안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 CVPR 2024에 게재된 논문으로, DETR 구조를 기반으로 Video Scene Graph Generation을 수행한 논문입니다. 리뷰 시작하도록 하겠습니다.

Introduction
Scene Graph Generation은 보다 높은 수준의 scene understanding을 수행하고자 하는 태스크로, 주어진 이미지 내의 물체들을 식별하고 이들 간의 관계를 예측해 시각 정보를 지식 그래프 형태로 기술하는 것을 목표로 합니다. 보통 Object Detection 수행 이후 탐지된 objects간의 관계를 예측해 <주어-서술어-목적어> triplet 형태의 예측 결과를 출력합니다. 이런 형태로 주어진 영상 데이터를 표현하면 보다 semantic한 정보를 잘 추출할 수 있어 Visual Question Answering, Visual Commonsense Reasoning, Image Generation 등의 task를 수행하는데 도움을 주는 등 응용 분야가 많을 것으로 기대를 받았고, 이후 3D, depth, video 데이터로도 확장되었습니다.
video scene graph generation(VidSGG)는 이를 비디오 데이터 도메인으로 확장한 것으로, 비디오 시퀀스를 입력받아 각 프레임의 subject, object와 이들 간 관계를 예측하고자 합니다. 기존 연구들은 보통 2-stage로 수행되었는데, Faster-RCNN과 같은 기존의 object detector를 활용해 모든 frame의 물체를 식별하고, 이후 tracker, tracklet등 시간적 정보를 처리할 수 있는 모듈이나 알고리즘을 활용해 인접 프레임들 간 시간 정보를 모델링 한 후, 시간적 정보를 고려하여 탐지된 물체들 간 relation을 후처리 하는 방법이 주로 사용되었습니다. end-to-end가 아닌 두 단계로 나눠 수행되기에 필연적으로 sub-optimal하였고, 검출된 객체들을 모두 처리해야 하므로 상당한 양의 negative sample이 섞인다는 단점이 있었다고 합니다. 또한 tracklet을 구성하거나 3D convolution을 도입하는 등 연산적인 부담이 컸다고 하네요.
저자들은 DETR 구조를 기반으로 Video Scene Graph Generation을 수행하는 모델을 제안합니다. DETR 구조를 기반으로 기존의 두 단계로 나뉘어 있던 예측 과정이 1-stage로 수행이 가능해졌고, 객체 및 이들 간 관계를 예측하는데 시공간 정보를 모두 반영하여 수행할 수 있게 되었습니다. 우선 공간적 정보를 활용해 object detection과 relation prediction을 수행하기 위해 detection을 담당하는 transformer decoder, relation prediction을 담당하는 transformer decoder를 배치하였고, 이들의 출력값을 temporal aggregation module을 거치게 해 temporal 정보를 반영할 수 있도록 했습니다.
저자들이 주장하는 contribution을 정리하면 다음과 같습니다 :
- 우리는 Video Scene Graph Generation를 pair-wise feature를 활용한 set prediction 문제로 모델링하는, OED라는 간단한 end-to-end VidSGG 프레임워크를 제안하였다.
- relation의 temporal dependency를 효과적으로 반영하기 위해 추가적인 tracker 없이 temporal context를 통합할 수 있는 Progressively Refined Module (PRM)을 제안한다. 이를 통해 모델이 End-to-End 학습이 가능하다.
- Action Genome 데이터셋을 활용한 벤치마크에서, 우리가 제안한 프레임워크가 우수한 결과를 보였다.
지금부터 자세한 방법론 디테일을 살펴보겠습니다.
Method
Task Formulation
Video Scene Graph Generation(Dynamic Scene Graph Generation이라고도 부릅니다)에서는 비디오 시퀀스가 들어오면, 이들 중 target sequence에서 발생한 시각적 관계들을 탐지하고자 합니다. 이렇게 만들어진 시각적 관계들은 object instance가 node를 이루고 이들 간 관계를 edge로 나타낸 장면 그래프(scene graph)라는 형태로 표현할 수 있습니다. 여기서 object는 공간적 위치(bbox나 segmentation mask 등)와 클래스 레이블로 예측됩니다. 이렇게 예측된 object instance들과 relation은 <subject-predicate-object> triplet 형태로 나타냅니다.
