안녕하세요 오늘의 X-Review 또한 Audio-Visual Question Answering task를 수행하는 방법론 논문을 소개해드리고자 합니다. 25년도 AAAI에 게재된 논문입니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
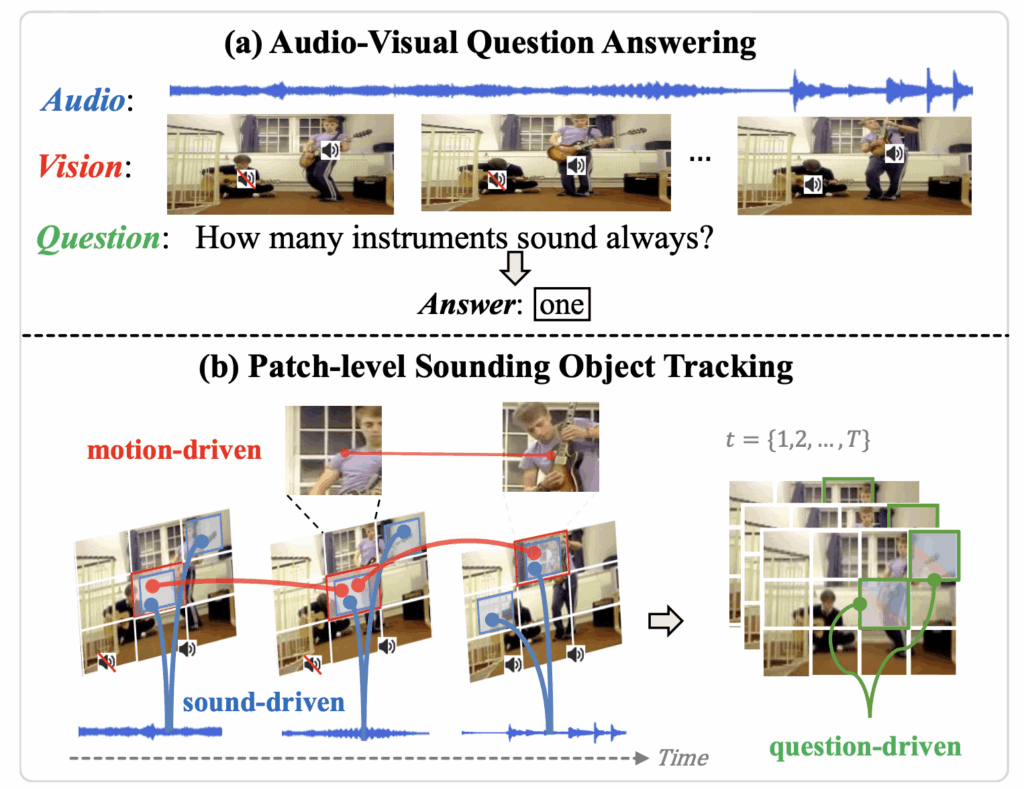
그림 1-(a)에서 Audio-Visual Question Answering (AVQA) task에 대해 알 수 있습니다. 오디오가 포함된 비디오와 자연어 텍스트로 구성된 질문이 입력됩니다. 그럼 모델은 오디오, 비디오, 텍스트 feature를 fusion하여 질문에 대한 올바른 답변을 분류해내야 합니다.
기존 방법론들은 spatial-temporal reasoning, object-level cross modal relations 관점으로 접근하거나, 간혹 Vicuna와 같은 거대 모델을 AVQA에 맞게 finetuning하기도 하였습니다. 그러나 기존 방법론들은 AVQA만을 위한 전문가 모델을 학습시키다보니 모두 높은 연산량과 자원을 요구합니다.
이와 관련해 저자는 AVQA라는 task 본연의 특성과 기존 방법론들의 문제점을 바탕으로 3가지 모듈을 포함하는 PSOT(Patch-level Sounding Object Tracking)라는 방법론을 제안합니다. 좀 더 자세히 설명드리면, 저자는 기존 방법론들이 주어지는 질문에 정확히 답변하기 어려운 이유가 몇가지를 정리합니다.
첫번째는 입력 오디오 신호의 정보 해석이 어렵다는 점입니다. 오디오 정보만 활용해서는 비디오에서 지금 소리내고있는 악기가 무엇인지 알기가 어렵다는 것입니다. 그림 1의 에시를 보시면, 두 개의 기타가 연주되고 있지만 오디오만 들어서는 기타가 두 개 있다는 정보를 알 수 없고, 그렇다보니 당연히 어떠한 기타가 지금 소리를 내고있는것인지 찾는 것은 불가능합니다.
