안녕하세요 이번에 들고온 논문은 Open-vocabulary 세팅에서 파인튜닝된 CLIP 이 가지는 confidence calibration 문제를 다룬 논문입니다. 바로 논문리뷰 시작하겠습니다.
Abstract
비전 언어 모델들은 최근 다양한 Open vacabulary task 에서 강력한 성능을 보여주며 이미지 인식이나 텍스트 기반 시각 콘텐츠 생성, 비주얼 챗봇등과 같은 응용 분야에서 두각을 나타내고 있다고 합니다. 특히 프롬프트 러닝과 같은 파라미터 효율적인 파인튜닝 기법에 집중해왔다고 하는데, 실제 배포 단계에서 모델의 신뢰성에 큰 영향을 줄 수 있는 중요한 문제인 confidence calibration 이 간과되어 왔다고 주장하게 됩니다. 저자의 논문은 이러한 공백을 메우고 프롬프트 러닝 환경에서의 신뢰도 보정 문제를 분석하였으며 기존의 보정 밥법들이 Open vocabulary 환경에서 충분히 효과적이지 않음도 밝혀냈다고 합니다.
이를 해결하기 위해 저자는 Distance-Aware Calibration (DAC) 이라는 단순하면서도 효과적인 접근법을 제안하게 됩니다. 간단히 얘기하면 예측된 텍스트 레이블과 베이스 클래스 사이의 거리를 이용해 temperature scaling 을 조절하는 방식이라고 합니다. 해당 방법론을 통해 11개의 다양한 다운스트림 데이터셋과 7가지 프롬프트 러닝 기법을 대상으로 실험했으며 추론 속도를 희생하지 않으면서 높은 효과를 냈다고 합니다.
프롬프트 튜닝을 설명하자면 CLIP 과 같은 VLM 등은 이미지와 텍스트를 같은 임베딩 공간으로 맵핑해서 비교하는 것은 모두 익숙히 들어봤을 것입니다. 이때 CLIP을 파인튜닝하는 방법 중 텍스트 인코더 쪽 입력을 조정하는 방법입니다.
“a photo of a [class]” 와 같은 고정 텍스트 대신 “[prompt] + class name” 의 형태로 학습합니다.
이때 [prompt] 는 학습 가능한 파라미터 (보통 몇 개의 토큰 형태)라서 downstream task 데이터셋에 맞춰 최적화됩니다.
confidence calibration이 왜 필요하고 무엇인지를 간단하게 언급하자면
모델의 confidence score가 만약 0.8인 클래스 A가 존재한다면 실제 같은 조건의 100개의 샘플중 80개가 클래스 A라면 잘 calibrated 되었다고 할 수 있습니다.
여러 상황이 있을 수 있지만 novel 클래스에 대한 과신이 있을수도 있고, base 클래스에 대해 underconfidence인 상황일 수도 있는데 이러한 상태를 confidence mismatch라고 생각하면 됩니다.
Introduction
Open vocabulary 논문을 읽으면 항상 등장하는 인트로인 VLM 의 발전이 CLIP 과 같은 모델의 자연어 supervision 을 활용한 대규모 학습으로 발전해왔다는 이야기를 합니다. 그러면서 VLM 의 다운스트림 응용 성능을 강화하기 위한 파인튜닝 기법 중 프롬프트 학습이 파라미터 효율성과 견고성 덕분에 가장 주목을 받았다고 합니다.
이상적으로는 Open vocab 설정에서 파인튜닝된 VLM은 학습에 포함된 base 클래스와 포함되지 않은 novel 클래스 모두에 대해 정확하고 신뢰할 수 있는 예측을 수행해야 합니다. 프롬프트 학습 기법을 사용하면 정확도를 크게 개선할 수 있지만, 여전히 신뢰도 문제가 있으며 충분히 탐구되지 않아 의료 진단이나 자율 주행과 같은 고위험 실생활 응용에서 모델 배포를 가로막고 있다고 합니다.
기존 연구에서는 사전학습된 CLIP 모델이 zero-shot 설정에서는 잘 보정되어 있다는 것이 밝혀졌지만, 다운스트림 태스크로 파인튜닝 된 후에는 보정 불일치 문제가 발생한다고 합니다. 즉 예측 확률이 실제 정답 가능성과 일치하지 않는다는 문제점이 생기는 것입니다. 지금까지의 연구는 파인튜닝된 CLIP의 base 클래스 보정 문제만 다루어 왔지만 저자의 연구는 처음으로 Open vocab 환경에서 파인튜닝된 VLM 의 보정문제를 다룹니다.
- 파인튜닝된 VLM은 novel 클래스에 대해서는 과도한 자신감을 보인다.
- base 클래스에 대해서는 자신감 부족을 보인다.
