Abstract
로봇 조작에서 인지와 행동을 연결하기 위해 물체의 상호작용 영역을 인식하는 것은 중요합니다. 실제 세계에서의 상호작용은 두 물체 사이의 상호작용이지만, 기존 연구들은 단일 이미지에만 집중하여 affordnce 영역을 인식하고 있습니다. 해당 논문은 데이터가 부족한 환경에서의 object-to-object affordance grounding을 다루고있으며, 새로운 one-shot 학습 방식을 제안합니다. VFM을 이용하여 추출한 semantic feature와 point cloud를 결합하여 기하학적 이해를 제공하며, one-shot 방식을 제안하여 새로운 객체와 카테고리로 효과적으로 일반화가 가능하도록 합니다. 또한, 3D affordance representation을 LLMs과 통합하여 LLM의 물체 상호작용 영역에 대한 이해 능력을 향상시키고, 실험을 통해 해당 논문에서 제안하는 O3Afford의 정확도와 일반화 성능에 대하여 어필합니다.
Introduction
affordance grounding은 물체의 기능적으로 대응되는 영역을 인식하는 연구로, 상호작용, 영상에 대한 이해, 로봇 조작 등을 가능하게 합니다. 기존의 affordance grounding 연구는 실제로 상호작용은 물체와 물체 사이에서 이루어진다는 점을 간과하고 단일 물체 중심으로 이루어졌습니다. 따라서 저자들은 object-to-object affordance grounding 연구를 다루고자 하였으며, 데이터 수집의 어려움도 함께 고려한 연구를 수행하였습니다. 이러한 object-to-object affordance grounding 연구 중 하나인 O2O-Afford는 annotation-free 방식으로 시뮬레이션을 활용하여 contact 정보를 뽑아내어 적용하고자 하였으나, placing과 fitting 정도의 단순한 affordance만을 고려하였습니다. 저자들은 이보다 더 복잡한, pouring과 cutting 등의 affordance를 목표로 연구를 수행하였습니다.
저자들은 학습을 최소화하여 object-to-object affordance grounding을 일반화하는 방식을 찾고자 하였으며, 최근 다양한 분야를 통해 zero-shot과 few-shot에 대한 일반화 성능이 입증된 VFMs를 활용하였습니다. 이러한 VFMs는 기존의 affordance grounding 관련 연구들을 통해 가능성이 입증되었으나, 기하학적 정보의 부족으로 인해 다른 시점, 새로운 물체 카테고리로의 일반화에는 제한이 있었습니다. 따라서 저자들은 3D representation으로 구한 기하학 정보가 VFMs의 의미론적 정보와 결합된다면 기하학적 변화와 새로운 물체 인스턴스, 새로운 물체 카테고리로도 일반화가 가능할 것이라 보고 VFMs로부터 3D의 의미론적 feature를 이용하는 O3Afford를 제안하였습니다.
O3Afford는 다중 시점 영상에 대하여 DINOv2로 추출한 feature를 source와 target object로 투영하고, semantic feature로 풍부해진 point cloud를 bi-directional affordance discovery 모듈을 통과시켜 두 물체 사이의 기하학적 맥락을 고려하여 최종적으로 3D affordance map을 예측하도록 합니다. 이렇게 예측된 3D affordance map을 LLM과 통합하여 최적화 기반의 로봇 작업의 제약을 생성함으로써, 로봇 조작에서 이미지와 point cloud만으로 추론하던 것에 비해 향상된 공간 이해 능력을 제공합니다.
해당 논문의 contribution을 정리하면,
- O3Afford라는 one-shot 기반의 object-to-object affordance learning 방식 제안
- LLM을 활용하여 제약을 생성하여 object-to-object affordance를 최적화 기반의 로봇 조작에 효과적으로 통합
- 다양한 시뮬레이션 및 real-world 로봇 조작에 적용하여 기존 연구보다 더 우수한 성능ㅇ르 보였으며, 의미론적 및 기하학적 일반화 능력을 입증
Problem Formulation
해당 논문은 제한적인 데이터를 활용하여 3D object-to-object(O2O) affordance learning 문제를 다룹니다. 각 affordance 카테고리마다 1개의 학습 샘플만 존재하며, O2O affordance grounding을 2개의 point cloud 사이의 functional map을 예측하는 문제로 공식화 합니다. source object와 target object의 point cloud를 P_s \in \mathbb{R}^{N_s ⨉(3+n)} , P_t \in \mathbb{R}^{N_t ⨉(3+n)}, 이때 N_s와 N_t는 source와 target object의 point cloud 수, n은 VFM으로 추출한 semantic feature의 차원 수)라 할 때, 저자들의 모델 f_\theta는 두 point cloud에 대한 affordance map A_s \in [0,1]^{N_s} , A_t \in [0,1]^{N_t}를 매핑시키는 것을 목표로 합니다.
