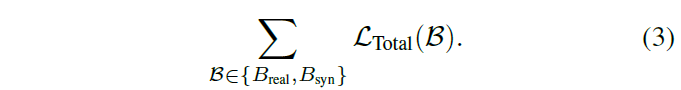
Text Encoder Architecture
마지막으로 모델 구조 변경점에 대해서 소개드리겠습니다. 저자들이 Text encoder의 성능 향상 및 효율성에 대한 trade-off를 고려하여 기존 CLIP architecture를 수정하였다고 합니다.
참고로 기존 CLIP의 text encoder는 Self-attention의 transformer로 구성이 되어있는데 이는 text encoding을 매우 효과적으로 수행할 수 있지만, 연산량 많이 먹기에 가볍고 효율적인 모델을 추구하는 입장에서는 그대로 사용하기 어렵게 됩니다.
최근 연구 중 하나는 컨볼루션이 텍스트 인코딩을 하는데 있어서 효과가 주장하는데, 저자들이 확인해보니 컨볼루션 구조만을 사용하는 것은 트랜스포머 대비 성능이 상당히 떨어졌다고 하네요. 그래서 저자들은 1D 컨볼루션만 활용하는 기존 연구와 달리 self-attention과 1D 컨볼루션을 적절히 섞어쓰는 하이브리드 방식으로 텍스트 인코더를 구성하였다고 합니다.
결과적으로, Text-RepMixer라는 컨볼루션 기반 토큰 믹서를 제안하는데, 이는 학습과 추론 단게에서 구조가 디커플링된다고 합니다. 저자들은 FastViT의 reparameterizable convolutional token mixing (RepMixer)에서 영감을 받았다고 하며, 추론 단계에서 skip connection 과정이 reparameterized 된다 합니다.
여기서 Reparameterization 개념이 생소하신 분들이 있으실텐데, 이게 저도 이론적 개념은 잘 모르지만 예전부터 학습 때 사용하는 연산을 추론 때는 빼버림으로써 성능과 효율성을 동시에 챙기는 방식들이 있긴 했었거든요?
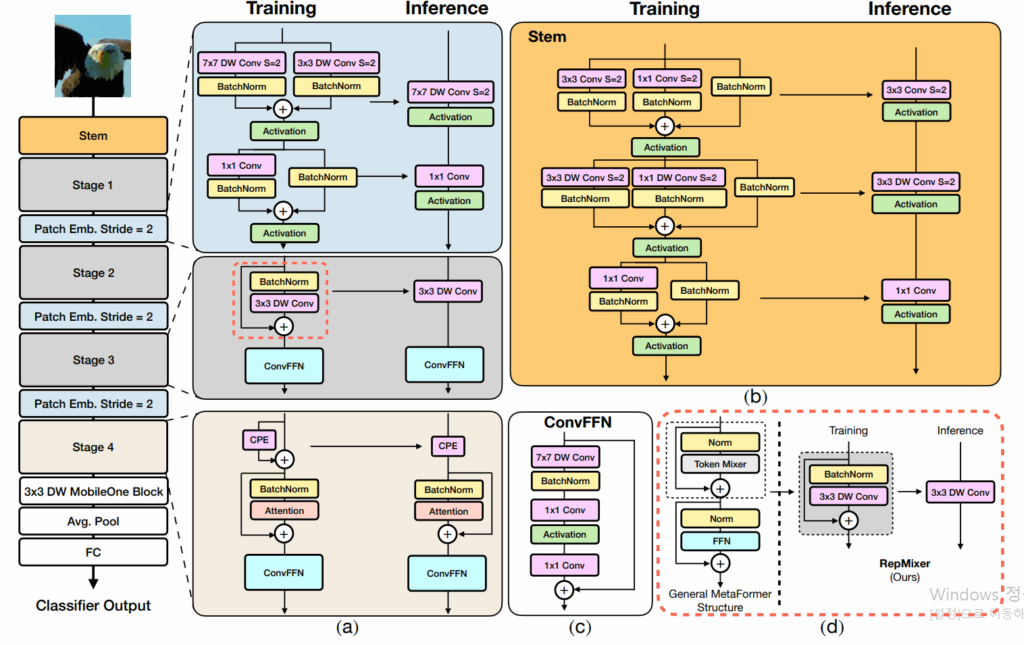
위에 그림이 FastViT의 구조인데 보시면 Training / Inference라고 나뉘어진 부분이 있는데 Training 단계에서는 Skip Connection과 Batch normalization이 있고, 또 7×7 DW Conv와 3×3 DW conv 등이 있었다면 추론 단계에서는 그저 7×7 DW Conv와 Activation만 있으면 되더라? 라는 그런 개념입니다.
