안녕하세요, 7번째 X-review 입니다. 이번에 소개해드릴 논문은 2025년 CoRL에 발표된 PicoPose로, RGB 이미지만으로 Novel Object의 6D Pose를 높은 정확도로 추정하는 새로운 프레임워크입니다. 그럼 바로 시작하도록 하겠습니다
Introduction
최근 6D Pose Estimation 연구는 학습 때 보지 못했던 새로운 물체(Novel Object)를 다루는 방향으로 활발히 진행되고 있습니다. 특히 로보틱스 응용 분야에서 새로운 물체를 즉각적으로 다루기 위해서는 이러한 Zero-shot 일반화 성능이 매우 중요합니다. 지금까지 RGB-D 이미지를 활용하는 방법들은 깊이(Depth) 정보가 제공하는 풍부한 3D 기하정보 덕분에 높은 성능을 달성해 왔습니다. 하지만 깊이 센서는 비용이 비싸고 특정 환경에서는 사용이 어렵다는 현실적인 한계가 있어, RGB 이미지만을 사용하는 방법이 더 매력적인 대안으로 여겨지고 있습니다.
하지만 RGB 이미지만으로 2D 이미지와 3D 모델 간의 대응점을 정확히 찾는 일은 본질적으로 매우 어렵습니다. 여기에는 몇 가지 이유가 있습니다.
기하학적 정보가 부족합니다. RGB 이미지에는 깊이 정보가 없어, 3D 공간상에서는 완전히 다른 위치에 있는 점들이 2D 이미지에서는 같은 픽셀로 투영될 수 있습니다. 이로 인해 어떤 2D 특징점이 어떤 3D 지점과 연결되는지 구분하기가 매우 모호해집니다.
또한 외형에서의 문제점이 생기는데요, 실제 환경에서는 조명, 그림자, 반사, 그리고 다른 물체에 의한 가려짐때문에 물체의 외형이 크게 달라집니다. 깨끗한 환경에서 렌더링된 3D 템플릿의 특징과 실제 촬영된 이미지의 특징이 일치하지 않는 경우가 많아, 시각적으로 비슷하지만 실제로는 다른 부분을 연결하는 오류가 발생하기 쉽습니다.
이러한 이유로 GigaPose, FoundPose와 같은 기존 RGB-only 연구들은 노이즈가 많고 이상치가 섞인 부정확한 대응점 문제로 인해 성능 저하를 겪는 경우가 많았습니다.
이번에 리뷰할 PicoPose는 바로 이 문제, 즉 RGB 이미지로부터 어떻게 하면 정확하고 강인한 대응점을 찾을 수 있을까 라는 질문에 Progressive Refinement 라는 아이디어로 접근하는 논문입니다. PicoPose는 총 3단계에 걸쳐 픽셀 단위의 대응점 정확도를 순차적으로 높이는 ‘점진적 픽셀 대 픽셀 대응점 학습’ 파이프라인을 제안합니다.
1단계 (Coarse Correspondence): 먼저 관측된 이미지와 렌더링된 3D 모델 템플릿 간의 특징점을 매칭하여 대략적인 대응점을 찾습니다.
2단계 (Smooth Correspondence): 다음으로, 이 거친 대응점 맵으로부터 2D 어파인 변환을 전역적으로 추정하여, 이상치를 효과적으로 제거하고 대응 관계를 매끄럽게 다듬습니다.
3단계 (Fine Correspondence): 마지막으로, 변환된 특징점 맵 내에서 지역적 옵셋을 학습하여 픽셀 수준의 매우 세밀한 대응점을 완성합니다.
이처럼 단계별로 대응점의 품질을 극대화하고, 최종적으로 PnP/RANSAC 알고리즘을 통해 정확한 6D 자세를 계산하는 것이 이 논문의 핵심입니다. 서두가 길었습니다. 본격적으로 논문의 Method 부분을 살펴보도록 하겠습니다.