두번째로, 비디오에서 소리를 내는 객체는 시간축에 따라 변할 수 있습니다. 만약 한 객체는 계속 소리내고 있었고 이제 동시에 다른 객체가 소리 내기를 시작하였다면, 모델 입장에선 정확히 어떤 객체가 ‘이제 막 소리내기 시작하는’ 것인지 분간하기 어렵습니다. 아마 이 문제는 대표적으로 벤치마크되는 MUSIC-AVQA에 “어떤 악기가 처음부터 끝까지 소리를 내는가?”와 같은 질문이 포함되어있어 문제로 삼은 것 같습니다. 아무튼 위와 같은 상황에서 모델은 혼란을 겪을 수 있기 때문에 audio-visual correspondence를 모델링할 때 주변의 여러 세그먼트를 함께 고려할 필요가 있습니다.
세번째로 여러 객체가 동시에 소리내는 경우, 단순히 모든 객체들이 소리를 낸다고 모든 객체에 구별력 없이 집중하는 것은 질문의 종류에 따라 오히려 노이즈가 될 수 있습니다. 즉 모델이 현재 답변해야하는 질문을 바탕으로 집중해야하는 패치를 분간할 수 있어야한다고 이야기합니다.
첫번째 포인트는 결국 오디오 단일 모달리티에 의존하여서는 AVQA를 해결하기 어렵다는 뜻으로 이해해볼 수 있습니다. 저자는 이에 따라 먼저 시각 정보에만 집중하여 인접 프레임 사이에서 움직임이 큰 패치를 잡아내는 Motion-driven Key Patch Tracking (M-KPT) 모듈을 제안합니다. 시각적인 움직임이 크다면, 해당 영역이 소리를 내는 객체이거나 질문과 유관할 확률이 높다는 전제 하에 동작하는 모듈입니다.
시각적 정보에만 의존하는 M-KPT와 다르게, 두번째 포인트를 개선하기 위해 시각 정보와 오디오 정보 사이 상관관계를 활용하는 Sound-driven Key Patch Tracking (S-KPT) 모듈을 제안합니다. 우선 M-KPT를 비롯해 S-KPT와 뒤에서 설명드릴 모듈도 모두 Graph Neural Network를 기반으로 설계되어 있는데요, M-KPT와 S-KPT의 차이는 그래프의 인접 매트릭스(두 feature간 유사도)밖에 없습니다. 즉 M-KPT는 인접 프레임의 패치 간 유사도를 기반으로 인접 매트릭스 생성, S-KPT는 시각 정보와 오디오 정보 간 유사도를 기반으로 인접 매트릭스를 생성한다는 의미입니다. 좀 더 자세히는 방법론 부분에서 알아보겠습니다.
다음으로 결국 AVQA의 목적은 질문에 대한 정확한 대답을 내는 것이기 때문에, 앞선 두 모듈과 다르게 질문과 패치의 관련성을 모델링해주는 Question-driven Key Patch Tracking (Q-KPT) 모듈 또한 제안합니다. 위 두 모듈에서 오디오-시각 정보간의 interaction만 진행하였고, 두 모듈이 잘 동작하였다면 움직임이 크고 소리를 내는 객체 영역(패치)는 모두 활성화되어있을텐데요. 들어온 질문에 따라 매번 모든 객체에 집중하는 것은 오히려 안좋은 영향을 줄 수 있습니다. 따라서 답변을 위해 집중해야하는 객체를 질문 기반으로 골라낼 수 있는 Q-KPT도 활용되고, 이 모듈도 그래프 네트워크 기반이며 인접 매트릭스는 질문 텍스트 feature와 그간 개선된 시각 패치들에 해당합니다. 최종적으로는 Multimodal Message Aggregation 모듈을 통해 마지막 답변을 분류해내게 됩니다.
2. Method
먼저 오디오가 포함되어있는 비디오를 1초 단위의 겹치지 않는 세그먼트 T개로 나눠줍니다. 이후 각 세그먼트에 대한 오디오와 시각 feature는 아래와 같이 정의됩니다.
- \textbf{A} = \{a_{t}\}_{t=1}^{T} \in{} \mathbb{R}^{T \times{} d}
- \textbf{V} = \{v_{t}\}_{t=1}^{T} \in{} \mathbb{R}^{T \times{} N^{2} \times{} d}
식에서 N^{2}이 각 프레임의 패치 개수에 해당합니다. 아래 그림 2가 제안하는 PSOT의 전체 프레임워크이며 salient한 sounding object를 찾고 이에 대해 질문과의 연관성을 강조해 정확한 답변을 내는 과정으로 구성되어있습니다.