- 최신 post-hoc보정 기법들이 base 클래스의 miscalibration 문제는 완화할 수 있으나, 그 효과가 novel 클래스에는 전이되지 않는다. 이는 Open vocab 보정을 위한 새로운 post-hoc 방법이 필요함을 얘기한다.
저자는 가장 널리 쓰이는 post-hoc 보정 방법인 temperature scaling을 간단히 수정하여 novel 클래스의 miscalibration 문제를 해결할 수 있음을 보입니다. 저자의 방법론인 DAC 는 novel 클래스의 편차 정도(deviation degree) 분석에서 영감을 받았습니다.
프롬프트 튜닝 방식은 base 클래스의 텍스트 피처와 novel 클래스의 텍스트 피처 사이의 큰 간극을 만드는데 novel 클래스의 편차 정도가 클수록 모델은 오히려 더 자신감 있게 예측하는 경향이 나타난다고 합니다. 저자의 DAC 의 핵심 아이디어는 novel 클래스의 텍스트 임베딩과 base 클래스의 텍스트 임베딩 사이의 거리를 기반으로 temperature 를 조정하는 것입니다. 구체적으로는 novel 클래스마다 텍스트 편차 점수를 추정하고, 그 크기에 따라 temperature를 스케일링 합니다. 이렇게 하면 base 클래스와 멀리 떨어진 novel 클래스일수록 더 높은 temperature가 적용되어 Open vocab 환경에서 보정 능력이 향상됩니다.
저자의 방법론은 7가지의 프롬프트 러닝 기법에서 일관되게 보정 성능을 향상시킴을 보였으며 기존의 post-hoc 기법과 결합했을때도 성능 향상이 확인되었다고 합니다.
저자는 논문의 주요 기여를 이렇게 말합니다.
- 문제 정의 : 파인튜닝된 VLM은 종종 miscalibration 문제를 겪으며, 기존 post-hoc 보정 방법은 Open vocabulary 환경에서 잘 동작하지 않는다.
- 분석: 보정 성능과 텍스트 분포 간격의 상관관계를 실험적으로 규명했으며, 프롬프트 러닝 이후 VLM은 base 클래스와 멀리 떨어진 novel 클래스에 대해 과도하게 자신감을 갖는 경향이 있다.
- 방법: DAC라는 단순하고 효과적인 post-hoc 보정 기법을 제안하여, 분류 정확도를 유지하면서도 confidence를 보정한다
- 평가: 7가지 VLM 튜닝 방법과 11가지 데이터셋을 대상으로 한 광범위한 실험을 통해 DAC의 효과성을 입증했다.
Background
CLIP
이미지와 텍스트 간의 정렬을 측정하는 비전-언어 모델로, 이를 통해 Open vocabulary class 에 대한 zero-shot 추론이 가능합니다.
이미지 인스턴스 x∈Rd 와 텍스트 라벨 c 가 주어졌을 때, CLIP의 로짓(logit) 함수는 다음과 같이 정의됩니다.
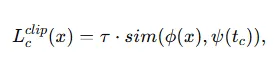
- ϕ 와 ψ는 각각 CLIP의 이미지 인코더와 텍스트 인코더입니다.
- tc 는 “a photo of a {class}”와 같은 수작업 프롬프트로부터 얻어진 텍스트입니다.
- τ 는 보통 100으로 설정되는 상수 스케일 파라미터입니다.
다중 클래스 분류에서는 라벨 후보 집합 에 대해 확률이 가장 높은 클래스를 선택합니다.
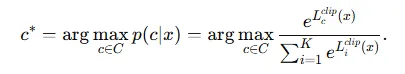
- p(c|x)는 인스턴스 x에 대해 클래스 c가 맞을 확률을 의미합니다.
Prompt Tuning
CLIP을 다운스트림 태스크에서 더 강화하기 위해, 프롬프트 튜닝 알고리즘이 제안되었습니다.
CoOP
- 수작업 프롬프트 대신 학습 가능한 텍스트 토큰 집합 T={v1,v2,…,vM} 을 사용합니다.
- 여기서 M 은 토큰 길이입니다.
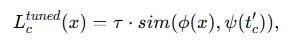
- t’c = [v1,v2……,vM,c] 이며 c는 클래스 이름의 임베딩 입니다.
튜닝 과정에서 학습 가능한 토큰 T 는 few-shot 데이터셋 D = {[xi,ci]}N_i=1 에 대해 cross entropy loss 를 최소화 하도록 최적화됩니다.
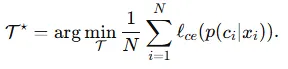
CoCoOp
unseen 클래스에 대해서도 일반화가 유지되도록 인스턴스에 따라 달라지는 조건부 프롬프트를 도입했다고 합니다.
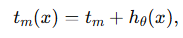
- 여기서 hθ 는 신경망으로 m ∈ {1,2,…M} 입니다.
