다시 CVPR 2025 Highlight 논문들을 중심으로 다양한 연구를 리뷰해보려고 합니다.

- Conference: CVPR 2025 (Highlight)
- Authors: Shaoan Xie, Lingjing, Yujia Zheng, Yu Yao, Zeyu Tang, Eric P. Xing, Guangyi Chen, Kun Zhang
- Affiliation: Carnegie Mellon University, Mohamed bin Zayed University of Artificial Intelligence, University of Sydney
- Title: SmartCLIP: Modular Vision-language Alignment with Identification Guarantees
1. Introduction
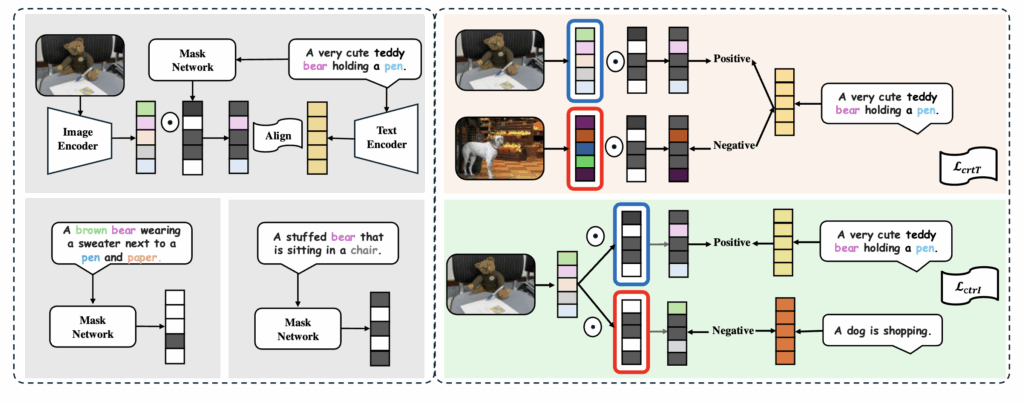
아시다시피, CLIP은 최근 멀티모달 학습에서 가장 대표적인 VLP 모델입니다. 이미지와 텍스트를 쌍으로 맞추는 contrastive learning 방식을 통해, 다양한 downstream task에서 뛰어난 성능을 보여주었죠. 하지만 CLIP에도 구조적인 한계가 존재한다고 합니다.

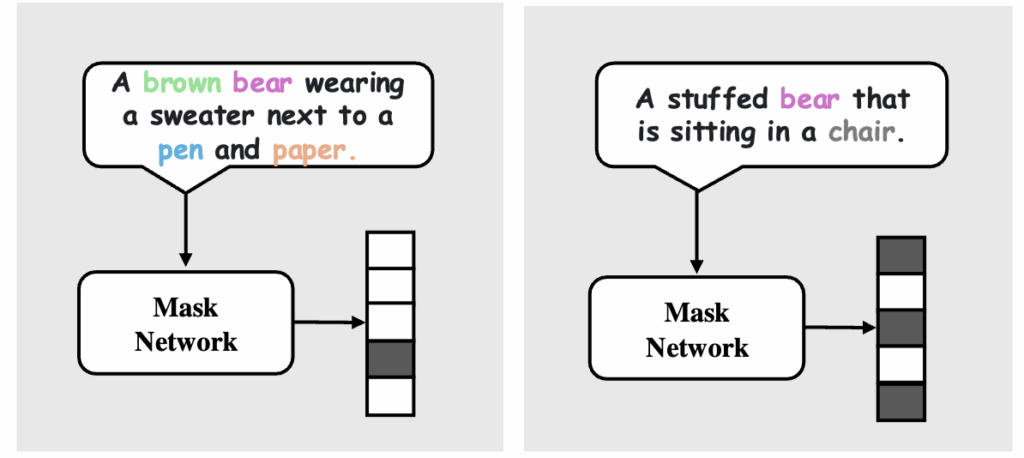
첫 번째는 Information Misalignment입니다. 예를 들어 Figure 1의 곰 인형 예시를 보면, 하나의 이미지에 대해 “펜을 쥔 곰인형” 혹은 “의자에 앉아 있는 곰인형”과 같이 서로 다른 관점을 강조하는 캡션들이 존재할 수 있습니다. CLIP은 모든 캡션을 동일한 정답으로 학습하기 때문에, 특정 캡션에 없는 개체(예: 의자, 종이, 펜 등)가 학습 과정에서 무시될 수 있습니다. 결국 이미지와 텍스트 사이에 중요한 개념들이 정렬되지 못하는 문제가 발생하는 것이죠.

두 번째는 Entangled Representations입니다. 최근 ShareGPT4V와 같은 모델은 더 풍부한 설명을 제공하지만, 지나치게 길고 세부적인 캡션은 또 다른 문제를 낳습니다. Figure 1 하단 캡션을 보면, “검은색 줄무늬 의자”, “초록 스웨터와 노란 꽃 장식”, “파란 펜”, “회색 카펫 바닥”, “종이 더미” 등 다양한 개념이 모두 한 문장 안에 등장합니다. CLIP이 이런 복잡한 문장을 그대로 학습하면, 각각의 개념을 분리해서 이해하지 못하고 얽힌 상태로 표현을 배우게 된다고 합니다. 그러면 특정 개체만 따로 인식해야 하는 downstream task(ex. 곰만 검색하기) 에서는 성능 저하가 불가피하다고 하죠
저자들은 이 두 가지 문제를 해결하기 위해, 텍스트와 이미지 표현을 모듈화된 방식으로 정렬할 수 있는 새로운 프레임워크를 제안하였습니다. 핵심은 이미지 표현 전체를 캡션과 무조건 맞추는 대신, 각 캡션이 실제로 포함하는 개념에 해당하는 부분만 선택적으로 정렬한다는 것입니다. 이 아이디어를 이론적으로 토대를 확인한 뒤, SmartCLIP이라는 새로운 방법론을 제시하였고, 다양한 리트리벌·분류·생성 태스크에서 CLIP과 Long-CLIP을 뛰어넘는 성능을 보여주었다고 합니다. 본격적인 설명 시작하겠습니다.
