안녕하세요 이번 논문은 제가 하고있는 창의학기제에서 풀려고하는 문제점들을 서베이하다가 네이버에서 낸 논문이 있어서 읽어본 논문입니다. ( 네이버랩스 유럽이라 한국인 이름은 안보이네요..)
그럼 리뷰 시작하겠습니다.
Abstarct
Open vocabulary object detection 은 classification, object detection 같은 task들을 언어 기반 태스크로 변환하여 사용자가 추론 시 원하는 어휘를 자유롭게 정의할 수 있게 해주었습니다.
저자들의 초기 조사결과 OVOD 모델들이 다양한 의미적 세분화 수준을 잘 다루지 못하며 이는 실제 응용에서 문제가 될 수 있다고 합니다. 여기서 의미적 세분화 수준은 coarse 한 수준에서 fine grained 클래스를 다루는 데까지로 생각하시면 될 것 같습니다.
저자는 SHiNE 라는 Semantic Hierarchy Nexus 구조를 제안하게 되는데 이는 클래스 계층 구조에서 얻은 의미 지식을 활용하는 새로운 분류기입니다. 구조나 동작 원리는 이후 차차 설명드리고 해당 분류기는 훈련이 필요 없는 training free 방식으로 작동하며 크게 3가지 단계로 구분됩니다.
- 계층구조에서 관련 상위/하위 카테고리(super-category/sub-category) 를 검색
- 이 카테고리들을 포함하는 계층 인식(hierarchy-aware) 문장을 생성
- 해당 문장들의 임베딩을 융합하여 최종 nexus classifier 벡터를 생성
실험 결과 SHiNe는 다양한 의미적 granularities 에서 강건성을 향샹시켰습니다. (granularities는 곡물의 낟알(grain)에서 생긴 단어로 다양한 분야에서 더 작은 작은 단위의 세분성이나 상세함의 정도를 표현합니다.)
대규모 언어모델이 생성한 계층구조를 사용해도 성능 향상이 유지되며 OV clasification (IN -1k) 에서도 CLIP zero shot 대비 2.8% 정확도 향상이 있었다고 합니다.
Introduction
Abstract에서도 간단하게 언급했지만 OVOD 모델들은 객체 검출문제를 시각 영역과 클래스 이름 간의 언어 기반 매칭 문제로 해결합니다. VLM에서 사전 정렬된 비전-언어 공간과 약한 감독 신호를 활용하여, OVOD 는 학습된 범주를 넘어 새로운 객체를 localize 하고 분류할 수 있는데요, 이는 클래스를 인덱스 대신 “a {Class name}” 형태의 텍스트 프롬프트로 객체를 표현하기 때문에 자연어로 Col(Class of interest) 를 자유롭게 정의할 수 있어 가능합니다.
다만 최근 연구들은 중요한 문제를 지적하는데, Open vocabulary 기법은 단어 선택에 민감하다는 점입니다. 예를 들어 Rosa 같은 학술적 명칭 대신 Rose 같은 일반 영어명을 쓰면 CLIP 의 zero shot 성능이 향상된다는 점 입니다. 최근 OVOD 모델들은 객체 특징과 VLM의 의미 공간을 더 잘 맞추어 성능을 높였기는 하지만 핵심 질문이 남아있다고 합니다. 이는 기존 OVOD 모델이 다양한 semantic granularity 에서 open vocabulary를 잘 처리할 수 있는지에 대한 의문입니다.
실제 상황에서는 Col 은 관찰자마다 다릅니다. 같은 Dog 영역에 대해 어떤 사람은 labrador (리트리버 종 이름) 다른 사람은 dog (종 이름) 또 다른 사람은 animal (상위 개념) 에 관심이 있을 수 있습니다. 즉 Col 은 서로 다른 granularity 수준으로 정의될 수 있다는 것입니다. 이상적으로는 같은 영역에 대한 표현이기 때문에 granularity가 달라도 탐지 성능은 일관되어야 합니다만 실험에서는 OVOD 성능은 granularity에 따라 많이 달라졌으며, 이러한 문제는 특히 자율주행과 같은 안전이 중요한 응용에서 심각한 문제라고 합니다.