이러한 튜닝 기법들은 좋은 성능을 보이지만, 예측 확률 p{c|x}의 신뢰도 문제는 여전히 불분명하여 저자의 논문에서 프롬프트 튜닝 환경에서의 confidence calibration 을 다룹니다.
Confidence Calibration
다중 클래스 분류에서 VLM은 클래스 확률 p(c|x) 를 출력합니다. 정확도가 높을 뿐만 아니라 예측 확률이 실제 정답 확률을 잘 반영하는 것이 기대되어야 한다고 합니다.
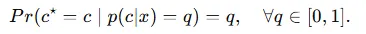
위의 수식을 설명하자면 앞서 말한 해당 샘플이 70% 확률로 클래스 A라고 한다면 실제로 그 조건에서는 70%는 맞아야 한다는 뜻입니다.
이를 수치화하기 위해 Expected Calibration Error (ECE) 를 사용한다고 합니다.
사용하는 방법은 샘플 N개를 K개의 구간(bin)으로 나누고 각 구간에서 정확도(acc) 와 평균 confidence 차이를 계산하여 가중합합니다.
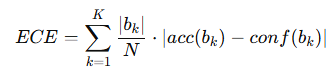
여기서 |bk|는 bin bk에 속한 샘플 수 입니다.
ECE 값이 작을수록 모델이 잘 보정되어 있다는 의미입니다.
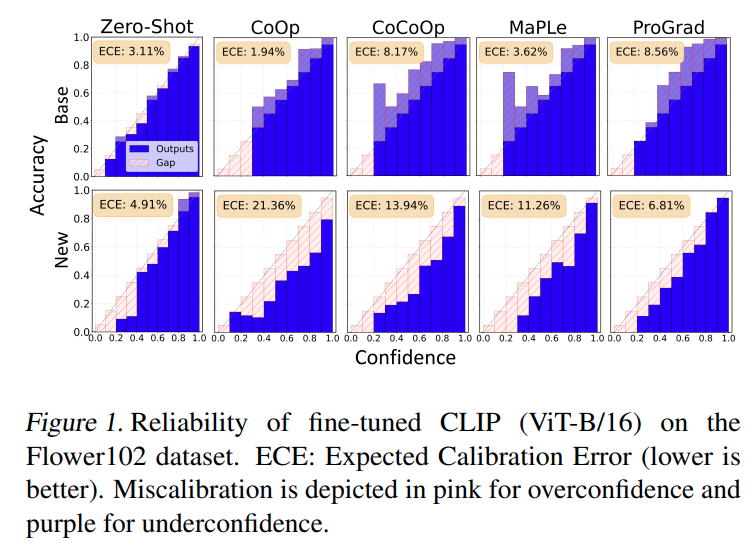
사전학습된 CLIP은 이미 잘 calibrated 된 모습임을 먼저 확인할 수 있습니다. 각 프롬프트 튜닝 알고리즘 방법론들의 ECE 동향을 분석하자면 우선 저자의 직관으로는 튜닝 후 딥 모델이 학습한 base 클래스에 대해서는 더 높은 confidence 를 보이고 학습되지 않은 novel 클래스에 대해서는 더 보수적으로 예측할 것으로 기대했으나 결과는 정반대였다고 합니다.
튜닝된 VLM은 base 클래스에서는 underconfident 한 모습을 보였으며, novel 클래스에 대해서는 overconfidnent 한 모습을 보였다고 합니다.
저자는 이러한 문제점을 해결하기 위해 일반적으로 사용하는 post-hoc confidence calibration 기법을 적용해서 분석하였다고 합니다.
- Scaling 기반 방법 : Temperature Scaling
- Binning 기방 방법 : Historgram Binning
Post-hoc 보정은 base 클래스의 miscalibration 문제를 개선할 수 있었다고 합니다. 다만 base 클래스에서 학습된 보정 효과는 novel 클래스에는 전이되지 않았다고 합니다.
분석으로는 base 클래스에서 학습된 보정기를 단순히 novel 클래스에 적용하는 것은 더 넓은 unseen 분포에 대해 최적이 아님을 보여준다고 합니다.
Open-Vocabulary calibration
먼저 비전-언어 임베딩 공간을 시각화하여 base 클래스와 novel 클래스 간의 텍스트 분포 차이가 보정에 중요할 역할을 한다는 것을 보였다고 합니다. 이후 이 간극을 정량화하기 위해 distance 기반 metric을 도입해서 novel 클래스의 편차 정도를 정의하고 저자가 제안하는 방법의 장점을 설명한다고 합니다.
Feature Space Analysis
VLM 프롬프트 튜닝에서 가장 큰 변화는 텍스트 특징에 나타납니다. 따라서 이러한 변화가 novel 클래스의 miscalibration 과 어떻게 연결되는지를 분석했다고 합니다.