학습 데이터는 K개의 상호작용 object 쌍으로 이루어지며, 각 object 쌍은 서로 다른 affordance 카테고리로 구성됩니다.(\mathcal{D}_{train} = \{(\mathbf{P}^{src}_i, \mathbf{P}^{tgt}_i, \mathbf{A}^{src}_i, \mathbf{A}^{tgt}_i)\}^{K}_{i=1}) 이때, (\mathbf{P}^{src}_i, \mathbf{P}^{tgt}_i) 쌍은 i번째 affordance 카테고리에 대한 하나의 샘플이며, 모델은 zero-shot 방식으로 학습에 없는 새로운 object 쌍에 대한 affordance를 평가합니다.(\mathcal{D}_{test} = \{(\mathbf{P}^{src}_j, \mathbf{P}^{tgt}_j \}^{K}_{j=1}, \mathcal{D}_{train} \cap\mathcal{D}_{test} = \varnothing)
Methodology
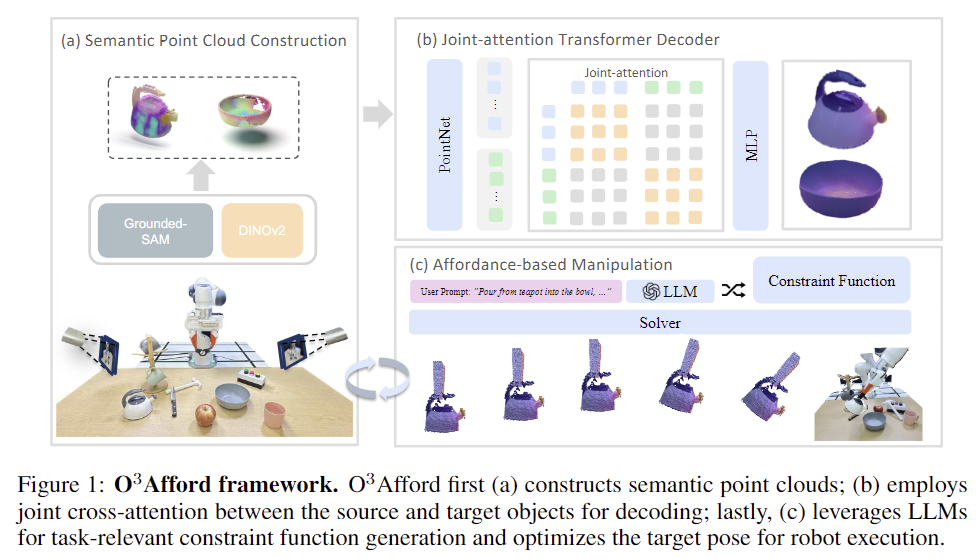
전체적인 파이프라인은 위의 Figure 1에서 확인하실 수 있습니다. 저자들은 DINOv2를 이용하여 point cloud에 대한 3D semantic feature를 생성한 뒤, 의미론적 정보가 포함된 point cloud를 활용하여 대응되는 affordance map을 생성한 뒤, 로봇 조작에 LLM과 함께 통합하여 최적화 방식을 기반으로 한 planning을 통해 로봇 작업을 수행합니다.