2. Problem Formulation
저자들이 풀고자 하는 핵심 문제는 두 가지입니다. 첫째, 이미지와 텍스트가 공유하는 전체 의미 정보를 가능한 한 보존하는 것이고, 둘째, 텍스트 캡션이 담고 있는 개별 개념들을 분리(disentangle)해서 표현하는 것입니다. 다시 말해, CLIP이 흔히 겪는 정보 손실과 얽힌 표현(entangled representation)의 문제를 이론적으로 정의하려는 단계라고 할 수 있습니다.
이를 위해 저자들은 비전-언어 데이터가 만들어지는 과정을 생성적 관점에서 바라봤다고 합니다. 기본 아이디어는 단순합니다.
하나의 이미지는 본질적으로 어떤 잠재 의미 벡터 \mathbf{z}_I \in \mathbb{R}^{d(\mathbf{z}_I)}를 갖고 있다고 가정합니다. 여기에는 곰, 의자, 펜 같은 모든 개체 정보가 포함되어 있습니다. 하지만 실제 캡션은 이 중 일부 정보만을 표현합니다. 예를 들어, “곰이 펜을 들고 있다”라는 문장은 ‘곰+펜’ 정보만 남기고 ‘의자’는 빠뜨린 것이죠.
이 과정을 수식으로 나타내면 다음과 같습니다.
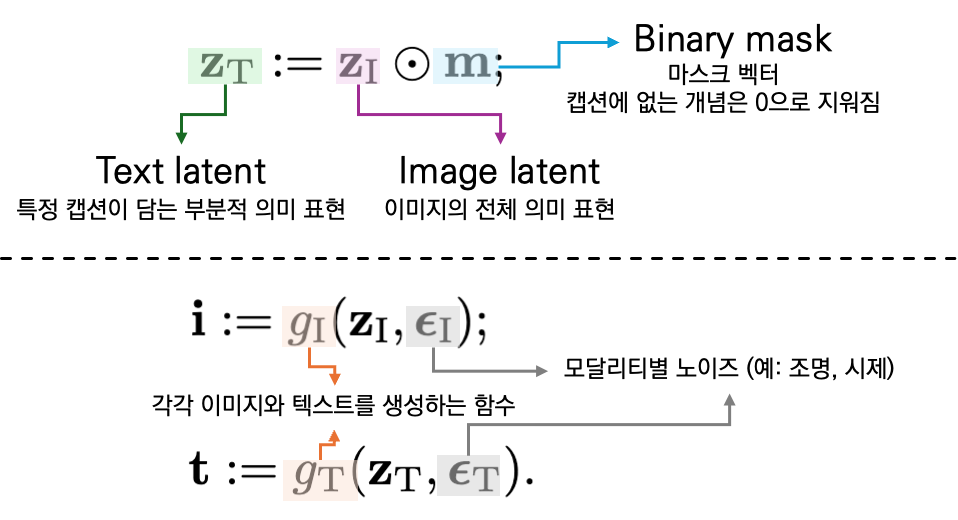
즉, 텍스트는 이미지 의미 \mathbf{z}_I의 부분 집합 표현으로 정의되며, 아래 Figure 2는 이 과정을 그림으로 도식화하여 보여줍니다. 하나의 이미지 의미가 여러 개의 캡션으로 파생되면서, 각 캡션마다 포함된 정보만 남고 나머지는 마스크 처리되는 모습이 도식적으로 표현되어 있습니다.
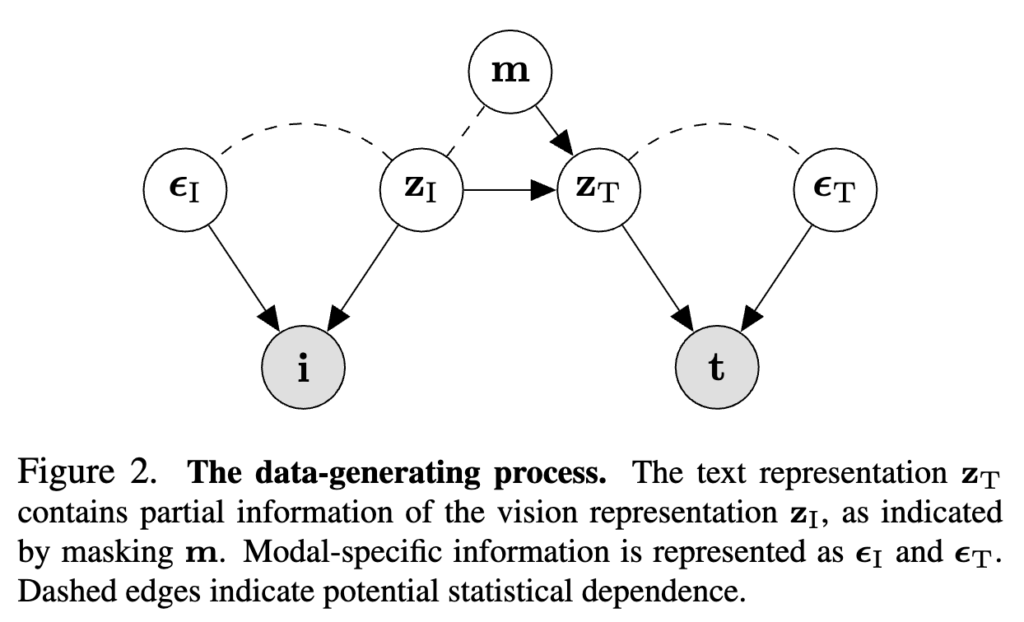
2.1 Goals
이제 두 가지 목표를 정리할 수 있습니다.
(a) Cross-modal 정보 보존
여러 캡션이 제각각 일부 정보만 담더라도, 모델은 원래 의미 벡터 zI\mathbf{z}_IzI 전체를 보존해야 합니다.