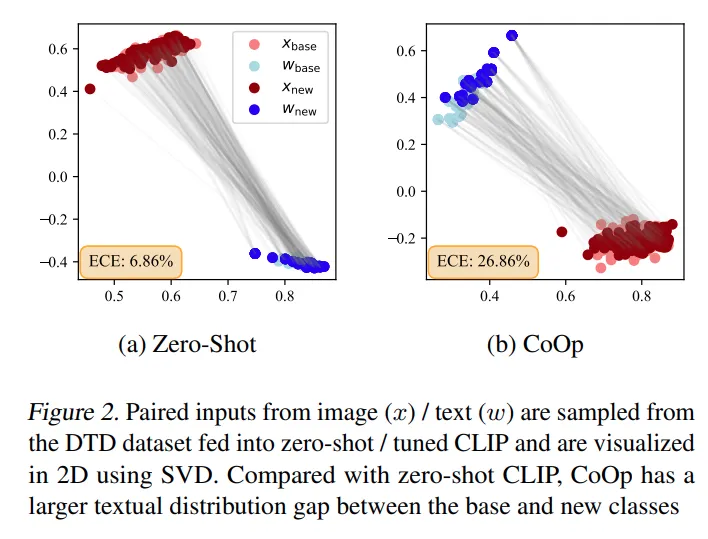
이미지와 텍스트 임베딩 벡터를 각각 SVD 로 특이값 분해를 하고 2D 로 시각화한 것입니다. zero shot CLIP에서는 text의 클래스간 분포가 base와 new 에서 밀집되어있지만 CoOp 에서는 상대적으로 떨어져 있어 전체 ECE 가 높은 것을 확인할 수 있습니다. 이러한 결과를 토대로 텍스트 분포 간극의 편차 정도가 Open Vocabulary 보정에 핵심적인 요인이라고 가설을 세웠다고 합니다.
저자는 이를 확인하기 위한 검증을 위해 proximity(Xiong et al. 2023) 라는 distance 기반 metric으로 novel 클래스의 편차 정도를 정량화 했습니다.
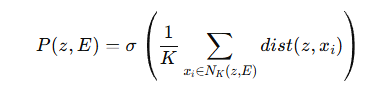
주어진 샘플 임베딩 z 와 hold-out feature 집합 E 에 대해 proximity는 샘플 z와 이웃 k개와의 평균거리에 반비례하는 함수라고 합니다.
- NK(z,E) : z의 K nearest neighbors
- dist(⋅,⋅): 거리 함수 (여기서는 l2-distance)
- σ: 단조 감소 함수 (여기서는 e^-x)
저자는 이를 VLM 에 적용하여 아래 수식으로 바꿨습니다.
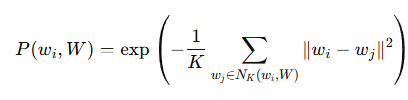
seen 클래스의 정규화된 텍스트 임베딩 집합을 W, test시 novel 클래스 ci 의 텍스트 임베딩 wi 와 base 클래스 집합 W 사이의 proximity 를 정의한 것입니다.
위의 수식에서 σ 를 exp 로 사용하고 dist 를 L2-distance 로 사용했다고 합니다.
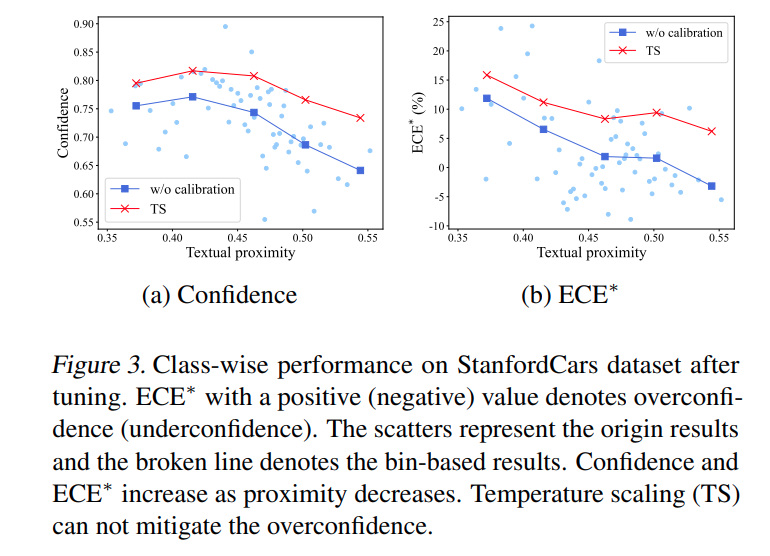
위의 수식을 분석하면 proximity 값이 낮을수록 confidence 가 높고 ECE 가 높아집니다 즉 base 분포에서 멀리 떨어진 novel 클래스일수록 tuned VLM은 오히려 더 과신하며 calibration 성능이 나빠집니다. 또한 Temperature Scaling 같은 기존 기법은 문제를 개선하지 못하고 오히려 악화시킵니다.
