안녕하세요, 이번주 X review는 real to sim to real을 주제로 작성한 논문입니다. 이번 2025년 CoRL의 Oral paper인데, 지난주와 마찬가지로 시뮬레이션환경, synthetic data를 어떤식으로 활용할 것인가?에 대한 인사이트를 주는 논문입니다. 작년 여름쯤 논문이 막 올라왔을때 해당 논문을 접했을땐 매번 강화학습을 진행해야 하니 너무 비효율적이라는 생각에 그냥 넘겼었는데, 이번에 oral이라는 소리에 헉해서 다시 읽어보니 강점이 확실한 연구였습니다. 리뷰 시작해보도록 하겠습니다.
Introduction
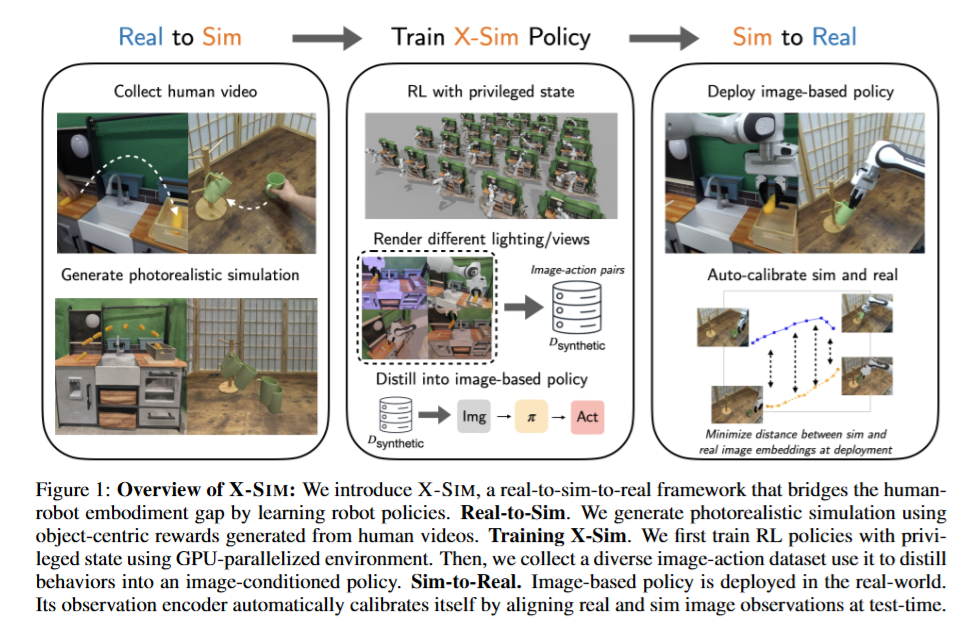
최근 로봇 파운데이션 모델을 꿈꾸며 대규모 로봇 데이터로 학습을 시키는 모델들이 등장하고 있는데요, 대부분은 Imitation Learning 방식으로 학습을 시킵니다. 현재는 데이터의 대부분이 실제 로봇을 teleoperation 하는 환경에 의존적이기 때문에 수집비용이 크고 확장성이 낮은 문제를 가지고있는데요, 많은 연구들이 해당 문제를 다양한 방법으로 해결하려고 노력중입니다. 그 중 소개하려는 방법론은 인간 비디오를 통해 문제를 해결하려는 연구입니다.
인간 비디오는 정말 풍부하지만 행동 라벨의 부재로 인해 현재 표준으로 사용되는 Imitation Learning 파이프라인에 바로 투입할 수 없다는 한계를 가지고 있는데요, 이를 해결하기 위해 retargeting을 하거나 동영상에 로봇팔을 합성해 넣는 overlay 방식, 물체의 움직임을 따라서 IK를 통해 시각적/기구학적인 방법들로 접근했습니다. 다만 이렇게 비디오에서 액션을 직접적으로 변환하는 것에는 많은 오차가 있고, 이는 여전히 데이터의 품질 부분에서 로봇을 요구하는 robot-human paired 환경 (teleoperation 의존 데이터)의 한계를 넘지 못 했습니다.
저자는 이러한 문제를 인간의 행동 대신 인간의 행동이 객체에 가하는 효과에 집중하자는 아이디어로 접근해서 해결을 시도했습니다. Real to Sim을 통해 강화학습을 위한 photorealistic 환경을 구성하고 물체의 6D 궤적 자체를 reward로 설정한 강화학습을 통해 인간의 행동을 억지로 모사하는게 아닌 “인간이 물체에 가하는 효과”를 로봇만의 행동으로 풀어내자는게 핵심인 방법입니다. 이렇게 강화학습으로 깨우친 로봇 중심의 행동을 기존의 Imitation Learning으로 전이시키고, 더 나아가 Online Adaptation을 제안해 Sim to Real 까지 진행했습니다.
결론적으로 저자들은 기존의 Retarget, IK, 실물 로봇의 필요성에 대한 의존성을 모두 없앤 채로 RL policy가 만든 롤아웃을 실제 환경으로 전이해 기존의 Behavior Cloning을 위한 데이터 취득 파이프라인 대비 10배 빠른 시간으로 더 일반화 성능이 뛰어난 policy를 학습시킬 수 있었다고 합니다. “사람의 행동은 로봇이 완전히 따라할 수 없지만, 물체가 움직이는 궤적 자체는 사람과 같이 할 수 있다”가 핵심 인사이트 입니다.