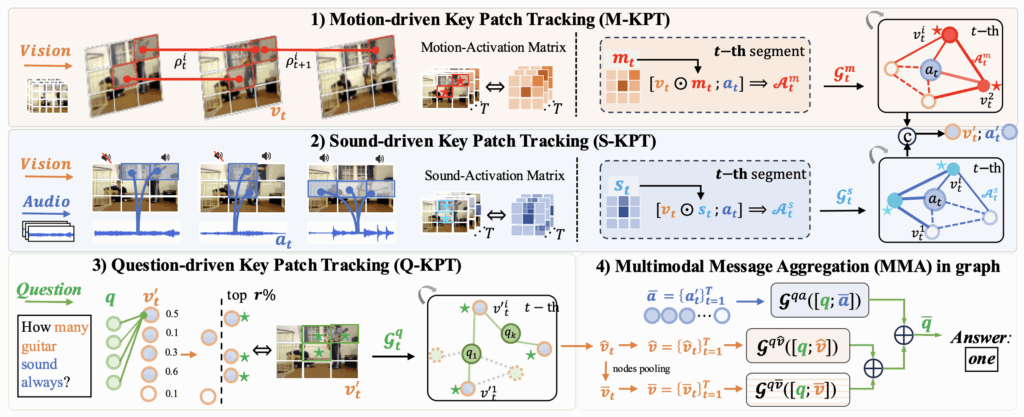
2.1 Motion-driven Key Patch Tracking
저자가 첫 번째 포인트에서 짚은 것과 같이, 오디오만 활용해서는 비디오에 존재하는 유사한 객체들 간 구분이 어렵기 때문에 먼저 시각 정보에만 의존하여 큰 움직임을 갖는 salient한 객체를 강조합니다. 사실 어떤 패치(객체)가 프레임 변화에 따른 움직임이 크다고해서 그게 무조건 답변을 위해 집중해야하는 핵심 객체라곤 할 수 없겠지만, 일차적으로 salient한 객체가 최종적으로 소리내는 객체와 관련있거나 질문과 유관한 객체일 확률이 높기 때문에 위와 같은 M-KPT 모듈이 도입되었다고 볼 수 있습니다.
여러 프레임에 걸친 특정 패치의 움직임을 보기 위해 optical flow 또한 쓸 수 있지만, 연산량이 너무 커 M-KPT 모듈에서는 동일 인덱스의 패치간 유사도를 계산합니다. i번째 패치에 대한 motion intensity \rho{}_{t}^{i}는 아래 수식 (1)과 같이 계산됩니다.
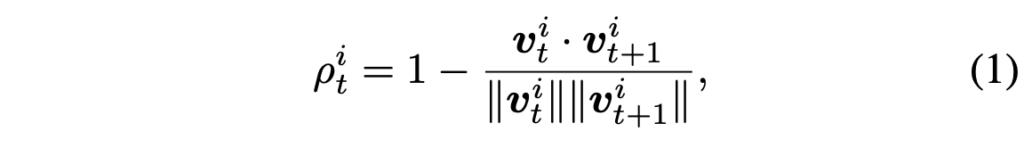
결국 \rho{}_{t}^{i}는 다음 프레임에서의 동일 인덱스(영역) 패치와의 유사도를 1에서 빼준 값으로 0~2 범위의 값을 갖습니다. 0에 가까울수록 유사하니 움직임이 적은 것이고, 2에 가까울수록 유사도가 작으니 프레임 간 해당 영역의 움직임이 큰 salient object라고 해석할 수 있습니다.
위 수식 (1)의 연산을 프레임 내 모든 패치에 적용하여 한 프레임의 intensity matrix \mathbf{\rho{}}_{t} = \{\rho{}_{t}^{i}\}_{i=1}^{N^2} 를 구할 수 있습니다. 이렇게까지만 계산하면, 일부 짧은 시간대에서만 움직임이 큰 객체는 그 짧은 시간대에서만 강조될 것입니다. 하지만 본 모듈의 목적은 움직임이 큰 객체를 시간 축 전 범위에서 강조해주는 것이기 때문에 그 목적을 위해 모든 프레임에서의 움직임 정도를 고려한 global motion intensity \bar{\mathbf{\mu{}}} = \frac{1}{T}\Sigma{}_{t=1}^{T} \mathbf{\rho{}}_{t}를 만들어줍니다. 이후 최종적인 각 프레임의 intensity matrix \textbf{m}_{t}는 아래 수식 (2)와 같이 하이퍼파라미터 \lambda{}=0.2로 가중되어 더해집니다.
