안녕하세요 황찬미입니다.
첫 x-review로 GPT1에 대한 논문을 리뷰해보고자 합니다. 9월이 된 후로 LLM관련된 내용을 공부하는 중인데 대학생활을 함께한 GPT가 몇번이고 언급되길래 이 GPT…과연 어떻게 태어나게 된 모델일까?! 하는 호기심해 해당 논문을 리뷰하게 되었습니다. 한번 살펴보겠습니다 !
1. Intro
기존의 LLM은 질의응답, 추론 등 다양한 언어 task를 수행하기 위해 구성되어 있지만 이 기존 언어모델의 가장 주요한 문제점은 Labeled 데이터가 부족하다는 것입니다. 반면에 세상에는 라벨이 없는(unlabeled) 텍스트 말뭉치는 무궁무진하게 많이 존재합니다. 저자들은 이러한 관점에 집중해서 이 방대한 양의 비라벨 데이터들을 활용해보고자 했습니다
논문에서는 실제로 비지도 방식으로 사전 학습된 워드 임베딩이 이미 다양한 NLP task에 활용되고 있고 또 성능향상 까지 보여주었다고 합니다. 하지만 이는 단어 수준의 정보에 한정되어 있어서 문장 수준의 의미표현을 다루기에는 한계가 있습니다.
이에 이 논문은 two-stage의 접근법을 제안했습니다! 1. 먼저 대규모의 비라벨 corpus로 언어모델(LM)을 사전학습하여 언어적인 패턴 및 일반지식들과 장기의존성을 학습하고 2. 이후에 각 태스크별로 라벨데이터를 사용한 fine-tuning을 진행하는 방식입니다.
여기서 중요한 부분은 모델 구조 자체는 transformer를 기반으로 하되 각 task별로 구조를 크게 바꾸지 않고도 지도학습 시의 약간의 입력 변환과 선형 layer추가를 통해 다양한 task를 수행 할 수 있도록 설계되었다는 점 입니다. 저자들은 이렇게 하면 task-agnostic인 모델을 유지하면서도 텍스트 유추(NLI), QA, Semantic Similarity , text Classification과 같은 여러 언어 task를 효과적으로 해결할수 있다고 합니다!
2. Framework
학습의 절차는 Intro에서 언급했듯이 두단계로 나누어져 있습니다. 단계별로 세부구조를 살펴보겠습니다.
[unsupervised pre-training]
GPT의 pre-trainng과정은 다음과 같이 진행됩니다
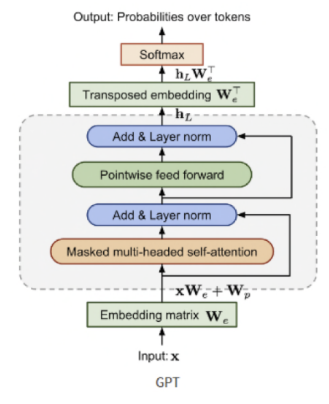
위의 구조를 하나씩 자세히 살펴보자면 먼저 비지도 사전학습의 Objective는 이전의 k(window size)개의 토큰이 주어졌을때다음 단어 u_i가 등장할 조건부 확률을 최대화 하는 것입니다. 이를 통해 모델이 문맥을 기반으로 한 언어적인 패턴을 학습할 수 있게 됩니다.
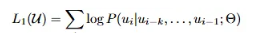
GPT의 기본 구조는 transformer의 Decoder로만 구성되어있습니다.주어진 대규모의 비라벨 corpus에서 입력 문장은 토큰화 된 후 두가지 임베딩인 토큰 임베딩과 포지션 임베딩이 합쳐져서 모델에 들어갑니다.
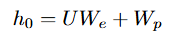
- (W_e)토큰 임베딩(Token Embedding): 각 단어를 고차원 벡터로 변환
- (W_p)포지션 임베딩(Position Embedding): 단어의 순서 정보를 반영
이렇게 합쳐진 임베딩은 12층의 Transformer블록을 연속적으로 통과합니다. 각 블록은 multi-head self-attention과 FFN으로 구성되어 있습니다.