비디오에는 occlusion이나 motion blur 등 시각적 정보의 열화 현상이 자주 발생하기 때문에, temporal 정보를 활용해 이를 보완하는것이 필요합니다. 기존 방법론들은 Faster-RCNN과 같은 object detector를 활용한 프레임 단위 검출 결과들을 모아 일련의 tracklet을 구성한 뒤 후처리를 하는 multi-stage pipeline을 채택했습니다.
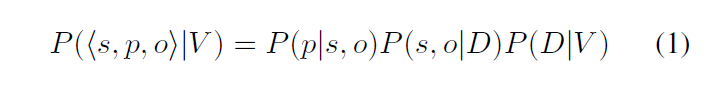
식 (1)에서 D는 V에서의 object detection 결과입니다. tracker나 tublet을 구성하는 방법론은 이를 다음과 같이 더 쪼개게 됩니다.
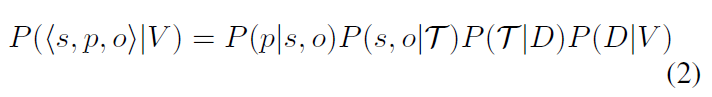
수식 2에서 T는 V에서의 object tracking 결과입니다. 이러한 기존의 multi-stage 방법들은 각 단계를 개별적으로 학습해야 하고 성능의 upper bound가 명확했기 때문에 sub-optimal하다는 한계가 있습니다. 본 논문의 저자들은 이를 지적하며 주어진 모델로부터 예측을 1-stage로 수행하는 방법을 제안합니다. 해당 방법은 입력된 비디오 시퀀스의 reference frame들을 참고해 target data의 예측값을 보완하여 1-stage로 spatial / temporal 정보를 반영한 VidSGG를 수행할 수 있도록 했습니다.
Overview
Figur 2.에 저자들이 제안하는 OED 프레임워크를 나타내었습니다. 비디오 시퀀스가 입력되어 target frame과 reference frame이 주어지면, DETR의 set prediction 방식으로 시공간적 문맥을 반영한 scene graph를 예측하게 됩니다.
우선, DETR과 동일하게 CNN backbone(논문에서는 ResNet을 기본값으로 사용했습니다) 및 트랜스포머 인코더를 순차적으로 태워 각 frame마다의 visual feature를 뽑아냅니다. 이후에 의미 있는 공간적 문맥을 추출하기 위해 DETR 의 디코더 구조를 기반으로 learnable query가 후보 object pair들의 pair-wise feature를 예측하도록 설계하였습니다. pair-wise feature는 순차적으로 디코더를 통과하며 공간적 문맥을 추출하여 object detection을 위한 query, 그리고 relation prediction을 위한 query를 출력합니다.
이후에는 temporal 정보를 반영하기 위해 RPM(Progressive Refined pair-wise feature interaction Module) 모듈을 배치하였습니다. 이 모듈은 reference frame들의 모든 query feature들을 사용하면 너무 noisy한 feature들이 반영되고 연산적 부담도 커지니 관련이 적은 쿼리들을 제외시켜 순차적으로 target frame의 pair-wise feature를 정제하는 방식으로 설계되었습니다.
최종적으로 spatial context aggregation module, temporal context aggregation module을 거친 feature를 사용해 target frame의 <s-p-o> triplet을 예측을 수행합니다.