동일한 객체인 labrador 는 여러 granularity로 분류될 수 있지만 “Labrador is a dog, Dog is an animal” 이라는 관계는 변하지 않습니다. 이러한 지식은 semantic hierarchy에 이미 존재하기 때문인데 이러한 semantic hierarchy를 활용하여 OVOD가 granularity 변화에도 강건하도록 만드는 것이 저자의 목표입니다. 최근 연구는 super-/sub-category 정보를 활용하여 정확도를 개선하였지만, 추론 시 탐색을 요구하여 연산 부담이 크고 detection에는 적합하지 않은 문제점이 남아있습니다.
저자의 SHiNe 방식은 granularities 관점에서 강건성을 보입니다. abstract에서 언급했던 3가지 순서를 다시 설명드리면
- 각 Col 에 대해 hierarchy에서 관련 super-/sub- category 검색
- “Is-A” 관계로 hierarchy-aware 문장 생성
- 여러 임베딩을 융합하여 nexus vector 생성 → classifier weight 로 사용
으로 설명드릴 수 있고 어떤 OVOD detector에도 바로 통합할 수 있으며 추론 시 복잡도는 Col 수에 선형적으로 비례한다고 합니다.
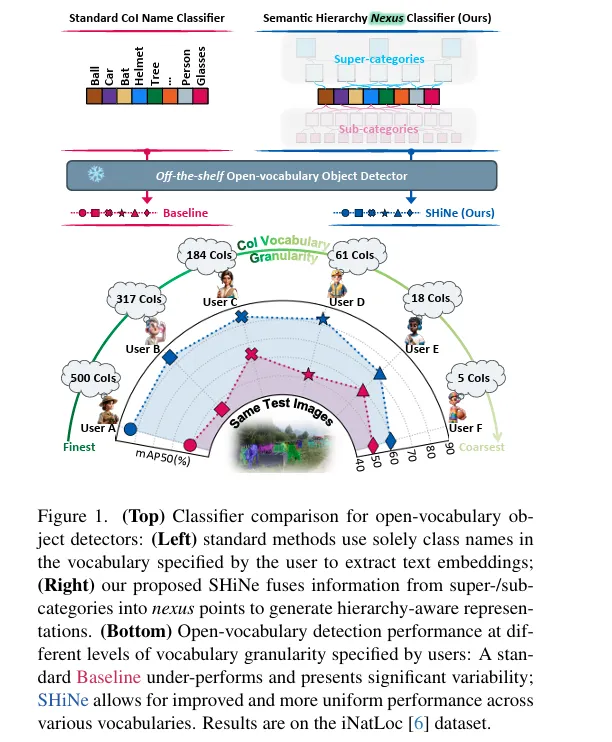
위 빨간색과 파란색 표시가 기존 방법론과 저자의 SHiNe을 사용했을때이며 아래는 성능 비교 표입니다. baseline은 car helmet tree 같은 단일 클래스 이름만 벡터화 시킨 상태이며 ShiNe은 클래스의 상위/하위 개념까지 연결하여 문장화하고 임베딩을 융합하여 계층 구조를 아는 classifier를 생성했을 때 입니다.
아래쪽 성능 비교를 보면 User A~F는 같은 test 이미지에서 vocabulary를 500개(fine-grained) 부터 5개(coarse-grained) 까지 다르게 정의했습니다. baseline 에서는 granularity에 따라 mAP 값이 크게 요동치지만 저자의 방법론은 일관된 성능을 보입니다.
Open-vocabulary object detection
OVOD는 실용적 중요성 덕분에 빠르게 주목받고 있습니다. OVOD는 사용자가 추론 시 원하는 Col( Class of interest) 를 자유롭게 정의할 수 있으며, 새롭게 지정된 객체를 zero-shot 방식으로 탐지할 수 있게 합니다. contrastive vision-language model 에 의해 미리 정렬된 이미지-텍스트 임베딩 공간에 시각 영역 특징을 효율적으로 맞추는 방식으로 zereo shot detector 보다 뛰어난 성능을 보이게 된다고 합니다.