저게 관련 연구 타고 가다보면 이론적으로 왜 저게 가능한지?에 대한 것을 쭉 작성한 논문이 하나 있는데 제가 그거 예전에 읽다가 이해가 안돼서 포기한 기억이 있어서… 지금은 다시 읽으면 이해가 되려나요 허허. 아무튼 저렇게 학습에 사용된 연산을 추론 단계에서 생략해버리는 과정을 reparamterization이라고 하고 MobileCLIP에서도 text encoder 설계 단계에서 해당 reparamterization을 적용했구나 라고 이해하고 넘어가시면 좋을 것 같아요.
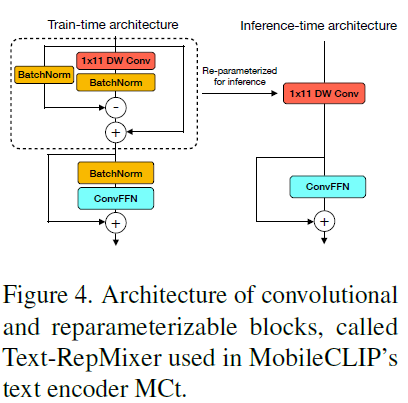
그래서 그림4 살펴보시면 실제 MobileCLIP의 text encoder도 BatchNorm과 SKIP connection이 여런 존재하는데 추론 단계에서는 그저 1×11 DW conv와 ConvFFN만 구성되는 모습입니다. 저자들은 이 1×11 DW Conv를 convolutional token mixer라고 이야기하네요.
그리고 저자들은 text encoder 설계 과정에서 우선 초반에는 순수히 컨볼루션 연산으로 구성된 세팅에서 점차 컨볼루션 블록을 self-attention layer로 바꾸어나가면서 최적의 CNN-Transformer 하이브리드 구조를 찾아갔다고 합니다.
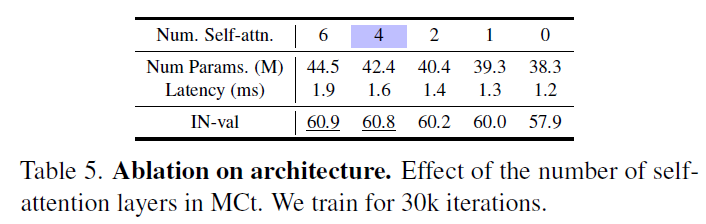
그리고 위에 표5가 그에 대한 실험 결과인데, 결과적으로는 Self-attention이 전혀 안들어간 (즉 숫자가 0)인 경우 IN zero-shot 성능이 57.9인 것에 반해 Self-attention을 6까지 적용한 것이 60.9로 성능이 3%정도 차이가 나는 것을 확인할 수 있습니다. 대신에 latency도 1.2ms에서 1.9ms로 거의 70% 정도 증가하는 모습이죠. 최종적으로는 self-attention을 4개정도 넣는 것이 성능도 0.1% 밖에 드랍이 발생하지 않으면서 latency도 0.4ms정도로 33%정도만 늘어났다고 합니다.