Distance-Aware Calibration
novel 클래스 샘플은 본래 불확실성이 커야하고 정확도가 낮아야 정상이라고 합니다. 이를 반영하기 위해 우선 tuned clip 과 pre-trained clip을 비교하여 novel 클래스의 편차를 계산합니다.
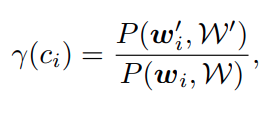
여기서 wi 와 wi’ 는 각각 pretrained 와 tuned 의 ci class 에서의 텍스트 feature 입니다.
W와 W’ 는 텍스트 피처 집합이라고 생각하면 되고 γ(ci) 는 TD 점수로 낮을수록 base 분포에서 멀리 벗어난 novel 클래스라고 합니다.
Tuned VLm은 이런 novel 클래스에 대해 과신하기 때문에 confidence score confidence 를 낮추는 방향으로 temperature scaling을 적용ㅎ압니다. 방법은
- 모든 클래스에 대해 Td 점수 집합 Γ = {qi} 을 계산해둡니다.
- 테스트 시 tuned clip 으로 예측된 클래스 c^hat = argmaxc p(c|x) 를 얻습니다.
- 그다음 보정된 logit은 다음과 같습니다.
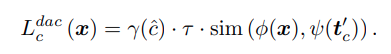
base 클래스라면 기존 temperature scaling을, novel 클래스라면 TD 점수로 scaling을 합니다.
장점으로는 텍스트 라벨 정보만 사용하므로 이미지 데이터가 없어도 적용이 가능하며 여러 알고리즘에 쉽겍 결합이 가능하고 추가적인 하이퍼파라미터 튜닝이나 연산 비용이 필요 없다는게 장점이라고 합니다.
results
저자는 다양한 프롬프트 튜닝 방법의 confidence calibration 성능을 평가합니다. 여러 데이터셋을 base클래스와 new 클래스로 나누었고 base 클래스만 학습하고 주로 new class에서 calibration 성능을 측정했습니다.
총 11개의 이미지 분류 데이터셋을 사용합니다.
- 일반 객체: ImageNet, Caltech101
- 세밀 분류(fine-grained): OxfordPets, StanfordCars, Flowers102, Food101, FGVCAircraft
- 특수 도메인: SUN397(장면 인식), UCF101(행동 인식), DTD(텍스처), EuroSAT(위성 이미지)
비교 방법
- Prompt tuning 계열:
- CoOp, CoCoOp, ProDA, KgCoOp, ProGrad
- Multi-modal tuning 계열:
- MaPLe, PromptSRC
평가 지표
- ECE (Expected Calibration Error)
- MCE (Maximum Calibration Error)
- ACE (Adaptive Calibration Error)
- PIECE (Proximity-Informed ECE)
세부사항
- CLIP (ViT-B/16) 사용, 3회 평균.
- Few-shot 학습: 클래스당 16 샘플.
- DAC에서는 최근접 텍스트 특징 개수 K=5로 설정해 TD 점수 계산.
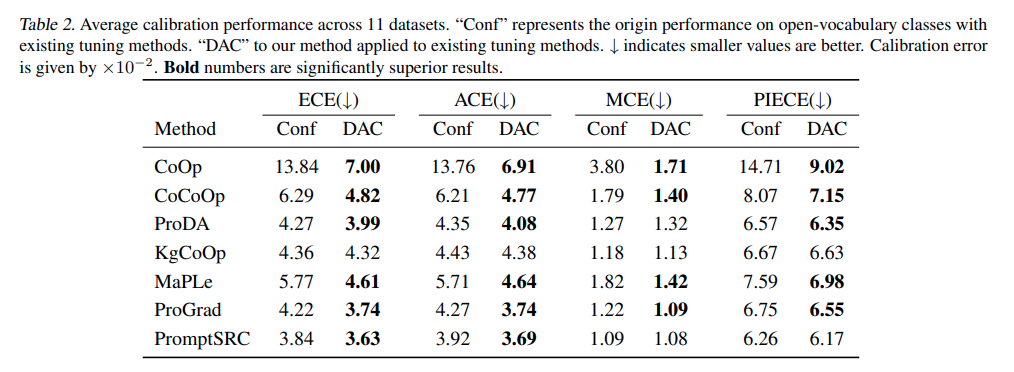
DAC가 모든 튜닝 방법에 대해서 calibration error 를 효과적으로 줄입니다. MaPLe, PromptSRC 같은 멀티 모달 튜닝에도 적용이 가능한 것을 알 수 있습니다. 결과적으로 테스트 분포 간극이 다양한 튜닝 방법에서 공통적으로 존재하고, DAC가 이를 보정해 줌을 정량적으로 확인할 수 있습니다.