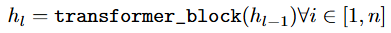
- masked multi-head self-attention
- 일반적인 self attention은 입력시퀀스의 전체를 보지만 생성형 언어모델에서는 미래 단어를 컨닝하면 안되기 때문에 뒷 글자를 가리는 masking기법을 적용합니다. 즉, 문장의 각 위치는 자기자신과 그 이전의 토큰까지만 참고할 수있고 이후 단어는 모두 마스킹되어 0(−∞)으로 처리됩니다
- 또한 멀티헤드 어텐션으로 각각의 헤드가 서로 다른 관점으로 문맥을 학습하게 됩니다
- FFN
- 다음으로는 앞선 과정인 어텐션 레이어에서 처리한 정보들을 추가로 가공하고,. 더 복잡한 패턴을 포착하는 역할을 수행하는 부분입니다. 두개의 fc layer와 활성화함수(gelu)를 사용합니다
각 블록은 Residual connection과 layer normalization이 적용되어 앞의 정보들을 잊지 않고 안정적으로 학습이 이루어 설계가 되어있습니다.
이 과정을 거친 최종 hidden state는 softmax계층을 통과하여 다음 단어의 확률 분포를 계산하게 되는데 GPT는 한 단어씩 예측하는 과정에서 문맥에 대한 이해와 장기의존성을 동시에 학습할 수 있게 됩니다.
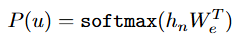
[supervised fine-tuning]
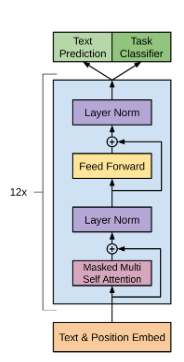
사전학습 끝난 후 모델은 각 task의 라벨이 포함된 데이터셋(C={(x1,…,xm,y)})을 사용하여 fine-tuning을 진행합니다.
지도학습의 과정을 자세히 살펴보자면, 입력시퀀스를 사전학습된 transformer에 입력되어 12개의 블록에 순차적으로 통과합니다. 마지막 블록에서 나온 hidden state는 새롭게 추가된 선형계층(W_y)에 연결되고 이어서 softmax 계층을 거쳐 최종적으로 각 라벨에 대한 확률 분포를 계산하며 이 중 가장 높은 확률을 가진 라벨이 모델의 예측이 됩니다
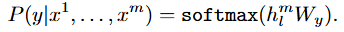
- 즉 파인튜닝의 기본 목표는 라벨의 정답 확률을 최대화 하는 것입니다. 이대 사전학습에서 얻었던 가중치를 초기값으로 두고 여기에다가 task별로 추가된 작은 linear layer만 학습되는 구조기 때문에 최소한의 파라미터 수정으로도 다양한 태스크에 쉽게 적용할 수 있게 됩니다.
이 지도학습의 기본 loss함수는 다음과 같이 구성됩니다.
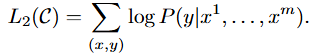
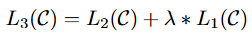
- 저자들은 보조LM을 추가하여 성능이 향상된다는 것을 발견하였고, 최종적인 파인튜닝 손실함수는 지도학습모델의 손실과 보조LM의 손실을 합하여 사용합니다. 이때의 람다는 두 손실간의 균형을 조절하는 하이퍼파라미터 입니다
[Task-specific input transformations]
GPT1은 사전학습 단계에서 연속된 문장 시퀀스를 입력으로 학습했기 때문에 파인튜닝 단계에서도 다양한 task를 이 구조에 맞춰주어햐 합니다. 즉, 모델 구조를 태스크마다 새로 짜지 않고 최소한의 입력변환만으로 Task-agnostic하게 적용이 가능하게 됩니다
아래의 사진은 각 task별로 변환하는 방식입니다
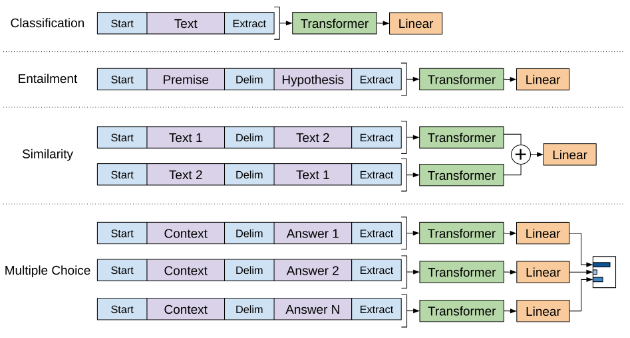
- 문서 분류는 단일 문장을 입력으로 받아 마지막 hidden state를 사용하여 라벨을 예측합니다
- 텍스트 추론은 전제와 가설 두 문장을 하나의 시퀀스로 이어붙이고 중간에 delimiter토큰$을 둡니다.