Method
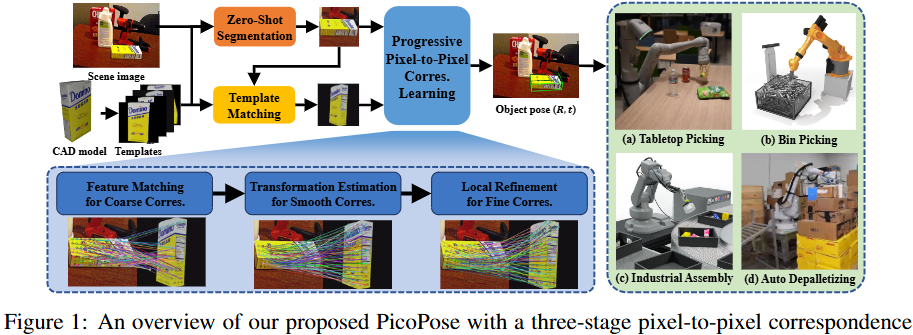
본격적으로 PicoPose의 Method 부분을 살펴보겠습니다. 전체적인 파이프라인은 위와 같이 크게 3단계의 점진적 대응점 학습 과정으로 구성됩니다. 이 3단계 파이프라인은 입력된 RGB 이미지와 여러 템플릿 이미지로부터 가장 적합한 템플릿을 찾고, 둘 사이의 픽셀 단위 대응점을 점진적으로 정제하여 최종 6D 자세를 추정하는 것을 목표로 합니다. 자세한 네트워크 구조는 아래 fig2를 통해 확인할 수 있습니다.
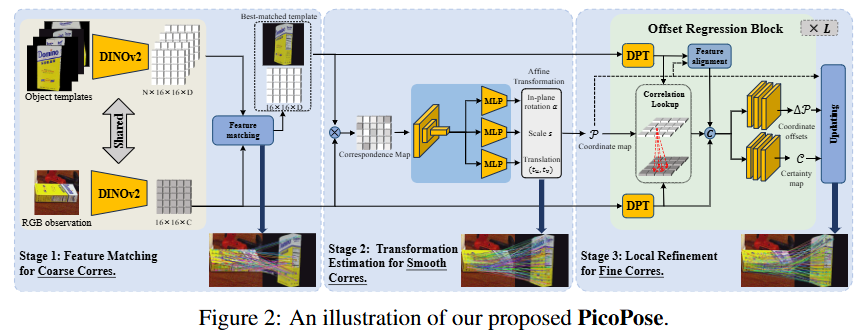
3단계 학습 과정에 들어가기 앞서, 먼저 전처리 단계가 필요합니다.
먼저, cluttered scene이 담긴 RGB 이미지가 주어지면, 학습 없이도 새로운 물체를 분할할 수 있는 제로샷 분할 모델(논문에서는 CNOS를 사용)을 통해 타겟 물체의 영역을 먼저 찾아냅니다. 이 과정을 통해 배경과 분리된 타겟 물체 이미지를 얻고, 이를 CAD 모델로부터 렌더링된 여러 템플릿 이미지들과 함께 고정된 크기(H \times W)로 조절하여 네트워크의 입력으로 사용합니다.
Stage 1: Feature Matching for Coarse Correspondences
첫 번째 단계의 목표는 수많은 템플릿 중에서 현재 이미지와 가장 잘 맞는 최적의 템플릿을 찾고, 둘 사이의 대략적인 대응 관계를 설정하는 것입니다.