1. Semantic Point Cloud
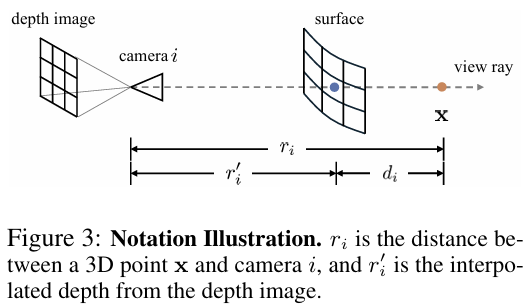
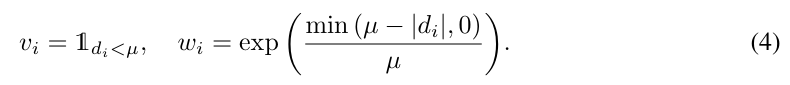
해당 파트의 경우 제가 지난주에 리뷰한 D3Field를 활용합니다. 어떠한 3D point \mathbf{x}에 대하여 i번째 시점의 카메라로 투영한 \mathbf{u}_i를 계산한 뒤, truncated depth difference d_i = r_i + r'_i를 센서로 구한 depth r_i와 보간된 depth r'_i의 차이로 구하며, 표면에 가까운 점에 집중하기 위해 visibility v_i와 가중치 w_i를 할당한 뒤, 이를 활용하여 시점별로 semantic feature \mathbf{f}_i와 instance mask \mathbf{p}_i를 구하는 방식입니다.
저자들은 이를 조금 변형하여 다중 시점의 RGB 정보를 point cloud와 정렬시켜 DINOv2 feature를 3D point cloud에 투영하고, 이를 직접적으로 point cloud representation여 인코딩하는 방식을 이용하였으며, 이를 통해 추가 학습 없이도 효과적이고 일반화된 representation이 가능하도록 하였다고 어필합니다. 즉, 앞서 point cloud에 n 차원의 feature vector를 매핑시킨 것이라 이해하시면 될 것 같습니다. (여러 시점의 view를 이용할 경우 겹치는 feature에 대해서 어떻게 처리할지 전혀 다루고 있지 않고, 코드도 아직 공개가 되지 않았습니다. D3Field방식처럼 d_i를 구하지 않고 결합하였다는 차이만 확인이 가능한 상태입니다. 실험 세팅에 따르면 시뮬레이션에서 4개 주변 시점, 실제 환경에서 2개의 카메라르 사용하였다고 하는 데, 최대한 겹치지 않도록 한 것이 아닐까 하고 추측됩니다..)
2. One-Shot Affordance Grounding
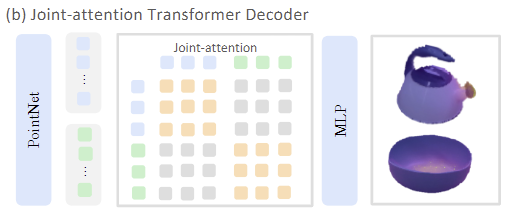
point cloud로부터 affordance 영역을 찾기 위해 저자들은 joint-attention transformer decoder를 제안하였습니다. source object와 target object의 point cloud 쌍 \mathbf{P}^{src}, \mathbf{P}^{tgt} \in \mathbb{R}^{B⨉N⨉3}과 DINOv2로 추출한 시각적 feature latex]\mathbf{F}^{src}, \mathbf{F}^{tgt} \in \mathbb{R}^{B⨉N⨉1024}[/latex]를 함께 입력으로 사용하고, point 별 affordance score를 출력합니다. 해당 네트워크는 크게 Point Cloud Encoder와 Joint-attention Transformer Decoder로 이루어지며, 해당 네트워크 학습은 BCE Loss를 이용하여 GT annotation 결과와 비교하며 최적화가 이루어집니다.
[Point Cloud Encoder]
해당 encoder는 point cloud와 DINOv2 features를 concate하여 처리합니다. (target과 source를 함께 처리합니다.) 먼저 FPS(farthest point sampling; 시작 점으로부터 가장 먼 점을 순차적으로 선택하는 방식)를 이용하여 T개의 패치 중심을 선택한 뒤, K-NN을 적용하여 주변의 값을 모아 패치를 구성합니다. 이후 PointNet을 통해 패치 레벨로 local geometric 정보를 압축한 feature를 구한 뒤, 토큰화된 입력 \mathbf{Z} \in \mathbb{R}^{2B⨉T⨉512}을 구합니다. 해당 토큰들은 one-hot encodding으로 source와 target object를 구분해둡니다.
[Joint-attention Transformer Decoder]
source와 target object 사이의 기하학적·의미론적 맥락 정보를 학습하기 위해 joint-attention transformer를 사용합니다. 여기서 cross-attention을 통해 두 객체 사이의 feature 상호작용이 가능하도록 하며, 8개의 multi-head attention을 통해 맥락을 학습합니다. (아래 수식의 괄호 안은 순차적으로 query-key-value를 의미합니다.) 이러한 cross-attention을 통해 양방향으로 상호 보완적인 affordance 관계에 대하여 효과적으로 인코딩 합니다.