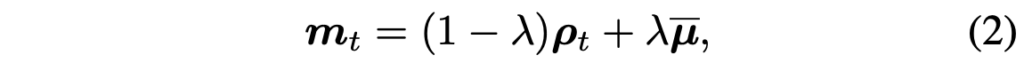
여기까지 하여 얻은 \textbf{m}_{t}는 N^{2}차원으로, 각 패치 영역에 대한 salient object의 가중치라고 볼 수 있습니다. 따라서 이를 원본 visual feature v_{t}에 원소곱(Hadamard product)한 뒤 오디오 feature a_{t}를 뒤에 concat 후 아래와 같은 형태의 motion-driven 인접 매트릭스 \mathcal{A}_{t}^{m} \in{} \mathbb{R}^{(N^{2}+1) \times{} (N^{2}+1)}을 만들어줍니다.
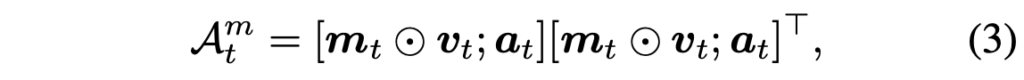
이후 각 프레임에서의 노드 \mathcal{N}_{t} = [v_{t};a_{t}] \in{} \mathbb{R}^{N^{2}+1} \times{} d를 만들어줍니다. 그럼 그래프 연산을 위한 노드 \mathcal{N}_{t}와 인접 매트릭스 \mathcal{A}_{t}^{m}를 얻었으니 아래 수식 (4)와 같은 그래프 연산을 수행해줍니다.
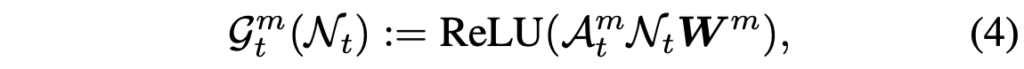
수식 (4)에서 \textbf{W}^{m}은 learnable matrix이고 이 과정을 L번 반복하여 얻은 노드 \mathcal{N}_{t}^{L}을 motion 정보를 바탕으로 생성된 audio-visual 노드로서 활용합니다. 위 과정을 모든 프레임에 대해 반복적으로 수행하는 것입니다.
여기서 \mathcal{A}_{t}\mathcal{N}_{t}W 형태로 구성되는 GNN 연산에 대해 간단히 설명드리면, 세 매트릭스가 결국 행렬곱으로 구성되어있는 것입니다. 먼저 노드 \mathcal{N}을 learnable matrix W와 곱해 임베딩으로 변환해주고, 이 임베딩을 인접 매트릭스 \mathcal{A}와 곱하는 과정에서 각 노드들이 주변 노드들과 얼마나 연관되어있는지를 반영해주는 것입니다. \mathcal{A} 자체가 feature 간 유사도(연관도)를 바탕으로 초기화되었기 때문입니다. 이 과정이 L번 반복된다고했는데, 0번 연산에서 얻은 출력값을 1번 연산의 노드 \mathcal{N}으로 삼아 계속 반복하는 것입니다. 인접 매트릭스나 가중치 행렬은 backward 때 갱신이 되겠죠.
2.2 Sound-driven Key Patch Tracking
앞선 절의 M-KPT에선 오로지 프레임 시각 정보 간의 차이만을 이용해 audio-visual 노드 \mathcal{N}_{t}^{L}을 만들어주었습니다. 모듈 간 핵심 차이점은 인접 매트릭스 초기화 방법이라고 말씀드렸고, 직전 모듈 M-KPT는 시간 축이 지남에 따른 패치의 변화 정도로 초기화는 것을 볼 수 있었습니다.
본 절에서 제안하는 S-KPT는, t번 프레임의 시각 정보 v_{t} \in{} \mathbb{R}^{N^{2} \times{} d}와 오디오 정보 a_{t} \in{} \mathbb{R}^d 간 유사도를 기준으로 인접 매트릭스를 초기화해줍니다.