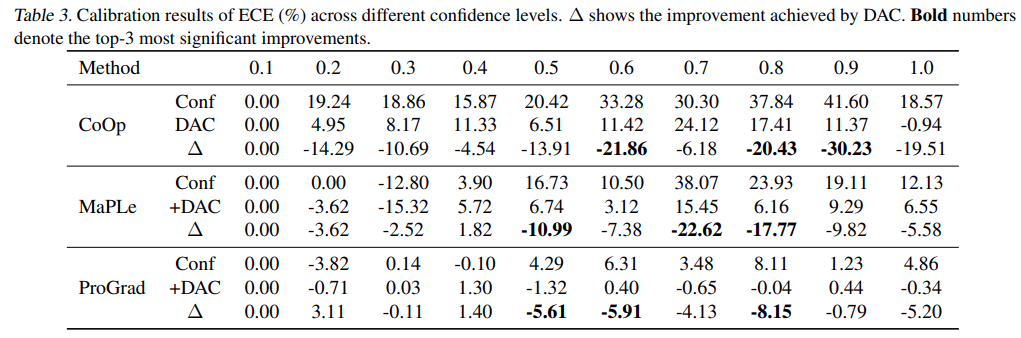
CoOp 과 멀티모달 튜닝계열에서의 confidence score 별 성능입니다. DAC가 특히 confidence score가 높은 대역대에서 효과가 상대적으로 큰 것을 알 수 있습니다.
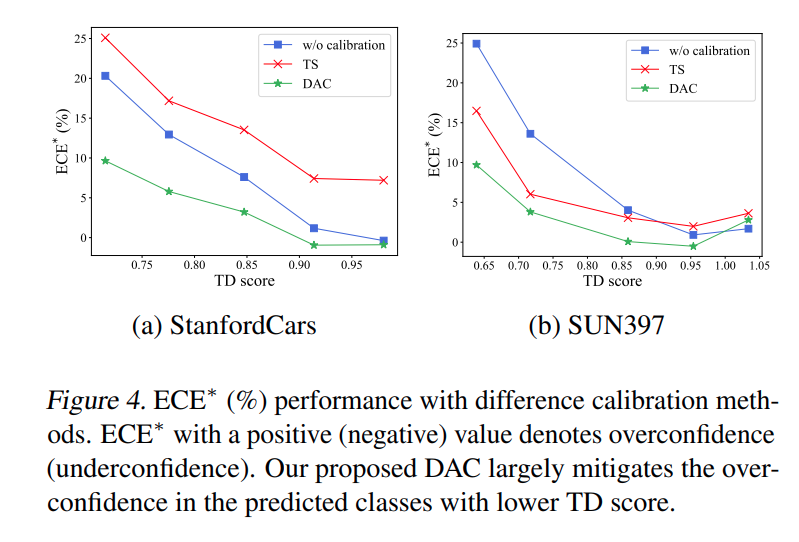
figure 를 통해 TD score 가 낮을수록 confidence가 높아지고 calibration 성능이 낮아짐을 알 수 있고 기존 방법론인 Temperature Scaling은 오히려 더 안좋은 결과를 내는 것도 알 수 있습니다.
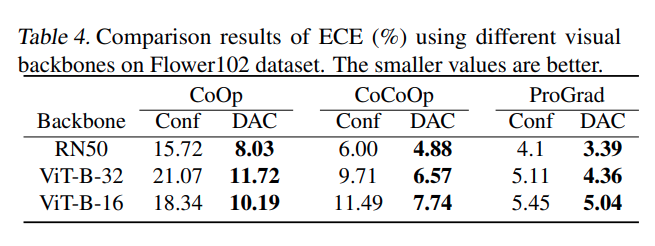
여러 백본에서도 저자의 방법론이 효과적으로 적용됨을 확인할 수 있습니다.