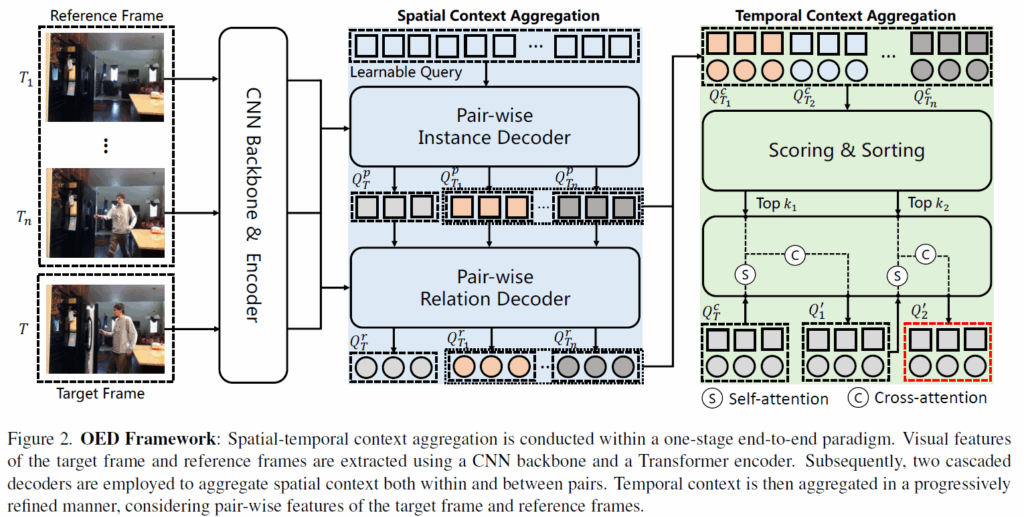
지금부터의 방법론 설명은 Figure 2를 참고하시면서 읽으시면 좋습니다. 간단하게 요약하면 결국 spatial 정보 집계를 위해 instance decoder와 relation decoder로 attention 연산을 하고, 이후 이 출력 피쳐들을 모아 temporal context aggregation module에서 다른 프레임들의 피쳐 간 attention을 수행해 최종 예측을 하는 흐름입니다.
Spatial Context Aggregation
CNN 백본과 Transformer encoder를 거쳐 각 프레임들의 feature F = {{f}_{T},{f}_{T1}, ..,{f}_{Tn}}를 얻어냅니다. 여기서 {f}_{i}는 HW×{d}_{model}차원의 feature map입니다. 이후 순차적으로 디코더를 거치며 예측을 수행합니다. DETR과 마찬가지로 learnable query를 사용해서 subject-object pair를 모델링하게 하는데, 순차적으로 디코더를 거치며 learnable query가 공간적 문맥을 반영하게 됩니다. 이 때 첫번째 디코더(pair-wise instance decoder)의 출력 쿼리로는 이후 subject, object의 detection을 수행하게 되고, 두번째 디코더(pair-wise relation decoder)의 출력 쿼리로는 subject, object 간의 relation을 classification하게 됩니다(서술어 예측은 사전 정의된 클래스 안에서의 분류로 수행됩니다). 이 때 디코더 내부에서는 당연하게도 attention 기반으로 연산이 수행됩니다.
Multi-head Attention
query embedding {X}_{q},key embedding {X}_{k}, value embedding {X}_{v}가 주어졌을 대 다음 연산을 통해 Multi-head attention이 수행됩니다.
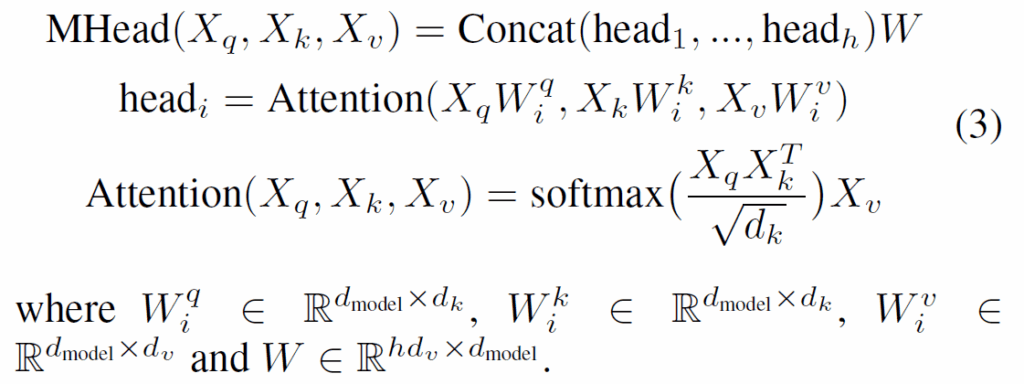
pair 간 spatial context dependencies는 multi-head self attention 연산 SelfAttn(Q)을 통해 모델링되고, 이후 각 pair의 공간적 문맥 집계(spatial context aggregation)은 주어진 비디오 시퀀스의 i번째 프레임에 multi-head cross attention 연산 CrossAttn(Q,{f}_{i})로 모델링됩니다.