Related Works
Behavior Cloning 중심의 Imitation Learning 기법들은 등장 초기부터 지금까지 image-action pair 데이터로 정책을 학습해왔고, 언제나 로봇 데이터를 필요로 했습니다. 이러한 데이터를 Human Video로부터 해결하려는 시도 또한 있었는데, 기본적으로 인간의 손에 집중해 인간 손의 trajectory를 로봇 end-effector로 매핑하려는 연구들, 사람의 손 위에 로봇팔을 오버레이해서 시각적인 부분만을 해결하려는 연구들, 객체 중심의 좌표계에서 사람의 손 움직임을 표현해 trajectory를 IK로 따라가는 object-relative hand trajectory연구들이 존재했습니다. 다만 이러한 연구들은 모두 embodiment mismatch (사람의 팔, 손 구조와 로봇의 구조가 기본적으로 다르다는 embodiment 구조의 gap)을 해결하지 못해 retargeting이 실패하기 쉽고, ill-pose에서는 IK가 작동하기 힘들어 현실에서 작동할때는 더더욱 문제점이 많았습니다.
이들의 공통적인 문제인 embodiment gap을 해결하기 위해서는 “로봇 행동의 레벨에서의 데이터 생성“이 이루어져야 했고, 이를 사람이 로봇 입장에서의 액션 labeling을 하는 teleoperation 방법으로 해결하고 있었습니다. 다만 해보신 분들은 모두 공감하겠지만 이는 사람 입장에서 부자연스러운 움직임을 야기하고, teleoperation을 통한 real data를 취득하는 것이 costly한 이유중에 하나가 되기도 합니다. 저자들은 이를 사람의 손 궤적을 무시하는 강화학습 기반의 cross-embodiment learning을 통해 해결했습니다. 기존에도 human motion을 강화학습의 reward로 설정하는 연구들이 존재했지만 이들은 사람의 trajectory를 reward로 설정해 기구학적인 불일치를 해결하지 못하거나 test time에서 object tracking이 필수이기 떄문에 noise, occlusion등에 매우 취약하다는 단점이 있었습니다.
다른 관점에서는 Real to Sim to Real 연구들이 어떻게든 학습을 시키고 나서 현실의 로봇으로 sim to real transfer를 하는 과정에서 발생하는 문제점들도 존재하는데요, 시뮬레이션이 시각적으로 현실적이지 못해 sim to real gap이 존재하거나 모션 플래너 기반의 open-loop로 실행하는 방법들은 작은 모델링 오차에도 실패하는 한계점이 존재했습니다. 저자들은 이러한 문제를 RL로 학습한 policy를 rollout하며 다양한 augmentation과 함께 closed-loop imitation learning policy로 이식하고 deployment시에 online domain adaptation을 수행해 실시간으로 gap을 보정하는 과정을 추가해 기존 연구들의 다양한 문제점을 해결했다고 합니다. 아래에서 자세한 방법론에 대해 다뤄보도록 하겠습니다.
Methods
앞서 얘기하기는 했지만 방법론의 핵심은 인간 행동 대신 object에 집중해 object의 궤적 변화를 reward로 사용해 RL을 학습시켜 state-action pair 인 synthetic data를 생성해 RL to IL distill을 했다는 점입니다. 파이프라인은 크게 세단계로 나눌 수 있는데요,
1. Photorealistic한 시뮬레이션 환경과 Object-centric Reward를 정의하기 위한 6D를 구하는 Real to Sim 단계
2. Simlation에서 RL을 학습시키고 그 행동을 기반으로 Synthetic Image-Action pair 데이터를 생성하는 단계
3. 생성된 synthetic data로 Image conditioned Policy를 학습하고 domain adaptation을 진행하는 단계
로 나눌 수 있을 것 같습니다. 각 단계별로 자세히 알아보도록 하겠습니다.
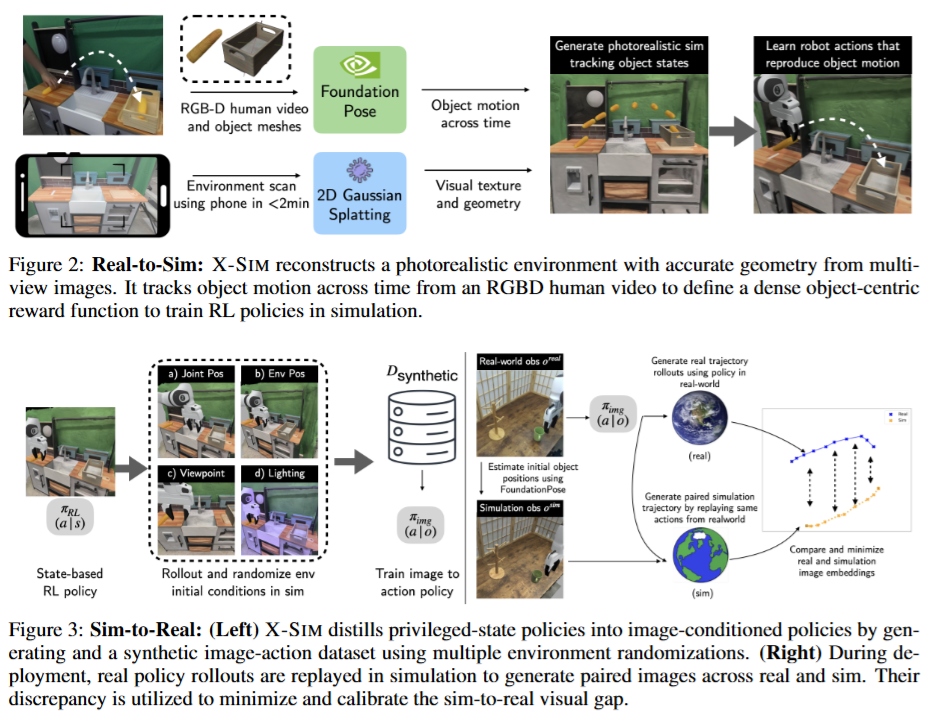
Real to Sim
Real to Sim은 현실적인 시뮬레이션 환경 구성과 object의 6D tracking을 위해 RGB-D 비디오가 input으로 사용됩니다. 제일 먼저 시뮬레이션 환경을 구성해야 하는데요, 이 때 저자들은 상호작용하는 물체의 경우 고품질 메시를 확보하기 위해 Polycam과 같은 off the shelf 3D scanner로 취득했습니다.