이를 위해 사전 학습된 DINOv2 (ViT-L)를 사용하여 이미지(\mathcal{I})와 각 템플릿(\mathcal{T}i)의 패치 특징(\mathcal{F}\mathcal{I}, \mathcal{F}_{\mathcal{T}_i})을 추출합니다. 그 후, 아래 수식 (1) 과 같이 각 템플릿의 매칭 점수(c_i)를 계산합니다.
c_{i}=\frac{1}{N^{\prime}}\sum_{j\in\mathfrak{FG}(\mathcal{F}{\mathcal{I}})}max{k=1,…,N}\frac{<f_{\mathcal{I},j},f_{\mathcal{T}{i},k}>}{|f{\mathcal{I},j}|\cdot|f_{\mathcal{T}_{i},k}|}이 수식은 이미지에 해당하는 각 패치(f_{\mathcal{I},j})에 대해, 현재 비교 중인 템플릿(\mathcal{T}i) 내에서 코사인 유사도가 가장 높은 패치(f{\mathcal{T}_i,k})를 찾고, 이 최대 유사도 값들의 평균을 내어 최종 점수로 삼는다는 의미입니다. 이렇게 계산된 점수가 가장 높은 템플릿(\mathcal{T})이 최적의 템플릿으로 선택되며, 이때의 특징 유사도를 기반으로 초기 대응점이 형성됩니다.
Stage 2: Global Transformation Estimation for Smooth Correspondences
1단계에서 얻은 대응점은 노이즈가 많기 때문에, 2단계에서는 이를 매끄럽게 다듬는 것을 목표로 합니다. PicoPose는 두 이미지 간의 2D 어파인 변환(Affine Transformation)을 예측하여 이 문제를 해결합니다. 이 변환 행렬 \mathcal{M}은 수식 (2) 와 같이 스케일(s), 평면상 회전(\alpha), 그리고 2D 이동(t_u, t_v) 파라미터로 구성됩니다.
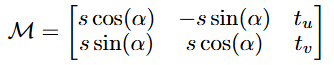
여기서 독특한 점은, 이 변환을 예측하기 위해 두 이미지의 특징을 직접 사용하는 대신, 두 특징 맵의 내적으로 계산된 대응점 맵(\mathcal{A}) 자체를 CNN과 MLP의 입력으로 사용한다는 것입니다. 이 대응점 맵은 트랜스포머의 크로스-어텐션 맵과 유사한 역할을 한다고 생각하면 이해하기 쉽습니다. 즉, 이미지의 각 부분이 템플릿의 어느 부분과 가장 유사한지를 나타냅니다. 저자들은 이 맵이 두 이미지 간의 기하학적 변환 정보를 더 효과적으로 담고 있기 때문에, 이로부터 직접 변환을 추정하는 것이 더 효과적이라고 주장합니다.
Stage 3: Local Refinement for Fine Correspondences
마지막 3단계는 2단계에서 얻은 매끄럽고 전역적으로 정렬된 대응점을 픽셀 수준으로 정밀하게 만드는 과정입니다. 이 단계의 핵심은 계층적(hierarchical)이고 점진적인 정제 방식에 있습니다.
먼저 DPT 를 통해 입력 이미지와 템플릿으로부터 저해상도부터 고해상도까지 여러 스케일의 특징 맵을 추출합니다. 그 다음, 여러 개의 Offset Regression Block 이 이 계층적 특징 맵을 순차적으로 활용합니다. 첫 번째 블록은 가장 coarse 저해상도 특징 맵을 사용하여 대응점의 큰 오차를 보정하는 초기 옵셋을 예측합니다. 이렇게 한 번 보정된 대응점 정보는 다음 블록으로 전달되고, 다음 블록은 더 높은 해상도의 특징 맵을 사용하여 더 세밀한 옵셋을 예측합니다. 이 과정이 가장 높은 해상도의 특징 맵까지 반복되면서, 대응점은 점차 픽셀 수준으로 정밀해집니다.
각 옵셋 회귀 블록 내부에서는 RAFT에서 제안된 Correlation Lookup 모듈 이 중요한 역할을 합니다. 이 모듈은 두 특징 맵 간의 지역적인 상관관계를 명시적으로 계산하여, 현재 대응점 주변의 특징이 얼마나 유사한지에 대한 풍부한 정보를 제공합니다. 이를 바탕으로 블록은 이동해야 할 정확한 좌표 옵셋(\Delta\mathcal{P}) 과 해당 예측에 대한 확실성(\mathcal{S}) 을 함께 추정합니다.