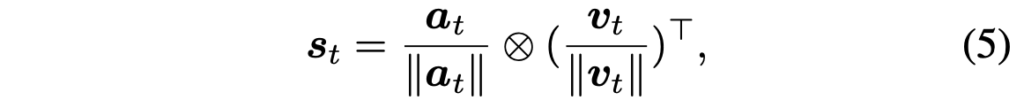
위 수식 (5)와 같이 두 feature 간 행렬곱을 통해 sound activation matrix s_{t} \in{} \mathbb{R}^{N^{2}}를 만들어줍니다. 즉 현 시점의 음성이 프레임의 어느 패치와 가장 유사한지를 따져 매트릭스로 만든 것이죠. 이후에는 M-KPT와 동일한 방식으로 sound-driven 인접 매트릭스를 만들어줍니다.
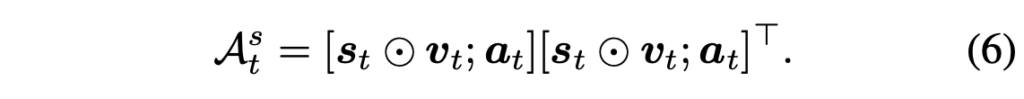
원본 시각 feature v_{t}에 sound-activation matrix를 곱해 그 영역을 강조하고 오디오 feature와 concat해준 것입니다. 여기서도 앞서와 마찬가지로 초기 audio-visual 노드 \mathcal{N}_{t} = [v_{t};a_{t}]를 가지고 아래 수식 (7)과 같은 그래프 연산을 진행합니다.
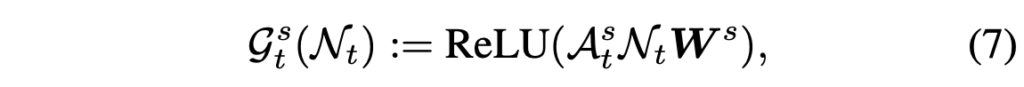
결국 M-KPT와 S-KPT의 과정은 거의 유사하나 인접 매트릭스의 초기화 값만 다른 것입니다. 또한 입력 feature에 대해 두 모듈이 parallel하게 진행되고 각 모듈에서 나온 출력값은 concat + FC layer를 타고 합쳐집니다. Concat되어 있는 매트릭스로부터 다시 인덱싱을 통해 시각, 오디오 feature를 분리할 수 있고 각각을 a'_{t}, v'_{t}라고 칭합니다.
2.3 Question-driven Key Patch Tracking
이제 시각과 오디오 정보에서 salient한 패치들은 잘 강조되었으니, 실제 답변을 위한 질문과의 연관성을 잡아내야합니다. 먼저 word-level text feature \textbf{q} \in{} \mathbb{R}^{K \times{} d}와, 앞서 얻은 \textbf{v'}_{t} 간의 유사도를 수식 (5)와 동일한 과정으로 구해줍니다. 여기서 K는 문장 내 단어 개수이고, 유사도 매트릭스의 형태는 \mathbb{R}^{K \times{} N^{2}}가 되겠죠.
이 매트릭스에 대해 단어축으로 평균을 내어 sentence-level question-to-visual 유사도 \alpha{}_{t} \in{} \mathbb{R}^{N^{2}}를 구해줍니다. 질문과 유관한 패치만을 남기기 위해 아래 수식 (8)과 같이 유사도 기준 top-r%의 패치만을 남겨 그 값을 1로, 나머지 패치는 0으로 만들어 일종의 마스크 \beta{}_{t}를 만들어줍니다.
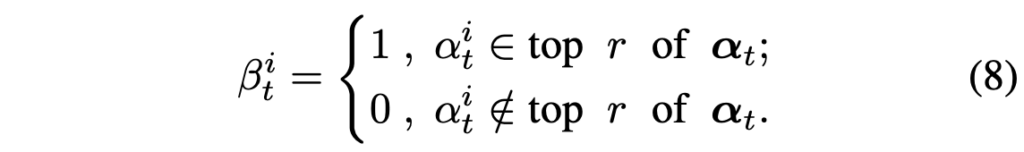
1로서 남아있는 N^{2} * r개의 패치 토큰만 이후 학습에 관여하여 나머지는 아예 학습에서 배제해주는 것이죠. \textbf{q}와 v'_{t}를 concat하여 노드 \mathcal{M}_{t}를 만들어주고, 스스로와의 곱을 통해 초기 인접 매트릭스 \mathcal{A}_{t}^{q} \in{} \mathbb{R}^{(K+N^{2}) \times{} (K+N^{2})}를 만들어줍니다. 이는 아래 수식 (9)와 같습니다.