이렇게 하면 모델은 두 문장을 하나의 시퀀스로 받아 관계(함의,모순,중립)을 예측할 수 있습니다 - 문장 유사도는 두 문장간의 순서가 없기 때문에 두 순서(a,b/b,a)를 각각 모델에 입력하여 얻은 각각의 최종 hidden state를 합하여 최종 뷴류계층으로 전달하여 문장간의 유사성을 대칭적으로 판단합니다.
- 마지막으로 질의응답과 상식추론은 문맥과 질문을 먼저 연결하고 여기에 후보답변을 하나씩 붙여서 [context ; question ; $ ; answer_k]이런 형태를 후보답변 개수만큼 만듭니다.
이후 각 후보답변마다 독립적으로 처리한 뒤 softmax를 통해 가장 높은 확률을 갖는 답변을 선택합니다.
3. Experiment
[Result on Downstream Task]
이 논문에서 다룬 주요task인 자연어 추론(NLI), 질의응답(QA) & 상식 추론, 문장 유사도(semantic similarity), 텍스트 분류 네 가지를 살펴보겠습니다
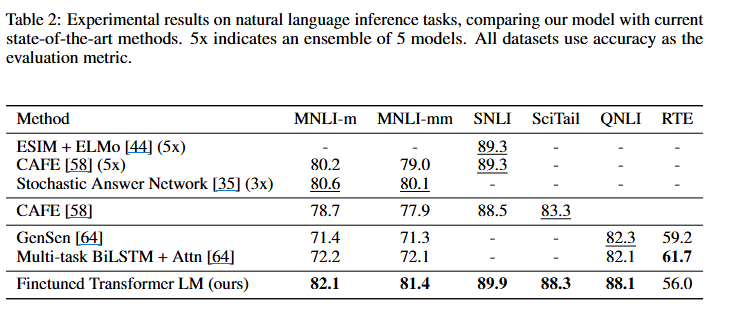
- NLI는 두 문장(전제,가정)이 주어졌을대 관계를 entailment, contradiction, neutral중 하나로 분류하는 태스크입니다.
- 각 데이터셋은 MultiNLI(소설, 보고서 등 다양한 도메인), SNLI(이미지 캡션 기반), SciTail(과학 시험 문제 기반), QNLI (위키 기반), RTE (뉴스 기사 등)으로 구성되어 있습니다
- 이 task는 lexical entailment, coreference, and lexical and syntactic ambiguity를 모두 고려해야하기때문에 어려운 문제인데 소규모 데이터셋인 RTE를 제외하고는 대부분의 데이터셋에서 기존 SOTA대비 성능향상이 있었습니다.
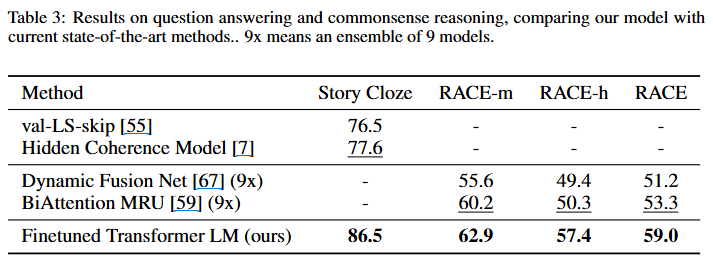
2. Question Answering & Commonsense Reasoning는 주어진 지문,질문+후보답변 중 정답을 고르는 태스크입니다.
- 각 데이터셋은 Story Cloze Test (짧은 이야기의 결말 맞히기), RACE(중·고등학교 영어 시험 문제)로 구성되어 있습니다.