(b) 개념 분리 (Disentanglement)
각 캡션이 지칭하는 개별 개념들을 분리하여 표현해야 합니다. 예를 들어, 학습 데이터에 “곰+펜” \mathbf{m}^{(1)} = [1,0,1]과 “곰+의자” \mathbf{m}^{(2)} = [1,1,0]만 있어도, 모델은 “곰”이라는 개념을 독립적으로 이해할 수 있어야 합니다.
정리하면, 이 장의 핵심 아이디어는 텍스트 = 이미지 의미에 마스크를 씌운 부분 표현이라는 관점입니다. 이를 통해 저자들은 CLIP의 두 가지 문제였던 정보 손실과 얽힌 표현을 각각 Goal (a)와 Goal (b)로 대응시켰습니다.
3. Identification Theory
이번 장에서는 이제 “SmartCLIP이 어떻게 하면 실제로 목표(a: cross-modal 정보 보존, b: 개념 분리)를 달성할 수 있는가?”라는 이론적 근거를 보입니다. 핵심은 학습 목표(objective)를 잘 설계하면, 학습된 표현 (\hat{\mathbf{z}}_I, \hat{\mathbf{z}}_T)이 실제 의미 표현 (\mathbf{z}_I, \mathbf{z}_T)과 동일한 수준으로 식별 가능하다는 것입니다.
3.1 Block-wise Identifiability란?
여기서 저자들이 사용하는 중요한 개념이 바로 block-wise identifiability입니다.
- 보통 ‘identifiability’란 학습된 표현이 원래의 의미 표현과 정확히 대응될 수 있음을 말한다고 합니다.
- 하지만 실제로는 개념 하나(예: 곰)가 벡터 공간의 단일 차원에만 매핑되지 않고, 여러 차원에 흩어져 표현되는 경우가 많습니다.
- 따라서 ‘곰’이라는 개념을 하나의 차원으로 식별하기는 어렵고, 여러 차원을 묶은 차원 블록(block)을 통해서만 안정적으로 대응할 수 있습니다.
즉, block-wise identifiability는 “개별 차원” 대신 “차원들의 묶음”을 개념 단위로 안정적으로 식별할 수 있는 성질이라고 할 수 있을 것 같습니다. 이를 통해 ‘곰’이라는 개념이 10개 차원에 흩어져 있어도, 그 묶음을 전체적으로 곰이라는 개념과 연결할 수 있게 됩니다.
3.2 Learning Objective
모델은 이미지 인코더 f_I, 텍스트 인코더 f_T, 그리고 마스크 추정 함수 \hat{\mathbf{m}}로 구성됩니다. 학습은 두 가지 Loss를 동시에 최소화합니다.
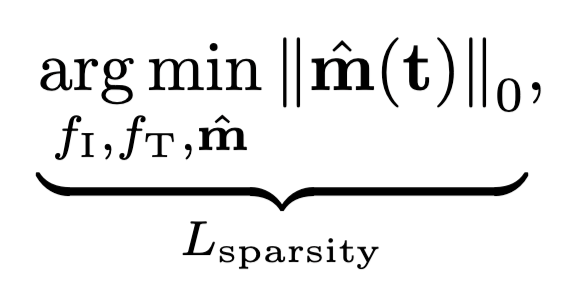
(1) Sparsity loss L_{\text{sparsity}} = \|\hat{\mathbf{m}}(t)\|_0
→ 가능한 단순한 마스크를 선택하여, 캡션이 담고 있는 핵심 개념만 뽑아내도록 함.
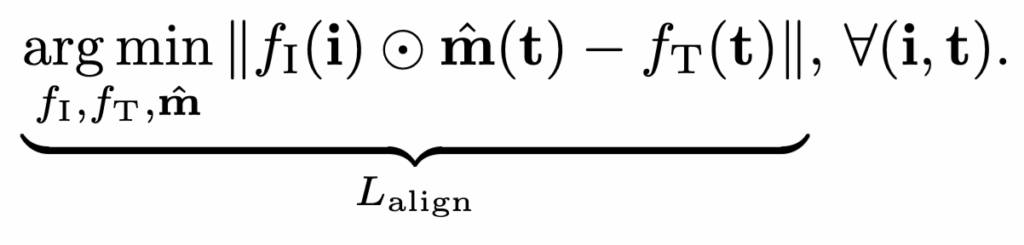
(2) Alignment loss L_{\text{align}}
→ 이미지 표현과 텍스트 표현이 올바르게 정렬되도록 함. 즉, 마스크로 걸러낸 이미지 표현이 해당 텍스트 캡션과 일치해야 함.
3.3 Identification 조건
block-wise identifiability를 보장하기 위해서는 두 가지 조건이 필요합니다.
Smoothness & Invertibility:
이미지·텍스트를 생성하는 함수 g_I, g_T가 매끄럽고 역함수를 가져야 합니다. 이렇게 해야 의미 표현이 손실되지 않습니다.
Fully-supported joint distribution:
의미 표현 \mathbf{z}_I와 마스크 \mathbf{m}의 조합이 충분히 다양한 형태로 나타나야 합니다. 여러 조합이 있어야 “곰”, “의자”, “펜” 같은 개별 개념을 disentangle할 수 있습니다.
3.4 Theorem 4.3
따라서 위 조건이 충족될 경우, 학습된 표현은 block-wise identifiable합니다. 즉,
- 여러 캡션을 합집합(union) 하면 모든 개념이 표현에 보존됨 (-> Goal a).
- 여러 캡션을 교집합(intersection) 하면 겹치는 개념을 독립적으로 분리해낼 수 있음 (-> Goal b).
예를 들어 “곰+펜”, “곰+의자”라는 두 캡션이 있으면,
- 합집합은 “곰, 펜, 의자” 전체를 보존하고,
- 교집합은 “곰”이라는 개념을 분리해낼 수 있습니다.
따라서 block-wise identifiability란 “한 차원이 아니라 여러 차원의 묶음을 통해 개념을 안정적으로 식별할 수 있는 성질”입니다. SmartCLIP은 sparsity + alignment 학습 목표와 위 두 조건을 만족시킴으로써, 모든 개념을 보존하면서도 세분화된 disentanglement까지 이론적으로 보장할 수 있었다고 하네요.