이미지-텍스트 임베딩 공간을 효율적으로 정렬하기 위해서는 비전 쪽 혹은 텍스트 쪽에서 접근하게 되는데, 이를 위해 region-aware training, pseudo-labeling, knowledge distillation, transfrer learning 기반 방법들이 연구되어 왔습니다. 저자의 연구에서는 이러한 pre-trained region-text aligned OVOD detector 위에 제안 기법을 적용하여 다양한 granularity 를 가진 vocabulary 에서도 성능과 강건성을 높였습니다.
Prompt engineering
prompt enginerring 은 VLM 개선을 위한 기술로 연구되어 왔다고 합니다. prompt enrichment 방법은 LLM 으로부터 가져온 클래스 설명을 활용해 동결된 VLM text classifier를 보강하는 접근인데, 저자의 연구는 계층에서 의미 지식을 얻는 것에 더 초점을 둡니다. prompt tuning은 학습 가능한 토큰 벡터를 프롬프트에 삽입하고 downstream task에 맞게 미세조정하지만 저자의 방법론은 training-free 라는 점을 어필하고 있습니다. 저자의 방법론은 CHiLS와 H-CLIP 이라는 최근 두 가지 방법과 관련이 깊다고 하는데, CHiLS 는 sub-category 내에서 더 높은 logit 점수를 찾고, 그 점수를 이용해 초기 예측을 갱신하는 방법이며 H-CLIP 은 super-/sub- category 프롬프트 조합을 탐색하여 더 높은 logit 점수를 얻는 방법입니다. 두 방법 모두 추론 시 on-the-fly 탐색을 수행해야 해서 계산 부담이 크며, classification 에만 적합합니다. 다만 SHiNe 방법론은 오프라인에서 동작하고 추론시 추가 계산 비용이 없어서 classification 뿐만 아니라 detection 모두에 적용이 가능합니다.
Method
목표는 off the shelf OVOD 모델을 다양한 granularity 사용자 정의 Col 에도 강건하게 만드는 것입니다. SHiNe는 training free로 작동하며 한번 classifier 를 만들면 새로운 dataset에도 zero shot transfer 가 가능하다고 합니다.
problem formulation
Open-vocabulary object detection의 목표는 모델 재학습 없이 사용자가 이미지 안에서 자유롭게 지정한 새로운 객체 클래스들을 지역화하고 분류하는 것입니다. Open vocabulary 능력을 얻기 위해서 OVOD는 제한된 어휘 Cdet 를 가진 박스 주석 데이터셋 Ddet와 약한 감독을 제공하는 보조 데이터셋 Dweak 을 사용합니다. Dweak 은 이미지-클래스 혹은 이미지-캡션 쌍의 세부 주석은 적지만 훨씬 넓은 어휘를 포괄하므로 탐지에서 다룰 수 있는 어휘를 크게 확장해줍니다.
조금 이해하기 쉽게 설명하자면 Ddet 와 Dweak 의 목적을 설명드려야할 것 같은데, OVOD 에서 zero shot 설정은 detector 가 보지못한 class들이라고 생각하면 됩니다.
순수 detection 데이터셋인 Ddet만으로 학습하면 모델이 아는 class가 Cdet로 고정됩니다. OVOD는 테스트시 Ctest를 임의로 지정할 수 있어야 하므로 모델이 보지 못한 단어/개념과도 언어-시각 임베딩 공간이 정렬되어 있어야합니다. Dweak 은 넓은 어휘의 Cweak을 제공합니다. CLIP 같은 VLM이 이미지-텍스트 임베딩을 광범위한 Dweak으로 정렬시킨 후 Detector 부분까지를 Ddet으로 학습시켜 보지 않은 클래스까지 점수 매칭이 가능하게 되는 것입니다.