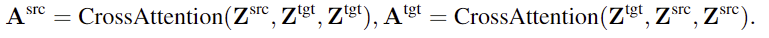
이후 포인트별로 affordance score를 예측하기 위해, 패치 수준의 embedding을 다시 원래 point cloud의 각 점으로 interpolation을 수행하여 point 단위의 dense embedding \mathbf{E}^{src},\mathbf{E}^{tgt} \in \mathbb{R}^{B⨉N⨉512}를 구한 뒤, 이 embeddings를 경량 MLP를 통과시켜 최종 affordance map \mathbf{A} \in [0,1]^{2B⨉K⨉N}을 구합니다. 여기서 K는 affordance 종류의 수를 의미하며, 즉 모든 affordance에 대한 확률을 구하는 것 입니다.(이렇게 되면 affordance 관점에서 확장의 어려움이 있을 듯 합니다. 물론 하나의 샘플을 제공하는 방식으로 모델에 확실한 가이드를 주는 방법이기도 합니다.)
저자들은 학습에 binary cross-entropy loss를 적용하였다고 합니다. 앞서 affordance map은 K개의 affordance를 고려한다고 되어있으나, 학습에서는 각 affordance에 대해서만 BCE loss를 적용하고, 평가할 때는 모든 affordance를 고려할 수 있도록 한 것으로 보입니다.
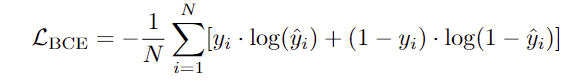
3. Affordance-Based Manipulation
객체들의 point cloud 상에서 예측된 affrodance는 두 객체 사이의 관계를 나타내며, 저자들은 이를 =로봇 조작의 제약으로 활용하는 최적화 문제로 공식화 합니다. source 와 target point cloud \mathbf{P}^{src}, \mathbf{P}^{tgt}, 각 object의 affordance map \mathbf{A}^{src},\mathbf{A}^{tgt}이 주어졌을 때, 6DoF의 Translation \mathbf{T} \in SE(3)을 최적화하여 source object가 작업을 수행하도록 정렬하며 여러 제약을 만족시키도록 하며 이에 대한 식은 아래와 같습니다. 아래의 식에서 \mathcal{S}_i는 충돌 회피와 같은 작업 수행을 위한 제약 함수이며 \lambda_i는 목적의 중요도를 나타내는 가중치입니다.
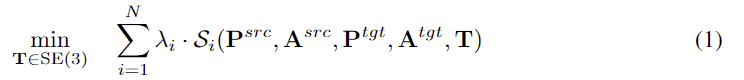
[Constraint Generation with LLM]

저자들은 다양한 작업으로의 확장을 위해 수동 규칙을 생성하는 대신 LLM을 활용하여 작업별로 제약 함수를 생성하도록 하였습니다. 즉, 위의 식에서 \mathcal{S}_i를 생성하는 방식입니다. LLM의 상식적 지식을 활용하여 객체가 어떻게 상호작용하고 변형되어야 하는지에 대한 고수준의 기하학적 목표로 변환합니다. 구체적으로는 위의 프롬프트와 같이 작업에 대한 설명을 제공하고, LLLM은 객체의 point cloud와 affordance map을 입력으로 사용하는 python 함수를 생성하게 됩니다. 이러한 python 함수는 물체의 alignment, contact, insertion과 같이 작업을 위한 공간적 관계를 나타내도록 하며, 아래의 Figure 11은 이에 대한 예시입니다.

이렇게 생성된 제약에 대한 점수를 활용하여 객체의 최종 자세 \mathbf{T} \in SE(3)를 최적화 solver로 계산하여 로봇 조작을 수행합니다.
Experiments
저자들은 실험을 통해 affordance grounding과 로봇 조작 task에 대한 평가를 수행합니다. 실험을 통해 (1) O2O affordance grounding에서 저자들의 방식이 얼마나 효과적인지, (2) 각 affordance 유형에 대하여 하나의 샘플만으로 학습하였을 때, 다른 객체로의 일반화가 가능한지, (3) 저자들이 제안한 방식이 로봇 작업에 어떤 효과를 줄 수 있는 지 확인하고자 하였습니다.