4. SmartCLIP
앞선 이론적 토대를 바탕으로, SmartCLIP은 실제 학습 과정에서 adaptive masking과 modular contrastive learning을 통해 Goal a(정보 보존)와 Goal b(개념 분리)를 구현합니다. Figure 3은 이러한 과정을 구체적으로 보여줍니다.
4.1 Adaptive Masking
Positive pair
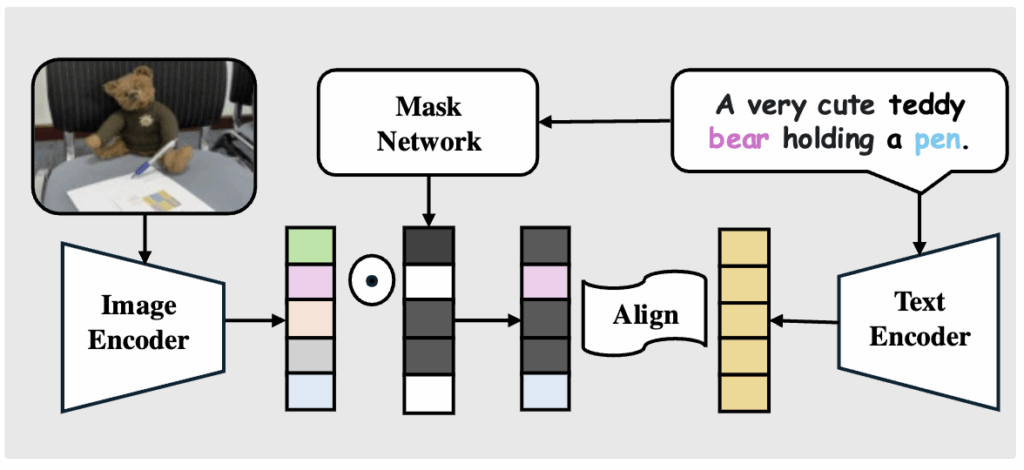
ㄴㄴ상단 그림을 보면 이미지 인코더가 추출한 표현에서 ㄴMask Network가 특정 차원만 남기는 것을 볼 수 있습니다. 예를 들어 “곰”과 “펜”을 언급하는 캡션이라면, 마스크 네트워크는 해당 개념에 해당하는 차원만 선택합니다. 이렇게 마스크된 이미지 표현은 대응되는 텍스트 인코더 출력과 Positive Pair로 정렬됩니다.
즉, 캡션이 포함한 개념 단위로 이미지와 텍스트가 정확히 매칭되도록 유도하는 것이죠.
이 때, mask network인 \hat{\mathbf{m}}(\cdot)는 Transformer 기반 블록입니다.
- 입력: 캡션 표현 \hat{\mathbf{z}}_T
- 출력: 각 개념 차원에 대한 이진 마스크 \hat{\mathbf{m}}(\hat{\mathbf{z}}_T)
Negative pair
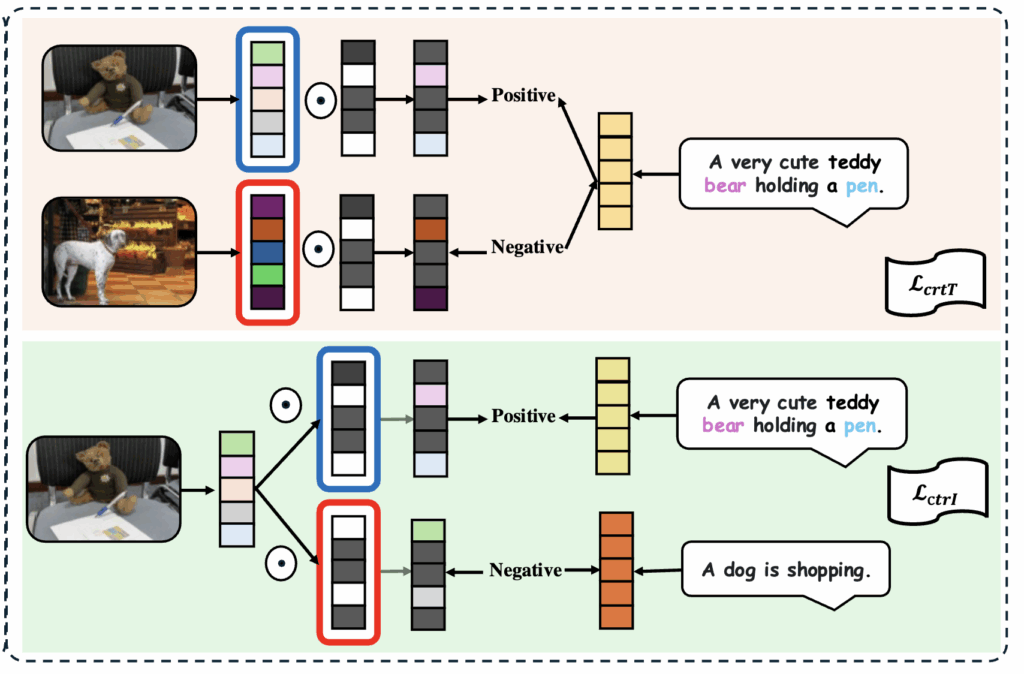
- 주황 박스, \text{ctrT}}: 올바른 이미지와 캡션 쌍이 있을 때, 같은 캡션을 다른 이미지 표현과 연결해 “negative pair”
- 초록 박스, </strong>L_{\text{ctrI}}<strong>: 반대로 올바른 이미지를 유지한 채, 엉뚱한 캡션과 연결해 “nagetive pair”
이렇게 positive/negative를 동시에 학습하면, 모델은 올바른 개념 조합만 강하게 연결하고, 무관한 조합은 분리하도록 학습됩니다.
상단 그림을 보면, 다른 캡션마다 선택되는 마스크가 달라지는 걸 확인할 수 있습니다. 예를 들어 하나의 캡션은 “곰+펜”을, 다른 캡션은 “곰+의자”를 활성화합니다. SmartCLIP은 sparsity penalty를 추가하여, 가능한 최소한의 차원만 활성화되도록 만들어 개별 개념이 disentangle되도록 유도합니다.