- 학습 시
Ddet : RPN/ROI 헤드, 박스 회귀, 분류 헤드 등을 학습 ( 강한 supervision) → COCO(80 class)
Dweak : VLM 또는 텍스트 인코더와의 공간 정렬을 보조 (이미지-텍스트 쌍/ 라벨로 약한 supervision) → ImageNet-21K 또는 웹 캡션 데이터 - 테스트 시
사용자가 Ctest를 자연어로 정의 (예 : Labarador , Husky, Dog)
텍스트 인코더로 텍스트 임베딩으로 변환 이미지에서 얻은 영역 임베딩과 텍스트 임베딩의 유사도 계산 → 가장 높은 클래스를 cm 으로 할당 → 재학습 없이 zero-shot 새로운 단어에도 대응 가능
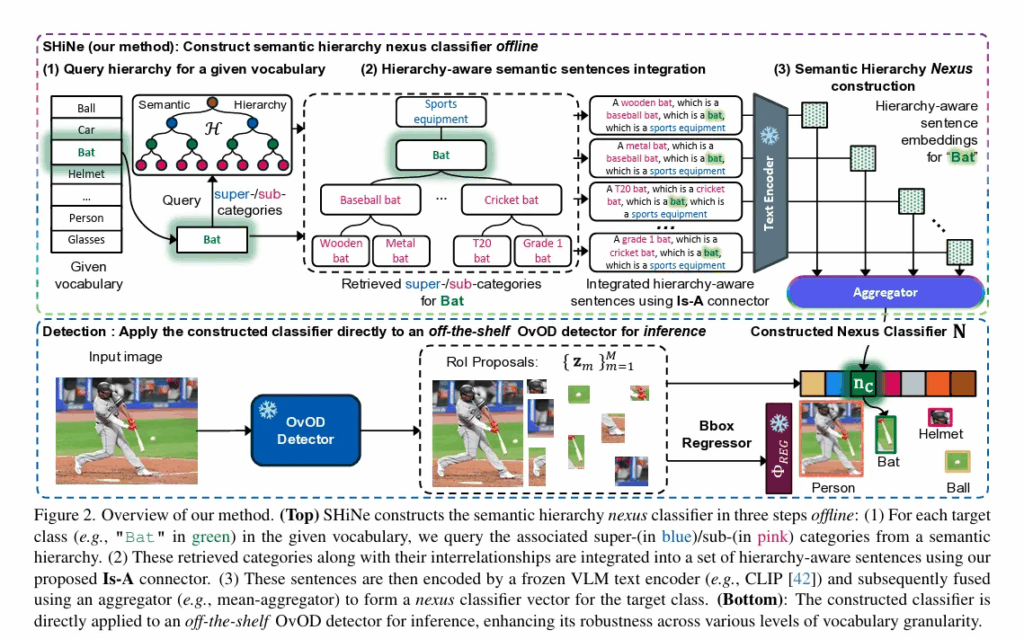
SHiNe classifier
- Query hierarchy for a given vocabulary 1-1. 주어진 vocabulary에서 Bat 라는 특정 클래스 선택한다. 1-2. semantic hierarchy 에서 관련 super-category 와 sub-category 를 검색한다. ex: sports equipment → bat → baseball bat → wooden bat
- Hierarchy-aware semantic sentence integration 검색된 super/sub/target 카테고리를 Is-A connector로 연결해 K 개 문장을 생성한다. 예시는 (2)번 항목의 4개의 문장을 보면 됩니다.
- semantic hierarchy Nexus construction 생성된 문장들을 CLIP 같은 VLM text encoder로 임베딩하고 이 sentence embedding들을 평균 혹은 SVD 기반으로 융합한다.
OVOD detector에 적용
- Input Image → OVOD detector → RPN 이 Roi proposlas 들을 추출한다.
- 각 RoI feature zm 과 nexus classifier nc 간 cosine sim 계산한다.
- Box regressor 로 위치 보정 및 nexus classifier 로 분류한다.
결과적으로 granularity 변화에도 안정적인 robust한 OVOD가 됩니다.
Queryingthesemantic hierarchy
관련된 suepr-/sub-category를 얻기 위해 semantic hierarchy H 가 필요한데 두 가지 유형을 고려한다고 합니다.
- dataset-sepcific taxonomy (예 : InatLoc, ImageNet-21K)
- LLM이 생성한 synthetic hierarchy (예: chatGPT 등으로 super-category p=3, sub-category q=10 생성)
Hierarchy-aware semantic sentence integration
수집된 카테고리에는 구체적인 의미와 추상적인 의미가 모두 들어있습니다. 단순 앙상블이나 concat은 hierarchy 가 주는 내재적 관계를 무시하기 때문에 Is-A connector를 제안하게 됩니다. 위의 figure 문장을 예시로 보시면 이해가 편한데, 각 super sub category 사이를 is a 로 연결하는 것입니다.