결론적으로, 3단계는 이러한 coarse-to-fine 전략을 통해 큰 오차부터 미세한 오차까지 단계적으로 보정함으로써, 최종적으로 매우 정확한 픽셀 단위의 대응점을 완성하는 핵심적인 과정입니다.
Training of PicoPose
PicoPose는 3단계의 점진적 학습 파이프라인 전체를 End-to-End 방식으로 학습합니다. 전체 손실 함수(\mathcal{L})는 각 단계의 손실 함수들의 합으로 구성됩니다.
\mathcal{L}=\mathcal{L}{coarse}+\mathcal{L}{smooth}+\mathcal{L}_{fine}첫 번째 단계의 손실 함수(\mathcal{L}_{coarse}) 는 특징 매칭을 위한 것으로, InfoNCE 손실(contrastive loss) 을 사용합니다. 이는 올바른 대응점(positive pair)의 유사도는 높이고, 잘못된 대응점(negative pair)의 유사도는 낮추도록 특징 표현을 학습시키는 방식입니다.
두 번째 단계의 손실 함수(\mathcal{L}_{smooth}) 는 2D 어파인 변환 파라미터를 예측하기 위해 사용됩니다. 회전 각도(\alpha)에 대해서는 각도의 순환적 특성을 올바르게 처리할 수 있는 Geodesic Distance를 사용하고, 스케일(s)과 2D 이동(t_u, t_v)에 대해서는 L1 거리를 사용하여 예측값과 실제 정답 간의 차이를 줄이도록 학습합니다.
마지막 세 번째 단계의 손실 함수(\mathcal{L}_{fine}) 는 좌표 옵셋(\Delta\mathcal{P})과 확실성(\mathcal{C}) 맵을 학습시키기 위해 두 가지 항의 가중치 합으로 이루어집니다. 첫 번째 항은 예측된 옵셋과 실제 옵셋 간의 L1 손실이며, 이때 확실한 대응점에 대해서만 손실이 계산되도록 마스킹됩니다. 두 번째 항은 예측된 확실성 맵 자체를 학습시키기 위한 BCE(Binary Cross-Entropy) 손실을 사용합니다.
Experiments
제안된 PicoPose의 성능을 검증하기 위해, 저자들은 먼저 실험 환경을 설정했습니다. 모델 학습에는 ShapeNet-Objects와 Google-Scanned-Objects의 합성 데이터를 사용했으며, 성능 평가는 LM-O, T-LESS, YCB-V 등이 포함된 7개의 BOP 벤치마크 핵심 데이터셋에 대해 수행되었습니다. 평가 지표로는 BOP 벤치마크의 표준인 AR을 사용했으며, 추가적으로 대응점의 품질을 평가하기 위해 EPE를 측정했습니다.
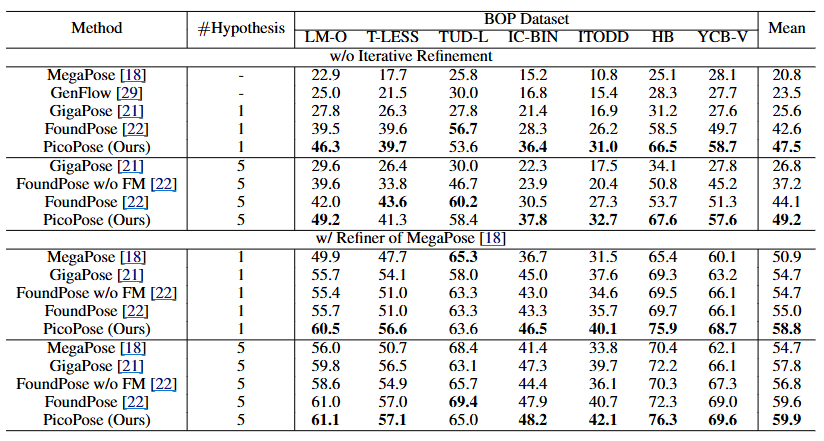
본격적인 성능 비교를 위해 PicoPose를 GigaPose, FoundPose 등 기존의 SOTA 모델들과 비교한 결과는 위 표에서 자세히 확인할 수 있습니다. 이 표를 보면 ‘#Hypothesis’라는 항목이 있는데, 이는 모델이 최종 자세를 결정하기 전에 생성하는 자세 후보의 수를 의미합니다. 가설이 1개인 경우는 가장 가능성이 높은 단 하나의 자세를 추정하는 것이고, 5개인 경우는 5개의 유력한 자세 후보를 생성한 뒤 그중에서 최적의 자세를 선택하여 강인함을 높이는 방식입니다.