0. Setup
고품질의 O2O affordance grounding 데이터 셋이 부재하므로, 저자들은 SAPIEN을 활용하여 시뮬레이션 상에서 자체적으로 어노테이션을 수행하고 데이터를 구축하였다고 합니다. affordance map을 생성하는 과정은 다음과 같습니다. 먼저 point cloud상에서 사용자가 contact point를 여러 개 할당 한 뒤, 각 지점 사이의 그래프 전파 기법을 사용하여 물체 표면 전체에 확률적 점수를 할당하는 방식으로, 3D affordance grounding 연구에서 사용되는 3D AffordanceNet의 annotation 방식을 활용하였습니다.

저자들은 시뮬레이션 환경(SAPIEN)과 실제 환경(Franka Research 3 robot) 모두에서 로봇 조작에 대한 실험을 수행하였으며, 시뮬레이션은 workspace 주변에 4개의 stereo-depth 센서, 실제 환경에서는 2개의 Orbbec Femto Bolt 카메라를 이용하였고, LLM으로는 GPT-4o를 사용하였다고 합니다. 또한, 두 객체가 의미 있는 상호작용을 위해 다음의 5가지 작업 시나리오를 설계하였으며, 각 affordance마다 하나의 샘플만을 학습에 포함하였습니다.
- pouring from teapot into bowl
- inserting toast into toaster
- pressing the button with hammer
- hanging mug onto mug tree
- cutting apple with knife
1. Affordance Grounding
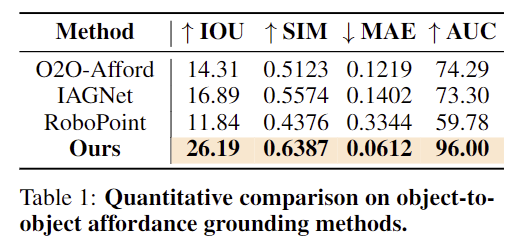
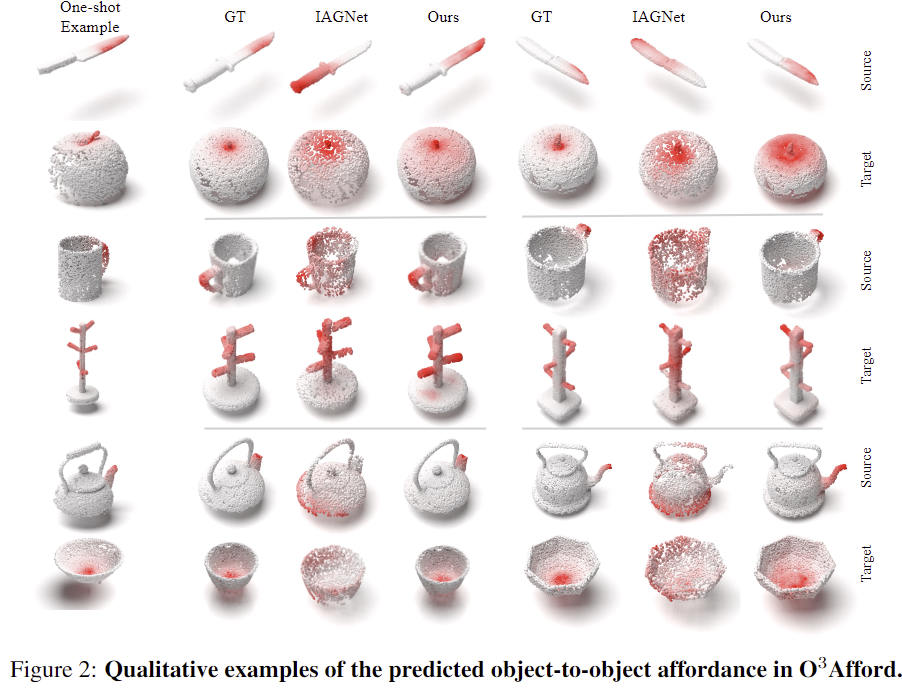
위의 Table 1은 affordance grounding에 대한 정량적 비교 결과이며, Figure 2는 3가지 affordance에 대한 정성적 결과입니다. O2O-Afford는 3D O2O 데이터로 학습하였으며, IAGNet은 2D 이미지에 대한 affordance 모델, RoboPoint는 VLM 기반의 방식으로, 이러한 베이스라인들과 비교하였을 때도 가장 좋은 성능을 달성하였습니다. 각 affordance에 대하여 하나의 샘플만으로 Intra-Class Generalization이 가능함을 보였습니다. (외형이 다르지만 같은 물체 카테고리)
[Generalization Analysis]
저자들은 occlusion 정도에 대한 일반화 성능과 cross-category에 대한 일반화 성능을 추가로 분석하였습니다.