상호작용하는 객체 외의 다른 배경에 해당하는 환경은 기하적, 광학적으로 인관성을 갖춘 photorealistic한 메시를 생성하는 2D Gaussian Splatting을 통해 환경 메쉬를 만들었습니다. 이후 생성된 메쉬를 직접 scaling하고 배치해 ManiSkill 시뮬레이터에 import 했습니다. 이 때 객체의 상태나 환경 파라미터(물리적인 속성값, 동역학 파라미터)들은 기본 값을 사용했다고 합니다.
이후 비디오의 첫 프레임에서 SAM으로 객체의 2D 마스크를 생성해 foundationpose에 RGB-D, 객체 메쉬, 초기의 2D 마스크를 입력해 모든 프레임에서 객체의 6D pose를 구합니다. 이렇게 시뮬레이션 환경과 Human Video에서 취득한 sequential한 6D pose를 구하는 단계가 real to sim 단계입니다. 해당 단계에서는 모두 다른 연구에서 진행한 방법들을 그대로 사용했는데, 해결하고자 하는 문제가 명확하다면 다른 부분에 있어서는 힘을 빼도 되는 것 같습니다. 어쨌든 policy 학습을 위한 재료들이 다 준비가 됐습니다.
Generating Robot Actions in Simulation
이제 구성된 재료들을 가지고 human video에서 정의된 태스크 (객체의 궤적을 잘 추적하는 액션 수행)을 로봇이 잘 수행하도록 obejct-centric reward를 기반으로 시뮬레이터에서 privileged-state RL을 진행합니다. 대부분 real to sim to real에서 사용하는 기법으로 현실에서 얻을 수 있는 state 외에 다양한 시뮬레이터에서 직접 얻어올 수 있는 값들을 통해 효율적인 강화학습을 진행합니다. 이렇게 학습한 정책을 시뮬레이터에서 그대로 수행하며 로봇 위치, 객체 위치, 뷰포인트, 조명을 다양화 하며 시뮬레이터 내의 카메라를 통해 image-action pair데이터셋을 구성합니다. 여기서 생각해보니 사실 시뮬레이터의 가장 큰 이점은 privileged state이고 이는 강화학습의 효율성과 직결되는 문제인데, 왜 시뮬레이션에 집중하면서 강화학습은 멀리했을까,, 하는 생각이 들기도 했습니다. (해당 연구가 oral이니까 뒤늦게 이런 생각이 드는것 같기도 합니다 ㅋㅋㅋ) 아래 사진은 observation으로 활용한 시뮬레이터 상의 privileged information들입니다.
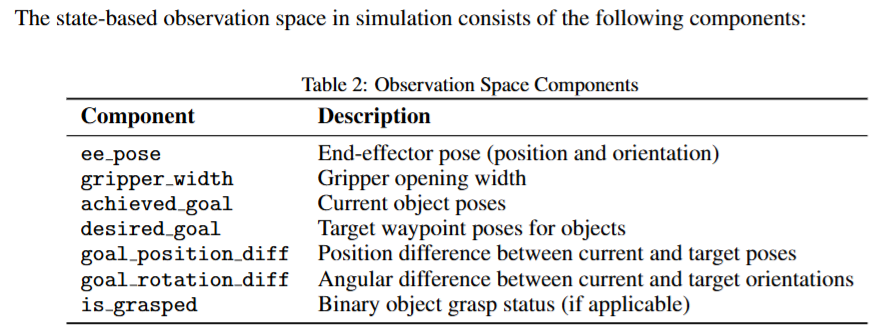
우선 RL을 진행하기 앞서 저자들은 object-centric Reward를 아래와 같이 정의했습니다.
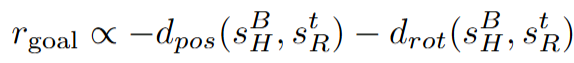
s^B_H는다음 목표 객체 상태 (human trajectory에서 얻은 다음 waypoint), s^t_R 현재 시뮬레이션 환경의 객체 상태, d_pos는 위치 오차 (position distance), d_rot는 회전 오차 (orientation distance)입니다. 결국 현재 객체의 pose와 다음 목표 pose의 차이를 계속 줄여갈수록 reward가 증가하는 형식입니다. PPO알고리즘이 이 reward를 최대화 하는 방향으로 계속 로봇을 옮겨가며 학습했습니다. 이 때 강건성을 갖기 위해 RL학습중에 객체 초기 pose를 랜덤화 했다고 합니다. 이렇게 학습된 정책은 시뮬레이터에서 실행하면서 image-action pair 데이터를 취득했는데, 이 때는 성공한 데이터만을 남겨두었다고 합니다. 객체의 초기 위치, 카메라 뷰포인트, lighting 조건을 rollout마다 체계적으로 변화시키면서 데이터 다양성을 확보했다고 합니다. 아래와 같은 randomization을 통해 하나의 비디오당 500개의 demonstration을 만들어 냈다고 합니다.