Semantic hierarchy Nexus construction
이 문장들을 Aggregator 로 융합하여 Nexus를 만듭니다.
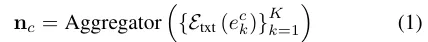
위의 figure에서 이미 언급한 2가지 방법이 있으며 주 방법으로 평균벡터를 사용하고 대안책으로는 SVD 로 문장 임베딩 벡터를 분해하여 주성분을 nexus로 사용하는 방법이 있다고 합니다.
Experiments
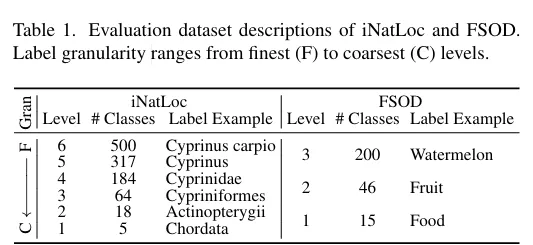
저자가 사용한 데이터셋의 fine to coarse 한 수준입니다. level이 높아질수록 더 fine 한 속성이고 iNatLoC은 생물 분류를 6단게로 나눴고 FSOD는 음식 도메인을 3단계로 나눈 것입니다.
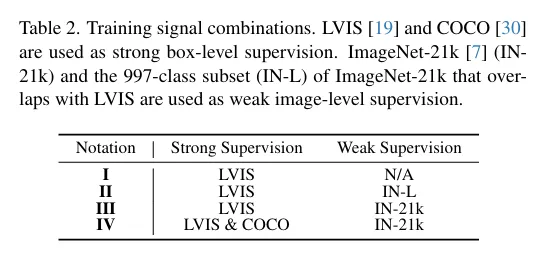
Table2는 저자가 weak supervision과 strong supervision을 나눠 학습시킨 설정을 다르게 했을때 이후 Detic에서의 기존 OVOD와 SHiNe 방식의 성능차이를 보이기 위한 실험세팅입니다. I → IV 로 갈수록 더 풍부한 지식을 학습했다고 생각하면 됩니다.
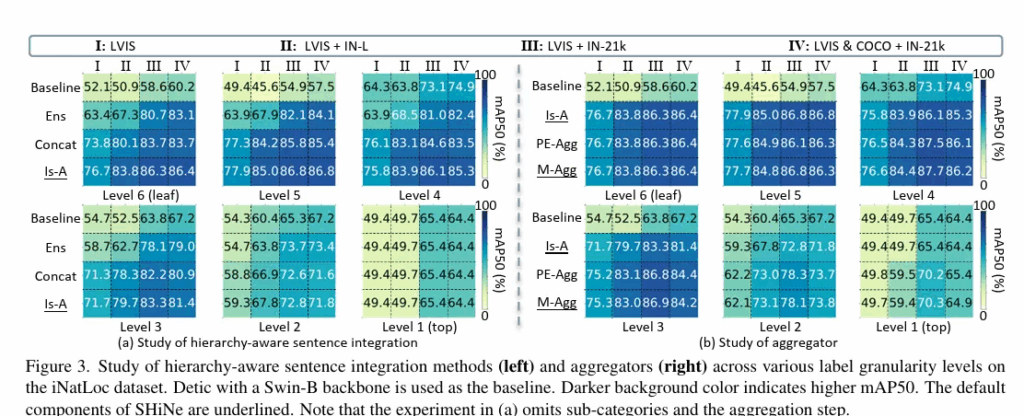
좌측 표
Baseline : 기존 Detic
ENS : 단순 평균으로 앙상블낸 텍스트 임베딩 벡터 사용
concat : 문장을 단순히 연결해서 사용
Is-A : 제안 방식으로 사용
어떤 방식이든 계층적 구조를 넣으면 확실히 성능이 오르는 것을 확인할 수 있으며 저자의 제안방법인 Is-A 가 가장 효과적입니다. 특히 level 6 인 가장 fine 한 기준에서 성능이 많이 오르는 것을 알 수 있습니다.