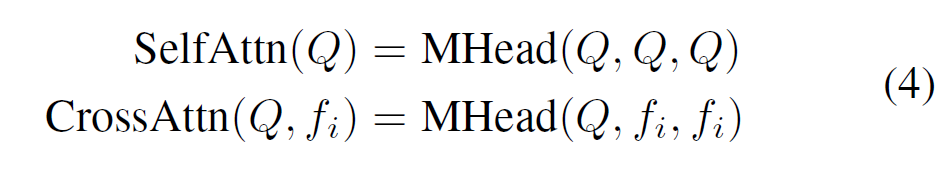
이 때 어차피 pair-wise query로 subject / object detection과 이들 간 관계 예측을 수행하게 되므로 디코더 하나로 모델링 할 수 있지 않을까?라는 생각이 드실 수 있지만, 기존 연구에서 단일 디코더 구조만으로는 pair detection과 predicate classification task를 처리하는데 어려움을 겪는다는 점이 관찰되었기에 저자들은 두 개의 디코더를 cascade 형식으로 구성하였다고 합니다. Figure 2를 참고하시면, pair-wise instance decoder에서는 learnable query 집합이 주어 / 목적어 instance 관련 정보를 포착하는데 사용됩니다. 이후 subject / object instance 관련 특징이 이들 사이의 predicate 예측에 강력한 사전정보(prior) 역할을 할 수 있을 것이라는 아이디어로 instance decoder 출력 쿼리들을 pair-wise relation decoder의 입력 쿼리로 그대로 사용합니다. 이후 해당 쿼리들은 predicate classification을 위한 공간적 문맥을 집계하게 됩니다. spatial context aggregation module의 두 디코더에서는 위 수식 (4) 연산이 동일하게 적용된다고 생각하시면 됩니다.
입력된 비디오 시퀀스에 대해 target frame과 reference frame들에 대해 모두 spatial context aggregation이 이루어지고, 이후 reference frame에 대한 pair-wise instance feature {Q}^{p}(instance decoder의 출력 쿼리)와 pair-wise relation feature {Q}^{r}(relation decoder의 출력 쿼리)들은 concat되어 temporal context aggregation module로 넘어갑니다.
Temporal Context Aggregation
두 개의 디코더를 거치면서 pair-wise feature {Q}^{c}에는 풍부한 공간적 문맥 정보가 반영되었습니다. 이제 Temporal Context Aggregation 단계(Figure2의 연두색 부분)에서는 비디오의 temporal 정보를 반영하게 됩니다. 이 단계에서는 여러 단계로 구성된 PRM(progressively refined interaction module)을 사용합니다. 간단하게 요약하면, reference frame들에서 추출한 pair-wise feature {Q}^{c}_{1..n}들과 target frame의 pair-wise feature {Q}^{c}_{T}을 반복적으로 attention 연산을 수행합니다. 이 때 모든 reference frame의 query들을 계속 사용하면 연산량도 많아지고 별로 관계 없는 noisy한 feature가 많이 섞이게 되니 어느 정도 필터링을 거치면서 피쳐를 정제하는 과정으로 생각하시면 됩니다.
우선, 앞에서 추출한 target / reference frame의 pair-wise spatial feature {{Q}^{c}_{T},{Q}^{c}_{T1}, ... {Q}^{c}_{Tn},} 중에서 reference frame들의 instance feature와 relation feature를 각각 classification head를 통과시켜 subject, object, predicate에 대한 예측 점수 {s}_{sub}, {s}_{obj}, {s}_{rel}를 만듭니다. 이후 이 점수들을 아래 식 (5)처럼 곱해 각 triplet <s-p-o>의 점수를 계산하고, 이 점수를 기반으로 top-k selection을 수행합니다.