- 이 task는 모델이 긴 맥락을 효과적으로 다루고, 추론이 필요한 문제에서 문맥적으로 reasoning한 결과를 도출해야 하는데 두 데이터셋 모두 SOTA대비 성능향상이 있었습니다
3. Semantic Similarity는 두 문장이 의미적으로 같은지, 유사한 정도는 어떤지 평가하는 task입니다.
- 각 데이터셋은 MRPC(뉴스 문장쌍), QQP(Quora 질문 쌍),STS-B (문장 의미 유사도 점수)로 구성되어 있습니다.
- 아래의 table4로 확인할 수 있듯이 MRPC를 제외하고는 가장 좋은 성능을 달성하였습니다
4. Text Classification는 문장을 보고 특정 레이블을 부여하는 task입니다
- 각 데이터셋은 CoLA(문장이 문법적으로 맞는지 여부),SST-2 (긍정/부정 sentiment분류)로 구성되어 있습니다.
- 아래의 table4로 확인할 수 있듯이 CoLA는 성능이 크게 향상 되었고 나머지는 비슷한 성능을 달성하였습니다
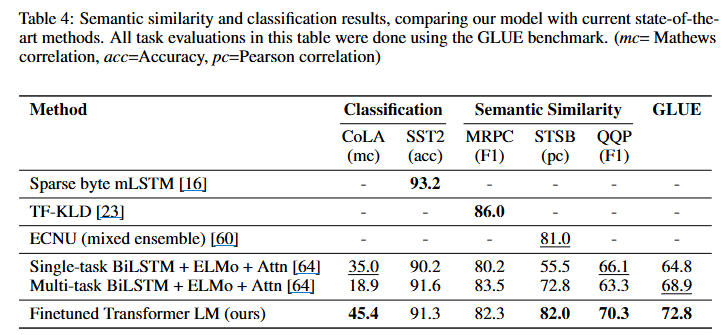
GPT1은 사전학습을 통해 얻은 언어표현 능력을 다양한 지도학습 task에 효과적으로 전이시켰고, 12개의 데이터셋 중 9개에서 SOTA를 달성함을 확인했습니다. 저자들이 제안한 2-stage의 접근법이 NLP전반적으로 효과적임을 보여주었습니다.
4. Analysis
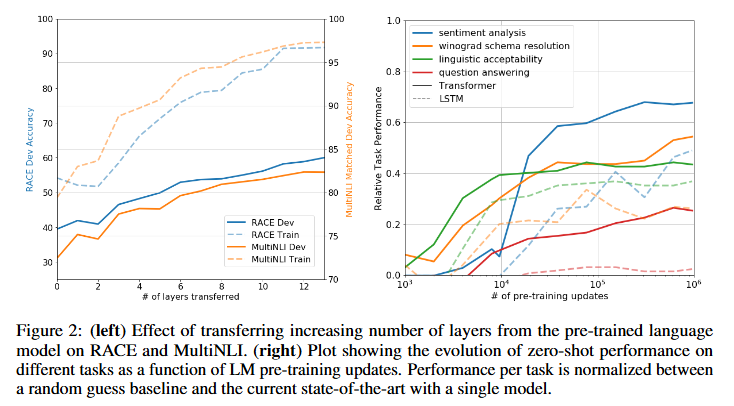
[Impact of number of layers transferred]
저자들은 사전훈련으로부터 얼마나 많은 층을 전이 하느냐에 따른 효과를 확인하기 위해 전이 할 레이어 수를 늘려가며 성능을 확인하는 실험을 진행하였습니다. 왼쪽 그래프를 통해 임베딩만 전이하는 것 부터 transformer의 각 layer를 추가로 전이할수록 정확도가 계속 오르는것을 확인 할 수 있습니다. 이를 통해 사전 학습된 각 층이 dawnstream task에 유용한 기능을 담고있다는 증거가 됩니다
- 개인적인 생각으로는 이전 실험에서 본 여러 task가 아닌 두 task로만 확인했기 때문에 모든 층을 전이하는게 대부분의 downstream task에 효과적이라고 일반화를 할수가 있나? 하는 생각이 들었는데 이와 관련된 언급이 없어서 아쉬웠습니다.