우측 표
Baseline : 기존 Detic
Is-A : 제안 방식
PE-AGG : SVD 분해로 주성분 벡터를 사용
M-AGG : 단순 평균 Aggregator 로 어떤 방식을 쓰던 baseline 보다 개선됨을 보입니다.
PE 방식과 M 방식의 성능차이는 크지 않아 구현 단순성과 성능에서의 trade off 가 있다고 합니다.
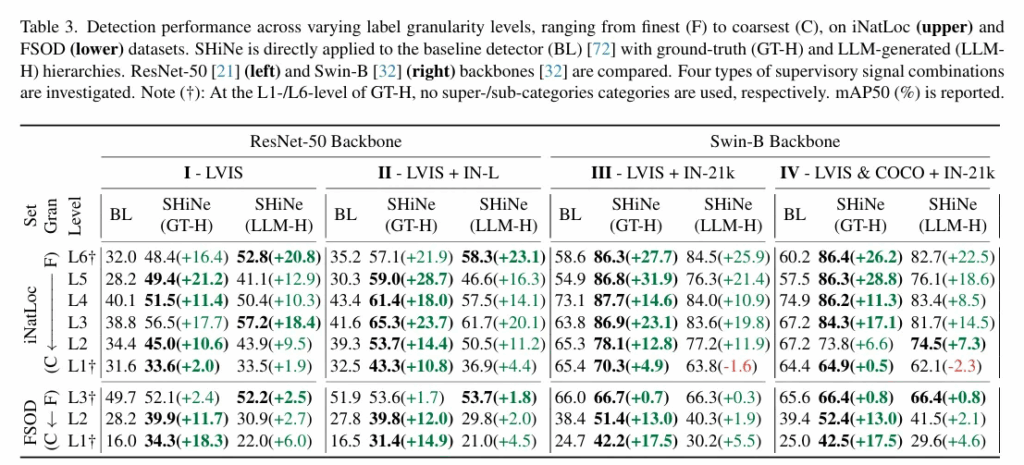
ResNet 백본과 Swin 백본에서 저자의 방법론을 GT 기반과 GPT 기반으로 만들었을때 모두 어느정도 큰 성능향상이 존재했습니다. Resnet과 Swin 을 사전학습 시킨 데이터의 사이즈가 차이나게끔 설정하긴 했지만 모델의 크기가 다르므로 사전학습 데이터량을 조절해서 성능을 측정한 것 같습니다. SHiNe이 어떤 백본을써도 성능향상이 있었으며, 데이터가 coarse하건 fine하건 전반적으로 성능이 향상함을 볼 수 있습니다. 뭔가 LLM 기반보다는 GT 기반의 계층적 구조가 더 성능향상이 있는 것으로 보여집니다.
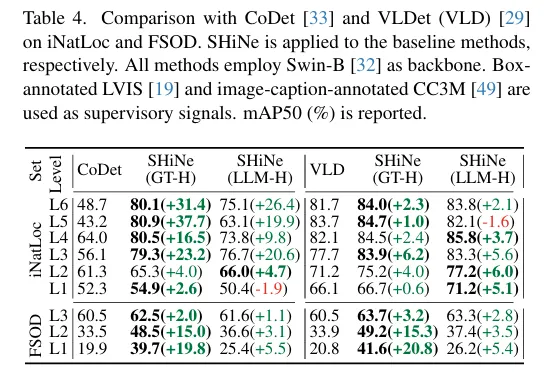
Detic 말고도 다른 detector와의 실험에서도 두 데이터셋에 대해 높은 성능향상을 보입니다.