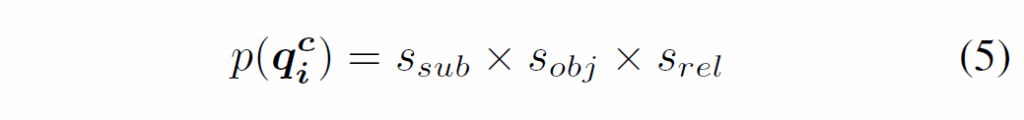
이 때 논문에서는 (5)의 점수가 더 높은 pair-wise feature일수록 해당하는 GT와 더 높은 상관관계를 가질 것으로 기대하고 top-k를 수행한다고 하는데, 처럼 읽을 때 너무 나이브한 선별 방식이 아닌가, hard sample들은 전부 걸러지지 않을까?하는 개인적인 생각이 들었네요. 기존 transformer 기반 SGG 방법론들에서 top-k 선별을 할 때 기준 score로 (5)를 많이 사용했기에, 기존 방식을 그대로 사용한 것 같습니다. 암튼, 점점 k개수를 줄여가며 multi-step으로 점진적으로 feature를 정제해갑니다. 구체적으로는 K=80, 50, 30순으로 3번 진행합니다.
i번째 단계에서 선택된 상위 {K}_{i}개의 reference pair-wise feature 가 트랜스포머 디코더 내에서 target frame의 pair-wise feature와 attention 연산으로 정보를 교환하게 됩니다. 다음 수식 (6)과정을 반복하게 되죠.
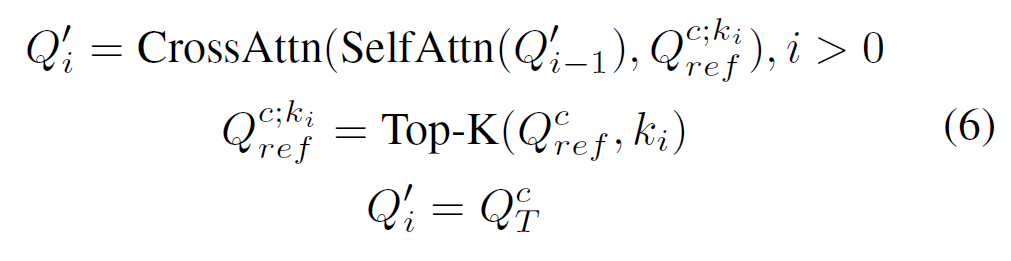
temporal decoder에서 점점 K개수를 줄여가면서 정제하는 방식에 대해 논문에서는 자기들이 제안했으며, 정해진 개수의 쿼리를 사용하면 너무 noisy한 개수를 선택하거나 시간적 정보를 얻는데 부족한 쿼리를 사용하게 될 수 있기에 K개수를 줄여가도록 설계했다 이런 식으로 길게 설명이 되어있긴 한데, 나중에 Video Object Detection 쪽 코드를 까보니 완전 똑같은 코드가 있더군요. K개수 80, 50, 30개도 동일한거 보니 이쪽에서 그냥 코드 긁어서 가져온 것 같습니다.