그냥 두 task로 각 층이 유용하다는 추론적인 주장 정도로만 받아들여야 하나..?
[Zero-shot Behaviors]
다음으로는 파인튜닝 없이 사전학습 된 LM으로만 여러 NLU task를 휴리스틱으로 풀어보는 실험을 진행하였습니다. 저자들은 실험에 설정된 가설은 사전학습 생성형 LM을 잘 학습시키면
- LM도 충분히 자연스럽게 여러 NLU의 기능들을 내재적으로 익히게 된다고 가정하였고,
- 트랜스포머의 attention메모리 구조가 LSTM보다 전이에 유리하다고 보았습니다.
위의 오른쪽 그래프를 통해 학습이 진행될수록 제로샷 성능이 꾸준히 우상향 하는 것을 확인함으로 생성형 사전학습이 다양한 NLU태스크 관련 능력을 함께 키울 수 있다는 것을 확인할수 있었습니다. 또 LSTM(점선)보다 Transformer(실선)가 일관되게 안정적으로 전이되는 경향을 확인함으로 트랜스포머 구조 자체가 언어 task에 더 적합한 구조적 특성을 지닌다는 것을 확인할 수 있었습니다.
[ablation studies]
마지막으로는 사전학습의 유무, aux LM, LSTM을 비교하였습니다.
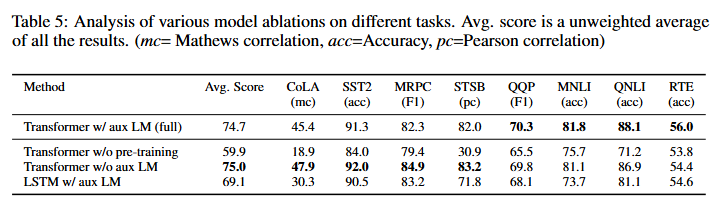
- Transformer w/o pre-training ⇒ 사전학습 한것과 안한것 차이 !
- 사전학습을 안할시 모든 task에서 성능이 떨어지는것을 확인함으로 사전학습 자체가 압도적으로 중요한 것을 증명하였습니다.
- Transformer w/o aux LM ⇒ 지도 학습시에 보조LM의 유무 !
- 데이터셋의 규모에 따라 보조 LM의 효과가 다르게 나타났는데 큰 데이터셋일수록 보조LM효과가 유익하지만 작은 데이터셋에서는 보조LM에서는 효과거 없다는걸 확인 할수있었습니다.
- 이 부분 또한 이유가 뭘지 궁금해서 이것저것 찾아보았지만..
개인적인 생각으로는 작은 dataset에서는 LM손실이 task에 노이즈를 줄 수 있어서일까..?라고 생각을 해보았습니다.
- 이 부분 또한 이유가 뭘지 궁금해서 이것저것 찾아보았지만..
- 데이터셋의 규모에 따라 보조 LM의 효과가 다르게 나타났는데 큰 데이터셋일수록 보조LM효과가 유익하지만 작은 데이터셋에서는 보조LM에서는 효과거 없다는걸 확인 할수있었습니다.
- LSTM w/ aux LM ⇒ 구조의 차이 (LSTM) !
- LSTM을 썼을 경우 평균적으로 5.6이 하락했고 전반적인 수치적으로 transformer구조가 전이에 훨씬 적합한 것을 확인할 수 있었습니다.
- 이 실험 또한 MRPC하나만 LSTM이 약간 높은데 이부분 또한 이렇다할 분석이 없어서 이것저것 찾아보고 생각을 해본결과..
뉴스문장쌍이니까.. 뉴스는 형식이 단순하고 패턴적이니까..? long term dependency가 크게 무의미한가…?