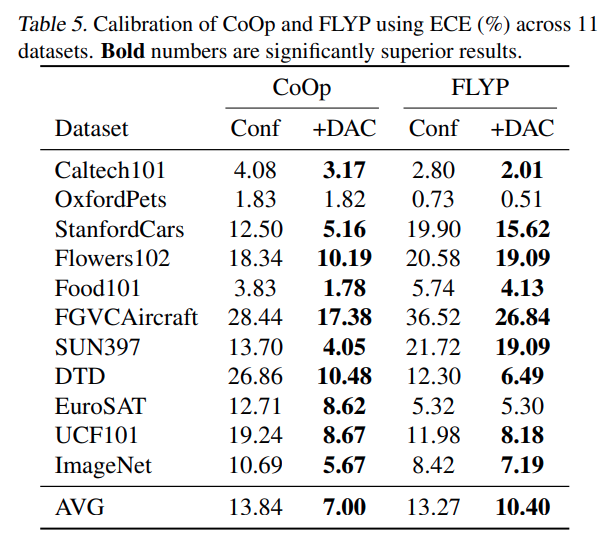
저자의 DAC방법론이 프롬프트 튜닝 뿐만 아니라 full fine-tuning 방식인 FLYP 에도 적용될 수 있음을 보입니다. 제가 이전에 리뷰한적이 있는 논문이라 궁금하시면 찾아보면 될 것 같고, 이미지와 텍스트 인코더를 모두 기존 CLIP loss로 파인튜닝한다고 생각하시면 됩니다.
conclusion
저자는 DAC라는 방법론을 제안하고 파인튜닝된 VLM에서의 temperature scaling을 간단히 보완하는 post-hoc 보정 기법으로 Open vocabulary 성능을 향상시켰습니다. 여러 데이터셋, 백본, 여러 방법론등에서 그 성능이 오름을 확인헀으며 추가 추론속도가 필요하지 않다는 점에서 그 contribution이 있다고 생각합니다.
저자는 이번 연구가 VLM 의 Calibration 분야에서 후속 연구가 연구되기를 기대한다고 합니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
리뷰를 읽다보니 저자들은 text embedding 간의 간극이 miscalibration의 주요 원인이라고 주장하지만, 혹시 다른 요인 예를들어서 이미지-텍스트 alignment 불균형이라던지 이런 것들은 아예 배제 시키고 생각하는 것인지 이러한 부분도 따로 언급한 부분이 있는지 궁금합니다. 만약 text space의 구조가 calibration에영향을 미친다면 단순한 post-hoc 보정보다도 prompt tuning 자체에서 embedding space의 위치를 유지하면서 학습하는 방식이 더 근본적인 해결책이 될 수 도있지 않을까 생각이 듭니다!
감사합니다.
안녕하세요 우현님 답글 감사합니다.
저자가 따로 이미지-텍스트 misalignment에 관한 내용을 언급하지는 않습니다. text space 에서의 novel base 간격 차이가 miscalibration에 영향을 준다는 것을 실험적으로 증명하고 개선한 것으로 contribution을 만든데에 그칩니다. 물론 이미지-텍스트의 불균형이 또 존재한다는 것을 입증하고 그걸 실험적으로까지 또 증명했다면 그것도 논문으로 썻을 것이라 생각되고, 이후에 말씀하신 “post-hoc 보정보다도 prompt tuning 자체에서 embedding space의 위치를 유지하면서 학습하는 방식이 더 근본적인 해결책이 될 수 도있지 않을까 생각이 듭니다!” 이부분은 약간 와닿지가 않아서.. 학습 과정에서 text embedding space가 무너진다는 가정을 해야 이 질문이 가능할 것 같은데 일단 그거가 이 논문에서 다뤄지거나 증명되지 않았어서 그 가정이 맞다면 해당 방법이 더 근본적인 방법론이긴 할 것 같습니다.
안녕하세요 인택님 리뷰 감사합니다.
제가 지식이 없어서 궁금해서 들어왔다가 모르는게 너무 많다는걸 느끼고 가네요,, 하하 용어도 잘 모르는 상태라 간단한 대한 질문 남기고 가겠습니다
Open vocab 환경에서 파인튜닝된 VLM이 novel 클래스에 대해서는 과도한 자신감을 보이고 base 클래스에 대해서는 자신감 부족을 보이는 이유가 temperature scaling때문인게 맞을까요? 맞다면 이유가 무엇인지 아직 와닿지가 않아서 조금만 설명 부탁드리겠습니다.. 또 post-hoc confidence calibration은 어떤 기법인가요?
안녕하세요 영규님 답변 감사합니다.
기존의 post-hoc 방식은 학습시키는 base class에 대해서만 overconfidence 하는 경향을 줄여주는 temperature scaling을 사용했습니다. 다만 Open vocabulary 설정에서 novel 클래스는 그런 고려가 존재하지 않았고 기존 text embedidng 과 거리가 멀기 때문에 모델이 상대적으로 쉽게 확신하는 경향성이 생겼고 그 갭을 보정하는 새로운 post-hoc 방식을 제안했다고 생각하시면 될 것 같습니다.
post hoc claibration 용어는 간단히 학습이 끝난 모델의 출력을 그대로 두고 출력 확률을 보정하는 추가 단계라고 생각하시면 됩니다.