4.2 Modular Contrast Construction
일반적인 CLIP은 이미지-텍스트 간 Contrastive learning을 통해 정렬을 수행합니다. SmartCLIP도 이 방식을 확장하되, 마스크를 통해 더 정밀한 모듈 단위 정렬을 수행합니다. 우선 기존 CLIP에서의 Loss 수식은 아래와 같습니다.
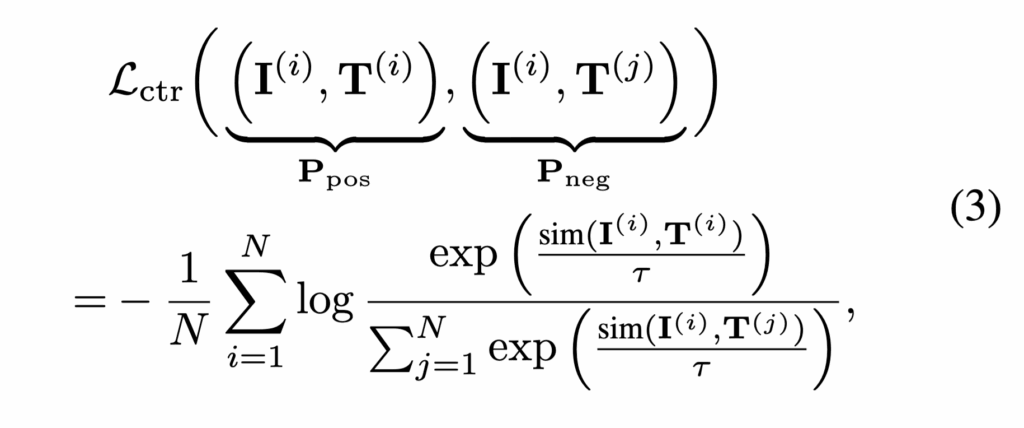
이 때, \tau: temperature, \text{sim}(\cdot): cosine similarity.
SmartCLIP은 두 가지 변형된 Loss를 사용합니다:
- \mathcal{L}_{\text{ctrI}}: 동일한 텍스트에 다른 이미지 표현을 네거티브 샘플로 사용
- \mathcal{L}_{\text{ctrT}}: 동일한 이미지에 다른 텍스트 표현을 네거티브 샘플로 사용
다시말해, 이미지 쪽과 텍스트 쪽 모두에서 모듈 단위로 negative sampling을 수행한 것이죠
4.3 Positive / Negative Pair 정의
따라서 SmartCLIP의 핵심은 positive와 negative pair를 마스크 기반으로 정의하는 것입니다.
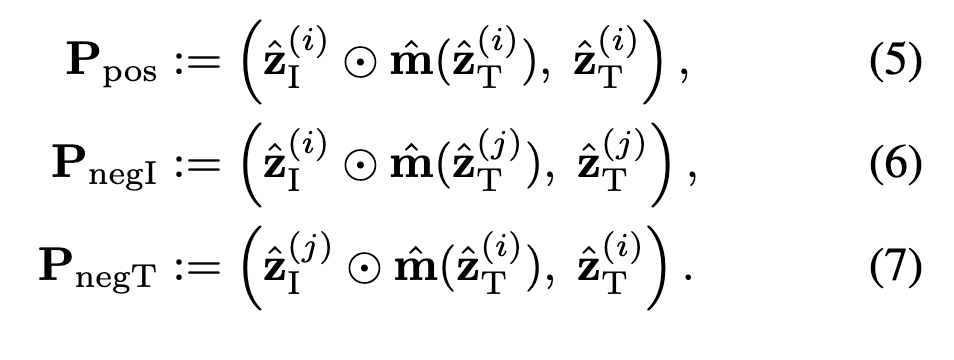
- \mathbf{P}_{\text{pos}}: 올바른 이미지-텍스트 쌍
- \mathbf{P}_{\text{negI}}: 이미지 쪽은 고정, 텍스트는 랜덤 샘플
- \mathbf{P}_{\text{negT}}: 텍스트 쪽은 고정, 이미지는 랜덤 샘플
이 구조를 통해 SmartCLIP은 텍스트가 선택한 개념 모듈 단위에서 정밀하게 Contrastive Learning을 수행할 수 있다고 합니다
4.4 Sparsity penalty
앞서 정의했던 sparsity loss도 포함됩니ㄴ다. 논문에서는 \ell_0 대신 학습 친화적인 \ell_1[/latex] Regularization를 사용하였습니다
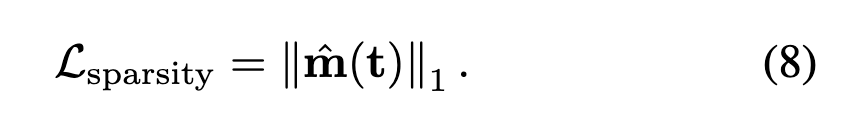
이는 텍스트가 가능한 최소한의 차원만 사용해 개념을 표현하도록 유도해, 개념 disentanglement를 강화하는 것이죠
4.5 SmartCLIP training objective
이제 최종 Loss입니다.