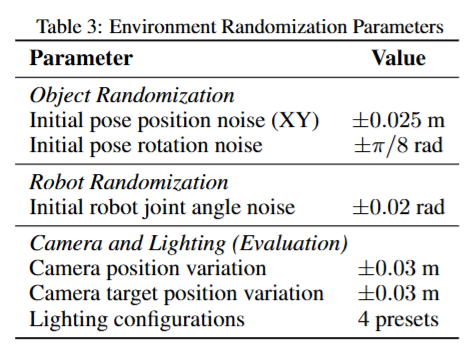
여기까지가 Real to Sim입니다. 요약하자면 해당 단계에서는 이전에 만들어둔 환경과 6D pose를 통해 reward를 설계하고 RL policy를 학습시켜 이를Imitation Learning을 위한 데이터로 정제했다고 보시면 될 것 같습니다.
Sim to Real Transfer of Image Based Policies
이제 앞서 시뮬레이션으로 만든 강화학습 기반의 synthetic data로 real world에서 작동할 image based policy를 학습해야 합니다. 저자들은 해당 논문을 작성할 떄는 Diffusion Policy를 사용했다고 합니다. Image based policy로 distill 한 후에 real-world transfer를 강화하기 위한 핵심적인 기법으로 online domain adaptation을 제안했습니다. Real image observation을 통해 같은 rollout을 진행하는 simulated view와 자동으로 쌍을 만들어 sim to real의 visual gap을 최대한 줄였다고 합니다. 이를 통해 teleoperation 데이터가 필요하지 않은 현실 로봇의 image based policy learning을 달성할 수 있었다고 합니다. DP 학습은 연구 당시의 sota 모델이었기 때문에 DP를 학습시켰고, ResNet을 백본으로 하는 여타 연구들과 동일한 세팅으로 학습을 진행했습니다. 핵심은 online domain adaptation을 통한 real and sim간의 auto-calibration입니다.
Calibration 대상은 policy의 observation encoder입니다. Synthetic data를 통해 imitation learning을 진행한 뒤에 우선 real 환경에서 inference를 진행한다고 합니다. 이 때 task를 real환경에서의 task 성공 유무와 관계없이 행동하는 동안의 state-action pair를 취득하고, 해당 action을 물체의 위치가 real환경과 동일한 세팅으로 세팅된 시뮬레이션 환경에서 그대로 rollout해줍니다. 동일한 세팅은 foundationpose를 통해 얻은 6D를 그대로 시뮬레이터에 적용했다고 합니다. (어쨌든 현실-시뮬레이터간 좌표계 문제는 해결을 한 것인가..) 여기서 rollout을 현실과 그대로 진행하면서 얻은 시뮬레이션의 이미지들과 현실에서 inference를 진행하면서 얻은 이미지들을 paired images로 정의하겠습니다. Paired images를 통해서 policy의 observation encoder를 contrastive learning을 통해 학습시킵니다. 한 쌍에서 각 이미지들은 같은 상태를 나타내는 것이기 때문에, 인코더가 두 이미지를 비슷한 특징벡터로 매핑하도록 학습합니다. 동시에, 다른 상태에서 나온 이미지들은 서로 멀리 떨어진 임베딩을 갖도록 학습합니다. 다른 환경에서의 이미지가 같은 state라면 가깝게, 다른 state라면 멀어지게 학습해서 결국 인코더가 조명이나 texture와 같은 요소들보다 로봇과 물체가 어디 있는지에 집중할 수 있게 해준다고 합니다. Calibration의 loss는 다음고 ㅏ같습니다.
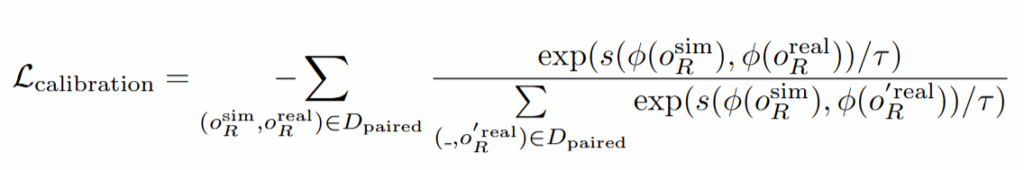
ϕ는 policy의 이미지 인코더를 의미하고, s는 cosine similarity 입니다. τ는 softmax분포의 sharpness를 조절해 positive와 negative의 차이를 얼마나 더 강하게 해줄지를 결정하는 temperature hyperparameter입니다.