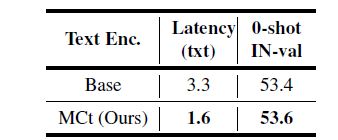
그리고 기존 CLIP의 text encoder를 Base라고 표현하였는데, 저자들의 text encoder는 CLIP text encoder와 비교해서 ms가 3.3 vs 1.6으로 무려 2배가 넘게 줄어든 것을 볼 수 있으며 오히려 성능은 0.2% 개선이 되었다는 점에서 속도도 빠르게 하고 성능은 올려버리는 매우 이상적인 상황을 연출하였습니다.
Experiments
다음은 실험 결과들 공유하고 리뷰 마치도록 할게요. 제가 중간중간에 method 설명하면서 ablation 실험들을 언급했기 때문에 여기서 소개드릴 실험이 그리 많지는 않을 듯 싶습니다.
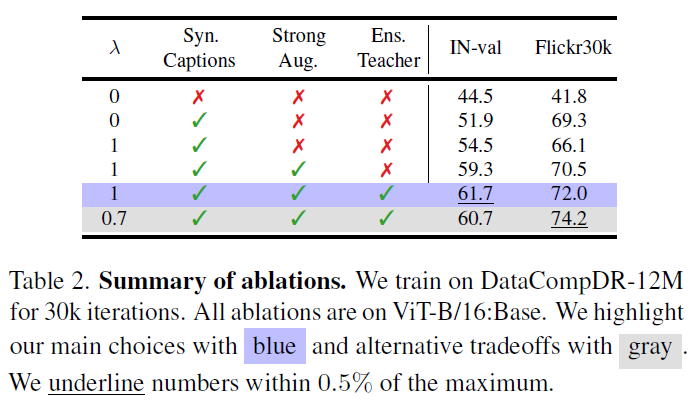
위에 표2는 저자들의 dataset reinforcement 과정에 대한 augmentation입니다. 저기 람다의 경우에는 loss 설명에서 언급한 수식2에서 기존 CLIP의 loss 계산과 KD distillation loss에 대한 비율을 의미하는 것입니다 (아래 수식 참고).
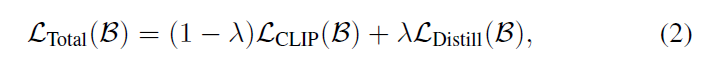
즉 람다가 0이라는 뜻은 knowledge distillation을 전혀 사용하지 않는다는 것이고, 그냥 기존 CLIP의 학습 방식을 적용하는데 이때 배치에 Real Text와 합성 caption을 적절히 섞어서 학습한 결과라고 합니다. 결과적으로 Synthetic caption을 사용하는 것만으로도 classification과 retrieval에서 성능이 크게 개선이 되는 모습입니다.
그리고 람다 값이 0이 되면 이때는 기존 CLIP loss는 사용하지 않고, teacher model의 embedding 결과를 통한 distillation loss만 적용한다는 것이고, 이때 성능 개선폭이 또 유의미하게 증가하는 모습입니다.
그리고 image에다가 strong augmentation을 취했을 때 retrieval에서는 성능 향상이 살짝 미미하게 증가하는 반면에 Image Classification에서 매우 크게 증가하는 것을 볼 수 있고, 이는 image level에서 strong augmentation을 취하는 것이 분류쪽 task에서 성능 향상에 크게 도움이 되었더라 라고 볼 수 있겠습니다.
그리고 teacher model에서 embedding을 추출할 때 하나의 teacher model을 쓰는 것이 아닌 앙상블을 사용하였을 때 얼만큼 성능 개선이 되는지를 보는 것이 맨 밑에서 2번째 실험 결과이고, 마지막으로 CLIP loss와 distillation loss를 3:7의 비율로 적용하였을 때 리트리벌에서는 가장 좋은 성능을 보여주고 image classification에서도 1% 정도 하락이 있긴 하지만 리트리벌의 성능이 개선폭이 커서 최종적으로는 람다를 0.7로 두었다고 하네요.