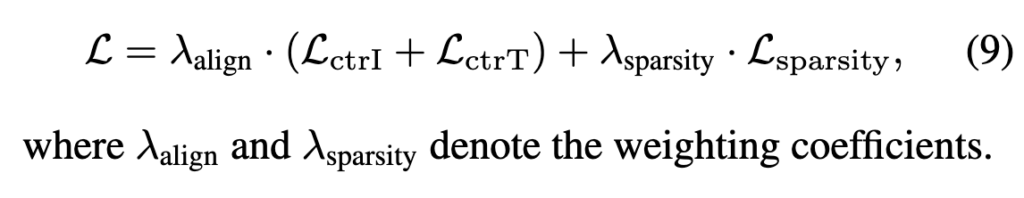
조금 내용이 복잡했으니 정리하자면... SmartCLIP은
- Adaptive Masking으로 캡션이 지칭하는 개념을 명시적으로 추정하고,
- Modular Contrastive Learning을 통해 모듈 단위의 이미지-텍스트 정렬을 수행하며,
- Sparsity Penalty로 개념을 가능한 최소한의 차원만 사용해 표현하도록 유도한 것이죠
5. Experiment
5.1 Benchmarks
(Table 1) Image-Text Retrieval (MS-COCO, Flickr30k)
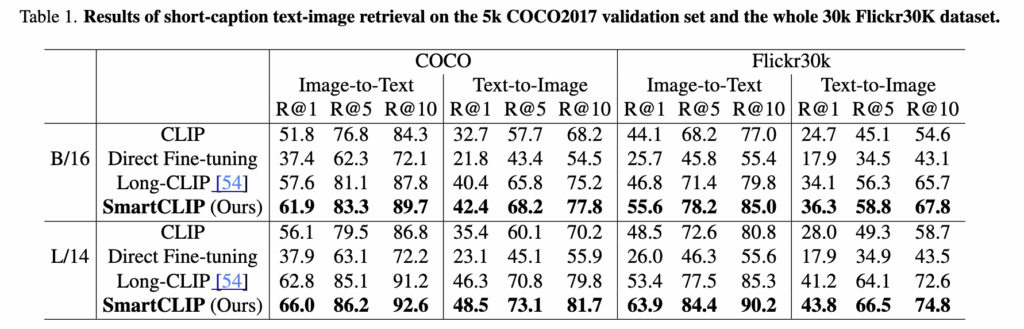
저자는 SmartCLIP을 COCO와 Flickr30k 벤치마크에서 평가하였습니다. 기존 CLIP 대비 SmartCLIP은 R@1, R@5, R@10 지표에서 모두 큰 폭의 성능 향상을 보였으며, 특히 cross-modal retrieval 시 더 세밀한 개념 매칭 능력을 보여주었습니다. 예를 들어 COCO에서 R@1 기준 +4.2% 향상이 있었고, Flickr30k에서는 R@1 +5.6% 개선을 기록했습니다. 이는 SmartCLIP의 adaptive masking이 캡션 속 부분 개념들을 올바르게 disentangle하여 retrieval 정확도를 끌어올린 결과로 볼 수 있습니다.
(Table 2) Robustness to Caption Noise
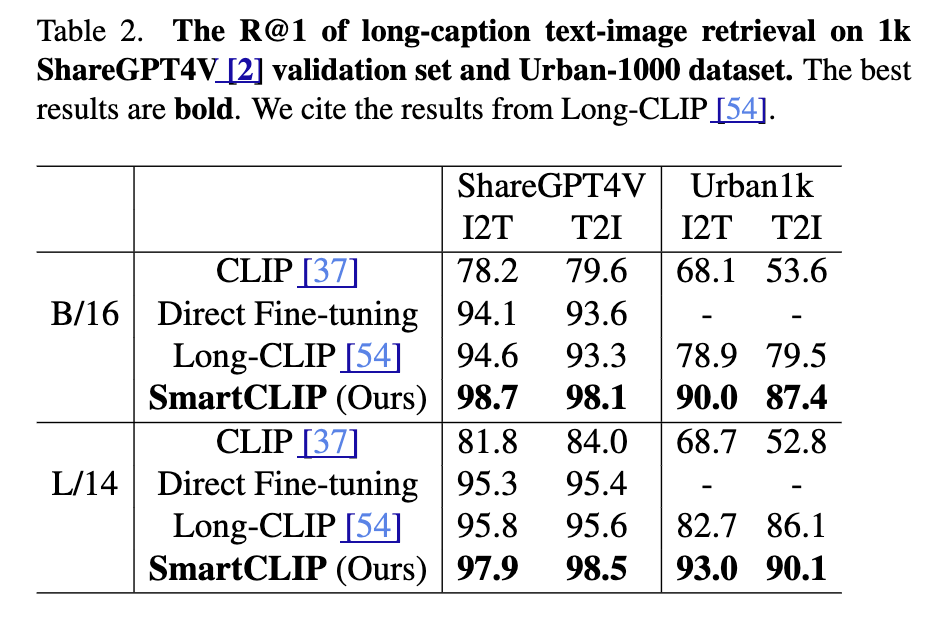
SmartCLIP은 캡션에 불필요한 수식어나 잡음이 포함될 경우에도 강건한 성능을 보였습니다. Table 2에 따르면, 기존 CLIP은 노이즈 비율이 높아질수록 성능이 급격히 저하되지만, SmartCLIP은 상대적으로 완만한 성능 하락을 보이며 안정성을 유지했습니다. 이는 마스크 네트워크가 핵심 개념만 남기고 불필요한 부분을 억제하는 역할을 수행했기 때문으로 해석된다고 합니다.