결과적으로 behavior cloning loss로 policy자체를 synthetic dataset을 통해 Diffusion Policy의 전체적인 파라미터들을 학습하고, action decoder는 냅두고 인코더만 따로 InfoNCE loss를 통해 학습 시키는 two stage 형태인 것 같습니다. 이 과정에서는 현실에서의 행동이 sim to real gap에 의해 실패하더라도 같은 액션을 그대로 시뮬레이터에서 취하기 때문에 똑같이 실패하고, 성공 유무와 상관없이 encoder를 강화할 수 있는 데이터로 취득될 수 있기 때문에 특히 강점을 갖는다고 합니다. 개인적으로 제가 경험한 바로는 시뮬레이터가 그렇게까지 정교할 수 있나..? 싶긴 한데 의문이긴 합니다. Contrastive learning을 위한 image pair가 시뮬레이터와 real의 환경 gap 말고는 완벽히 같은 observation을 취하지 않아도 괜찮은건가.. 싶기도 하고 완전한 이해가 있어야 납득이 될 것 같습니다. 어쨌든 이 과정을 통해 평균 8퍼센트의 성능 향상이 있었다고합니다. 이 때도 대부분의 실험을 pick and place 수준에서 진행했지만 조금 더 고도화된 머그컵 걸기의 성능이 다른 task 대비 더 많이 (13퍼센트) 향상 했다고 하니, 의미가 있는 것 같습니다. 직접 따라가보거나 저자가 데이터를 올려주면 Contrastive Learning을 위한 데이터가 어떤 수준으로 구성돼있는지 확인해보고 싶습니다.
Experiments
실험은 X-sim이 human video로부터 synthetic data를 생성해 고성능 real-robot policy를 잘 학습할 수 있는가?를 검증하기 위해 아래와 같이 4개의 core question을 평가했습니다.
- Bridging the Embodiment Gap via Simulation — 단일 human demonstration 영상만 주어졌을 때, hand-tracking baselines 대비 X-SIM의 성능은 어떠한가?
- Sim-to-Real Policy Transfer — image-based policies의 sim-to-real transfer 실용성은 alternate observation representations 대비 어떤가?
- Data Efficiency — teleoperated robot data로 학습한 behavior cloning(BC) 대비, 데이터 수집 시간이 늘수록 X-SIM 성능은 어떻게 스케일링되는가?
- Robustness to Test-Time Changes — test-time 환경 변화에 대해 강인한가?
Core question들의 구성이 human video로부터 human과 robot의 구조 차이를 잘 다루었는지와 다른 real to sim to real 방법들과 다르게 privileged RL학습을 image based policy로 옮긴다는 컨셉이 sim to real gap을 줄이는 데에 있어서 기존의 pose based 대비 어떻게 우세한지를 평가하는 것으로 이해하면 될 것 같습니다.
실험 환경과 같은 경우는 kitchen환경과 tabletop 환경에서 총 5개의 task를 구성해 진행했다고 합니다. 로봇은 7DoF인 Franka Panda를 활용했고 입력 이미지로는 ZED2 stereo camera를 통해 녹화한 RGB-D 비디오를 활용했습니다. Task는 pick and place, letter arrange, precise insertion으로 나누어 진행했습니다. 따로 언급은 없지만 입력 이미지와 같은 카메라를 통해 policy를 inference했다는 것과 실험 이미지를 통해 유추해보면 wrist cam 없이 진행한 것 같습니다. 평가 지표로는 human video 대비 초기자세를 약간씩 바꿔가며 10번의 trial을 진행하며 grasp based task들은 approach, grasp, goal complete 세개로 나누어 average task progress를 지표로 사용했고, letter arrange와 같은 task는 approach, rotation, goal complete로 나누어 task progress를 구했다고 합니다.
Bridging the Embodiment Gap via Simulation

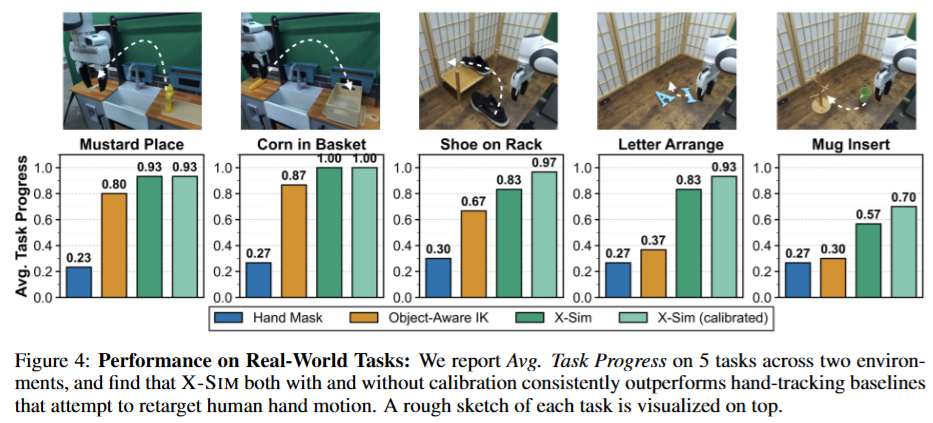
X-sim이 기존의 hand-retargeting approach들의 한계를 해결했는지?에 대해 human hand를 inpatining하는 기법들과 IK를 통한 retargeting을 하는 방법론들을 baseline으로 삼아 평가를 진행했습니다. Baseline 방법론들 모두 시뮬레이션을 활용하지 않고, 사람의 행동을 로봇이 다 재현할 수 있다는 가정을 통해 진행했기 때문에 시각적, 역학적 gap의 한계를 극복하지 못 했다고 합니다. Hand mask의 경우 baseline으로 PHANTOM이라는 방법론을 사용했습니다. Human Video에 손을 검은색으로 색칠해서 object를 따라가게 하고 inference시에도 유사하게 로봇팔을 검은색으로 색칠해서 접근하는 방식이라고 합니다. 당연하게 robot의 observation과 human의 visual gap을 극복하지 못해 approach phase를 넘기지 못 하는 경우가 많았다고 합니다. HAMER라는 손의 trajectory를 추적하고 이를 IK로 따라하는 IK를 통한 접근또한 table top환경에서 kinematic infeasibility가 두드러지며 human motion을 직접 모방할 수 없었다고 합니다. 해당 baseline들은 x-sim이 calibration 없이도 일관되게 더 높은 성능을 달성했다고 합니다
Sim to Real Policy Transfer


여기서는 RGB이미지 만으로 sim 에서 real로의 전이가 가능한지 평가하고, 이를 기존의 privileged state만 활용하는 sim to real 방법과 비교했습니다. baseline으로는 human2sim2robot이라는 연구를 활용했습니다. 현실에서는 당연하게 occlusion, depth noise, 데이터 취득을 위한 vision model들의 한계로 인해 privileged state 베이스의 모델이 학습한 환경과 견줄만한 observation을 하기 힘들고, 실제로 inference 시에 tracking error가 조금이라도 생기면 ood로 실패했다고 합니다. Privileged state based 에서 vision based로의 전환이 굉장히 의미가 있는 점을 어필하는 실험입니다. 또 이때 시뮬레이션으로의 불완전한 real to sim 역시 online calibration을 통해 극복할 수 있음을 보여줍니다. 정밀한 시뮬레이션의 필요성이 좀 죽어버리는 실험이어서.. 아차 싶었습니다. Paired sim/real videos로 policy observation encoder를통한 t-SNE embedding을 시간축으로 시각화 했을 때 임베딩의 정렬이 좋아지는것과, domain-specific한 attribute에 대해 오버피팅을 막았다는 결괄르 볼 수 있습니다.