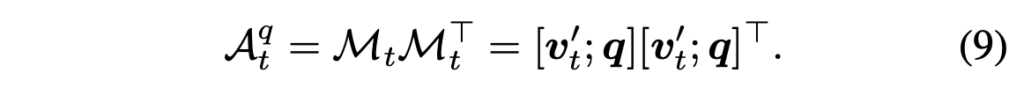
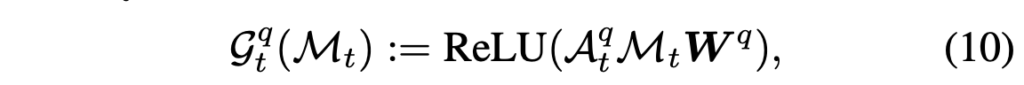
수식 (8)에서의 \alpha{}는 사실 외적으로 구해주는 과정이 존재하기보단, 수식 (10)의 인접 매트릭스가 계산되고 반복적인 학습을 진행하며 자동적으로 만들어진다고 보시면 될 것 같습니다. 물론 중간중간 r%의 패치를 버리는 과정은 직접 진행해줘야겠죠. 다만 이게 매 layer마다 이루어지는 것인지, 처음이나 마지막에 한 번 진행되는 것인지까지는 설명이 없습니다. 사실 이 부분이 직관적으로 잘 이해가 되지 않아 코드를 보고싶었으나 공개가 되어있지 않아 확인이 어려웠습니다. 아무튼 여기서는 이전 두 모듈과 마찬가지로 수식 (10) 과정도 모든 프레임에 적용되며 질문과 관련된 패치를 남기게 되고, 여기서 얻은 출력의 시각 feature 부분을 \hat{v}_{t} \in{} \mathbb{R}^{N^{2} \times{} d}라 칭합니다.
2.4 Multimodal Message Aggregation
이제 앞서 구한 feature들을 잘 aggregate하여 최종 답변을 분류해내는 과정만 남았습니다. 이전 모듈까지 진행하여 개선된 오디오와 시각 feature는 각각 \bar{a} = \{a'_{t}\}_{t=1}^{T} \in{} \mathbb{R}^{T \times{} d}, \hat{v} = \{\hat{v}\}_{t=1}^{T} \in{} \mathbb{R}^{T \times{} N^{2} \times{} d}였고, 여기서 \hat{v}를 spatial 축으로 평균내어 \bar{v} \in{} \mathbb{R}^{T \times{} d}를 얻어줍니다.
이런 출력값을 활용해 Multimodal Message Aggregation (MMA) 모듈은 질문과 유관한 feature를 최종적으로 추리는 역할을 합니다. 마찬가지로 그래프 네트워크를 활용하며, 오디오/시각 feature와 질문 텍스트 feature 간 모델링을 해줍니다. 위에서 얻은 \bar{a}, \hat{v}, \bar{v} 각각과 질문 feature q를 concat하여 각각을 노드 삼아 그래프 네트워크에 넣어줍니다. 각 그래프 네트워크에선 앞 모듈과 마찬가지로 두 feature 간 유사도를 초기 인접 매트릭스로 활용합니다.
이 3개의 그래프 연산에서 얻은 3개의 출력 각각에서 텍스트와 관련된 인덱스를 떼어 최종 question feature \bar{q}를 만들고 FC + Softmax에 태워 예측 확률 p \in{} \mathbb{R}^{C}를 만들어줍니다. 여기서 C는 답변이 될 수 있는 전체 클래스 개수를 의미합니다. 학습에는 CE loss를 사용합니다.
3. Experiments
3.1 Experimental Setup
평가에는 AVQA의 대표 데이터셋 MUSIC-AVQA가 활용됩니다. 보통 그래도 2-3개 정도는 평가에 사용하는데 하나만 사용한 점이 특이하네요. 평가 지표는 답변 분류 정확도입니다. MUSIC-AVQA 데이터셋의 비디오는 전부 60초인데, 1초당 1개의 segment로 나눈 뒤 6초당 하나의 segment를 uniform sampling 하여 결국 한 비디오 당 10개의 segment를 사용했다고 합니다. 오디오도 샘플링된 segment로부터 가져오는 것입니다.
추가로 제가 지금 CLIP-ViT-L/14 이미지 인코더로부터 patch feature를 활용하는 실험을 하며 patch feature 사이즈가 너무 커 데이터 로드에 문제가 있는 상황이었는데, 본 논문에서는 원래 프레임 당 256개인 패치를 연산량 이슈로 인해 64개로 average pooling하여 사용했다고 합니다. 참고해볼만한 사항인 것 같습니다. 오디오 feature는 기존 연구와 동일하게 VGGish 백본을 활용하였고 CLAP이라는 백본으로부터 추출하여 얻은 결과도 같이 리포팅하였습니다. 텍스트는 이미지와 마찬가지로 CLIP-ViT-L/14의 텍스트 인코더를 사용했습니다.