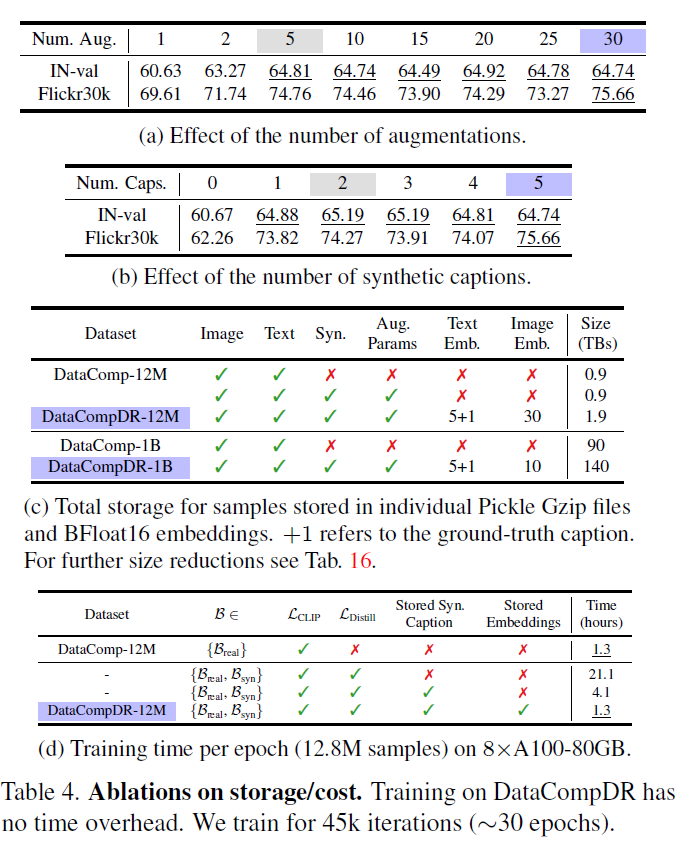
그리고 다음은 하나의 image 샘플에 대해 몇개의 augmentation 이미지를 추출하는지 그 수와, 합성 캡션 데이터의 개수 등에 대한 ablation 실험 결과입니다. 결론부터 말씀드리면 Image 증강 수를 30개, 합성 캡션 데이터의 수를 5개로 하였을 때 성능이 크게 개선되지는 않고 이미지 증강 5개, 합성 캡션 2개 썼을 때와 성능 차이가 비슷한 것 같아서 저자들은 데이터 저장 비용 관점을 고려하였을 때 dataset reinforcement 과정에서 샘플 당 이미지 증강 수는 5개, 합성 캡션 생성은 총 2개로 정하였다고 합니다.
그리고 저장 공간 관련돼서는 표4-c를 살펴보시면 되는데, 12M 데이터셋과 1B 데이터셋에서 원본 데이터가 차지하는 크기는 0.9테라와 90테라였다면, 저자들의 reinforecement의 경우 teacher model의 임베딩을 저장해야하다보니 저장공간이 각각 1.9, 140테라로 늘어나는 모습입니다.
저게 학습 시간을 크게 줄일 수 있다는 점에서는 각각 1테라, 50테라 정도는 비용을 지불할 수 있지 않나? 라는 생각이 들기도 하구요. 근데 또 결코 적지 않은 비용이다 라고 생각할 수도 있어서 사용자의 개인적 판단에 맡겨야할 것 같습니다.
다만 저자들은 이 임베딩이 Float 32로 구성하면 너무 많은 공간을 차지하는지 BFloat16으로 양자화해서 저장했다고 하는데 저자들 주장으로는 32로 하나 16으로 하나 모델의 성능에는 크게 차이가 없어서 공간 효율성을 위해 Float16으로 내려서 저장했다고 합니다.
결과적으로, 저장공간만 넉넉하면 표4-d에서 보시다시피 실제 DataComp-12M 데이터셋으로 학습할 때와 저자들의 reinforcement dataset인 DataCompDR-12M으로 학습시킬 때의 training time이 동일한 것을 볼 수 있습니다.
Comparison with small CLIP model
자 그럼 저자들의 MobileCLIP이 다른 VLM과 비교해서 얼마나 좋은지?에 대해서 정량 비교해보겠습니다.