Data Efficiency
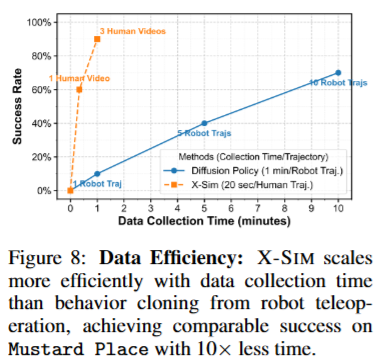
해당 실험에서는 X-sim의 성능이 데이터 취득 시간에 비례해 어떻게 스케일링 되는지 확인하기 위해 로봇 teleoperation을 통한 BC 방법과 비교를 진행했습니다. Task는 머스타드 병을 지정된 위치에 집어다 놓는 pick and place로 진행했습니다. 학습 데이터 다양성을 강제하기 위해 initial state distribution을 확장한 채로 실험을 진행했고, 실험 진행 결과 시뮬레이션에서 object pose를 다양하게 바꿔서 initial state에대한 분포를 커버할 수 있는 강점이 드러나는 것을 볼 수 있었습니다. X-sim 의 경우 1분 정도의 human video 만으로 90%의 success rate를 달성했지만 기존의 robot demostration을 활용한 경우 10분동안의 robot demonstration을 통해서도 70퍼센트 정도의 성공률을 기록했습니다.
Robustness to Test-Time Changes
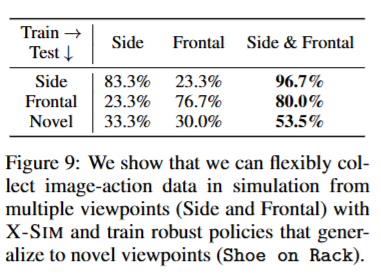
여기선 inference시에 view point에 대한 일반화 실험을 진행했습니다. 신발을 지정된 랙에 정렬하는 pick and place 실험인 shoe on rack task를 가지고 평가했고, 기존의 image conditioned policies가 viewpoint에 굉장히 민감해서 여러 카메라 view에 대한 추가적인 데이터 수집이 필요하다는 점을 어필했습니다. 따라서 아래와 같이 Side, Frontal viewpoint에서 렌더링 하며 데이터를 취득해 side, frontal 만 가지고 학습했을 때 보다 각각의 viewpoint와 더불어 Novel viewpoint에서도 더 높은 성공률을 기록했습니다. 이 점이 시뮬레이션의 큰 강점중에 하나인 것 같습니다.

Conclusion
X-sim은 robot teleoperation 없이 human video로부터 robot manipulation policy를 학습할 수 있는 프레임워크인데 저는 사실 ‘로봇 없이’라는 부분은 결국 현실에서 rollout을 하며 encoder를 학습시켜야 하는 점에서 조금 약하지 않나.. 라고 생각하고, 이런 데이터 수집 파이프라인을 기존의 state-action pair로 학습하는 많은 IL 방법론들에 그대로 적용시키며 로봇 기준으로의 액션을 더 명확히 정의할 수 있는 점에서 굉장히 의미가 있다고 생각합니다. 기존의 Privileged RL과 imitation learning의 장점들을 잘 결합한 연구이지 않나 생각합니다. 해당 방법으로 기존의 pretrained model들을 fine tuning했을때 성능이 어떻게 될지에 대한 실험이 있었다면 굉장히 흥미로웠을 것 같습니다.
다만 역시 객체 mesh를 따로 만들어 두어야 한다는 점 (mesh는 무조건 고퀄리티로 존재한다는 전제)과 6D pose estimation에 의존한다는 점에서 성능적으로는 조금 고도화된 task들에 대해서, 아니면 특정 환경에서 제약이 있을 것 같다는 한계가 있었고, 무엇보다 시뮬레이션을 활용한다는 점에서 articulated, deformable object들에 대한 학습은 불가능 하다는 한계를 볼 수 있었습니다. 또 물체와 시뮬레이션 환경의 물리적인 파라미터들이 전부 다 기본값을 사용할 수 밖에 없었다고 저자들은 한계로 인정한다며 언급했는데, 현재 진행되고 있는 각종 연구들의 필요성 또한 한 번 더 각인이 됐던 것 같습니다.