(Table 3) Zero-Shot Transfer
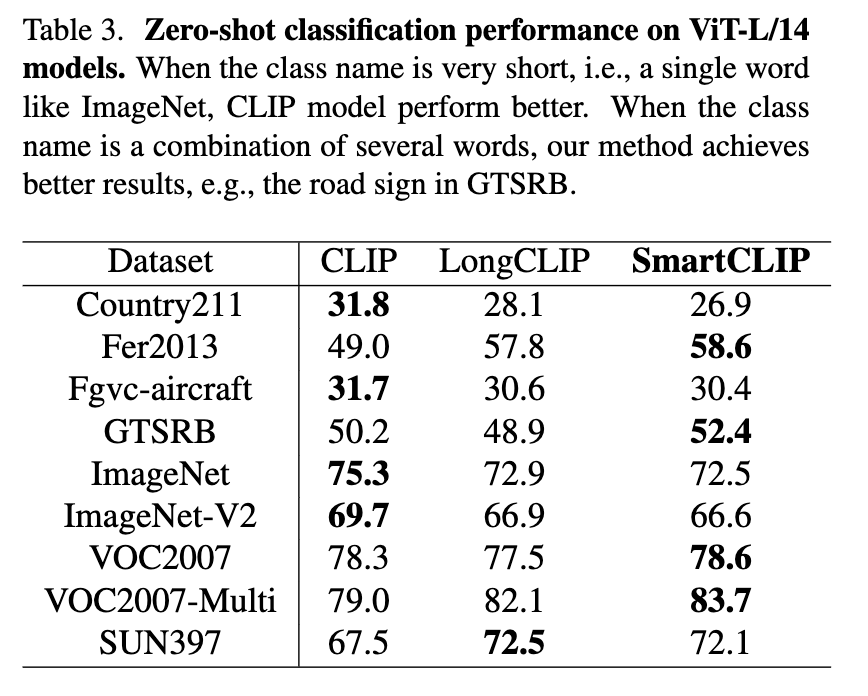
SmartCLIP은 학습에 포함되지 않은 새로운 도메인으로 transfer했을 때도 우수한 zero-shot 성능을 기록했습니다. COCO에서 학습한 후 Flickr30k로 평가했을 때, CLIP 대비 SmartCLIP은 R@1 성능이 +3.1% 개선되었으며, 반대 방향에서도 일관된 성능 향상이 확인되었습니다. 이는 SmartCLIP이 개념 단위 표현을 disentangle한 덕분에, 새로운 도메인에서도 안정적으로 개념 정렬을 수행할 수 있음을 보여주었다고 하네요.
5.2 Ablation Study
(Figure 4) Effect of Masking Strategy

Figure 4는 SmartCLIP에서 제안하는 adaptive masking이 성능에 미치는 영향을 분석한 결과입니다. 마스크 없이 전체 표현을 사용하는 경우 성능이 하락했으며, 랜덤 마스크를 적용했을 때도 불안정한 결과를 보였습니다. 반면 adaptive masking은 각 캡션에 맞게 활성 차원을 조절하여 가장 높은 성능을 달성했습니다. 이를 통해 마스크 네트워크가 단순한 feature selection을 넘어 의미 단위의 정렬에 기여한다는 점을 확인할 수 있었습니다.
(Figure 6) Qualitative Results

Figure 6은 SmartCLIP이 실제 retrieval 과정에서 보여주는 정성적 사례를 제시합니다. 예를 들어 “곰이 펜을 들고 있다”라는 문장이 주어졌을 때, 기존 CLIP은 펜이 없는 곰 이미지도 상위에 검색했지만, SmartCLIP은 반드시 “곰”과 “펜”이 함께 등장하는 이미지를 더 높은 순위로 반환했습니다. 또 “의자에 앉은 곰”이라는 쿼리에서는 단순히 곰만 있는 장면이 아니라, 곰과 의자가 동시에 포함된 이미지를 정확히 찾아냈다고 하네요.
종합하면, SmartCLIP은 (1) 벤치마크 데이터셋에서 CLIP 대비 일관된 성능 향상을 보였고, (2) 캡션 노이즈에 강건성을 지녔으며, (3) zero-shot 전이 성능까지 개선된다는 점이 확인되었습니다. Ablation과 정성적 결과를 통해, 이러한 성능 개선이 단순한 파라미터 증가가 아니라 adaptive masking과 modular alignment라는 설계 덕분이라고 합니다.
6. Summary
SmartCLIP은 기존 CLIP이 가진 한계(즉캡션이 이미지의 일부 정보만 담아 개념이 부분적으로만 매칭되거나, 여러 개념이 얽혀 disentangle되지 않는 문제)를 해결하기 위해 제안된 모델입니다. 저자들은 block-wise identifiability라는 이론적 토대를 통해 “개념 단위로 표현을 안정적으로 식별할 수 있다”는 점을 보였으며, 이를 실제 학습 과정에서는 adaptive masking, modular contrastive learning, sparsity penalty라는 세 가지 설계로 구현하였습니다.
아이디어가 되게 와닿아서 읽게 되었는데, 이론적 수식부터 구현까지 이해하는 데 꽤 시간이 걸렸던 것 같습니다. 다만 한 가지 염려스러운 부분은 SmartCLIP은 추가적인 마스크 네트워크 학습으로 인해 연산 복잡도가 늘어난다는 점이 아닐까 싶습니다.
안녕하세요 주영님 좋은 리뷰 감사합니다.
논문 설정이 이미지 임베딩 벡터는 모든 객체나 이미지에 대한 정보가 공평하게 잘 뽑힌다는 전제가 있겠네요..
아이디어 자체가 되게 간단한데 실험하기는 쉽지 않아보여 동기부여 되는 논문인 것 같습니다. 음 논문에 있었는지는 모르겠지만 읽다가 드는 궁금점은 어떤한 객체가 여러 차원들의 집합으로 표현이 될텐데, 물론 그 차원들을 최소화해서 특정 객체를 표현한다고는 하지만, 물체들이 평균 몇개의 차원으로 표현되는지에 대한 언급이 있었을까요?
예를들어 512 차원으로 이미지가 표현되고 있다면 10개만 선택되어도 곰이라는 것을 알 수 있었는지, 모든 객체는 비슷한 차원을 선택하면 걸러낼 수 있는건지 그런 언급이나 실험도 있었는지 궁금합니다.
감사합니다.
좋은 질문 감사합니다.
질문처럼 “곰이라는 개념이 몇 개 차원으로 표현되는가?” 같은 구체적인 수치는 논문에서 직접적으로 리포팅되지는 않았습니다. 다만 저자들은 sparsity penalty를 통해 가능하면 최소한의 차원만 활성화되도록 유도했고, Figure 6의 정성적 결과를 통해 특정 개념이 disentangle되어 나타난다는 점을 보여주었죠. 즉, 개별 객체가 평균적으로 몇 개 차원으로 표현되는지보다는, 캡션에 따라 필요한 개념 차원만 안정적으로 선택된다는 것을 강조한 셈이라고나 할까요
또한 “모든 객체가 비슷한 차원을 공유하느냐”에 대해서도, block-wise identifiability 관점에서 동일한 객체(ex. 곰)은 여러 조합 속에서 공통 차원 묶음으로 식별 가능하다고 설명하였습니다. 하지만 구체적인 차원 수를 계량적으로 제시하는 실험은 없었습니다
안녕하세요, 주영님. 좋은 리뷰 감사합니다.