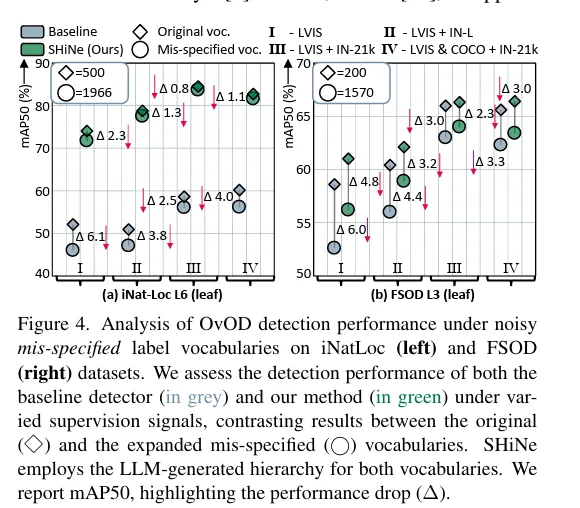
다이아몬드가 기존 vocabulary 즉 test 셋에 나오는 클래스 집합이고 원으로 표현된 것이 실제 테스트 데이터셋에 나오지 않는 잡음이 포함된 클래스로 구성될 때의 성능입니다. 왼쪽의 iNat 기준으로 설명을 드리면 original 클래스 500종이 iNat 에 원래 존재하고 이들은 실제로 test 이미지에 존재합니다. 여기에 Openimage 500종 + LVIS 의 1203 종 클래스를 더하고 중복을 제거하여 1466 개의 추가 클래스를 넣었을때 test 로는 iNatLoc test 데이터로 평가했을때의 성능 drop을 보여준 것입니다. 이런 noisy 들을 의도적으로 추가하더라도 저자의 계층적 구조를 사용하면 기존 방법론이 6~4퍼정도의 성능 드랍을 보일 때 저자는 2.3~0.8의 성능 드랍을 보여 강건함을 보입니다.
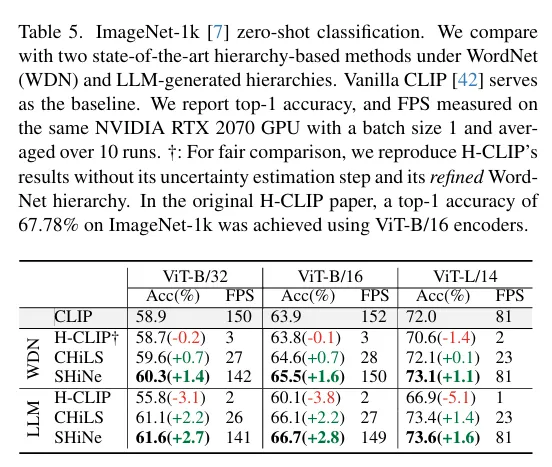
저자의 방법론이 ImageNet-1k 의 zero shot classification 에서도 효과적임을 보입니다. 정확도가 기존 다른 계층구조를 사용하는 것보다 더 높으며 FPS 도 비교적 빠른 것을 확인할 수 있습니다.
conclusion
OVOD에서는 사용자가 정의하는 vocab가 핵심인데, granularity에 따라 성능이 크게 바뀌는 단점이 있었고 이를 간단한 training-free 방식 계층구조 기반 nexus classifier로 해결했다고 볼 수 있습니다. 연산 복잡도는 기존과 동일하고 클래수가 늘어나면 선형적으로 증가하기는 하지만 GT 계층구조든 LLM 기반 계층구조든 기존 baseline 모델들에서 성능이 오르는 것을 보여 그 의의가 있다고 생각합니다.
감사합니다.
리뷰 잘 읽었습니다
그나저나 제목만 보고, 예전에 현우님이 리뷰해주신 Compositional Temporal Grounding 연구인줄 알았는데 아니었네요? 그 논문도 Shine 이었던거 같은데 허허
Introduction을 읽다 궁금해진 건 “bat(동물/방망이)” 같은 다의어는 그럼 어떻게 되는지? 그러니까 “labrador vs. labrador retriever”처럼 동의어/표기 변이에 대해 SHiNe의 nexus 벡터가 얼마나 안정적인지 궁금하네요
다음으로 혹시 실험에 평균/concat/CHiLS/H-CLIP 대비 Is-A connector 자체의 성능을 확인할 수 있는지 궁금한데요. 더 정밀하게 그 요소들을 분리(e.g., 동일 토큰 수로 통제)한 ablation이 있을까요?
안녕하세요 주영님 답글 감사합니다.
첫번째 질문인 다의어 같은 경우 논문에 언급은 되어있지 않았고 따로 분석하지는 않았습니다.