안녕하세요. 리뷰 잘 읽었습니다. 분야가 분야다보니 제가 이해가 좀 잘 안돼서 질문이 좀 긴 점 양해부탁드릴게요. 질문 드릴 때 저의 의식의 흐름을 같이 설명드려야 할 것 같아서요ㅋㅋ..
사람의 행동을 로봇이 따라하지 못하지만 물체가 움직이는 궤적은 사람과 유사하게 로봇이 할 수 있다는 개념을 강조하셨는데, 사람의 행동을 로봇이 따라하지 못한다는 건 로봇팔의 관절 등 자유도가 사람과 동일하지 않아서 불가능하다고 이해했습니다. 그래서 학습을 위한 action 결과값을 결국 로봇팔을 직접 teleoperation해서 취득할 수 밖에 없는데 이는 사람 관점에서 너무 취득이 힘들고 비용이 많이 든다는 단점을 리뷰에 언급해주셨구요.
다른 대안책으로 사람의 모션을 reward로 삼은 강화학습 기반 방법론들이 활용될 수 있는데, 이게 그럼 맨 처음의 문제인 사람의 움직임은 로봇팔의 움직임과 같을 수 없다는 문제점?에 여전히 가로막혔다고 이해를 했습니다.
그래서 저자들이 새로운 제안책으로 사람의 손 궤적은 무시하고 객체의 궤적 움직임에 집중하자라고 했는데, 여기서 제 의문은 사람처럼 움직이지 못하는데 사람이 어떤 물체를 옮길 때 발생하는 궤적을 어떻게 로봇팔이 따라할 수 있다는 것인지 그 저자의 통찰에 대해서 저는 감을 잘 못잡겠네요.
그냥 단순하게 생각해서 왼쪽 바구니에 있는 공을 오른쪽 바구니에 넣어야한다면 그게 어떻게 움직여야 시작 위치에서 끝 위치로 갈 수 있을지에 대한 매우 다양한 경우의 수를 알아서 reward가 높아지는 방식으로 학습한다는건가요?
그리고 실제로 저자의 철학이 구현되는 reward 계산 방식에 대해서도 질문이 있습니다. 테이블2와 3 사이에 있는 수식을 통해서 모델이 궤적을 학습하는 것으로 저는 이해를 했는데, 저게 단순히 연속된 프레임이 있으면 이전 pose에서 로봇팔이 움직였을 때의 객체 pose가 실제 정답 pose와 유사해지도록 reward를 계산하는거 아닌가요? 제가 잘 몰라서 그런 생각을 할 수도 있지만 지금 reward 계산 방식이 직관적이고 단순해보여서.. 기존 연구들은 사람 모션에 대한 reward 계산을 어떻게 모델링했길래 저자의 저 단순해보이는 reward 계산 방식이 기존의 문제점을 해결하고 더 좋은 결과를 가져왔는지 궁금하네요.
질문이 너무 길었는데 정리하자면 저자의 “사람의 궤적이 아닌 물체의 궤적에 집중하자”라는 철학을 더 깊이 있게 이해하려면 기존 연구들은 어떤식으로 reward 계산을 하고 모델링했는지 구체적인 부분을 조금 더 알면 좋을 것 같아서 그 부분을 질문드립니다.
감사합니다.
안녕하세요 정민님 댓글 감사합니다.
말씀해주신 것 처럼 로봇은 사람처럼 움직일 수 없는게 맞습니다. 다만 로봇이 사람처럼 움직일 수 없는것과 물체의 궤적을 따라갈 수 없는것은 다른 문제입니다. 간단하게 로봇이 물체를 움직일 수 있는 “로봇만의 동작”이 있는데, “사람의 동작”을 따라하라고 하려다보니 문제가 생기는 것입니다.
기존의 연구들은 사람의 모션을 reward로 주어 강화학습을 진행하거나, 기구학적인 접근을 하더라도 사람 손의 trajectory를 IK로 추적했습니다. 그러다보니 모션 자체가 action space에서 정의될 수 없는 모션인 경우들이 생겼고, 이러한 embodiment gap이라는 한계를 넘을 수 없었습니다. 완전히 맞는 예시인지는 모르겠지만 바닥에 있는 물체를 휠체어에 탄 사람이 집을 수는 있지만 두 발이 자유로운 사람과는 다른 궤적을 통해 잡아야하는데, 두 발이 자유로운 사람의 궤적을 무조건 따라하라고 하니 닿을 수 없는 waypoint들이 생기는 것입니다.
따라서 저자들은 결과적으로 객체가 어떻게 움직였는지에만 집중하고, 그 길을 로봇한테 ‘너가 도달할 수 있는 방법으로 알아서 가봐라’ 라고 하는 것입니다. 과정은 알아서 하되, 결과에 집중한다고 생각하시면 될 것 같습니다. 그래서 저자들이 설정한 reward도 현재 프레임 기준으로 다음 프레임의 물체 pose에 조금이라도 가까워 진다면 증가하도록 설계되었습니다. 실제로 굉장히 단순한 reward 설계이고, trajectory만을 따라가는 task를 학습하는 것이기 때문에 가능하다고 생각합니다. 물론 이전에 trajectory를 따라게 하는 reward가 제시된적이 없는것도 아닙니다. 다만 모두가 인간의 행동에 로봇을 맞추려고 할 때 물체에 집중했다는 점이 차별점입니다.