3.2 Comparison with Prior Works
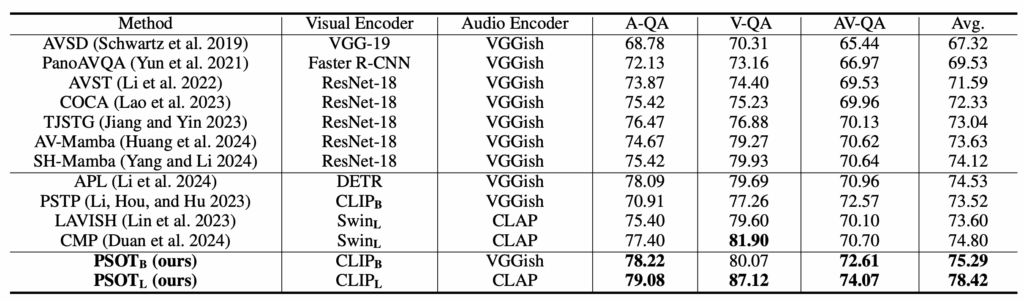
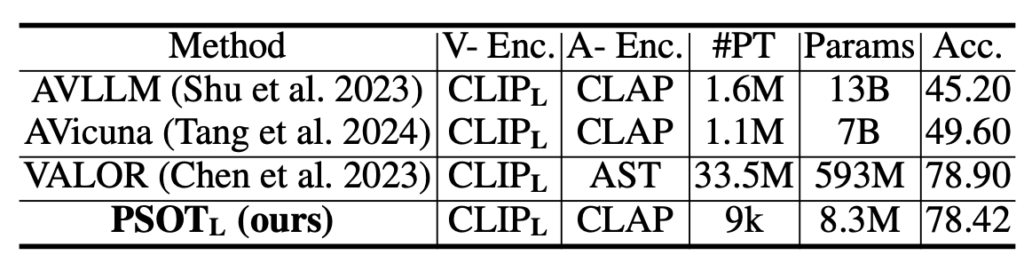
표 1, 2는 MUSIC-AVQA 데이터셋에서의 벤치마크 성능을 보여주고 있습니다. 표 1은 MUSIC-AVQA의 학습 스플릿만을 활용해 학습하는 소규모 모델들과 저자가 제안하는 PSOT 방법론 간 성능 비교이고, PSOT도 표 1의 방법론들과 결이 동일하다고 볼 수 있습니다. 오디오 백본은 visual 백본과 크기를 얼추 맞춰 타 모델들과 비교할 수 있도록 실험하였고, 결국 최종 성능 측면에서 가장 높은 성능을 달성하였습니다.
다음으로 표 2는 거대모델에 audio token을 projection하고 디코딩하여 fine-tuning을 진행하는 AVQA 방법론들과의 성능 비교입니다. 표 2의 타 모델들도 AVQA만을 위해 fine-tuning 되었다는 점을 감안하면 PSOT가 훨씬 적은 학습 데이터와 모델 사이즈임에도 높은 성능을 달성함을 알 수 있습니다.
3.3 Ablation Studies
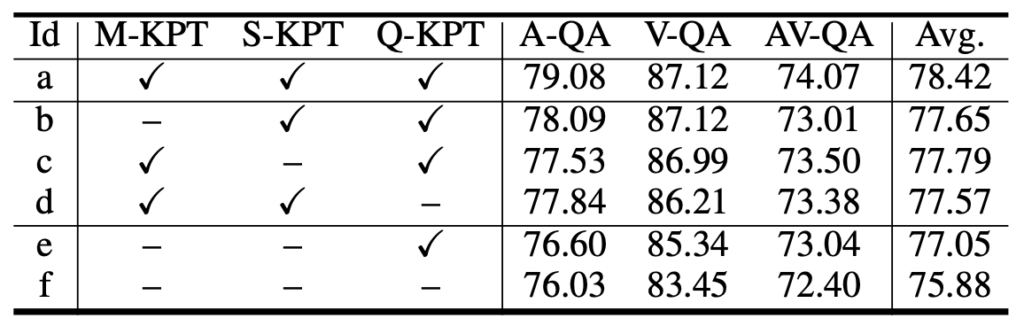
표 3은 PSOT의 모듈별 ablation 성능입니다. 여기서도 실험 (a)와 (b), (c), (d) 비교 및 실험 (e)와 (f) 비교를 통해 여전히 텍스트 쿼리에 대한 모델링이 가장 큰 성능 향상을 불러오는 것을 볼 수 있습니다. 텍스트 쿼리에 대한 모듈인 Q-KPT만을 제외한 (d)가 (b), (c)에 비해 가장 큰 성능 하락이 발생합니다. 또한 세 모듈이 서로 상호보완적 열할을 하며 모두 사용했을때 기존보다 성능이 큰 폭으로 오름을 알 수 있습니다.