PicoPose는 가설을 1개만 사용한 경우와 5개를 사용한 경우 모두에서 다른 모델들을 큰 차이로 능가하는 SOTA 성능을 달성했습니다. 예를 들어, 5개의 가설을 사용했을 때 후처리가 없는 PicoPose는 GigaPose보다 22.4%, FoundPose보다는 5.1% 높은 AR 점수를 기록했습니다. 이러한 정량적 결과는 아래 fig에서 시각적으로도 뒷받침되는데, 다른 모델들에 비해 PicoPose가 훨씬 정확하게 자세를 추정하는 것을 확인할 수 있습니다.

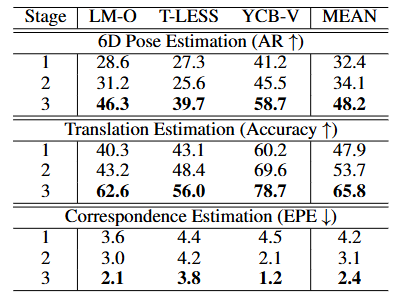
다음으로 저자들은 제안한 방법론의 각 구성 요소가 실제로 효과적인지를 검증하기 위해 Ablation Study를 수행했습니다. 이 표는 Stage 1에서 Stage 3으로 진행될수록 6D 성능(AR)과 이동(Translation) 정확도가 일관되게 향상되는 것을 명확하게 보여줍니다. 또한, 대응점 품질을 나타내는 EPE (End-Point-Error, 픽셀 단위 오차)는 수치가 낮을수록 좋은데, 이 역시 단계가 진행될수록 꾸준히 감소하는 것을 볼 수 있습니다. 이는 PicoPose의 핵심 주장인 점진적 정제의 효과를 강력하게 입증합니다.
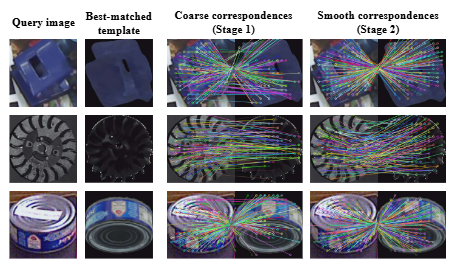
Conclusion
PicoPose는 ‘점진적 픽셀 대 픽셀 대응점 학습’이라는 효과적인 3단계 파이프라인을 통해, RGB 이미지 기반 6D 자세 추정의 SOTA 성능을 달성한 연구입니다.
다만, 저자들이 언급했듯 몇 가지 한계점도 명확합니다. 템플릿의 수에 성능이 의존하여 정확도와 실시간성 간의 트레이드오프가 발생하며 초기 추정 성능이 매우 높아 기존 후처리기로는 추가적인 성능 향상이 미미합니다. 또한, 단일 이미지 시나리오에서는 3D 모델 복원 성능이 전체 성능을 좌우하는 병목 현상도 존재한다고 합니다.
감사합니다
안녕하세요. 리뷰 잘 보았습니다.
우선 해당 방법론은 관심 object에 대하여 template이라는 개념이 존재하는 것 같은데, 원래 6D pose에서는 이 template이라는 개념이 항상 입력으로 들어올 수 있나요? 제가 6D pose쪽을 잘 모르긴하지만 예전에 한번 과제 제안서 때문에 서베이할 때 보기로는 이쪽에서 생각하는 unseen의 개념이 vision 쪽이랑은 많이 다르다고 듣긴 했었는데.. 아무래도 template이 있다는 것 자체가 실용적인 관점에서는 무언가 적용하기 어려울 것 같아서요.