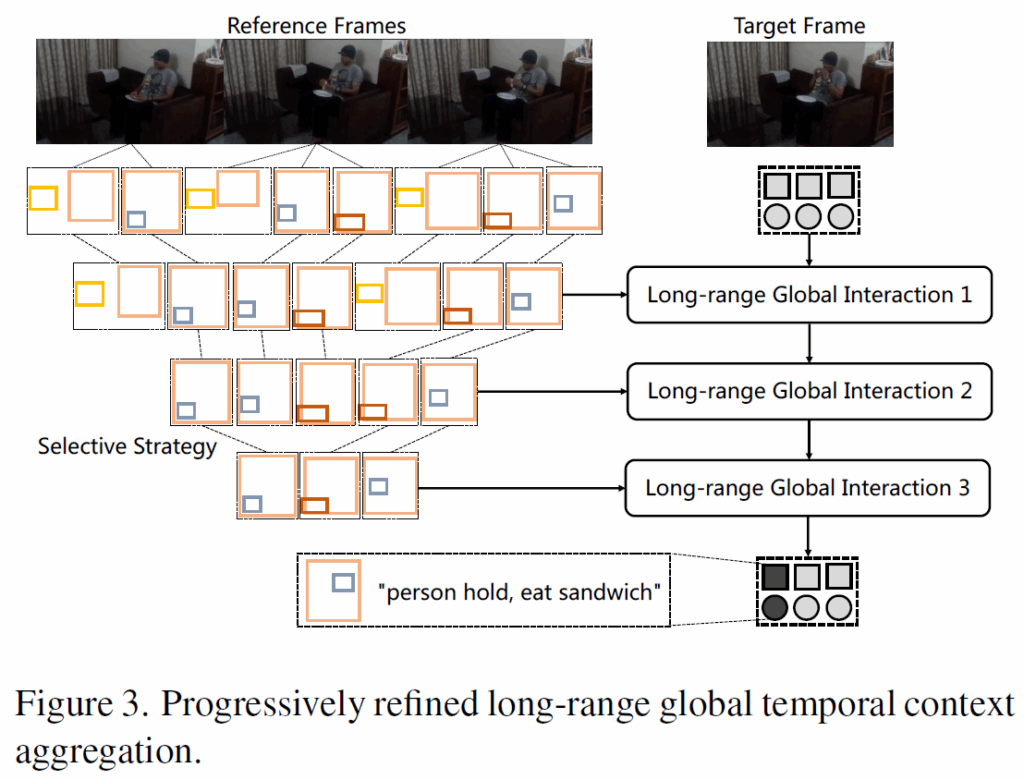
이런 방법이 그래도 어느 정도 노이즈를 잘 걸러주고, long-range global temporal interaction이 가능하게 해주기에 이점이 어느 정도 있는 것으로 보입니다.
이렇게 spatial context, temporal context를 모두 집계하게 되면 각 pair-wise feature(디코더를 거친 쿼리들)에 풍부한 시공간적 정보가 반영됩니다. 이 쿼리들을 사용해 최종 예측을 수행하게 됩니다. instance feature로는 subject / object detection을, relation feature로는 subject, object 간 관계의 classification을 수행합니다.
Training
기본적으로 DETR구조 기반이므로, 학습 및 예측도 DETR과 유사합니다. 비디오 시퀀스가 주어지면 모델이 각 frame에 대해 고정된 개수의 예측값 집합을 생성하고, 헝가리안 알고리즘을 통해 prediction set과 GT set 간 최적의(matching cost {L}_{match} 가 최소가 되는) 일대일 매칭을 수행합니다.
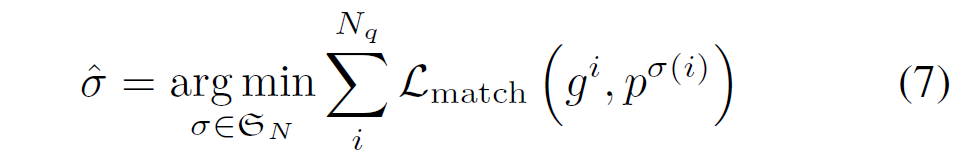
해당 모델의 matching loss는 다음과 같이 구성됩니다.
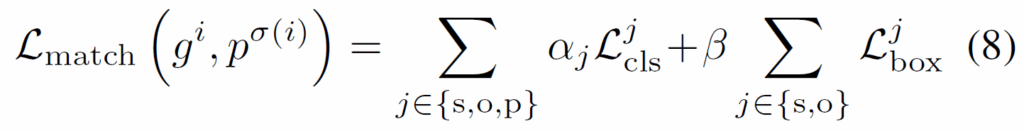
위 수식 (8)에서 {L}_{cls}^{j} 는 다음 수식과 같이 subject, object, predicate에 대한 classification loss를 의미합니다. 이 때 subject, object class에는 cross-entropy를 사용하고 predicate에 대해서는 focal loss를 사용합니다.