그런 경우라면 따로 다의어까지도 강건함을 보이는 새로운 실험들을 보여야할 것 같은데 제 생각에는 앞 뒤 문맥을 통해 잘 파악이 된다면 강건하겠지만 저자의 nexus 구조가 앞뒤문맥을 더 잘 파악하게 하는 목적으로 무언갈 넣지 않아서 안정성은 보장 못한다고 생각합니다.
두번째 질문에 대한 답변으로는 Is-A connector가 효과적이었다고 여러번 언급한 것 치고 그부분만 동일 토큰수로 통제한 ablation 이 존재하지는 않습니다. 논문이 굵직 굵직한 실험들만 리포팅하고 appendix도 따로 존재하지 않아 세부실험들은 코드를 가져와서 따로 해봐야 알 것 같습니다.
감사합니다.
좋은 리뷰 감사합니다.
제가 SHiNe의 전체적인 방법론 흐름을 이해한 바로는 먼저 사용자가 정의한 vocabulary가 주어지면 각 클래스에 대한 상위/하위 개념들을 계층 구조에서 가져오고, ‘Is-A’ 를 통해 이 개념들을 하나의 긴 문장으로 엮어낸 뒤, 이 문장 임베딩들을 융합하여 최종 넥서스 분류기를 오프라인으로 구축하는 과정으로 보입니다. 그리고 이렇게 완성된 넥서스 분류기는 기존에 학습된 detector의 원래 분류기를 대체하여 추론에 사용되고 모델의 시각적인 부분은 그대로 둔 채, text classifier만 더 정교한 것으로 교체하는 방식이라고 생각했습니다. 제가 이해한 흐름이 맞을까요?
그러면 궁금한 점은, 이렇게 시각 모듈과 언어 분류기를 분리하여 교체했을 때 발생할 수 있는 mismatch 문제입니다. 기존 학습에서는 학습 과정에서 “a bat”과 같은 단순한 텍스트 프롬프트에 맞춰 visual feature을 정렬하도록 훈련되었을 것인데 추론 시에 갑자기 훨씬 복잡한 의미가 담긴 넥서스 분류기와 짝을 맞추게 되면, 두 모듈 사이에 gap이 생기지않나요? align맞춰주는 작업이 필요해보이는데 그에대한 언급은없는지 궁금합니다.
감사합니다
안녕하세요 우진님 답글 감사합니다.
우선 이해하신 흐름이 맞습니다.
질문에 대한 답변을 드리자면 저자들은 training-free 방식을 주요한 contribution으로 보고있습니다.
따로 정합을 맞춰주지 않아도 성능이 보존되거나 오르는 리포팅을 통해 contribution을 증명했다고 생각하고 그런 mismatch가 있을 수 있다고는 생각합니다. 만약 그 mismatch를 다시 align 해주는 작은 학습 connector를 추가했을때 성능이 훨씬 많이 오른다거나 성능 drop 이 적었다면 보조실험으로 진행했을법도 하지만 최초 주장하는 contribution을 굳히기 위해 굳이 안넣은게 아닌가 조심히 생각해봅니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
제가 해당 개념에 대해서 잘 몰라서 하는 질문일 것 같은데 coarse 랑 fine granularity를 구분하는 기준이 궁금합니다. 도메인 마다 차이가 있을 것 같기도하고 그래서 실험에서는 coarse이랑 fine label 계층이 명확히 존재하는 데이터셋을 사용한 거 같은데 일반적인 open world에서에서 granularity 기준이 애매하거나 모호할 때도 해당 방법론이 잘 동작할 수 있을지가 궁금합니다.
감사합니다.
안녕하세요 우현님 답글 감사합니다.
granularity는 데이터셋마다 다르긴한데, 기존에 게층적 구조가 드러나는 iNatLoc 에 경우에는 그 계층 구조를 fine & coarse 의 정도로 사용하였고 FSOD 의 경우에는 iNatLoc 보단 아니지만 3단계의 계층구조를 설정하여 사용하였습니다. 일반적인 open world 에서 granularity가 기준이 애매한 경우가 분명 존재할 수 있으나 애매한 경우 제외하거나 그 계층의 정보를 2중라벨링 하는 등의 방법을 이용할 수 있을 것 같습니다.
감사합니다.