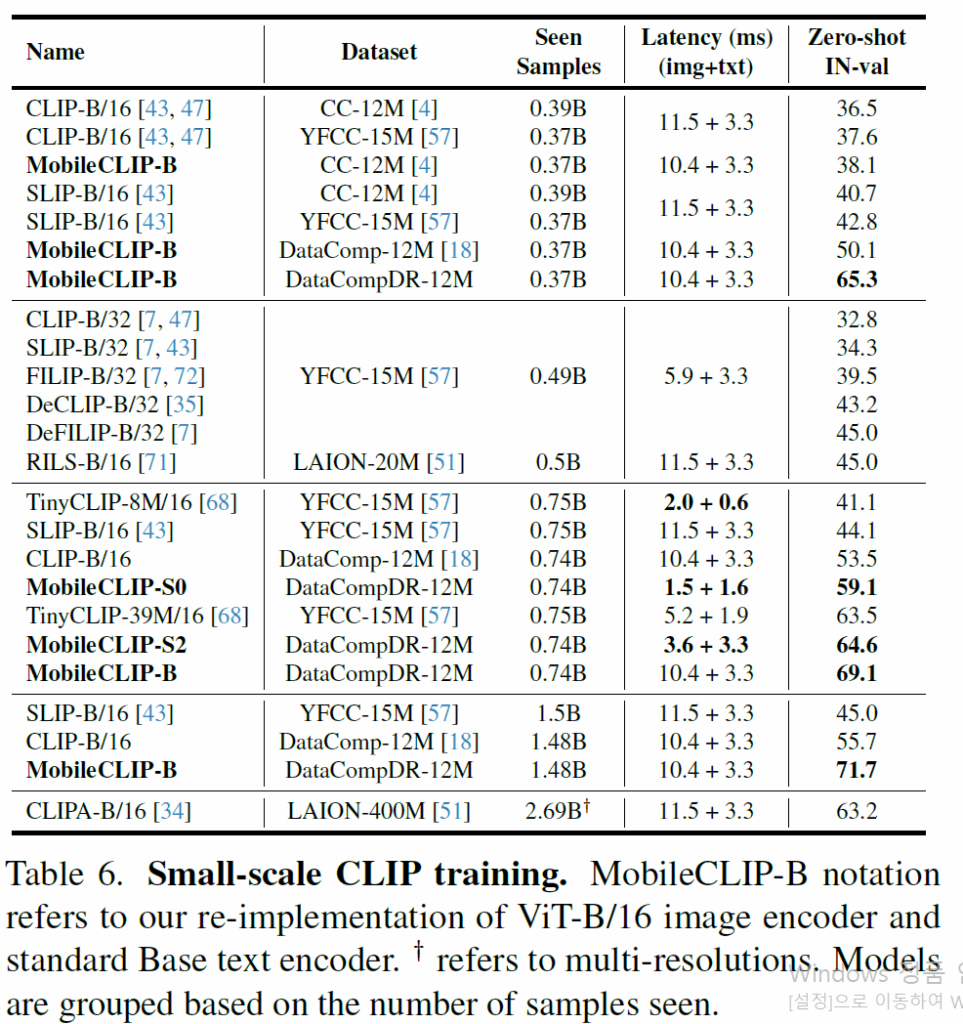
우선 CLIP-B/16 모델이 DataComp-12M으로 학습하였을 때 성능이 저자들의 MobileCLIP-S0가 DataCompDR-12M(데이터셋 강화된 버전)으로 학습했을 때와 성능을 비교해보면 53.5 vs 59.1 accuracy로 5.6%정도 뒤처지는 것을 볼 수 있습니다. 놀라운 점은, latency가 CLIP-B/16은 13.7ms인 반면에 MobileCLIP-S0는 3.1ms로 무려 4배나 넘게 차이가 나는데도 MobileCLIP이 더 좋은 성능을 보여준다는 것이죠.