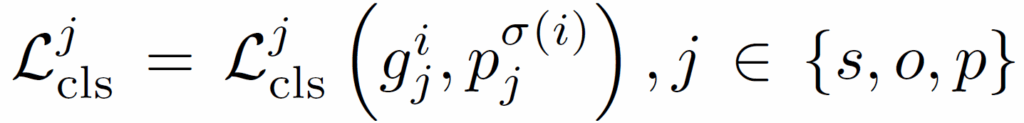
수식 (8)에서 {L}_{box}^{j} 는 subject와 object에 대한 bounding box regression loss이고, DETR의 bbox loss처럼 L1 loss와 GIoU loss를 가중합하여 사용합니다.
위 매칭 loss를 전체 objective function으로 사용하지만, 이 때 predicate loss는 불완전한 annotation 때문에 (padding되지 않고) 실제 매칭된 예측값에 대해서만 predicate loss를 계산한다고 합니다.
Experiments
실험은 Video Scene Graph가 항상 그렇듯 Action Genome 벤치마크에서 이루어졌습니다.
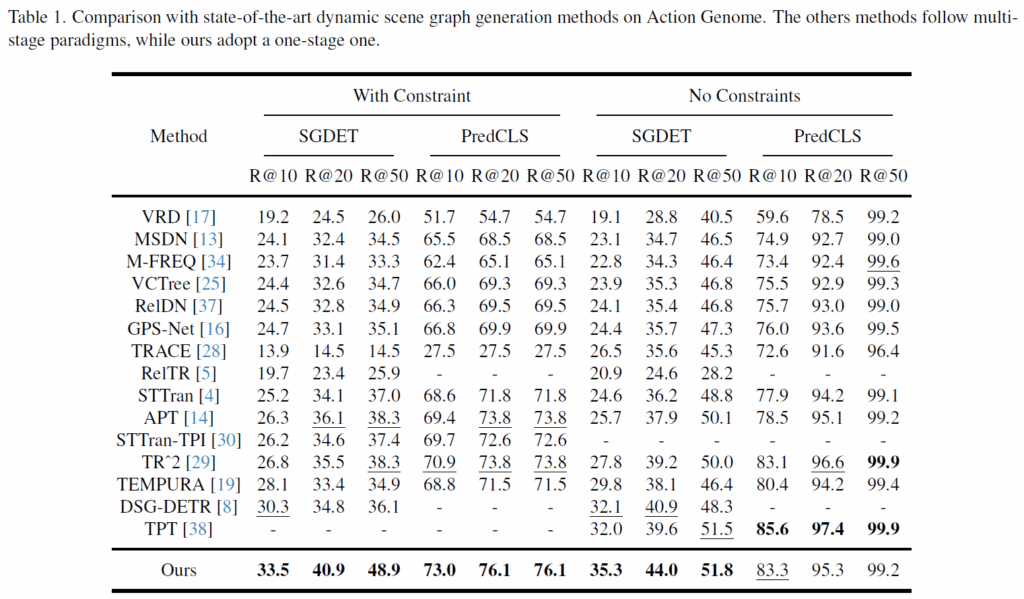
평가 지표는 SGG 관련 리뷰에서 워낙 여러 번 설명했으니 자세한 건 생략하고 간단히 설명드리겠습니다. 기본적으로 Recall@K로 성능을 측정하게 되고, 보통 SGCLS, PredCLS, SGDet 세 가지 세팅에서 평가됩니다. 아쉽게도 해당 논문에서 SGCLS는 리포팅하지 않았습니다. SGDet은 이미지만 주어지고 SGG을 수행하는 세팅이고, PredCLS는 object에 대한 box, class 정보가 주어지고 relation만 예측하는 것으로 생각하시면 됩니다. 전반적인 성능은 위 Table 1과 같습니다. 기존 방법론들보다 상당히 개선된 성능을 보여주었습니다.