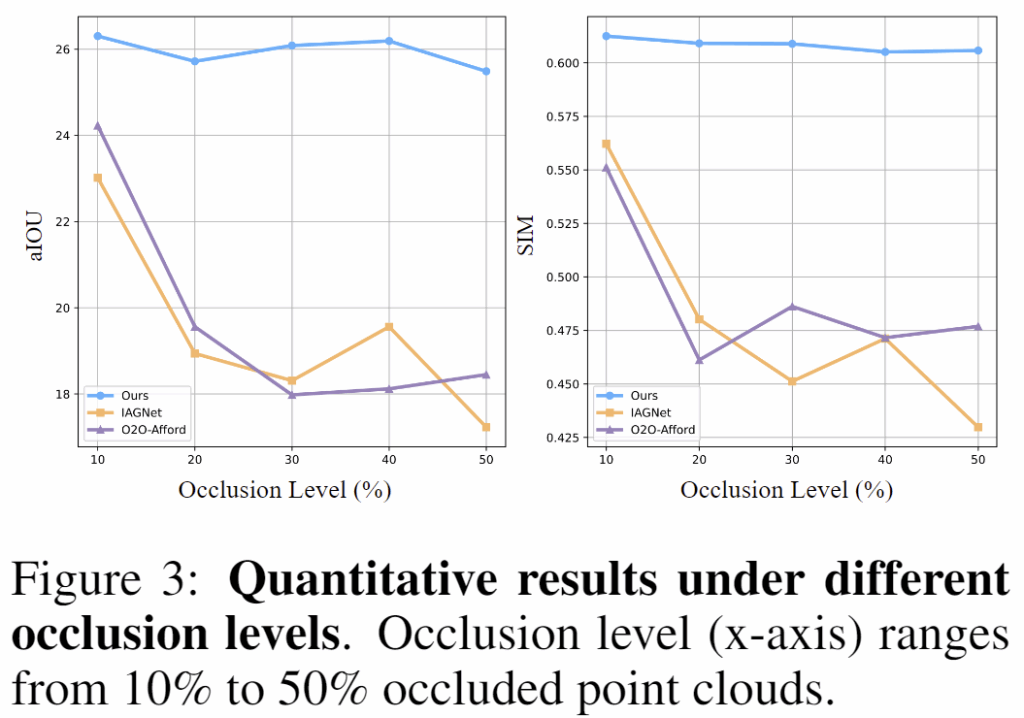

저자들은 point를 단순히 제거하는 것이 아니라 다른 객체에 의해 가려지는 현실적인 occlusion 상황을 통해 occlusion에 대한 일반화 성능을 확인하고자 하였습니다. 해당 실험에서 RoboPoint는 학습 기반 방식이 아니므로 제외하였으며, 위의 Figure 3은 가려짐 정도에 따른 aIoU와 SIM의 변화를 나타내는 그래프이며, Figure 6은 가려짐 정도에 따른 정성적 결과입니다. 해당 논문의 방식은 성능 저하가 적다는 것을 그래프로 확인할 수 있으며, 다른 방식은 기하학적 변하로 인해 성능이 크게 저하되었다고 어필합니다. 그런데 4가지 지표가 아니라 2가지만 리포팅한 것이 의문이기는 합니다. 그래도 다른 방법론과 비교하였을 때, aIoU와 SIM에서의 성능 차이가 상당하기 때문에 유의미한 결과라 생각합니다.

다음으로 cross-category에 대한 일반화 성능을 확인하기 위한 실험으로 위의 Figure 4는 새로운 객체에 대한 예측 결과를 정성적으로 나타낸 것 입니다. (칼→가위, 머그 걸이→행거, 주전자→분무기) 학습에 사용되지 않은 물체 카테고리에 대하여 확장이 가능함을 확인하였으며, latent 패치에 대한 시각화를 통해 (아래의 Figure 9) 유사한 기하학적 부분이 모이는 경향이 있다는 것을 보였습니다.