안녕하세요 인택님
좋은 리뷰 감사합니다
새로운 클래스의 텍스트 특징과 기존에 학습한 클래스들의 텍스트 특징 간의 거리를 계산하여 신뢰도를 보정하는 후처리 기법으로 Distance-Aware Calibration을 사용한것 같습니다. 텍스트 특징의 거리가 멀수록 모델의 예측 신뢰도를 낮추도록 하는 방법인거 같은데, 반대로 시각적 정보의 변화나 특이성은 전혀 고려하지 못하나요? 만약 텍스트적으로는 유사하지만 시각적으로는 완전히 다른 분포를 가진 데이터가 들어올 경우 어떻게 처리되나요 또는 저자의 언급이있나요
안녕하세요 우진님 답글 감사합니다.
우선 이해하신게 맞고, 시각적 정보에 대한 특이성은 고려하지 못하는 설정 방법이 맞습니다.
그것을 고려하려면 FLYP 같은 이미지-텍스트를 동시에 align을 맞추는 방식이 필요하며 FLYP 를 사용한 것에도 저자의 방법론을 적용할 수 있어서 다른 방법론과 같이 사용하는 것이 필요할 것 같습니다.
그리고 시각적으로 유사한 데이터가 들어오면 만약 CLIP 과 동일한 loss로 재학습한다는 가정에서는 텍스트 임베딩이 이미지를 어느정도 따라갈거라 base novel 이 벌어지지 않을수도 있습니다. 이건 데이터셋에 따라 다르고 실제 정량적으로 비교를 해봐야 알 수 있는 정보일 것 같네요.
안녕하세요 인택님, 좋은 리뷰 감사합니다.
상식적으로 생각했을 때 파인튜닝된 VLM이 novel 클래스보다 base 클래스에서 높은 자신감을 보일 것 같은데, 실제로는 반대의 결과가 나온다는 점이 신기했던 것 같습니다.
신입 연구원의 입장에서 간단한 질문 하나만 드리고 싶은데, temperature라는 개념이 생소해서, temperature가 어떤 개념인지 그리고 temperature scaling은 어떻게 수행하는 것인지 간단한 추가 설명 부탁드려도 될까요?
안녕하세요 재윤님 답글 감사합니다.
temperature는 softmax 함수에서 확률값이 되기 전 로짓에 T 라는 상수를 나눠줘 너무 극단적으로 확률값이 치우쳐지지 않게 학습되거나 고정시켜놓는 파라미터입니다. 물론 T를 1보다 작은 숫자로 두면 더 극단적으로 치우쳐지게 학습시킬수도 있습니다.
안녕하세요 인택님, 좋은 리뷰 감사합니다.
파인튜닝 된 CLIP에서, novel 텍스트 임베딩이 base 텍스트 임베딩의 분포와 거리가 멀수록 miscalibration이 심하게 나타난다는 것을 실험적으로 보이고, 이를 해결하기 위해 이 거리가 클수록 더 높은 temperature를 부여하여 novel 클래스에 대한 confidence를 낮추는 방식이라고 이해했습니다.
1. 사전학습 된 CLIP에서는 novel 클래스와 base 클래스 구분없이 텍스트 임베딩의 분포가 고르게 퍼져 있지만, 파인튜닝을 하면서 base 클래스들이 그에 최적화 된 분포를 가지게 되기 때문에 파인튜닝 이후에는 base와 novel 텍스트의 분포에 많은 차이가 생기는 것이라고 생각했습니다. 제가 이해한 바가 맞을까요?
2. Distance-Aware Calibration에서 base 클래스는 기존 scailing 방식(base 클래스에서 좋은 성능을 보이는)을 취한다고는 하였는데, 그렇다면 이를 적용했을 때 base 클래스에 대한 성능 저하는 전혀 없는 것인가요?
감사합니다!
안녕하세요 예은님 답글 감사합니다.
1번 질문에 대해서는 올바르게 이해하셨습니다. 파인튜닝을 진행하지 않았을때는 뭐 당연하게도 base novel 클래스에 대해 비슷한 분포를 가지고 있는 것이 맞고, 학습 이후에는 달라지는 것도 맞습니다.
2번 질문에 대해서는 흠 성능 저하라는 측면은 사실 이번 논문에서 다루고자 하는 부분은 아닙니다. DAC의 목적은 성능 자체를 바꾸는 게 아니라, confidence score의 신뢰도를 높이는 것에 있습니다. 논문에서 base 클래스는 기존 scaling 방식인temperature scaling과 크게 다르지 않게 처리되므로, base 성능 저하가 두드러지게 보고되지는 않았습니다. 다만 말씀처럼 실제 실생활 배포에서는 thresholding 방식에 따라 간접적인 영향이 있을 수 있습니다. 저자들도 논문 초반에 밝힌 것처럼, DAC의 주된 목표는 실제 환경에서 신뢰할 수 있는 confidence를 만드는 것에 있었고, base 성능 손실 최소화는 부차적인 고려였다고 보시면 될 것 같습니다.