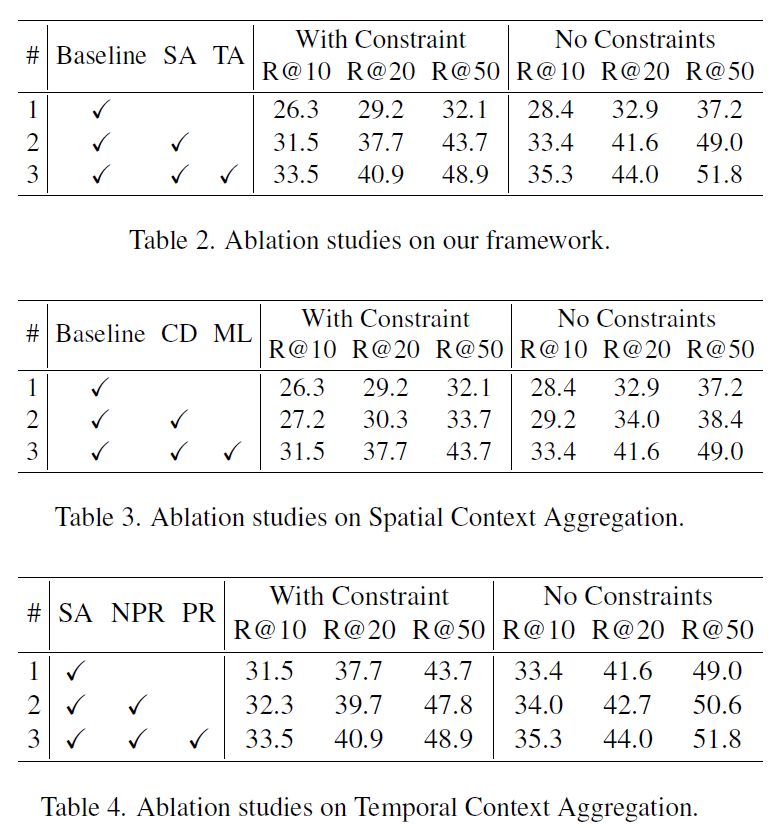
이후에는 ablation study를 나타내었습니다.
Table 2에서는 DETR을 베이스라인으로, 하나의 디코더로 주어/목적어의 detection과 술어의 classification을 모두 수행한 것이라고 합니다. Spatial Context Aggregation Module, Temporal Context Aggregation Module을 하나씩 추가할때마다 전반적으로 성능이 개선됩니다.
Table 3에서는 Spatial Context Aggregation 설계 요소를 나타내었습니다. CD는 Cascaded Decoder 구조, ML은 Matched Predicate Loss를 의미합니다. 마찬가지고 이를 추가할수록 성능이 상승하였습니다.
Table 4에서는 Temporal Context Aggregation 관련 ablation입니다. 베이스라인은 spatial aggregation module만을 추가한 것입니다. NPR은 progressive refined interaction이 없는 버전의 temporal aggregation이고, PR은 점진적으로 refined interaction을 수행한 것입니다. 결과적으로 제안한 방법이 가장 좋은 성능을 보였습니다.

마지막 Table 1은 supplementary material의 Table입니다. 보통 SGG에서는 long-tailed distribution에 얼마나 강건한지 확인하기 위해 mean Recall K를 함께 리포팅하는데, 그 내용이라고 생각하시면 됩니다. 결과적으로 기존의 DSG-DETR 및 TEMPURA보다 일관적으로 좋은 결과를 보여주었습니다. long-tail 세팅이라고 정확도가 아주 무너지지는 않는 모습입니다. mR@K를 기준으로 head, body, tail class의 성능을 확인했을때도 모든 metric에서 기존보다 개선된 결과를 보였습니다. TEMPURA가 long-tail 문제를 다룬 방법론임을 고려하면, 제안하는 방법이 어느 정도 long-tail에 강건함을 확인할 수 있습니다.
DETR 기반의 Video SGG 방법론을 제안한 OED를 살펴보았습니다. 점점 Video SGG분야에서 이 논문을 새로운 베이스라인으로 개선하는 흐름이 보이고 있네요. 이만 리뷰 마무리하도록 하겠습니다.
감사합니다.