그리고 그 외에 SLIP, TinyCLIP 등등의 방법론들과도 비교해보면 저자들의 방법론이 더 빠르면서 정확한 것을 볼 수 있습니다. 근데 이제 SLIP이나 TinyCLIP 같은 애들은 YFCC-15M? 이라는 데이터셋으로 학습하는 등 저자들의 DataCompDR 데이터셋이랑 다른 데이터셋으로 학습을 한 바람에 직접적인 비교는 어렵습니다. 저자들도 이를 의식했는지 Seen sample 수를 보여주는 컬럼을 추가함으로써 학습 때 본 데이터셋의 규모가 비슷함을 어필하고 있습니다.
즉 비슷한 양의 데이터로 학습했는데 더 좋은 성능을 자신들이 보였다는 것이죠.
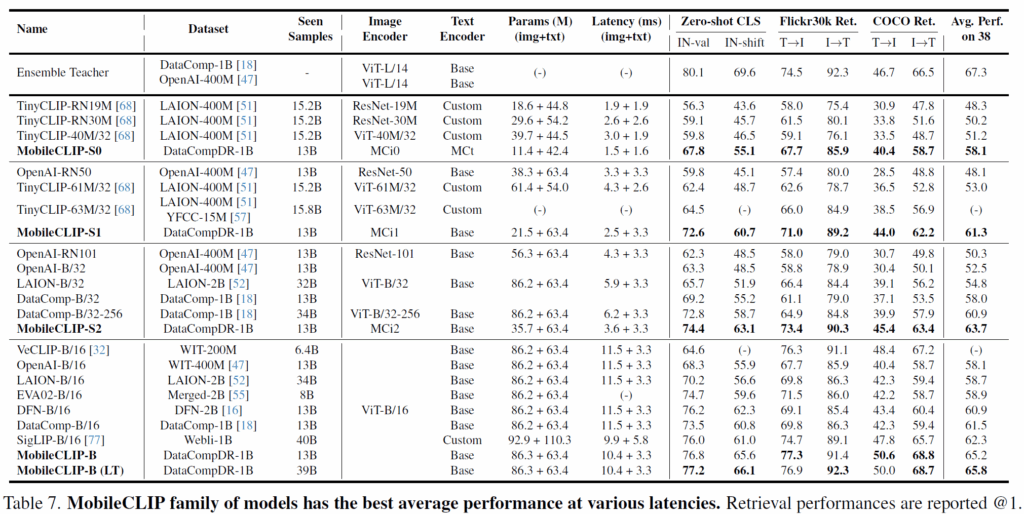
그 외에도 자신들의 MobileCLIP-S0~B가 zero-shot classification, Flickr30k Retrieval, COCO Retrieval 등등에서 기존의 연구들과 비슷한 크기의 파라미터 수를 맞추거나 학습 때 본 양의 데이터를 맞추거나 등등 최대한 공평한? 상황에서 항상 좋은 성능을 보여주고 추론 속도도 비슷하거나 훨씬 더 빠르다 라는 것을 저자들이 강조하고 있습니다.
결론
CLIP이 등장하면서 정말 다양한 task들이 확장되어 연구가 진행되고 있고, multi-modal 분야에서 특히 CLIP을 베이스로 많이들 연구를 하고 있는 것으로 알고 있는데 이게 비디오 레벨로 확장되거나 그렇게 되면 결국 기존 CLIP이 무겁긴 하잖아요? 그런 관점에서 MobileCLIP을 사용해봐도 좋긴 하겠다 라는 생각이 드네요.
그리고 이 논문이 작년 CVPR2024에 나왔는데 벌써 올해 어디 붙었는지는 미정이지만 MobileCLIPv2가 또 등장했더라구요. 멀티 모달쪽 연구를 해야하는데 연산 비용이 너무 많이 들어서 연구가 어렵다고 생각이 드시는 분들은 한번 mobileCLIP을 활용해보면 어떨까 싶습니다. 물론 기존 연구들이 다 CLIP을 쓰는 바람에 fair comparison을 위해서 CLIP을 고집해야 될 수 밖에 없을 수도 있겠지만서도요.