추론 단계에서 3D 캐드 정보가 같이 제공되는 데이터가 항상 들어오기는 현실적으로 어려울 것 같은데, 요즘은 이미지 한장으로 3D 캐드 모델을 생성해주는 foundation model이 있다고 지난번 세미나에서 보았던 것 같아서 그런 모델을 먼저 적용하면 이 문제가 해결될까 라는 생각도 들긴 하는데 우진님은 이 template을 활용하는 framework에 대해 어떻게 생각하시는지 궁금하네요.
그리고 여기서는 feature matching을 위해 DINOv2의 feature를 활용하는 것 같은데 이번 ICCV2025에 게재된 논문 중 “Mind the Gap: Aligning Vision Foundation Models to Image Feature Matching”이라는 제목의 논문이 있어요. 여기서는 DINOv2가 생각보다 feature matching을 수행하는데 있어 적합하지 않은 feature라고 주장하고 오히려 stable diffusion과 같은 생성 모델이 강건한 feature matching을 수행하는데 도움이 더 된다고 하더라구요.
관심 있으시면 논문 한번 찾아서 읽어보시고 우진님이 하시는 연구에 응용해봐도 좋을 것 같아서 말씀드립니다.
안녕하세요 우진님. 좋은 리뷰 잘 읽었습니다.
읽으면서 몇가지 궁금한 점이 생겨서 질문 드립니다!
우진님이 말하신대로 이 모델은 템플릿의 수에 따라 정확도와 실시간성의 트레이드오프가 발생할 것 같습니다.
그래서 궁금한 점이 다른 모델들과 성능을 비교한 부분에서 picopose 모델의 템플릿 수가 논문에 나와있거나, 속도 부분에서 비교한 자료는 있나요? 아니면 제가 잘 몰라서 그러는데 모델 성능을 비교할 때는 시간적인 측면을 보통 잘 고려하지 않나요..? 뭔가 정확도만 비교한 것 같아 말씀하신 트레이드오프의 단점을 무시한 것 같아서 질문드립니다.
좋은 리뷰 감사합니다.
우진님 좋은 리뷰 감사합니다.
해당 방법론은 DINOv2 feature로 대응점을 구한 뒤 바로 이후의 작업을 수행하는 것이 아니라, feature 사이의 similarity를 구한 map을 이용하여 CNN과 MLP 입력으로 사용하여 2D affine transformation을 예측한 뒤, 여러 Offset Regression Block을 통해 저해상도의 대응점 정보를 보정에 활용하여 점차 고해상도의 대응점 정보를 찾는 방식으로 6D Pose Estimation을 하는 것으로 이해하였습니다.
이와 관련하여 궁금한 점이 있습니다. DinoV2 feature로 similarity를 구한 map으로부터 구한 2D affine transformation은 이후 네트워크에 활용이 되는 지 설명이 따로 없어 궁금합니다. 대략적인 pose를 구하는 데 사용이 될 것 같았는데, 이후에는 loss에만 확인이 가능하여 질문 남깁니다.
또한, 해당 방법론이 novel object에 대하여 다루는 연구로 이해하였는데, 이에 해당하는 실험을 따로 없었나요?
안녕하세요 우진님 리뷰 감사합니다.
DINO feature를 사용한 대응점은 노이즈가 많아 2D Affine 변환을 활용해 refine한다는 부분이 설명에 있었는데요, 2D ffine matrix가 어떤 역할을 하는건가요? L_smooth로 학습시에 사용되는 것으로 이해했는데 조금 더 설명 부탁드리겠습니다.
또 마지막 사진이 Novel object들인가요?? 실험 결과에 대해서도 조금만 더 설명 부탁드리겠습니다!