5. Conclusion
GPT는 두단계 프레임 워크인 (1)대규모 코퍼스 기반 Generative Pre-Training → (2)태스크별 라벨 데이터 기반 Supervised Fine-tuning) 이 과정을 통해 다양한 언어task를 해결할수 있었습니다. 또 transformer를 사용하여 대규모 Corpus에서 학습한 Generative Pre-Training모델을 통해 world knowledge와 장기의존성에 강력한 처리 능력을 얻을 수 있게 되었고 이로인해 downstream task(NLI, QA, semantic similarity, classification)작업에 효과적으로 전이 할수 있었습니다.
논문의 가장 중요한 메시지는 비지도 사전학습이 지도학습 성능을 크게 향상시킬 수 있다는 점에 있습니다. 저도 이 논문을 보며, 단순히 “비라벨 데이터에 라벨을 어떻게 붙일까?”가 아니라, “비라벨 데이터 자체를 어떻게 활용할까?”라는 새로운 관점에서 접근했다는 것이 굉장히 인상 깊었습니다.
막 복잡한 기법을 쓰는게 아니라 단순한 발상 하나로 GPT라는 큰 변화가 생겼다는게 거창하고 대단한 기술들도 당연히 중요하겠지만 데이터나 문제를 바라보는 시각 자체가 더 중요한것 같다는걸 생각하게 되었습니다
첫 x-review다 보니 부족한 점들이 많겠지만 그래도 끝까지 읽어주셔서 감사합니다 🙂
안녕하세요, 찬미님! 처음 리뷰 잘 읽었습니다 🙂
말씀하신대로 이 논문을 기점으로 NLP뿐만 아니라 다양한 인공지능 분야에서 비지도 학습 방식으로의 큰 성능 향상이 이루어진 것이 가장 큰 기여라고 생각합니다.
GPT 논문 리뷰인 만큼, 더 공부해보면 좋을 것 같다 생각하는 내용들을 댓글로 남겨두겠습니다.
Q1. GPT가 Transformer의 Decoder-only 구조를 사용한 이유를 더 찾아보면 좋겠습니다. 당시 Encoder-Decoder 구조나 LSTM 대신 이 방식을 선택한 배경을 살펴보면 모델 설계 철학을 이해하는 데 도움이 되지 않을까 싶네 (ex. BERT와의 차이점도 함께 비교해보면 좋겠네요!)
Q2. Position Embedding의 역할과 어떤 값이 더해지는 지와 같은 구조를 조금 더 깊게 알아보면 좋을 것 같습니다. 단순히 더하는 방식에서 오는 한계와, 이후 등장한 RoPE(Rotary Position Embedding) 같은 개선된 포지셔널 인코딩 기법과 비교해보면 더 도움이 될 것 같아요.
안녕하세요 주영님! 제 첫 x-review에 첫 댓글을 달아주셔서 감사합니다 🙂
Q1-1. 먼저 En-De가 아닌 Decoder-only구조를 사용한 이유는 사전학습의 task가 앞의 토큰들로 다음 토큰을 예측하는 것인데 이 task는 뒷 정보는 보지 않는 masked self-attention만으로도 가능하기 때문입니다. (반대로 크로스 어텐션 구조가 포함되는 인코더-디코더 구조는 입력문장-> 출력문장이 따로있는 번역과 같은 task에 더 적합합니다!)
Q1-2. 두번째로 LSTM구조가 아닌 이유는 LSTM은 데이터가 순차적으로 처리가 되기 때문에 장기 의존성을 잡기 어렵기 때문입니다. 반면에 GPT에서 사용되는 트랜스포머의 self-attention은 전체 문맥자체를 한번에 보고 병렬로 학습을 진행하기 때문에 긴 문맥이나 대규모 코퍼스를 다루는 task에 훨씬 더 적합합니다.
Q2 먼저 포지셔널 임베딩의 역할은 어텐션은 기본적으로 토큰을 집합처럼 다루기 때문에 토큰의 순서에 대한 정보가 없고 토큰의 위치에 대한 정보를 따로 추가해줘야 합니다. 따라서 각 토큰벡터에다가 해당 토큰의 위치벡터를 더해진 값이 모델로 들어가게 됩니다.
하지만 이렇게 절대위치를 더하기만 하는 방법은 각 토큰이 얼마나 떨어져있는지와 같은 상대적인 거리정보를 담지 못하고 길이가 길어질 경우 불안정해질수가 있다는 한계를 가집니다.