본문에서 설명해주신 것처럼 Mask Network는 이미지 인코더가 추출한 표현 벡터에서 여러 차원 중 캡션에 해당하는 개념 차원만 남겨 매칭하는 역할을 수행한다고 이해했습니다. 그런데 이 Mask Network는 초기 가중치가 어떻게 설정되는지 궁금합니다. 만약 랜덤 초기화된다면, 학습 초반에는 캡션과 이미지 간 매칭이 제대로 이루어지지 않을 수도 있을 것 같은데, 이 경우 학습 과정에서 attention과 같은 메커니즘을 활용해 올바른 마스크를 학습하도록 유도하는 방식이 적용되는지 알고 싶습니다.
감사합니다.
말씀해주신 것처럼 Mask Network는 이미지 인코더가 뽑아낸 고차원 벡터에서 캡션과 관련된 차원만 남기는 역할을 합니다. 이때 초기 가중치에 대해서는 논문에서 구체적으로 별도의 사전 학습이나 특수한 초기화를 사용했다고 언급하지는 않았습니다. 랜덤 초기화된 파라미터에서 시작하지 않을까 싶긴 합니다
다만 중요한 점은, 학습 과정에서 단순히 reconstruction loss 같은 신호만 주어지는 것이 아니라, contrastive alignment loss가 함께 작동한다는 것입니다. 즉, 잘못된 마스크가 선택되면 이미지–텍스트 매칭 성능이 바로 낮아지고, positive/negative pair 구분 과정에서 큰 페널티를 받게 되죠. 결과적으로 캡션에서 언급된 개념에 대응하는 차원을 점점 선택하도록 Mask Network가 학습되는 것입니다.
주영님 안녕하세요. 좋은 리뷰 감사합니다.
SmartCLIP의 학습은 어떻게 이루어지는지 궁금합니다. 예를 들어 표 1에서의 성능은 원본 CLIP을 가져와 COCO와 Flickr30K의 학습셋을 제안하는 방식으로 추가 학습한 것으로 이해하면 되나요?
또한 sparsity loss의 역할인 각 개념이 최소한의 차원만으로 표현되어야 한다라는 점은 이해가 되었는데, 수식에 따라 텍스트 feature의 l1-norm을 최소화하는 것이 왜 최소한의 차원만을 사용하는 것으로 연결되는지 잘 이해가 되지 않아, 혹시 이 부분에 대한 추가 설명이나 분석 실험이 있었는지 궁금합니다.
Q1. SmartCLIP의 학습 방식?
논문에 나온 표 1(COCO, Flickr30k 실험)은 말씀하신 대로 원본 CLIP을 그대로 사용하는 것이 아니라, COCO와 Flickr30k 학습셋을 활용해 SmartCLIP 구조로 다시 학습한 결과라고 이해하면 될 것 같습니다. 즉, 기존 CLIP의 백본(예: ViT-B/32)을 가져오고, 거기에 Mask Network와 loss 설계를 추가하여 학습을 다시 진행하는 구조입니다.
결과만 놓고 보면 “당연히 Fine-tuning 하는데 CLIP zero-shot보다는 성능이 좋아질 수밖에 없는 것 아닌가?”라는 의문이 들 것 같습니다. 이걸 의식해서인지, 단순히 fine-tuning한 baseline(CLIP-FT)과 SmartCLIP을 비교합니다. Table 1에서 CLIP 자체 성능과 SmartCLIP을 직접 비교하는 게 아니라 같은 조건(데이터셋으로 fine-tuning)에서 SmartCLIP 구조가 추가로 얼마나 개선된지를 보인 것이라고 이해하시면 좋을 것 같네요.
Q2. Sparsity Loss (l1-norm 최소화) 해석
저자들이 도입한 sparsity loss는 최소화하는 방식입니다. 여기서 m(t)는 캡션 t에 따라 선택되는 마스크 벡터입니다. L1-norm은 각 차원의 크기를 가능한 한 “0에 가깝게” 만드는 경향이 있다고 합니다. 즉, 많은 차원을 동시에 크게 쓰기보다는, 소수의 차원만 활성화하는 쪽으로 학습을 유도합니다.
이 때문에 하나의 개념을 표현할 때 불필요하게 여러 차원을 쓰는 대신, 가장 중요한 몇 개 차원만 남기게 된다는 효과가 생깁니다. 이 부분에 대해 저자들은 이론적으로 “block-wise identifiability”를 근거로 들며, sparsity가 개념 단위 disentanglement에 필요하다고 주장하였습니다
홍주영 연구원님, 좋은 리뷰 감사합니다.
CLIP 학습에서 캡션이 이미지의 전체 정보를 담지 못하는것을 마스크라는 아이디어로 잘 모델링한 논문인 것 같습니다. 아이디어가 신기해서 재밌게 읽었어요. 뭔가 CV쪽 학회보다는 ICML, ICLR같은 ML 쪽 학회 느낌이 더 많이 나네요
리뷰 읽다 몇가지 궁금한 점이 있어 질문 남기겠습니다.
(1) 3.3 Identification 조건 첫번째를 보면 gI,gT가 smooth하고 역함수를 가져야 의미 표현이 손실되지 않는다고 했는데, 여기서 의미 표현이 손실되지 않는다는게 무슨 뜻이고, 왜 smoothness, invertibile해야 의미 표현이 손실되지 않는 것인가요?
(2) sparsity penalty loss는 결국 특정 의미(ex:곰)이 여러 차원에 걸쳐 표현되는게 아니라 최소한의 차원만 사용하도록 강제하는것 같은데, 왜 m(t)의 절댓값을 작아지게 하는 방향으로 설계된 것인가요? 그냥 여러 차원에 걸쳐서 절댓값이 작은 수들이 분포하는 형식으로 수렴할 수 있지 않을까 하는 궁금증에 질문 드립니다.
감사합니다.