또 해당 연구의 contribution은 강화학습 이후에 현실로 deploy하는 과정에서 로봇 policy의 인코더를 학습하는 loss를 제안해 현실과 시뮬레이터의 gap을 줄인것에도 있기 때문에 reward 자체가 꼼꼼하게 설계됐다기 보다는 기존의 방법을 따르되 관점만 좀 새롭게 바꾸고, 추가적인 refinement를 진행해서 성능이 향상됐다고 이해하시면 될 것 같습니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
인간의 행동 대신 인간의 행동이 객체에 가하는 효과에 집중하자에서 시작해서 물체의 6D 궤적이 reward로 쓰인 RL 이후, 그 기반으로 rollout한 synthetic data와, 그것과 view가 쌍을 이루는 real image obs 를 둘 다 활용해서 IL의 DP를 학습한 것으로 이해했는데요. 여기선 특히 synthetic view 와 real view 간의 visual gap을 줄이기 위해 auto-calibration을 진행한 것도 핵심으로 이해했습니다.
즉 핵심이 reward를 물체의 6D 궤적으로 한 RL과, RL->IL distill에서 visual-gap 줄이기 위해 online domain adaptation을 통해 auto-calibration하자가 핵심 contribution인 것으로 이해했습니다.
근데 실험 파트에서 이 reward를 다른 방식으로 변화를 주어 RL을 진행한 ablation이 없는 것이 의아한데요. RL의 reward와 auto-calibration 중 어느 것이 더 성능 향상에 도움을 주었는지 잘 파악을 못해서 그런데, 혹시 figure4 가 RL reward, auto-calibration의 유무에 변화를 두며 진행한 실험인 것으로 이해하면 되는 건가요?
안녕하세요 재찬님 댓글 감사합니다.
reward를 다른 방식으로 변화를 주어 RL을 진행한 ablation이라는 표현이 객체 중심의 reward와 모션 중심의 reward를 말씀하시는건가요? 그렇다면 baseline으로 심은 human2sim2robot과의 비교를 보시면 될 것 같습니다. 해당 연구가 사람의 손을 기준으로 강화학습을 진행해서 sim to real을 진행한 연구입니다. figure4는 이해하신 부분이 맞습니다! (나머지 부분은 구두로 답변했습니다)
안녕하세요 영규님 좋은 리뷰 감사합니다.
제가 리뷰를 읽으면서 이해한 바로는, 사람이 옮기는 물체의 trajectory 학습해서 로봇의 end-effector가 그 trajectory를 따라가도록 학습 된다는 것으로 이해했습니다. 이는 로봇과 사람간의 embodiment gap을 어느정도 해소하는데 도움이 된다는 것을 보고 흥미로웠습니다.
읽으면서 몇가지 궁금한 점이 생겼습니다.
첫번째는 읽으면서 궁금한 점은 로봇이 경로만 알고 있으면, 그 경로를 따라가는 많은 로봇 관절의 값들이 있을텐데.. 그 값들 중 최적화 된 값을 찾아내는 것인가요? 그리고 singularity 문제가 발생할 수도 있을 것 같은데 그런 경우에는 학습 과정에서 배제되는 건가요?
두번째는 이전의 연구 중 인간의 손에 집중해 인간 손의 trajectory를 로봇 end-effector로 매핑하려는 연구들 또한 결국 인간이 물체를 옮길 때 손의 경로를 따라가니까 소개해 주신 방식과 비슷한 것 같은데.. 다른 점이 무엇인가요?
감사합니다.
안녕하세요 인하님 리뷰 읽어주셔서 감사합니다.
첫번째 질문에 대한 답으로는 해당 기법은 물체의 trajectory를 dense reward로 정의해서 강화학습을 통해서 manipulator가 trajectory를 따라가도록 학습시킵니다. 강화학습은 다음 action을 로봇 입장에서 고르기 때문에 기존 IK등의 retargeting 방법들이 겪는 embodiment gap을 최소화합니다. Singularity 문제가 아예 없다고 확신은 못 하겠지만 굉장히 많이 줄어들 것 같습니다.
두번째 질문에 대한 답도 결국 인간 손을 따라가다보면 로봇이 로봇만의 방식으로 작동하는게 아닌 다른 관절구조, 링크 구조를 갖는 인간의 움직임을 따라가면서 embodiment gap이 발생하게 되는데, 물체의 위치를 로봇이 알아서 찾아가면서 해당 문제를 최소화합니다
좋은 리뷰 감사합니다. 잘 읽었습니다.
로봇 분야의 논문리뷰는 처음 읽어봐서 어렵지만 흥미로웠습니다.
simulation으로는 강화학습을 해서 마치 teacher model처럼 사용하고
real에서는 imitation learning으로 distillation하는게 인상 깊었습니다.
의문이 드는 부분이 한 곳이 있어서 질문 드리겠습니다.
‘이 때 강건성을 갖기 위해 RL학습중에 객체 초기 pose를 랜덤화 했다고 합니다’라는 부분이 이해가 안갔습니다. 결국 real to sim에서는 사람 행동의 6D 궤적을 학습에 이용한다고 이해했습니다. 그렇다면 initial pose를 simulation상에서 랜덤화한다면, 추출한 사람의 6D 궤적과 안맞게 되는게 아닌가하는 의문이 들었습니다.