그래서 언급해주신 Rotary Position Embedding과 같은 방법이 등장하게 되었습니다! 해당 방법은 위치정보를 단순히 더해주는 대신 쿼리와 키 벡터를 위치마다 ‘회전’시켜줘서 토큰의 어텐션스코어가 절대위치가 아닌 상대적인 거리(뭐가 뭐를 수식하는지 등)에 직접 반응이 되도록 했고 긴 텍스트에서도 안정적인 강점을 가지게 됩니다.
남겨주신 댓글 덕분에 조금 더 깊게 공부해볼수 있었습니다~! 감사합니다 !!
안녕하세요 첫 리뷰 축하드립니다
먼저 unlabeled pre-training 부분에 질문이 있습니다. 해당 단계를 학습할때 다음단어의 확률 분포를 계산한다고 작성해주셨는데, 다음 단어의 확률분포를 구하는 방법은 무엇인가요?
다음으로, 4번 Analysis 실험에 질문이 있습니다. zero-shot behaviors에서 “파인튜닝 없이 사전학습 된 LM으로만 여러 NLU task를 휴리스틱으로 풀어보는 실험을 진행”했다고 했는데, 휴리스틱으로 풀어보는게 무엇인지 보충 설명 부탁드립니다. 또한 동일 실험에서 트렌스포머의 attention 메모리 구조가 LSTM 보다 전이에 유리하다고 판단한 결과는 성능의 우수성 뿐인지 궁금합니다. 혹시 추가적 실험이 있었나요?
감사합니다
안녕하세요 찬미님, 좋은 리뷰 감사합니다!
방대한 언어 데이터를 효과적으로 활용하기 위해 대규모 비지도 사전학습으로 긴 문맥을 학습하고, 다양한 NLU 태스크를 수행하기 위해 파인튜닝을 수행하는 방식이라고 이해했습니다.
GPT 계열에서 decoder-only 단방향 LM을 선택한 구체적 이유는 무엇인가요? BERT는 bidirectional인 것으로 알고 있는데, 왜 GPT는 단방향 구조를 채택했는지, 단방향 구조의 장단점은 무엇인지 궁금합니다.
감사합니다!
안녕하세요 예은님 댓글 감사합니다~!!
이해하신대로 비지도 사전학습에다가 지도학습을 파인튜닝하여 다양한 task를 수행하게 됩니다!
예은님이 주신 질문들은 위의 주영님이 달아주신 댓글에 내용이 포함되어 해당 댓글에 자세하게 적어 놓았으니 참고해주시면 감사하겠습니다~!
안녕하세요 찬미님 첫 논문리뷰로 어려운 논문을 리뷰해주셨네요
간단하게 두가지 질문이 있는데, GPT 논문이지만 구조적 설명에서 Transformer 설명이 가장 중요하게 설명된 만큼 masked multi head 구조와 FFN 말고도 add & layernorm 부분에 대한 설명도 간단하게 있었으면 좋겠습니다.
그리고 masked self attention 에서 “문장의 각 위치는 자기자신과 그 이전의 토큰까지만 참고할 수있고 이후 단어는 모두 마스킹되어 0(−∞)으로 처리됩니다” 여기서 0 혹은 -inf 로 처리되는 부분에 대한 설명도 추가적으로 있었으면 좋겠습니다.
안녕하세요 인택님 질문 감사합니다~!!
1. Masked Self-Attention은 현재 토큰이 현재와 이전 토큰만 보도록 미래위치를 마스킹하는것을 말하는데 −∞는 softmax 전에 미래 위치를 확률 0으로 만드는 방법이고 0은 softmax 후 나온 가중치를 강제로 0으로 지우는 방법을 말합니다.
2. add & layernorm은 간단하게 설명하자면 먼저 add는 sub레이어 출력에 해당 입력을 더하는 잔차연결을 말합니다! 이것으로 원래 정보로 보존할 수 있게되고, layernorm은 레이어 별로 평균과 분산을 맞추어주어 각 토큰벡터의 채널 단위로 값을 정리함으로 학습을 안정화 해줍니다