2. Affordance-Guided Manipulation
다음은 로봇 작업에 대한 실험 결과입니다. 저자들은 keypoint를 활용하여로봇 조작을 수행하는 ReKep과 저자들의 방식에서 affordance를 사용하지 않고 point cloud만 직접 사용하는 방식을 Baseline으로 하여 로봇 조작을 평가하였습니다. 5가지 작업에 대한 결과로, 10번의 시도 중 몇 번 성공하였는지를 평가하였습니다.
[Results in Simulation]

위의 Table 2는 5가지 작업에 대한 성공률로, 카메라 view 개수에 따른 성능 변화를 함께 보였습니다. (저자들은 4개를 full observation으로 보고, 2-view를 심각한 occlusion이 발생한 것으로 보았습니다.) 정량적 결과를 통해 저자들이 제안하는 방식이 모두 좋은 성능을 보이는 것을 확인할 수 있었으며, occlusion이 발생하더라도 강인하게 작동한다는 것을 2-view 결과를 통해 보였습니다. 또한, Baseline 방식은 객체 사이의 관계를 고려하지 못하여 가장 성능이 낮았으며, 이를 통해 로봇 작업에 affordance를 통합하는 것이 중요함을 어필하였습니다.
또한, 저자들은 ReKep의 2가지 한계를 분석하였습니다. 하나는 ReKep 방식의 keypoint가 실제 작업에 유효한 keypoint라는 보장이 없다는 것으로, full observation에서도 성능이 낮다는 점을 근거로 들었습니다. 또 다른 하나는 occlusion에 취약하다는 것으로 view 수가 줄어들수록 성능이 저하된다는 것을 실험적으로 보였습니다.
[Results in Real-World]
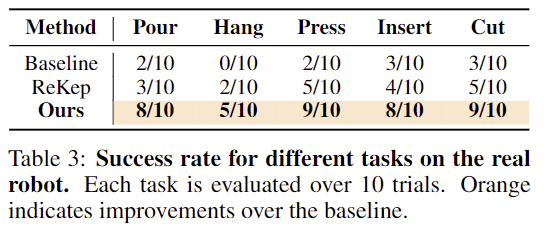
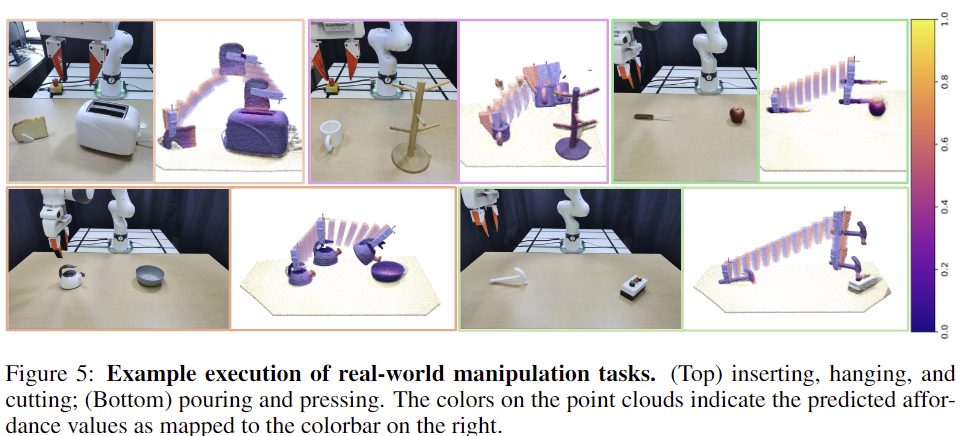
시뮬레이션 환경과 동일하게 5가지 작업에 대하여 2가지 방법론을 실험하였으며, Table 3이 이에 대한 정량적 결과입니다. 실험 결과 마찬가지로 다른 방법론 대비 뛰어난 성능을 보이는 것을 확인할 수 있으며, Hang과 같이 복잡한 작업에 대해서는 Baseline 방식이 모두 실패하였으나, 저자들의 방식은 50% 성공하였음을 어필합니다. 아래의 Figure 5는 저자들의 방식에 대한 정성적 결과로, 작업이 이루어짐에 있어 일관된 조작이 가능함을 보여줍니다.