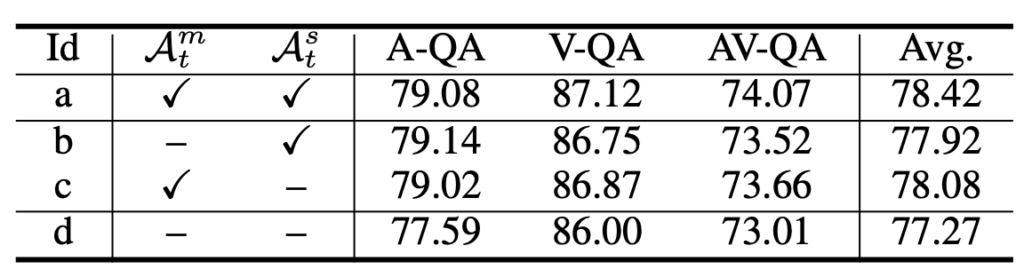
표 4는 M-KPT와 S-KPT 모듈에서의 인접 매트릭스 초기화 여부에 따른 성능입니다. 저자가 제안한 방식으로 각 모듈에서 목표하는 feature끼리의 유사도를 아다마르곱, 행렬곱 하여 인접 매트릭스를 초기화할지, 원본 feature간의 유사도로 초기화하는지에 따른 성능 차이라고 보시면 됩니다.
각 모듈의 방식대로 인접 매트릭스를 초기화하였을때 성능이 더욱 높은 점을 통해 저자가 찾고자했던 프레임이 지남에따라 크게 움직이는 패치, 오디오와 유사한 패치로 학습을 시작하는 것이 그래프 학습에 있어 더욱 효과적이었음을 알 수 있습니다.
3.4 Qualitative Results
마지막으로 정성적 결과를 보며 리뷰를 마치겠습니다.

위 그림 3은 S-KPT 모듈에서 집중하는 ‘소리와 연관된 부분’, M-KPT 모듈에서 집중하는 ‘움직임과 연관된 부분’, 그리고 Q-KPT에서 집중하는 ‘질문과 연관된 부분’을 시각화한 것입니다.
“어떤 우쿨렐레가 소리를 먼저 내냐?”라는 질문에 대해, 가장 왼쪽의 S-KPT 시각화 결과를 보면 비디오에서 두 우쿨렐레가 동시에 소리를 내는 구간이 있기에 두 우쿨렐레 모두 활성화되어있고, 여기까지만 봐서는 제대로 답변을 내긴 어려운 상황입니다. 그러나 M-KPT 모듈의 결과를 보시면 둘 중 왼쪽 우쿨렐레가 많이 움직이며 소리를 내고 있음을 모델이 파악한 것을 볼 수 있습니다. 아마 이런 상황이 ‘많이 움직이는 객체’와 ‘소리를 내는 객체’가 맞아떨어지는 케이스인 것 같습니다. 마지막으로 Q-KPT에서는 앞선 두 모듈이 강조하는 영역 중에서도 실제 답변에 관여하는 우쿨렐레 및 사람 부분, 사람 부분 중에서도 연주가 이루어지는 상체쪽을 남김으로써 집중할 영역을 추리는 것을 볼 수 있습니다.
이상으로 리뷰 마치겠습니다.
김현우 연구원님. 좋은 리뷰 감사합니다. 읽다 보니 궁금한 점이 있어 질문 남기겠습니다.
M-KPT 모듈에서 모션에 집중하는 전제가 ‘salient하거나 모션이 있는 물체가 소리를 내고 있는 물체일 가능성이 높다’인데, 사실 이 부분이 잘 납득이 가지 않습니다. 소리를 낼 수 있는 물체가 다양할텐데 오디오 정보 없이 모션이 있는 물체로 찍고 보자 이런 느낌인 것 같아요(스피커 같은 물체는 고정되어있지만 소리가 나죠). 논문에서 혹시 이런 가정에 대한 추가적인 설명이나 실험 결과같은게 있나요? 맨 마지막 정성적 결과만으로는 부족한 것 같아 질문 드립니다.
감사합니다.